目錄
- 本章重點
- 排序的概念及其運用
- 排序的概念
- 排序運用
- 常見的排序演算法
- 常見排序演算法的實作
- 插入排序
- 直接插入排序
- 希爾排序
- 選擇排序
- 直接選擇排序
- 堆排序
- 交換排序
- 冒泡排序
- 快速排序
- hoare版本
- 挖坑法
- 雙指標法(推薦)
- 快排的非遞回
- 歸并排序
- 計數排序(非比較排序)
- 內外排序
禿頭俠們好呀,今天咱們來聊聊 排序

本章重點
1.排序的概念及其運用
2.常見排序演算法的實作
3.排序演算法復雜度及穩定性分析
排序的概念及其運用
排序的概念
排序:所謂排序,就是使一串記錄,按照其中的某個或某些關鍵字的大小,遞增或遞減的排列起來的操作,
穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,
內部排序:資料元素全部放在記憶體中的排序,
外部排序:外部排序指的是大檔案的排序,即待排序的記錄存盤在外存盤器上,待排序的檔案無法一次裝入記憶體,需要在記憶體和外部存盤器之間進行多次資料交換,以達到排序整個檔案的目的,
排序運用
還有的等等太多地方都要使用到排序了
常見的排序演算法
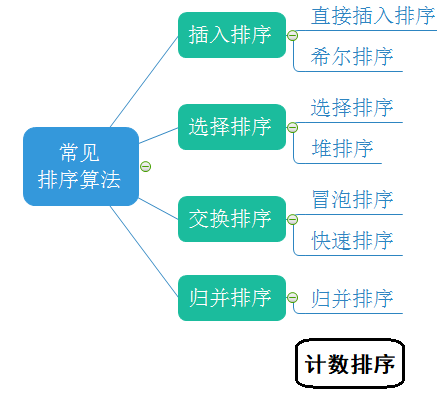
常見排序演算法的實作
插入排序
基本思想:
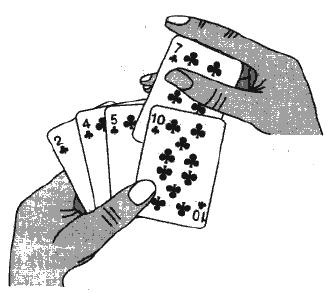
把待排序的記錄按其關鍵碼值的大小逐個插入到一個已經排好序的有序序列中,直到所有的記錄插入完為止,得到一個新的有序序列 ,
實際中我們玩撲克牌時,就用了插入排序的思想
直接插入排序
代碼實作:
void InsertSort(int* a, int n)
{
assert(a);
for (int i = 0; i < n - 1; i++)
{
int end = i;
int x = a[end + 1];
while (end>=0)
{
if (a[end] > x)
{
a[end+1] = a[end];
}
else
{
break;
}
end--;
}
a[end + 1] = x;
}
}
直接插入排序的特性
1、時間復雜度:O(N^2)
最壞O(N^2)— 逆序
最好O(N)—有序或接近有序
2、空間復雜度O(1)
3、穩定性:穩定
4、元素集合越接近有序,直接插入排序演算法的時間效率越高
希爾排序
希爾排序法又稱縮小增量法,是對直接插入排序思想上的優化
基本思想:
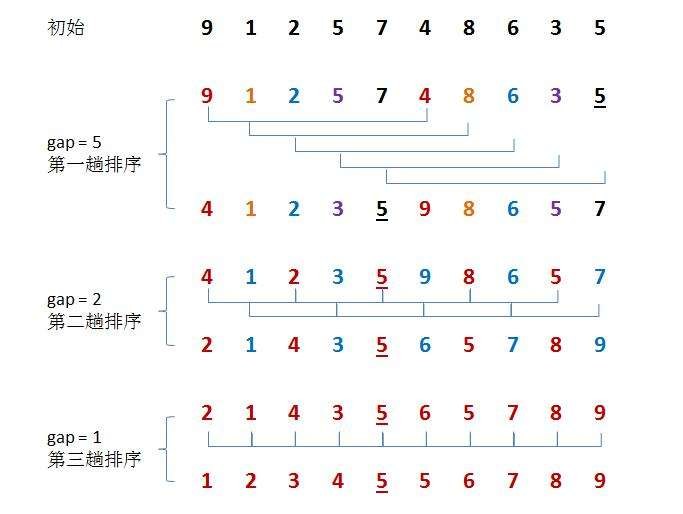
將n個待排序的元素序列,取一個小于n的整數m作為間隔,將全部的n個元素分為m個子序列,所有距離為m的元素放在同一個子序列中,在每個子序列中分別進行直接插入排序;然后,縮小間隔m,比如取m=m/2,重復劃分子序列和排序;直到m==1為止(即將所有元素放在同一個序列中排序),
