圖論
- 資料結構的圖存盤結構
- 圖存盤結構基本常識
- 圖存盤結構的分類
- 什么是連通圖,(強)連通圖詳解
- 強連通圖
- 什么是生成樹,生成樹(生成森林)詳解
- 生成森林
- 圖的順序存盤結構及其C語言代碼實作
- 圖的順序存盤結構C語言實作
- 圖的鄰接表存盤結構詳解
- 鄰接表計算頂點的出度和入度
- 圖的十字鏈表存盤結構
資料結構的圖存盤結構,常用于存盤邏輯關系為 “多對多” 的資料,圖存盤結構,是重點,也是難點,
小白要想玩轉資料結構的圖,就必須穩扎穩打,死摳圖結構的每一個知識點,每一行代碼,只有這樣,才有徹底學會圖存盤結構的可能,
除了圖存盤結構的理論知識,還會穿插一些與圖存盤結構相關的常用演算法,例如克魯斯卡爾演算法,迪杰斯特拉演算法、弗洛伊德演算法等,
資料結構的圖存盤結構
我們知道,資料之間的關系有 3 種,分別是 “一對一”、“一對多” 和 “多對多”,前兩種關系的資料可分別用線性表和樹結構存盤,具有"多對多"邏輯關系資料的結構——圖存盤結構,
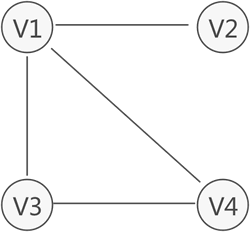
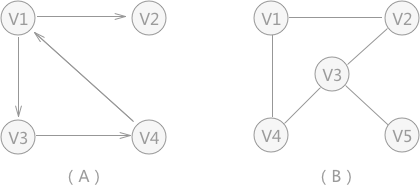
圖 1 所示為存盤 V1、V2、V3、V4 的圖結構,從圖中可以清楚的看出資料之間具有的"多對多"關系,例如,V1 與 V4 和 V2 建立著聯系,V4 與 V1 和 V3 建立著聯系,以此類推,
與鏈表不同,圖中存盤的各個資料元素被稱為頂點(而不是節點),拿圖 1 來說,該圖中含有 4 個頂點,分別為頂點 V1、V2、V3 和 V4,
圖存盤結構中,習慣上用 Vi 表示圖中的頂點,且所有頂點構成的集合通常用 V 表示,如圖 1 中頂點的集合為 V={V1,V2,V3,V4},
注意,圖 1 中的圖僅是圖存盤結構的其中一種,資料之間 “多對多” 的關系還可能用如圖 2 所示的圖結構表示:
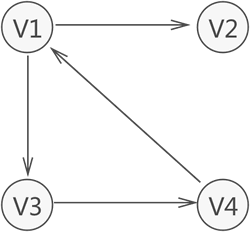
可以看到,各個頂點之間的關系并不是"雙向"的,比如,V4 只與 V1 存在聯系(從 V4 可直接找到 V1),而與 V3 沒有直接聯系;同樣,V3 只與 V4 存在聯系(從 V3 可直接找到 V4),而與 V1 沒有直接聯系,以此類推,
因此,圖存盤結構可細分兩種表現型別,分別為無向圖(圖 1)和有向圖(圖 2),
圖存盤結構基本常識
-
弧頭和弧尾
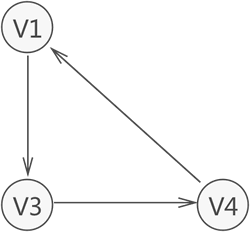
- 有向圖中,無箭頭一端的頂點通常被稱為"初始點"或"弧尾",箭頭直線的頂點被稱為"終端點"或"弧頭", 入度和出度
- 對于有向圖中的一個頂點 V 來說,箭頭指向 V 的弧的數量為 V 的入度(InDegree,記為 ID(V));箭頭遠離 V 的弧的數量為 V 的出度(OutDegree,記為OD(V)),拿圖 2 中的頂點 V1來說,該頂點的入度為 1,出度為 2(該頂點的度為 3), (V1,V2) 和 <V1,V2> 的區別
- 無向圖中描述兩頂點(V1 和 V2)之間的關系可以用 (V1,V2) 來表示,而有向圖中描述從 V1 到 V2 的"單向"關系用 <V1,V2> 來表示,由于圖存盤結構中頂點之間的關系是用線來表示的,因此 (V1,V2) 還可以用來表示無向圖中連接 V1 和 V2 的線,又稱為邊;同樣,<V1,V2> 也可用來表示有向圖中從 V1 到 V2 帶方向的線,又稱為弧, 集合 VR 的含義
- 并且,圖中習慣用 VR 表示圖中所有頂點之間關系的集合,例如,圖 1 中無向圖的集合 VR={(v1,v2),(v1,v4),(v1,v3),(v3,v4)},圖 2 中有向圖的集合 VR={<v1,v2>,<v1,v3>,<v3,v4>,<v4,v1>}, 路徑和回路
-
