第一章 計算機系統概論
\1. 什么是計算機系統、計算機硬體和計算機軟體?硬體和軟體哪個更重要?
解:P3
計算機系統:由計算機硬體系統和軟體系統組成的綜合體,
計算機硬體:指計算機中的電子線路和物理裝置,
計算機軟體:計算機運行所需的程式及相關資料,
硬體和軟體在計算機系統中相互依存,缺一不可,因此同樣重要,
\5. 馮?諾依曼計算機的特點是什么?
解:馮?諾依曼計算機的特點是:P8
l 計算機由運算器、控制器、存盤器、輸入設備、輸出設備五大部件組成;
l 指令和資料以同同等地位存放于存盤器內,并可以按地址訪問;
l 指令和資料均用二進制表示;
l 指令由操作碼、地址碼兩大部分組成,操作碼用來表示操作的性質,地址碼用來表示運算元在存盤器中的位置;
l 指令在存盤器中順序存放,通常自動順序取出執行;
l 機器以運算器為中心(原始馮?諾依曼機),
\7. 解釋下列概念:
主機、CPU、主存、存盤單元、存盤元件、存盤基元、存盤元、存盤字、存盤字長、存盤容量、機器字長、指令字長,
解:P9-10
主機:是計算機硬體的主體部分,由CPU和主存盤器MM合成為主機,
CPU:中央處理器,是計算機硬體的核心部件,由運算器和控制器組成;(早期的運算器和控制器不在同一芯片上,現在的CPU內除含有運算器和控制器外還集成了CACHE),
主存:計算機中存放正在運行的程式和資料的存盤器,為計算機的主要作業存盤器,可隨機存取;由存盤體、各種邏輯部件及控制電路組成,
存盤單元:可存放一個機器字并具有特定存盤地址的存盤單位,
存盤元件:存盤一位二進制資訊的物理元件,是存盤器中最小的存盤單位,又叫存盤基元或存盤元,不能單獨存取,
存盤字:一個存盤單元所存二進制代碼的邏輯單位,
存盤字長:一個存盤單元所存二進制代碼的位數,
存盤容量:存盤器中可存二進制代碼的總量;(通常主、輔存容量分開描述),
機器字長:指CPU一次能處理的二進制資料的位數,通常與CPU的暫存器位數有關,
指令字長:一條指令的二進制代碼位數,
\8. 解釋下列英文縮寫的中文含義:
CPU、PC、IR、CU、ALU、ACC、MQ、X、MAR、MDR、I/O、MIPS、CPI、FLOPS
解:全面的回答應分英文全稱、中文名、功能三部分,
CPU:Central Processing Unit,中央處理機(器),是計算機硬體的核心部件,主要由運算器和控制器組成,
PC:Program Counter,程式計數器,其功能是存放當前欲執行指令的地址,并可自動計數形成下一條指令地址,
IR:Instruction Register,指令暫存器,其功能是存放當前正在執行的指令,
CU:Control Unit,控制單元(部件),為控制器的核心部件,其功能是產生微操作命令序列,
ALU:Arithmetic Logic Unit,算術邏輯運算單元,為運算器的核心部件,其功能是進行算術、邏輯運算,
ACC:Accumulator,累加器,是運算器中既能存放運算前的運算元,又能存放運算結果的暫存器,
MQ:Multiplier-Quotient Register,乘商暫存器,乘法運算時存放乘數、除法時存放商的暫存器,
X:此字母沒有專指的縮寫含義,可以用作任一部件名,在此表示運算元暫存器,即運算器中作業暫存器之一,用來存放運算元;
MAR:Memory Address Register,存盤器地址暫存器,在主存中用來存放欲訪問的存盤單元的地址,
MDR:Memory Data Register,存盤器資料緩沖暫存器,在主存中用來存放從某單元讀出、或要寫入某存盤單元的資料,
I/O:Input/Output equipment,輸入/輸出設備,為輸入設備和輸出設備的總稱,用于計算機內部和外界資訊的轉換與傳送,
MIPS:Million Instruction Per Second,每秒執行百萬條指令數,為計算機運算速度指標的一種計量單位,
\9. 畫出主機框圖,分別以存數指令“STA M”和加法指令“ADD M”(M均為主存地址)為例,在圖中按序標出完成該指令(包括取指令階段)的資訊流程(如→①),假設主存容量為256M*32位,在指令字長、存盤字長、機器字長相等的條件下,指出圖中各暫存器的位數,
解:主機框圖如P13圖1.11所示,
(1)STA M指令:PC→MAR,MAR→MM,MM→MDR,MDR→IR,
OP(IR) →CU,Ad(IR) →MAR,ACC→MDR,MAR→MM,WR
(2)ADD M指令:PC→MAR,MAR→MM,MM→MDR,MDR→IR,
? OP(IR) →CU,Ad(IR) →MAR,RD,MM→MDR,MDR→X,ADD,ALU→ACC,ACC→MDR,WR
假設主存容量256M*32位,在指令字長、存盤字長、機器字長相等的條件下,ACC、X、IR、MDR暫存器均為32位,PC和MAR暫存器均為28位,
\11. 指令和資料都存于存盤器中,計算機如何區分它們?
解:計算機區分指令和資料有以下2種方法:
l 通過不同的時間段來區分指令和資料,即在取指令階段(或取指微程式)取出的為指令,在執行指令階段(或相應微程式)取出的即為資料,
l 通過地址來源區分,由PC提供存盤單元地址的取出的是指令,由指令地址碼部分提供存盤單元地址的取出的是運算元,
第3章 系統總線
\1. 什么是總線?總線傳輸有何特點?為了減輕總線負載,總線上的部件應具備什么特點?
答:P41.總線是多個部件共享的傳輸部件,
總線傳輸的特點是:某一時刻只能有一路資訊在總線上傳輸,即分時使用,
為了減輕總線負載,總線上的部件應通過三態驅動緩沖電路與總線連通,
\4. 為什么要設定總線判優控制?常見的集中式總線控制有幾種?各有何特點?哪種方式回應時間最快?哪種方式對電路故障最敏感?
