文章目錄
- 前言
- 原始碼分析
- 1. Kafka 服務端的啟動流程
- 2. Kafka 服務端新建連接的處理
- 3. Kafka 服務端請求處理流程
前言
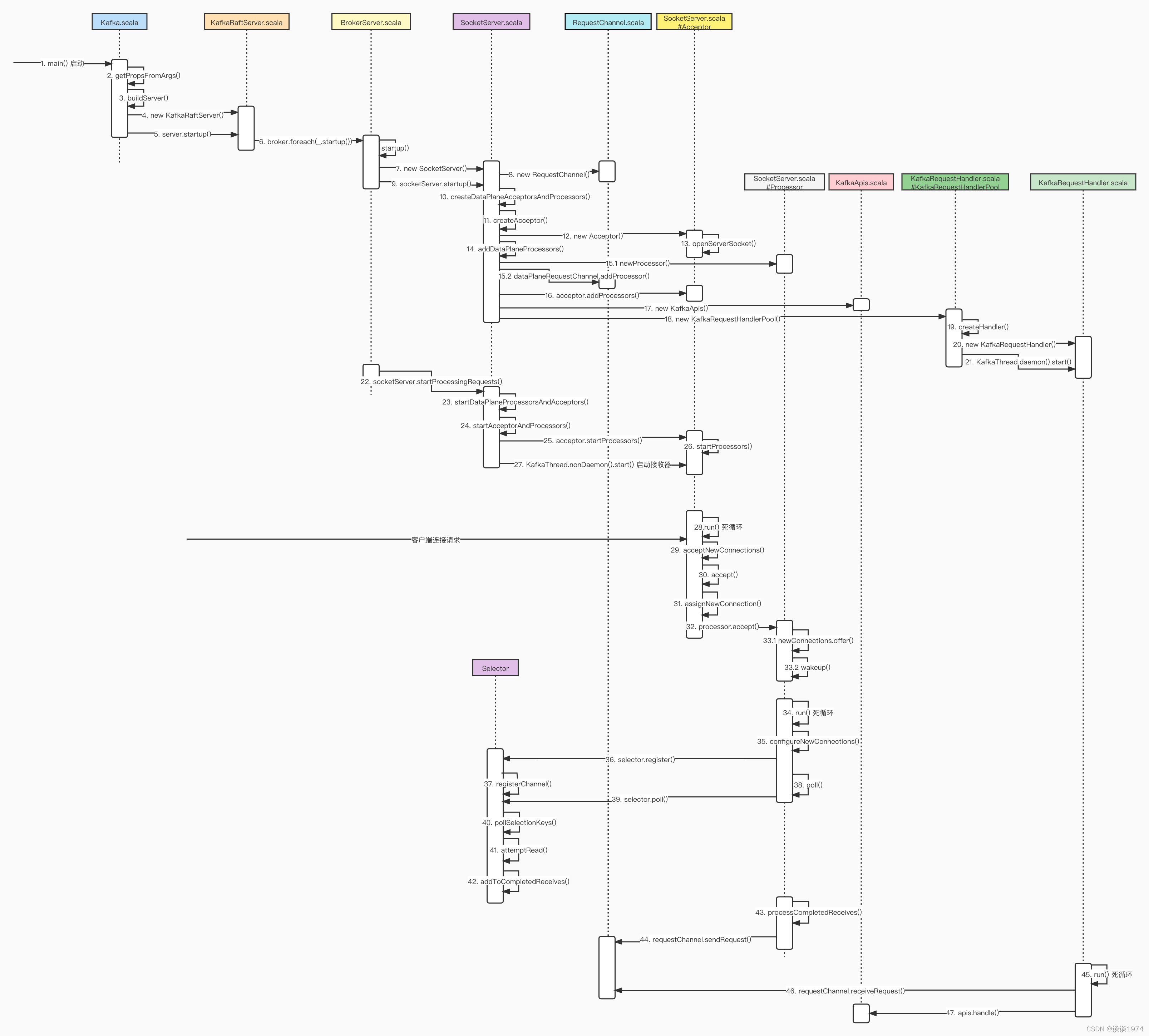
在 Kafka 3.0 原始碼筆記(1)-Kafka 服務端的網路通信架構 中筆者介紹了 Kafka 3.0 版本的組件構成,其實由此也可以將本文內容分為三個部分,主要時序如下圖所示:
- Kafka 服務端的啟動流程
- Kafka 服務端新建連接的處理
- Kafka 服務端請求處理流程
原始碼分析
1. Kafka 服務端的啟動流程
-
Kafka 服務端的啟動由
Kafka.scala#main()方法為入口,可以看到主要步驟如下:- 呼叫
Kafka.scala#getPropsFromArgs()方法將啟動引數中指定的組態檔加載到記憶體中 - 呼叫
Kafka.scala#buildServer()方法創建 kafka 的服務端實體物件 - 呼叫創建的服務端實體物件的介面方法
Server.scala#startup()方法啟動服務端
def main(args: Array[String]): Unit = { try { val serverProps = getPropsFromArgs(args) val server = buildServer(serverProps) try { if (!OperatingSystem.IS_WINDOWS && !Java.isIbmJdk) new LoggingSignalHandler().register() } catch { case e: ReflectiveOperationException => warn("Failed to register optional signal handler that logs a message when the process is terminated " + s"by a signal. Reason for registration failure is: $e", e) } // attach shutdown handler to catch terminating signals as well as normal termination Exit.addShutdownHook("kafka-shutdown-hook", { try server.shutdown() catch { case _: Throwable => fatal("Halting Kafka.") // Calling exit() can lead to deadlock as exit() can be called multiple times. Force exit. Exit.halt(1) } }) try server.startup() catch { case _: Throwable => // KafkaServer.startup() calls shutdown() in case of exceptions, so we invoke `exit` to set the status code fatal("Exiting Kafka.") Exit.exit(1) } server.awaitShutdown() } catch { case e: Throwable => fatal("Exiting Kafka due to fatal exception", e) Exit.exit(1) } Exit.exit(0) } - 呼叫
-
Kafka.scala#getPropsFromArgs()方法的核心是呼叫Utils#loadProps()加載指定的組態檔,這部分邏輯比較簡單,不做深入def getPropsFromArgs(args: Array[String]): Properties = { val optionParser = new OptionParser(false) val overrideOpt = optionParser.accepts("override", "Optional property that should override values set in server.properties file") .withRequiredArg() .ofType(classOf[String]) // This is just to make the parameter show up in the help output, we are not actually using this due the // fact that this class ignores the first parameter which is interpreted as positional and mandatory // but would not be mandatory if --version is specified // This is a bit of an ugly crutch till we get a chance to rework the entire command line parsing optionParser.accepts("version", "Print version information and exit.") if (args.length == 0 || args.contains("--help")) { CommandLineUtils.printUsageAndDie(optionParser, "USAGE: java [options] %s server.properties [--override property=value]*".format(this.getClass.getCanonicalName.split('$').head)) } if (args.contains("--version")) { CommandLineUtils.printVersionAndDie() } val props = Utils.loadProps(args(0)) if (args.length > 1) { val options = optionParser.parse(args.slice(1, args.length): _*) if (options.nonOptionArguments().size() > 0) { CommandLineUtils.printUsageAndDie(optionParser, "Found non argument parameters: " + options.nonOptionArguments().toArray.mkString(",")) } props ++= CommandLineUtils.parseKeyValueArgs(options.valuesOf(overrideOpt).asScala) } props } -
Kafka.scala#buildServer()方法創建服務端實體物件是非常關鍵的一步,需要注意的點如下:- 通過
KafkaConfig.scala#fromProps()方法將加載到記憶體中的配置轉化構建為KafkaConfig物件 - 呼叫
KafkaConfig.scala#requiresZookeeper()方法確定 Kafa 服務端的啟動模式,此處主要是通過 process.roles 配置的存在與否來判斷,如果這個配置存在則以移除 zk 依賴的KRaft模式啟動,否則以依賴 zk 的舊模式啟動 - 本文基于 Kafka 3.0 版本,此版本的 KRaft 支持已經比較穩定,故以 KRaft 模式為例進行分析,此處將創建
KafkaRaftServer物件
private def buildServer(props: Properties): Server = { val config = KafkaConfig.fromProps(props, false) if (config.requiresZookeeper) { new KafkaServer( config, Time.SYSTEM, threadNamePrefix = None, enableForwarding = false ) } else { new KafkaRaftServer( config, Time.SYSTEM, threadNamePrefix = None ) } } - 通過
-
Scala的語法與Java有不少差異,比如 Scala 中建構式是直接與類宣告相關聯的,另外KafkaRaftServer物件的創建動作會觸發執行不少關鍵成員物件的創建,與本文直接相關的如下:broker:BrokerServer物件,當節點的配置 process.roles 中指定了broker角色時才會創建,處理訊息資料類請求,例如訊息的生產消費等controller:ControllerServer物件,當節點的配置 process.roles 中指定了broker角色時才會創建,處理元資料類請求,包括 topic 創建洗掉等
class KafkaRaftServer( config: KafkaConfig, time: Time, threadNamePrefix: Option[String] ) extends Server with Logging { KafkaMetricsReporter.startReporters(VerifiableProperties(config.originals)) KafkaYammerMetrics.INSTANCE.configure(config.originals) private val (metaProps, offlineDirs) = KafkaRaftServer.initializeLogDirs(config) private val metrics = Server.initializeMetrics( config, time, metaProps.clusterId ) private val controllerQuorumVotersFuture = CompletableFuture.completedFuture( RaftConfig.parseVoterConnections(config.quorumVoters)) private val raftManager = new KafkaRaftManager[ApiMessageAndVersion]( metaProps, config, new MetadataRecordSerde, KafkaRaftServer.MetadataPartition, KafkaRaftServer.MetadataTopicId, time, metrics, threadNamePrefix, controllerQuorumVotersFuture ) private val broker: Option[BrokerServer] = if (config.processRoles.contains(BrokerRole)) { Some(new BrokerServer( config, metaProps, raftManager, time, metrics, threadNamePrefix, offlineDirs, controllerQuorumVotersFuture, Server.SUPPORTED_FEATURES )) } else { None } private val controller: Option[ControllerServer] = if (config.processRoles.contains(ControllerRole)) { Some(new ControllerServer( metaProps, config, raftManager, time, metrics, threadNamePrefix, controllerQuorumVotersFuture )) } else { None } ... } -
經過以上步驟,Kafka 服務端的
Server物件創建完畢,最終創建了一個KafkaRaftServer物件,則在本節步驟1第三步將KafkaRaftServer.scala#startup()方法啟動服務端,可以看到和本文相關的重點如下:controller.foreach(_.startup())啟動節點上可能存在的ControllerServer,呼叫其ControllerServer.scala#startup()方法broker.foreach(_.startup())啟動節點上可能存在的BrokerServer,呼叫其BrokerServer.scala#startup()方法
本文將以
BrokerServer的啟動為例進行分析,其實從網路通信結構的角度來看,BrokerServer和ControllerServer幾乎是完全一致的override def startup(): Unit = { Mx4jLoader.maybeLoad() raftManager.startup() controller.foreach(_.startup()) broker.foreach(_.startup()) AppInfoParser.registerAppInfo(Server.MetricsPrefix, config.brokerId.toString, metrics, time.milliseconds()) info(KafkaBroker.STARTED_MESSAGE) } -
BrokerServer.scala#startup()方法比較長,其中涉及的關鍵物件如下,不過去蕪存菁,和網路通信相關的重點其實只有兩個,分別是SocketServer 底層網路服務器的創建及配置啟動和KafkaRequestHandlerPool 上層請求處理器池的創建啟動kafkaScheduler:KafkaScheduler物件,定時任務的執行緒池metadataCache:KRaftMetadataCache物件,集群元資料管理組件clientToControllerChannelManager:BrokerToControllerChannelManager物件,broker 到 controller 的連接管理器forwardingManager:ForwardingManagerImpl物件,持有clientToControllerChannelManager物件,負責轉發應該由 controller 處理的請求socketServer:SocketServer物件,面向底層網路的服務器物件_replicaManager:ReplicaManager物件,副本管理器,負責訊息的存盤讀取groupCoordinator:GroupCoordinator物件,普通消費者組的協調器,負責輔助完成消費者組內各個消費者消費磁區的協調分配dataPlaneRequestProcessor:KafkaApis物件,上層的請求處理器,持有底層網路服務器的請求佇列socketServer.dataPlaneRequestChannel,負責從佇列中取出請求進行處理dataPlaneRequestHandlerPool:KafkaRequestHandlerPool物件,上層的請求處理器執行緒池
