學習資料:吳恩達機器學習課程
一. K-means演算法
1. 演算法思想
- K-均值演算法是無監督學習中聚類演算法中的一個

- 初始化k個聚類中心
- 回圈:
- 將每個訓練樣本歸類到最近的聚類中心組成一個個聚類
- 移動聚類中心到本身聚類的中心(平均值)
2. 目標優化

3. 隨機初始化
K-均值的一個問題在于,它有可能會停留在一個區域最小值處,而這取決于初始化的情況,
-
解決方法:通常需要多次運行(50-1000次)K-均值演算法,每一次都重新進行隨機初始化,最后再比較多次運行K-均值的結果,選擇代價函式最小的結果,
初始化時隨機選擇訓練樣本作為聚類中心 -
這種方法在較小的時候\(K\)較小時(2-10)還是可行的,但是\(K\)如果較大,就沒有必要多次隨機初始化了,
4. 選擇聚類的數目K
- 根據“肘部法則”
- 根據聚類演算法分類后的目的來決定數量
二. 主成分分析PCA
1. Dimensionality reduction降維
- 主成分分析是降維的一種方法,將高緯資料壓縮成較低維度資料,比如將兩個維度的壓縮成一個維度時:就是指將兩個特征壓縮成一個新的特征,
- 降緯的作用:
- 壓縮資料,減少資料存盤空間;
- 加快學習演算法速度;
- 可視化資料:降到2D、3D可以可視化資料,
2. PCA步驟
首先進行資料預處理,均值標準化
\[\frac{X^{[i]}-x_{平均值}}{s_{標準差}/x_{max}-x_{min}} \]
n維度\(X^{[i]}\) 降到k維度$Z^{[i]} $,PCA演算法找到k維度:能夠最小化投影距離的平方
SVD 奇異值分解


3. 壓縮重構
壓縮后的維度K重新變回之前的維度n
之前是 \(Z = U_{reduce} ^T*X\) 矩陣維度分析: kn * n1 = k*1
現在可以用 \(X = U_{reduce}*Z\) 變回之前的維度 矩陣維度分析: nk * k1 = n*1
4. 選擇K的大小
使得平均最小投影距離/平均距離原點的距離<=0.01,即保留99%方差,降維后的資料更接近原資料,


僅僅通過SVD中的S就可以得到k的最優值
5. PCA的誤用
- 雖然PCA可以降維,但是PCA不是避免過擬合的方法,過擬合最好還是用正則化,
- 在剛開始進行建立一個學習模型時,不要把PCA作為剛開始就做的步驟,而是要先用$X^{[i]} $ ,只有當確實需要用到時才去用PCA,
三. 例外檢測Anomaly detection
- 主要用在非監督學習,但是也可以用在監督學習里,
1. 高斯分布例外檢測
引數估計:一些引數分布滿足高斯分布的時候,可以求出這些引數的平均值和方差用來表示這些引數的分布情況
- 選擇需要進行例外檢測的特征
- 求出這些特征對應高斯分布的平均值和方差
- 所有這些特征的高斯分布累積如果很小(小于一個閾值),就判定為例外

2. Anomaly detection vs supervised learning
-
例外檢測大多用于非監督學習,因為無監督學習中特征沒有label,所以可以根據這些特征的分布情況來建立一個模型,當有新的樣本進來時檢測樣本的這些特征是否符合模型,不符合則代表例外
-
例外檢測也可以用于監督學習,這時候例外檢測與監督學習演算法類似,例外樣本有對應的label=0,正常樣本對應的label=1,兩種演算法都是建立模型來區分例外和正常樣本,
-
兩種演算法的應用情況:
- 當例外樣本很少時,用例外檢測演算法:對大量正常樣本建立模型,測驗樣本符合模型則表示正常,不符合則表示例外,
- 當例外樣本數量較多時,則可以用監督學習演算法:同時對兩種樣本建立分類模型,
3. 如何選擇特征
對于一個樣本(無論正常還是例外),有許多特征可以選擇來判斷是否一個樣本是例外,例如:對于電腦是否損壞,有大量正常電腦和很少的例外電腦樣本,我們可以選擇的特征有CPU load,network traffc等,如下圖:

那么如何選擇合適的特征:
- 選擇的特征應該符合高斯分布,如果不符合對特征進行一些處理轉換使其大致符合高斯分布,(比如對于特征:\(x\)可以用\(x*0.5\) ,\(log(x)\)試一試)
- 根據誤差分析建立設計特征,比如\(x_1/x_2\)、\(x_1^2/x_3\)
4. 多元高斯分布
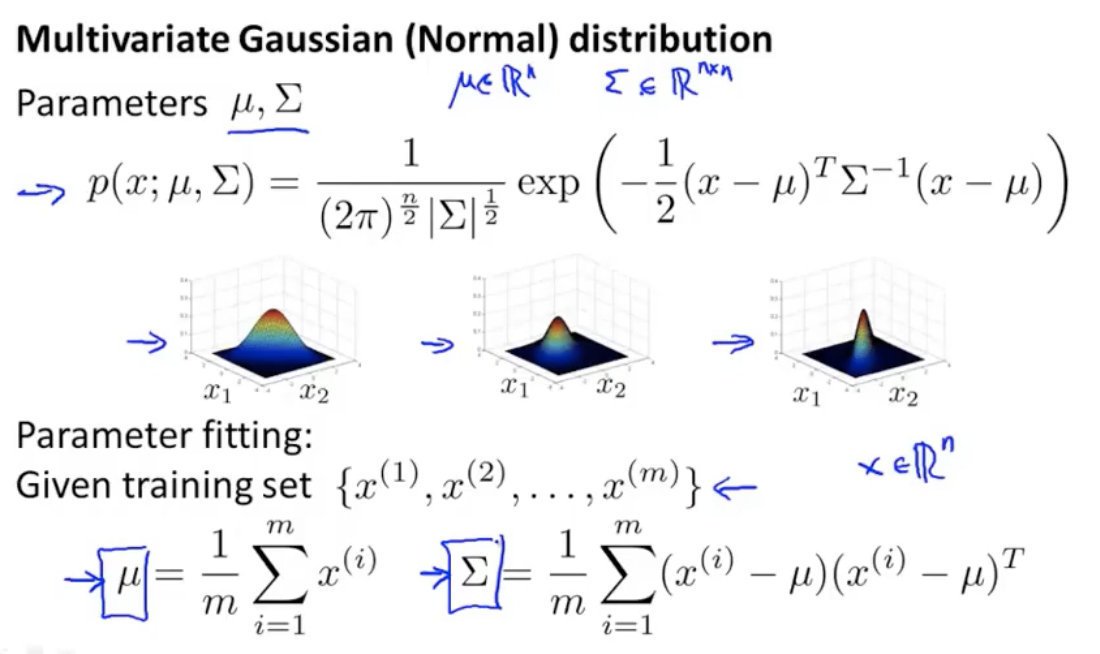

x個特征的高斯分布直接累積有個缺點是不能反映2個特征之間相互關系的影響,
多元高斯分布降特征合在一起建立一個高斯分布模型
5. Original model vs Multivariate Gaussian

-
原始高斯分布和多元高斯分布最大的區別是是否捕捉相關性的特征
-
兩種分布在可視化圖中的區別是:原始高斯分布得到的橢圓是軸對齊的(軸與x軸或y軸平行),而多元高斯分布橢圓軸可以是任意方向,所以原始高斯分布是多元的一種特殊情況,
-
多元高斯分布優點:可以自動尋找特征間的關系,其實原始高斯分布中手動設計特征就是在找特征之間的關系
-
多元高斯分布缺點:需要訓練樣本遠大于特征值,而且計算要求更高,反之原始高斯分布不需要
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/39018.html
標籤:其他
上一篇:監督學習方法
下一篇:機器學習專案完整的作業流程