目錄
1、使用ArrayList存盤自定義物件并遍歷
LinkedList
LinkedList特有的功能
添加功能
void addFirst(Object obj)
void addLast(Object obj)
獲取功能
Object getFirst()
Object getLast()
洗掉功能
Object removeFirst()
Object removeLast()
Vector
Vector特有的方法
public void addElement(Object obj)
public Object elementAt(int index)
public Enumeration elements()
案例1
解決方法一:迭代器遍歷,迭代器修改
解決方法二:集合遍歷,集合修改
案例2
案例3
案例4
1、使用ArrayList存盤自定義物件并遍歷
參考代碼:
創建Student類:
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}創建ArrayList測驗類:
package com.hjl.test.day23;
import java.util.ArrayList;
import java.util.Iterator;
/*
使用ArrayList存盤自定義物件并遍歷
*/
public class ArrayListDemo01 {
public static void main(String[] args) {
//創建ArrayList集合物件
ArrayList arrayList = new ArrayList();
//創建學生物件
Student s1 = new Student("劉德華", 23);
Student s2 = new Student("張學友", 22);
Student s3 = new Student("郭富城", 23);
Student s4 = new Student("彭于晏", 24);
Student s5 = new Student("周杰倫", 25);
//將學生物件添加到集合中
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
arrayList.add(s4);
arrayList.add(s5);
//遍歷的第一種方式:迭代器遍歷
//獲取迭代器物件
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()){
Student s = (Student) iterator.next();
System.out.println(s.getName() + "---" +s.getAge());
}
System.out.println("================================");
//遍歷的第二種方式:get()和size()方法結合
for (int i = 0;i < arrayList.size();i++){
Student student = (Student) arrayList.get(i);
System.out.println(student.getName() + "---" + student.getAge());
}
}
}
輸出結果:
劉德華---23
張學友---22
郭富城---23
彭于晏---24
周杰倫---25
================================
劉德華---23
張學友---22
郭富城---23
彭于晏---24
周杰倫---25
LinkedList
查看API檔案我們知道:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable雙鏈表實作了
List和Deque介面, 實作所有可選串列操作,并允許所有元素(包括null),所有的操作都能像雙向串列一樣預期, 索引到串列中的操作將從開始或結束遍歷串列,以更接近指定的索引為準,
請注意,此實作不同步, 如果多個執行緒同時訪問鏈接串列,并且至少有一個執行緒在結構上修改串列,則必須在外部進行同步, (結構修改是添加或洗掉一個或多個元素的任何操作;僅設定元素的值不是結構修改,)這通常通過在自然封裝串列的物件上進行同步來實作, 如果沒有這樣的物件存在,串列應該使用Collections.synchronizedList方法“包裝”, 這最好在創建時完成,以防止意外的不同步訪問串列:
List list = Collections.synchronizedList(new LinkedList(...));這個類的
iterator和listIterator方法回傳的迭代器是故障快速的 :如果串列在迭代器創建之后的任何時間被結構化地修改,除了通過迭代器自己的remove或add方法之外,迭代器將會拋出一個ConcurrentModificationException , 因此,面對并發修改,迭代器將快速而干凈地失敗,而不是在未來未確定的時間冒著任意的非確定性行為,請注意,迭代器的故障快速行為無法保證,因為一般來說,在不同步并發修改的情況下,無法做出任何硬性保證, 失敗快速迭代器盡力投入
ConcurrentModificationException, 因此,撰寫依賴于此例外的程式的正確性將是錯誤的:迭代器的故障快速行為應僅用于檢測錯誤,
底層資料結構為鏈表所以具有查詢慢,增刪快,執行緒不安全,效率高的特點
LinkedList特有的功能
-
添加功能
void addFirst(Object obj)