答:總線判優控制解決多個部件同時申請總線時的使用權分配問題;
常見的集中式總線控制有三種:鏈式查詢、計數器定時查詢、獨立請求;
特點:鏈式查詢方式連線簡單,易于擴充,對電路故障最敏感;計數器定時查詢方式優先級設定較靈活,對故障不敏感,連線及控制程序較復雜;獨立請求方式速度最快,但硬體器件用量大,連線多,成本較高,
\5. 解釋下列概念:總線寬度、總線帶寬、總線復用、總線的主設備(或主模塊)、總線的從設備(或從模塊)、總線的傳輸周期和總線的通信控制,
答:P46,
總線寬度:通常指資料總線的根數;
總線帶寬:總線的資料傳輸率,指單位時間內總線上傳輸資料的位數;
總線復用:指同一條信號線可以分時傳輸不同的信號,
總線的主設備(主模塊):指一次總線傳輸期間,擁有總線控制權的設備(模塊);
總線的從設備(從模塊):指一次總線傳輸期間,配合主設備完成資料傳輸的設備(模塊),它只能被動接受主設備發來的命令;
總線的傳輸周期:指總線完成一次完整而可靠的傳輸所需時間;
總線的通信控制:指總線傳送程序中雙方的時間配合方式,
\6. 比較同步通信和異步通信,
答:同步通信:指由統一時鐘控制的通信,控制方式簡單,靈活性差,當系統中各部件作業速度差異較大時,總線作業效率明顯下降,適合于速度差別不大的場合,
異步通信:指沒有統一時鐘控制的通信,部件間采用應答方式進行聯系,控制方式較同步復雜,靈活性高,當系統中各部件作業速度差異較大時,有利于提高總線作業效率,
\7. 畫圖說明異步通信中請求與回答有幾種互鎖關系
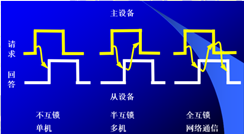
1)不互鎖方式:
主模塊發出請求請求信號后,不必等待從模塊的回答信號,而是經過一段時間,確認從模塊已收到請求信號后,便撤銷其請求信號;從模塊接收請求信號后,在條件允許時發出回答信號,并且經過一段時間(這段時間的設定對不同設備而言是不同的)確認主模塊已收到回答信號后,自動撤銷回答信號,
2)半互鎖方式:
主模塊發出請求信號,必須待接到從模塊的回答信號后再撤銷其請求信號,有互鎖關系;而從模塊在接到請求信號后發出回答信號,但不必等待獲知主模塊的請求信號已經撤銷,而是隔一段時間后自動撤銷其回答信號,無互鎖關系,由于一方存在互鎖關系,一方不存在互鎖關系,故稱為半互鎖方式,
3)全互鎖方式:
主模塊發出請求信號后,必須待從模塊回答后再撤銷其請求信號;從模塊發出回答信號后,必須待獲知主模塊請求信號已撤銷后,再撤回其回答信號,雙方存在互鎖關系,故稱為全互鎖方式,
\8. 為什么說半同步通信同時保留了同步通信和異步通信的特點?
答:半同步通信既能像同步通信那樣由統一時鐘控制,又能像異步通信那樣允許傳輸時間不一致,因此作業效率介于兩者之間,
3.14 設總線的時鐘頻率為8MHz,一個總線周期等于一個時鐘周期,如果一個總線周期中并行傳送16位資料,試問總線的帶寬是多少?
解;總線寬度 = 16位/8 =2B 總線帶寬 = 8MHz×2B =16MB/s
3.15 在一個32位的總線系統中,總線的時鐘頻率為66MHz,假設總線最短傳輸周期為4個時鐘周期,試計算總線的最大資料傳輸率,若想提高資料傳輸率,可采取什么措施?
解法1: 總線寬度 =32位/8 =4B 時鐘周期 =1/ 66MHz =0.015μs
總線最短傳輸周期 =0.015μs×4 =0.06μs
總線最大資料傳輸率 = 4B/0.06μs =66.67MB/s
解法2: 總線作業頻率 = 66MHz/4 =16.5MHz 總線最大資料傳輸率=16.5MHz×4B =66MB/s
若想提高總線的資料傳輸率,可提高總線的時鐘頻率,或減少總線周期中的時鐘個數,或增加總線寬度,
3.16 在異步串行傳送系統中,字符格式為:1個起始位、8個資料位、1個校驗位、2個終止位,若要求每秒傳送120個字符,試求傳送的波特率和位元率,
解: 一幀 =1+8+1+2 =12位 波特率 =120幀/秒×12位=1440波特
位元率 = 1440波特×(8/12)=960bps或:位元率 = 120幀/秒×8 =960bps
第4章 存盤器
\1. 解釋概念:主存、輔存、Cache、RAM、SRAM、DRAM、ROM、PROM、EPROM、EEPROM、CDROM、Flash Memory,
答:主存:主存盤器,用于存放正在執行的程式和資料,CPU可以直接進行隨機讀寫,訪問速度較高,
輔存:輔助存盤器,用于存放當前暫不執行的程式和資料,以及一些需要永久保存的資訊,
Cache:高速緩沖存盤器,介于CPU和主存之間,用于解決CPU和主存之間速度不匹配問題,
RAM:半導體隨機存取存盤器,主要用作計算機中的主存,
SRAM:靜態半導體隨機存取存盤器,
DRAM:動態半導體隨機存取存盤器,
ROM:掩膜式半導體只讀存盤器,由芯片制造商在制造時寫入內容,以后只能讀出而不能寫入,
PROM:可編程只讀存盤器,由用戶根據需要確定寫入內容,只能寫入一次,
EPROM:紫外線擦寫可編程只讀存盤器,需要修改內容時,現將其全部內容擦除,然后再編程,擦除依靠紫外線使浮動柵極上的電荷泄露而實作,
EEPROM:電擦寫可編程只讀存盤器,
CDROM:只讀型光碟,
Flash Memory:閃速存盤器,或稱快擦型存盤器,
\3. 存盤器的層次結構主要體現在什么地方?為什么要分這些層次?計算機如何管理這些層次?
答:存盤器的層次結構主要體現在Cache-主存和主存-輔存這兩個存盤層次上,
Cache-主存層次在存盤系統中主要對CPU訪存起加速作用,即從整體運行的效果分析,CPU訪存速度加快,接近于Cache的速度,而尋址空間和位價卻接近于主存,
主存-輔存層次在存盤系統中主要起擴容作用,即從程式員的角度看,他所使用的存盤器其容量和位價接近于輔存,而速度接近于主存,
綜合上述兩個存盤層次的作用,從整個存盤系統來看,就達到了速度快、容量大、位價低的優化效果,
主存與CACHE之間的資訊調度功能全部由硬體自動完成,而主存與輔存層次的調度目前廣泛采用虛擬存盤技術實作,即將主存與輔存的一部分通過軟硬結合的技術組成虛擬存盤器,程式員可使用這個比主存實際空間(物理地址空間)大得多的虛擬地址空間(邏輯地址空間)編程,當程式運行時,再由軟、硬體自動配合完成虛擬地址空間與主存實際物理空間的轉換,因此,這兩個層次上的調度或轉換操作對于程式員來說都是透明的,
\4. 說明存取周期和存取時間的區別,
解:存取周期和存取時間的主要區別是:存取時間僅為完成一次操作的時間,而存取周期不僅包含操作時間,還包含操作后線路的恢復時間,即:
存取周期 = 存取時間 + 恢復時間
\5. 什么是存盤器的帶寬?若存盤器的資料總線寬度為32位,存取周期為200ns,則存盤器的帶寬是多少?
