「為什么 MySQL 采用 B+ 樹作為索引?」這句話,是不是在面試時經常出現,
要解釋這個問題,其實不單單要從資料結構的角度出發,還要考慮磁盤 I/O 操作次數,因為 MySQL 的資料是存盤在磁盤中的嘛,
這次,就跟大家一層一層的分析這個問題,圖中包含大量的動圖來幫助大家理解,相信看完你就拿捏這道題目了!
怎樣的索引的資料結構是好的?
MySQL 的資料是持久化的,意味著資料(索引+記錄)是保存到磁盤上的,因為這樣即使設備斷電了,資料也不會丟失,
磁盤是一個慢的離譜的存盤設備,有多離譜呢?
人家記憶體的訪問速度是納秒級別的,而磁盤訪問的速度是毫秒級別的,也就是說讀取同樣大小的資料,磁盤中讀取的速度比從記憶體中讀取的速度要慢上萬倍,甚至幾十萬倍,
磁盤讀寫的最小單位是扇區,扇區的大小只有 512B 大小,作業系統一次會讀寫多個扇區,所以作業系統的最小讀寫單位是塊(Block),Linux 中的塊大小為4KB,也就是一次磁盤 I/O 操作會直接讀寫 8 個扇區,
由于資料庫的索引是保存到磁盤上的,因此當我們通過索引查找某行資料的時候,就需要先從磁盤讀取索引到記憶體,再通過索引從磁盤中找到某行資料,然后讀入到記憶體,也就是說查詢程序中會發生多次磁盤 I/O,而磁盤 I/O 次數越多,所消耗的時間也就越大,
所以,我們希望索引的資料結構能在盡可能少的磁盤的 I/O 操作中完成查詢作業,因為磁盤 I/O 操作越少,所消耗的時間也就越小,
另外,MySQL 是支持范圍查找的,所以索引的資料結構不僅要能高效地查詢某一個記錄,而且也要能高效地執行范圍查找,
所以,要設計一個適合 MySQL 索引的資料結構,至少滿足以下要求:
-
能在盡可能少的磁盤的 I/O 操作中完成查詢作業;
-
要能高效地查詢某一個記錄,也要能高效地執行范圍查找;
分析完要求后,我們針對每一個資料結構分析一下,
什么是二分查找?
索引資料最好能按順序排列,這樣可以使用「二分查找法」高效定位資料,
假設我們現在用陣列來存盤索引,比如下面有一個排序的陣列,如果要從中找出數字 3,最簡單辦法就是從頭依次遍歷查詢,這種方法的時間復雜度是 O(n),查詢效率并不高,因為該陣列是有序的,所以我們可以采用二分查找法,比如下面這張采用二分法的查詢程序圖:

可以看到,二分查找法每次都把查詢的范圍減半,這樣時間復雜度就降到了 O(logn),但是每次查找都需要不斷計算中間位置,
什么是二分查找樹?
用陣列來實作線性排序的資料雖然簡單好用,但是插入新元素的時候性能太低,
因為插入一個元素,需要將這個元素之后的所有元素后移一位,如果這個操作發生在磁盤中呢?這必然是災難性的,因為磁盤的速度比記憶體慢幾十萬倍,所以我們不能用一種線性結構將磁盤排序,
其次,有序的陣列在使用二分查找的時候,每次查找都要不斷計算中間的位置,
那我們能不能設計一個非線形且天然適合二分查找的資料結構呢?