查看API檔案我們知道:
public void addFirst(E e)在該串列開頭插入指定的元素,
Specified by:
addFirst在介面Deque<E>引數
e- 要添加的元素
參考代碼:
import java.util.LinkedList;
public class LinkedListDemo1 {
public static void main(String[] args) {
//創建LinkedList物件
LinkedList linkedList = new LinkedList();
//添加元素到集合中
linkedList.add("hello");
linkedList.add("world");
linkedList.add("java");
linkedList.add("hadoop");
linkedList.add("hive");
linkedList.add("spark");
System.out.println(linkedList);
System.out.println("================================================");
//void addFirst(Object obj) 在該串列開頭插入指定的元素,
linkedList.addFirst("flink");
System.out.println(linkedList);
}
}輸出結果:
[hello, world, java, hadoop, hive, spark]
================================================
[flink, hello, world, java, hadoop, hive, spark]
從輸出結果上可以看出void addFirst(Object obj)就是在該串列開頭插入指定的元素,
void addLast(Object obj)
查看API檔案我們知道:
public void addLast(E e)將指定的元素追加到此串列的末尾,
這個方法相當于add(E) ,
Specified by:
addLast在介面Deque<E>引數
e- 要添加的元素
參考代碼:
import java.util.LinkedList;
public class LinkedListDemo1 {
public static void main(String[] args) {
//創建LinkedList物件
LinkedList linkedList = new LinkedList();
//添加元素到集合中
linkedList.add("hello");
linkedList.add("world");
linkedList.add("java");
linkedList.add("hadoop");
linkedList.add("hive");
linkedList.add("spark");
System.out.println(linkedList);
System.out.println("================================================");
//void addLast(Object obj) 將指定的元素追加到此串列的末尾,
linkedList.addLast("hdfs");
System.out.println(linkedList);
}
}輸出結果:
[hello, world, java, hadoop, hive, spark]
================================================
[hello, world, java, hadoop, hive, spark, hdfs]
從輸出結果來看void addList(Object obj)就是將指定的元素追加到此串列的末尾 ,
-
獲取功能
Object getFirst()
查看API檔案我們知道:
public E getFirst()回傳此串列中的第一個元素,
Specified by:
getFirst在介面Deque<E>結果
這個串列中的第一個元素
例外
NoSuchElementException- 如果此串列為空
參考代碼:
import java.util.LinkedList;
public class LinkedListDemo1 {
public static void main(String[] args) {
//創建LinkedList物件
LinkedList linkedList = new LinkedList();
//添加元素到集合中
linkedList.add("hello");
linkedList.add("world");
linkedList.add("java");
linkedList.add("hadoop");
linkedList.add("hive");
linkedList.add("spark");
System.out.println(linkedList);
System.out.println("================================================");
//Object getFirst() 回傳此串列中的第一個元素,
Object first = linkedList.getFirst();
System.out.println(first);
System.out.println(linkedList);
