目錄
前言
1.鏈表的概念
2.鏈表的分類
3.不帶頭單向非回圈鏈表
3.1 不帶頭單向非回圈鏈表的結構
3.2 不帶頭單向非回圈鏈表的介面函式
鏈表節點申請及鏈表的列印,銷毀
鏈表插入元素
鏈表洗掉元素
鏈表元素查找
3.3 不帶頭單向非回圈鏈表的全部代碼
4.帶頭雙向回圈鏈表
4.1 帶頭雙向回圈鏈表的結構
4.2 帶頭雙向回圈鏈表的介面函式
鏈表的初始化和銷毀
鏈表插入元素
鏈表洗掉元素
鏈表的查找和列印
4.3 帶頭雙向回圈鏈表的全部代碼
5.順序表和鏈表的對比
后記
前言
在上篇順序表文章末尾(【資料結構】順序表),我們留了幾個問題,主要是道出了順序表的不足之處,例如,插入資料困難,要不斷申請空間,而且會有空間浪費,
那么,有沒有一種結構,可以較好的解決這幾個問題呢?這就要提到我們今天的主角——鏈表,
1.鏈表的概念
鏈表是一種物理存盤結構上非連續、非順序的存盤結構,資料元素的邏輯順序是通過鏈表中的指標鏈接次序實作的 ,
與順序表不同,使用鏈表存盤的資料元素,其物理存盤位置是隨機的,
應該怎么理解呢?
日常生活中的火車可以較為形象的表示鏈表結構,火車是由許多節車廂連接而成的的,同時,火車如果要卸下/加裝某一節車廂的話,只需要將其中一節斷開/插入即可,所以火車就像是用許多鏈條串起來的一樣,可以近似表示鏈表,
那么,鏈表的結構到底是什么樣子呢?
鏈表節點至少需要兩個成員,一個是指向下一個元素的指標,這個指標所在的區域,我們稱為指標域,另一個是要儲存的資料,儲存資料的區域,我們叫資料域,
所有鏈表節點(火車的節)串在一起,我們就叫它鏈表(火車),
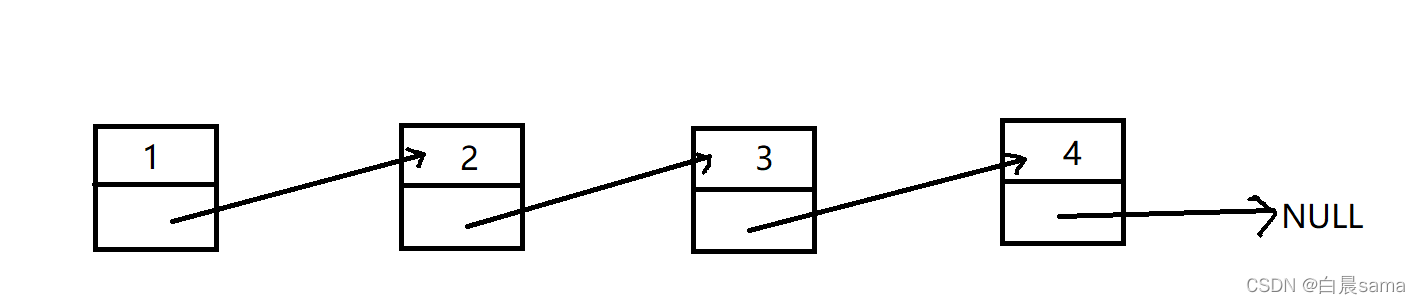
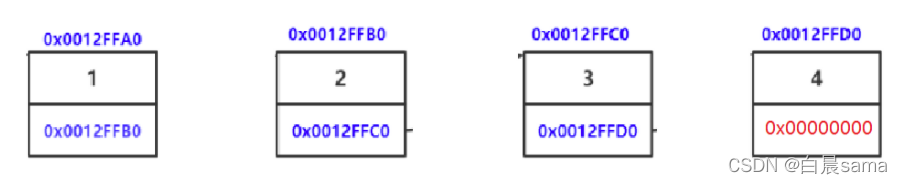
我們從兩個角度去理解,一種是邏輯結構,一種是物理結構,
邏輯結構:
相當于,每一個元素都指向著后面的元素,
物理結構:
這是記憶體中實實在在的結構,一個鏈表節點可以分為資料域和指標域,指標域中存放著下一個鏈表節點的地址,通過這個地址,我們就可以找到下一個鏈表節點,
總結一下:
1.鏈表在邏輯上是連續的,但在物理儲存結構一般上不連續,
2.鏈表的空間一般都是動態記憶體開辟的,
2.鏈表的分類
1.根據鏈表的指向,可以分為單向和雙向,
單向:
雙向:


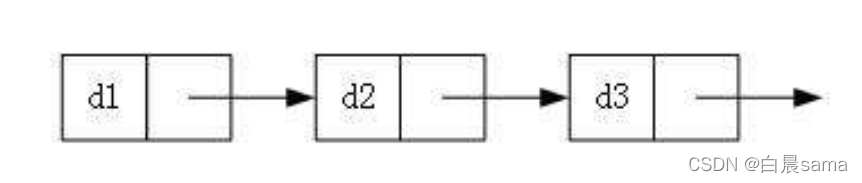
2.根據有無哨兵位節點,可以分為帶頭和不帶頭,
哨兵位,主要的作用是讓鏈表有頭節點,同樣是鏈表節點,但是不儲存有效資料,
plist所指向的就是一個哨兵位,從哨兵位下一個起,才是有效資料,
帶頭:
不帶頭:

3.根據最后一個鏈表節點是否指向第一個節點,可以分為回圈和非回圈,
回圈:
非回圈:
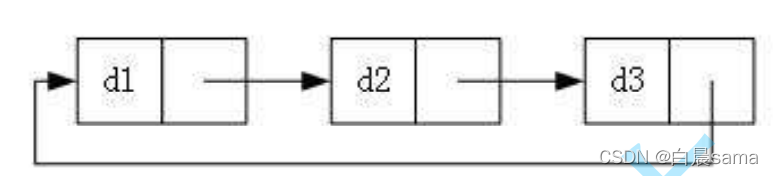