無論是無向圖還是有向圖,從一個頂點到另一頂點途徑的所有頂點組成的序列(包含這兩個頂點),稱為一條路徑,如果路徑中第一個頂點和最后一個頂點相同,則此路徑稱為"回路"(或"環"),
并且,若路徑中各頂點都不重復,此路徑又被稱為"簡單路徑";同樣,若回路中的頂點互不重復,此回路被稱為"簡單回路"(或簡單環),
拿圖 1 來說,從 V1 存在一條路徑還可以回到 V1,此路徑為 {V1,V3,V4,V1},這是一個回路(環),而且還是一個簡單回路(簡單環),
在有向圖中,每條路徑或回路都是有方向的,
-
權和網的含義
- 在某些實際場景中,圖中的每條邊(或弧)會賦予一個實數來表示一定的含義,這種與邊(或弧)相匹配的實數被稱為"權",而帶權的圖通常稱為網,如圖 3 所示,就是一個網結構:
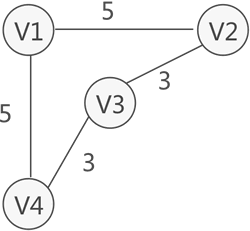
子圖:指的是由圖中一部分頂點和邊構成的圖,稱為原圖的子圖,
圖存盤結構的分類
根據不同的特征,圖又可分為完全圖,連通圖、稀疏圖和稠密圖:
- 完全圖:若圖中各個頂點都與除自身外的其他頂點有關系,這樣的無向圖稱為完全圖(如圖 4a)),同時,滿足此條件的有向圖則稱為有向完全圖(圖 4b)),
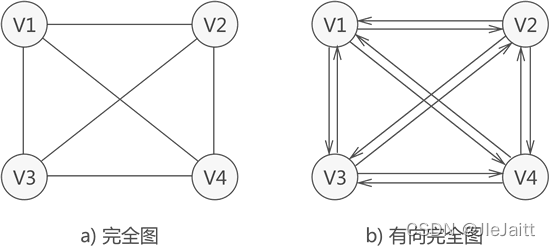
具有 n 個頂點的完全圖,圖中邊的數量為 n(n-1)/2;而對于具有 n 個頂點的有向完全圖,圖中弧的數量為 n(n-1),
稀疏圖和稠密圖:這兩種圖是相對存在的,即如果圖中具有很少的邊(或弧),此圖就稱為"稀疏圖";反之,則稱此圖為"稠密圖",
稀疏和稠密的判斷條件是:e<nlogn,其中 e 表示圖中邊(或弧)的數量,n 表示圖中頂點的數量,如果式子成立,則為稀疏圖;反之為稠密圖,
什么是連通圖,(強)連通圖詳解
圖中從一個頂點到達另一頂點,若存在至少一條路徑,則稱這兩個頂點是連通著的,例如圖 1 中,雖然 V1 和 V3 沒有直接關聯,但從 V1 到 V3 存在兩條路徑,分別是 V1-V2-V3 和 V1-V4-V3,因此稱 V1 和 V3 之間是連通的,
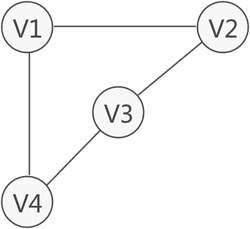
無向圖中,如果任意兩個頂點之間都能夠連通,則稱此無向圖為連通圖,例如,圖 2 中的無向圖就是一個連通圖,因為此圖中任意兩頂點之間都是連通的,
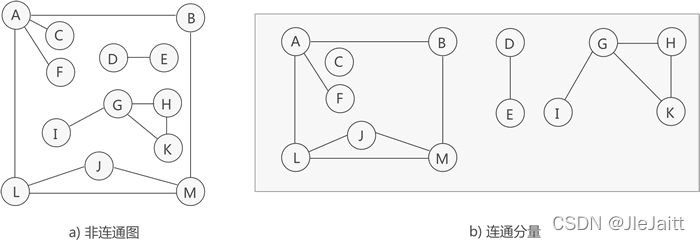
若無向圖不是連通圖,但圖中存盤某個子圖符合連通圖的性質,則稱該子圖為連通分量,
前面講過,由圖中部分頂點和邊構成的圖為該圖的一個子圖,但這里的子圖指的是圖中"最大"的連通子圖(也稱"極大連通子圖"),
如圖 3 所示,雖然圖 3a) 中的無向圖不是連通圖,但可以將其分解為 3 個"最大子圖"(圖 3b)),它們都滿足連通圖的性質,因此都是連通分量,
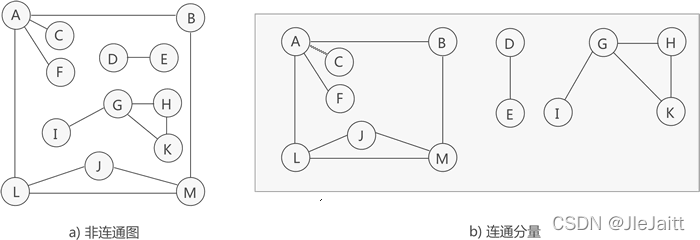
提示,圖 3a) 中的無向圖只能分解為 3 部分各自連通的"最大子圖",
需要注意的是,連通分量的提出是以"整個無向圖不是連通圖"為前提的,因為如果無向圖是連通圖,則其無法分解出多個最大連通子圖,因為圖中所有的頂點之間都是連通的,
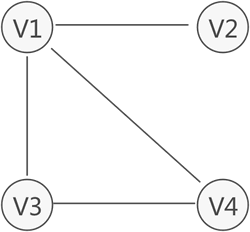
強連通圖
有向圖中,若任意兩個頂點 Vi 和 Vj,滿足從 Vi 到 Vj 以及從 Vj 到 Vi 都連通,也就是都含有至少一條通路,則稱此有向圖為強連通圖,如圖 4 所示就是一個強連通圖,
與此同時,若有向圖本身不是強連通圖,但其包含的最大連通子圖具有強連通圖的性質,則稱該子圖為強連通分量,
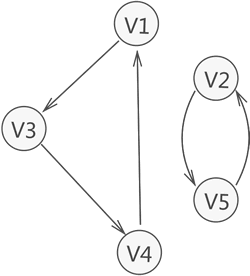
如圖 5 所示,整個有向圖雖不是強連通圖,但其含有兩個強連通分量,