def startup(): Unit = { if (!maybeChangeStatus(SHUTDOWN, STARTING)) return try { info("Starting broker") /* start scheduler */ kafkaScheduler = new KafkaScheduler(config.backgroundThreads) kafkaScheduler.startup() /* register broker metrics */ _brokerTopicStats = new BrokerTopicStats quotaManagers = QuotaFactory.instantiate(config, metrics, time, threadNamePrefix.getOrElse("")) logDirFailureChannel = new LogDirFailureChannel(config.logDirs.size) metadataCache = MetadataCache.kRaftMetadataCache(config.nodeId) // Create log manager, but don't start it because we need to delay any potential unclean shutdown log recovery // until we catch up on the metadata log and have up-to-date topic and broker configs. logManager = LogManager(config, initialOfflineDirs, metadataCache, kafkaScheduler, time, brokerTopicStats, logDirFailureChannel, keepPartitionMetadataFile = true) // Enable delegation token cache for all SCRAM mechanisms to simplify dynamic update. // This keeps the cache up-to-date if new SCRAM mechanisms are enabled dynamically. tokenCache = new DelegationTokenCache(ScramMechanism.mechanismNames) credentialProvider = new CredentialProvider(ScramMechanism.mechanismNames, tokenCache) val controllerNodes = RaftConfig.voterConnectionsToNodes(controllerQuorumVotersFuture.get()).asScala val controllerNodeProvider = RaftControllerNodeProvider(raftManager, config, controllerNodes) clientToControllerChannelManager = BrokerToControllerChannelManager( controllerNodeProvider, time, metrics, config, channelName = "forwarding", threadNamePrefix, retryTimeoutMs = 60000 ) clientToControllerChannelManager.start() forwardingManager = new ForwardingManagerImpl(clientToControllerChannelManager) val apiVersionManager = ApiVersionManager( ListenerType.BROKER, config, Some(forwardingManager), brokerFeatures, featureCache ) // Create and start the socket server acceptor threads so that the bound port is known. // Delay starting processors until the end of the initialization sequence to ensure // that credentials have been loaded before processing authentications. socketServer = new SocketServer(config, metrics, time, credentialProvider, apiVersionManager) socketServer.startup(startProcessingRequests = false) clientQuotaMetadataManager = new ClientQuotaMetadataManager(quotaManagers, socketServer.connectionQuotas) val alterIsrChannelManager = BrokerToControllerChannelManager( controllerNodeProvider, time, metrics, config, channelName = "alterIsr", threadNamePrefix, retryTimeoutMs = Long.MaxValue ) alterIsrManager = new DefaultAlterIsrManager( controllerChannelManager = alterIsrChannelManager, scheduler = kafkaScheduler, time = time, brokerId = config.nodeId, brokerEpochSupplier = () => lifecycleManager.brokerEpoch ) alterIsrManager.start() this._replicaManager = new ReplicaManager(config, metrics, time, None, kafkaScheduler, logManager, isShuttingDown, quotaManagers, brokerTopicStats, metadataCache, logDirFailureChannel, alterIsrManager, threadNamePrefix) /* start token manager */ if (config.tokenAuthEnabled) { throw new UnsupportedOperationException("Delegation tokens are not supported") } tokenManager = new DelegationTokenManager(config, tokenCache, time , null) tokenManager.startup() // does nothing, we just need a token manager in order to compile right now... // Create group coordinator, but don't start it until we've started replica manager. // Hardcode Time.SYSTEM for now as some Streams tests fail otherwise, it would be good to fix the underlying issue groupCoordinator = GroupCoordinator(config, replicaManager, Time.SYSTEM, metrics) val producerIdManagerSupplier = () => ProducerIdManager.rpc( config.brokerId, brokerEpochSupplier = () => lifecycleManager.brokerEpoch, clientToControllerChannelManager, config.requestTimeoutMs ) // Create transaction coordinator, but don't start it until we've started replica manager. // Hardcode Time.SYSTEM for now as some Streams tests fail otherwise, it would be good to fix the underlying issue transactionCoordinator = TransactionCoordinator(config, replicaManager, new KafkaScheduler(threads = 1, threadNamePrefix = "transaction-log-manager-"), producerIdManagerSupplier, metrics, metadataCache, Time.SYSTEM) autoTopicCreationManager = new DefaultAutoTopicCreationManager( config, Some(clientToControllerChannelManager), None, None, groupCoordinator, transactionCoordinator) /* Add all reconfigurables for config change notification before starting the metadata listener */ config.dynamicConfig.addReconfigurables(this) dynamicConfigHandlers = Map[String, ConfigHandler]( ConfigType.Topic -> new TopicConfigHandler(logManager, config, quotaManagers, None), ConfigType.Broker -> new BrokerConfigHandler(config, quotaManagers)) if (!config.processRoles.contains(ControllerRole)) { // If no controller is defined, we rely on the broker to generate snapshots. metadataSnapshotter = Some(new BrokerMetadataSnapshotter( config.nodeId, time, threadNamePrefix, new BrokerSnapshotWriterBuilder(raftManager.client) )) } metadataListener = new BrokerMetadataListener(config.nodeId, time, threadNamePrefix, config.metadataSnapshotMaxNewRecordBytes, metadataSnapshotter) val networkListeners = new ListenerCollection() config.advertisedListeners.foreach { ep => networkListeners.add(new Listener(). setHost(if (Utils.isBlank(ep.host)) InetAddress.getLocalHost.getCanonicalHostName else ep.host). setName(ep.listenerName.value()). setPort(if (ep.port == 0) socketServer.boundPort(ep.listenerName) else ep.port). setSecurityProtocol(ep.securityProtocol.id)) } lifecycleManager.start(() => metadataListener.highestMetadataOffset(), BrokerToControllerChannelManager(controllerNodeProvider, time, metrics, config, "heartbeat", threadNamePrefix, config.brokerSessionTimeoutMs.toLong), metaProps.clusterId, networkListeners, supportedFeatures) // Register a listener with the Raft layer to receive metadata event notifications raftManager.register(metadataListener) val endpoints = new util.ArrayList[Endpoint](networkListeners.size()) var interBrokerListener: Endpoint = null networkListeners.iterator().forEachRemaining(listener => { val endPoint = new Endpoint(listener.name(), SecurityProtocol.forId(listener.securityProtocol()), listener.host(), listener.port()) endpoints.add(endPoint) if (listener.name().equals(config.interBrokerListenerName.value())) { interBrokerListener = endPoint } }) if (interBrokerListener == null) { throw new RuntimeException("Unable to find inter-broker listener " + config.interBrokerListenerName.value() + ". Found listener(s): " + endpoints.asScala.map(ep => ep.listenerName().orElse("(none)")).mkString(", ")) } val authorizerInfo = ServerInfo(new ClusterResource(clusterId), config.nodeId, endpoints, interBrokerListener) /* Get the authorizer and initialize it if one is specified.