}
}輸出結果:
[hello, world, java, hadoop, hive, spark]
================================================
hello
[hello, world, java, hadoop, hive, spark]
從輸出結果上可以看出Obje getFirst()就是回傳此串列中的第一個元素,
Object getLast()
查看API檔案我們知道:
public E getLast()回傳此串列中的最后一個元素,
Specified by:
getLast在介面Deque<E>結果
這個串列中的最后一個元素
例外
NoSuchElementException- 如果此串列為空
參考代碼:
import java.util.LinkedList;
public class LinkedListDemo1 {
public static void main(String[] args) {
//創建LinkedList物件
LinkedList linkedList = new LinkedList();
//添加元素到集合中
linkedList.add("hello");
linkedList.add("world");
linkedList.add("java");
linkedList.add("hadoop");
linkedList.add("hive");
linkedList.add("spark");
System.out.println(linkedList);
System.out.println("================================================");
//Object getLast() 回傳此串列中的最后一個元素,
Object last = linkedList.getLast();
System.out.println(last);
System.out.println(linkedList);
}
}輸出結果:
[hello, world, java, hadoop, hive, spark]
================================================
spark
[hello, world, java, hadoop, hive, spark]
從輸出結果來看Object getList()就是從此串列中回傳最后一個元素,
-
洗掉功能
Object removeFirst()
查看API檔案我們知道:
public E removeFirst()從此串列中洗掉并回傳第一個元素,
Specified by:
removeFirst在介面Deque<E>結果
這個串列中的第一個元素
例外
NoSuchElementException- 如果此串列為空
參考代碼:
import java.util.LinkedList;
public class LinkedListDemo1 {
public static void main(String[] args) {
//創建LinkedList物件
LinkedList linkedList = new LinkedList();
//添加元素到集合中
linkedList.add("hello");
linkedList.add("world");
linkedList.add("java");
linkedList.add("hadoop");
linkedList.add("hive");
linkedList.add("spark");
System.out.println(linkedList);
System.out.println("================================================");
//Object removeFirst() 從此串列中洗掉并回傳第一個元素,
Object o = linkedList.removeFirst();
System.out.println(o);
System.out.println(linkedList);
}
}
輸出結果:
[hello, world, java, hadoop, hive, spark]
================================================
hello
[world, java, hadoop, hive, spark]
從輸出結果可以看出Object removeFirst()就是從此串列中洗掉并回傳第一個元素,
Object removeLast()
查看api檔案我們知道:
public E removeLast()從此串列中洗掉并回傳最后一個元素,
Specified by:
removeLast在界面Deque<E>結果
這個串列中的最后一個元素
例外
NoSuchElementException- 如果此串列為空
參考代碼:
import java.util.LinkedList;
public class LinkedListDemo1 {
public static void main(String[] args) {
//創建LinkedList物件
LinkedList linkedList = new LinkedList();
//添加元素到集合中
linkedList.add("hello");
linkedList.add("world");
linkedList.add("java");