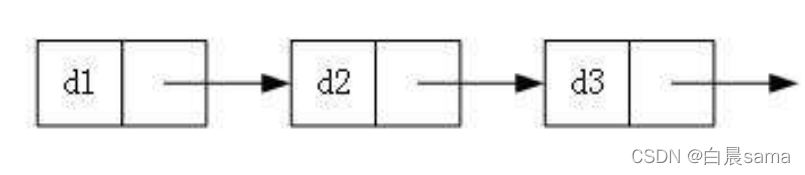
根據這三種分法,我們可以排列組合出八種不同的鏈表,
本文主要講解兩種常用的鏈表:不帶頭單向非回圈鏈表和帶頭雙向回圈鏈表
3.不帶頭單向非回圈鏈表
無頭單向非回圈鏈表:結構簡單,一般不會單獨用來存資料,實際中更多是作為其他資料結構的子結構,如哈希桶、圖的鄰接表等等,另外這種結構在筆試面試中出現很多,
這類結構一般在OJ題目中出現的比較多,因為它的結構最簡單,所以,缺陷也就越大,經常會有很多問題,
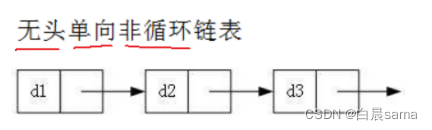
3.1 不帶頭單向非回圈鏈表的結構
typedef int SLTDataType; typedef struct SListNode { SLTDataType data; struct SListNode* next; }SLTNode;這個結構很簡單,這里不過多贅述,上文的例子都是這種結構,不太理解的同學可以結合代碼和上文圖片在紙上畫一畫,
3.2 不帶頭單向非回圈鏈表的介面函式
所有介面函式:
// 鏈表資料列印
void SListPrint(SLTNode* phead);
// 尾插
void SListPushBack(SLTNode** pphead, SLTDataType x);
// 頭插
void SListPushFront(SLTNode** pphead, SLTDataType x);
// 尾刪
void SListPopBack(SLTNode** pphead);
// 頭刪
void SListPopFront(SLTNode** pphead);
// 資料查找
SLTNode* SListFind(SLTNode* phead, SLTDataType x);
// 在pos位置之后去插入一個節點
void SListInsertAfter(SLTNode* pos, SLTDataType x);
// 在pos位置之前去插入一個節點
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
void SListInsert1(SLTNode** pphead, int pos, SLTDataType x);
// 洗掉pos節點
void SListErase(SLTNode** pphead, SLTNode* pos);
void SListErase1(SLTNode** pphead, int pos);
// 洗掉pos之后的節點
void SListEraseAfter(SLTNode* pos);
// 鏈表銷毀
void SListDestroy(SLTNode** pphead);
可以看到引數傳的都是二級指標,為什么呢?