可以這樣說,連通圖是在無向圖的基礎上對圖中頂點之間的連通做了更高的要求,而強連通圖是在有向圖的基礎上對圖中頂點的連通做了更高的要求,
什么是生成樹,生成樹(生成森林)詳解
學習連通圖的基礎上,本節學習什么是生成樹,以及什么是生成森林,
對連通圖進行遍歷,程序中所經過的邊和頂點的組合可看做是一棵普通樹,通常稱為生成樹,
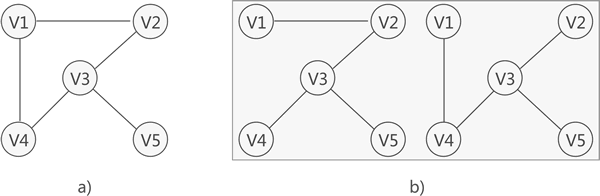
如圖 1 所示,圖 1a) 是一張連通圖,圖 1b) 是其對應的 2 種生成樹,
連通圖中,由于任意兩頂點之間可能含有多條通路,遍歷連通圖的方式有多種,往往一張連通圖可能有多種不同的生成樹與之對應,
連通圖中的生成樹必須滿足以下 2 個條件:
- 包含連通圖中所有的頂點;
- 任意兩頂點之間有且僅有一條通路;
因此,連通圖的生成樹具有這樣的特征,即生成樹中邊的數量 = 頂點數 - 1,
生成森林
生成樹是對應連通圖來說,而生成森林是對應非連通圖來說的,
我們知道,非連通圖可分解為多個連通分量,而每個連通分量又各自對應多個生成樹(至少是 1 棵),因此與整個非連通圖相對應的,是由多棵生成樹組成的生成森林,、
如圖 2 所示,這是一張非連通圖,可分解為 3 個連通分量,其中各個連通分量對應的生成樹如圖 3 所示:
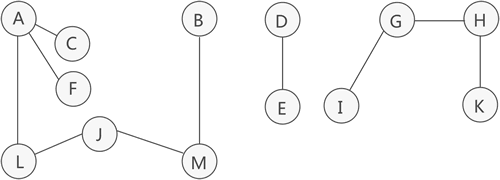
注意,圖 3 中列出的僅是各個連通分量的其中一種生成樹,
因此,多個連通分量對應的多棵生成樹就構成了整個非連通圖的生成森林,
圖的順序存盤結構及其C語言代碼實作
使用圖結構表示的資料元素之間雖然具有“多對多”的關系,但是同樣可以采用順序存盤,也就是使用陣列有效地存盤圖,
使用陣列存盤圖時,需要使用兩個陣列,一個陣列存放圖中頂點本身的資料(一維陣列),另外一個陣列用于存盤各頂點之間的關系(二維陣列),
存盤圖中各頂點本身資料,使用一維陣列就足夠了;存盤頂點之間的關系時,要記錄每個頂點和其它所有頂點之間的關系,所以需要使用二維陣列,
不同型別的圖,存盤的方式略有不同,根據圖有無權,可以將圖劃分為兩大類:圖和網 ,
圖,包括無向圖和有向圖;網,是指帶權的圖,包括無向網和有向網,存盤方式的不同,指的是:在使用二維陣列存盤圖中頂點之間的關系時,如果頂點之間存在邊或弧,在相應位置用 1 表示,反之用 0 表示;如果使用二維陣列存盤網中頂點之間的關系,頂點之間如果有邊或者弧的存在,在陣列的相應位置存盤其權值;反之用 0 表示,
結構代碼表示:
#define MAX_VERtEX_NUM 20 //頂點的最大個數
#define VRType int //表示頂點之間的關系的變數型別
#define InfoType char //存盤弧或者邊額外資訊的指標變數型別
#define VertexType int //圖中頂點的資料型別
typedef enum{DG,DN,UDG,UDN}GraphKind; //列舉圖的 4 種型別
typedef struct {
VRType adj; //對于無權圖,用 1 或 0 表示是否相鄰;對于帶權圖,直接為權值,
InfoType * info; //弧或邊額外含有的資訊指標
}ArcCell,AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];
typedef struct {
VertexType vexs[MAX_VERtEX_NUM]; //存盤圖中頂點資料
AdjMatrix arcs; //二維陣列,記錄頂點之間的關系
int vexnum,arcnum; //記錄圖的頂點數和弧(邊)數
GraphKind kind; //記錄圖的種類
}MGraph;
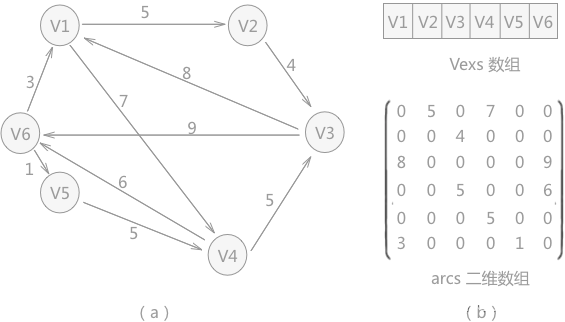
