文章目錄
- 前言
- 一. 摘要
- 二. 引言
- 2.1 本部分主要介紹
- 2.2 歸納偏置(inductive biases)
- 2.3 相關作業
- 2.3.1 簡要介紹
- 三. 方法 & 復現
- 3.1 圖片處理
- 3.1.1 復現(基于paddlepaddle框架)
- patch embedding
- attention layer
- VIT前向部分
- 3.2 FINE-TUNING AND HIGHER RESOLUTION:模型微調與高解析度影像處理
- 四. 實驗
- 總結與評價
前言
VIT模型,其開創性的作業是:使用了一種純粹的transformer結構,正如其論文名稱所示:AN IMAGE IS WORTH 16X16 WORDS,其將圖片經過embedding處理成一串sequence,經過多個encoder結構與head實作了能夠媲美CNN中SOTA模型的效果,

CNN已經統治各大影像任務榜許久,之前有時會認為CNN結構就是最優的結構,但是似乎近期的資料已經打了臉,為什么這樣說?paperwithcode的各大影像任務排行榜中(例如分割、檢測),基于transformer的模型已經占據各大排行榜榜首甚至前十,真實的資料擺在這里, 我們不禁要問:我們是不是要告別CNN時代了? 這里只是拋出一個疑問,也是編者自己的疑問,
我們這篇文章是分析VIT的,下面正式開始介紹VIT模型,
隨著transformer在各大nlp領域挑戰RNN,并且伴隨著BERT與GPT模型的發布,transformer在大規模的模型中表現出其優秀的下游任務的泛化能力和大規模資料下仍未飽和的“胃口”,慢慢的,CV領域也開始被注意,
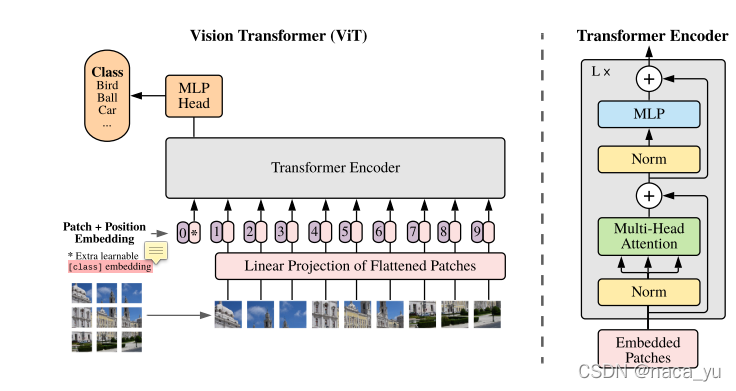
如圖所示,相信有過transformer學習經歷的朋友直接一眼就可以看出作者模型的架構,這個圖簡單易懂,VIT由將圖片進行patch embedding,也就是將圖片分成多個塊(patch),然后通過embedding,將每個patch展開為sequence序列,同時作者為了進行分類任務,引入了一個額外的class token,也就是輸入序列的0位置的向量,用作分類任務,HEAD由一個多頭注意力以及mlp層進行種類預測,整體結構簡單明了,讓人有一種如沐春風的感覺,
一. 摘要

作者先引出了注意力機制在nlp領域取得的成就,隨后出現了一些基于注意力機制與卷積的混合模型,而作者摒棄傳統的CNN結構,提出了一種基于純粹transformer的模型,在實驗方面,作者利用在大型資料集上訓練并遷移到中小尺度的資料集進行效果驗證,其性能能夠與當前的SOTA卷積網路模型相媲美,并且需要更少的算力(這里指的是2500天tpu v3的天數,足以見到作者的雄厚財力)
二. 引言
2.1 本部分主要介紹
- transformer在nlp領域的現狀,解釋了為什么它能夠在最近的論文中統治nlp領域,也就是它的優點
- 在影像領域transformer的應用現狀,存在仍帶有影像的偏置假設,并且難以在現代gpu上加速的問題,引出作者的作業,也就是動機,也算是說明了作者要解決的問題:hybrid結構并不能在cv中勝過全cnn結構,或者說作者想嘗試一下純粹的transformer結構能夠在視覺任務中表現出比VNN更好的效果,
- 介紹了作者提出的結構特點,提出并解決了實驗程序中的重要問題,即在同等資料集下,VIT的表現總是比CNN結構性能要低一些(如下面英文簡摘所示),在最后,作者展示了自己模型的絕佳表現,
When pre-trained on the public ImageNet-21k dataset or the in-house JFT-300M dataset, ViT
approaches or beats state of the art on multiple image recognition benchmarks. In particular,
the best model reaches the accuracy of 88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55%
on CIFAR-100, and 77.63% on the VTAB suite of 19 tasks.