有的,請看下圖這個神奇的操作,找到所有二分查找中用到的所有中間節點,把他們用指標連起來,并將最中間的節點作為根節點,

怎么樣?是不是變成了二叉樹,不過它不是普通的二叉樹,它是一個二叉查找樹,
二叉查找樹的特點是一個節點的左子樹的所有節點都小于這個節點,右子樹的所有節點都大于這個節點,這樣我們在查詢資料時,不需要計算中間節點的位置了,只需將查找的資料與節點的資料進行比較,
假設,我們查找索引值為 key 的節點:
-
如果 key 大于根節點,則在右子樹中進行查找;
-
如果 key 小于根節點,則在左子樹中進行查找;
-
如果 key 等于根節點,也就是找到了這個節點,回傳根節點即可,
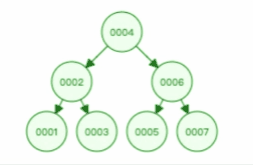
二叉查找樹查找某個節點的動圖演示如下,比如要查找節點 3 :
另外,二叉查找樹解決了插入新節點的問題,因為二叉查找樹是一個跳躍結構,不必連續排列,這樣在插入的時候,新節點可以放在任何位置,不會像線性結構那樣插入一個元素,所有元素都需要向后排列,
下面是二叉查找樹插入某個節點的動圖演示:

因此,二叉查找樹解決了連續結構插入新元素開銷很大的問題,同時又保持著天然的二分結構,
那是不是二叉查找樹就可以作為索引的資料結構了呢?
不行不行,二叉查找樹存在一個極端情況,會導致它變成一個瘸子!
當每次插入的元素都是二叉查找樹中最大的元素,二叉查找樹就會退化成了一條鏈表,查找資料的時間復雜度變成了 O(n),如下動圖演示:

由于樹是存盤在磁盤中的,訪問每個節點,都對應一次磁盤 I/O 操作(假設一個節點的大小「小于」作業系統的最小讀寫單位塊的大小),也就是說樹的高度就等于每次查詢資料時磁盤 IO 操作的次數,所以樹的高度越高,就會影響查詢性能,
二叉查找樹由于存在退化成鏈表的可能性,會使得查詢操作的時間復雜度從 O(logn)降低為 O(n),
而且會隨著插入的元素越多,樹的高度也變高,意味著需要磁盤 IO 操作的次數就越多,這樣導致查詢性能嚴重下降,再加上不能范圍查詢,所以不適合作為資料庫的索引結構,
什么是自平衡二叉樹?
為了解決二叉查找樹會在極端情況下退化成鏈表的問題,后面就有人提出平衡二叉查找樹(AVL 樹),