解:存盤器的帶寬指單位時間內從存盤器進出資訊的最大數量,
存盤器帶寬 = 1/200ns ×32位 = 160M位/秒 = 20MB/秒 = 5M字/秒
注意:字長32位,不是16位,(注:1ns=10-9s)
\6. 某機字長為32位,其存盤容量是64KB,按字編址它的尋址范圍是多少?若主存以位元組編址,試畫出主存字地址和位元組地址的分配情況,
解:存盤容量是64KB時,按位元組編址的尋址范圍就是64K,
如按字編址,其尋址范圍為:64K / (32/8)= 16K
主存字地址和位元組地址的分配情況:如圖
\7. 一個容量為16K×32位的存盤器,其地址線和資料線的總和是多少?當選用下列不同規格的存盤芯片時,各需要多少片?
1K×4位,2K×8位,4K×4位,16K×1位,4K×8位,8K×8位
解:地址線和資料線的總和 = 14 + 32 = 46根;
選擇不同的芯片時,各需要的片數為:
1K×4:(16K×32) / (1K×4) = 16×8 = 128片
2K×8:(16K×32) / (2K×8) = 8×4 = 32片
4K×4:(16K×32) / (4K×4) = 4×8 = 32片
16K×1:(16K×32)/ (16K×1) = 1×32 = 32片
4K×8:(16K×32)/ (4K×8) = 4×4 = 16片
8K×8:(16K×32) / (8K×8) = 2×4 = 8片
\9. 什么叫重繪?為什么要重繪?說明重繪有幾種方法,
解:重繪:對DRAM定期進行的全部重寫程序;
重繪原因:因電容泄漏而引起的DRAM所存資訊的衰減需要及時補充,因此安排了定期重繪操作;
常用的重繪方法有三種:集中式、分散式、異步式,
集中式:在最大重繪間隔時間內,集中安排一段時間進行重繪,存在CPU訪存死時間,
分散式:在每個讀/寫周期之后插入一個重繪周期,無CPU訪存死時間,
異步式:是集中式和分散式的折衷,
\10. 半導體存盤器芯片的譯碼驅動方式有幾種?
解:半導體存盤器芯片的譯碼驅動方式有兩種:線選法和重合法,
線選法:地址譯碼信號只選中同一個字的所有位,結構簡單,費器材;
重合法:地址分行、列兩部分譯碼,行、列譯碼線的交叉點即為所選單元,這種方法通過行、列譯碼信號的重合來選址,也稱矩陣譯碼,可大大節省器材用量,是最常用的譯碼驅動方式,
\11. 一個8K×8位的動態RAM芯片,其內部結構排列成256×256形式,存取周期為0.1μs,試問采用集中重繪、分散重繪和異步重繪三種方式的重繪間隔各為多少?
解:采用分散重繪方式重繪間隔為:2ms,其中重繪死時間為:256×0.1μs=25.6μs
采用分散重繪方式重繪間隔為:256×(0.1μs+×0.1μs)=51.2μs
采用異步重繪方式重繪間隔為:2ms
\15. 設CPU共有16根地址線,8根資料線,并用(低電平有效)作訪存控制信號,
作讀寫命令信號(高電平為讀,低電平為寫),現有下列存盤芯片:ROM(2K×8位,4K×4位,8K×8位),RAM(1K×4位,2K×8位,4K×8位),及74138譯碼器和其他門電路(門電路自定),試從上述規格中選用合適芯片,畫出CPU和存盤芯片的連接圖,要求:
(1)最小4K地址為系統程式區,4096~16383地址范圍為用戶程式區,
(2)指出選用的存盤芯片型別及數量,
(3)詳細畫出片選邏輯,
解:(1)地址空間分配圖:
? 系統程式區(ROM共4KB):0000H-0FFFH
? 用戶程式區(RAM共12KB):1000H-3FFFH
(2)選片:ROM:選擇4K×4位芯片2片,位并聯
? RAM:選擇4K×8位芯片3片,字串聯(RAM1地址范圍為:1000H-1FFFH,RAM2地址范圍為2000H-2FFFH, RAM3地址范圍為:3000H-3FFFH)
(3)各芯片二進制地址分配如下:
| A15 | A14 | A13 | A12 | A11 | A10 | A9 | A8 | A7 | A6 | A5 | A4 | A3 | A2 | A1 | A0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ROM1,2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| RAM1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| RAM2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| RAM3 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
CPU和存盤器連接邏輯圖及片選邏輯如下圖(3)所示:
圖(3)
\17. 寫出1100、1101、1110、1111對應的漢明碼,
解:有效資訊均為n=4位,假設有效資訊用b4b3b2b1表示
校驗位位數k=3位,(2k>=n+k+1)
設校驗位分別為c1、c2、c3,則漢明碼共4+3=7位,即:c1c2b4c3b3b2b1
校驗位在漢明碼中分別處于第1、2、4位
c1=b4⊕b3⊕b1
c2=b4⊕b2⊕b1
c3=b3⊕b2⊕b1
當有效資訊為1100時,c3c2c1=110,漢明碼為0111100,
當有效資訊為1101時,c3c2c1=001,漢明碼為1010101,
當有效資訊為1110時,c3c2c1=000,漢明碼為0010110,
當有效資訊為1111時,c3c2c1=111,漢明碼為1111111,
\18. 已知收到的漢明碼(按配偶原則配置)為1100100、1100111、1100000、1100001,檢查上述代碼是否出錯?第幾位出錯?
解:假設接收到的漢明碼為:c1’c2’b4’c3’b3’b2’b1’
糾錯程序如下:
P1=c1’⊕b4’⊕b3’⊕b1’
P2=c2’⊕b4’⊕b2’⊕b1’
P3=c3’⊕b3’⊕b2’⊕b1’
如果收到的漢明碼為1100100,則p3p2p1=011,說明代碼有錯,第3位(b4’)出錯,有效資訊為:1100
如果收到的漢明碼為1100111,則p3p2p1=111,說明代碼有錯,第7位(b1’)出錯,有效資訊為:0110
如果收到的漢明碼為1100000,則p3p2p1=110,說明代碼有錯,第6位(b2’)出錯,有效資訊為:0010
如果收到的漢明碼為1100001,則p3p2p1=001,說明代碼有錯,第1位(c1’)出錯,有效資訊為:0001
\24. 一個4體低位交叉的存盤器,假設存盤周期為T,CPU每隔1/4存取周期啟動一個存盤體,試問依次訪問64個字需多少個存取周期?
解:4體低位交叉的存盤器的總線傳輸周期為τ,τ=T/4,依次訪問64個字所需時間為:
t=T+(64-1) τ=T+63T/4=16.75T
\25. 什么是“程式訪問的區域性”?存盤系統中哪一級采用了程式訪問的區域性原理?
