hive學習知識總結
- Hive定義
- Hive的特點及應用場景
- Hive架構
- Hive中的庫
- Hive 中的表
- 行轉列,列轉行
- Rank函式
- UDF
Hive定義
Hive由FaceBook開源用于解決海量資料化日志的資料統計,
Hive 是Hadoop生態系統中必不可少的一個工具, 它可以將存盤在HDFS中的結構化資料映射為一張表,并提供了一種SQL方言對其進行查詢, 這些sql陳述句最侄訓翻譯成MapReduce程式執行,
Hive的特點及應用場景
hive是基于Hadoop的應用程式, 受限于Hadoop的設計, Hive不能提供完整的資料功能, 最大的限制就是Hive不支持行級別的更新、插入、或者洗掉操作, 同時,因為MapReduce的啟動程序需要消耗較長的時間, 所有Hive查詢延遲比較嚴重, 傳統資料庫中秒級別可以完成的查詢, 在Hive中即使資料集相對較小, 往往也需要執行更長的時間, 最后需要說明的是, Hive不支持事務,
因此Hive是最適合于資料倉庫應用程式,使用該應用程式進行相關的靜態資料分析, 不需要快速給出回應結果, 而且資料本身不會頻繁變化,,
Hive架構
大家先看一張圖
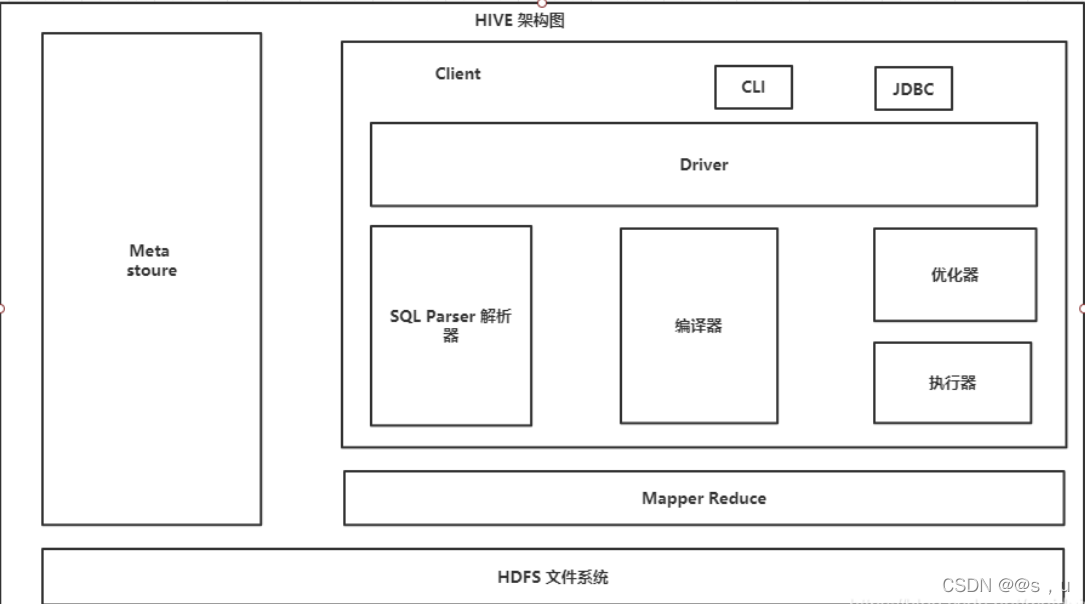
Hive中客戶端有這三種:CLI(命令列客戶端),HWI(網頁客戶端),和Thrift Server(編程客戶端),
在客戶端輸入的所有命令和查詢都會進入到Driver(驅動模塊)進行決議,編譯,優化和執行,
Driver包含SQL Paser, Physcial Plan, Query Optimizer,和Execution四個模塊,
SQL Parser是決議器,用于將SQL陳述句轉換為抽象語法樹,
Physical Plan 是編譯器,用于將抽象語法樹編譯生成邏輯計劃,
Query Optimizer 是優化器, 用于對邏輯執行計劃進行優化,
Execution 是執行器,用于把邏輯執行計劃轉換為可執行的MapReduce程式,
Meta Store(元資料存盤)是一個獨立的關系型資料庫(通常是MySql),Hive會在其中保存表模式和其他系統元資料,
Hive中的庫
Hive中資料庫的概念本質上僅僅是一個表的一個目錄或者命名空間,對于有很多組和用戶的大集群, 這是非常有用的, 因為這樣可以避免表命名沖突,
舉個栗子~ 創建一個庫,
CREATE DATABASE school;
如果資料庫school已經存在的話, 那么會拋出一個錯誤資訊, 使用以下陳述句可以避免這種情況!