linkedList.add("hadoop");
linkedList.add("hive");
linkedList.add("spark");
System.out.println(linkedList);
System.out.println("================================================");
//Object removeLast() 從此串列中洗掉并回傳最后一個元素,
Object o = linkedList.removeLast();
System.out.println(o);
System.out.println(linkedList);
}
}輸出結果:
[hello, world, java, hadoop, hive, spark]
================================================
spark
[hello, world, java, hadoop, hive]
從輸出結果可以看出Object removeLast()就是從此串列中洗掉并回傳最后一個元素,
Vector
查看API檔案我們知道:
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
Vector類實作了可擴展的物件陣列, 像陣列一樣,它包含可以使用整數索引訪問的組件, 但是,Vector的大小可以根據需要增長或縮小,以適應在創建Vector之后添加和洗掉專案,每個向量嘗試通過維護
capacity和capacityIncrement優化存盤capacityIncrement,capacity總是至少與矢量大小一樣大; 通常較大,因為當向量中添加組分時,向量的存盤空間大小capacityIncrement, 應用程式可以在插入大量組件之前增加向量的容量; 這減少了增量重新分配的數量,The iterators returned by this class's個 iterator和listIterator方法是快速失敗的 :如果向量在任何時間從結構上修改創建迭代器之后,以任何方式除非通過迭代器自身remove種或add方法,迭代器都將拋出一個ConcurrentModificationException , 因此,面對并發修改,迭代器將快速而干凈地失敗,而不是在未來未確定的時間冒著任意的非確定性行為, 由elements回傳的Enumerations 不是故障快速的,
請注意,迭代器的故障快速行為無法保證,因為一般來說,在不同步并發修改的情況下,無法做出任何硬性保證, 失敗快速迭代器盡力投入
ConcurrentModificationException, 因此,撰寫依賴于此例外的程式的正確性將是錯誤的:迭代器的故障快速行為應僅用于檢測錯誤,從Java 2平臺v1.2,這個類被改造為實作List介面,使其成為成員Java Collections Framework , 與新集合實作不同,
Vector是同步的, 如果不需要執行緒安全的實作,建議使用ArrayList代替Vector,
vector:底層資料結構是陣列具有查詢快、增刪慢、執行緒安全、效率低的特點,(雖然是執行緒安全的,但是我們并不經常使用他,后面我們會講一個執行緒安全的類代替它)
-
Vector特有的方法
public void addElement(Object obj)
查看API檔案我們知道:
public void addElement(E obj)將指定的組件添加到此向量的末尾,將其大小增加1, 如果該載體的大小大于其容量,則該載體的容量增加,
該方法的功能與add(E)方法相同(它是List介面的一部分),
引數
obj- 要添加的組件
參考代碼:
import java.util.Vector;
public class VectorDemo1 {
public static void main(String[] args) {
//創建Vector集合物件
Vector vector = new Vector();
//向集合中添加元素
vector.addElement("hello");
vector.add("hadoop");
vector.addElement("java");
System.out.println(vector);
}
}輸出結果:
[hello, hadoop, java]
從運行結果來看addElement()和add()的效果一樣,是將元素添加到集合的末尾,
public Object elementAt(int index)
查看API檔案我們知道:
public E elementAt(int index)回傳指定索引處的組件,
該方法的功能與get(int)方法相同(它是List介面的一部分),
引數
index- 這個向量的索引結果
指定索引處的組件
例外
ArrayIndexOutOfBoundsException- 如果索引超出范圍(index < 0 || index >= size())
回傳指定索引處的組件和get(int index)效果相同
參考代碼1:
import java.util.Vector;
public class VectorDemo1 {
public static void main(String[] args) {
//創建Vector集合物件
Vector vector = new Vector();
//向集合中添加元素
vector.addElement("hello");
vector.add("hadoop");