答:程式運行的區域性原理指:在一小段時間內,最近被訪問過的程式和資料很可能再次被訪問;在空間上,這些被訪問的程式和資料往往集中在一小片存盤區;在訪問順序上,指令順序執行比轉移執行的可能性大 (大約 5:1 ),存盤系統中Cache-主存層次和主存-輔存層次均采用了程式訪問的區域性原理,
\28. 設主存容量為256K字,Cache容量為2K字,塊長為4,
(1)設計Cache地址格式,Cache中可裝入多少塊資料?
(2)在直接映射方式下,設計主存地址格式,
(3)在四路組相聯映射方式下,設計主存地址格式,
(4)在全相聯映射方式下,設計主存地址格式,
(5)若存盤字長為32位,存盤器按位元組尋址,寫出上述三種映射方式下主存的地址格式,
解:(1)Cache容量為2K字,塊長為4,Cache共有2K/4=211/22=29=512塊,
Cache字地址9位,字塊內地址為2位
? 因此,Cache地址格式設計如下:
| Cache字塊地址(9位) | 字塊內地址(2位) |
|---|---|
(2)主存容量為256K字=218字,主存地址共18位,共分256K/4=216塊,
主存字塊標記為18-9-2=7位,
? 直接映射方式下主存地址格式如下:
| 主存字塊標記(7位) | Cache字塊地址(9位) | 字塊內地址(2位) |
|---|---|---|
(3)根據四路組相聯的條件,一組內共有4塊,得Cache共分為512/4=128=27組,
主存字塊標記為18-7-2=9位,主存地址格式設計如下:
| 主存字塊標記(9位) | 組地址(7位) | 字塊內地址(2位) |
|---|---|---|
(4)在全相聯映射方式下,主存字塊標記為18-2=16位,其地址格式如下:
| 主存字塊標記(16位) | 字塊內地址(2位) |
|---|---|
(5)若存盤字長為32位,存盤器按位元組尋址,則主存容量為256K*32/4=221B,
Cache容量為2K32/4=214B,塊長為432/4=32B=25B,字塊內地址為5位,
在直接映射方式下,主存字塊標記為21-9-5=7位,主存地址格式為:
| 主存字塊標記(7位) | Cache字塊地址(9位) | 字塊內地址(5位) |
|---|---|---|
在四路組相聯映射方式下,主存字塊標記為21-7-5=9位,主存地址格式為:
| 主存字塊標記(9位) | 組地址(7位) | 字塊內地址(5位) |
|---|---|---|
在全相聯映射方式下,主存字塊標記為21-5=16位,主存地址格式為:
| 主存字塊標記(16位) | 字塊內地址(5位) |
|---|---|
\29. 假設CPU執行某段程式時共訪問Cache命中4800次,訪問主存200次,已知Cache的存取周期為30ns,主存的存取周期為150ns,求Cache的命中率以及Cache-主存系統的平均訪問時間和效率,試問該系統的性能提高了多少倍?
解:Cache被訪問命中率為:4800/(4800+200)=24/25=96%
則Cache-主存系統的平均訪問時間為:ta=0.9630ns+(1-0.96)150ns=34.8ns
Cache-主存系統的訪問效率為:e=tc/ta100%=30/34.8100%=86.2%
性能為原來的150ns/34.8ns=4.31倍,即提高了3.31倍,
\30. 一個組相連映射的CACHE由64塊組成,每組內包含4塊,主存包含4096塊,每塊由128字組成,訪存地址為字地址,試問主存和高速存盤器的地址各為幾位?畫出主存地址格式,
解:cache組數:64/4=16 ,Cache容量為:64*128=213字,cache地址13位
主存共分4096/16=256區,每區16塊
主存容量為:4096*128=219字,主存地址19位,地址格式如下:
| 主存字塊標記(8位) | 組地址(4位) | 字塊內地址(7位) |
|---|---|---|
\32. 設某機主存容量為4MB,Cache容量為16KB,每字塊有8個字,每字32位,設計一個四路組相聯映射(即Cache每組內共有4個字塊)的Cache組織,
(1)畫出主存地址欄位中各段的位數,
(2)設Cache的初態為空,CPU依次從主存第0,1,2,…,89號單元讀出90個字(主存一次讀出一個字),并重復按此次序讀8次,問命中率是多少?
(3)若Cache的速度是主存的6倍,試問有Cache和無Cache相比,速度約提高多少倍?
解:(1)根據每字塊有8個字,每字32位(4位元組),得出主存地址欄位中字塊內地址為3+2=5位,
根據Cache容量為16KB=214B,字塊大小為8*32/8=32=25B,得Cache地址共14位,Cache共有214-5=29塊,
根據四路組相聯映射,Cache共分為29/22=27組,
根據主存容量為4MB=222B,得主存地址共22位,主存字塊標記為22-7-5=10位,故主存地址格式為:
| 主存字塊標記(10位) | 組地址(7位) | 字塊內地址(5位) |
|---|---|---|
(2)由于每個字塊中有8個字,而且初態為空,因此CPU讀第0號單元時,未命中,必須訪問主存,同時將該字所在的主存塊調入Cache第0組中的任一塊內,接著CPU讀第1~7號單元時均命中,同理,CPU讀第8,16,…,88號時均未命中,可見,CPU在連續讀90個字中共有12次未命中,而后8次回圈讀90個字全部命中,命中率為:
(3)設Cache的周期為t,則主存周期為6t,沒有Cache的訪問時間為6t908,有Cache的訪問時間為t(908-12)+6t12,則有Cache和無Cache相比,速度提高的倍數為:
第5章 輸入輸出系統
\1. I/O有哪些編址方式?各有何特點?
