學習資料:《統計學習方法 第二版》、《機器學習實戰》、吳恩達機器學習課程
一. 感知機Proceptron
-
感知機是根據輸入實體的特征向量\(x\)對其進行二類分類的線性分類模型:\(f(x)=\operatorname{sign}(w \cdot x+b)\),感知機模型對應于輸入空間(特征空間)中的分離超平面\(w \cdot x+b=0\),
-
感知機學習的策略是極小化損失函式:\(\min _{w, b} L(w, b)=-\sum_{x_{i} \in M} ;y_{i}\left(w \cdot x_{i}+b\right)\);
損失函式對應于誤分類點到分離超平面的總距離, -
感知機學習演算法是基于隨機梯度下降法的對損失函式的最優化演算法,對于所有誤分類的點,計算這些點到超平面的距離,目的是最小化這些點到平面的距離,
當訓練資料集線性可分時,感知機學習演算法存在無窮多個解,其解由于不同的初值或不同的迭代順序而可能有所不同,
二. K近鄰演算法
-
K-近鄰演算法是一種沒有顯示學習程序的演算法,資料集的可代表性就很重要!
-
K-近鄰原理:把資料集和輸入實體點都映射到空間內,對給定的輸入實體點,首先確定輸入實體點的??個最近鄰訓練實體點,這??個訓練實體點的類的多數就是預測的輸入實體點的類,
-
K-近鄰演算法的核心要素是K的值、距離度量(一般為歐式距離)、分類決策規則(一般是多數表決),當訓練集和核心要素確定時,其結果確定,
-
\(k\)值小時,\(k\)近鄰模型更復雜;??值大時,??近鄰模型更簡單,
三. 樸素貝葉斯
1. 數學公式
樸素的意思是所有特征相互獨立且同等重要,就說明
\[P(x_1x_2…x_k)=P(x_1)P(x_2)…P(x_k) \]
貝葉斯定理:
\[P(X,Y)=P(Y)P(X|Y) \]
得到樸素貝葉斯法的模型:
\[P(Y | X)=\frac{P(X, Y)}{P(X)}=\frac{P(Y) P(X | Y)}{\sum_{Y} P(Y) P(X | Y)} \]
2. 三種常用的樸素貝葉斯模型
- 高斯模型 當特征是連續變數時使用,假設特征符合高斯分布