因為不帶頭鏈表的頭節點隨時可能被頭插,頭刪等操作更換,所以必須要傳二級指標來保證頭節點地址會隨著這些操作變更,也即要將頭節點的地址傳回去,
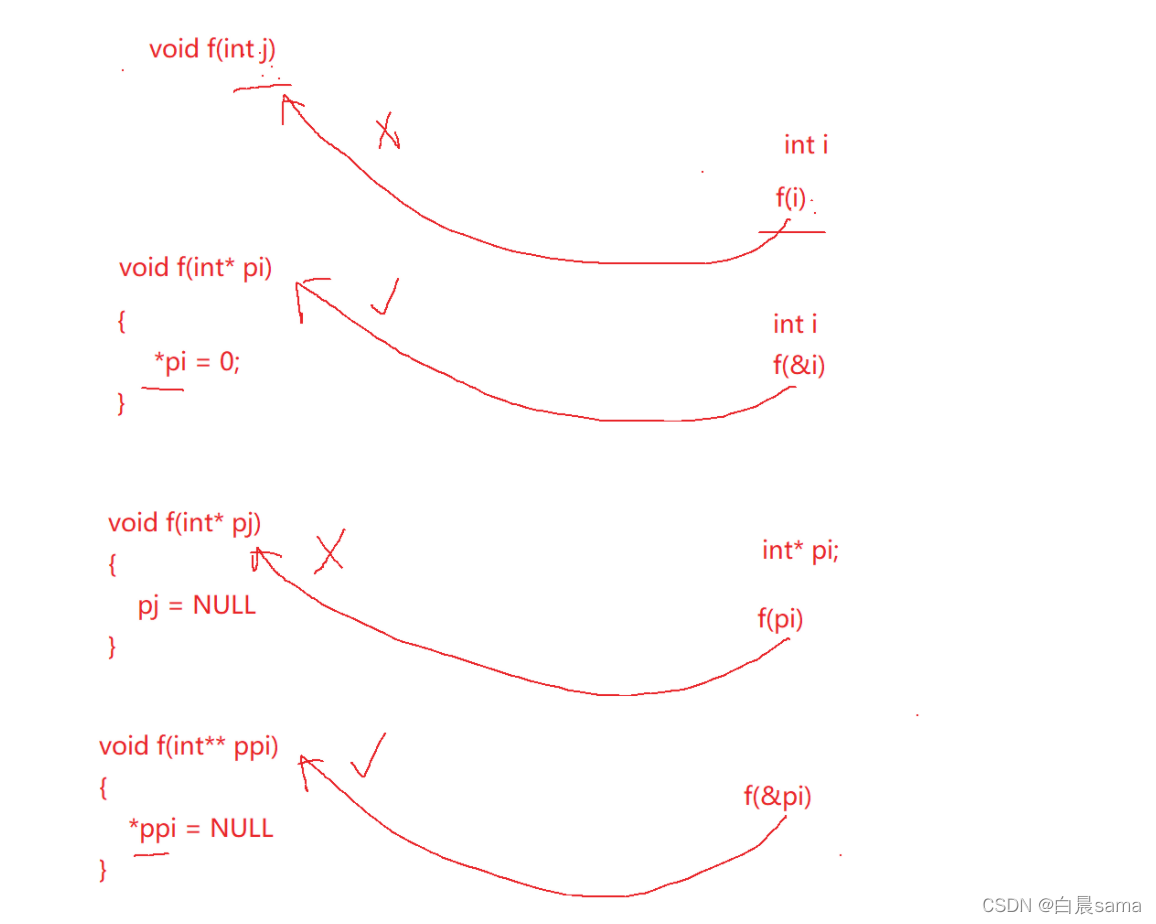
鏈表節點申請及鏈表的列印,銷毀
SLTNode* BuyListNode(SLTDataType x) { SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); if (newnode == NULL) { perror("BuyListNode"); exit(-1); } newnode->data = x; newnode->next = NULL; return newnode; }先開辟一個動態空間,判斷不為空后,將資料放到新開辟的節點中,再回傳節點的地址,
void SListDestroy(SLTNode** pphead) { SLTNode* next = *pphead; while (*pphead) { next = (*pphead)->next; free(*pphead); *pphead = next; } }遍歷鏈表,只要 *pphead 不為空,也就是鏈表不指向空,就繼續釋放,
void SListPrint(SLTNode* plist) { assert(plist); while (plist) { printf("%d ", plist->data); plist = plist->next; } }也是一樣的操作,遍歷鏈表即可,這里不用傳二級指標是因為不用改變頭指標的值,
鏈表插入元素
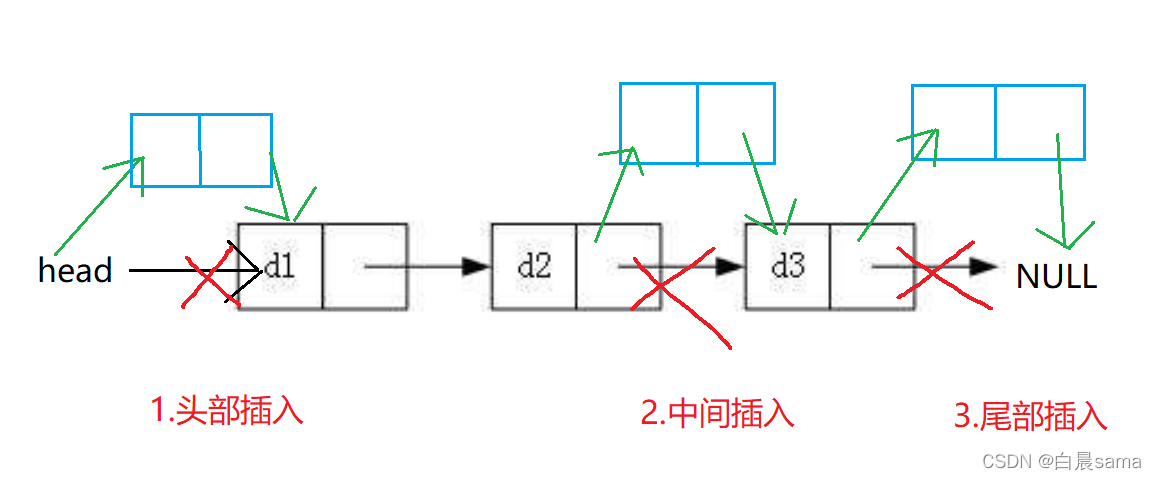
根據添加位置不同,可分為以下 3 種情況:
- 插入到鏈表的頭部(頭節點之后),作為首元節點;
- 插入到鏈表中間的某個位置;
- 插入到鏈表的最末端,作為鏈表中最后一個資料元素;
無論什么情況還是分兩步走:
- 先讓新節點的 next 指向插入位置的節點;
- 再讓插入位置前的節點 next 指向新節點,
具體實作:
普通插入:
//傳遞指標版 void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) { assert(pphead); SLTNode* newnode = BuyListNode(x); if (pos == *pphead) { newnode->next = *pphead; *pphead = newnode; } else { SLTNode* cur = *pphead; while (cur->next != pos) { cur = cur->next; } newnode->next = pos; cur->next = newnode; } } //傳遞下標版 void SListInsert1(SLTNode** pphead, int pos, SLTDataType x)//第一個節點序數為0 { assert(pphead); SLTNode* posPrev = *pphead; SLTNode* newnode = BuyListNode(x); if (pos == 0) { newnode->next = *pphead; *pphead = newnode; } else { for (int i = 0; i < pos - 1; i++) { if (!posPrev) { return; } posPrev = posPrev->next; } newnode->next = posPrev->next; posPrev->next = newnode; }兩種插入方式都可以,看自己喜好,
