目錄
- 引言
- 論文介紹
- 1. Continuous prompt
- 2. Prompt是否真的有用
- 思考
- 總結
引言
像 BERT 這樣的預訓練模型學習了大規模語料的詞分布,同時也學習了語料中的客觀事實,基于這樣的直覺,Petroni et al. (2019) 提出 LAMA 模型,首次從 BERT 中以完形填空的方式提取客觀事實,探究語言模型中包含多少客觀知識,他們將 BERT 的準確度看作預訓練模型含客觀事實的比例的下界,
事實推理任務(Factual Probing)被定義為三元組 (subject, relation, object) + 表示關系的人工設計模版 prompt,例如,(Dante, place_of_birth, Florence) + [X] was born in [Y] 可以生成帶掩碼的句子 “Dante was born in [MASK]”,作為 BERT 的輸入,在這里,事實推理任務就是預測 [mask],Prompt 可抽象為
![]() 之后的一系列作業都著力于改進 prompt ,期望在不微調所有引數,只微調 prompt 引數的情況下,最大限度地提取預訓練模型中包含的客觀事實,Jiang et al. (2020) 提出 LPAQA 模型,用文本挖掘和改寫尋找最優模版;Shin et al. (2020) 提出 AUTOPROMPT 模型,將
[
V
]
i
[V]_i
[V]i? 設定為詞表中的任意詞,在詞表中搜索最大化期望概率的詞組合,本文主要介紹的是2021年4月陳丹綺女神發表的作業 OPTIPROMPT——將
[
V
]
i
[V]_i
[V]i? 設定為連續空間的向量,在連續空間中優化期望概率,
之后的一系列作業都著力于改進 prompt ,期望在不微調所有引數,只微調 prompt 引數的情況下,最大限度地提取預訓練模型中包含的客觀事實,Jiang et al. (2020) 提出 LPAQA 模型,用文本挖掘和改寫尋找最優模版;Shin et al. (2020) 提出 AUTOPROMPT 模型,將
[
V
]
i
[V]_i
[V]i? 設定為詞表中的任意詞,在詞表中搜索最大化期望概率的詞組合,本文主要介紹的是2021年4月陳丹綺女神發表的作業 OPTIPROMPT——將
[
V
]
i
[V]_i
[V]i? 設定為連續空間的向量,在連續空間中優化期望概率,
論文名稱:Factual Probing Is [MASK]: Learning vs. Learning to Recall
論文鏈接:http://arxiv.org/abs/2104.05240
論文介紹
主要結論:
- 在連續空間定義的 [ V ] i [V]_i [V]i? 作為模版可以最有效地提取知識,用人工設計的模版初始化 [ V ] i [V]_i [V]i? 可以優化搜索程序;
- 客觀事實之間不是相互獨立的,資料驅動生成的 prompt 可以借鑒訓練集中知識的分布,用于提取語言模型中的知識,甚至可以在隨機初始化的語言模型中恢復客觀事實,
1. Continuous prompt
將 prompt 限制為能夠理解的字是一種次優的人工假設,因此,作者提出應該在連續空間上優化 prompt,
作者預先設定好 prompt 的長度,然后將
[
V
]
i
[V]_i
[V]i? 嵌入為與輸入大小相同的稠密向量,組成模版
t
r
t_r
tr?,訓練集包括800個三元組,測驗集包括200個三元組,三元組套入模版
t
r
t_r
