清覽作業
- 作業00
- 作業01
- 作業02
- 作業03
- 作業04
- 作業05
- 作業06
- 作業07
- 作業08
作業00
-
人們通常最熟悉結構化資料的分析,除了半結構化、“準”結構化和非結構化這三種基本資料型別以外,還有一種重要的資料型別為元資料,它主要由( ),能夠添加到資料集中,
A.人工輸入
B.機器生成
C.自然產生
D.分析計算
-
資料多樣性指的是大資料解決方案需要支持多種( )、不同型別的資料,資料多樣性給企業帶來的挑戰包括資料聚合、資料交換、資料處理和資料存盤等,
A.不同大小
B.不同方向
C.不同格式
D.不同語言
-
( )、傳感器和資料采集技術的快速發展、通過云和虛擬化存盤設施增加的資訊鏈路,以及創新軟體和分析工具,正在驅動著大資料,
A.廉價的存盤
B.昂貴的存盤
C.小而精的存盤
D.昂貴且精準的存盤
-
實際上,大多數的大資料都是( )的,
A.結構化
B.非結構化
C.非或半結構化
D.半結構化
-
所謂大資料,狹義上可以定義為( ),
A.用現有的一般技術難以管理的大量資料的集合
B.隨著互聯網的發展,在我們身邊產生的大量資料
C.隨著硬體和軟體技術的發展,資料的存盤、處理成本大幅下降,從而促進資料大量產生
D.隨著云計算的興起而產生的大量資料
-
所謂“用現有的一般技術難以管理”,例如是指( ),
A.用目前在企業資料庫占據主流地位的關系型資料庫無法進行管理、具有復雜結構的資料
B.由于資料量的增大,導致對非結構化資料的查詢產生了資料丟失
C.分布式處理系統無法承擔如此巨大的資料量
D.資料太少無法適應現有的資料庫處理條件
-
大資料的定義是一個被故意設計成主觀性的定義,即并不定義大于一個特定數字的TB才叫大資料,隨著技術的不斷發展,符合大資料標準的資料集容量( ),
A.穩定不變
B.略有精簡
C.也會增長
D.大幅壓縮
-
可以用3個特征相結合來定義大資料:即( ),
A.數量、數值和速度
B.龐大容量、極快速度和多樣豐富的資料
C.數量、速度和價值
D.豐富的資料、極快的速度、極大的能量
-
隨著計算機技術全面和深度地融入社會生活,資訊爆炸不僅使世界充斥著比以往更多的資訊,而且其增長速度也在加快,資訊總量的變化導致了( )——量變引起了質變,( ),
A.資料庫的出現
B.資訊形態的變化
C.網路技術的發展
D.軟體開發技術的進步
-
下列( )不是預測分析的主要作用,
A.決策管理
B.滾動預測
C.成本計算
D.自適應管理
-
定量分析專注于量化從資料中發現的模式和關聯,這項技術涉及分析大量從資料集中所得的觀測結果,其結果是( )的,
A.相對字符型
B.相對數值型
C.絕對字符型
D.絕對數值型
-
大資料分析結合了( ),
A.傳統統計分析方法和現代統計分析方法
B.傳統統計分析方法和計算分析方法
C.現代統計方法和計算分析方法
D.傳統計算分析方法和現代計算分析方法
-
資料分析學涵蓋了對整個資料生命周期的管理,而資料生命周期包含了資料收集、( )、資料組織、資料分析、資料存盤以及資料管理等程序,
A.資料完善
B.資料清理
C.資料編輯
D.資料增減
-
資料分析是一個通過處理資料,從資料中發現一些深層知識、模式、關系或是趨勢的程序,資料分析的總體目標是( ),
A.做出唯一決策
B.做出最好決策
C.做出更好決策
D.產生完整的資料集
-