vector.addElement("java");
System.out.println(vector);
System.out.println("===============================");
//public Object elementAt(int index)
Object o = vector.elementAt(0);
System.out.println(o);
System.out.println(vector.elementAt(1));
System.out.println(vector.elementAt(2));
System.out.println(vector.get(0));
}
}輸出結果:
[hello, hadoop, java]
===============================
hello
hadoop
java
hello
從輸出結果來看elementAt()效果和get()一樣,如果我們不知道集合中有多少元素不小心取多了會發生什么呢?
參考代碼2:
import java.util.Vector;
public class VectorDemo1 {
public static void main(String[] args) {
//創建Vector集合物件
Vector vector = new Vector();
//向集合中添加元素
vector.addElement("hello");
vector.add("hadoop");
vector.addElement("java");
System.out.println(vector);
System.out.println("===============================");
//public Object elementAt(int index)
Object o = vector.elementAt(0);
System.out.println(o);
System.out.println(vector.elementAt(1));
System.out.println(vector.elementAt(2));
System.out.println(vector.get(0));
System.out.println(vector.elementAt(3));
}
}
運行結果:
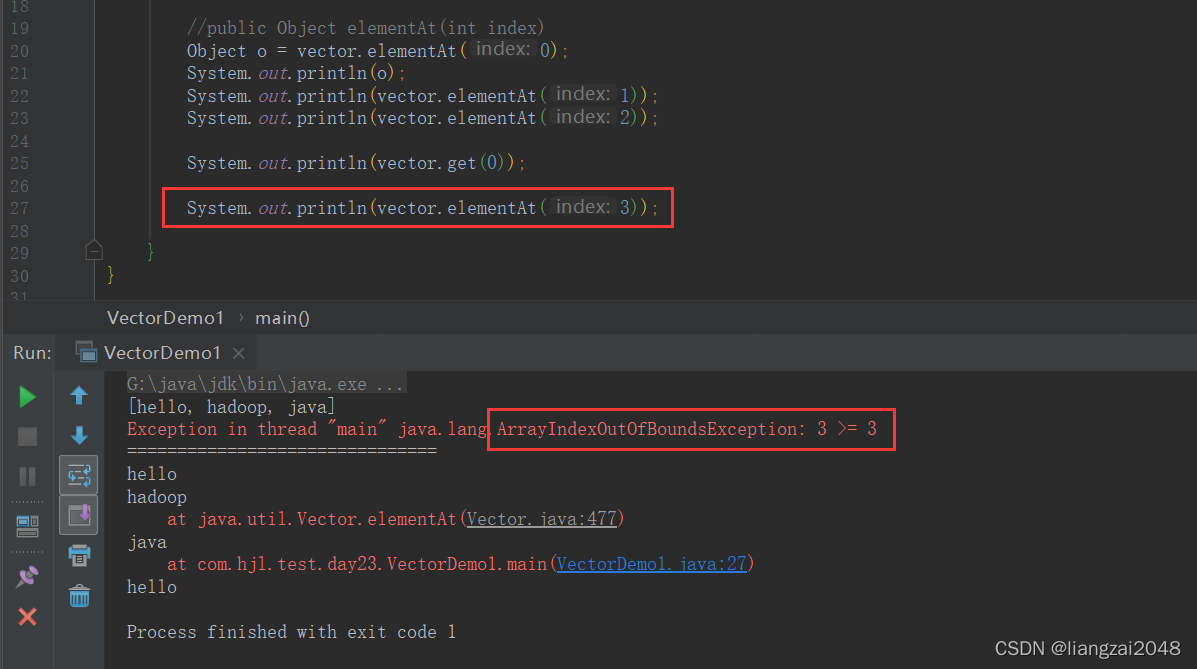
ArrayIndexOutOfBoundsException 陣列越界例外
public Enumeration elements()
查看API檔案我們知道:
public Enumeration<E> elements()回傳此向量的組件的列舉, 回傳的
Enumeration物件將生成此向量中的所有項, 產生的第一項是在索引的項0,則在索引項1,依此類推,結果
這個向量的組件的列舉
參考代碼:
import java.util.Enumeration;
import java.util.Vector;
public class VectorDemo1 {
public static void main(String[] args) {
//創建Vector集合物件
Vector vector = new Vector();
//向集合中添加元素
vector.addElement("hello");
vector.add("hadoop");
vector.addElement("java");
System.out.println(vector);
System.out.println("===============================");
//public Enumeration elements()
Enumeration elements = vector.elements();
while (elements.hasMoreElements()){
Object o = elements.nextElement();
System.out.println(o);
}
System.out.println("===========================");
System.out.println(vector);
}
}輸出結果:
[hello, hadoop, java]
===============================
hello
hadoop
java
===========================
[hello, hadoop, java]
從運行結果上我們可以看出該方法就是回傳此向量的組件的列舉,
接下來我們寫幾個案例來練習一下
案例1
需求:
現在有一個集合,集合中有些字串的元素,我想判斷一下里面有沒有"bigdata"這個字串 如果有,我們就添加一個"yes"
解決方法一:迭代器遍歷,迭代器修改
參考代碼1:
import java.util.ArrayList;
import java.util.Iterator;
public class ListTestDemo1 {
public static void main(String[] args) {
//創建一個集合物件
ArrayList list = new ArrayList();
//添加元素到集合中
list.add("hello");
list.add("world");
list.add("java");
list.add("bigdata");
list.add("hadoop");