解:常用的I/O編址方式有兩種: I/O與記憶體統一編址和I/O獨立編址,
特點:I/O與記憶體統一編址方式的I/O地址采用與主存單元地址完全一樣的格式,I/O設備和主存占用同一個地址空間,CPU可像訪問主存一樣訪問I/O設備,不需要安排專門的I/O指令,
I/O獨立編址方式時機器為I/O設備專門安排一套完全不同于主存地址格式的地址編碼,此時I/O地址與主存地址是兩個獨立的空間,CPU需要通過專門的I/O指令來訪問I/O地址空間,
3.I/O設備與主機交換資訊時,有哪幾種控制方式?簡述他們的特點
答: (1)程式查詢方式,其特點是主機與I/O串行作業,CPU啟動I/O后,時刻查詢I/O是否準備好,若設備準備就緒,CPU便轉入處理I/O與主機間傳送資訊的程式;若設備未做好準備,則CPU反復查詢,直到I/O準備就緒為止,可見這種方式CPU效率很低
(2)程式中斷方式,其特點是主機與I/O并行作業,CPU啟動I/O后,不必時刻查詢I/O是否準備好,而是繼續執行程式,當I/O準備就緒時,向CPU發中斷請求信號,CPU在適當時候回應I/O的中斷請求,暫停現行程式為I/O服務,這種方式消除了“踏步”現象,提高了CPU效率,(特點為:CPU與設備并行作業,傳送與主程式串行作業)
(3)DMA方式,其特點是主機與I/O并行作業,主存和I/O之間有一條直接資料通路,CPU啟動I/O后,不必查詢I/O是否準備好,當I/O準備就緒后,發出DMA請求,此時CPU不參與I/O和主存間的資訊交換,只是把外部總線(地址線、資料線以及有關的控制線)的使用權暫時賦予DMA,仍然可以完成自身內部的操作(如加法、位移等),故不必中斷現行程式,只需暫停一個存取周期訪存(即周期挪用),CPU的效率高,(特點為:CPU與設備并行作業,傳送與主程式并行作業)
(4)通道方式,通道是一個具有特殊功能的處理器,CPU把部分權力下放給通道,由它實作對外圍設備的統一管理和外圍設備與主存之間的資料交換,大大提高了CPU的效率,但它是以花費更多的硬體為代價,
(5)I/O處理機方式,它是通道方式的進一步發展,CPU將I/O操作及外圍設備的管理權全部交給I/O處理機,其實質是多機系統,因而效率有更大提高
\10. 什么是I/O介面,與埠有何區別?為什么要設定I/O介面?I/O介面如何分類?
解:I/O介面一般指CPU和I/O設備間的連接部件,而埠是指I/O介面內CPU能夠訪問的暫存器,埠加上相應的控制邏輯即構成I/O介面,
I/O介面分類方法很多,主要有:
(1)按資料傳送方式分有并行介面和串行介面兩種;
(2)按資料傳送的控制方式分有程式控制介面、程式中斷介面、DMA介面三種,
\12. 結合程式查詢方式的介面電路,說明其作業程序,
解:程式查詢介面作業程序如下(以輸入為例):
1)CPU發I/O地址設備開始作業;地址總線?介面?設備選擇器譯碼?選中?發SEL信號; 2)CPU發啟動命令 DBR?開命令接收門; ? D置0,B置1 ? 介面向設備發啟動命令;3)CPU等待,輸入設備讀出資料;4)外設作業完成,B置0,D置1;5)準備就緒信號?介面?完成信號?控制總線? CPU;6)輸入:CPU通過輸入指令(IN)將DBR中的資料取走,
若為輸出,除資料傳送方向相反以外,其他操作與輸入類似,作業程序如下:
開命令接收門;?選中,發SEL信號?設備選擇器譯碼?介面?地址總線?1)CPU發I/O地址 2)輸出: CPU通過輸出指令(OUT)將資料放入介面DBR中;設備開始作業;?介面向設備發啟動命令? D置0,B置1 ? 3)CPU發啟動命令 4)CPU等待,輸出設備將資料從 DBR取走; B置0,D置1;?介面? 5)外設作業完成,完成信號 CPU,CPU可通過指令再次向介面DBR輸出資料,進行第二次傳送,?控制總線?6)準備就緒信號,
\13. 說明中斷向量地址和入口地址的區別和聯系,
解:中斷向量地址和入口地址的區別:
向量地址是硬體電路(向量編碼器)產生的中斷源的記憶體地址編號,中斷入口地址是中斷服務程式首址,
中斷向量地址和入口地址的聯系:
中斷向量地址可理解為中斷服務程式入口地址指示器(入口地址的地址),通過它訪存可獲得中斷服務程式入口地址, (兩種方法:在向量地址所指單元內放一條JMP指令;主存中設向量地址表,參考8.4.3)
\16. 在什么條件和什么時間,CPU可以回應I/O的中斷請求?
解:CPU回應I/O中斷請求的條件和時間是:當中斷允許狀態為1(EINT=1),且至少有一個中斷請求被查到,則在一條指令執行完時,回應中斷,
?
\28. CPU對DMA請求和中斷請求的回應時間是否一樣?為什么?
解: CPU對DMA請求和中斷請求的回應時間不一樣,因為兩種方式的交換速度相差很大,因此CPU必須以更短的時間間隔查詢并回應DMA請求,回應中斷請求是在每條指令執行周期結束的時刻,而回應DMA請求是在存取周期結束的時刻,
中斷方式是程式切換,而程式又是由指令組成,所以必須在一條指令執行完畢才能回應中斷請求,而且CPU只有在每條指令執行周期結束的時刻才發出查詢信號,以獲取中斷請求信號,若此時條件滿足,便能回應中斷請求,
DMA請求是由DMA介面根據設備的作業狀態向CPU申請占用總線,此時只要總線未被CPU占用,即可立即回應DMA請求;若總線正被CPU占用,則必須等待該存取周期結束時,CPU才交出總線的使用權,
\31. 假設某設備向CPU傳送資訊的最高頻率是40 000次/秒,而相應的中斷處理程式其執行時間為40ms,試問該外設是否可用程式中斷方式與主機交換資訊,為什么?
解:該設備向CPU傳送資訊的時間間隔 =1/40000=0.025×10-3=25 m s < 40ms
則:該外設不能用程式中斷方式與主機交換資訊,因為其中斷處理程式的執行速度比該外設的交換速度慢,
\32. 設磁盤存盤器轉速為3000轉/分,分8個扇區,每扇區存盤1K位元組,主存與磁盤存盤器資料傳送的寬度為16位(即每次傳送16位),假設一條指令最長執行時間是25ms,是否可采用一條指令執行結束時回應DMA請求的方案,為什么?若不行,應采取什么方案?
解:先算出磁盤傳送速度,然后和指令執行速度進行比較得出結論,
道容量= 1K ×8 ×8 位= 8KB = 4K字
數傳率=4K字×3000轉/分=4K字×50轉/秒 =200K字/秒
一個字的傳送時間=1/200K秒? 5ms (注:在此1K=1024,來自資料塊單位縮寫,)
因為5 ms<<25ms,所以不能采用一條指令執行結束回應DMA請求的方案,應采取每個CPU機器周期末查詢及回應DMA請求的方案(通常安排CPU機器周期=MM存取周期),
第6章 計算機的運算方法
\5. 已知[x]補,求[x]原和x,
[x1]補=1.1100; [x2]補=1.1001; [x3]補=0.1110; [x4]補=1.0000;
[x5]補=1,0101; [x6]補=1,1100; [x7]補=0,0111; [x8]補=1,0000;
解:[x]補與[x]原、x的對應關系如下:
| [x]補 | 1.1100 | 1.1001 | 0.1110 | 1.0000 | 1,0101 | 1,1100 | 0,0111 | 1,0000 |
|---|---|---|---|---|---|---|---|---|
| [x]原 | 1.0100 | 1.0111 | 0.1110 | 無 | 1,1011 | 1,0100 | 0,0111 | 無 |
| x | -0.0100 | -0.0111 | 0.1110 | -1 | -1011 | -100 | 0,0111 | -10000 |
\9. 當十六進制數9B和FF分別表示為原碼、補碼、反碼、移碼和無符號數時,所對應的十進制數各為多少(設機器數采用一位符號位)?