值得注意的是,當進行頭部插入時,要改變頭指標的值,這里也解釋了為什么要傳遞二級指標,因為如果傳遞一級指標改變的是頭指標的臨時拷貝,并不能改變頭指標,
如果了解了插入的原理,我們就可以把剩下的插入都寫出來了
在插入位置之后插入:
void SListInsertAfter(SLTNode* pos, SLTDataType x) { assert(pos); SLTNode* newnode = BuyListNode(x); newnode->next = pos->next; pos->next = newnode; }我們發現這次的就不用傳遞二級指標,因為不會改變頭指標的值,而且代碼少得多,說明單鏈表不適合前插,但是適合尾插,
尾插:
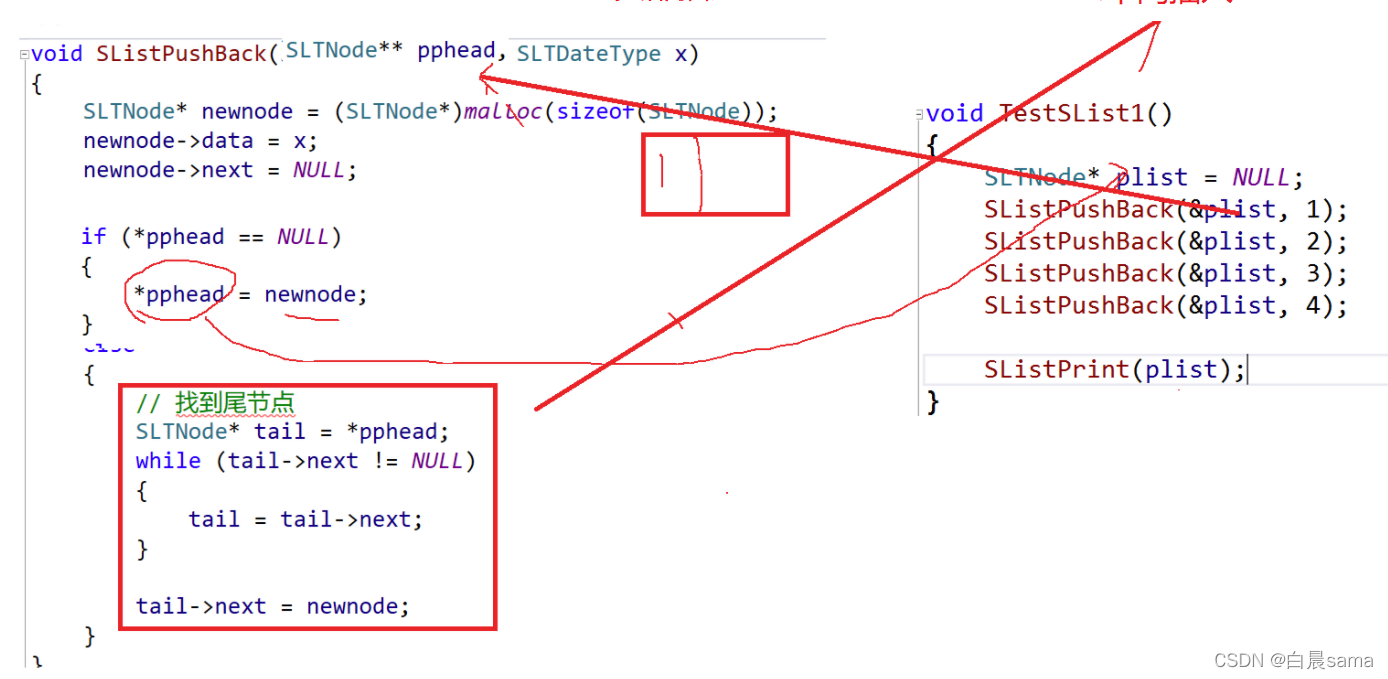
void SListPushBack(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = BuyListNode(x); if (*pphead == NULL) { *pphead = newnode; } else { SLTNode* tail = *pphead; while (tail->next != NULL) { tail = tail->next; } tail->next = newnode; } }
頭插:
void SListPushFront(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = BuyListNode(x); newnode->next = *pphead; *pphead = newnode; }
鏈表洗掉元素
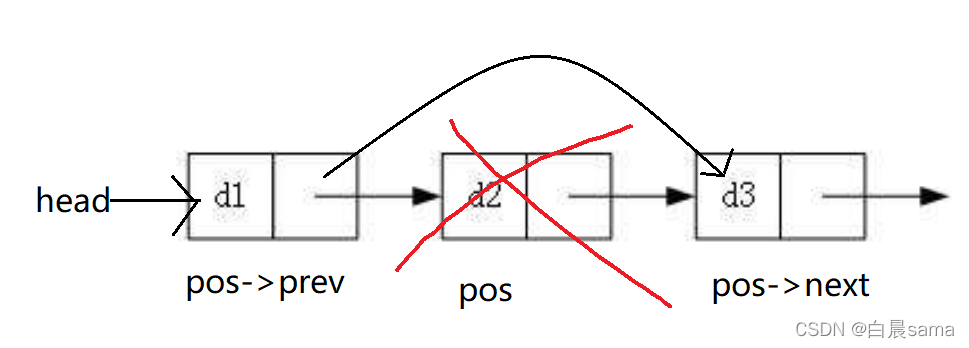
無論洗掉哪個節點都可以分為三步:
- 保存被洗掉節點后的節點的地址;
- 釋放被洗掉節點;
- 連接被洗掉節點前的節點和被洗掉節點后的節點,
普通洗掉:
void SListErase(SLTNode** pphead, SLTNode* pos) { assert(pphead); assert(*pphead); assert(pos); if (pos == *pphead) { *pphead = (*pphead)->next; free(*pphead); } else { SLTNode* posPrev = *pphead; while (posPrev->next != pos) { posPrev = posPrev->next; } posPrev->next = pos->next; free(pos); pos = NULL; } }洗掉pos之后的節點:
void SListEraseAfter(SLTNode* pos) { assert(pos); assert(pos->next); SLTNode* next = pos->next->next; free(pos->next); pos->next = next; }頭刪:
void SListPopFront(SLTNode** pphead) { assert(pphead); assert(*pphead); SLTNode* next = (*pphead)->next; free(*pphead); *pphead = next; }尾刪:
void SListPopBack(SLTNode** pphead) { assert(pphead); assert(*pphead); if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* tail = *pphead; while (tail->next->next != NULL) { tail = tail->next; } free(tail->next); tail->next = NULL; } }