//獲取迭代器物件
Iterator iterator = list.iterator();
while (iterator.hasNext()){
String s = (String) iterator.next();
if("bigdata".equals(s)){
list.add("yes");
}
}
System.out.println(list);
}
}
運行結果:
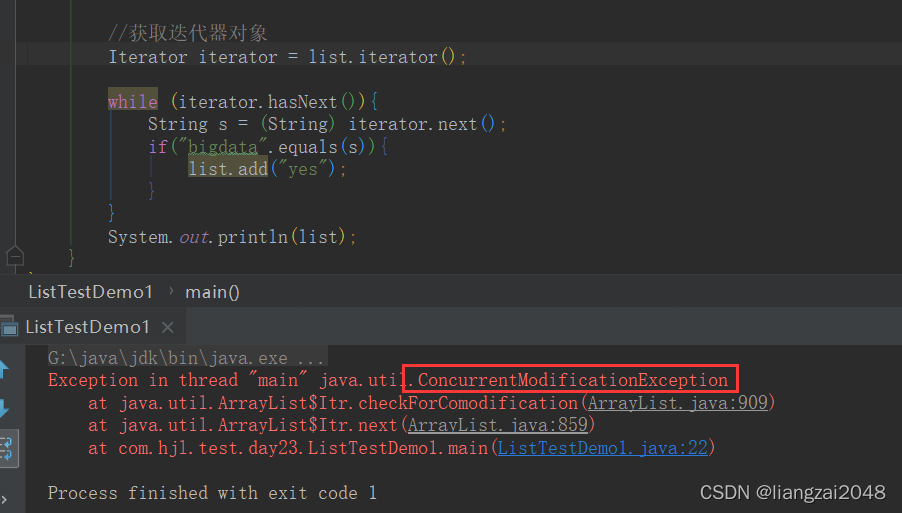
用我們之前學的獲取迭代器物件則出現了一個ConcurrentModificationException:并發修改例外,當不允許這樣的修改時,可以通過檢測到物件的并發修改的方法來拋出此例外,
原因:迭代器是依賴于集合存在的,在遍歷迭代器元素的時候,當我們判斷成功后,往集合中添加 了一個元素,但是呢,迭代器這個時候并不知道已經添加了元素,所以就報錯了,
簡單的來說就是在迭代器遍歷的時候不能通過集合去修改元素,
這個時候就要用到我們的迭代器遍歷,迭代器修改和集合遍歷,集合修改這兩種方法去解決,
參考代碼2:
import java.util.ArrayList;
import java.util.ListIterator;
public class ListTestDemo1 {
public static void main(String[] args) {
//創建一個集合物件
ArrayList list = new ArrayList();
//添加元素到集合中
list.add("hello");
list.add("world");
list.add("java");
list.add("bigdata");
list.add("hadoop");
//迭代器遍歷,迭代器修改
ListIterator listIterator = list.listIterator();
while (listIterator.hasNext()){
String s = (String) listIterator.next();
if ("bigdata".equals(s)){
//在迭代器元素"bigdata"后面添加
listIterator.add("yes");
}
}
System.out.println(list);
}
}
輸出結果:
[hello, world, java, bigdata, yes, hadoop]
在迭代器元素"bigdata"后面添加 ,
解決方法二:集合遍歷,集合修改
參考代碼3:
import java.util.ArrayList;
public class ListTestDemo1 {
public static void main(String[] args) {
//創建一個集合物件
ArrayList list = new ArrayList();
//添加元素到集合中
list.add("hello");
list.add("world");
list.add("java");
list.add("bigdata");
list.add("hadoop");
//集合遍歷,集合修改
for (int i = 0;i<list.size();i++){
String s = (String) list.get(i);
if ("bigdata".equals(s)){
//在集合尾部添加
list.add("yes");
}
}
System.out.println(list);
}
}輸出結果:
[hello, world, java, bigdata, hadoop, yes]
在集合尾部添加
案例2
需求:去除集合中字串的重復值(字串的內容相同)
參考代碼:
import java.util.ArrayList;
import java.util.Iterator;
public class ArrayListTest1 {
public static void main(String[] args) {
//創建舊集合物件
ArrayList list = new ArrayList();
//向集合中添加字串元素
list.add("hello");
list.add("world");
list.add("java");
list.add("hadoop");
list.add("hive");
list.add("hello");
list.add("spark");
list.add("java");
System.out.println("去重之前的集合為:" + list);
//創建一個新的集合保存去重后的元素
ArrayList list2 = new ArrayList();
//遍歷舊集合
Iterator iterator = list.iterator();
while (iterator.hasNext()){
//向下轉型
String s = (String) iterator.next();
//獲取到元素后,拿到這個元素去新的集合里面去找,如果找到說明重復,如果沒有找到,就添加到新集合中
if (!list2.contains(s)){
list2.add(s);
}
}
System.out.println("去重后的集合為:" + list2);
}
}輸出結果:
去重之前的集合為:[hello, world, java, hadoop, hive, hello, spark, java]
去重后的集合為:[hello, world, java, hadoop, hive, spark]
