如何保證訊息佇列高可用
首先MQ會導致系統可用性降低,所以只要你用了MQ,那就一定有缺點了
RabbitMQ的高可用性
RabbitMQ是比較有代表性的,因為是基于主從(非分布式)做高可用的,我們就以RabbitMQ為例子講解第一種MQ的高可用是怎么實作
RabbitMQ有三種模式:單機,普通集群,鏡像集群
單機模式
單機模式,玩具罷了
普通集群模式(沒有高可用性)
普通集群模式,意思就是在多臺機器上啟動多個RabbitMQ實體,每個機器啟動一個,你創建的queue,只會放在一個RabbitMQ實體上,但是每個實體都同步queue的元資料(元資料可以認為是queue的一些配置資訊,通過元資料,可以找到queue所在實體),你消費的時候,實際上如果連接到了另外一個實體,那么那個實體會從queue所在實體上拉取資料
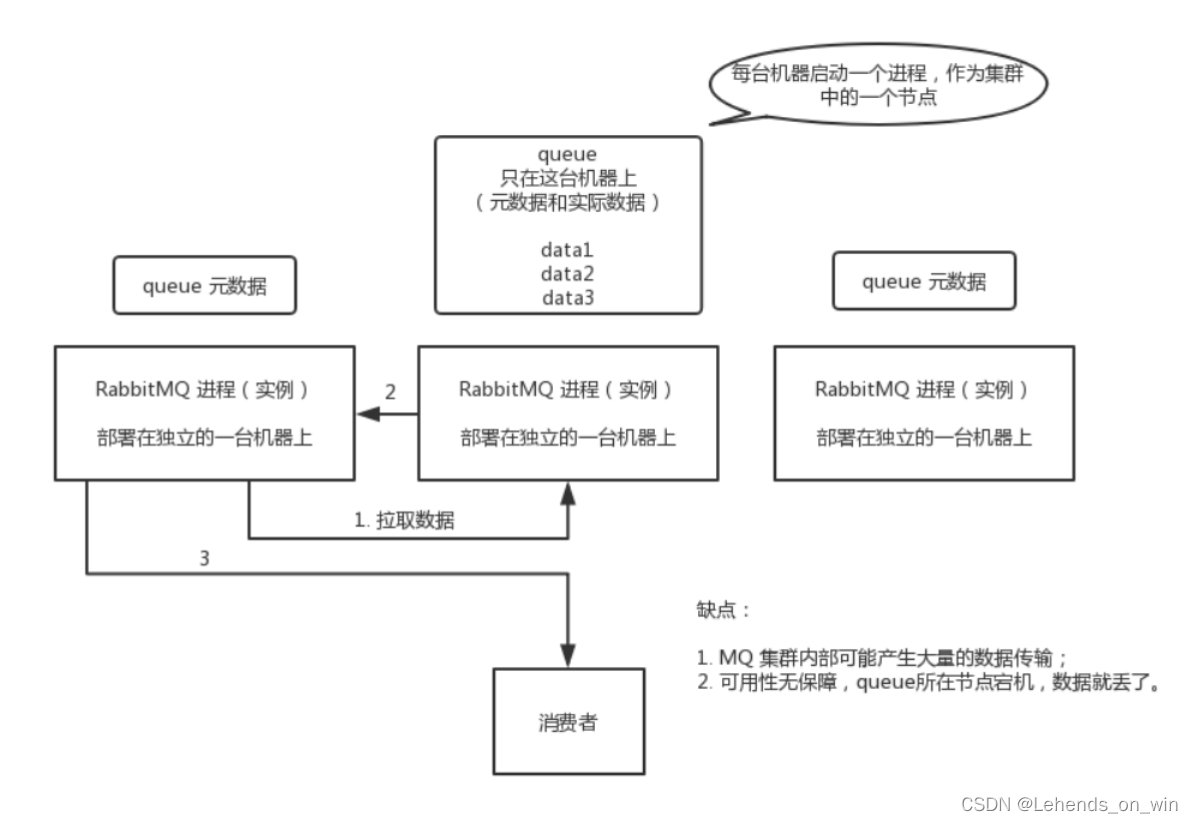
這種方式確實很麻煩,也不怎么好,沒做到所謂的分布式,就是個普通集群,因為這導致消費者每次隨機連接一個實體然后拉取資料,要么固定連接那個queue所在實體消費資料,前者有資料拉取的開銷,后者導致單實體性能瓶頸
這就很尷尬了,沒有所謂的高可用性,這方案主要是提高吞吐量的
鏡像集群模式(高可用性)
這種模式,才是所謂的RabbitMQ的高可用模式,就是raft嘛,每個RabbitMQ節點都有這個queue的一個完整鏡像,包含queue的全部資料的意思,然后每次你寫訊息到queue的時候,都會自動把訊息同步到多個實體的queue上,
- 好處:任何一個機器宕機了,沒事兒,其他機器(節點)還包含了這個queue的完整資料,別的consumer都可以到其他節點上去消費資料
- 壞處:
- 性能開銷太大了,訊息需要同步到所有機器上,導致網路帶寬壓力和消耗很重!