tr? 中作為BERT 的輸入,預測 [MASK], 以 MLM 任務的損失作為損失函式,在訓練程序中固定其他引數只優化
[
V
]
i
[V]_i
[V]i? 的嵌入,
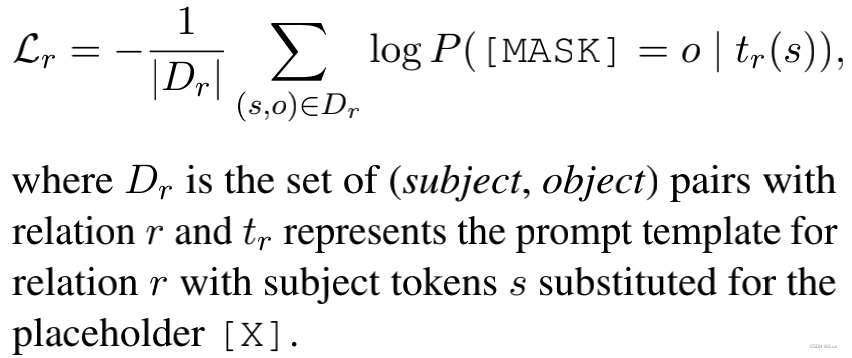
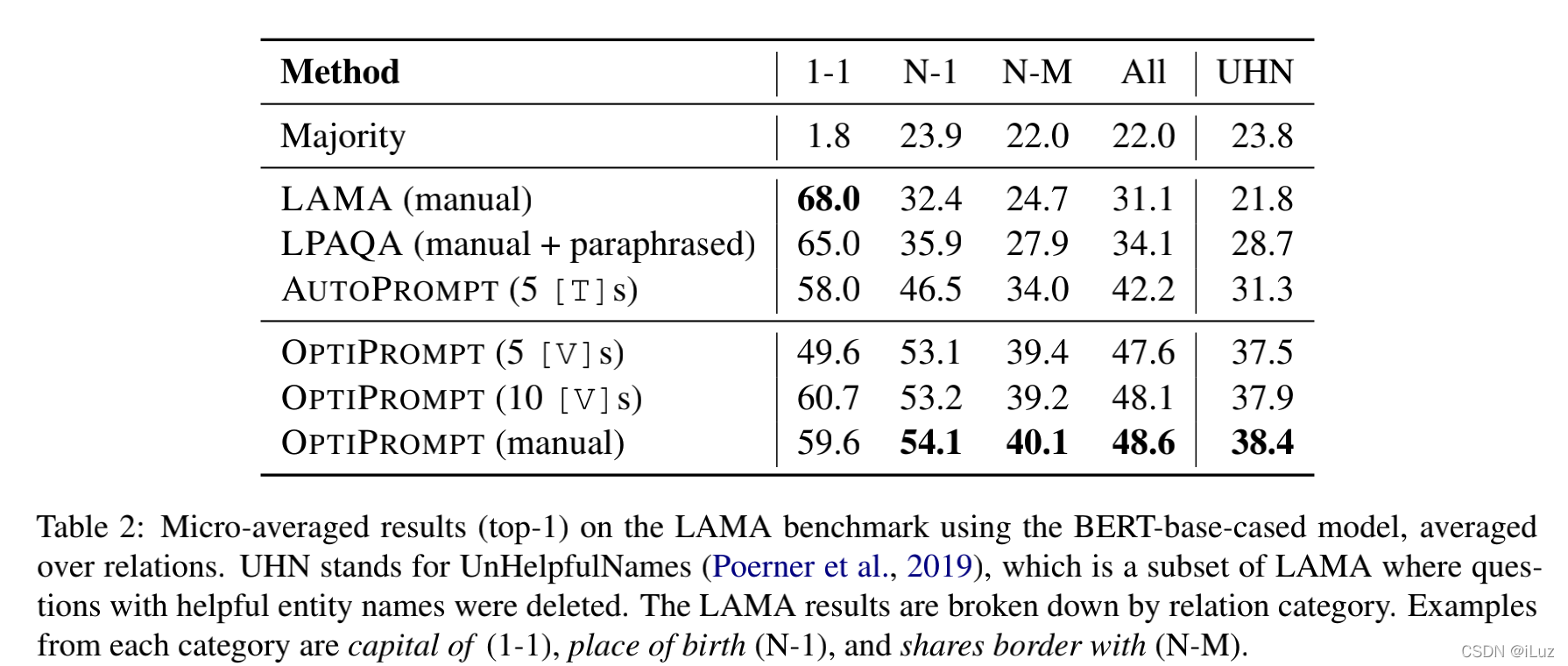
在實驗設定上,作者嘗試了隨機初始化
[
V
]
i
[V]_i
[V]i? 和人工模版初始化
[
V
]
i
[V]_i
[V]i? ,在多種三元組對應關系上,人工初始化的 OPTIPROMTPT 表現最好,值得注意的是,prompt 長度越長,可優化的引數越多,能提取的知識也越多,準確度越高,在筆者自己的實驗中也發現長度越長效果越好,然而作者并沒有就此展開討論,
2. Prompt是否真的有用
LPAQA、AUTOPROMPT 和本文的 OPTIPROMPT 都在 wiki 資料上進行訓練的,wiki 資料上的關系分布是否有利于事實推斷,prompt 又是否可以學習到這樣的資料分布,為了回答這兩個問題,作者設定了三組實驗:
- 作者利用三元組在訓練集中的共現關系證明了 wiki 資料中事實分布的模式有助于預測沒看過的事實,例如,某種關系里只有一兩個對應的主語;
- 通過舍棄預訓練好的引數使得模型不包含任何知識,初始化所有引數從頭訓練 prompt,證明了 prompt 學到了訓練集中的部分關系分布;
- 在第二個實驗中驗證了 prompt 可以學習到部分關系分布,作者進行了第三個實驗探究學習到了哪些分布,將訓練集分為 easy sample 和 hard sample,實驗證明了 OPTIPROMPT 不論難易都比 LPAQA、AUTOPROMPT 有額外的表現,
思考
作者提供的三個量化實驗證明了 prompt 在 factual probing 上有效,除了事實推理,prompt learning 在其他任務上是否同樣奏效,筆者在抽取式問答任務上做的實驗發現,prompt learning 收效甚微,
Prompt 之所以能在 factual probing 上奏效是因為 factual probing 任務并沒有過多的先驗知識和假設,我們可以自然的通過添加 prompt 的方式鼓勵語言模型提取客觀事實,而對于有很多假設的任務而言,prompt 的表現往往不如根據假設特別設計出來的微調任務,例如抽取式問答任務假設里回答就在給定的文本中,通常的微調任務是預測回答的起始位置和終結位置,而如果使用 prompt learning,則需要 prompt 通過訓練自己學到答案就在給定的文本里,在這種強假設的場景下 prompt 的能力有限,
總結
作者提出的 prompt 改進方案十分簡單,但提供了充分扎實的實驗證明了 OPTIPROMPT 的有效性,今年以來,針對 prompt 的研究如雨后春筍般涌現,同期的作業除了把離散空間搜索變為連續空間搜索外,還有復雜化 prompt 的嵌入,增加可調節引數等方向(如 prefix-prompt、P-tuning 等 ),Prompt 由于其只需要微調小部分引數就能學習到樣本里的資訊,在少樣本學習上也有十分可觀的前景,CMU的劉鵬飛博士在他的 Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing 中也稱預訓練語言模型加持下的 prompt learning 可能是未來自然語言處理技術發展的第四范式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394136.html
標籤:AI