- 多項式模型 當特征是離散值使用
多項式模型在計算先驗概率\(P(y_k)P(y_k)\)和條件概率\(P(x_i|y_k)P(x_i|y_k)\)時,會做一些平滑處理,
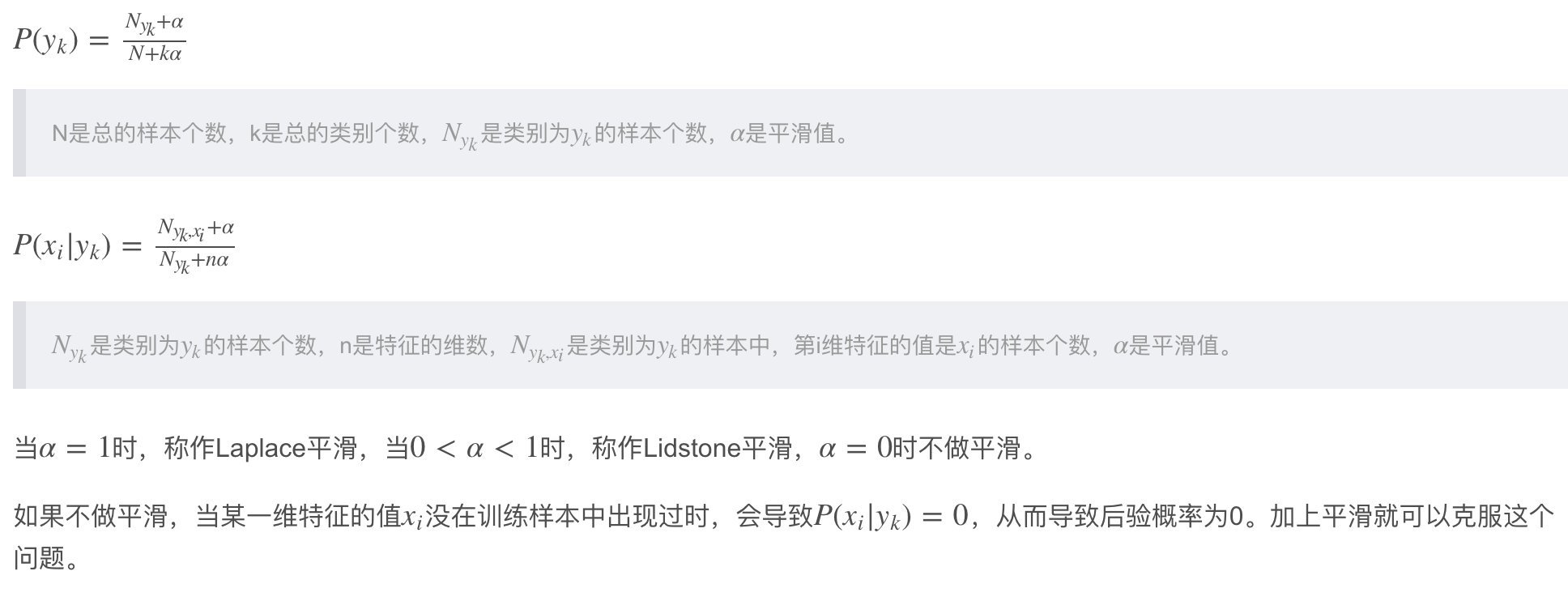
- 伯努利模型 當特征是離散值且是二值離散時使用
四. 決策樹
決策樹是基于特征對實體進行分類的樹形結構,包括三大步驟:特征的選擇、決策樹的生成、決策樹的剪枝,
1. 特征的選擇
熵
資訊論(information theory)中的熵(香農熵)的定義:隨機變數不確定性的度量,
熵是一種資訊的度量方式,表示資訊的混亂程度,也就是說:資訊越有序,資訊熵越低,例如:火柴有序放在火柴盒里,熵值很低,相反,熵值很高,熵越大,隨機變數的不確定性就越大,
資訊增益
資訊增益的定義:熵之差,在這里表示的是得知特征X后使得類Y劃分不確定度減少的程度,
選擇特征的方法是:計算每個特征對于訓練集的資訊增益,選擇資訊增益最大的特征,即分類能力強的特征,
資訊增益比
用資訊增益來選擇特征易選擇取值較多的特征,資訊增益比在資訊增益的基礎之上乘上一個懲罰引數:特征個數較多時,懲罰引數較小,資訊增益比也變小;特征個數較少時,懲罰引數較大,資訊增益比隨之增大,
資訊增益比偏向于選擇取值較少的特征,
基尼指數
基尼指數(基尼不純度)表示在樣本集合中一個隨機選中的樣本被分錯的概率,即指數越小表示集合中被選中的樣本被分錯的概率越小,也就是說集合的純度越高,反之,集合越不純,
2. 決策樹的生成
對于當前資料集的每一次的劃分,都希望根據某特征劃分之后的各個子集的純度更高,不確定性更小,
ID3演算法
用資訊增益從大到小選擇特征,根據特征的取值將訓練集分為相應子集,形成對應子結點,每個子結點中的訓練子集中數量最多的類作為該結點的類標記,然后遞回構建決策樹,
C4.5演算法
用資訊增益比從大到小選擇特征,遞回構建決策樹,
CART演算法
CART是個二叉樹,也就是當使用某個特征劃分樣本集合時,不管這個特征有幾個取值,劃分時都只有兩個集合:一個是等于給定的特征值的樣本集合D1 ,另一個是不等于給定的特征值的樣本集合D,實際上是對擁有多個取值的特征的二值處理,