CREATE DATABASE IF NOT EXISTS school;
可以使用以下命令查看HIve中所包含的資料庫;
SHOW DATABASES;
資料庫所以目錄位于屬性 hive.metastore.warehouse.dir 所指定的頂層目錄之后, 假設用戶使用的是這個屬性的默認配置, 也就是/usr/hive/warehouse, 那么當我們創建資料庫school的時候, HIve將會對應地創建一個目錄/usr/hive/warehouse/school.db, 這里請注意,資料庫的檔案目錄命是以.db結尾的,
USE 命令用于將某個資料庫設定用戶當前的作業資料庫, 和在文 件系統中切換作業目錄是一個概念;
USE school;
最后用戶可以洗掉資料庫:
DROP DATABASE IF EXITS school CASCADE;
IF EXISTS 子句是可選的,如果加了這個子句, 就可以避免因資料庫school不存在而拋出的警告資訊,
默認情況下,Hive是不允許洗掉一個包含有表的資料庫, 用戶要么先洗掉資料庫中的表再洗掉資料庫, 要么在洗掉 命令最后加上CASCADE關鍵字, CASCADE 關鍵字可以使Hive自行先洗掉資料庫中的表, 再洗掉資料庫,
Hive 中的表
Hive支持關系資料庫中的大多數進本資料型別,同時HIve還支持關系資料庫中的不常出現的3中集合資料型別,
| 資料型別 | 長度 | 例子 |
|---|---|---|
| TINYINT | 1byte有符號整數 | 10 |
| SMALINT | 2byte有符號整數 | 10 |
| INT | 4byte有符號整數 | 10 |
| BIGINT | 8byte有符號整數 | 10 |
| BOOLEAN | 布爾型別,true或者false | TRUE |
| FLOAT | 單精度浮點數 | 1.0 |
| DOUBLE | 雙精度浮點數 | 1.0 |
| STRING | 字串 | ”cat“ |
| TIMESTAMP | 日期,時間戳或者字串 | 132788或者’2020-5-12 13:30:2’ |
| ARRAY | 一組有序的欄位,型別必須相同 | Array(1,2) |
| MAP | 一組 無序的鍵值對 | Map(‘a’,1’b’,2) |
| STRUCT | 一組命名的欄位,欄位型別可以不同 | Struct(‘a’,1,1,0) |
行轉列,列轉行
行轉列:
CONCAT(string A/col, string B/col…)**:回傳輸入字串連接后的結果,支持任意個輸入字串;
CONCAT_WS(separator, str1, str2,...)**:它是一個特殊形式的 CONCAT(),第一個引數剩余引數間的分隔符,分隔符可以是與剩余引數一樣的字串,如果分隔符是 NULL,回傳值也將為 NULL,這個函式會跳過分隔符引數后的任何 NULL 和空字串,分隔符將被加到被連接的字串之間;
COLLECT_SET(col)**:函式只接受基本資料型別,它的主要作用是將某欄位的值進行去重匯總,產生array型別欄位,
列轉行:
EXPLODE(col):將hive一列中復雜的array或者map結構拆分成多行,
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
Rank函式
RANK() :值相同時,排序相同時會重復,總數不會變,比如,1,2,2,2,5
DENSE_RANK():值相同時,排序相同時會重復,總數會減少,比如,1,2,2,2,3
ROW_NUMBER() :值相同時,排序按照順序不重復,總數不變,比如,1,2,3,4,5,
PERCENT_RANK:百分比排序
UDF
UDF(User-Defined Functions)即是用戶定義HIve函式,當Hive自帶的函式不能滿足業務需求時,就需要我們的自定義函式了,
Hive中有3三種自定義函式:
UDF:操作單個資料行,產生單個資料行(一進一出)
UDAF:操作多個資料行,產生一個資料行(多進一出)
UDTF:操作一個資料行,產生多個資料行一個表作為輸出(一進一出)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385535.html
標籤:其他