例如,存盤圖 1 中的無向圖(B)時,除了存盤圖中各頂點本身具有的資料外,還需要使用二維陣列存盤任意兩個頂點之間的關系,
由于 (B) 為無向圖,各頂點沒有權值,所以如果兩頂點之間有關聯,相應位置記為 1 ;反之記為 0 ,構建的二維陣列如圖 2 所示,

在此二維陣列中,每一行代表一個頂點,依次從 V1 到 V5 ,每一列也是如此,比如 arcs[0][1] = 1 ,表示 V1 和 V2 之間有邊存在;而 arcs[0][2] = 0,說明 V1 和 V3 之間沒有邊,
對于無向圖來說,二維陣列構建的二階矩陣,實際上是對稱矩陣,在存盤時就可以采用壓縮存盤的方式存盤下三角或者上三角,
通過二階矩陣,可以直觀地判斷出各個頂點的度,為該行(或該列)非 0 值的和,例如,第一行有兩個 1,說明 V1 有兩個邊,所以度為 2,
存盤圖 1 中的有向圖(A)時,對應的二維陣列如圖 3 所示:

例如,arcs[0][1] = 1 ,證明從 V1 到 V2 有弧存在,且通過二階矩陣,可以很輕松得知各頂點的出度和入度,出度為該行非 0 值的和,入度為該列非 0 值的和,例如,V1 的出度為第一行兩個 1 的和,為 2 ; V1 的入度為第一列中 1 的和,為 1 ,所以 V1 的出度為 2 ,入度為 1 ,度為兩者的和 3 ,
圖的順序存盤結構C語言實作
#include <stdio.h>
#define MAX_VERtEX_NUM 20 //頂點的最大個數
#define VRType int //表示頂點之間的關系的變數型別
#define InfoType char //存盤弧或者邊額外資訊的指標變數型別
#define VertexType int //圖中頂點的資料型別
typedef enum{DG,DN,UDG,UDN}GraphKind; //列舉圖的 4 種型別
typedef struct {
VRType adj; //對于無權圖,用 1 或 0 表示是否相鄰;對于帶權圖,直接為權值,
InfoType * info; //弧或邊額外含有的資訊指標
}ArcCell,AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];
typedef struct {
VertexType vexs[MAX_VERtEX_NUM]; //存盤圖中頂點資料
AdjMatrix arcs; //二維陣列,記錄頂點之間的關系
int vexnum,arcnum; //記錄圖的頂點數和弧(邊)數
GraphKind kind; //記錄圖的種類
}MGraph;
//根據頂點本身資料,判斷出頂點在二維陣列中的位置
int LocateVex(MGraph * G,VertexType v){
int i=0;
//遍歷一維陣列,找到變數v
for (; i<G->vexnum; i++) {
if (G->vexs[i]==v) {
break;
}
}
//如果找不到,輸出提示陳述句,回傳-1
if (i>G->vexnum) {
printf("no such vertex.\n");
return -1;
}
return i;
}
//構造有向圖
void CreateDG(MGraph *G){
//輸入圖含有的頂點數和弧的個數
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
//依次輸入頂點本身的資料
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->vexs[i]));
}
//初始化二維矩陣,全部歸0,指標指向NULL
for (int i=0; i<G->vexnum; i++) {