主要是在二叉查找樹的基礎上增加了一些條件約束:每個節點的左子樹和右子樹的高度差不能超過 1,也就是說節點的左子樹和右子樹仍然為平衡二叉樹,這樣查詢操作的時間復雜度就會一直維持在 O(logn) ,
下圖是每次插入的元素都是平衡二叉查找樹中最大的元素,可以看到,它會維持自平衡:
除了平衡二叉查找樹,還有很多自平衡的二叉樹,比如紅黑樹,它也是通過一些約束條件來達到自平衡,不過紅黑樹的約束條件比較復雜,不是本篇的重點重點,大家可以看《資料結構》相關的書籍來了解紅黑樹的約束條件,
下面是紅黑樹插入節點的程序,這左旋右旋的操作,就是為了自平衡,
不管平衡二叉查找樹還是紅黑樹,都會隨著插入的元素增多,而導致樹的高度變高,這就意味著磁盤 I/O 操作次數多,會影響整體資料查詢的效率,
比如,下面這個平衡二叉查找樹的高度為 5,那么在訪問最底部的節點時,就需要磁盤 5 次 I/O 操作,
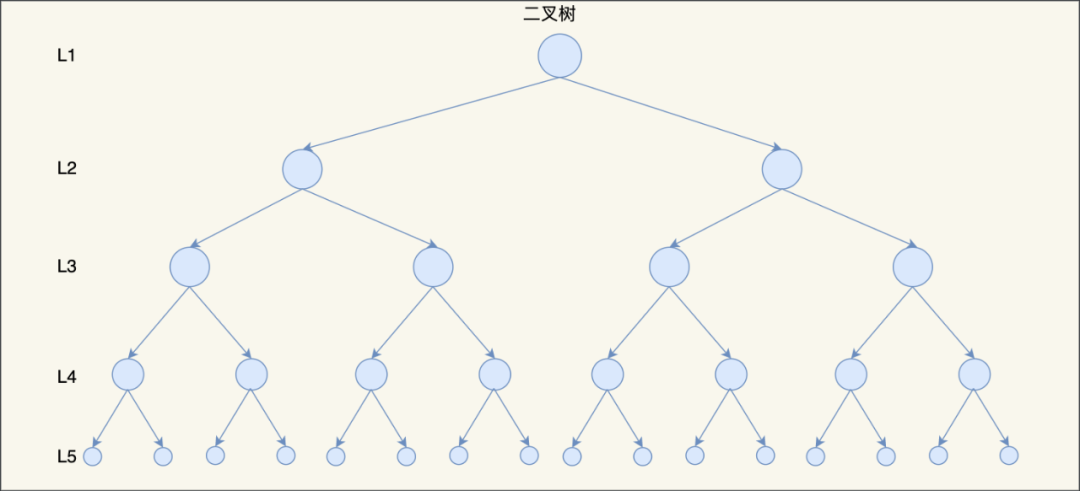
根本原因是因為它們都是二叉樹,也就是每個節點只能保存 2 個子節點 ,如果我們把二叉樹改成 M 叉樹(M>2)呢?
比如,當 M=3 時,在同樣的節點個數情況下,三叉樹比二叉樹的樹高要矮,
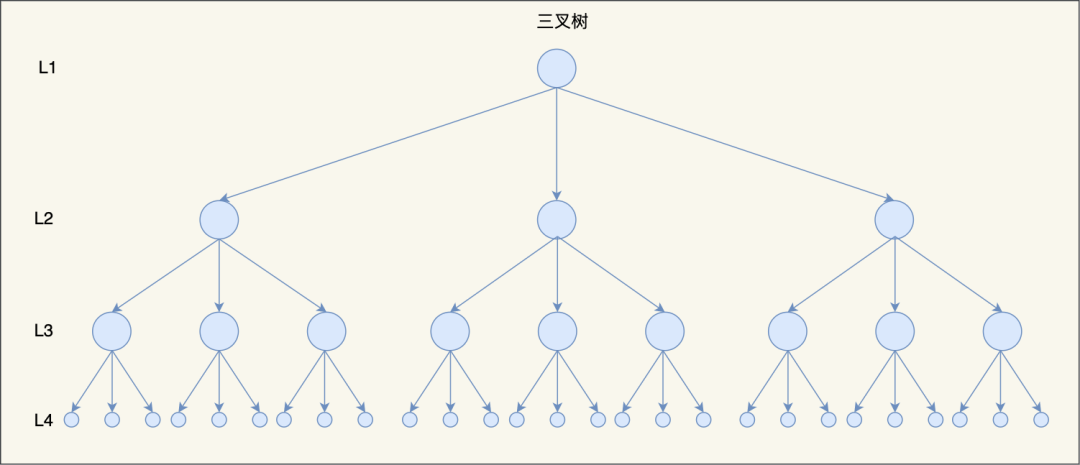
因此,當樹的節點越多的時候,并且樹的分叉數 M 越大的時候,M 叉樹的高度會遠小于二叉樹的高度,
什么是 B 樹
自平衡二叉樹雖然能保持查詢操作的時間復雜度在O(logn),但是因為它本質上是一個二叉樹,每個節點只能有 2 個子節點,那么當節點個數越多的時候,樹的高度也會相應變高,這樣就會增加磁盤的 I/O 次數,從而影響資料查詢的效率,
為了解決降低樹的高度的問題,后面就出來了 B 樹,它不再限制一個節點就只能有 2 個子節點,而是允許 M 個子節點 (M>2),從而降低樹的高度,
B 樹的每一個節點最多可以包括 M 個子節點,M 稱為 B 樹的階,所以 B 樹就是一個多叉樹,
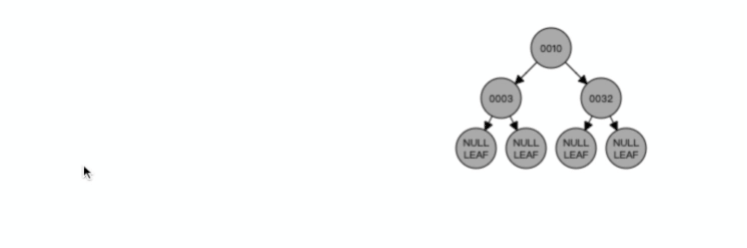
假設 M = 3,那么就是一棵 3 階的 B 樹,特點就是每個節點最多有 2 個(M-1個)資料和最多有 3 個(M個)子節點,超過這些要求的話,就會分裂節點,比如下面的的動圖:

我們來看看一棵 3 階的 B 樹的查詢程序是怎樣的?