鏈表元素查找
查找方法:
一般就是遍歷鏈表,如果找到,回傳該鏈表節點的地址或者下標,未找到,回傳NULL,
SLTNode* SListFind(SLTNode* phead, SLTDataType x) { assert(phead); SLTNode* pos = phead; while (pos) { if (pos->data == x) { return pos; } pos = pos->next; } return NULL; }這里給出,回傳地址的寫法,大家可以自己試著寫一下回傳下標的寫法,
3.3 不帶頭單向非回圈鏈表的全部代碼
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
void SListPrint(SLTNode* plist)
{
assert(plist);
while (plist)
{
printf("%d ", plist->data);
plist = plist->next;
}
}
SLTNode* BuyListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("BuyListNode");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuyListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuyListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SListPopBack(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
void SListPopFront(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
assert(phead);
SLTNode* pos = phead;
while (pos)
{
if (pos->data == x)
{
return pos;
}
pos = pos->next;
}
return NULL;
}
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuyListNode(x);
if (pos == *pphead)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
SLTNode* cur = *pphead;
while (cur->next != pos)
{
cur = cur->next;
}
newnode->next = pos;
cur->next = newnode;
}
}
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuyListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
void SListErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
if (pos == *pphead)
{
*pphead = (*pphead)->next;
free(*pphead);
}
else
{
SLTNode* posPrev = *pphead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
posPrev->next = pos->next;