預測分析模型不僅要靠基本人口資料,例如住址、性別等,而且也要涵蓋近期性、頻率、購買行為、經濟行為以及電話和上網等產品使用習慣之類的( )變數,
A.行為預測
B.生活預測
C.經濟預測
D.動作預測
作業01
-
大資料分析結果可以用來為商業使用者提供商業決策支持,為使用者提供更多使用這些分析結果的機會,分析結果的使用階段致力于確定( )分析資料能保證產出更大的價值,
A.如何以及在哪里處理
B.怎樣以及什么時候
C.是否以及怎樣
D.如何列印以及存盤
-
資料聚合和表示階段是專門為了將( )進行聚合,從而獲得一個統一的視圖,
A.關鍵資料集
B.離散資料
C.單個資料集
D.多個資料集
-
資料分析階段致力于執行實際的分析任務,通常會涉及一種或多種型別的資料分析,在這個階段,尤其是在探索性分析的情況下,分析程序會( ),
A.重復進行,直到資料被清零
B.回圈進行,直到人為終止
C.自然迭代,直到適當的模式或者相關性被發現
D.一次完成,分析結果被列印和存盤
-
資料可視化階段致力于由使用者使用( )技術和工具,并通過圖形表示有效的分析結果,
A.圖形設計
B.資料可視化
C.Photoshop
D.數字媒體
-
資料標識階段主要是用來標識分析專案所需要的資料集和所需的資源,標識種類眾多的資料資源可能會提高找到( )的可能性,
A.資料獲取和資料列印
B.演算法分析和列印模式
C.隱藏模式和相互關系
D.隱藏價值和潛在商機
-
資料提取階段主要是要提取不同的資料,并將其轉化為大資料解決方案中可用于( )的格式,需要提取和轉化的程度取決于分析的型別和大資料解決方案的能力,
A.資料分析
B.列印輸出
C.資料存盤
D.資料整合
-
大資料分析的生命周期可以分為九個階段,但以下( )不是其中的階段之一,
A.商業案例評估
B.數值計算
C.資料獲取與過濾
D.資料提取
-
大資料分析的生命周期可以分為九個階段,但以下( )不是其中的階段之一,
A.資料標識
B.資料驗證與清理
C.分析結果的使用
D.資料列印
-
大資料分析的生命周期中,在資料( )程序中有許多的步驟,這些都是在資料分析之前所必需的,
A.識別、獲取、過濾、提取、清理和聚合
B.列印、計算、過濾、提取、清理和聚合
C.統計、計算、過濾、存盤、清理和聚合
D.存盤、提取、統計、計算、分析和列印
-
經過數十年發展,分析架構經歷了從獨立的桌面到企業級( )的一個實質性轉變,
A.資料倉庫再到大資料平臺
B.大資料平臺到資料倉庫
C.大資料平臺到資料挖掘
D.資料挖掘到資料倉庫
-
持續改善,即在生產活動中不斷提高,其核心不包括( ),
A.增加產量,團結員工
B.從小處人手
C.去除過于復雜的作業
D.進行實驗以確定和消除無用之處
-
精明的企業可以通過逆向思維找到( )分析機遇,解決那些在過去看來不可能解決的問題,
A.現成的
B.不存在的
C.潛在的
D.丟失的
-
一個基于九項核心原則的方法成為建立現代分析方法的基礎,但下列( )不是這些原則之一,
A.實作商業價值和影響
B.專注于最后一公里
C.加速學習能力和執行力
D.標準化統一分析
-
在大資料分析商業案例的評估中,如果關鍵績效指標不容易獲取,則需要努力使這個分析專案變得SMART,即( ),
A.實際的、大膽的、有價值的、可分析的
B.有風險的、有機會的、能實作的和有價值的
C.具體的、可衡量的、可實作的、相關的和及時的
D.有理想的、有價值的、有前途的和能實作的
-
大資料分析的生命周期可以分為九個階段,但以下( )不是其中的階段之一,