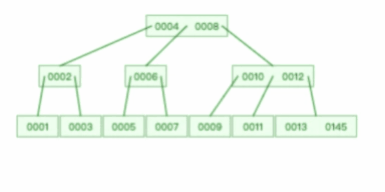
假設我們在上圖一棵 3 階的 B 樹中要查找的索引值是 9 的記錄那么步驟可以分為以下幾步:
-
與根節點的索引(4,8)進行比較,9 大于 8,那么往右邊的子節點走;
-
然后該子節點的索引為(10,12),因為 9 小于 10,所以會往該節點的左邊子節點走;
-
走到索引為9的節點,然后我們找到了索引值 9 的節點,
可以看到,一棵 3 階的 B 樹在查詢葉子節點中的資料時,由于樹的高度是 3 ,所以在查詢程序中會發生 3 次磁盤 I/O 操作,
而如果同樣的節點數量在平衡二叉樹的場景下,樹的高度就會很高,意味著磁盤 I/O 操作會更多,所以,B 樹在資料查詢中比平衡二叉樹效率要高,
但是 B 樹的每個節點都包含資料(索引+記錄),而用戶的記錄資料的大小很有可能遠遠超過了索引資料,這就需要花費更多的磁盤 I/O 操作次數來讀到「有用的索引資料」,
而且,在我們查詢位于底層的某個節點(比如 A 記錄)程序中,「非 A 記錄節點」里的記錄資料會從磁盤加載到記憶體,但是這些記錄資料是沒用的,我們只是想讀取這些節點的索引資料來做比較查詢,而「非 A 記錄節點」里的記錄資料對我們是沒用的,這樣不僅增多磁盤 I/O 操作次數,也占用記憶體資源,
另外,如果使用 B 樹來做范圍查詢的話,需要使用中序遍歷,這會涉及多個節點的磁盤 I/O 問題,從而導致整體速度下降,
什么是 B+ 樹?
B+ 樹就是對 B 樹做了一個升級,MySQL 中索引的資料結構就是采用了 B+ 樹,B+ 樹結構如下圖:
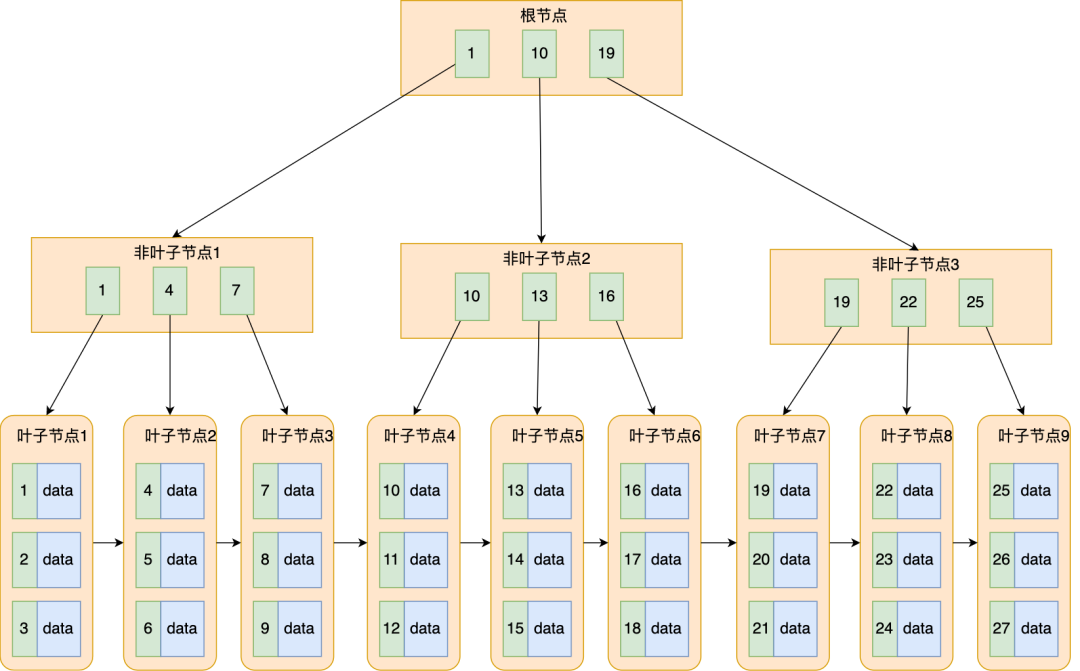
B+ 樹與 B 樹差異的點,主要是以下這幾點:
-
葉子節點(最底部的節點)才會存放實際資料(索引+記錄),非葉子節點只會存放索引;
-
所有索引都會在葉子節點出現,葉子節點之間構成一個有序鏈表;
-
非葉子節點的索引也會同時存在在子節點中,并且是在子節點中所有索引的最大(或最小),
-
非葉子節點中有多少個子節點,就有多少個索引;
下面通過三個方面,比較下 B+ 和 B 樹的性能區別,