2.2 歸納偏置(inductive biases)
作者在文章中,多次提到了歸納偏置,其實也就是在說卷積,在傳統卷積中,我們引入了兩個假設,也就是引入了先驗:
- 平移不變性:訓練出來的卷積核在面對同樣的圖片時,表現或者生成的特征圖是相似的,或者說只對圖片中某種東西感興趣,
- 區域性相關性:卷積核在滑動的程序中,相鄰的兩個生成像素點之間因為權值共享的原因,是相關的,
引入以上兩點假設,我們人為的給模型帶來了先驗知識,因此,作者為了去除這種人為的假設,另一種觀點,為了彌補transformer去除歸納偏置帶來的性能下降,作者增加大量的訓練資料去彌補,其實就是用更多的資料學習這兩種歸納偏置,是否有種撿了西瓜丟了芝麻之意,這里見仁見智,作者本身是給我們帶來另一種思考的方式,
2.3 相關作業
記住了沐神課堂上一句話:
相關作業這邊寫的很多,并不會讓你的作業顯得非常少和簡單,反而會讓你的論文更加簡單易懂,
2.3.1 簡要介紹
-
先寫transformer在nlp領域的最新進展,然后提出了transformer在影像領域的相關作業及問題:例如將影像按照像素大小直接展開時帶來的計算災難,區域注意力機制,sparse transformer,或者只對單個坐標軸的像素采取注意力等方法,但是這些方法都存在一個問題,難以運用于現代gpu上,因為其預處理步驟太過于繁瑣,作者所求,即是簡介,
-
提出與自己最相近的相關作業并進行對比:一是前人提出的patch size過小,因此只能應用于小解析度的影像,二是作者在大型資料集上做預訓練,使其能夠達到SOTA的效果,
-
寫出了另一種思路:hybrid mathod,DETR就是將resnet作為backbone,將特征圖作為輸入序列,
-
寫出最近的一些進展:iGPT,
最后作者分析大型的資料集而不是像standard ImageNet dataset這種標準的資料集,對于模型訓練的作用,作者舉出了一些目前對于cnn在不同尺度的資料集下的性能表現,
總結來說,作者分析了為什么要提出這種純粹transformer的結構的原因,另一方面,給出了目前視覺transformer受bert影響而誕生的igpt,最后說明了大型的資料集對于模型性能的重要作用,
三. 方法 & 復現
3.1 圖片處理

第一步:原始輸入圖片為(H, W, C)大小,首先將其進行分割,假設分割成P大小的正方形塊:
第二步:N為分割的塊數,也是patch的數量,將圖片進行展平,也就是展成2Dpatch,N 個 P2 * C大小的patch,
第三步:加入位置向量和class token向量,其中位置向量是可學習的引數,
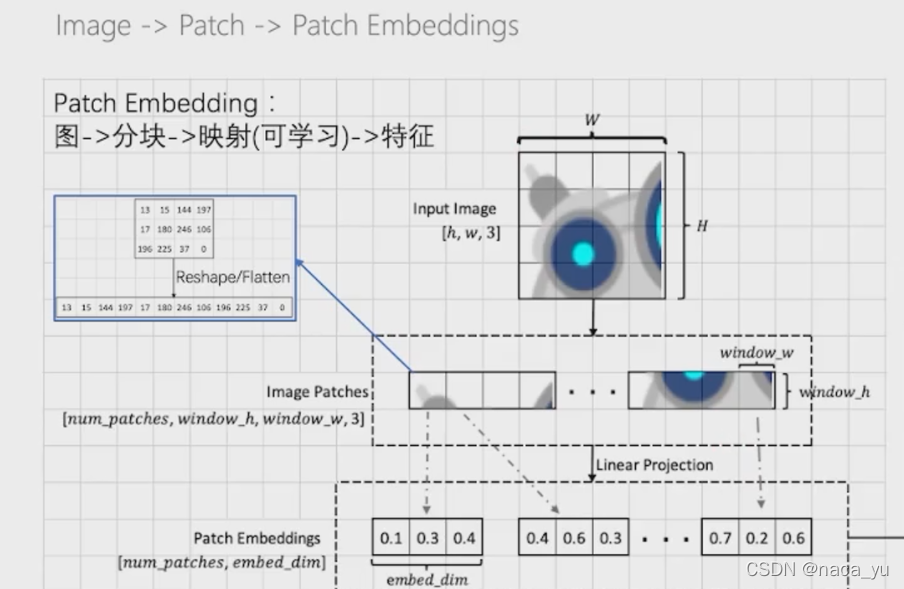
3.1.1 復現(基于paddlepaddle框架)
patch embedding
#patch embedding流程
class PatchEmbedding(nn.Layer):
def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.):
super().__init__()
self.embed_dim = embed_dim
n_patches = (image_size // patch_size) * (image_size // patch_size)
self.patch_embedding = nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