解:真值和機器數的對應關系如下:
| 9BH | 原碼 | 補碼 | 反碼 | 移碼 | 無符號數 |
|---|---|---|---|---|---|
| 對應十進制數 | -27 | -101 | -100 | +27 | 155 |
| FFH | 原碼 | 補碼 | 反碼 | 移碼 | 無符號數 |
| 對應十進制數 | -128 | -1 | -0 | +128 | 256 |
\14. 設浮點數字長為32位,欲表示±6萬間的十進制數,在保證數的最大精度條件下,除階符、數符各取1位外,階碼和尾數各取幾位?按這樣分配,該浮點數溢位的條件是什么?
解:若要保證數的最大精度,應取階碼的基值=2,
若要表示±6萬間的十進制數,由于32768(215)< 6萬 <65536(216),則:階碼除階符外還應取5位(向上取2的冪),
故:尾數位數=32-1-1-5=25位
? 25(32) 該浮點數格式如下:
| 階符(1位) | 階碼(5位) | 數符(1位) | 尾數(25位) |
|---|---|---|---|
按此格式,該浮點數上溢的條件為:階碼325
\19. 設機器數字長為8位(含1位符號位),用補碼運算規則計算下列各題,
(1)A=9/64, B=-13/32,求A+B,
(2)A=19/32,B=-17/128,求A-B,
(3)A=-3/16,B=9/32,求A+B,
(4)A=-87,B=53,求A-B,
(5)A=115,B=-24,求A+B,
解:(1)A=9/64= 0.001 0010B, B= -13/32= -0.011 0100B
? [A]補=0.001 0010, [B]補=1.100 1100
[A+B]補= 0.0010010 + 1.1001100 = 1.1011110 ——無溢位
A+B= -0.010 0010B = -17/64
(2)A=19/32= 0.100 1100B, B= -17/128= -0.001 0001B
? [A]補=0.100 1100, [B]補=1.110 1111 , [-B]補=0.001 0001
[A-B]補= 0.1001100 + 0.0010001= 0.1011101 ——無溢位
A-B= 0.101 1101B = 93/128B
(3)A= -3/16= -0.001 1000B, B=9/32= 0.010 0100B
[A]補=1.110 1000, [B]補= 0.010 0100
[A+B]補= 1.1101000 + 0.0100100 = 0.0001100 —— 無溢位
A+B= 0.000 1100B = 3/32
(4) A= -87= -101 0111B, B=53=110 101B
[A]補=1 010 1001, [B]補=0 011 0101, [-B]補=1 100 1011
[A-B]補= 1 0101001 + 1 1001011 = 0 1110100 —— 溢位
(5)A=115= 111 0011B, B= -24= -11 000B
[A]補=0 1110011, [B]補=1,110 1000
[A+B]補= 0 1110011 + 1 1101000 = 0 1011011——無溢位
A+B= 101 1011B = 91
26.按機器補碼浮點運算步驟,計算[x±y]補.
(1)x=2-011× 0.101 100,y=2-010×(-0.011 100);
(2)x=2-011×(-0.100 010),y=2-010×(-0.011 111);
(3)x=2101×(-0.100 101),y=2100×(-0.001 111),
解:先將x、y轉換成機器數形式:
(1)x=2-011× 0.101 100,y=2-010×(-0.011 100)
[x]補=1,101;0.101 100, [y]補=1,110;1.100 100
[Ex]補=1,101, [y]補=1,110, [Mx]補=0.101 100, [My]補=1.100 100
1)對階:
[DE]補=[Ex]補+[-Ey]補 = 11,101+ 00,010=11,111 < 0,
應Ex向Ey對齊,則:[Ex]補+1=11,101+00,001=11,110 = [Ey]補
[x]補=1,110;0.010 110
2)尾數運算:
[Mx]補+[My]補= 0.010 110 + 11.100 100=11.111010
[Mx]補+[-My]補=0.010 110 + 00.011100= 00.110 010
3)結果規格化:
[x+y]補=11,110;11.111 010 = 11,011;11.010 000 (尾數左規3次,階碼減3)
[x-y]補=11,110;00.110 010, 已是規格化數,
4)舍入:無
5)溢位:無
則:x+y=2-101×(-0.110 000)
x-y =2-010×0.110 010
(2)x=2-011×(-0.100010),y=2-010×(-0.011111)
[x]補=1,101;1.011 110, [y]補=1,110;1.100 001
1)對階:程序同(1)的1),則
[x]補=1,110;1.101 111
2)尾數運算:
[Mx]補+[My]補= 11.101111 + 11. 100001 = 11.010000
[Mx]補+[-My]補= 11.101111 + 00.011111 = 00.001110
3)結果規格化:
[x+y]補=11,110;11.010 000,已是規格化數
[x-y]補=11,110;00.001 110 =11,100;00.111000 (尾數左規2次,階碼減2)
4)舍入:無
5)溢位:無
則:x+y=2-010×(-0.110 000)
x-y =2-100×0.111 000
(3)x=2101×(-0.100 101),y=2100×(-0.001 111)
[x]補=0,101;1.011 011, [y]補=0,100;1.110 001
1)對階:
[DE]補=00,101+11,100=00,001 >0,應Ey向Ex對齊,則:
[Ey]補+1=00,100+00,001=00,101=[Ex]補
[y]補=0,101;1.111 000(1)
2)尾數運算:
[Mx]補+[My]補= 11.011011+ 11.111000(1)= 11.010011(1)
[Mx]補+[-My]補= 11.011011+ 00.000111(1)= 11.100010(1)
3)結果規格化:
[x+y]補=00,101;11.010 011(1),已是規格化數
[x-y]補=00,101;11.100 010(1)=00,100;11.000 101 (尾數左規1次,階碼減1)
4)舍入:
[x+y]補=00,101;11.010 011(舍)
[x-y]補 不變
5)溢位:無
則:x+y=2101×(-0.101 101)
x-y =2100×(-0.111 011)
第7章 指令系統
1.什么叫機器指令?什么叫指令系統?為什么說指令系統與機器的主要功能以及與硬體結構之間存在著密切的關系?
答:參考P300,
3.什么是指令字長、機器字長和存盤字長?