free(pos);
pos = NULL;
}
}
void SListEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* next = pos->next->next;
free(pos->next);
pos->next = next;
}
void SListDestroy(SLTNode** pphead)
{
SLTNode* next = *pphead;
while (*pphead)
{
next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}
void SListInsert1(SLTNode** pphead, int pos, SLTDataType x)//第一個節點序數為0
{
assert(pphead);
SLTNode* posPrev = *pphead;
SLTNode* newnode = BuyListNode(x);
if (pos == 0)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
for (int i = 0; i < pos - 1; i++)
{
if (!posPrev)
{
return;
}
posPrev = posPrev->next;
}
newnode->next = posPrev->next;
posPrev->next = newnode;
}
}
void SListErase1(SLTNode** pphead, int pos)
{
assert(pphead);
assert(*pphead);
if (pos == 0)
{
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
else
{
SLTNode* next = *pphead;
for (int i = 0; i < pos - 1; i++)
{
if (!next)
{
return;
}
next = next->next;
}
SLTNode* tmp = next->next->next;
free(next->next);
next->next = tmp;
}
}4.帶頭雙向回圈鏈表
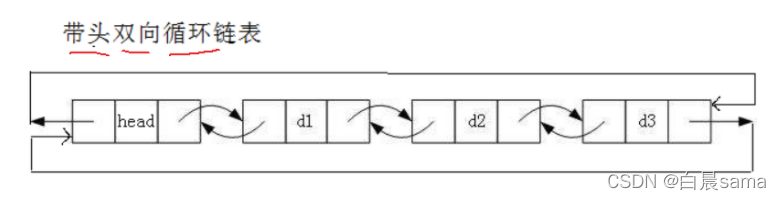
帶頭雙向回圈鏈表:結構最復雜,一般用在單獨存盤資料,實際中使用的鏈表資料結構,都是帶頭雙向回圈鏈表,另外這個結構雖然結構復雜,但是使用代碼實作以后會發現結構會帶來很多優勢,實作反而簡單了,后面我們代碼實作了就知道了
4.1 帶頭雙向回圈鏈表的結構
typedef int LTDataType; typedef struct ListNode { LTDataType data; struct ListNode* next; struct ListNode* prev; }LTNode;
其實就是雙向鏈表的結構,帶頭和回圈還得靠我們初始化實作,
4.2 帶頭雙向回圈鏈表的介面函式
鏈表的初始化和銷毀
初始化要完成兩件事:
- 為頭節點開辟空間
- 讓頭結點的next 和prev 指標指向自己,并回傳頭節點地址
LTNode* ListInit() { LTNode* phead = (LTNode*)malloc(sizeof(LTNode)); if (phead == NULL) { exit(-1); } phead->next = phead; phead->prev = phead; return phead; }
銷毀:
由于回圈鏈表不會指向NULL,所以用頭節點作為遍歷結束的標志,
所以要先釋放掉保存有效資料的節點,再釋放頭節點,