A.資料刪減
B.資料聚合與表示
C.資料分析
D.資料可視化
作業02
-
在某些情況下,分析師將從文本中提取出的特性補充到預測模型中,稱之為( )問題,
A.檔案分析
B.資料分析
C.文本挖掘
D.數值分析
-
( )和預報包括廣泛應用于企業的一類獨特分析,并且往往嵌入到企業系統中,用于管理制造、物流、門店運營等,
A.時間序列分析
B.業務增長預測
C.蒙特卡洛分析
D.線性增長估算
-
所謂“( )”,泛指由一個指標的變化導致的其他指標的系統性變化,
A.預測
B.解釋
C.預報
D.模擬
-
為建立一個完美的模型,更大的分析資料集為分析師帶來了新的機會和問題,但下列( )是錯誤的,
A.更多的用例、更多的觀察結果、更多的資料行
B.更多的變數、更多的特性、更多的資料列
C.更好的演算法和結構
D.許多小模型
-
構建( )是分析中的經典用例,它是許多常見應用的基礎,
A.預測模型
B.資料模型
C.資料結構
D.程式模塊
-
一個用例是實作一個目標所需步驟的描述,而分析用例是那些需要定義( )的組織所需要的關鍵成功要素之一,
A.程式模板
B.資料結構
C.分析架構
D.物件實體
-
用例分析描述了分析師解決的通用問題和用于解決這些問題的方法和技術,( )可以解決所有分析問題,
A.有一些技術
B.沒有任何一種技術
C.多數現有的技術都
D.不清楚是否有技術
-
為中層管理者需求服務的分析應用專注于( )功能問題,
A.重要的
B.具體的
C.現實的
D.嚴重的
-
基于獨立性、可信性、過往成就的紀錄、緊迫性和( ),企業傾向于更多地依賴外部顧問進行戰略分析,
A.內部資料
B.核心資料
C.外部資料
D.重要資料
-
面向客戶的分析,是指標對( )的分析,
A.業務伙伴
B.企業中層
C.產品下游
D.最終消費者
作業03
-
時間序列圖可以分析在固定時間間隔記錄的資料,它通常用( )圖表示,x軸表示時間,y軸記錄資料值,
A.圓餅
B.折線
C.熱區
D.直方
-
在視覺分析中,網路分析是一種側重于分析網路內物體關系的技術,一個網路圖描繪互相連接的( ),它可以是一個人,一個團體,或者其他商業領域的物品,例如產品,
A.物體
B.人體
C.物體
D.虛體
-
視覺分析是一種資料分析,指的是對資料進行( )來開啟或增強視覺感知,相比于文本,人類可以迅速理解影像并得出結論,因此,視覺分析成為大資料領域的勘探工具,
A.數值計算
B.文化虛擬
C.圖形表示
D.字符表示
-
文本分析是專門通過資料挖掘、機器學習和自然語言處理技術去發掘( )文本價值的分析應用,文本分析實質上提供了發現,而不僅僅是搜索文本的能力,
A.自然語言
B.非結構化
C.結構化
D.字符與數值
-
深度學習是一類基于( )的建模訓練技術,
A.資料結構
B.資料規模
C.特征學習
D.模塊層次
-
過濾是自動從專案池中尋找有關專案的程序,專案可以基于用戶行為或通過匹配多個用戶的行為被過濾,通常過濾的主要方法是( ),
A.完全過濾和不完全過濾
B.數值過濾和字符過濾
C.自動過濾和手動過濾
D.協同過濾和內容過濾
-
聚類常用在( )上來理解一個給定資料集的性質,在形成理解之后,分類可以被用來更好地預測相似但卻是全新或未見過的資料,
A.自動計算
B.程式設計
C.資料挖掘
D.數值分析
-
聚類是一種( )的學習技術,通過這項技術,資料被分割成不同的組,每組中的資料有相似的性質,類別是基于分組資料產生的,資料如何成組取決于用什么型別的演算法,