# TODO: add class token
self.class_token = paddle.create_parameter(#這里加入可學習的class token向量作為分類等下游任務使用
shape = [1, 1, embed_dim],
dtype = 'float32',
default_initializer = nn.initializer.Constant(0.),
)
# TODO: add position embedding
self.position_embedding = paddle.create_parameter(#加入可學習的位置向量
shape = [1, n_patches + 1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02)
)
def forward(self, x):
# [n, c, h, w] 原始圖片大小:每個batch中含有n張圖片,每張為h * w * c
class_token = self.class_token.expand([x.shape[0], 1, self.embed_dim])#由于輸入的圖片大小是不固定的,所以用expand
#這里進行圖片的分割,用卷積達到類似的效果,當stride=kernel_size的時候,生成的就是patch
x = self.patch_embedding(x)
x = x.flatten(2)
x = x.transpose([0, 2, 1])
x = paddle.concat([class_token, x], axis=1)
#加位置向量
x = x + self.position_embedding
return x
完成了上一段,就完成了對圖片的編碼,至此,我們可以將回傳的tensor輸入到attention layer中計算,
attention layer
這一段,我們主要復現attention的部分:
#attention部分,將上一段代碼回傳的patch embedding輸入到attention layer中
class Attention(nn.Layer):
"""multi-head self attention"""
def __init__(self, embed_dim, num_heads, qkv_bias=True, dropout=0., attention_dropout=0.):
super().__init__()
self.num_heads = num_heads
self.head_dim = int(embed_dim / num_heads)#計算頭數
self.all_head_dim = self.head_dim * num_heads
self.scales = self.head_dim ** -0.5#計算縮放因子,也就是根號下dk
#qkv初始化
self.qkv = nn.Linear(embed_dim,
self.all_head_dim * 3,
bias_attr=False if qkv_bias is True else None
)
#這里的linear層主要是起到mlp最后輸出的作用
self.proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
self.attention_dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(axis=-1)