答:第一章7題
6.對于二地址指令而言,運算元的物理地址可安排在什么地方?舉例說明,
答:對于二地址指令而言,運算元的物理地址可安排在暫存器內、指令中或記憶體單元內等,
\8. 某機指令字長16位,每個運算元的地址碼為6位,設操作碼長度固定,指令分為零地址、一地址和二地址三種格式,若零地址指令有M條,一地址指令有N種,則二地址指令最多有幾種?若操作碼位數可變,則二地址指令最多允許有幾種?
解:1)若采用定長操作碼時,二地址指令格式如下:
| OP(4位) | A1(6位) | A2(6位) |
|---|---|---|
設二地址指令有K種,則:K=24-M-N
當M=1(最小值),N=1(最小值)時,二地址指令最多有:Kmax=16-1-1=14種
2)若采用變長操作碼時,二地址指令格式仍如1)所示,但操作碼長度可隨地址碼的個數而變,此時,K= 24 -(N/26 + M/212 );
當(N/26 + M/212 )£1時(N/26 + M/212 向上取整),K最大,則二地址指令最多有:
Kmax=16-1=15種(只留一種編碼作擴展標志用,)
\16. 某機主存容量為4M′16位,且存盤字長等于指令字長,若該機指令系統可完成108種操作,操作碼位數固定,且具有直接、間接、變址、基址、相對、立即等六種尋址方式,試回答:(1)畫出一地址指令格式并指出各欄位的作用;
(2)該指令直接尋址的最大范圍;
(3)一次間址和多次間址的尋址范圍;
(4)立即數的范圍(十進制表示);
(5)相對尋址的位移量(十進制表示);
(6)上述六種尋址方式的指令哪一種執行時間最短?哪一種最長?為什么?哪一種便于程式浮動?哪一種最適合處理陣列問題?
(7)如何修改指令格式,使指令的尋址范圍可擴大到4M?
(8)為使一條轉移指令能轉移到主存的任一位置,可采取什么措施?簡要說明之,
解:(1)單字長一地址指令格式:
?
| OP(7位) | M(3位) | A(6位) |
|---|---|---|
? OP為操作碼欄位,共7位,可反映108種操作;
? M為尋址方式欄位,共3位,可反映6種尋址操作;
? A為地址碼欄位,共16-7-3=6位,
(2)直接尋址的最大范圍為26=64,
(3)由于存盤字長為16位,故一次間址的尋址范圍為216;若多次間址,需用存盤字的最高位來區別是否繼續間接尋址,故尋址范圍為215,
(4)立即數的范圍為-32——31(有符號數),或0——63(無符號數),
(5)相對尋址的位移量為-32——31,
(6)上述六種尋址方式中,因立即數由指令直接給出,故立即尋址的指令執行時間最短,間接尋址在指令的執行階段要多次訪存(一次間接尋址要兩次訪存,多次間接尋址要多次訪存),故執行時間最長,變址尋址由于變址暫存器的內容由用戶給定,而且在程式的執行程序中允許用戶修改,而其形式地址始終不變,故變址尋址的指令便于用戶編制處理陣列問題的程式,相對尋址運算元的有效地址只與當前指令地址相差一定的位移量,與直接尋址相比,更有利于程式浮動,
(7)方案一:為使指令尋址范圍可擴大到4M,需要有效地址22位,此時可將單字長一地址指令的格式改為雙字長,如下圖示:
| OP(7位) | MOD(3位) | A(高6位) |
|---|---|---|
| A(低16位) |
方案二:如果仍采用單字長指令(16位)格式,為使指令尋址范圍擴大到4M,可通過段尋址方案實作,安排如下:
硬體設段暫存器DS(16位),用來存放段地址,在完成指令尋址方式所規定的尋址操作后,得有效地址EA(6位),再由硬體自動完成段尋址,最后得22位物理地址, 即:物理地址=(DS)′26 + EA
注:段尋址方式由硬體隱含實作,在編程指定的尋址程序完成、EA產生之后由硬體自動完成,對用戶是透明的,
方案三:在采用單字長指令(16位)格式時,還可通過頁面尋址方案使指令尋址范圍擴大到4M,安排如下:
硬體設頁面暫存器PR(16位),用來存放頁面地址,指令尋址方式中增設頁面尋址,當需要使指令尋址范圍擴大到4M時,編程選擇頁面尋址方式,則:EA =(PR)‖A (有效地址=頁面地址“拼接”6位形式地址),這樣得到22位有效地址,
(8)為使一條轉移指令能轉移到主存的任一位置,尋址范圍須達到4M,除了采用(7) 方案一中的雙字長一地址指令的格式外,還可配置22位的基址暫存器或22位的變址暫存器,使EA = (BR) + A (BR為22位的基址暫存器)或EA =(IX)+ A(IX為22位的變址暫存器),便可訪問4M存盤空間,還可以通過16位的基址暫存器左移6位再和形式地址A相加,也可達到同樣的效果,
總之,不論采取何種方式,最終得到的實際地址應是22位,
第8章 CPU的結構和功能
\1. CPU有哪些功能?畫出其結構框圖并簡要說明各個部件的作用,
答:參考P328和圖8.2,
\2. 什么是指令周期?指令周期是否有一個固定值?為什么?
解:指令周期是指取出并執行完一條指令所需的時間,
由于計算機中各種指令執行所需的時間差異很大,因此為了提高CPU運行效率,即使在同步控制的機器中,不同指令的指令周期長度都是不一致的,也就是說指令周期對于不同的指令來說不是一個固定值,
\3. 畫出指令周期的流程圖,分析說明圖中每個子周期的作用,
答:參看P343及圖8.8,
\5. 中斷周期前是什么階段?中斷周期后又是什么階段?在中斷周期CPU應完成什么操作?
答:中斷周期前是執行周期,中斷周期后是取指周期,在中斷周期,CPU應完成保存斷點、將中斷向量送PC和關中斷等作業,
\17. 在中斷系統中INTR、INT、EINT三個觸發器各有何作用?