1、單點查詢
B 樹進行單個索引查詢時,最快可以在 O(1) 的時間代價內就查到,而從平均時間代價來看,會比 B+ 樹稍快一些,
但是 B 樹的查詢波動會比較大,因為每個節點即存索引又存記錄,所以有時候訪問到了非葉子節點就可以找到索引,而有時需要訪問到葉子節點才能找到索引,
B+ 樹的非葉子節點不存放實際的記錄資料,僅存放索引,因此資料量相同的情況下,相比存盤即存索引又存記錄的 B 樹,B+樹的非葉子節點可以存放更多的索引,因此 B+ 樹可以比 B 樹更「矮胖」,查詢底層節點的磁盤 I/O次數會更少,
2、插入和洗掉效率
B+ 樹有大量的冗余節點,這樣使得洗掉一個節點的時候,可以直接從葉子節點中洗掉,甚至可以不動非葉子節點,這樣洗掉非常快,
比如下面這個動圖是洗掉 B+ 樹某個葉子節點節點的程序:
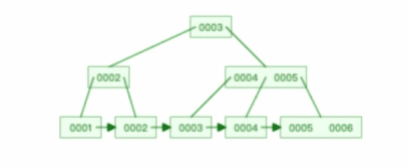
注意,:B+ 樹對于非葉子節點的子節點和索引的個數,定義方式可能會有不同,有的是說非葉子節點的子節點的個數為 M 階,而索引的個數為 M-1(這個是維基百科里的定義),因此我本文關于 B+ 樹的動圖都是基于這個,但是我在前面介紹 B+ 樹與 B+ 樹的差異時,說的是「非葉子節點中有多少個子節點,就有多少個索引」,主要是 MySQL 用到的 B+ 樹就是這個特性,
甚至,B+ 樹在洗掉根節點的時候,由于存在冗余的節點,所以不會發生復雜的樹的變形,比如下面這個動圖是洗掉 B+ 樹根節點的程序:
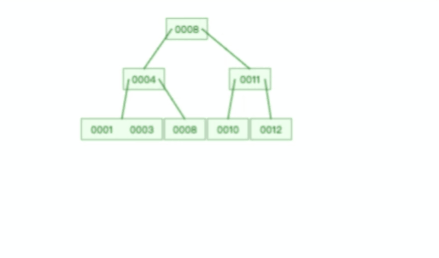
B 樹則不同,B 樹沒有冗余節點,洗掉節點的時候非常復雜,比如洗掉根節點中的資料,可能涉及復雜的樹的變形,比如下面這個動圖是洗掉 B 樹根節點的程序:
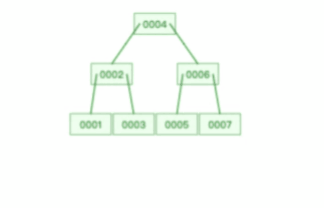
B+ 樹的插入也是一樣,有冗余節點,插入可能存在節點的分裂(如果節點飽和),但是最多只涉及樹的一條路徑,而且 B+ 樹會自動平衡,不需要像更多復雜的演算法,類似紅黑樹的旋轉操作等,
因此,B+ 樹的插入和洗掉效率更高,
3、范圍查詢