希爾的想法其實就是:
1、分組預排序,想讓陣列接近有序,讓小數(大數)快速到前面,大數(小數)快速到后面,
2、最后因為陣列已經接近有序,再進行一次直接插入排序
代碼實作:
void ShellSort(int* a, int n)
{
int gap = n;
while (gap>1)
{
gap /= 2;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int x = a[end + gap];
while (end>=0)
{
if (a[end] > a[end + gap])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = x;
}
}
}
希爾排序的特性
- 希爾排序是對直接插入排序的優化,
- 當gap > 1時都是預排序,目的是讓陣列更接近于有序,當gap == 1時,陣列已經接近有序的了,這樣就會很快,這樣整體而言,可以達到優化的效果,
- 希爾排序的時間復雜度不好計算,因為gap的取值方法很多,導致很難去計算,因此在好多書中給出的希爾排序的時間復雜度都不固定,
- 時間復雜度(總結下來一般有這幾種,NlogN以2為底,NlogN以3為底,約等于N^1.3)
- 穩定性:不穩
選擇排序
基本思想:
每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始(末尾)位置,直到全部待排序的資料元素排完 ,
直接選擇排序
在元素集合選出最小的數(或最大的數),放開頭(或者末尾),然后,再找次小的(或次大的),,,
我們這里為了更高效一點,我們直接一次選兩個數,最大和最小,把最小的放開頭,最大的放最后,
代碼實作:
void SelectSort(int* a, int n)
{
assert(a);
int begin = 0;
int end = n - 1;
while (begin<end)
{
int min = begin;
int max = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[min])
min = i;
if (a[i] > a[max])
max = i;
}
Swap(&a[begin], &a[min]);
if (begin == max) //begin==max時,最大值被換走了,修正一下max的位置
max = min;
Swap(&a[end], &a[max]);
begin++;
end--;
}
}
直接選擇排序的特性
- 直接選擇排序思考非常好理解,但是效率不是很好,實際中很少使用
