Elasticsearch基本操作
文章目錄
- Elasticsearch基本操作
- 一、概述
- 1.1 正排索引和倒排索引
- 二、安裝程式
- 三、HTTP操作
- 3.1 索引操作
- 3.1.1 創建索引
- 3.1.2 查看索引
- 3.1.3 洗掉索引
- 3.2 檔案操作
- 3.2.1 創建檔案
- 3.2.2 查看檔案
- 3.2.3 修改檔案
- 3.2.4 洗掉檔案
- 3.3 多種查詢方式
- 3.3.1 條件查詢
- 3.3.2 全量查詢
- 3.3.3 分頁查詢
- 3.3.4 多條件查詢
- 3.3.5 范圍查詢
- 3.3.6 全文檢索
- 3.3.7 完全匹配
- 3.3.8 聚合查詢
- 3.3.9 映射關系
一、概述
Elasticsearch,簡稱為ES, 是一個開源的、高擴展的、RESTful 風格的分布式全文搜索引擎,它可以近乎實時的存盤、檢索資料;本身擴展性很好,可以擴展到上百臺服務器,處理PB級別的資料,
這里說到的全文搜索引擎指的是目前廣泛應用的主流搜索引擎,它的作業原理是計算機索引程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程式就根據事先建立的索引進行查找,并將查找的結果反饋給用戶的檢索方式,這個程序類似于通過字典中的檢索字表查字的程序,
Elasticsearch 是面向檔案型資料庫,一條資料就是一個檔案,Elasticsearch 中存盤的檔案資料和 MySQL 存盤資料的對比:
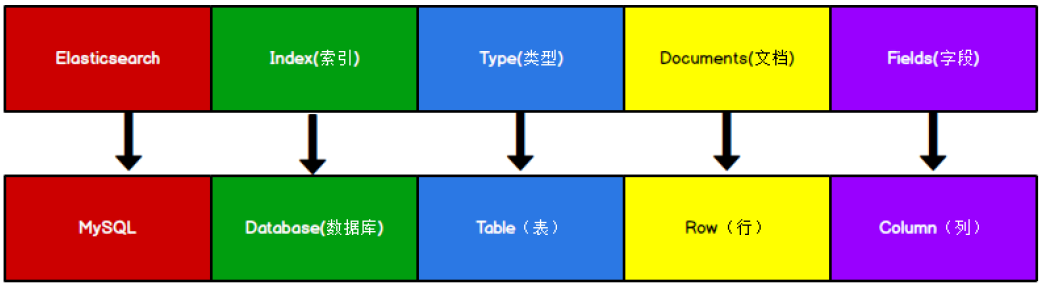
注:Elasticsearch 中 Type 的概念已經被洗掉了,
1.1 正排索引和倒排索引
正排索引:
MySQL中采用的是正排索引,比如根據主鍵索引查詢某一記錄中對應欄位的值,但是如果模糊查詢(查詢某一個欄位中某一部分),根據索引只能定位到完整的欄位值,所以這種索引就可能會失效,
倒排索引:
ES采用的是倒排索引,對文章進行分詞拆解操作,對每一個詞都建立索引,根據某一個具體的詞就可以查詢到對應的索引值,根據這個索引值就可以查詢到整個文章內容,這就是倒排索引,
二、安裝程式
-
下載地址:Past Releases of Elastic Stack Software | Elastic(本文使用7.8.0版本的Win格式)
-
對壓縮包進行解壓,得到如下目錄結構:
-
解壓后,進入 bin 目錄,點擊 elasticsearch.bat 檔案啟動 ES 服務:
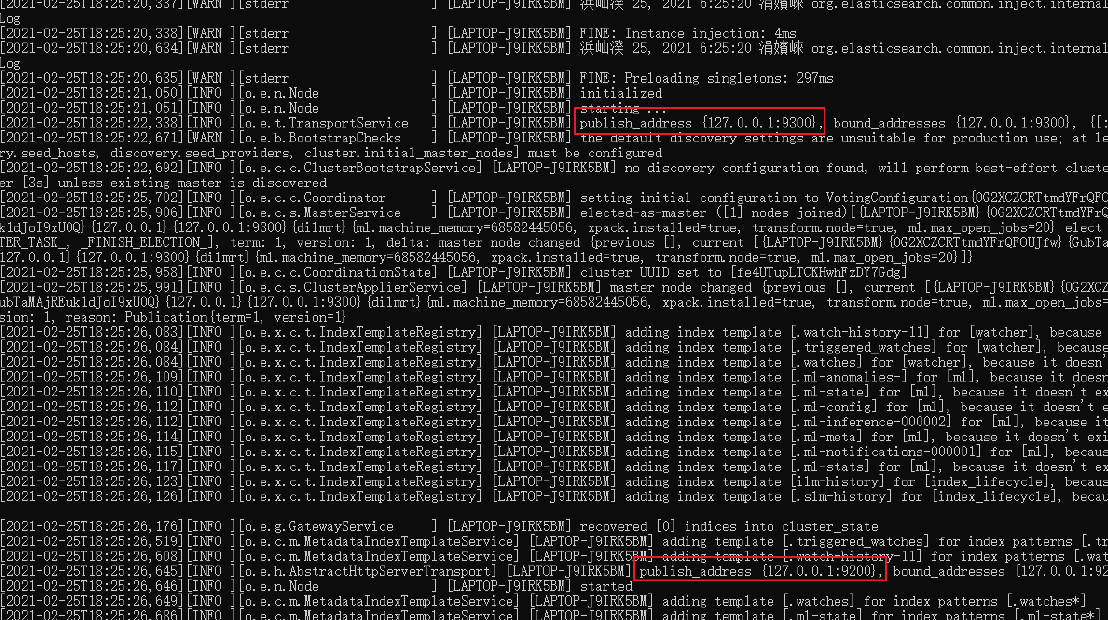
注意: 9300 埠為 Elasticsearch 集群間組件的通信埠, 9200 埠為瀏覽器訪問的 HTTP 協議 RESTful 埠,
-
打開瀏覽器,輸入網址:http://localhost:9200/,出現如下界面表示啟動成功:

-
為了能夠方便的使用 RESTful 風格的請求,所以安裝 Postman 軟體,下載地址:https://www.getpostman.com/apps
三、HTTP操作
3.1 索引操作
3.1.1 創建索引
對比關系型資料庫,創建索引就相當于創建資料庫,
創建索引的 PUT 請求:http://127.0.0.1:9200/索引名稱:
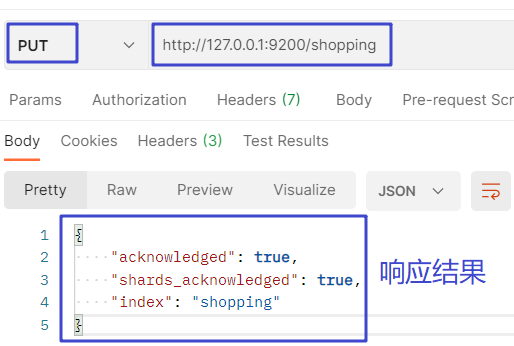
# 回應結果,true表示成功
"acknowledged": true,