B 樹和 B+ 樹等值查詢原理基本一致,先從根節點查找,然后對比目標資料的范圍,最后遞回的進入子節點查找,
因為 B+ 樹所有葉子節點間還有一個鏈表進行連接,這種設計對范圍查找非常有幫助,比如說我們想知道 12 月 1 日和 12 月 12 日之間的訂單,這個時候可以先查找到 12 月 1 日所在的葉子節點,然后利用鏈表向右遍歷,直到找到 12 月12 日的節點,這樣就不需要從根節點查詢了,進一步節省查詢需要的時間,
而 B 樹沒有將所有葉子節點用鏈表串聯起來的結構,因此只能通過樹的遍歷來完成范圍查詢,這會涉及多個節點的磁盤 I/O 操作,范圍查詢效率不如 B+ 樹,
因此,存在大量范圍檢索的場景,適合使用 B+樹,比如資料庫,而對于大量的單個索引查詢的場景,可以考慮 B 樹,比如 nosql 的MongoDB,
MySQL 中的 B+ 樹
MySQL 的存盤方式根據存盤引擎的不同而不同,我們最常用的就是 Innodb 存盤引擎,它就是采用了 B+ 樹作為了索引的資料結構,
下圖就是 Innodb 里的 B+ 樹:
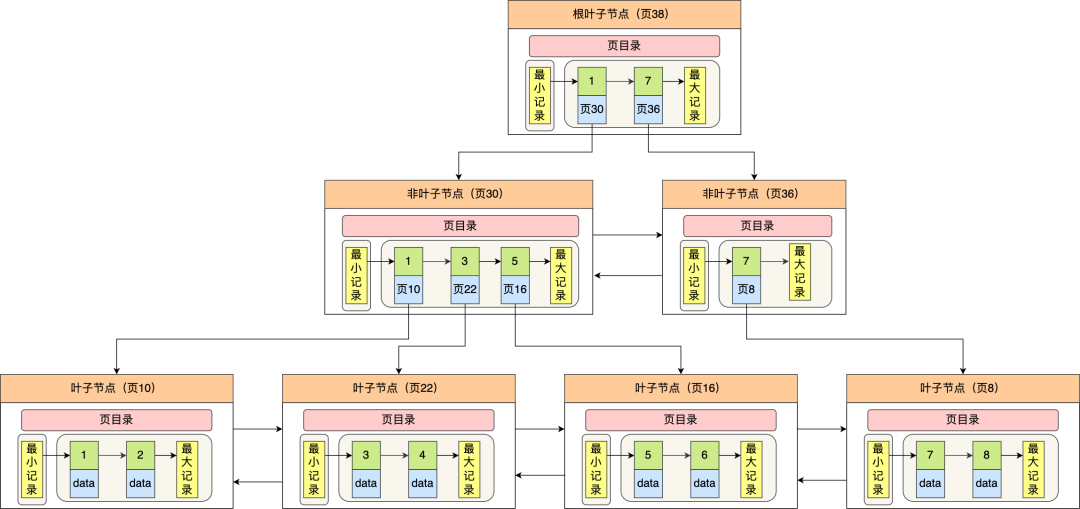
但是 Innodb 使用的 B+ 樹有一些特別的點,比如:
-
B+ 樹的葉子節點之間是用「雙向鏈表」進行連接,這樣的好處是既能向右遍歷,也能向左遍歷,
-
B+ 樹點節點內容是資料頁,資料頁里存放了用戶的記錄以及各種資訊,每個資料頁默認大小是 16 KB,
Innodb 根據索引型別不同,分為聚集和二級索引,他們區別在于,聚集索引的葉子節點存放的是實際資料,所有完整的用戶記錄都存放在聚集索引的葉子節點,而二級索引的葉子節點存放的是主鍵值,而不是實際資料,
因為表的資料都是存放在聚集索引的葉子節點里,所以 InnoDB 存盤引擎一定會為表創建一個聚集索引,且由于資料在物理上只會保存一份,所以聚簇索引只能有一個,而二級索引可以創建多個,
總結
MySQL 是會將資料持久化在硬碟,而存盤功能是由 MySQL 存盤引擎實作的,所以討論 MySQL 使用哪種資料結構作為索引,實際上是在討論存盤引使用哪種資料結構作為索引,InnoDB 是 MySQL 默認的存盤引擎,它就是采用了 B+ 樹作為索引的資料結構,