- 時間復雜度:O(N^2)
最好最壞都是O(N^2) - 整體而言最差的排序,因為無論什么情況下都是O(N^2)
- 穩定性:不穩定
堆排序
堆排序(Heapsort)是指利用堆積樹(堆)這種資料結構所設計的一種排序演算法,它是選擇排序的一種,它是通過堆來進行選擇資料,需要注意的是排升序要建大堆,排降序建小堆,
 代碼實作:
代碼實作:
void AdjustDown(int* a, int n, int parent)
{
assert(a);
int child = parent*2 + 1;
while (child<n)
{
if (child + 1 < n && a[child + 1] > a[child])
{
child = child + 1;
}
if (a[child] > a[parent])
{
Swap(&a[child] , &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
for (int end = n - 1; end > 0; end--)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
}
}
堆排序的特性
- 堆排序使用堆來選數,效率就高了很多
- 時間復雜度:O(NlogN)
最好最壞都是O(NlogN) - 空間復雜度:O(1)
- 穩定性:不穩定
具體堆排序問題詳解
交換排序
基本思想:
所謂交換,就是根據序列中兩個記錄鍵值的比較結果來對換這兩個記錄在序列中的位置,交換排序的特點是:將鍵值較大的記錄向序列的尾部移動,鍵值較小的記錄向序列的前部移動,
冒泡排序
第一個數和第二個數比較,第一個大于第二的話交換,然后看第二個和第三個的比較,一趟下來把最大的數放到最后面了,然后不管最后的數,再看前N-1個數,
代碼實作:
void BubbleSort(int* a, int n)
{
assert(a);
int flag = 0;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n - 1 - i; j++)
{
if (a[j] > a[j + 1])
{
flag = 1;
Swap(&a[j], &a[j + 1]);
}
}
if (flag == 0)
break;
}
}
冒泡排序的特性
- 時間復雜度:O(N^2)
最好是O(N)—有序
最壞是O(N^2) - 空間復雜度:O(1)
- 穩定性:穩定
快速排序
快速排序是Hoare于1962年提出的一種二叉樹結構的交換排序方法,
基本思想:
任取待排序元素序列中的某元素作為基準值,按照該排序碼將待排序集合分割成兩子序列,左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值,然后最左右子序列重復該程序,直到所有元素都排列在相應位置上為止,