A.手工處理
B.有控制
C.有監督
D.無監督
-
人類善于發現資料中的( ),但不能快速地處理大量的資料,另一方面,機器非常善于迅速處理大量資料,但它們得知道怎么做,如果人類知識可以和機器的處理速度相結合,機器可以處理大量資料而不需要人類干涉,這就是機器學習的基本概念,
A.大小與數量
B.模式與規律
C.模式與關系
D.數量與關系
-
分類是一種( )的機器學習,它將資料分為相關的、以前學習過的類別,這項技術的常見應用是過濾垃圾郵件,
A.完全自動
B.有監督
C.無監督
D.無需控制
-
“無監督學習”指的是那些在( )資料或者缺乏定義因變數的資料中尋找模式的技術,
A.結構化
B.無標簽
C.非結構化
D.有標簽
-
回歸性分析技術旨在探尋在一個資料集內一個( )有著怎樣的關系,
A.外部變數和內部變數
B.小資料變數和大資料變數
C.組織變數和社會變數
D.因變數與自變數
-
在大資料分析中,( )分析可以首先讓用戶發現關系的存在,( )分析可以用于進一步探索關系并且基于自變數的值來預測因變數的值,
A.相關性,回歸性
B.回歸性,相關性
C.相關性,復雜性
D.復雜性,回歸性
-
相關性分析是一種用來確定( )的技術,如果發現它們有關,下一步是確定它們之間是什么關系,
A.兩個變數是否相互獨立
B.兩個變數是否互相有關系
C.多個資料集是否相互獨立
D.多個資料集是否相互有關系
-
統計分析就是用以( )為手段的統計方法來分析資料,
A.計算函式
B.數學公式
C.資料結構
D.程式結構
-
( )是希望通過變換消除原始特征之間的相關關系或減少冗余,得到新的特征,更加便于資料的分析,
A.特征選擇
B.特征運算
C.特征加工
D.特征變換
-
特征工程包含( )、特征選擇、特征構建和特征學習等問題,
A.結構重組
B.特征提取
C.結構簡化
D.資料清洗
-
( )是大資料分析的原材料,對最終模型有著決定性的影響,
A.資料
B.特征
C.資源
D.資訊
-
解決大資料分析問題的一個重要思路就在于減少資料量,可以通過減少描述資料的屬性來達到目的,這就是( )技術,
A.降維
B.減法
C.復合
D.審計
-
一般來說,隨著預測視窗長度的延長,模型預測的精確性會( ),
A.上升
B.反彈
C.下降
D.不確定
-
預測視窗對分析專案的設計有很大影響,它會影響到( ),
A.系統規模的設定
B.系統質量的要求
C.啟動時間的設定
D.分析方法的選擇和資料的選擇
-
預測分析使用的技術可以發現( )之間的關系,從而預測未來的事件和行為,
A.歷史資料
B.原始資料
C.當前資料
D.資料模型
-
在某些情況下,分析師將從文本中提取出的特性補充到預測模型中,稱之為( )問題,
A.檔案分析
B.資料分析
C.文本挖掘
D.數值分析
-
( )和預報包括廣泛應用于企業的一類獨特分析,并且往往嵌入到企業系統中,用于管理制造、物流、門店運營等,
A.時間序列分析
B.業務增長預測
C.蒙特卡洛分析
D.線性增長估算
-
為建立一個完美的模型,更大的分析資料集為分析師帶來了新的機會和問題,但下列( )是錯誤的,
A.更多的用例、更多的觀察結果、更多的資料行
B.更多的變數、更多的特性、更多的資料列
C.更好的演算法和結構
D.許多小模型
作業04
-
( )分析用戶興趣,在用戶群中找到指定用戶的相似(興趣)用戶,綜合這些相似用戶對某一資訊的評價,形成對指定用戶對此資訊的喜好程度預測,