void ListDestroy(LTNode* phead) { assert(phead); LTNode* cur = phead->next; while (cur != phead) { LTNode* nextNode = cur->next; free(cur); cur = nextNode; } free(phead); phead = NULL; }
鏈表插入元素
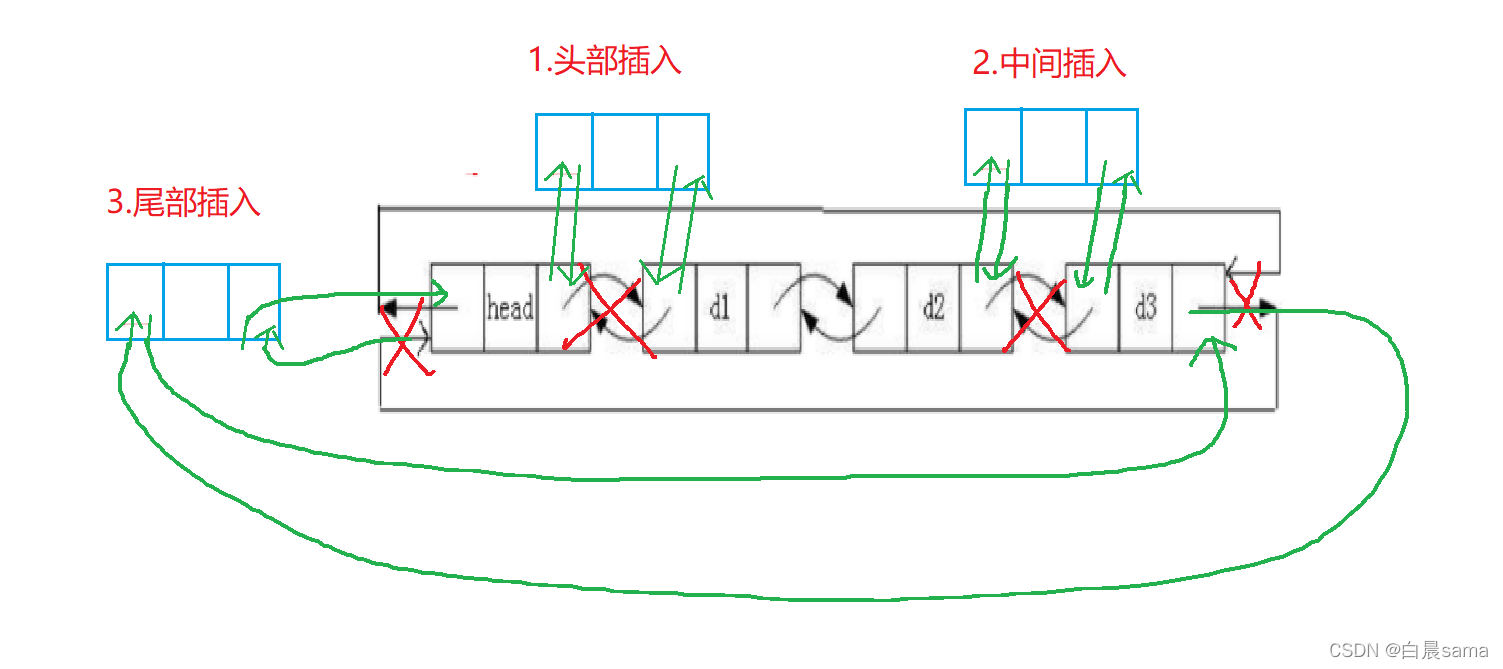
我們發現,
- 要將雙新節點先與其直接后繼節點建立雙層邏輯關系,新節點的直接前驅節點與之建立雙層邏輯關系
- 頭部插入變為了在頭節點后插入,所以怎么改變都不會影響頭節點,可以只傳一級指標,
- 中間插入基本沒什么變化
- 尾部插入變成了在頭節點前插入,與尾節點和原尾節點之間要建立雙重邏輯關系,
普通插入:
void ListInsert(LTNode* pos, LTDataType x) { assert(pos); LTNode* newnode = BuyListNode(x); LTNode* Prev = pos->prev; Prev->next = newnode; newnode->prev = Prev; newnode->next = pos; pos->prev = pos; }用普通插入直接實作尾插和頭插,
尾插:
void ListPushBack(LTNode* phead, LTDataType x) { ListInsert(phead->prev, x); }頭插:
void ListPushFront(LTNode* phead, LTDataType x) { ListInsert(phead->next, x); }
鏈表洗掉元素
雙鏈表洗掉結點時
- 只需拿到要洗掉的節點,然后將該節點從表中摘除;
- 建立被洗掉節點前后節點的雙向聯系即可,
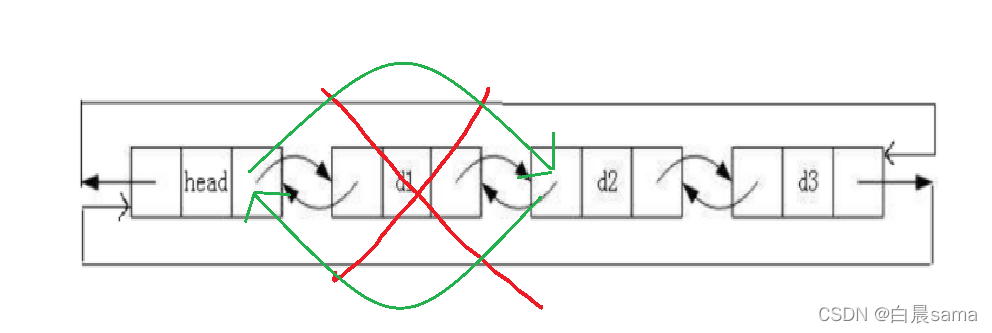
普通洗掉:
void ListErase(LTNode* pos) { assert(pos); assert(pos->next != pos);//保證鏈表不為空 LTNode* next = pos->next; LTNode* prev = pos->prev; free(pos); pos = NULL; prev->next = next; next->prev = prev; }用普通洗掉函式實作尾刪和頭刪,
尾刪:
void ListPopBack(LTNode* phead) { ListErase(phead->prev); }頭刪:
void ListPopFront(LTNode* phead) { ListErase(phead->next); }
鏈表的查找和列印
兩者邏輯大致相同
- 首先遍歷鏈表,查找函式遇到所要找的節點停止,并回傳此節點的地址;
- 遇到頭節點停止遍歷,查找函式遇到頭節點代表未找到,回傳NULL,
列印:
void ListPrint(LTNode* phead) { assert(phead); LTNode* cur = phead->next; while (cur != phead) { printf("%d ", cur->data); cur = cur->next;//記得要推進回圈 } printf("\n"); }查找:
LTNode* ListFind(LTNode* phead, LTDataType x) { assert(phead); assert(phead->next != phead); LTNode* cur = phead->next; while (cur != phead) { if (cur->data == x) { return cur; } cur = cur->next; } return NULL; }