def transpose_multihead(self, x):#這個函式將x轉化為需要的格式
# x: [N, num_patches, all_head_dim] -> [N, n_heads, num_patches, head_dim]
new_shape = x.shape[:-1] + [self.num_heads, self.head_dim]
x = x.reshape(new_shape)
x = x.transpose([0, 2, 1, 3])
return x
def forward(self, x):
# TODO
B, N, _ = x.shape
qkv = self.qkv(x).chunk(3, -1)
q, k, v = map(self.transpose_multihead, qkv)
atten = paddle.matmul(q, k, transpose_y = True)#計算注意力
atten = atten * self.scales#尺度縮放
atten = self.softmax(atten)
out = paddle.matmul(atten, v)#注意力矩陣計算
out = out.transpose([0, 2, 1, 3])
out = out.reshape([B, N, -1])
#out:[b, n, num_heads * head_dim]
out = self.proj(out)
return out
VIT前向部分
class ViT(nn.Layer):
def __init__(self):
super().__init__()
self.patch_embed = PatchEmbedding(224, 7, 3, 16)
layer_list = [EncoderLayer(16) for i in range(5)]#stack五層的encoder,每個的輸入維度(embedding)大小是16
self.encoders = nn.LayerList(layer_list)
self.head = nn.Linear(16, 10)#這里是分類層,輸入為16維度,輸出10維,即一共分為十類
self.avgpool = nn.AdaptiveAvgPool1D(1)#這里是1維的average pool,就是為了把所有的patch輸出取平均進行分類
def forward(self, x):
x = self.patch_embed(x) # [n, h*w, c]: 4, 1024, 16
for encoder in self.encoders:
x = encoder(x)#多個encoder疊加
# avg
x = x.transpose([0, 2, 1])#轉置[n, h * w, c] 轉為[n, c, h * w]
x = self.avgpool(x)#[n, c, 1]
x = x.flatten(1)#[n*c],也就是[16, 1]
x = self.head(x)
return x
綜上,完成了從圖片的patch embedding到最后的分類結果預測的前向結構復現,
3.2 FINE-TUNING AND HIGHER RESOLUTION:模型微調與高解析度影像處理
這一部分名字叫:微調與高解析度,很適合作者所做出的成果,一方面,作者在大資料集上進行預訓練并遷移到小資料集達到了benchmark上的sota效果,另一方面,作者還通過調整patch大小(大于前人所用的2×2),來達到消耗較少的計算資源情況下處理高解析度的影像,