A.協同過濾推薦
B.關聯分析推薦
C.基于內容推薦
D.基于平臺推薦
-
數學圖是用來描述系統(如分布式計算機網路)、交通網路,或者一個網站頁面的一個有用的比喻,當使用一個數學圖來建立社會體系模型時,其結果是( )圖,
A.程式流程
B.社交網路
C.網路分析
D.關系鏈接
-
“基于( )的推薦”以規則為基礎,把已購商品作為規則頭,把推薦物件作為規則體,
A.運算規則
B.計算方法
C.分析原理
D.關聯規則
-
采用( )方法,可以通過用戶之間的聯系和用戶之間的相似度來判別用戶之間的關系強度,
A.有監督模型
B.無監督模型
C.強監督網路
D.弱監督網路
-
社交網路的重要成分是物體和( )的關系,因此可以用圖來為社交網路建模,
A.物體間
B.虛體
C.虛體間
D.物體間
-
( )是為一個客戶單獨使用而構建的,因而提供對資料、安全性和服務質量的最有效控制,
A.公有云
B.私有云
C.應用云
D.計算云
-
云計算是基于( )概念的分布式計算,最終用戶只需把任務提交到云端,
A.資料包
B.資訊包
C.檔案夾
D.資源池
-
Apache Spark是一個( )平臺,它可用于基于Hadoop的分布式記憶體高級分析,
A.開源
B.集成
C.商用
D.封閉
-
并行計算的主要效益在于速度和( )可擴展性,
A.可擴展性
B.大容量
C.多樣性
D.高利潤
-
分布式計算是指將行程處理分布于多個( )機器上的能力,
A.超級
B.物理或虛擬
C.計算
D.數字
-
所謂多執行緒處理,是指從軟體或者硬體上實作多個執行緒( )執行(當具備相關資源時)的技術,
A.順序
B.互斥
C.并發
D.合并
-
在一個程式中獨立運行的程式( )叫作“執行緒”,
A.片段
B.代碼
C.模塊
D.機器碼
-
“并行計算”是指:將一個任務分為( )的單元,并將其同時執行的方式,
A.更大
B.獨立
C.完整
D.更小
-
在大資料分析中有很多分析平臺可供選擇,但下列( )選項不是,
A.資料庫分析
B.硬碟分析
C.記憶體分析
D.云計算分析
-
資料是分析的原材料,而分析決定了( )的價值,
A.資料
B.程式
C.系統
D.電腦
-
客觀事物或現象是一個多因素綜合體,模型是被研究物件(客觀事物或現象)的一種抽象,( )是對客觀事物或現象的一種描述,
A.作業日程
B.資料結構
C.分析模型
D.計算方法
-
( )反映物件最本質的東西,略去了枝節,是被研究物件實質性的描述和某種程度的簡化,其目的在便于分析研究,模型可以是數學模型或物理模型,
A.模型
B.結構
C.函式
D.模塊
-
如果兩個或多個變數之間存在一定的( ),那么其中一個變數的狀態就能通過其他變數進行預測,
A.結合
B.沖突
C.變化
D.關聯
-
回歸分析方法是在眾多的相關變數中,根據實際問題考察其中一個或多個變數(因變數)與其余變數(自變數)的( ),
A.結合程度
B.對抗關系
C.依賴關系
D.不同之處
-
在一些問題中,不僅經常需要考察兩個變數之間的相關程度,而且還經常需要考察多個變數與多個變數之間即( )之間的相關關系,
A.數值數字
B.多組變數
C.復雜元素
D.兩組變數
作業05
-
簡述計算機虛擬化技術以及常見的虛擬化軟體,