4.3 帶頭雙向回圈鏈表的全部代碼
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
LTNode* ListInit()
{
LTNode* phead = (LTNode*)malloc(sizeof(LTNode));
if (phead == NULL)
{
exit(-1);
}
phead->next = phead;
phead->prev = phead;
return phead;
}
LTNode* BuyListNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;//記得要推進回圈
}
printf("\n");
}
void ListDestroy(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* nextNode = cur->next;
free(cur);
cur = nextNode;
}
free(phead);
phead = NULL;
}
LTNode* ListFind(LTNode* phead, LTDataType x)
{
assert(phead);
assert(phead->next != phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = BuyListNode(x);
LTNode* Prev = pos->prev;
Prev->next = newnode;
newnode->prev = Prev;
newnode->next = pos;
pos->prev = pos;
}
void ListErase(LTNode* pos)
{
assert(pos);
assert(pos->next != pos);
LTNode* next = pos->next;
LTNode* prev = pos->prev;
free(pos);
pos = NULL;
prev->next = next;
next->prev = prev;
}
void ListPushBack(LTNode* phead, LTDataType x)
{
ListInsert(phead->prev, x);
}
void ListPopBack(LTNode* phead)
{
ListErase(phead->prev);
}
void ListPushFront(LTNode* phead, LTDataType x)
{
ListInsert(phead->next, x);
}
void ListPopFront(LTNode* phead)
{
ListErase(phead->next);
}
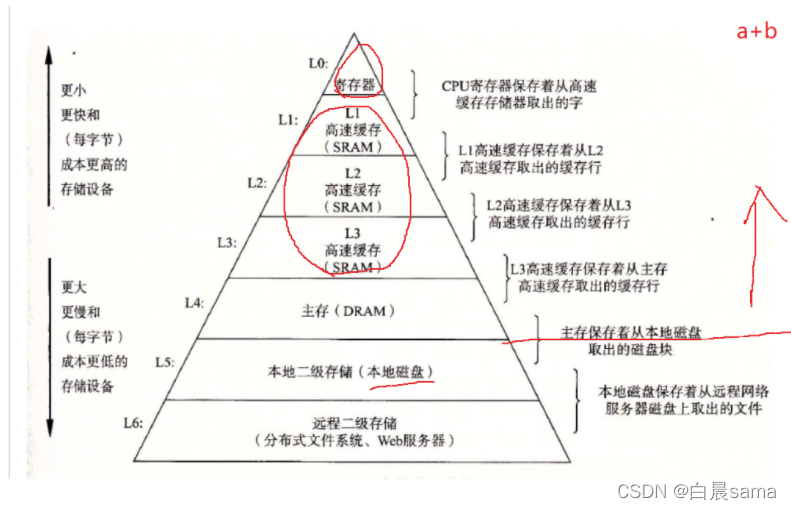
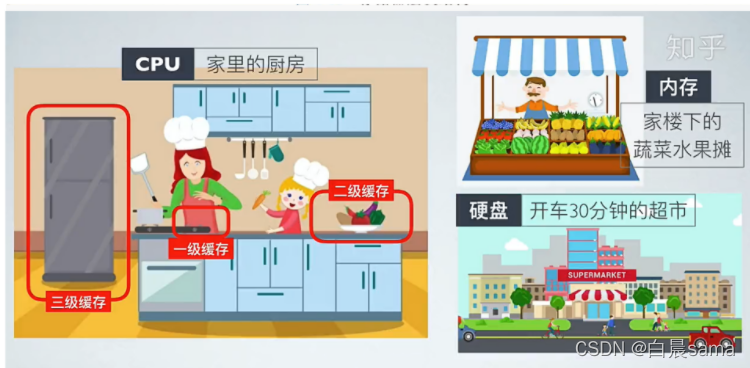
5.順序表和鏈表的對比

關于高速快取:

后記
我們用了兩篇文章,講述了順序表和鏈表,接下來,我們就要講到它們的應用了,
我在函式堆疊幀中講過,堆疊是一種后進先出的結構,那么這種特性如何用我們學過的兩種結構實作呢?
大家可以用這兩種結構試一試,
tips:主要是介面函式的實作,
以上就是本次的分享內容了,喜歡我的分享的話,別忘了點贊加關注喲!
如果你對我的文章有任何看法,歡迎在下方評論留言或者私信我鴨!
我是白晨,我們下次分享見!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/393924.html
標籤:其他
上一篇:Manacher(馬拉車演算法)