for (int j=0; j<G->vexnum; j++) {
G->arcs[i][j].adj=0;
G->arcs[i][j].info=NULL;
}
}
//在二維陣列中添加弧的資料
for (int i=0; i<G->arcnum; i++) {
int v1,v2;
//輸入弧頭和弧尾
scanf("%d,%d",&v1,&v2);
//確定頂點位置
int n=LocateVex(G, v1);
int m=LocateVex(G, v2);
//排除錯誤資料
if (m==-1 ||n==-1) {
printf("no this vertex\n");
return;
}
//將正確的弧的資料加入二維陣列
G->arcs[n][m].adj=1;
}
}
//構造無向圖
void CreateDN(MGraph *G){
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->vexs[i]));
}
for (int i=0; i<G->vexnum; i++) {
for (int j=0; j<G->vexnum; j++) {
G->arcs[i][j].adj=0;
G->arcs[i][j].info=NULL;
}
}
for (int i=0; i<G->arcnum; i++) {
int v1,v2;
scanf("%d,%d",&v1,&v2);
int n=LocateVex(G, v1);
int m=LocateVex(G, v2);
if (m==-1 ||n==-1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj=1;
G->arcs[m][n].adj=1;//無向圖的二階矩陣沿主對角線對稱
}
}
//構造有向網,和有向圖不同的是二階矩陣中存盤的是權值,
void CreateUDG(MGraph *G){
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->vexs[i]));
}
for (int i=0; i<G->vexnum; i++) {
for (int j=0; j<G->vexnum; j++) {
G->arcs[i][j].adj=0;
G->arcs[i][j].info=NULL;
}
}
for (int i=0; i<G->arcnum; i++) {
int v1,v2,w;
scanf("%d,%d,%d",&v1,&v2,&w);
int n=LocateVex(G, v1);
int m=LocateVex(G, v2);
if (m==-1 ||n==-1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj=w;
}
}
//構造無向網,和無向圖唯一的區別就是二階矩陣中存盤的是權值
void CreateUDN(MGraph* G){
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->vexs[i]));
}
for (int i=0; i<G->vexnum; i++) {
for (int j=0; j<G->vexnum; j++) {
G->arcs[i][j].adj=0;
G->arcs[i][j].info=NULL;
}
}
for (int i=0; i<G->arcnum; i++) {
int v1,v2,w;
scanf("%d,%d,%d",&v1,&v2,&w);
int m=LocateVex(G, v1);
int n=LocateVex(G, v2);