*/ authorizer = config.authorizer authorizer.foreach(_.configure(config.originals)) val authorizerFutures: Map[Endpoint, CompletableFuture[Void]] = authorizer match { case Some(authZ) => authZ.start(authorizerInfo).asScala.map { case (ep, cs) => ep -> cs.toCompletableFuture } case None => authorizerInfo.endpoints.asScala.map { ep => ep -> CompletableFuture.completedFuture[Void](null) }.toMap } val fetchManager = new FetchManager(Time.SYSTEM, new FetchSessionCache(config.maxIncrementalFetchSessionCacheSlots, KafkaServer.MIN_INCREMENTAL_FETCH_SESSION_EVICTION_MS)) // Create the request processor objects. val raftSupport = RaftSupport(forwardingManager, metadataCache) dataPlaneRequestProcessor = new KafkaApis(socketServer.dataPlaneRequestChannel, raftSupport, replicaManager, groupCoordinator, transactionCoordinator, autoTopicCreationManager, config.nodeId, config, metadataCache, metadataCache, metrics, authorizer, quotaManagers, fetchManager, brokerTopicStats, clusterId, time, tokenManager, apiVersionManager) dataPlaneRequestHandlerPool = new KafkaRequestHandlerPool(config.nodeId, socketServer.dataPlaneRequestChannel, dataPlaneRequestProcessor, time, config.numIoThreads, s"${SocketServer.DataPlaneMetricPrefix}RequestHandlerAvgIdlePercent", SocketServer.DataPlaneThreadPrefix) if (socketServer.controlPlaneRequestChannelOpt.isDefined) { throw new RuntimeException(KafkaConfig.ControlPlaneListenerNameProp + " is not " + "supported when in KRaft mode.") } // Block until we've caught up with the latest metadata from the controller quorum. lifecycleManager.initialCatchUpFuture.get() // Apply the metadata log changes that we've accumulated. metadataPublisher = new BrokerMetadataPublisher(config, metadataCache, logManager, replicaManager, groupCoordinator, transactionCoordinator, clientQuotaMetadataManager, featureCache, dynamicConfigHandlers.toMap) // Tell the metadata listener to start publishing its output, and wait for the first // publish operation to complete. This first operation will initialize logManager, // replicaManager, groupCoordinator, and txnCoordinator. The log manager may perform // a potentially lengthy recovery-from-unclean-shutdown operation here, if required. metadataListener.startPublishing(metadataPublisher).get() // Log static broker configurations. new KafkaConfig(config.originals(), true) // Enable inbound TCP connections. socketServer.startProcessingRequests(authorizerFutures) // We're now ready to unfence the broker. This also allows this broker to transition // from RECOVERY state to RUNNING state, once the controller unfences the broker. lifecycleManager.setReadyToUnfence() maybeChangeStatus(STARTING, STARTED) } catch { case e: Throwable => maybeChangeStatus(STARTING, STARTED) fatal("Fatal error during broker startup. Prepare to shutdown", e) shutdown() throw e } } -
SocketServer物件創建時會觸發內部的請求佇列RequestChannel物件的創建,其內部關鍵成員物件如下:maxQueuedRequests:請求佇列的大小,由queued.max.requests配置決定dataPlaneProcessors: 快取網路連接上資料平面資料處理器的 MapdataPlaneAcceptors: 快取網路連接的資料平面接收器的 MapdataPlaneRequestChannel: 資料平面RequestChannel請求佇列物件,快取收到的請求controlPlaneRequestChannelOpt: 控制平面的RequestChannel請求佇列物件,默認大小為 20,由配置 control.plane.listener.name 決定是否創建,在 Kafka 3.0 版本的 KRaft 模式下如果該配置存在將報例外
class SocketServer(val config: KafkaConfig, val metrics: Metrics, val time: Time, val credentialProvider: CredentialProvider, val apiVersionManager: ApiVersionManager) extends Logging with KafkaMetricsGroup with BrokerReconfigurable { private val maxQueuedRequests = config.queuedMaxRequests private val nodeId = config.brokerId private val logContext = new LogContext(s"[SocketServer listenerType=${apiVersionManager.listenerType}, nodeId=$nodeId] ") this.logIdent = logContext.logPrefix private val memoryPoolSensor = metrics.sensor("MemoryPoolUtilization") private val memoryPoolDepletedPercentMetricName = metrics.metricName("MemoryPoolAvgDepletedPercent", MetricsGroup) private val memoryPoolDepletedTimeMetricName = metrics.metricName("MemoryPoolDepletedTimeTotal", MetricsGroup) memoryPoolSensor.add(new Meter(TimeUnit.MILLISECONDS, memoryPoolDepletedPercentMetricName, memoryPoolDepletedTimeMetricName)) private val memoryPool = if (config.queuedMaxBytes > 0) new SimpleMemoryPool(config.queuedMaxBytes, config.socketRequestMaxBytes, false, memoryPoolSensor) else MemoryPool.NONE // data-plane private val dataPlaneProcessors = new ConcurrentHashMap[Int, Processor]() private[network] val dataPlaneAcceptors = new ConcurrentHashMap[EndPoint, Acceptor]() val dataPlaneRequestChannel = new RequestChannel(maxQueuedRequests, DataPlaneMetricPrefix, time, apiVersionManager.newRequestMetrics) // control-plane private var controlPlaneProcessorOpt : Option[Processor] = None private[network] var controlPlaneAcceptorOpt : Option[Acceptor] = None val controlPlaneRequestChannelOpt: Option[RequestChannel] = config.controlPlaneListenerName.map(_ => new RequestChannel(20, ControlPlaneMetricPrefix, time, apiVersionManager.newRequestMetrics)) private var nextProcessorId = 0 val connectionQuotas = new ConnectionQuotas(config, time, metrics) private var startedProcessingRequests = false private var stoppedProcessingRequests = false ...... } -
在本節步驟6中可以看到
SocketServer物件被創建后立即就被呼叫了啟動方法SocketServer.scala#startup(),該方法的核心如下:- 呼叫
SocketServer.scala#createControlPlaneAcceptorAndProcessor()方法創建控制平面的連接接收器及連接處理器,此處是兼容舊版本的處理,在 Kafka 3.0 版本的 KRaft 模式下不支持控制平面的 control.plane.listener.name配置,故此方法呼叫可忽略 - 呼叫
SocketServer.scala#createDataPlaneAcceptorsAndProcessors()方法創建資料平面的連接接收器及連接處理器,此處該方法引數來源于默認引數,即KafkaConfig.scala#dataPlaneListeners()方法的回傳值 - 根據
startProcessingRequests引數決定是否啟動底層網路監聽,此處是不啟動的