# 分片操作成功
"shards_acknowledged": true,
# 創建的索引名稱
"index": "shopping"
如果重復添加相同索引,會回傳錯誤資訊:
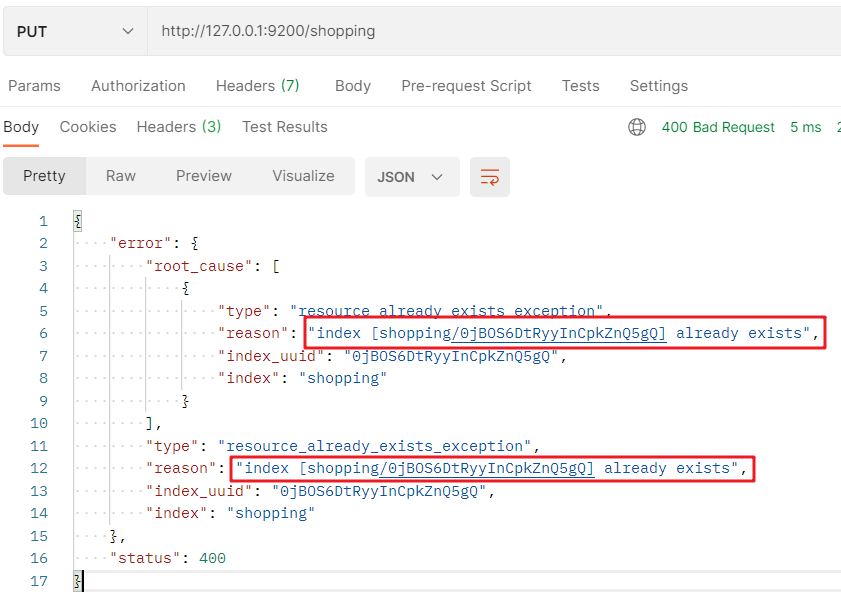
3.1.2 查看索引
查看所有索引:
查看所有索引的 GET 請求:http://127.0.0.1:9200/_cat/indices?v:
- _cat:表示查看的意思
- indices:表示所有索引
- ?v:表示結果使用表格的形式展示
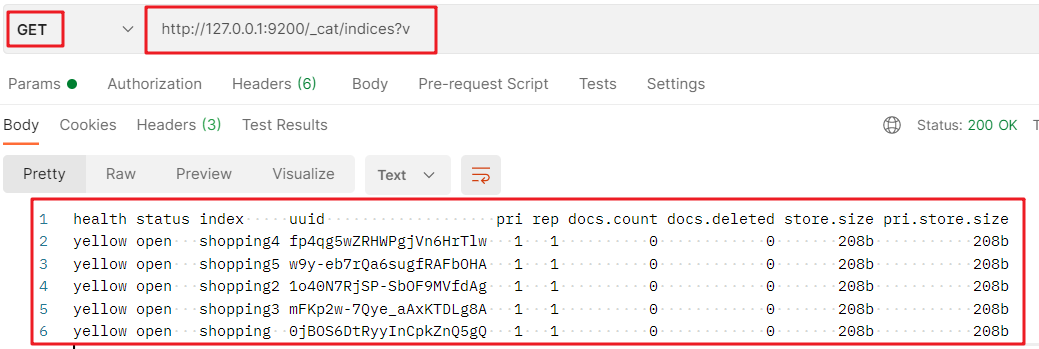
回應結果詳細內容如下:
查看單個索引:
查看單個索引的 GET 請求:http://127.0.0.1:9200/索引名:
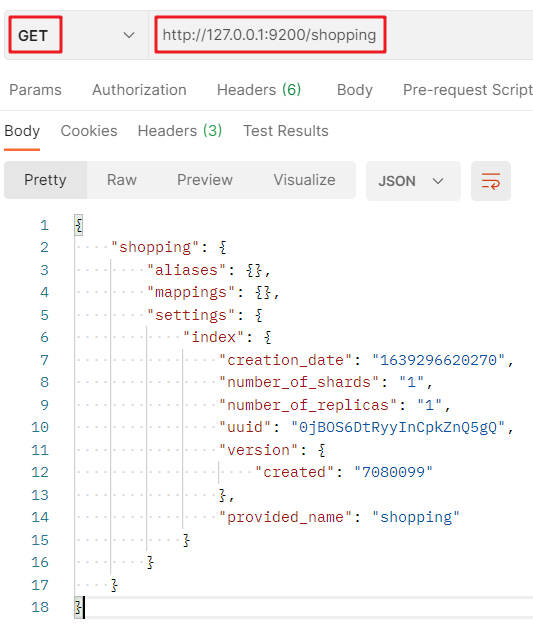
對回應結果的決議:
# 索引名
shopping
# 別名
aliases
# 映射
mappings
# 設定
settings
# 設定-索引
settings-index
# 設定-索引-創建時間
settings-index-creation_date
# 設定-索引-主分片數量
settings-index-number_of_shards
# 設定-索引-副分片數量
settings-index-number_of_replicas
# 設定-索引-唯一標識
settings-index-uuid
# 設定-索引-版本
settings-index-version
# 設定-索引-名稱
settings-index-provided_name
3.1.3 洗掉索引
洗掉索引的 DELETE 請求:http://127.0.0.1:9200/索引名:
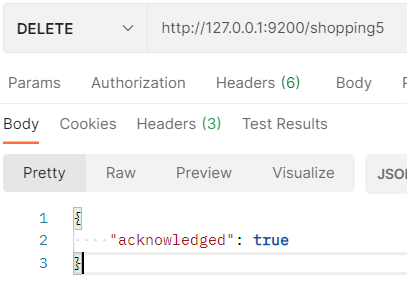
再次訪問索引,回應索引不存在:
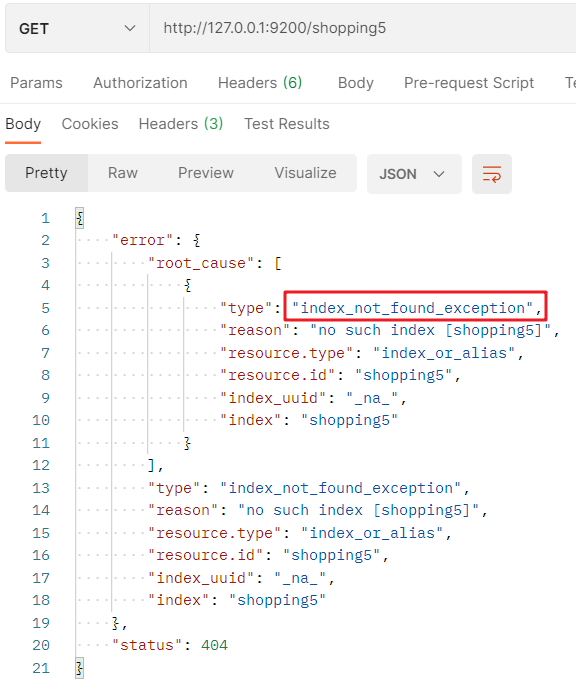
3.2 檔案操作
3.2.1 創建檔案
隨機生成id值:
創建檔案就相當于創建表的記錄,這條記錄的格式為 JSON 格式,
創建檔案的 POST 請求為:http://127.0.0.1:9200/索引名/_doc + JSON格式請求體:
- _doc:表示檔案:
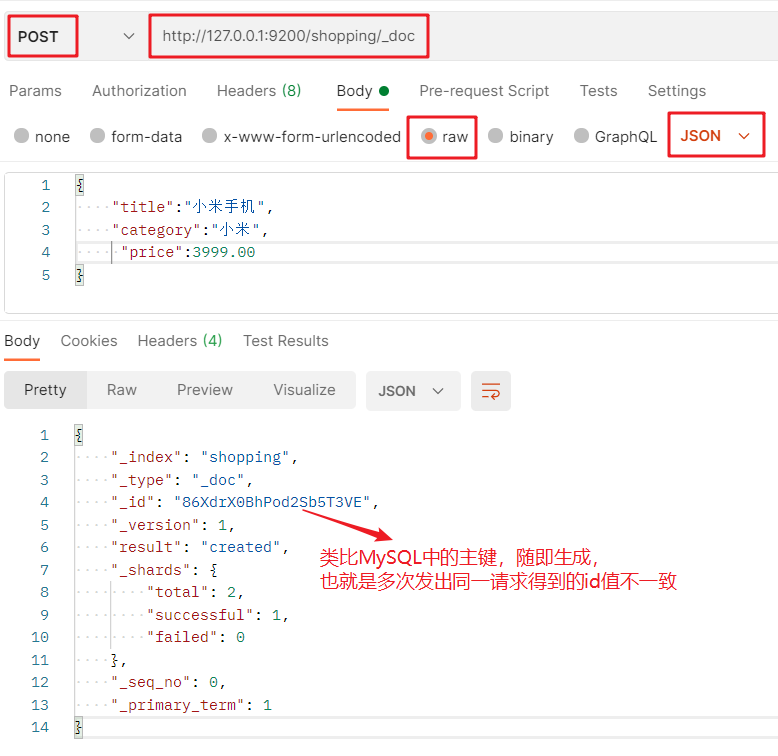
注:由于 PUT 操作是冪等的,多次發出相同的請求,后一個會把前一個覆寫掉,而創建檔案回傳的 _id 值是不同的,所以需要使用 POST 來創建,而 PUT 一般用來改資源,
生成固定id值:
創建檔案的 POST 請求為:http://127.0.0.1:9200/索引名/_doc/id值 + JSON格式請求體:
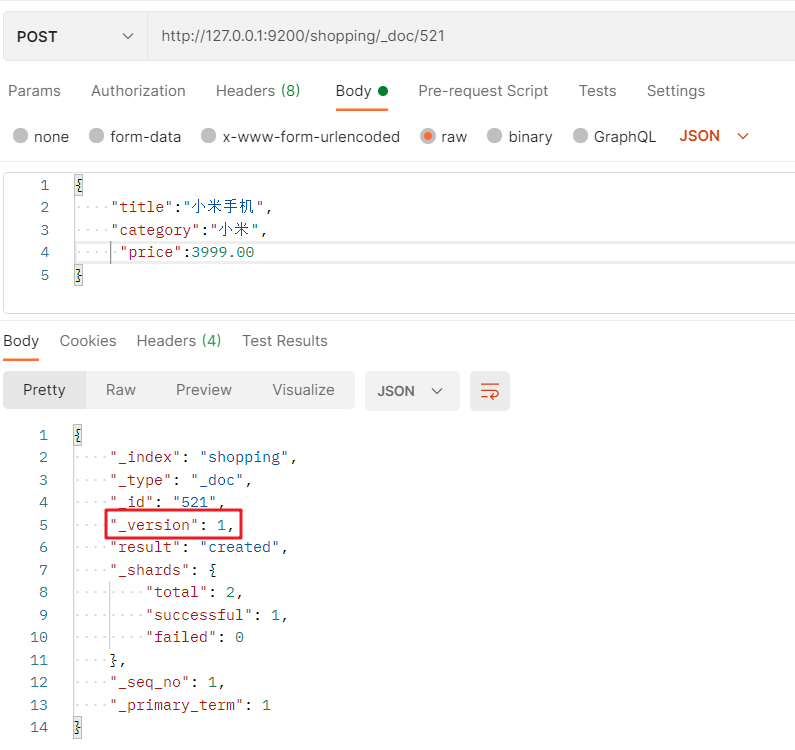
注:如果創建檔案時明確資料主鍵(id)值,那么請求方式也可以使用PUT,
3.2.2 查看檔案
查看檔案時,需要指明檔案的唯一標識,類似于 MySQL 的主鍵查詢,
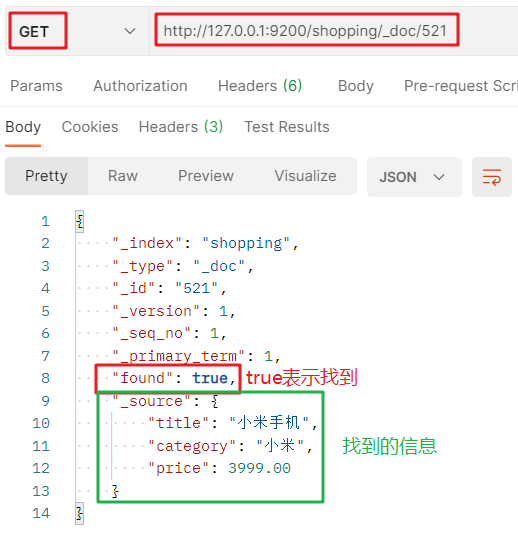
查詢檔案的 GET 請求:http://127.0.0.1:9200/索引名/_doc/檔案主鍵值:
3.2.3 修改檔案
修改整個檔案
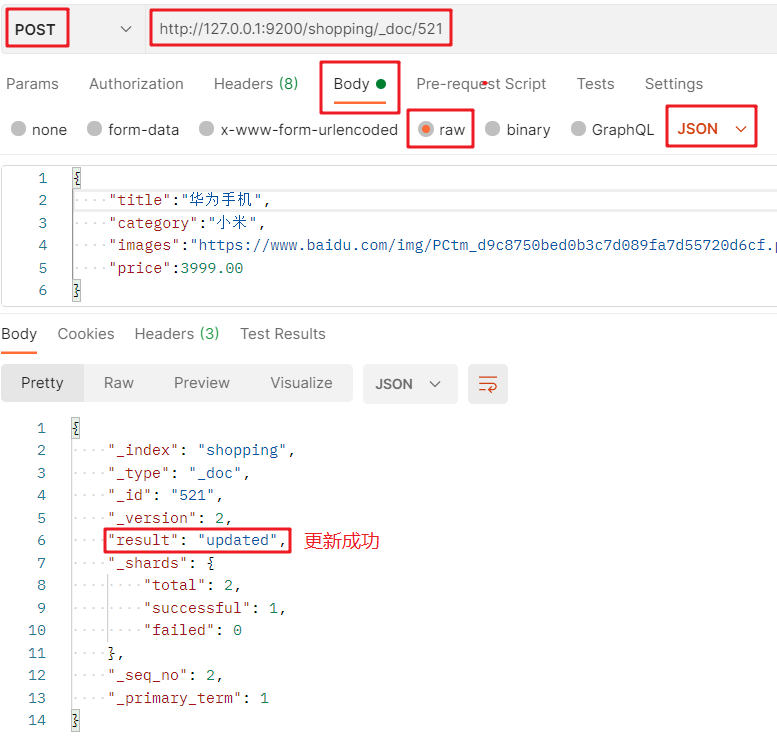
修改整個檔案的 POST 請求:http://127.0.0.1:9200/索引名/_doc/檔案主鍵值 + JSON請求體:
修改檔案部分欄位
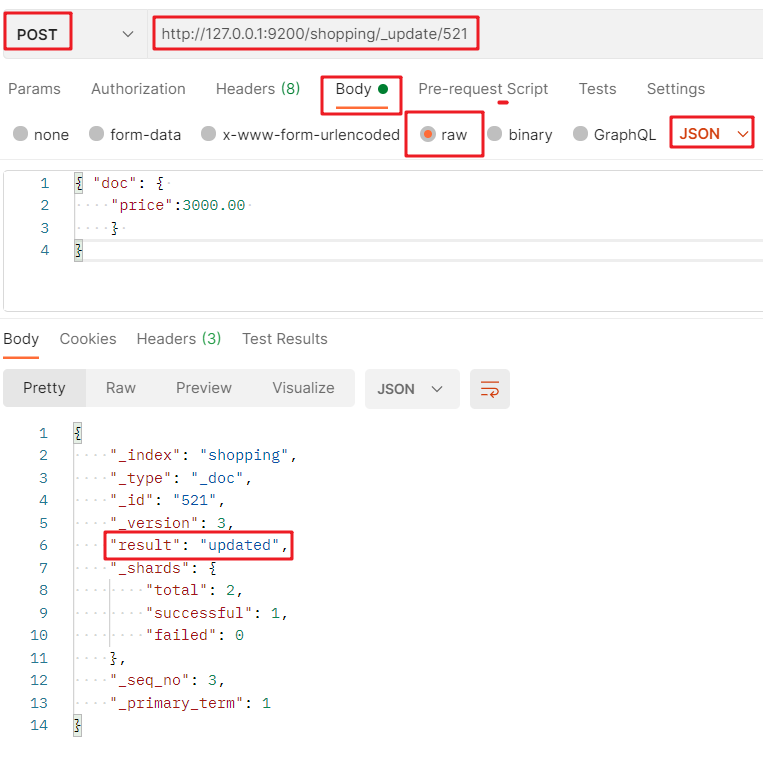
修改檔案部分欄位的 POST 請求:http://127.0.0.1:9200/索引值/_update/檔案主鍵值 + JSON格式請求體:
3.2.4 洗掉檔案
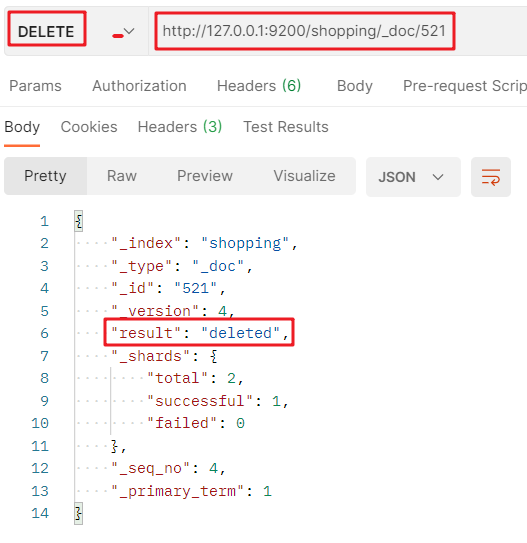
洗掉一個檔案并不會立即從磁盤中洗掉,他只是被標記為已洗掉(邏輯洗掉),
洗掉檔案的 DELETE 請求:http://127.0.0.1:9200/索引值/_doc/檔案主鍵值:
3.3 多種查詢方式
3.3.1 條件查詢
將結果全部查詢出來之后進行過濾,僅顯示符合指定欄位值的檔案,
方式一:
發送 GET 請求:http://127.0.0.1:9200/索引值/_search?q=欄位名:欄位值
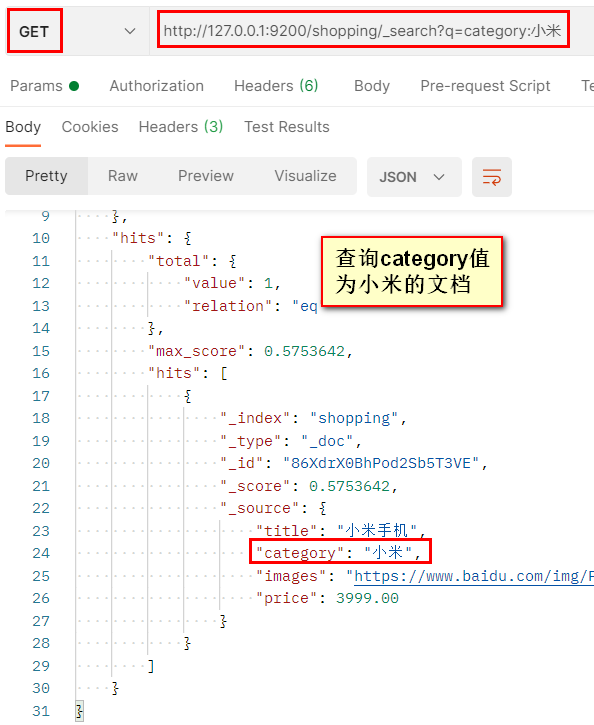
方式二:
發送 GET 請求:http://127.0.0.1:9200/索引值/_search + JSON格式請求體
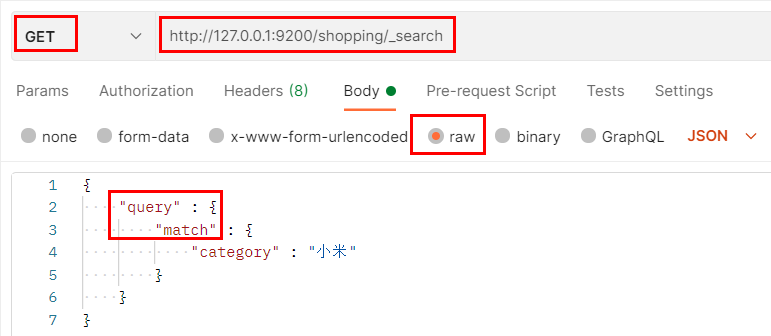
3.3.2 全量查詢
查詢某一索引下的全部檔案,
方式一:
發送 GET 請求:http://127.0.0.1:9200/索引名/_search
方式二:
發送 GET 請求:http://127.0.0.1:9200/索引名/_search + JSON格式請求體
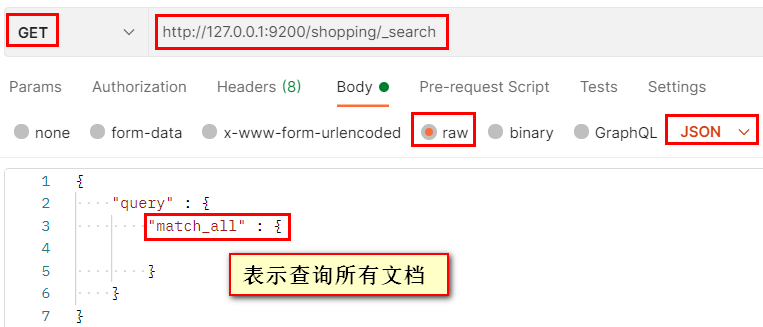
3.3.3 分頁查詢
對查詢結果進行分頁操作,
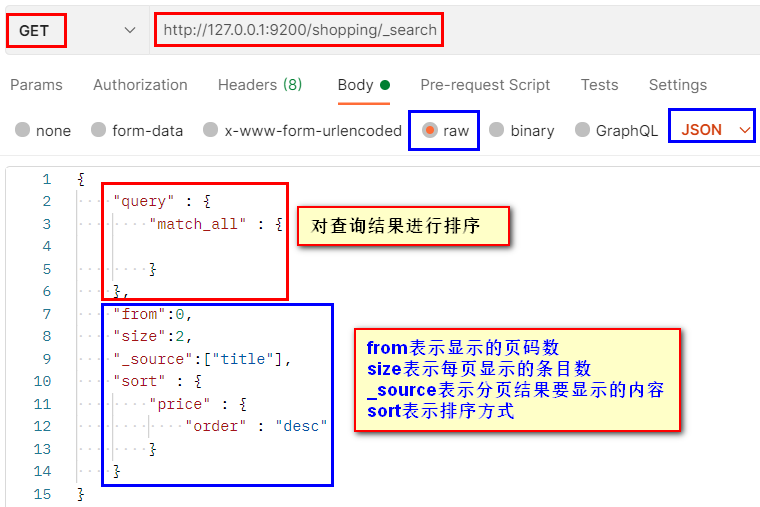