因而對于一個具有多個取值(超過2個)的特征,需要計算以每一個取值作為劃分點,對樣本D劃分之后子集的純度Gini(D,Ai),(其中Ai 表示特征A的可能取值),然后從所有的可能劃分的Gini(D,Ai)中找出Gini指數最小的劃分,這個劃分的劃分點,便是使用特征A對樣本集合D進行劃分的最佳劃分點,
3. 決策樹的剪枝
- 簡化決策樹,防止過擬合;
- 合并無法產生大量資訊增益的葉結點,消除過度匹配的問題;
- 通過優化損失函式,減小決策樹復雜度,
五. logistic回歸
logistic回歸是一種二分類演算法
1. 運算式和函式影像
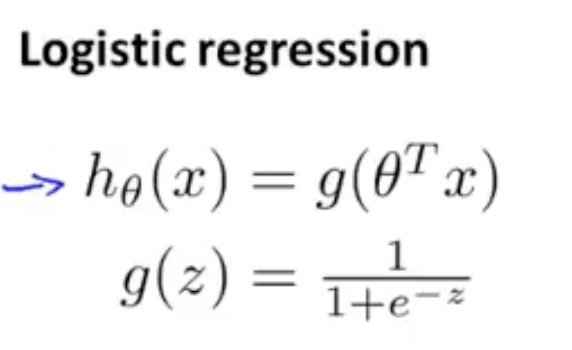
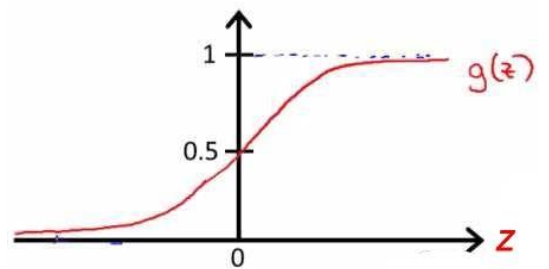
2. cost function
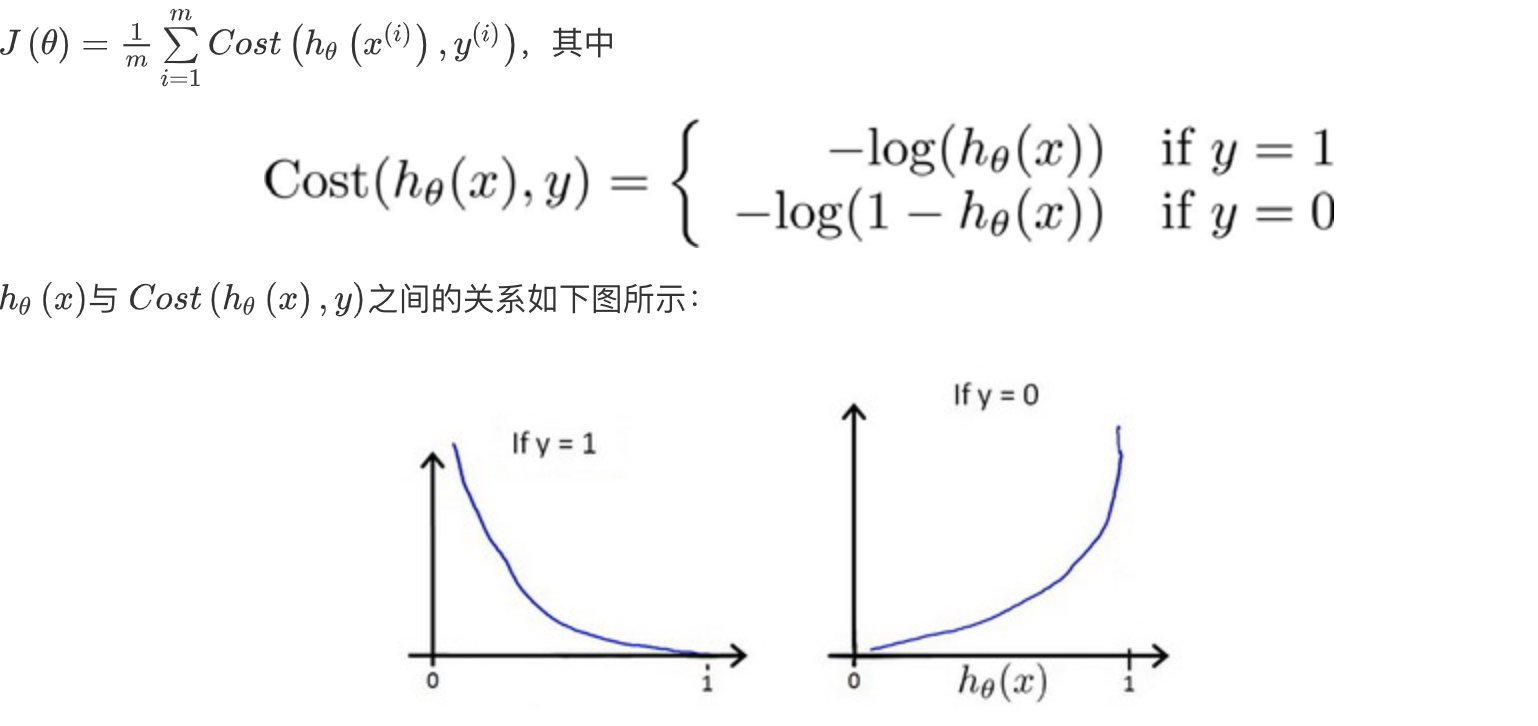

3. 梯度下降

六. SVM
Support Vector(支持向量):就是離超平面最近的點
SVM是線性分類演算法,與感知機不同的是,SVM的原理是不僅僅要成功做到線性可分,還要找最大間隔largest margin——就是支持向量離超平面最近的距離,然后最大化這個距離,進而轉化為最優化問題——最優化距離,
1. 松弛變數
之前的模型噪聲對非常敏感,如果資料集存在噪音,會導致最終超平面的選擇不夠好,甚至造成線性不可分的情況,在優化目標函式上加上松弛變數就類似于正則化變數一樣,允許離群點的存在,但是會對離群點有所懲罰,尋找最優最大間隔與考慮離群點的存在之間的平衡就成了優化目標,
2. 核函式
SVM是線性分類演算法,對于非線性可分的資料集,可以利用核函式將資料映射到高維空間,從而把低緯線性不可分資料轉為高緯度線性可分資料,然后再用SVM,
七. 集成方法
bagging、boosting都是集成多個分類器的方法,
1. bagging
把訓練集進行隨機放回抽樣,抽取出與原訓練集數量相同的新資料集,總共生成多個樣本數量相同的新訓練集,利用同一個學習演算法對這幾個訓練集訓練,形成多個分類器,之后預測新實體時用多個分類器同時進行預測,選擇最多的分類類別作為結果,