def startup(startProcessingRequests: Boolean = true, controlPlaneListener: Option[EndPoint] = config.controlPlaneListener, dataPlaneListeners: Seq[EndPoint] = config.dataPlaneListeners): Unit = { this.synchronized { createControlPlaneAcceptorAndProcessor(controlPlaneListener) createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, dataPlaneListeners) if (startProcessingRequests) { this.startProcessingRequests() } } newGauge(s"${DataPlaneMetricPrefix}NetworkProcessorAvgIdlePercent", () => SocketServer.this.synchronized { val ioWaitRatioMetricNames = dataPlaneProcessors.values.asScala.iterator.map { p => metrics.metricName("io-wait-ratio", MetricsGroup, p.metricTags) } ioWaitRatioMetricNames.map { metricName => Option(metrics.metric(metricName)).fold(0.0)(m => Math.min(m.metricValue.asInstanceOf[Double], 1.0)) }.sum / dataPlaneProcessors.size }) newGauge(s"${ControlPlaneMetricPrefix}NetworkProcessorAvgIdlePercent", () => SocketServer.this.synchronized { val ioWaitRatioMetricName = controlPlaneProcessorOpt.map { p => metrics.metricName("io-wait-ratio", MetricsGroup, p.metricTags) } ioWaitRatioMetricName.map { metricName => Option(metrics.metric(metricName)).fold(0.0)(m => Math.min(m.metricValue.asInstanceOf[Double], 1.0)) }.getOrElse(Double.NaN) }) newGauge("MemoryPoolAvailable", () => memoryPool.availableMemory) newGauge("MemoryPoolUsed", () => memoryPool.size() - memoryPool.availableMemory) newGauge(s"${DataPlaneMetricPrefix}ExpiredConnectionsKilledCount", () => SocketServer.this.synchronized { val expiredConnectionsKilledCountMetricNames = dataPlaneProcessors.values.asScala.iterator.map { p => metrics.metricName("expired-connections-killed-count", MetricsGroup, p.metricTags) } expiredConnectionsKilledCountMetricNames.map { metricName => Option(metrics.metric(metricName)).fold(0.0)(m => m.metricValue.asInstanceOf[Double]) }.sum }) newGauge(s"${ControlPlaneMetricPrefix}ExpiredConnectionsKilledCount", () => SocketServer.this.synchronized { val expiredConnectionsKilledCountMetricNames = controlPlaneProcessorOpt.map { p => metrics.metricName("expired-connections-killed-count", MetricsGroup, p.metricTags) } expiredConnectionsKilledCountMetricNames.map { metricName => Option(metrics.metric(metricName)).fold(0.0)(m => m.metricValue.asInstanceOf[Double]) }.getOrElse(0.0) }) } - 呼叫
-
SocketServer.scala#createDataPlaneAcceptorsAndProcessors()方法根據組態檔中listeners配置的監聽器串列,遍歷監聽器創建對應的Acceptor和Processor,其關鍵如下:- 首先呼叫
SocketServer.scala#createAcceptor()創建連接接收器Acceptor - 再呼叫
SocketServer.scala#addDataPlaneProcessors()為連接接收器創建屬于它的Processor,Processor個數由 num.network.threads 配置決定
private def createDataPlaneAcceptorsAndProcessors(dataProcessorsPerListener: Int, endpoints: Seq[EndPoint]): Unit = { endpoints.foreach { endpoint => connectionQuotas.addListener(config, endpoint.listenerName) val dataPlaneAcceptor = createAcceptor(endpoint, DataPlaneMetricPrefix) addDataPlaneProcessors(dataPlaneAcceptor, endpoint, dataProcessorsPerListener) dataPlaneAcceptors.put(endpoint, dataPlaneAcceptor) info(s"Created data-plane acceptor and processors for endpoint : ${endpoint.listenerName}") } } - 首先呼叫
-
SocketServer.scala#createAcceptor()方法如下,可以看到主要操作是新建一個SocketServer.scala#Acceptor物件private def createAcceptor(endPoint: EndPoint, metricPrefix: String) : Acceptor = { val sendBufferSize = config.socketSendBufferBytes val recvBufferSize = config.socketReceiveBufferBytes new Acceptor(endPoint, sendBufferSize, recvBufferSize, nodeId, connectionQuotas, metricPrefix, time) } -
SocketServer.scala#Acceptor為內部類,其比較關鍵的成員物件如下:nioSelector: Java 中的Selector物件,負責監聽網路連接serverChannel: Java 中的服務端ServerSocketChannel物件,該物件由SocketServer.scala#Acceptor#openServerSocket()方法創建,創建時會系結監聽埠
private[kafka] class Acceptor(val endPoint: EndPoint, val sendBufferSize: Int, val recvBufferSize: Int, nodeId: Int, connectionQuotas: ConnectionQuotas, metricPrefix: String, time: Time, logPrefix: String = "") extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup { this.logIdent = logPrefix private val nioSelector = NSelector.open() val serverChannel = openServerSocket(endPoint.host, endPoint.port) private val processors = new ArrayBuffer[Processor]() private val processorsStarted = new AtomicBoolean private val blockedPercentMeter = newMeter(s"${metricPrefix}AcceptorBlockedPercent", "blocked time", TimeUnit.NANOSECONDS, Map(ListenerMetricTag -> endPoint.listenerName.value)) private var currentProcessorIndex = 0 private[network] val throttledSockets = new mutable.PriorityQueue[DelayedCloseSocket]() ...... private def openServerSocket(host: String, port: Int): ServerSocketChannel = { val socketAddress = if (Utils.isBlank(host)) new InetSocketAddress(port) else new InetSocketAddress(host, port) val serverChannel = ServerSocketChannel.open() serverChannel.configureBlocking(false) if (recvBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE) serverChannel.socket().setReceiveBufferSize(recvBufferSize) try { serverChannel.socket.bind(socketAddress) info(s"Awaiting socket connections on ${socketAddress.getHostString}:${serverChannel.socket.getLocalPort}.") } catch { case e: SocketException => throw new KafkaException(s"Socket server failed to bind to ${socketAddress.getHostString}:$port: ${e.getMessage}.", e) } serverChannel } ······ } -
回到本節步驟9,
SocketServer.scala#addDataPlaneProcessors()方法實作如下,可以看到核心 for 回圈創建Processor,重要處理如下:- 呼叫
SocketServer.scala#newProcessor()方法創建Processor - 呼叫
RequestChannel.scala#addProcessor()方法將新創建的Processor物件保存在內部串列,后續將用于請求處理完成后回應的分配處理 - for 回圈結束,呼叫
Acceptor#addProcessors()將創建的所有Processor快取到內部,后續將用于新建連接的分配
private def addDataPlaneProcessors(acceptor: Acceptor, endpoint: EndPoint, newProcessorsPerListener: Int): Unit = { val listenerName = endpoint.listenerName val securityProtocol = endpoint.securityProtocol val listenerProcessors = new ArrayBuffer[Processor]() val isPrivilegedListener = controlPlaneRequestChannelOpt.isEmpty && config.interBrokerListenerName == listenerName for (_ <- 0 until newProcessorsPerListener) { val processor = newProcessor(nextProcessorId, dataPlaneRequestChannel, connectionQuotas, listenerName, securityProtocol, memoryPool, isPrivilegedListener) listenerProcessors += processor dataPlaneRequestChannel.addProcessor(processor) nextProcessorId += 1 } listenerProcessors.foreach(p => dataPlaneProcessors.put(p.id, p)) acceptor.addProcessors(listenerProcessors, DataPlaneThreadPrefix) } - 呼叫
-
SocketServer.scala#Processor定義如下,可以看到內部比較關鍵的屬性newConnections: 新連接串列,負責快取由Acceptor接收后分配至Processor處理的連接將responseQueue: 回應串列,負責快取請求處理完成后的回應selector: Kafak 的KSelector物件,其內部封裝著 Java 的 Selector,負責監聽分配給Processor處理的連接