要設計一個 MySQL 的索引資料結構,不僅僅考慮資料結構增刪改的時間復雜度,更重要的是要考慮磁盤 I/0 的操作次數,因為索引和記錄都是存放在硬碟,硬碟是一個非常慢的存盤設備,我們在查詢資料的時候,最好能在盡可能少的磁盤 I/0 的操作次數內完成,
二分查找樹雖然是一個天然的二分結構,能很好的利用二分查找快速定位資料,但是它存在一種極端的情況,每當插入的元素都是樹內最大的元素,就會導致二分查找樹退化成一個鏈表,此時查詢復雜度就會從 O(logn)降低為 O(n),
為了解決二分查找樹退化成鏈表的問題,就出現了自平衡二叉樹,保證了查詢操作的時間復雜度就會一直維持在 O(logn) ,但是它本質上還是一個二叉樹,每個節點只能有 2 個子節點,隨著元素的增多,樹的高度會越來越高,
而樹的高度決定于磁盤 I/O 操作的次數,因為樹是存盤在磁盤中的,訪問每個節點,都對應一次磁盤 I/O 操作,也就是說樹的高度就等于每次查詢資料時磁盤 IO 操作的次數,所以樹的高度越高,就會影響查詢性能,
B 樹和 B+ 都是通過多叉樹的方式,會將樹的高度變矮,所以這兩個資料結構非常適合檢索存于磁盤中的資料,
但是 MySQL 默認的存盤引擎 InnoDB 采用的是 B+ 作為索引的資料結構,原因有:
-
B+ 樹的非葉子節點不存放實際的記錄資料,僅存放索引,因此資料量相同的情況下,相比存盤即存索引又存記錄的 B 樹,B+樹的非葉子節點可以存放更多的索引,因此 B+ 樹可以比 B 樹更「矮胖」,查詢底層節點的磁盤 I/O次數會更少,
-
B+ 樹有大量的冗余節點(所有非葉子節點都是冗余索引),這些冗余索引讓 B+ 樹在插入、洗掉的效率都更高,比如洗掉根節點的時候,不會像 B 樹那樣會發生復雜的樹的變化;
-
B+ 樹葉子節點之間用鏈表連接了起來,有利于范圍查詢,而 B 樹要實作范圍查詢,因此只能通過樹的遍歷來完成范圍查詢,這會涉及多個節點的磁盤 I/O 操作,范圍查詢效率不如 B+ 樹,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385517.html
標籤:其他