案例3
需求:去除集合中自定義物件的值(物件的成員變數值都相同,姓名和年齡相同)
參考代碼1:
創建Student類:
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}'+ "\n";
}
}測驗類:
import java.util.ArrayList;
import java.util.Iterator;
public class ArrayListTest2 {
public static void main(String[] args) {
//創建集合物件
ArrayList list = new ArrayList();
//創建學生物件
Student s1 = new Student("劉德華", 18);
Student s2 = new Student("張學友", 19);
Student s3 = new Student("郭富城", 20);
Student s4 = new Student("劉德華", 18);
Student s5 = new Student("劉德華", 19);
//向集合中添加元素
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s4);
list.add(s5);
System.out.println("去重之前的集合為:\n" + list);
System.out.println("==================================================");
//創建新的集合物件
ArrayList list2 = new ArrayList();
//遍歷舊的集合
Iterator iterator = list.iterator();
while (!iterator.hasNext()){
//向下轉型
Student s = (Student) iterator.next();
//判斷重復的向新集合中添加
if (list2.contains(s)){
list2.add(s);
}
}
System.out.println("去重后的集合為:\n" + list2);
}
}
輸出結果:
去重之前的集合為:
[Student{name='劉德華', age=18}
, Student{name='張學友', age=19}
, Student{name='郭富城', age=20}
, Student{name='劉德華', age=18}
, Student{name='劉德華', age=19}
]
==================================================
去重后的集合為:
[]
通過運行結果發現,這并不是我們想要的結果,我們按照字串的形式處理重復的自定義物件,發現結果并沒有去重這是為什么呢?
查看原碼分析:
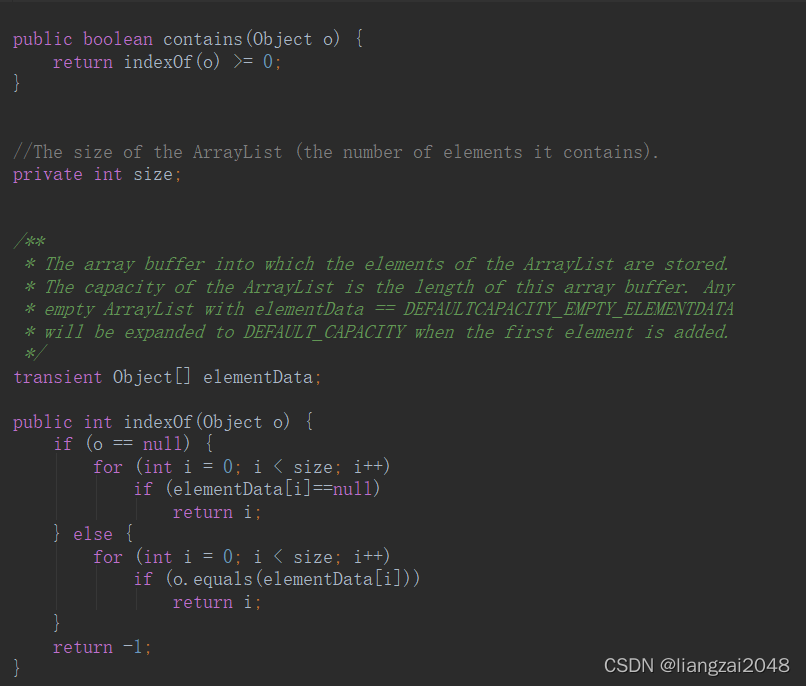
經過查看原碼的分析后,我們發現問題出現了在判斷的時候出現了, 因為只有當if里面是true的時候,才添加到新集合中, 說明我們的代碼一直都是true,換句話說,contains()方法并沒有生效 怎么改呢?要想知道怎么改,看一看contains內部是怎么實作的, 底層呼叫的是元素的equals方法,又因為我們Student類沒有重寫equals方法 呼叫的是父類Object類中的equals方法,比較的是地址值,所以contains() 結果永遠是true,if判斷永遠判斷的是新集合不包含,就添加到新集合中,所以 產生了沒有去重的效果,
解決辦法:元素類重寫equals()方法
在Student類中重寫equals方法:
import java.util.Objects;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}'+"\n";
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
}用我們之前的測驗類:
import java.util.ArrayList;
import java.util.Iterator;
public class ArrayListTest2 {
public static void main(String[] args) {
//創建集合物件
ArrayList list = new ArrayList();
//創建學生物件
Student s1 = new Student("劉德華", 18);
Student s2 = new Student("張學友", 19);
Student s3 = new Student("郭富城", 20);
Student s4 = new Student("劉德華", 18);
Student s5 = new Student("劉德華", 19);
//向集合中添加元素
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s4);
list.add(s5);
System.out.println("去重之前的集合為:\n" + list);
System.out.println("==================================================");
//創建新的集合物件
ArrayList list2 = new ArrayList();
//遍歷舊的集合
Iterator iterator = list.iterator();
