大資料技術原理與應用 第三版 林子雨 期末復習(一)大資料概述 第一章 P2
- 大資料概念(4V)
- 三次資訊化浪潮(每隔15年發生一次)
- 大資料對于研究思維的影響
- 資料產生的三個階段
- 大資料計算模式
- 大資料與云計算、物聯網
- 概念
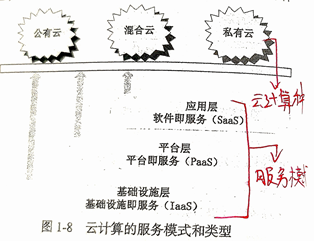
- 云計算種類與服務模式
- 大資料與云計算、物聯網的關系
大資料概念(4V)
1 volume (大量)
隨著傳感器等技術的應用,資料規模逐漸增大,而大資料的規模通常達到PB EB級,
2 variety (多種)
大資料涉及到的資料種類多,包含大量結構化與非結構化資料,
3 velocity (高速)
同一時間下有大量資料產生,并且某些資料價值會隨著時間流逝下降,因此大資料對資料處理的實時性要求較高,
4 value (價值)
對于大資料而言價值密度較低,整體價值較高,很多有價值的資訊分散于海量資料當中,
三次資訊化浪潮(每隔15年發生一次)
| 資訊化浪潮 | 發生時間 | 標志 | 解決問題 |
|---|---|---|---|
| 第一次 | 1980 | 個人計算機 | 資訊處理 |
| 第二次 | 1995 | 互聯網 | 資訊傳輸 |
| 第三次 | 2010 | 大資料、云計算、物聯網 | 資訊爆炸 |
大資料對于研究思維的影響
1 全樣而非抽樣
大資料時代,隨著資料存盤與分析能力的提升,更傾向于使用全樣資料而非抽樣資料解決問題,
2 效率而非精準
由于使用了全樣資料因此在傳統分析方法中誤差的放大問題得以解決,同時由于資料量的激增所以可以犧牲部分精確性保證效率,
3 相關而非因果
在大資料時代更感興趣的是事物之間的相關性而非因果性,
資料產生的三個階段
1 運營式系統階段(被動)
傳統資料產生隨著運營資訊產生而產生,通常存盤于SQL中,
2 原創式系統階段(主動)
智能手機等移動設備的出現加速了用戶原創性內容的產生,
3 感知式系統階段(自動)
物聯網的發展與傳感器的應用最終導致了大資料量的產生,
大資料計算模式
大資料計算模式 解決問題 代表產品
批處理 大規模資料的批量處理 MapReduce Spark
流計算 實時流資料 Stom Flink Spark streaming
圖計算 大規模圖結構 GraphX
查詢分析 大規模資料的存盤管理和查詢分析 Hive
| 大資料計算模式 | 解決問題 | 代表產品 |
|---|---|---|
| 批處理 | 大規模資料的批量處理 | MapReduce、Spark |
| 流計算 | 實時流資料 | Stom、Flink、Spark streaming |
| 圖計算 | 大規模圖結構 | GraphX |
| 查詢分析 | 大規模資料的存盤管理和查詢分析 | Hive |
大資料與云計算、物聯網
概念
云計算:通過網路獲取計算資源,
物聯網:物物聯網,可以看作互聯網的延伸,
云計算種類與服務模式
大資料與云計算、物聯網的關系
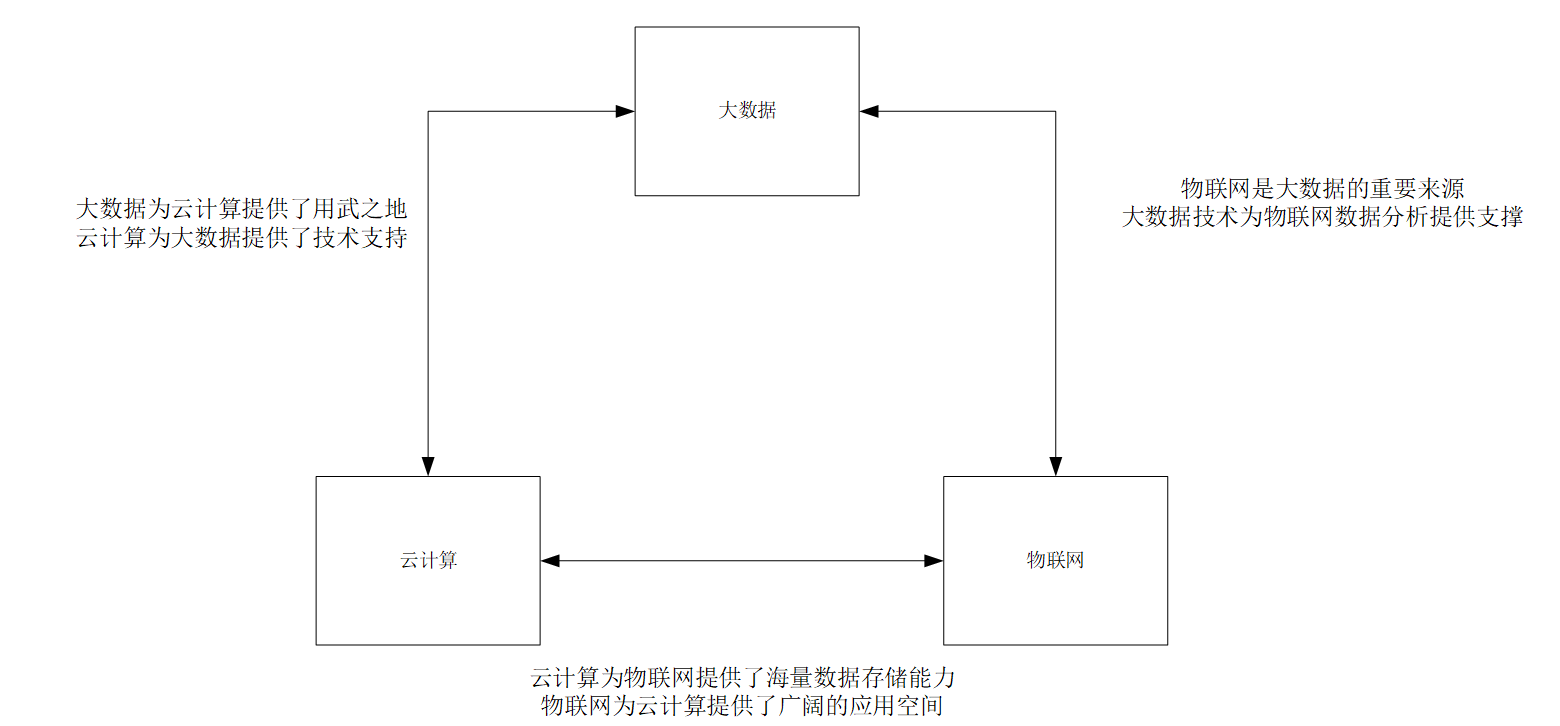
大資料注重于對海量資料的存盤、處理、分析,
云計算注重于通過網路提供廉價計算資源,
物聯網側重實作物物相連,是創新應用開發核心,
本文及后續文章內容均由個人總結,僅用于復習記錄,如發現錯誤請大家伙指正,侵刪,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390473.html
標籤:其他
上一篇:移植 MicroPython