private[kafka] class Processor(val id: Int, time: Time, maxRequestSize: Int, requestChannel: RequestChannel, connectionQuotas: ConnectionQuotas, connectionsMaxIdleMs: Long, failedAuthenticationDelayMs: Int, listenerName: ListenerName, securityProtocol: SecurityProtocol, config: KafkaConfig, metrics: Metrics, credentialProvider: CredentialProvider, memoryPool: MemoryPool, logContext: LogContext, connectionQueueSize: Int, isPrivilegedListener: Boolean, apiVersionManager: ApiVersionManager) extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup { ...... private val newConnections = new ArrayBlockingQueue[SocketChannel](connectionQueueSize) private val inflightResponses = mutable.Map[String, RequestChannel.Response]() private val responseQueue = new LinkedBlockingDeque[RequestChannel.Response]() private[kafka] val metricTags = mutable.LinkedHashMap( ListenerMetricTag -> listenerName.value, NetworkProcessorMetricTag -> id.toString ).asJava newGauge(IdlePercentMetricName, () => { Option(metrics.metric(metrics.metricName("io-wait-ratio", MetricsGroup, metricTags))).fold(0.0)(m => Math.min(m.metricValue.asInstanceOf[Double], 1.0)) }, // for compatibility, only add a networkProcessor tag to the Yammer Metrics alias (the equivalent Selector metric // also includes the listener name) Map(NetworkProcessorMetricTag -> id.toString) ) val expiredConnectionsKilledCount = new CumulativeSum() private val expiredConnectionsKilledCountMetricName = metrics.metricName("expired-connections-killed-count", MetricsGroup, metricTags) metrics.addMetric(expiredConnectionsKilledCountMetricName, expiredConnectionsKilledCount) private val selector = createSelector( ChannelBuilders.serverChannelBuilder( listenerName, listenerName == config.interBrokerListenerName, securityProtocol, config, credentialProvider.credentialCache, credentialProvider.tokenCache, time, logContext, () => apiVersionManager.apiVersionResponse(throttleTimeMs = 0) ) ) // Visible to override for testing protected[network] def createSelector(channelBuilder: ChannelBuilder): KSelector = { channelBuilder match { case reconfigurable: Reconfigurable => config.addReconfigurable(reconfigurable) case _ => } new KSelector( maxRequestSize, connectionsMaxIdleMs, failedAuthenticationDelayMs, metrics, time, "socket-server", metricTags, false, true, channelBuilder, memoryPool, logContext) } ...... } -
回到本節步驟6
BrokerServer.scala#startup()方法內成員變數dataPlaneRequestHandlerPool的賦值,可以看到實體為KafkaRequestHandler.scala#KafkaRequestHandlerPool類物件,并且持有了KafkaApis物件作為上層的請求處理器,其關鍵屬性如下:threadPoolSize: 處理器執行緒池大小,由配置num.io.threads 決定runnables: 處理器KafkaRequestHandler的陣列,各個處理器由KafkaRequestHandler.scala#KafkaRequestHandlerPool#createHandler()方法創建,可以看到實際處理器物件為封裝了KafkaApis物件的KafkaRequestHandler物件,該物件被創建后就扔進了新建執行緒中執行
class KafkaRequestHandlerPool(val brokerId: Int, val requestChannel: RequestChannel, val apis: ApiRequestHandler, time: Time, numThreads: Int, requestHandlerAvgIdleMetricName: String, logAndThreadNamePrefix : String) extends Logging with KafkaMetricsGroup { private val threadPoolSize: AtomicInteger = new AtomicInteger(numThreads) /* a meter to track the average free capacity of the request handlers */ private val aggregateIdleMeter = newMeter(requestHandlerAvgIdleMetricName, "percent", TimeUnit.NANOSECONDS) this.logIdent = "[" + logAndThreadNamePrefix + " Kafka Request Handler on Broker " + brokerId + "], " val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads) for (i <- 0 until numThreads) { createHandler(i) } def createHandler(id: Int): Unit = synchronized { runnables += new KafkaRequestHandler(id, brokerId, aggregateIdleMeter, threadPoolSize, requestChannel, apis, time) KafkaThread.daemon(logAndThreadNamePrefix + "-kafka-request-handler-" + id, runnables(id)).start() } ...... } -
KafkaRequestHandler的類定義如下,可以看到其作為執行緒任務啟動后會在KafkaRequestHandler.scala#run()方法中死回圈不斷處理底層接收到的請求,關鍵步驟如下:requestChannel.receiveRequest()不斷輪詢請求佇列,獲取請求,如沒有請求則執行緒阻塞apis.handle呼叫介面方法ApiRequestHandler#handle(),將請求投遞到處理器中進行處理
class KafkaRequestHandler(id: Int, brokerId: Int, val aggregateIdleMeter: Meter, val totalHandlerThreads: AtomicInteger, val requestChannel: RequestChannel, apis: ApiRequestHandler, time: Time) extends Runnable with Logging { this.logIdent = s"[Kafka Request Handler $id on Broker $brokerId], " private val shutdownComplete = new CountDownLatch(1) private val requestLocal = RequestLocal.withThreadConfinedCaching @volatile private var stopped = false def run(): Unit = { while (!stopped) { // We use a single meter for aggregate idle percentage for the thread pool. // Since meter is calculated as total_recorded_value / time_window and // time_window is independent of the number of threads, each recorded idle // time should be discounted by # threads. val startSelectTime = time.nanoseconds val req = requestChannel.receiveRequest(300) val endTime = time.nanoseconds val idleTime = endTime - startSelectTime aggregateIdleMeter.mark(idleTime / totalHandlerThreads.get) req match { case RequestChannel.ShutdownRequest => debug(s"Kafka request handler $id on broker $brokerId received shut down command") completeShutdown() return case request: RequestChannel.Request => try { request.requestDequeueTimeNanos = endTime trace(s"Kafka request handler $id on broker $brokerId handling request $request") apis.handle(request, requestLocal) } catch { case e: FatalExitError => completeShutdown() Exit.exit(e.statusCode) case e: Throwable => error("Exception when handling request", e) } finally { request.releaseBuffer() } case null => // continue } } completeShutdown() } ...... } -
上層的請求處理器已經啟動,此時回到步驟6啟動底層網路服務器的方法
SocketServer.scala#startProcessingRequests(),從原始碼中可以看到,此處核心為呼叫SocketServer.scala#startDataPlaneProcessorsAndAcceptors()方法,最終啟動Acceptor和Prrocessor的邏輯在SocketServer.scala#startAcceptorAndProcessors()方法中def startProcessingRequests(authorizerFutures: Map[Endpoint, CompletableFuture[Void]] = Map.empty): Unit = { info("Starting socket server acceptors and processors") this.synchronized { if (!startedProcessingRequests) { startControlPlaneProcessorAndAcceptor(authorizerFutures) startDataPlaneProcessorsAndAcceptors(authorizerFutures) startedProcessingRequests = true } else { info("Socket server acceptors and processors already started") } } info("Started socket server acceptors and processors") } private def startDataPlaneProcessorsAndAcceptors(authorizerFutures: Map[Endpoint, CompletableFuture[Void]]): Unit = { val interBrokerListener = dataPlaneAcceptors.asScala.keySet .find(_.listenerName == config.interBrokerListenerName) val orderedAcceptors = interBrokerListener match { case Some(interBrokerListener) => List(dataPlaneAcceptors.get(interBrokerListener)) ++ dataPlaneAcceptors.asScala.filter { case (k, _) => k != interBrokerListener }.values case None => dataPlaneAcceptors.asScala.values } orderedAcceptors.foreach { acceptor => val endpoint = acceptor.endPoint startAcceptorAndProcessors(DataPlaneThreadPrefix, endpoint, acceptor, authorizerFutures) } } -
SocketServer.scala#startAcceptorAndProcessors()方法的實作如下,簡單來說分為兩步,至此服務端的啟動告一段落- 首先呼叫