while (iterator.hasNext()){
//向下轉型
Student s = (Student) iterator.next();
//判斷重復的向新集合中添加
if (!list2.contains(s)){
list2.add(s);
}
}
System.out.println("去重后的集合為:\n" + list2);
}
}
輸出結果:
去重之前的集合為:
[Student{name='劉德華', age=18}
, Student{name='張學友', age=19}
, Student{name='郭富城', age=20}
, Student{name='劉德華', age=18}
, Student{name='劉德華', age=19}
]
==================================================
去重后的集合為:
[Student{name='劉德華', age=18}
, Student{name='張學友', age=19}
, Student{name='郭富城', age=20}
, Student{name='劉德華', age=19}
]
這樣就達到我們想要的目的了,是不是很有意思呢?
案例4
面試題
需求:請用LinkedList模擬堆疊資料結構的集合,并測驗
參考代碼1:
import java.util.Iterator;
import java.util.LinkedList;
public class LinkedListTest2 {
public static void main(String[] args) {
//創建LinkedList集合
LinkedList linkedList = new LinkedList();
//使用addFirst向集合中添加元素
linkedList.addFirst("hello");
linkedList.addFirst("world");
linkedList.addFirst("java");
linkedList.addFirst("hadoop");
System.out.println("入堆疊:\n" + linkedList);
System.out.println("=======================");
//遍歷集合
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.println("出堆疊:\n" + next);
}
//如果面試的時候,你按照上面的寫法 0分
}
}
輸出結果:
入堆疊:
[hadoop, java, world, hello]
=======================
出堆疊:
hadoop
出堆疊:
java
出堆疊:
world
出堆疊:
hello
如果面試的時候,按照上面的寫法 0分!!!
題目真正的意思是,讓我們自己寫一個類,底層是LinkedList,呼叫自己寫的方法實作堆疊資料結構!
參考代碼:
創建MyStack類:
import java.util.LinkedList;
public class MyStack {
private LinkedList linkedList;
//自定義集合類
MyStack(){
linkedList = new LinkedList();
}
//進堆疊方法
public void myAdd(Object object){
linkedList.addFirst(object);
}
//出堆疊方法
public Object myGet(){
return linkedList.removeFirst();
}
//由于不知道集合元素有多少判斷集合是否為空
public boolean myIsEmpty(){
return linkedList.isEmpty();
}
@Override
public String toString() {
return "MyStack{" +
"linkedList=" + linkedList +
'}';
}
}
創建測驗類MyStackTest:
public class MyStackTest {
public static void main(String[] args) {
//創建自己定義的集合類
MyStack myStack = new MyStack();
//添加元素(入堆疊)
myStack.myAdd("hello");
myStack.myAdd("world");
myStack.myAdd("java");
myStack.myAdd("bigdata");
System.out.println("入堆疊:\n" + myStack);
//遍歷
System.out.println("出堆疊:");
while (!myStack.myIsEmpty()){
//向下轉型
String s = (String) myStack.myGet();
System.out.println(s);
}
}
}輸出結果:
入堆疊:
MyStack{linkedList=[bigdata, java, world, hello]}
出堆疊:
bigdata
java
world
hello
這樣我們就可以面試拿滿分啦!
到底啦!給靚仔一個關注吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/387830.html
標籤:其他
上一篇:云計算清覽作業
下一篇:大資料和云計算