我們首先來學快排的遞回
先看一下快排遞回的框架
// 假設按照升序對array陣列中[left, right]區間中的元素進行排序
void QuickSort(int*a, int left, int right)
{
if(left>=right)
return;
// 按斬訓準值對陣列的 [left, right]區間中的元素進行劃分
int keyi = partion(a, left, right);
// 劃分成功后以keyi為邊界形成了左右兩部分 [left, keyi-1] 和 [keyi+1, right]
// 遞回排[left, keyi-1]
QuickSort(a, left, keyi-1);
// 遞回排[keyi+1, right]
QuickSort(a, keyi+1, right);
}
上述為快速排序遞回實作的主框架,發現與二叉樹前序遍歷規則非常像,現在我們只需要完成partion部分的選key就可以了,這里介紹3種方法,
hoare版本
 hoare的基本思想:
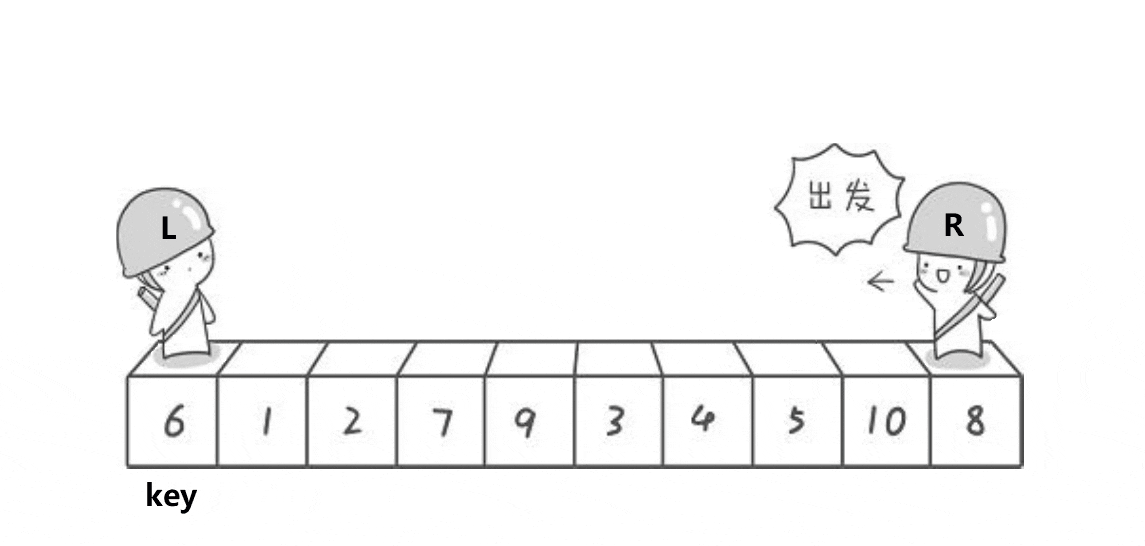
hoare的基本思想:
1、取最左邊的做key,最左邊的為L指標,右邊的為R指標
2、L指標往后走,找比key大的數,R往前走,找比key小的數,找到之后將其交換
3、當L和R相遇時,讓key位置數和相遇處交換,此時key左邊都是小于key的,key右邊都是大于key的
4、此時key的位置就是這個值該待的位置
5、之后再遞回key左邊的區間和key右邊的區間
注意一點:
選左邊的值做key,右邊先走
選右邊的值做key,左邊先走
至于為什么家人們可以帶進去試一試就知道了
代碼實作:
int Partion1(int* a, int left, int right)
{
assert(a);
int keyi = left;
while (left<right)
{
while (left < right && a[left] <= a[keyi])
left++;
while (left < right && a[right] >= a[keyi])
right--;
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
return left;
}
討論一下存在的問題同時也是對快排的優化
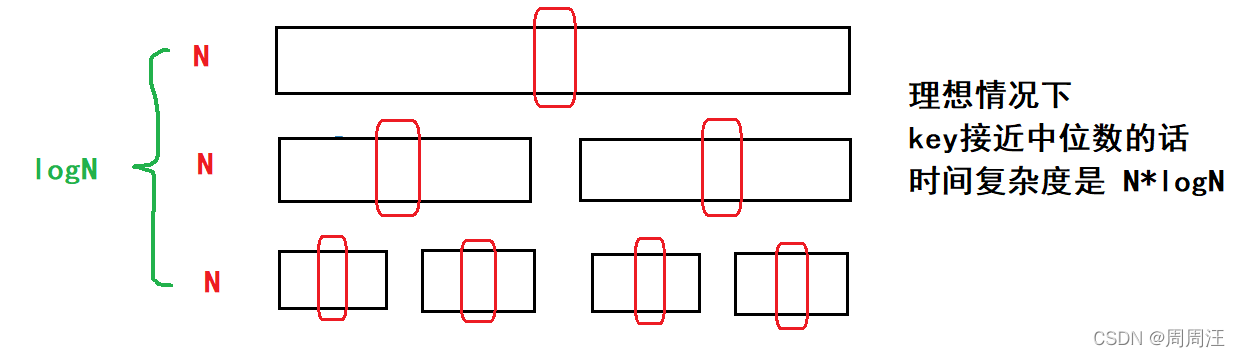
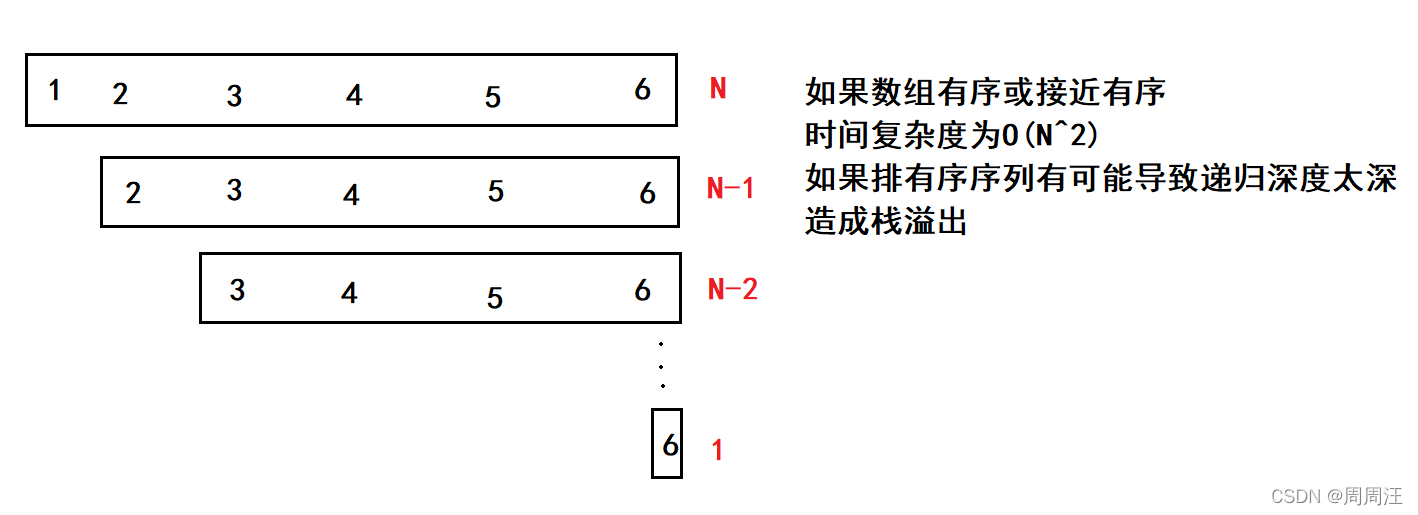 那么怎么解決快排面對有序序列的問題?
那么怎么解決快排面對有序序列的問題?