分頁結果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "86XdrX0BhPod2Sb5T3VE",
"_score": null,
"_source": {
// 僅指定的title欄位被顯示出來
"title": "小米手機"
},
"sort": [
3999.0
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "XndgzH0BZ5WKFcQMlsuM",
"_score": null,
"_source": {
"title": "華為手機"
},
"sort": [
2503.36
]
}
]
}
}
3.3.4 多條件查詢
情況1:且條件
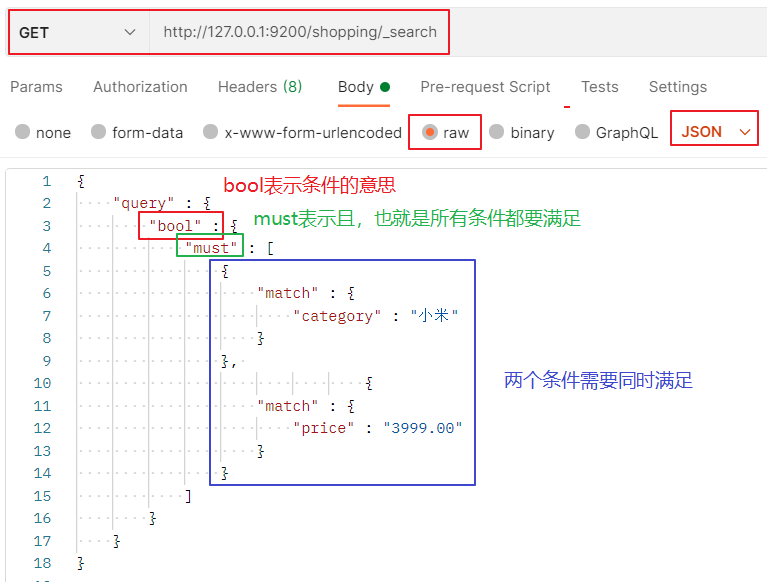
情況2:或條件
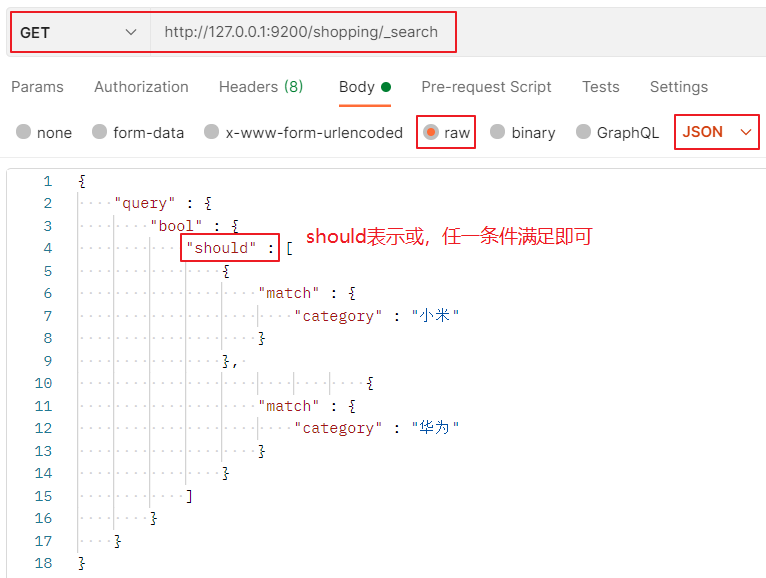
3.3.5 范圍查詢
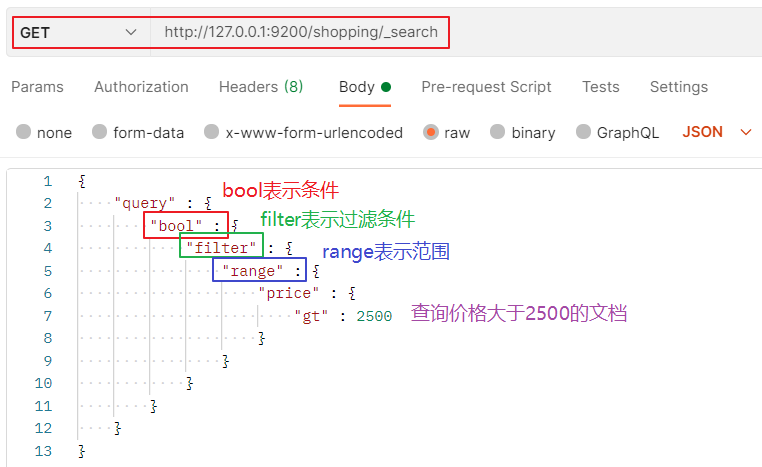
注意:
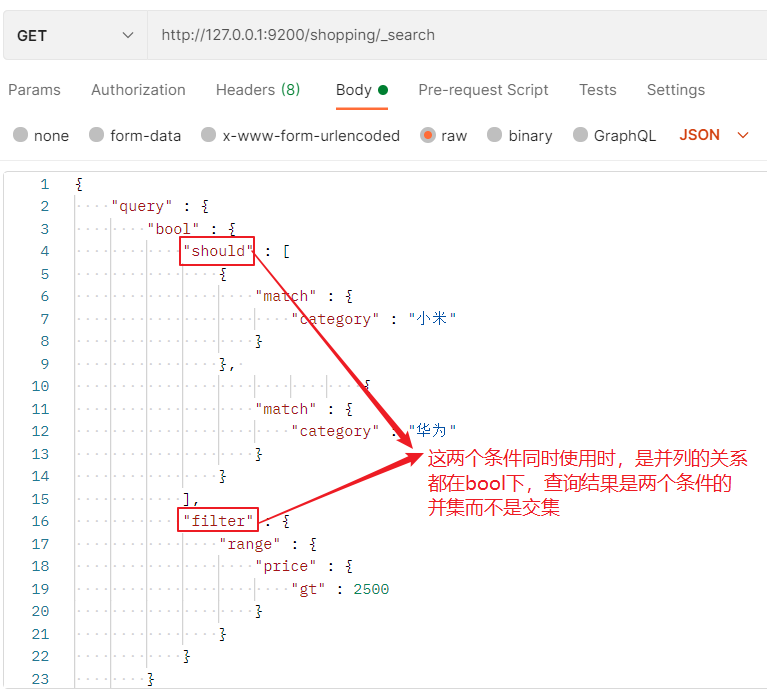
3.3.6 全文檢索
情況一:
有時在查詢時,并沒有輸入欄位完整的值,也可以將結果查詢出來,比如:
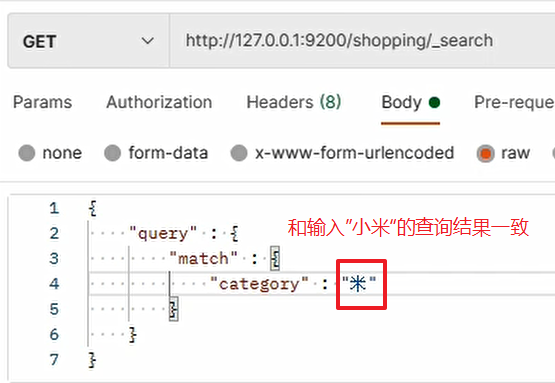
出現的原因:保存檔案時,ES 會將資料文字進行分詞拆解操作,并將拆解結果保存在倒排索引中,這樣,即使使用文字的一部分也能將對應的結果查詢出來,
情況二:
輸入兩個檔案中不同的欄位值組合結構,本身這個值不存在任何檔案的欄位中,但會將兩篇檔案全部查詢出,如下:
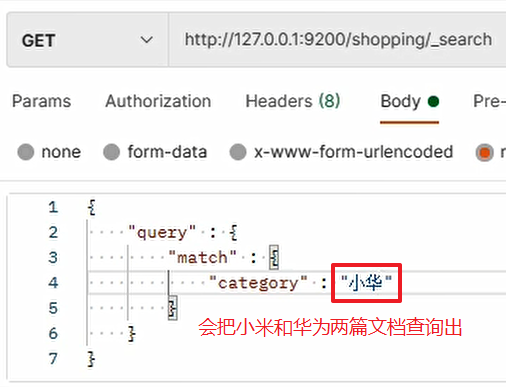
出現的原因:ES 會將查詢條件也進行分詞拆解操作,分成了 “小” 和 “華” 兩部分,兩個字分別對應情況1(進行倒排索引的匹配),所以會將兩篇檔案全部查詢出,
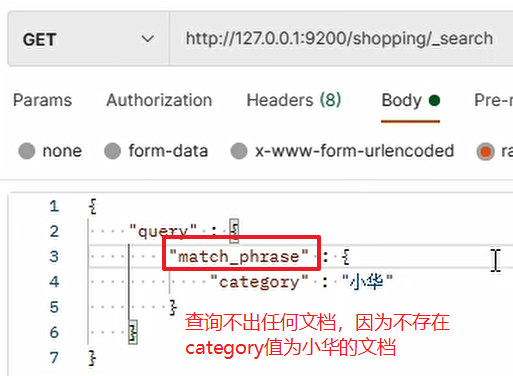
3.3.7 完全匹配
如果不想出現全文檢索部分匹配的情況,而想要完全的匹配查詢值,需要使用關鍵字 match_phrase:
3.3.8 聚合查詢
可以對查詢結果進行分組、求平均值、最大值等操作,
分組操作示例:
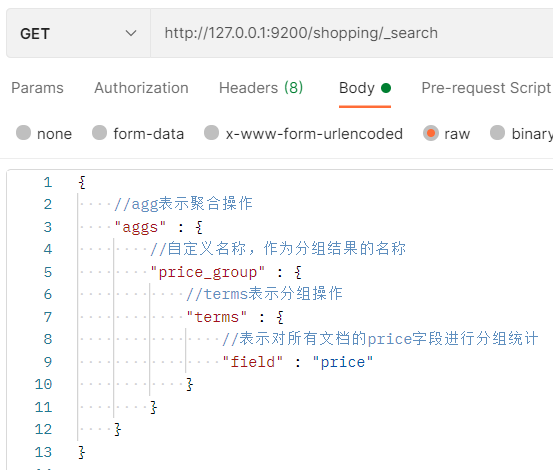
查詢結果:
"aggregations": {
//自定義分組結果名稱
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
//表示價格為2503.3的檔案個數為2個
{
"key": 2503.3,
"doc_count": 2
},
//表示價格為3999.0的檔案個數為1個
{
"key": 3999.0,
"doc_count": 1
}
]
}
}
求平均值操作示例:
請求體:
{
//agg表示聚合操作
"aggs" : {
//自定義名稱,作為結果的名稱
"price_avg" : {
//avg表示求平均值操作
"avg" : {
//表示對所有檔案的price欄位求平均值
"field" : "price"
}
}
},
//僅顯示平均值結果,而不顯示所有的檔案具體內容
"size" : 0
}
查詢結果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