在計算機中,虛擬化(Virtualization)是一種資源管理技術,是將計算機的各種物體資源,如服務器、網路、記憶體及存盤等,予以抽象、轉換后呈現出來,打破物體結構間的不可分割的障礙,使用戶可以比原本的組態更好的方式來應用這些資源,這些資源的新虛擬部分是不受現有資源的架設方式,地域或物理組態所限制,一般所指的虛擬化資源包括計算能力和資料存盤,常見的虛擬化軟體有VirtualBox、VMware Workstation、KVM,
-
簡述大資料集群系統,
集群技術是指通過高速通信網路將一組相互獨立的計算機聯系在一起,組成一個計算機系統,該系統中每一臺計算機都是一個獨立的服務器,運行各自的行程,它們相互之間可以通信,既可以看作是一個個單一的系統,也能夠協同起來為用戶提供服務,對網路用戶來講,后端就像是一個單一的系統,協同向用戶提供系統資源、系統服務,通過網路連接組合成一個組合來共同完一個任務,Hadoop 分布式集群是為了對海量的非結構化資料進行存盤和分析而設計的一種特定的集群,其本質上是一種計算集群,
-
簡述大資料的存盤方式,
存盤系統作為資料中心最核心的資料基礎,不再僅是傳統分散的、單一的底層設備,除了要具備高性能、高安全、高可靠等基于大資料應用需求,“應用定義存盤”概念被提出,主要有以下幾種存盤方式: 1、分布式系統 2、NoSQL資料庫 3、云資料庫 4、大資料存盤技術路線 1) 采用MPP架構的新型資料庫集群 2) 基于Hadoop的技術擴展和封裝 3) 大資料一體機
-
簡述大資料的概念,
自2012年以來,“大資料”一詞越來越引起人們的關注,但是,目前為止,在學術研究領域和產業界中,大資料并沒有一個標準的定義,在維克托·邁爾-舍恩伯格撰寫的《大資料時代》一書中大資料指不用隨機分析法(抽樣調查)這樣捷徑,而采用所有資料進行分析處理,而麥肯錫全球研究所則定義大資料為一種規模大到在獲取、存盤、管理、分析方面大大超出了傳統資料庫軟體工具能力范圍的資料集合,具有海量的資料規模、快速的資料流轉、多樣的資料型別和價值密度低四大特征,通常來說,大資料是指資料量超過一定大小,無法用常規的軟體在規定的時間范圍內進行抓取、管理和處理的資料集合,
-
簡述大資料的基本特征,
大資料的主要特征可用“5V+1C”來進行概括,分別是:資料量大(Volume)、資料型別多(Variety)、資料時效性強(Velocity)、價值密度低(Value)、準確性高(Veracity)、復雜性高(Complexity),
作業06
-
簡述Hadoop系統及其優點,
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺,它主要有以下幾個優點:(1)高可靠性,(2)高擴展性,(3)高效性(4)高容錯性,
-
簡述 HDFS寫資料的流程,
詳細流程如下:(1)首先HDFS的客戶端通過Distributed FileSystem(HDFS中API里的一個物件);(2)通過Distributed FileSystem發送客戶端的請求給NameNode(NameNode主要是接受客戶端請求)并且會帶著檔案要保存的位置、 檔案名、操作的用戶名等資訊一起發送給NameNode;(3)NameNode會給客戶端回傳了一個FSDataOutputStream,同時也會回傳檔案要寫入哪些DataNode上(負載較低的);(4)通過FSDataOutputStream進行寫操作,在寫之前就做檔案的拆分,將檔案拆分成多個Block,第一個寫操作寫在負載比較低的DataNode上,并將這個block復制到其他的DataNode上;(5)當所有的block副本復制完成后會反饋給FSDataOutputStream;(6)當所有的block副本全都復制完成,就可以將FSDataOutputStream流關閉;(7)通過Distributed FileSystem更新NameNode中的源資料資訊,