SocketServer.scala#Acceptor#startProcessors()將Acceptor內部的Processor都扔進執行緒中啟動 - 其次新起執行緒,將當前
Acceptor扔進執行緒中啟動
private def startAcceptorAndProcessors(threadPrefix: String, endpoint: EndPoint, acceptor: Acceptor, authorizerFutures: Map[Endpoint, CompletableFuture[Void]] = Map.empty): Unit = { debug(s"Wait for authorizer to complete start up on listener ${endpoint.listenerName}") waitForAuthorizerFuture(acceptor, authorizerFutures) debug(s"Start processors on listener ${endpoint.listenerName}") acceptor.startProcessors(threadPrefix) debug(s"Start acceptor thread on listener ${endpoint.listenerName}") if (!acceptor.isStarted()) { KafkaThread.nonDaemon( s"${threadPrefix}-kafka-socket-acceptor-${endpoint.listenerName}-${endpoint.securityProtocol}-${endpoint.port}", acceptor ).start() acceptor.awaitStartup() } info(s"Started $threadPrefix acceptor and processor(s) for endpoint : ${endpoint.listenerName}") } - 首先呼叫
2. Kafka 服務端新建連接的處理
-
Acceptor連接接收器啟動后,會觸發SocketServer.scala#Acceptor#run()方法執行,可以看到起關鍵操作如下:- 首先通過
serverChannel.register()將服務端ServerSocketChannel注冊到Selector上,并設定監聽的事件為SelectionKey.OP_ACCEPT - 在死回圈中不斷呼叫
SocketServer.scala#Acceptor#acceptNewConnections()方法接收遠端連接
def run(): Unit = { serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT) startupComplete() try { while (isRunning) { try { acceptNewConnections() closeThrottledConnections() } catch { // We catch all the throwables to prevent the acceptor thread from exiting on exceptions due // to a select operation on a specific channel or a bad request. We don't want // the broker to stop responding to requests from other clients in these scenarios. case e: ControlThrowable => throw e case e: Throwable => error("Error occurred", e) } } } finally { debug("Closing server socket, selector, and any throttled sockets.") CoreUtils.swallow(serverChannel.close(), this, Level.ERROR) CoreUtils.swallow(nioSelector.close(), this, Level.ERROR) throttledSockets.foreach(throttledSocket => closeSocket(throttledSocket.socket)) throttledSockets.clear() shutdownComplete() } } - 首先通過
-
SocketServer.scala#Acceptor#acceptNewConnections()方法其實就是標準的 NIO 處理,可以看到核心如下:- 首先呼叫
nioSelector.select()輪詢底層連接,如有連接就緒則呼叫nioSelector.selectedKeys()獲取事件處理 - 如果是接收連接事件,則呼叫
SocketServer.scala#Acceptor#accept()進行連接接收,隨后按照連接計數器取模選定一個Processor,最后呼叫SocketServer.scala#Acceptor#assignNewConnection()方法將連接分配給選定的Processor
private def acceptNewConnections(): Unit = { val ready = nioSelector.select(500) if (ready > 0) { val keys = nioSelector.selectedKeys() val iter = keys.iterator() while (iter.hasNext && isRunning) { try { val key = iter.next iter.remove() if (key.isAcceptable) { accept(key).foreach { socketChannel => // Assign the channel to the next processor (using round-robin) to which the // channel can be added without blocking. If newConnections queue is full on // all processors, block until the last one is able to accept a connection. var retriesLeft = synchronized(processors.length) var processor: Processor = null do { retriesLeft -= 1 processor = synchronized { // adjust the index (if necessary) and retrieve the processor atomically for // correct behaviour in case the number of processors is reduced dynamically currentProcessorIndex = currentProcessorIndex % processors.length processors(currentProcessorIndex) } currentProcessorIndex += 1 } while (!assignNewConnection(socketChannel, processor, retriesLeft == 0)) } } else throw new IllegalStateException("Unrecognized key state for acceptor thread.") } catch { case e: Throwable => error("Error while accepting connection", e) } } } } - 首先呼叫
-
SocketServer.scala#Acceptor#accept()內部呼叫serverSocketChannel.accept()進行標準的連接接收處理,可以看到此處配置了新連接的一些關鍵屬性private def accept(key: SelectionKey): Option[SocketChannel] = { val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel] val socketChannel = serverSocketChannel.accept() try { connectionQuotas.inc(endPoint.listenerName, socketChannel.socket.getInetAddress, blockedPercentMeter) socketChannel.configureBlocking(false) socketChannel.socket().setTcpNoDelay(true) socketChannel.socket().setKeepAlive(true) if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE) socketChannel.socket().setSendBufferSize(sendBufferSize) Some(socketChannel) } catch { case e: TooManyConnectionsException => info(s"Rejected connection from ${e.ip}, address already has the configured maximum of ${e.count} connections.") close(endPoint.listenerName, socketChannel) None case e: ConnectionThrottledException => val ip = socketChannel.socket.getInetAddress debug(s"Delaying closing of connection from $ip for ${e.throttleTimeMs} ms") val endThrottleTimeMs = e.startThrottleTimeMs + e.throttleTimeMs throttledSockets += DelayedCloseSocket(socketChannel, endThrottleTimeMs) None } } -
SocketServer.scala#Acceptor#assignNewConnection()方法的核心是呼叫SocketServer.scala#Processor#accept()方法將新建立的鏈接丟到Processor的新連接佇列private def assignNewConnection(socketChannel: SocketChannel, processor: Processor, mayBlock: Boolean): Boolean = { if (processor.accept(socketChannel, mayBlock, blockedPercentMeter)) { debug(s"Accepted connection from ${socketChannel.socket.getRemoteSocketAddress} on" + s" ${socketChannel.socket.getLocalSocketAddress} and assigned it to processor ${processor.id}," + s" sendBufferSize [actual|requested]: [${socketChannel.socket.getSendBufferSize}|$sendBufferSize]" + s" recvBufferSize [actual|requested]: [${socketChannel.socket.getReceiveBufferSize}|$recvBufferSize]") true } else false } -
SocketServer.scala#Processor#accept()方法主要處理是新連接入隊,其次也會呼叫SocketServer.scala#Processor#wakeup()喚醒Processor的Selector,至此新連接的處理分配告一段落def accept(socketChannel: SocketChannel, mayBlock: Boolean, acceptorIdlePercentMeter: com.yammer.metrics.core.Meter): Boolean = { val accepted = { if (newConnections.offer(socketChannel)) true else if (mayBlock) { val startNs = time.nanoseconds newConnections.put(socketChannel) acceptorIdlePercentMeter.mark(time.nanoseconds() - startNs) true } else false } if (accepted) wakeup() accepted }
3. Kafka 服務端請求處理流程
-
新連接入隊后,需要將其注冊到
Processor的Selector上才能實作讀寫事件監聽,這些主要在SocketServer.scala#Processor#run()方法中處理,可以看到這個方法關鍵邏輯如下:- 首先呼叫
SocketServer.scala#Processor#configureNewConnections()方法將新連接串列中的連接注冊到Selector上 - 接下來呼叫
SocketServer.scala#Processor#processNewResponses()方法將回應串列中的回應存入連接快取,注冊監聽可寫事件SelectionKey.OP_WRITE - 呼叫
SocketServer.scala#Processor#poll()方法處理連接上的可讀事件,將網路資料暫存到接識訓沖區 - 呼叫
SocketServer.scala#Processor#processCompletedReceives()方法將接識訓沖區的網路資料決議為 Kafka 請求,并將其扔進請求佇列,等待請求處理器輪詢處理