那就是 三數取中
就是拿最左邊的數,最右邊的數和中間數,三者比較選出不是最大也不是最小的那個作為key,這樣就解決了上述問題,
代碼實作:
int GetMidIndex(int* a, int left, int right)
{
int mid = left + ((right - left) >> 1);//取中間值,這樣寫是怕大于int的最大值溢位
if (a[left] > a[mid])
{
if (a[right] > a[left])
return left;
else if (a[mid] > a[right])
return mid;
else
return right;
}
else
{
if (a[left] > a[right])
return left;
else if (a[right] > a[mid])
return mid;
else
return right;
}
}
挖坑法
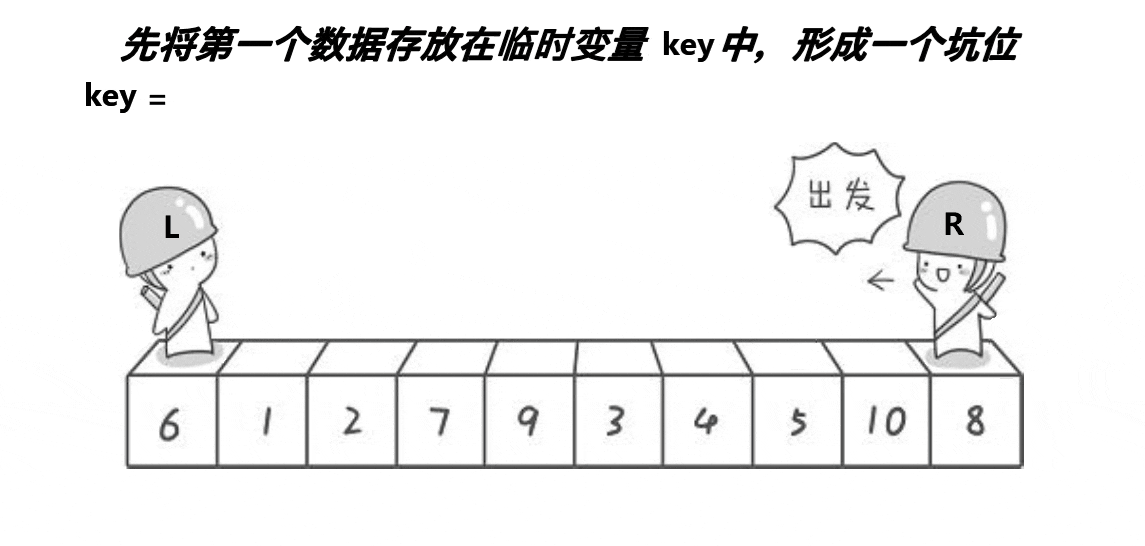 挖坑法的基本思想
挖坑法的基本思想
1、將最左邊的值作為key,并且將該位置作為一個坑位
2、也是有兩個指標L和R,R先向前走,找比key小的值,放到坑位,然后自己成為坑位
3、之后L向后走,找比key大的值,放到剛才的坑位,然后自己變成坑位
4、最后L和R相遇時,把最開始的key值放到相遇處的坑位
5、至此就把key放到它排好序該在的位置了
代碼實作:
void Partion2(int* a, int left, int right)
{
assert(a);
int key = a[left];
int pivot = left;
while (left<right)
{
//右邊找小,放到左邊的坑位
while (left<right && a[right]>=key)
right--;
a[pivot] = a[right];
pivot = right;
//左邊找大,放到右邊的坑位
while (left < right && a[left] <= key)
left--;
a[pivot] = a[left];
pivot = left;
}
a[pivot] = key;
return pivot;
}
雙指標法(推薦)

最后一種方法是雙指標法,也是最推薦的一種方法
雙指標法的基本思想
1、選取最左邊的作為key值
2、雙指標prev和cur
3、cur往后找比key小的值
4、當找到之后,讓prev++然后交換數值
5、等于cur找小往左邊扔,prev把大的數往右邊扔
6、當cur結束的時候,將key和prev交換
7、至此就讓key到了它排好序該在的位置了
代碼實作:
void Partion3(int* a, int left, int right)
{
assert(a);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur<=right)
{
if (a[cur] < a[keyi])
{
prev++;
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}
還有一個地方可以優化
那就是 小區間優化
現在我們已經知道快排是一種二叉樹結構的交換排序法,
二叉樹是遞回的,
而且二叉樹的最后1,2層的遞回次數幾乎是整個二叉樹遞回的次數了,