-
簡述Hadoop技術生態系統,
Hadoop生態系統主要包括:HDFS、MapReduce、Spark、Storm、HBase、Hive、Pig、ZooKeeper、 Avro 、Sqoop、Ambari、HCatalog、Chukwa 、Flume、Mahout、Phoenix、Tez、Shark等,
-
簡述Hadoop原理及運行機制,
Hadoop的核心由3個子專案組成:Hadoop Common、HDFS、和MapReduce, Hadoop Common包括檔案系統(File System)、遠程程序呼叫協議(RPC)和資料串行化庫(Serialization Libraries),
-
簡述 HDFS讀資料的流程,
詳細流程如下:(1)首先HDFS的客戶端通過Distributed FileSystem(HDFS中API里的一個物件);(2)通過Distributed FileSystem發送給NameNode請求,同時將用戶資訊及檔案名的資訊等發送給NameNode,并回傳給DistributedFileSystem,該檔案包含的block所在的DataNode位置;(3)HDFS客戶端通過FSDataInputStream按順序去讀取DataNode中的block資訊(它會選擇負載最低的或離客戶端最近的一臺DataNode去讀block);(4)FSDataInputStream按順序一個一個的讀,直到所有的block都讀取完畢;(5)當讀取完畢后會將FSDataInputStream關閉,
作業07
-
3種鳶尾花資料(萼片寬度、萼片長度、 花瓣寬度、花瓣長度)為: (4.9,3.0,1.4,0.2)、(5.0,3.6,1.4,0.2)、(5.2,2.7,3.9,1.4)、(6.1,2.9,4.7,1.4)、(7.7,2.6,6.9,2.3)、(6.6,2.9,4.6,1.3)、(4.4,3.2,1.3,0.2)、(5.7,2.8,4.1,1.3),計算其聚類中心并將資料進行分類,
參見《大資料技術與應用》第9章第3節
-
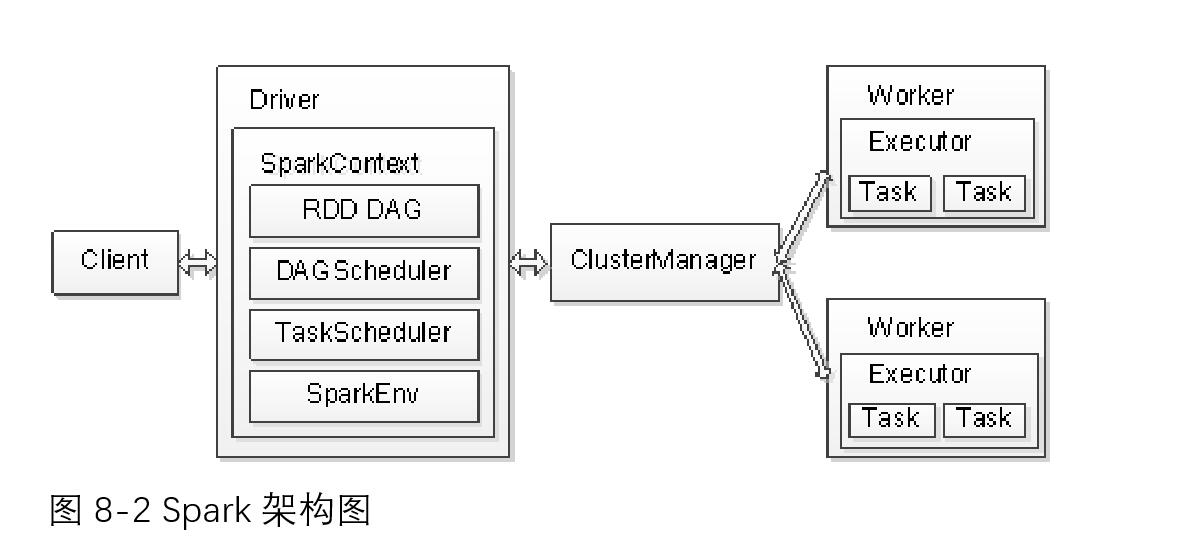
簡述Spark開源框架及其特點,
Spark架構采用了分布式計算中的Master-Slave模型,Spark架構如下圖所示:
-
簡述Spark生態系統及其主要組件,
Spark主要包括Spark Core和在Spark Core基礎之上建立的應用框架Spark SQL、Spark Streaming、MLlib和GraphX,除了這些庫以外,還有一些其他的庫,如BlinkDB和Tachyon,此外,還有一些用于與其他產品集成的配接器,如Cassandra(Spark Cassandra連接器)和R(SparkR),
作業08
有一道題答案是錯的,但不知道是哪一道,如果有人發現的話,可以在評論區留言,
-
過一系列處理,在基本保持原始資料完整性的基礎上,減小資料規模的()
A.資料清洗
B.資料融合
C.資料規約
D.資料挖掘
-
大資料的最顯著特征是( ),
A.資料規模大