最常用的方法:隨機森林
2. boosting
只用原始資料集,但對里面每個樣本賦予權重,先后用同種弱分類器訓練資料集,每個弱分類器訓練結束得到由分類正確率計算出來的alpha值,再通過這個值更新樣本權重,預測新實體時是將每個弱分類器預測結果乘alpha值線性相加得到,
最常用的方法:Adaboost
八. 分類
分類問題可以分為二分類問題、多分類問題、多標簽分類問題和多輸出分類
二分類:一個樣本只有一個標簽且只可能是0或者1;
多分類:一個樣本只有一個標簽但標簽結果為多個;
多標簽:一個樣本有多個標簽,但每個標簽的值是0或1;
多輸出:一個樣本有多個標簽且每個標簽的值為多個,
如何解決多分類的問題
-
一些演算法(比如隨機森林分類器或者樸素貝葉斯分類器)可以直接處理多類分類問題,
-
其他一些演算法(比如 SVM 分類器或者線性分類器)則是嚴格的二分類器,但是,用一些策略可以讓二分類器去執行多類分類,
- OvA n個類需要n個分類器:每一個類對應一個二分類器,輸出是或否,優點是分類器較少,缺點是每個分類器需要訓練所有資料,
- OvO n個類需要
n(n-1)/2個分類器:每兩個類組成一個二分類器,輸出兩個類中的一個,優點是每個分類器只需要在訓練集的部分資料上面進行訓練,這部分資料是它所需要區分的那兩個類對應的資料,缺點是分類器較多,(SVM適合OvO)
九. 線性回歸
線性回歸模型中將cost function最小化除了用梯度下降還可以用正規方程,正規方程法不需要學習率,不需要特征縮放,可以直接一次計算出:
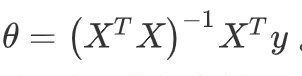
只要特征變數的數目并不大,標準方程是一個很好的計算引數的替代方法,具體地說,只要特征變數數量小于一萬,通常使用標準方程法,而不使用梯度下降法,
注意:有些時候對于某些模型不能使用正規方程而只能用梯度下降,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/39015.html
標籤:其他
上一篇:機器學習概述
下一篇:無監督學習方法