所以當遞回到最后幾層小區間時,我們可以不再讓其使用快速排序,不讓他再遞回了,
而是使用插入排序
所以最終我們的快排代碼實作:
int Partion3(int* a, int left, int right)
{
assert(a);
int mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[mid]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur<=right)
{
if (a[cur] < a[keyi])
{
prev++;
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}
void QuickSort(int* a, int left,int right)
{
if (left >= right)
return;
if (right - left + 1 < 10)
InsertSort(a + left, right - left + 1);
else
{
int keyi = Partion3(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1,right);
}
}
說完了快排的遞回實作,我們知道遞回函式是在堆疊上開辟空間的,但堆疊的空間很小,如果遞回深度太深,很有可能造成堆疊溢位
(堆疊溢位的原因有二:遞回深度太深;沒有寫回傳出口條件)
遞回相比回圈,性能較差,因為之前講過了,遞回就意味著要開辟和釋放很多次函式堆疊幀,而每次的函式堆疊幀的開辟和釋放都是對時間和空間的消耗,只不過隨著科技進步,現在的編譯器的優化已經很好了(比如VS上的release版本就對函式堆疊幀優化了很多),所以現在的遞回和回圈性能差不了多少了,
快排的非遞回
快排的非遞回運用的是資料結構中的堆疊結構
運用堆疊結構的后進先出,堆疊是malloc出來的了,所以是在堆上開辟的,優勢就很明顯了:
堆比堆疊空間大的多,
代碼實作:
void QuickSortNonR(int* a, int left, int right)
{
assert(a);
ST st;
StackInit(&st);
StackPush(&st, left);
StackPush(&st, right);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin= StackTop(&st);
StackPop(&st);
int keyi = Partion3(a, begin, end);
if (keyi + 1 < end)
{
StackPush(&st, keyi+1);
StackPush(&st, end);
}
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi-1);
}
}
}
快速排序的特性
1、快速排序整體的綜合性能和使用場景都是比較好的,所以才敢叫快速排序
2、時間復雜度:O(N*logN)
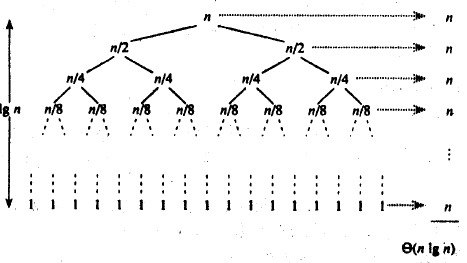
3、空間復雜度:O(logN)
4、穩定性:不穩定
5、快排的非遞回遍歷可以使用堆疊模擬二叉樹的前序遍歷來實作,也可以用佇列模擬二叉樹的層序遍歷來實作,
