字串
首先,先說什么是字串,簡而言之就是雙引號引起的一串字符被稱為字串,
它的結束標志是\0,具體什么意思呢,我們后面會具體說到,
上節我們知道,c語言給我們提供了很多資料型別,其中包括整型,浮點型,字符型等等一系列的型別
但是c語言并沒有給我們提供字串型別的變數,那這樣我們該如何創建呢?
首先,字串是由一系列字符組成的,但我們只可以創建字符型別的變數,那么怎么成為很多個字符變數在一起呢?
陣列,對陣列,陣列可以把相同型別的變數存放到一起,只要我們把很多char既字符型別的變數放到一起便可以構成字串了,
形式如下:
char arr1[]="abcde";
它的意思是把"abcde"這一個字串存放到arr1陣列中,
這樣我們就成功創建并初始化了一個字串,
與此同時,它還有另外一種初始化的方法,
char arr2[]={'a','b','c','d','e'};
那它的意思是不是把"abcde"存放到arr2中呢?
我們接下來輸出它們:
char arr1[] = "abcde";
char arr2[] = { 'a','b','c','d','e' };
printf("%s\n", arr1);
printf("%s\n", arr2);輸出結果如下:
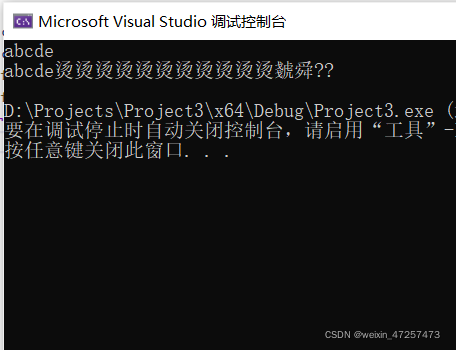
很明顯,arr1符合我們的才想,但arr2好像出了點問題,這是為什么呢?
大家還記得我剛開始說的\0是字串的結束標志嗎,其實問題就出在這里了,
原來,我們創建arr1時我們是以一個字串形式傳進去的,編譯器會自動在末尾加上\0
但是arr2是一個字符一個字符的傳入,最后并沒有結束標志,既然沒有了結束標志,那字串就會一直往后讀取,后面的是什么我們也不知道,于是就會出現了“燙燙”這一列的亂碼,至于最后為什么停下來了,是因為往后讀取的時候隨機遇到了\0,所以停下來了,
所以arr2應該怎樣改進呢,很簡單,就是加上\0,如下:
char arr2[]={'a','b','c','d','e','\0'};
改進之后我們再運行:
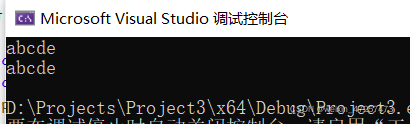
結果一樣,完美解決!
以上就是字串的兩種常見的創建及初始化的方式,
小拓展:一個漢字占兩個字符,
strlen庫函式(string庫函式)
既然\0是結束標志,那么它算不算是字串中的一個字符呢?