解:INTR——中斷請求觸發器,用來登記中斷源發出的隨機性中斷請求信號,以便為CPU查詢中斷及中斷排隊判優線路提供穩定的中斷請求信號,
EINT——中斷允許觸發器,CPU中的中斷總開關,當EINT=1時,表示允許中斷(開中斷),當EINT=0時,表示禁止中斷(關中斷),其狀態可由開、關中斷等指令設定,
INT——中斷標記觸發器,控制器時序系統中周期狀態分配電路的一部分,表示中斷周期標記,當INT=1時,進入中斷周期,執行中斷隱指令的操作,
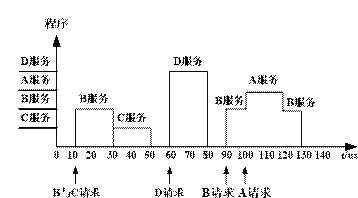
\24. 現有A、B、C、D四個中斷源,其優先級由高向低按A、B、C、D順序排列,若中斷服務程式的執行時間為20μs,請根據下圖所示時間軸給出的中斷源請求中斷的時刻,畫出CPU執行程式的軌跡,
解:A、B、C、D的響優先級即處理優先級,CPU執行程式的軌跡圖如下:
\25. 某機有五個中斷源L0、L1、L2、 L3、L4,按中斷回應的優先次序由高向低排序為L0? L1?L2?L3?L4,根據下示格式,現要求中斷處理次序改為L1?L4?L2?L0?L3,根據下面的格式,寫出各中斷源的屏蔽字,
解:各中斷源屏蔽狀態見下表:
| 中斷源 | 屏蔽字 | ||||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| I0 | 1 | 0 | 0 | 1 | 0 |
| I1 | 1 | 1 | 1 | 1 | 1 |
| I2 | 1 | 0 | 1 | 1 | 0 |
| I3 | 0 | 0 | 0 | 1 | 0 |
| I4 | 1 | 0 | 1 | 1 | 1 |
表中:設屏蔽位=1,表示屏蔽;屏蔽位=0,表示中斷開放,
第9章 控制單元的功能
\3. 什么是指令周期、機器周期和時鐘周期?三者有何關系?
答:CPU每取出并執行一條指令所需的全部時間叫指令周期;
機器周期是在同步控制的機器中,執行指令周期中一步相對完整的操作(指令步)所需時間,通常安排機器周期長度等于主存周期;
時鐘周期是指計算機主時鐘的周期時間,它是計算機運行時最基本的時序單位,對應完成一個微操作所需時間,通常時鐘周期等于計算機主頻的倒數,
\4. 能不能說機器的主頻越快,機器的速度就越快,為什么?
解:不能說機器的主頻越快,機器的速度就越快,因為機器的速度不僅與主頻有關,還與資料通路結構、時序分配方案、ALU運算能力、指令功能強弱等多種因素有關,要看綜合效果,
\5. 設機器A的主頻為8MHz,機器周期含4個時鐘周期,且該機的平均指令執行速度是0.4MIPS,試求該機的平均指令周期和機器周期,每個指令周期中含幾個機器周期?如果機器B的主頻為12MHz,且機器周期也含4個時鐘周期,試問B機的平均指令執行速度為多少MIPS?
解:先通過A機的平均指令執行速度求出其平均指令周期,再通過主頻求出時鐘周期,然后進一步求出機器周期,B機引數的演算法與A機類似,計算如下:
A機平均指令周期=1/0.4MIPS=2.5μs
A機時鐘周期=1/8MHz=125ns
A機機器周期=125ns×4=500ns=0.5μs
A機每個指令周期中含機器周期個數=2.5μs÷0.5μs=5個
B機時鐘周期 =1/12MHz?83ns
B機機器周期 =83ns×4=332ns
設B機每個指令周期也含5個機器周期,則:
B機平均指令周期=332ns×5=1.66μs
B機平均指令執行速度=1/1.66μs=0.6MIPS
結論:主頻的提高有利于機器執行速度的提高,
\6. 設某機主頻為8MHz,每個機器周期平均含2個時鐘周期,每條指令平均有4個機器周期,試問該機的平均指令執行速度為多少MIPS?若機器主頻不變,但每個機器周期平均含4個時鐘周期,每條指令平均有4個機器周期,則該機的平均指令執行速度又是多少MIPS?由此可得出什么結論?
解:先通過主頻求出時鐘周期,再求出機器周期和平均指令周期,最后通過平均指令周期的倒數求出平均指令執行速度,計算如下:
時鐘周期=1/8MHz=0.125×10-6s
機器周期=0.125×10-6s×2=0.25×10-6s
平均指令周期=0.25×10-6s×4=10-6s
平均指令執行速度=1/10-6s=1MIPS
當引數改變后:機器周期= 0.125×10-6s×4=0.5×10-6s
平均指令周期=0.5×10-6s×4=2×10-6s
平均指令執行速度=1/(2×10-6s) =0.5MIPS
結論:兩個主頻相同的機器,執行速度不一定一樣,
\11. 設CPU內部結構如圖9.4所示,此外還設有B、C、D、E、H、L六個暫存器,它們各自的輸入和輸出端都與內部總線相通,并分別受控制信號控制(如Bi為暫存器B的輸入控制;Bo為B的輸出控制),要求從取指令開始,寫出完成下列指令所需的全部微操作和控制信號,
(1)ADD B,C ((B)+(C) ?B)
(2)SUB A,H ((AC)-(H) ?AC)
解:先畫出相應指令的流程圖,然后將圖中每一步資料通路操作分解成相應的微操作,再寫出同名的微命令即可,
(1) ADD B,C指令流程及微命令序列如下:

(2) SUB A,H指令流程及微命令序列如下:
第10章 控制單元的設計
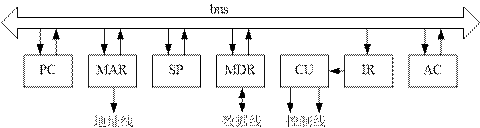
\2. 寫出完成下列指令的微操作及節拍安排(包括取指操作),
(1)指令ADD R1,X完成將R1暫存器的內容和主存X單元的內容相加,結果存于R1的操作,
(2)指令ISZ X完成將主存X單元的內容增1,并根據其結果若為0,則跳過下一條指令執行,
解:設采用單總線結構的CPU資料通路如下圖所示,且ALU輸入端設兩個暫存器C、D(見17題圖),并設采用同步控制,每周期3節拍:
(1)指令ADD R1,X的微操作及節拍安排如下:
取指周期:T0 PC?MAR,1? R
T1 M(MAR) ?MDR,PC+1?PC
T2 MDR?IR,OP(IR) ?ID
執行周期1:T0 Ad(IR)?MAR,1?R
? T1 M(MAR) ?MDR
T2 MDR?D
執行周期2:T0 R1?C
T1 +
T2 ALU?R1
(2)指令ISZ X的微操作及節拍安排:
取指周期同(1):略
執行周期1: T0 Ad(IR)-MAR,1-R
? T1 M(MAR)-MDR
T2 MDR-C,+1-ALU
執行周期2:T0 ALU-MDR,1-W
T1 (PC+1)·Z+ PC-PC
\15. 設控制存盤器的容量為512×48位,微程式可在整個控存空間實作轉移,而控制微程式轉移的條件共有4個(采用直接控制),微指令格式如下:
解:因為控制存盤器共有51248=2948
所以,下址欄位應有9位,微指令字長48位
又因為控制微程式轉移的條件有4個,4+1<=23
所以判斷測驗欄位占3位
因此控制欄位位數為:48-9-3=36
微指令格式為:
48 13 12 10 9 1
控制欄位 測驗欄位 下址欄位
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/393860.html
標籤:其他
上一篇:Render顯示層級的決定因素
下一篇:嵌入式實時作業系統8——等待表