- 不是分布式的,就沒有擴展性可言了
kafka的高可用性
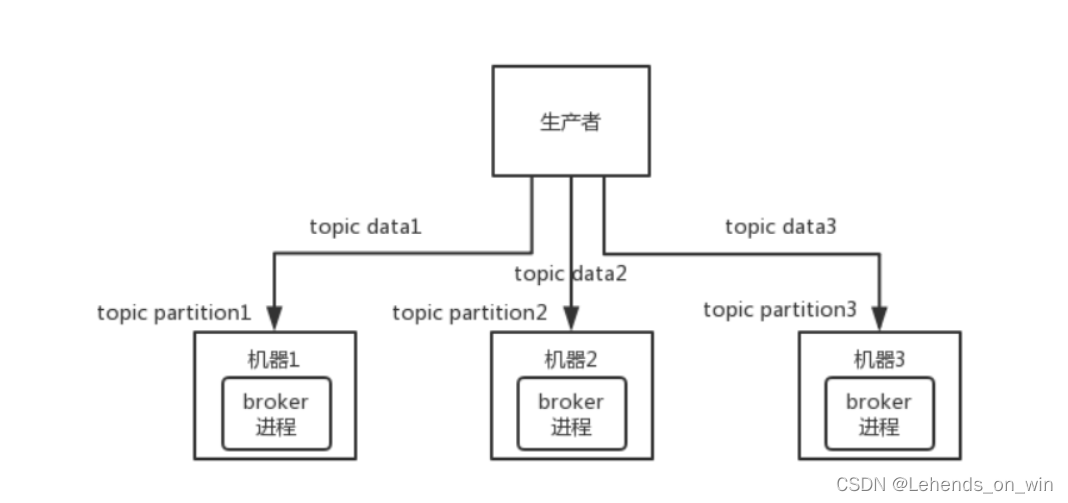
kafka一個最基本的架構認識:由多個broker組成,每個broker是一個節點,你創建一個topic,這個topic可以劃分為多個partition,每個partition可以存在于不同的broker上,每個partition就放一部分資料
這就是天然的分布式訊息佇列,就是說一個topic的資料,是分散在多個機器上的,每個機器就放一部分資料
實際上RabbitMQ之類的,并不是分布式訊息佇列,只不過提供一些集群,HA(High Availability,高可用)機制
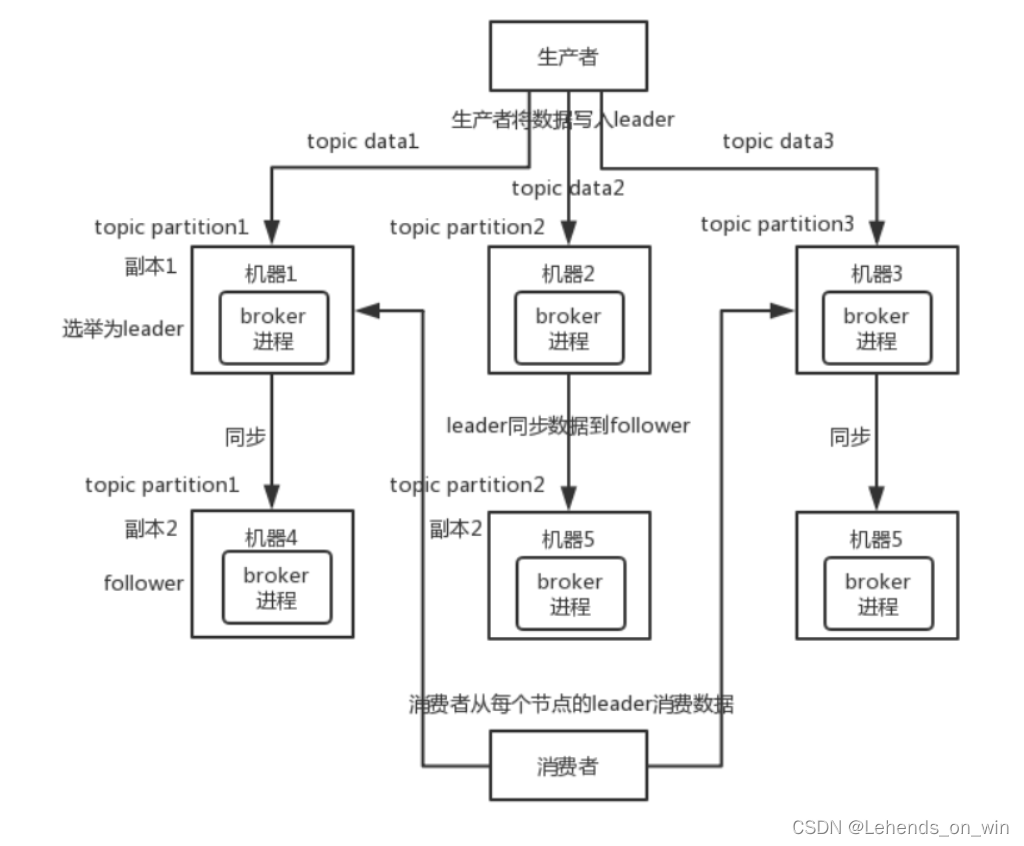
kafka 0.8之前,是沒有HA機制的,就是任何一個broker宕機了,那個broker上的partition就廢了,沒法讀也沒法寫
kafka 0.8以后,提供了HA機制,就是replica(復制品)副本機制,每個partition的資料都會同步到其他機器上,形成自己的多個replica副本,所有replica會選舉一個leader出來,那么生產和消費都跟這個leader打交道,然后其他replica就是follower,寫的時候,leader會負責把資料同步到所有follower上去,讀的時候就直接讀leader上的資料
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/386512.html
標籤:其他
上一篇:Flume基礎概念及其環境配置
下一篇:CentOS7安裝的ZooKeeper 啟動時一直報: Starting zookeeper … FAILED TO START