override def run(): Unit = { startupComplete() try { while (isRunning) { try { // setup any new connections that have been queued up configureNewConnections() // register any new responses for writing processNewResponses() poll() processCompletedReceives() processCompletedSends() processDisconnected() closeExcessConnections() } catch { // We catch all the throwables here to prevent the processor thread from exiting. We do this because // letting a processor exit might cause a bigger impact on the broker. This behavior might need to be // reviewed if we see an exception that needs the entire broker to stop. Usually the exceptions thrown would // be either associated with a specific socket channel or a bad request. These exceptions are caught and // processed by the individual methods above which close the failing channel and continue processing other // channels. So this catch block should only ever see ControlThrowables. case e: Throwable => processException("Processor got uncaught exception.", e) } } } finally { debug(s"Closing selector - processor $id") CoreUtils.swallow(closeAll(), this, Level.ERROR) shutdownComplete() } } - 首先呼叫
-
SocketServer.scala#Processor#configureNewConnections()方法的關鍵處理其實就是從新連接串列newConnections中拿到連接物件,隨后呼叫selector.register()將其注冊到Selector上并設定監聽事件為SelectionKey.OP_READprivate def configureNewConnections(): Unit = { var connectionsProcessed = 0 while (connectionsProcessed < connectionQueueSize && !newConnections.isEmpty) { val channel = newConnections.poll() try { debug(s"Processor $id listening to new connection from ${channel.socket.getRemoteSocketAddress}") selector.register(connectionId(channel.socket), channel) connectionsProcessed += 1 } catch { // We explicitly catch all exceptions and close the socket to avoid a socket leak. case e: Throwable => val remoteAddress = channel.socket.getRemoteSocketAddress // need to close the channel here to avoid a socket leak. close(listenerName, channel) processException(s"Processor $id closed connection from $remoteAddress", e) } } } -
SocketServer.scala#Processor#poll()方法如下,可以看到核心是呼叫Selector.java#poll()方法去處理底層連接的讀寫事件private def poll(): Unit = { val pollTimeout = if (newConnections.isEmpty) 300 else 0 try selector.poll(pollTimeout) catch { case e @ (_: IllegalStateException | _: IOException) => // The exception is not re-thrown and any completed sends/receives/connections/disconnections // from this poll will be processed. error(s"Processor $id poll failed", e) } } -
Selector.java#poll()方法內部也是標準的 NIO 操作處理,輪詢出來的讀寫就緒連接都交給了Selector.java#pollSelectionKeys()方法處理public void poll(long timeout) throws IOException { if (timeout < 0) throw new IllegalArgumentException("timeout should be >= 0"); boolean madeReadProgressLastCall = madeReadProgressLastPoll; clear(); boolean dataInBuffers = !keysWithBufferedRead.isEmpty(); if (!immediatelyConnectedKeys.isEmpty() || (madeReadProgressLastCall && dataInBuffers)) timeout = 0; if (!memoryPool.isOutOfMemory() && outOfMemory) { //we have recovered from memory pressure. unmute any channel not explicitly muted for other reasons log.trace("Broker no longer low on memory - unmuting incoming sockets"); for (KafkaChannel channel : channels.values()) { if (channel.isInMutableState() && !explicitlyMutedChannels.contains(channel)) { channel.maybeUnmute(); } } outOfMemory = false; } /* check ready keys */ long startSelect = time.nanoseconds(); int numReadyKeys = select(timeout); long endSelect = time.nanoseconds(); this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds()); if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) { Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys(); // Poll from channels that have buffered data (but nothing more from the underlying socket) if (dataInBuffers) { keysWithBufferedRead.removeAll(readyKeys); //so no channel gets polled twice Set<SelectionKey> toPoll = keysWithBufferedRead; keysWithBufferedRead = new HashSet<>(); //poll() calls will repopulate if needed pollSelectionKeys(toPoll, false, endSelect); } // Poll from channels where the underlying socket has more data pollSelectionKeys(readyKeys, false, endSelect); // Clear all selected keys so that they are included in the ready count for the next select readyKeys.clear(); pollSelectionKeys(immediatelyConnectedKeys, true, endSelect); immediatelyConnectedKeys.clear(); } else { madeReadProgressLastPoll = true; //no work is also "progress" } long endIo = time.nanoseconds(); this.sensors.ioTime.record(endIo - endSelect, time.milliseconds()); // Close channels that were delayed and are now ready to be closed completeDelayedChannelClose(endIo); // we use the time at the end of select to ensure that we don't close any connections that // have just been processed in pollSelectionKeys maybeCloseOldestConnection(endSelect); } -
Selector.java#pollSelectionKeys()方法的關鍵處理有兩處:- 呼叫
Selector.java#attemptRead()方法接收可讀連接上的資料,并將其暫存在接識訓沖區 - 呼叫
Selector.java#attemptWrite()方法嘗試將該連接發送緩沖區的資料寫入Socket
void pollSelectionKeys(Set<SelectionKey> selectionKeys, boolean isImmediatelyConnected, long currentTimeNanos) { for (SelectionKey key : determineHandlingOrder(selectionKeys)) { KafkaChannel channel = channel(key); long channelStartTimeNanos = recordTimePerConnection ? time.nanoseconds() : 0; boolean sendFailed = false; String nodeId = channel.id(); // register all per-connection metrics at once sensors.maybeRegisterConnectionMetrics(nodeId); if (idleExpiryManager != null) idleExpiryManager.update(nodeId, currentTimeNanos); try { /* complete any connections that have finished their handshake (either normally or immediately) */ if (isImmediatelyConnected || key.isConnectable()) { if (channel.finishConnect()) { this.connected.add(nodeId); this.sensors.connectionCreated.record(); SocketChannel socketChannel = (SocketChannel) key.channel(); log.debug("Created socket with SO_RCVBUF = {}, SO_SNDBUF = {}, SO_TIMEOUT = {} to node {}", socketChannel.socket().getReceiveBufferSize(), socketChannel.socket().getSendBufferSize(), socketChannel.socket().getSoTimeout(), nodeId); } else { continue; } } /* if channel is not ready finish prepare */ if (channel.isConnected() && !channel.ready()) { channel.prepare(); if (channel.ready()) { long readyTimeMs = time.milliseconds(); boolean isReauthentication = channel.successfulAuthentications() > 1; if (isReauthentication) { sensors.successfulReauthentication.record(1.0, readyTimeMs); if (channel.reauthenticationLatencyMs() == null) log.warn( "Should never happen: re-authentication latency for a re-authenticated channel was null; continuing..."); else sensors.reauthenticationLatency .record(channel.reauthenticationLatencyMs().doubleValue(), readyTimeMs); } else { sensors.successfulAuthentication.record(1.0, readyTimeMs); if (!channel.connectedClientSupportsReauthentication()) sensors.successfulAuthenticationNoReauth.record(1.0, readyTimeMs); } log.debug("Successfully {}authenticated with {}", isReauthentication ? "re-" : "", channel.socketDescription()); } } if (channel.ready() && channel.state() == ChannelState.NOT_CONNECTED) channel.state(ChannelState.READY); Optional<NetworkReceive> responseReceivedDuringReauthentication = channel.pollResponseReceivedDuringReauthentication(); responseReceivedDuringReauthentication.ifPresent(receive -> { long currentTimeMs = time.milliseconds(); addToCompletedReceives(channel, receive, currentTimeMs); }); //if channel is ready and has bytes to read from socket or buffer, and has no //previous completed receive then read from it if (channel.ready() && (key.isReadable() || channel.hasBytesBuffered()) && !hasCompletedReceive(channel) && !explicitlyMutedChannels.contains(channel)) { attemptRead(channel); } if (channel.hasBytesBuffered() && !explicitlyMutedChannels.contains(channel)) { //this channel has bytes enqueued in intermediary buffers that we could not read //(possibly because no memory). it may be the case that the underlying socket will //not come up in the next poll() and so we need to remember this channel for the //next poll call otherwise data may be stuck in said buffers forever. If we attempt //to process buffered data and no progress is made, the channel buffered status is //cleared to avoid the overhead of checking every time. keysWithBufferedRead.add(key); } /* if channel is ready write to any sockets that have space in their buffer and for which we have data */ long nowNanos = channelStartTimeNanos != 0 ? channelStartTimeNanos : currentTimeNanos; try { attemptWrite(key, channel, nowNanos); } catch (Exception e) { sendFailed = true; throw e; } /* cancel any defunct sockets */ if (!key.isValid()) close(channel, CloseMode.GRACEFUL); } catch (Exception e) { String desc = channel.socketDescription(); if (e instanceof IOException) { log.debug("Connection with {} disconnected", desc, e); } else if (e instanceof AuthenticationException) { boolean isReauthentication = channel.successfulAuthentications() > 0; if (isReauthentication) sensors.failedReauthentication.record(); else sensors.failedAuthentication.record(); String exceptionMessage = e.getMessage(); if (e instanceof DelayedResponseAuthenticationException) exceptionMessage = e.getCause().getMessage(); log.info("Failed {}authentication with {} ({})", isReauthentication ? "re-" : "", desc, exceptionMessage); } else { log.warn("Unexpected error from {}; closing connection", desc, e); } if (e instanceof DelayedResponseAuthenticationException) maybeDelayCloseOnAuthenticationFailure(channel); else close(channel, sendFailed ? CloseMode.NOTIFY_ONLY : CloseMode.GRACEFUL); } finally { maybeRecordTimePerConnection(channel, channelStartTimeNanos); } } } - 呼叫
-
Selector.java#attemptRead()方法會從連接上讀取網路資料,并呼叫Selector.java#addToCompletedReceives()方法將接收到的網路資料暫存到緩沖區private void attemptRead(KafkaChannel channel) throws IOException { String nodeId = channel.id(); long bytesReceived = channel.read(); if (bytesReceived != 0) { long currentTimeMs = time.milliseconds(); sensors.recordBytesReceived(nodeId, bytesReceived, currentTimeMs); madeReadProgressLastPoll = true; NetworkReceive receive = channel.maybeCompleteReceive(); if (receive != null) { addToCompletedReceives(channel, receive, currentTimeMs); } } if (channel.isMuted()) { outOfMemory = true; //channel has muted itself due to memory pressure. } else { madeReadProgressLastPoll = true; } } -
回到本節步驟1,
SocketServer.scala#Processor#processCompletedReceives()方法會將上一步接收到的網路資料決議為上層處理器能夠處理的 Kafka 請求,其關鍵點如下,至此 Kafka 請求處理的關鍵流程基本結束- 呼叫
SocketServer.scala#Processor#parseRequestHeader()決議出請求的頭資訊 - 呼叫
RequestChannel.scala#Request構造方法將網路資料入參創建 Kafka 請求,其內部將根據 Kafka 自定義的協議完成請求的決議作業 requestChannel.sendRequest()觸發RequestChannel.scala#sendRequest()方法,將決議完成的請求扔進請求佇列,上層處理器KafkaRequestHandler將呼叫RequestChannel.scala#receiveRequest()方法輪詢請求佇列完成請求處理,也就是本文第一節步驟15的流程
private def processCompletedReceives(): Unit = { selector.completedReceives.forEach { receive => try { openOrClosingChannel(receive.source) match { case Some(channel) => val header = parseRequestHeader(receive.payload) if (header.apiKey == ApiKeys.SASL_HANDSHAKE && channel.maybeBeginServerReauthentication(receive, () => time.nanoseconds())) trace(s"Begin re-authentication: $channel") else { val nowNanos = time.nanoseconds() if (channel.serverAuthenticationSessionExpired(nowNanos)) { // be sure to decrease connection count and drop any in-flight responses debug(s"Disconnecting expired channel: $channel : $header") close(channel.id) expiredConnectionsKilledCount.record(null, 1, 0) } else { val connectionId = receive.source val context = new RequestContext(header, connectionId, channel.socketAddress, channel.principal, listenerName, securityProtocol, channel.channelMetadataRegistry.clientInformation, isPrivilegedListener, channel.principalSerde) val req = new RequestChannel.Request(processor = id, context = context, startTimeNanos = nowNanos, memoryPool, receive.payload, requestChannel.metrics, None) // KIP-511: ApiVersionsRequest is intercepted here to catch the client software name // and version. It is done here to avoid wiring things up to the api layer. if (header.apiKey == ApiKeys.API_VERSIONS) { val apiVersionsRequest = req.body[ApiVersionsRequest] if (apiVersionsRequest.isValid) { channel.channelMetadataRegistry.registerClientInformation(new ClientInformation( apiVersionsRequest.data.clientSoftwareName, apiVersionsRequest.data.clientSoftwareVersion)) } } requestChannel.sendRequest(req) selector.mute(connectionId) handleChannelMuteEvent(connectionId, ChannelMuteEvent.REQUEST_RECEIVED) } } case None => // This should never happen since completed receives are processed immediately after `poll()` throw new IllegalStateException(s"Channel ${receive.source} removed from selector before processing completed receive") } } catch { // note that even though we got an exception, we can assume that receive.source is valid. // Issues with constructing a valid receive object were handled earlier case e: Throwable => processChannelException(receive.source, s"Exception while processing request from ${receive.source}", e) } } selector.clearCompletedReceives() } - 呼叫
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385534.html
標籤:其他
上一篇:Elasticsearch介紹及基本操作 ---- HTTP協議方式
下一篇:hive知識點總結