作者提到,如果將VIT訓練好的模型應用于下游任務,只需要將預測的HEAD頭去掉,然后將VIT后面連接一個D*K的零初始化的前向預測層(D是層數,K是下游任務的類別數量),就可以實作下游任務,同時,VIT能夠處理任意長度的序列,序列的長度受到patch大小和記憶體的限制(patch會暫時放到記憶體中計算),但是變長會導致預訓練好的位置編碼無效,需要重新訓練,
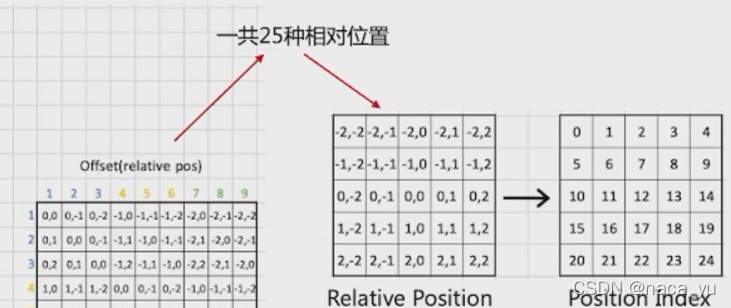
作者比對了位置編碼1D與2D編碼(如下圖)的異同,通過比較,作者并沒有發現兩種編碼方式所帶來的性能差異較大,同時作者認為2D編碼會引入影像的歸納偏置問題,背離了作者想摒棄歸納偏置的初衷,
四. 實驗

作者與ResNet為代表的純卷積方法與 Hybrid(混合模型) 做了性能對比實驗,同時作者為了說明每種模型對于資料量的需求程度,將其在不同大小的資料集上進行訓練并遷移到不同benchmark驗證效果,事實證明,其以更低的預訓練花費達到了SOTA效果,作者也對自監督式的訓練表現出了期望,
以下為作者設計的三種不同大小的模型,其規模大小和引數大小設定了不同的尺度,
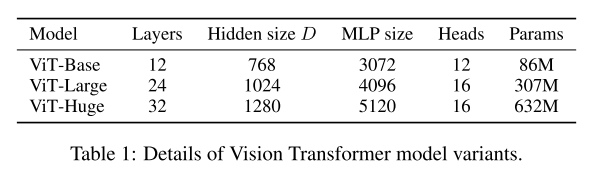
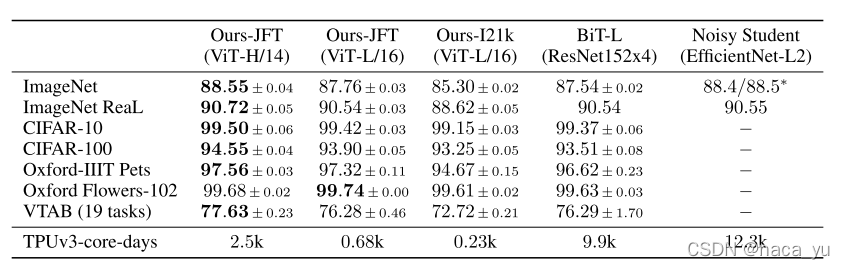
可以看到,在VIT-HUGE版本上,在imagenet作為benchmark中,作者的模型性能超過了ResNet一個多百分點,而需要訓練的天數也低于resnet的9.9k,
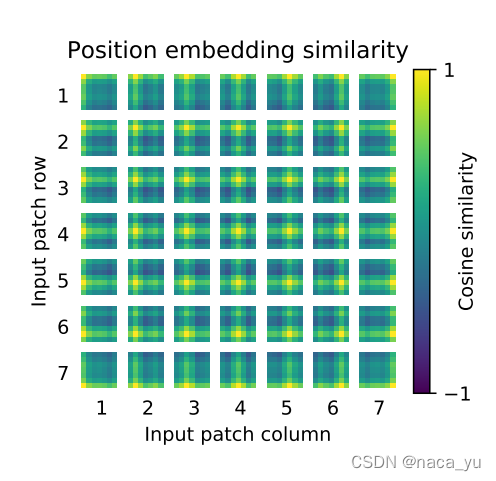
下圖是作者為了更加方便理解VIT內部對于影像的處理機制,進行了可視化輸出,

下圖是作者將學習后的位置編碼可視化后的結果(選取了前28個主成分),影像顯示,相鄰位置的位置編碼相似程度更高,
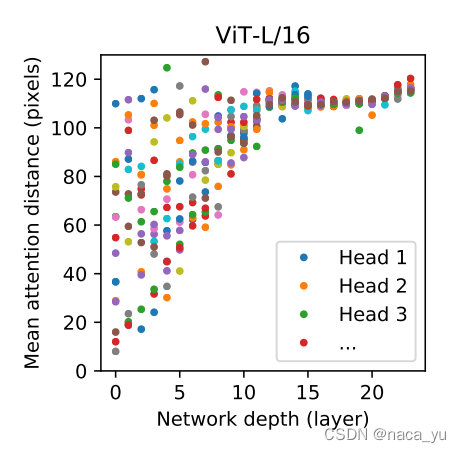
同時,實驗顯示,如下圖所示,越深的層,多頭注意力的head對于全域的注意力范圍越遠,這其實就像cnn,越深的層數,對于特征的抽象程度越高,能看到范圍更大的特征,感受野越大,
總結與評價
整體來說,作者提出的transformer在對視覺transformer的貢獻上已經可以說是起到了一個里程碑的作用,后面很多的提出的用于各類下游任務的模型都是基于這個結構,
但是模型結構仍然存在以下幾點問題:一是由于對影像分塊進行檢測,雖然降低了計算消耗,提高了對高解析度影像的處理能力,但是對于小目標檢測卻較為乏力,這一點在后面的swin transformer提出了有了改進,二是以及訓練資料以及算力要求過高的問題,這一點同樣在DEIT中進行了改進,
但是這里就像alexnet提出時一樣,任何新提出的革命性模型,都要經過提出 - 發現問題 - 改進完善的程序,就像最近占據榜首的swin transformer等,都是在此基礎上進行打補丁等的操作,
作者的貢獻具體來說主要分為兩點:
1.作者相對前面基于視覺transformer的模型,引入patch,避免了引入卷積帶來的的歸納偏置,加入了可學習的影像位置編碼,
2.作者證明了VIT在大型資料集訓練后遷移到小資料集上的可行性,并可以媲美SOTA的CNN結構,
同時作者做出了展望:
1.下游任務:分割,檢測等能夠進一步展開,
2.對自監督預訓練方法的探索,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385594.html
標籤:其他
上一篇:CSP-J 2021解題報告