if (m==-1 ||n==-1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj=w;
G->arcs[m][n].adj=w;//矩陣對稱
}
}
void CreateGraph(MGraph *G){
//選擇圖的型別
scanf("%d",&(G->kind));
//根據所選型別,呼叫不同的函式實作構造圖的功能
switch (G->kind) {
case DG:
return CreateDG(G);
break;
case DN:
return CreateDN(G);
break;
case UDG:
return CreateUDG(G);
break;
case UDN:
return CreateUDN(G);
break;
default:
break;
}
}
//輸出函式
void PrintGrapth(MGraph G)
{
for (int i = 0; i < G.vexnum; i++)
{
for (int j = 0; j < G.vexnum; j++)
{
printf("%d ", G.arcs[i][j].adj);
}
printf("\n");
}
}
int main() {
MGraph G;//建立一個圖的變數
CreateGraph(&G);//呼叫創建函式,傳入地址引數
PrintGrapth(G);//輸出圖的二階矩陣
return 0;
}
注意:在此程式中,構建無向網和有向網時,對于之間沒有邊或弧的頂點,相應的二階矩陣中存放的是 0,目的只是為了方便查看運行結果,而實際上如果頂點之間沒有關聯,它們之間的距離應該是無窮大(∞),
例如,使用上述程式存盤圖 4(a)的有向網時,存盤的兩個陣列如圖 4(b)所示:
相應地運行結果為:
2
6,10
1
2
3
4
5
6
1,2,5
2,3,4
3,1,8
1,4,7
4,3,5
3,6,9
6,1,3
4,6,6
6,5,1
5,4,5
0 5 0 7 0 0
0 0 4 0 0 0
8 0 0 0 0 9
0 0 5 0 0 6
0 0 0 5 0 0
3 0 0 0 1 0
總結一下,主要詳細介紹了使用陣列存盤圖的方法,在實際操作中使用更多的是鏈式存盤結構,例如鄰接表、十字鏈表和鄰接多重表,將在后文重點介紹
圖的鄰接表存盤結構詳解
通常,圖更多的是采用鏈表存盤,具體的存盤方法有 3 種,分別是鄰接表、鄰接多重表和十字鏈表,
先講解圖的鄰接表存盤法,鄰接表既適用于存盤無向圖,也適用于存盤有向圖,
在具體講解鄰接表存盤圖的實作方法之前,先普及一個"鄰接點"的概念,在圖中,如果兩個點相互連通,即通過其中一個頂點,可直接找到另一個頂點,則稱它們互為鄰接點,
鄰接指的是圖中頂點之間有邊或者弧的存在,
鄰接表存盤圖的實作方式是,給圖中的各個頂點獨自建立一個鏈表,用節點存盤該頂點,用鏈表中其他節點存盤各自的臨界點,
與此同時,為了便于管理這些鏈表,通常會將所有鏈表的頭節點存盤到陣列中(也可以用鏈表存盤),也正因為各個鏈表的頭節點存盤的是各個頂點,因此各鏈表在存盤臨界點資料時,僅需存盤該鄰接頂點位于陣列中的位置下標即可,
例如,存盤圖 1a) 所示的有向圖,其對應的鄰接表如圖 1b) 所示:
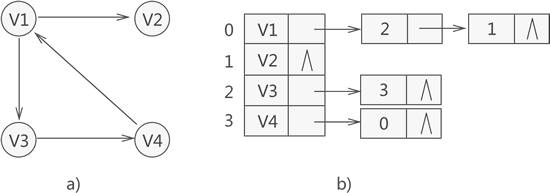
拿頂點 V1 來說,與其相關的鄰接點分別為 V2 和 V3,因此存盤 V1 的鏈表中存盤的是 V2 和 V3 在陣列中的位置下標 1 和 2,
從圖 1 中可以看出,存盤各頂點的節點結構分為兩部分,資料域和指標域,資料域用于存盤頂點資料資訊,指標域用于鏈接下一個節點,如圖 2 所示:

在實際應用中,除了圖 2 這種節點結構外,對于用鏈接表存盤網(邊或弧存在權)結構,還需要節點存盤權的值,因此需使用圖 3 中的節點結構:

圖 1 中的鏈接表結構轉化為對應 C 語言代碼如下:
#define MAX_VERTEX_NUM 20//最大頂點個數
#define VertexType int//頂點資料的型別
#define InfoType int//圖中弧或者邊包含的資訊的型別
typedef struct ArcNode{
int adjvex;//鄰接點在陣列中的位置下標
struct ArcNode * nextarc;//指向下一個鄰接點的指標
InfoType * info;//資訊域
}ArcNode;
typedef struct VNode{
VertexType data;//頂點的資料域
ArcNode * firstarc;//指向鄰接點的指標
}VNode,AdjList[MAX_VERTEX_NUM];//存盤各鏈表頭結點的陣列
typedef struct {
AdjList vertices;//圖中頂點的陣列
int vexnum,arcnum;//記錄圖中頂點數和邊或弧數
int kind;//記錄圖的種類
}ALGraph;
鄰接表計算頂點的出度和入度
使用鄰接表計算無向圖中頂點的入度和出度會非常簡單,只需從陣列中找到該頂點然后統計此鏈表中節點的數量即可,
而使用鄰接表存盤有向圖時,通常各個頂點的鏈表中存盤的都是以該頂點為弧尾的鄰接點,因此通過統計各頂點鏈表中的節點數量,只能計算出該頂點的出度,而無法計算該頂點的入度,
對于利用鄰接表求某頂點的入度,有兩種方式:
- 遍歷整個鄰接表中的節點,統計資料域與該頂點所在陣列位置下標相同的節點數量,即為該頂點的入度;
- 建立一個逆鄰接表,該表中的各頂點鏈表專門用于存盤以此頂點為弧頭的所有頂點在陣列中的位置下標,比如說,建立一張圖 1a) 對應的逆鄰接表,如圖 4 所示:
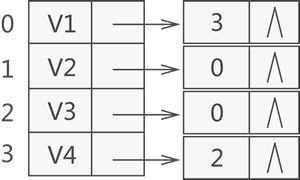
對于具有 n 個頂點和 e 條邊的無向圖,鄰接表中需要存盤 n 個頭結點和 2e 個表結點,在圖中邊或者弧稀疏的時候,使用鄰接表要比前一節介紹的鄰接矩陣更加節省空間,
圖的十字鏈表存盤結構
前面介紹了圖的鄰接表存盤法,本節繼續講解圖的另一種鏈式存盤結構——十字鏈表法,
與鄰接表不同,十字鏈表法僅適用于存盤有向圖和有向網,不僅如此,十字鏈表法還改善了鄰接表計算圖中頂點入度的問題,
十字鏈表存盤有向圖(網)的方式與鄰接表有一些相同,都以圖(網)中各頂點為首元節點建立多條鏈表,同時為了便于管理,還將所有鏈表的首元節點存盤到同一陣列(或鏈表)中,
其中,建立個各個鏈表中用于存盤頂點的首元節點結構如圖 1 所示:

從圖 1 可以看出,首元節點中有一個資料域和兩個指標域(分別用 firstin 和 firstout 表示):
- firstin 指標用于連接以當前頂點為弧頭的其他頂點構成的鏈表;
- firstout 指標用于連接以當前頂點為弧尾的其他頂點構成的鏈表;
- data 用于存盤該頂點中的資料;
由此可以看出,十字鏈表實質上就是為每個頂點建立兩個鏈表,分別存盤以該頂點為弧頭的所有頂點和以該頂點為弧尾的所有頂點,
注意,存盤圖的十字鏈表中,各鏈表中首元節點與其他節點的結構并不相同,圖 1 所示僅是十字鏈表中首元節點的結構,鏈表中其他普通節點的結構如圖 2 所示:

從圖 2 中可以看出,十字鏈表中普通節點的存盤分為 5 部分內容,它們各自的作用是:
- tailvex 用于存盤以首元節點為弧尾的頂點位于陣列中的位置下標;
- headvex 用于存盤以首元節點為弧頭的頂點位于陣列中的位置下標;
- hlink 指標:用于鏈接下一個存盤以首元節點為弧頭的頂點的節點;
- tlink 指標:用于鏈接下一個存盤以首元節點為弧尾的頂點的節點;
- info 指標:用于存盤與該頂點相關的資訊,例如量頂點之間的權值;
比如說,用十字鏈表存盤圖 3a) 中的有向圖,存盤狀態如圖 3b) 所示:
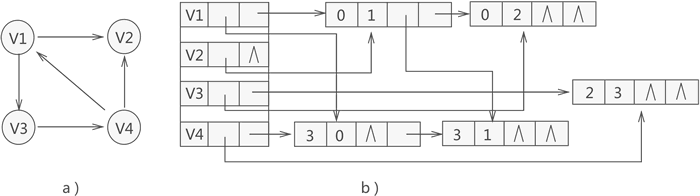
拿圖 3 中的頂點 V1 來說,通過構建好的十字鏈表得知,以該頂點為弧頭的頂點只有存盤在陣列中第 3 位置的 V4(因此該頂點的入度為 1),而以該頂點為弧尾的頂點有兩個,分別為存盤陣列第 1 位置的 V2 和第 2 位置的 V3(因此該頂點的出度為 2),
對于圖 3 各個鏈表中節點來說,由于表示的都是該頂點的出度或者入度,因此沒有先后次序之分,
圖 3 中十字鏈表的構建程序轉化為 C 語言代碼為:
#define MAX_VERTEX_NUM 20
#define InfoType int//圖中弧包含資訊的資料型別
#define VertexType int
typedef struct ArcBox{
int tailvex,headvex;//弧尾、弧頭對應頂點在陣列中的位置下標
struct ArcBox *hlik,*tlink;//分別指向弧頭相同和弧尾相同的下一個弧
InfoType *info;//存盤弧相關資訊的指標
}ArcBox;
typedef struct VexNode{
VertexType data;//頂點的資料域
ArcBox *firstin,*firstout;//指向以該頂點為弧頭和弧尾的鏈表首個結點
}VexNode;
typedef struct {
VexNode xlist[MAX_VERTEX_NUM];//存盤頂點的一維陣列
int vexnum,arcnum;//記錄圖的頂點數和弧數
}OLGraph;
int LocateVex(OLGraph * G,VertexType v){
int i=0;
//遍歷一維陣列,找到變數v
for (; i<G->vexnum; i++) {
if (G->xlist[i].data==v) {
break;
}
}
//如果找不到,輸出提示陳述句,回傳 -1
if (i>G->vexnum) {
printf("no such vertex.\n");
return -1;
}
return i;
}
//構建十字鏈表函式
void CreateDG(OLGraph *G){
//輸入有向圖的頂點數和弧數
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
//使用一維陣列存盤頂點資料,初始化指標域為NULL
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->xlist[i].data));
G->xlist[i].firstin=NULL;
G->xlist[i].firstout=NULL;
}
//構建十字鏈表
for (int k=0;k<G->arcnum; k++) {
int v1,v2;
scanf("%d,%d",&v1,&v2);
//確定v1、v2在陣列中的位置下標
int i=LocateVex(G, v1);
int j=LocateVex(G, v2);
//建立弧的結點
ArcBox * p=(ArcBox*)malloc(sizeof(ArcBox));
p->tailvex=i;
p->headvex=j;
//采用頭插法插入新的p結點
p->hlik=G->xlist[j].firstin;
p->tlink=G->xlist[i].firstout;
G->xlist[j].firstin=G->xlist[i].firstout=p;
}
}
提示,代碼中新節點的插入采用的是頭插法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/393925.html
標籤:其他
上一篇:【資料結構】鏈表全決議