6、快排的非遞回沒有本質上提高時間效率,時間復雜度沒變,但因為沒有遞回,所以可以減少堆疊空間的開銷
7、快排是基于分治法的一個排序演算法
歸并排序
基本思想:
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(DivideandConquer)的一個非常典型的應用,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
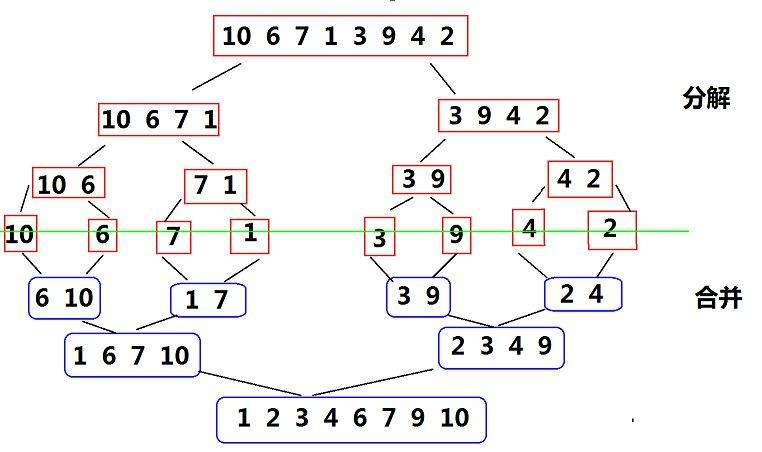
歸并的遞回代碼實作:
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid+1,right, tmp);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1<=end1&&begin2<=end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1<=end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
for (int j = left; j <= right; j++)
{
a[j] = tmp[j];
}
}
void MergeSort(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}
歸并的非遞回代碼實作:
void MergeSortNonR(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
int gap = 1;
while (gap<n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//核心思想:end1,begin2,end2都可能越界,
//end1,begin2都不需要修正
if (end1 >= n || begin2 >= n)
{
break;
}
//當end2越界則需要修正end2
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
for (int j = i; j <= end2; j++)
{
a[j] = tmp[j];
}
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}
歸并的非遞回難點在于邊界控制(即當陣列元素數量不是2的次方數的時候)
歸并排序的特性
- 歸并的缺點在于需要O(N)的空間復雜度,歸并排序的思考更多的是解決在磁盤中的外排序問題,
- 歸并排序是一種二分排序演算法,每次都需要給N個元素排序,排序的程序需要logN,即樹的高度次,所以時間復雜度:O(NlogN)
最好最壞都是O(NlogN) - 空間復雜度:O(N)
- 穩定性:穩定
計數排序(非比較排序)
基本思想:
計數排序又稱為鴿巢原理,是對哈希直接定址法的變形應用,
- 統計相同元素出現次數
- 根據統計的結果將序列回收到原來的序列中
這個排序的思想很巧妙:
找到這個陣列里最大的數N,然后開一個N+1的陣列,下標是從0到N,然后統計這個陣列里各數出現的次數,把相應的次數計數到剛才開的陣列,最后再根據這個計數的陣列,把陣列排序,