//不顯示具體的檔案內容,如果不使用size=0,則這里會顯示所有的檔案具體內容
"hits": []
},
"aggregations": {
//自定義名稱
"price_avg": {
//平均值結果
"value": 3001.90673828125
}
}
}
3.3.9 映射關系
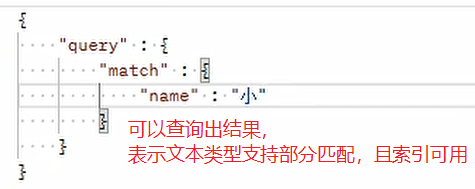
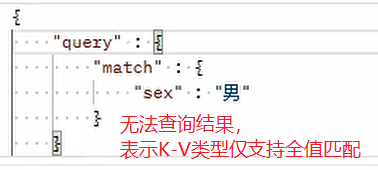
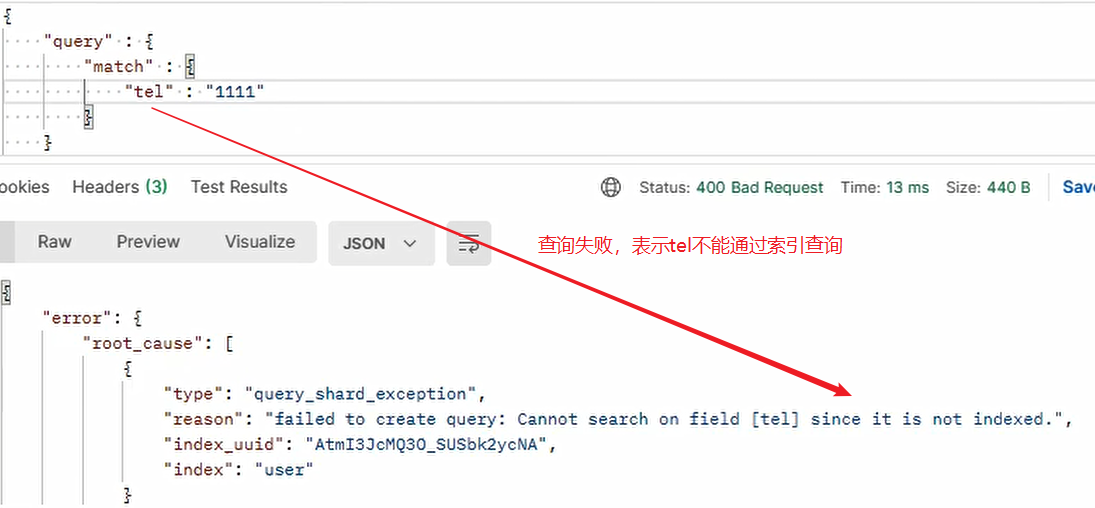
文本型別可以進行全文檢索部分匹配,而 K-V 型別只能進行完全匹配,
1. 創建user索引
http://127.0.0.1:9200/user
2. 定義欄位的映射型別
發送的請求:

攜帶的請求體:
{
//設定映射關系
"properties" : {
//name欄位的型別是文本,而且此欄位可以使用索引
"name" : {
"type" : "text",
"index" : true
},
//sex欄位的型別是K-V,而且此欄位可以使用索引
"sex" : {
"type" : "keyword",
"index" : true
},
//sex欄位的型別是K-V,而且此欄位不能使用索引
"tel" : {
"type" : "keyword",
"index" : false
}
}
}
3. 創建檔案
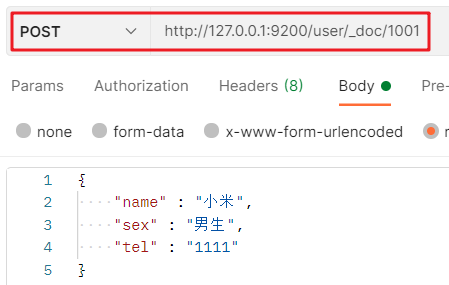
4. 查詢欄位值
情況一:
情況二:
情況三:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385532.html
標籤:其他