B.資料型別多樣
C.資料處理速度快
D.資料價值密度高
-
下列關于大資料的分析理念的說法中,錯誤的是( ),
A.在資料基礎上傾向于全體資料而不是抽樣資料
B.在分析方法上更注重相關分析而不是因果分析
C.在分析效果上更追究效率而不是絕對精確
D.在資料規模上強調相對資料而不是絕對資料
-
大資料的4V特征中的Velocity是指( ),
A.價值密度低
B.處理速度快
C.資料型別繁多
D.資料體量巨大
-
大資料的起源是( ),
A.金融
B.電信
C.互聯網
D.公共管理
-
下列演示方式中,不屬于傳統統計圖方式的是( ),
A.柱形圖
B.餅狀圖
C.曲線圖
D.網路圖
-
下列關于舍恩伯格對大資料特點的說法中,錯誤的是( )
A.資料規模大
B.資料型別多樣
C.資料處理速度快
D.資料價值密度高
-
大資料不是要教機器像人一樣思考,相反,它是( ),
A.把數學演算法運用到海量的資料上來預測事情發生的可能性
B.被視為人工智能的一部
C.被視為一種機器學習
D.預測與懲罰
-
HDfS 中的 block 默認保存幾份?
A.3 份
B.2 份
C.1 份
D.不確定
-
HDFS 默認 Block Size 是()
A.32MB
B.64MB
C.128MB
-
下列哪項通常是集群的最主要瓶頸?
A.CPU
B.網路
C.磁盤IO
D.記憶體
-
下面哪個程式負責 HDFS 資料存盤( ),
A.NameNode
B.Jobtracker
C.Datanode
D.secondaryNameNode
-
配置Hadoop時,JAVA_HOME包含在哪一個組態檔中( )
A.hadoop-default.xml
B.hadoop-env.sh
C.hadoop-site.xml
D.configuration.xs
-
下列關于 Hadoop API 的說法錯誤的是( ),
A.Hadoop的檔案API不是通用的,只用于HDFS檔案系統
B.Configuration類的默認實體化方法是以HDFS系統的資源配置為基礎的
C.FileStatus物件存盤檔案和目錄的元資料
D.FSDataInputStream是java.io.DataInputStream的子類
-
下列哪個程式通常與 NameNode 在一個節點啟動?( )
A.SecondaryNameNode
B.DataNode
C.TaskTracker
D.Jobtracker
-
下面與 HDFS 類似的框架是?( )
A.NTFS
B.FAT32
C.GFS
D.EXT3
-
HBase中的批量加載底層使用( )實作,
A.MapReduce
B.Hive
C.Coprocessor
D.Bloom Filter
-
從大量資料中提取知識的程序通常稱為( ),
A.資料挖掘
B.人工智能
C.資料清洗
D.資料倉庫
-
Hadoop fs中的-get和-put命令操作物件是( )、
A.檔案
B.目錄
C.兩者都是
-
HDFS默認的當前作業目錄是/user/$USER,fs.default.name的值需要在哪個組態檔內說明
A.mapred-site.xml
B.core-site.xml
C.hdfs-site.xml
D.以上均不是
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/387829.html
標籤:其他
上一篇:大資料實訓