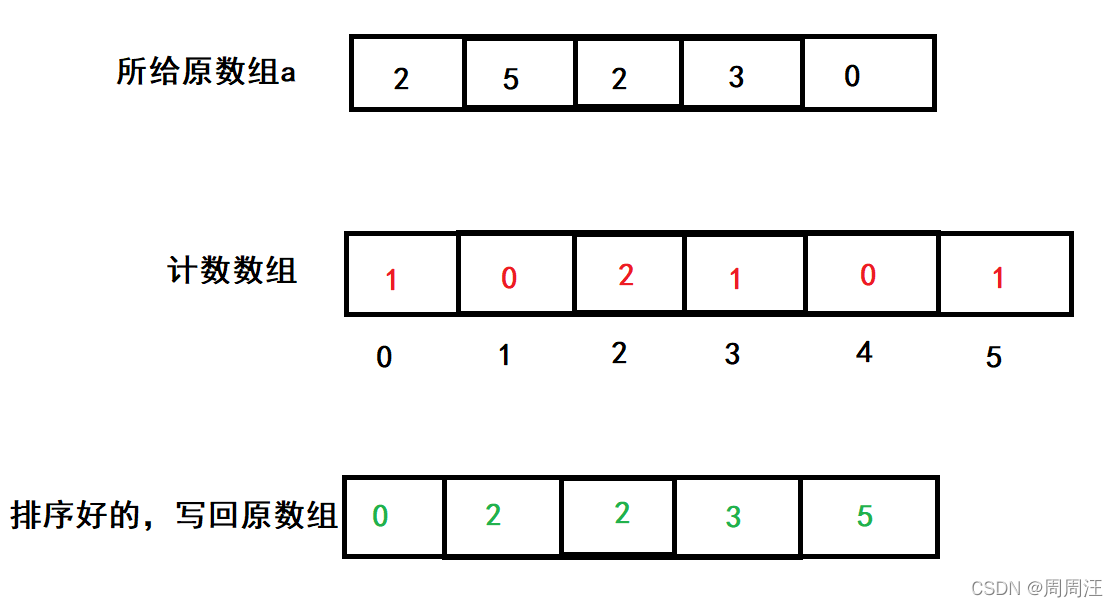
但如果是1000,1001,1002,1200,1500這樣的數列,再直接開1501個空間的話,前1000個都浪費了,所以我們優化一下,開MAX-MIN+1個空間,計數的時候,計數原元素-MIN,最后寫回去的時候再加上MIN就可以了,
代碼實作:
void CountSort(int* a, int n)
{
assert(a);
int max = a[0], min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] < min)
min = a[i];
if (a[i] > max)
max = a[i];
}
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
printf("malloc fail\n");
exit(-1);
}
memset(count, 0, sizeof(int) * range);
//統計次數
for (int i = 0; i < n; i++)
{
count[a[i] - min]++;
}
//根據次數排序
int j = 0;
for (int i = 0; i < range; i++)
{
while (count[i]--)
{
a[j++] = i + min;
}
}
free(count);
count = NULL;
}
計數排序的特性
- 計數排序在資料范圍集中時,效率很高,但是適用范圍及場景有限,比如浮點數
- 可以處理負數
- 時間復雜度:O(MAX(N,range))
- 空間復雜度:O(range)
- 穩定性:不穩定
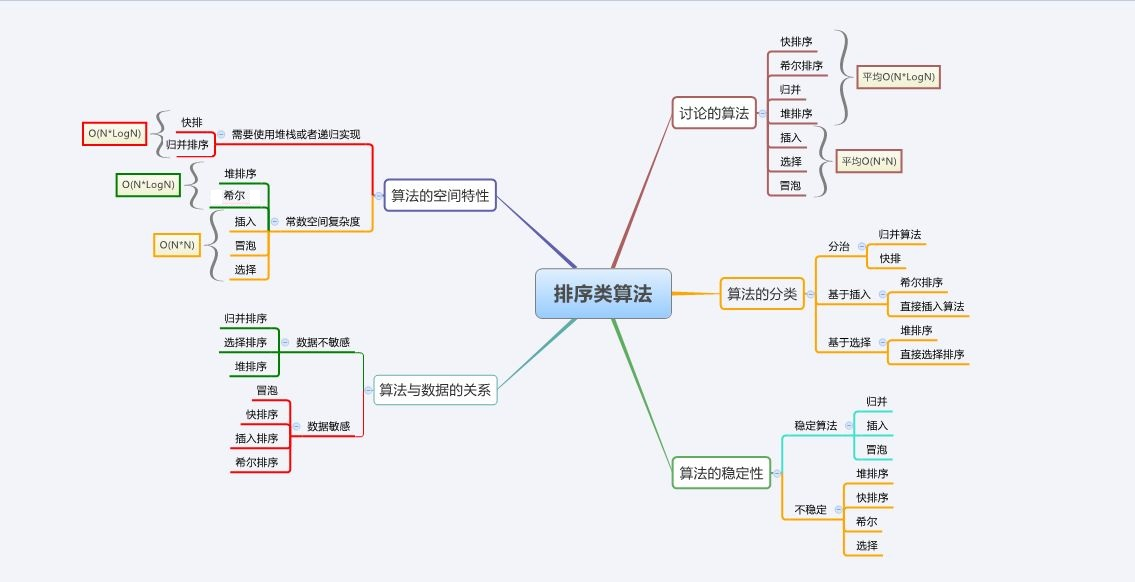
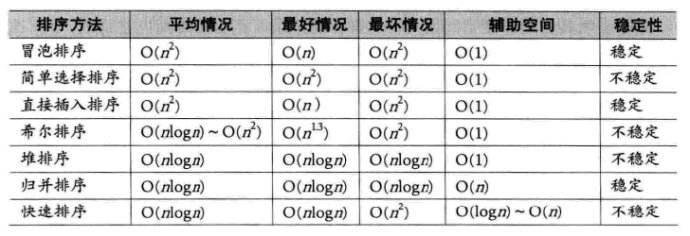
說一下穩定性存在的意義吧
穩定性:
陣列中相同值在排序以后相對位置是否變化,不變就是穩定,變了就是不穩
應用:
比如考試成績,如果兩個人一樣,則需要看誰先交卷,先交卷的排名在前,所以就得保證順序的先后,這種就得用穩定排序了,
內外排序
內部排序:資料元素全部放在記憶體中的排序,
外部排序:外部排序指的是大檔案的排序,即待排序的記錄存盤在外存盤器上,待排序的檔案無法一次裝入記憶體,需要在記憶體和外部存盤器之間進行多次資料交換,以達到排序整個檔案的目的,
舉例:
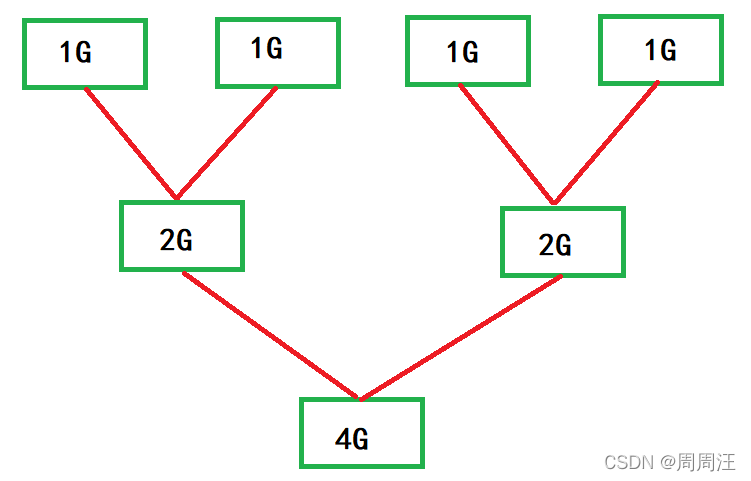
現在讓你對10億個整數排序,但我們只有1G記憶體,怎么排序呢?
1、首先,10億個整數大約占4G記憶體,所以不能用一般的排序,因為他們都需要寫到記憶體上才能排序,
2、我們把4G檔案分為4份,四個小檔案,每個檔案1G;
把1G小檔案的資料加載到記憶體,用快排,排序完再寫回檔案,依次把4個小檔案都給排有序;
3、然后我們用檔案之間的讀寫,用歸并的方法,把兩個1G的歸并成一個2G的,兩個2G的歸并成一個4G的,則這10億個整數就排序好了
感謝閱讀,我們下期再見
如有錯 歡迎提出一起交流
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390340.html
標籤:其他