先來說strlen,strlen是用來計算字串的長度,注意只能是字串,
那我們來測驗一下吧:
在使用之前,我們得先呼叫相應的庫函式
#include<string.h>
char arr1[] = { 'a','b','c','d','e','\0' };
printf("%d", strlen(arr1));運行結果如下:
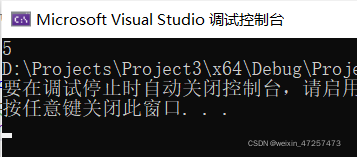
結果是5,然而我們已經有5個字符abcde了,說明\0并沒有算入其中
也就是說strlen只能計算字串中\0之前的長度
當然,我們在這里還可以用這個函式來驗證一下上面那個arr2的長度是不是一個隨機值,
代碼如下:
#include<stdio.h>
#include<string.h>
int main()
{
char arr1[] = "abcde";
char arr2[] = { 'a','b','c','d','e'};
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
return 0;
}此時我們沒有給arr2加\0,
輸出結果如下:
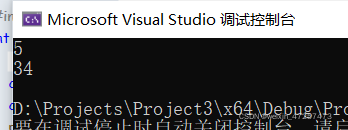
怎么樣,arr2是不是個隨機值,你們可以在各自電腦上嘗試一下,第二個數字都不會一樣的,
當我們加上\0時
char arr2[] = { 'a','b','c','d','e','\0'};
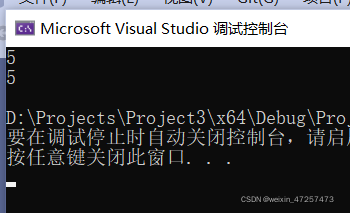
至此也驗證了我們的思想是正確的,
小結:
字串是被雙引號引起來的一系列字符,c語言中沒有字串型別,必須用
字符陣列(如:char a[]={‘0’};)來創建和初始化
strlen函式是用來計算字串的長度的(字串),計算時,\0不計入其內,
轉義字符
顧名思義,就是把一個字符的意思改變了,轉變成了別的意思,下面給大家介紹并解釋一些常見的轉義字符的用法,
/n
/n是換行的意思,即將滑鼠游標移到下一行,
有的同學可能注意到前面我輸出arr1和arr2是,在%s后面加了個\n,其實這個\n就是一個轉義字符,意為換行的意思,所以你會看到arr1和arr2的內容分別在一行,而不是在一列,
\b表示退格符,將滑鼠游標向前移動一個字符,
\a電腦發出一聲蜂鳴聲
\f換頁
\t水平制表符,就相當于按一下鍵盤上的Tab鍵,占8個空格,每個電腦可能占得格數不一樣,
\v垂直制表符
\\防轉義(防止\被轉義成一個轉義字符)
如果不太理解,我們看接下來的例子
比如你要輸出
c:\test\test.c
我們寫
printf("c:\test\test.c");我們看輸出結果是否符合我們的猜想:
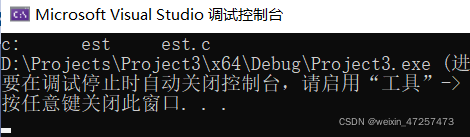
很遺憾,程式并沒有達到我們想要的效果,這是為什么呢?仔細一看,原來\t消失了,再一想,\t不是一個轉義字符嗎,加上上圖的那些空格,我們可以確定:
\t被轉義了,轉成水平制表符了,所以會有空格,
但我們就要輸出c:\test\test.c,有什么辦法呢?
我們只需要在\t前面再加一個\,意思是不讓\t轉義成別的意思,所以代碼改進如下:
printf("c:\\test\\test.c");輸出結果如下:

這樣就達到我們預期的效果啦,
同樣其實你可以舉一反三的完成下面的問題
比如你就要單純的輸出一個'
你這樣寫:
printf("%c",''');我們輸出一下:
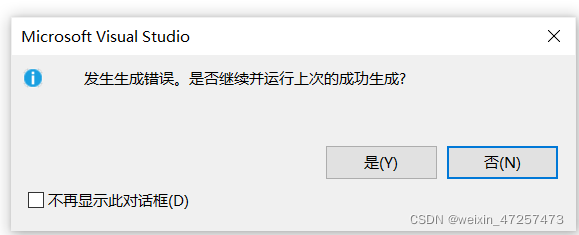
程式又報錯了,
這是怎么一回事呢,其實程式在執行時,第一個'和第二個'會結合在一起,會留下了第三個',此時當然不符合c語言語法了,所以我們為了避免這種情況發生,可以在第二個就是你想輸入的那個符號前面加個\,就是轉變它原來的意思,不再是原來 ' 的意思,所以他就不會和第一個 ' 再結合了
改進如下:
printf("%c", '\'');此時我們運行:
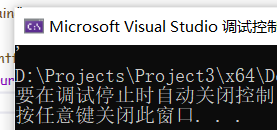
成功輸出了!達到我們預期的效果啦,
輸出單個"也是同樣的道理,
下面來到了一個很重要的轉義了
\ddd與\xdd
\ddd
ddd表示1~3個八進制數字,如\130
那它具體是什么作用呢?
我們接下來看下面的代碼:
printf("%c\n",'\130');輸出結果會是什么呢?
130?130的十進制?
結果如下:
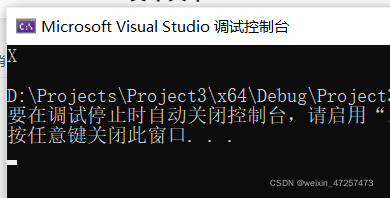
結果是X!???可能會有人說數字怎么會成為了字母,你這程式有問題啊!
其實呢 是代表它的十進制的ASCII碼值,
比如我們把130轉化為十進制,就是8^0*0+8^1*3+^2*1=88,后面我會專門出一節精講進制轉化之類的問題的
八進制的130轉化為十進制是88,可以發現88對應的ASCII碼值正好是X,這也就符合了我剛才說的了,
結論:/130的意思是把130這個八進制數字轉化成10機制數字后的88,作為ASCII碼值代表的字符
/xdd,dd表示兩個16進制數字
例如:
printf("c",'\x31');這會也是同樣的道理,先把16進制的31轉化成十進制,既1*16^0+3*16^1=49作為ASCII值,所代表的字符是‘1’;下面看輸出結果:
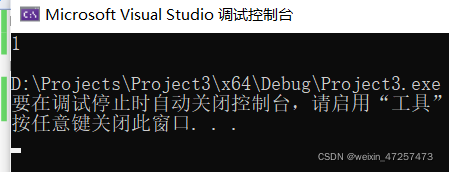
結果對了!
最后,我們再來練一道題吧,一定要細心哦!
printf("%d\n",strlen("c:\test\628\test.c"));
上面忘記說了,轉義字符算作是一個字符,如\t,\b,\n等等都是占用1個字符,既占一個長度,
結果是多少呢?
18?13?14?
我們看結果吧
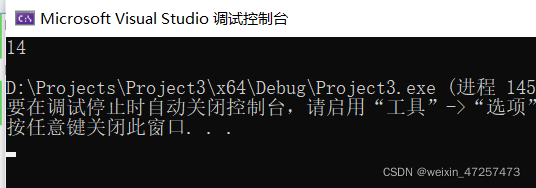
其實很大一部分人都是13,因為\t一個字符,\628也是一個字符,加起來應該是13個,為什么是14個呢?
這里我們注意了,\628它真的是3個八進制數字嗎,很明顯最后一個不是啊,是個8,八進制范圍是0~7,所以不屬于哪個八進制數字里面的了,既\62才一個字符,8被單獨出來又算作是一個字符,所以總共是14個
那有的同學就會說,那好把8改成7,小于8不就行了嗎?
我們再來試試:
printf("%d\n", strlen("c:\test\627\test.c"));誒,你猜猜結果是什么?
14?13?
結果如下:
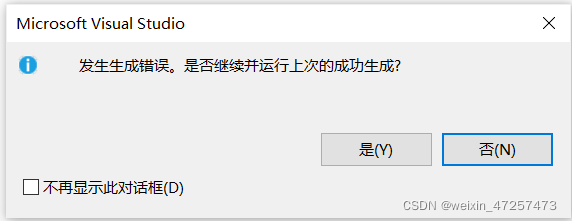
哈哈,是不是很不可思議啊,明明改成7了為什么反而報錯了呢?
我們來看錯誤原因:

407,emm,我們把八進制的627轉化成10進制,發現恰好是407,對字符來說太大?
我們回顧剛才講的,就是把八進制的數字轉化127成10進制然后轉化成對應的ascii碼值
ASCII值最大值才是127,它都407了肯定不行了
可能會有些已經稍微有點暈的同學說了,那\628為什么運行了,他也超過了127啊,哈哈,8不是不是八進制數字嗎,所以轉化的是\62,轉化成10進制是50在范圍之內,當然能運行了,
以上就是這次的所有內容啦,如果有任何疑問或者指導意見,歡迎私聊我或評論區留言哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/392113.html
標籤:其他