簡介
模仿學習是強化學習的好伙伴,使用模仿學習可以讓智能體在比強化學習短得多的時間內得到與人類操作相近的結果,但是這種做法并不能超越人類,而強化學習能夠得到遠超人類的智能體,但訓練時間往往非常漫長,因此我們希望讓智能體并不是從零開始學,我們給予智能體人類的演示,在學習人類演示的基礎上,再進行強化學習,這樣往往能大大減少強化學習的訓練時間,在金字塔環境中,只需要四輪人類的游戲資料,就能使訓練步數減少四分之三以上,因此,模仿學習和強化學習往往是一起使用的,好處是既能大大加快訓練速度,又能得到超越人類的超高水準,
模仿學習是一種Supervised Learning(監督學習)的方法,也就是根據我們給定人類演示中的狀態和對應的動作,就能訓練智能體的策略網路去逼近我們的這個演示,光用模仿學習的缺點是,人類沒有辦法給出環境中所有的狀態對應的做法,往往人類的演示中只包含了所有狀態中的一小部分的應對方式,因此只進行模仿學習后,智能體沒有辦法應對人類演示資料中沒有遇到過的情況,因此才需要用強化學習進行彌補,
ML-Agents提供了關于模仿學習的兩種演算法,一種是Generative Adversarial Imitation Learning(生成對抗模仿學習),簡稱GAIL,還有一種是Behavior Cloning(行為克隆),簡稱BC,在大多數情況下,兩者可以一起使用,
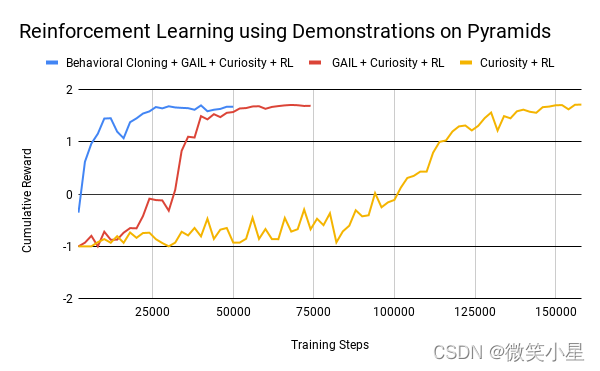
如下圖,在金字塔環境中,同時使用生成對抗模仿學習,行為克隆,好奇心獎勵,普通強化學習四種方法的情況下,得到相同結果的時長大大減少,
下面來講解一下對應的演算法,
注意:這里需要對ML-Agents有一定的了解,詳情請見:Unity強化學習之ML-Agents的使用、ML-Agents命令及配置大全,
Behavioral Cloning
Behavior Cloning(行為克隆),簡稱BC,它的思想較為簡單,就是把智能體的策略網路訓練得和人類的演示資料的行為模式越接近越好,也就是說,輸入相同的狀態s,應當有相近的輸出a,這單純就是一個Supervised Learning,每一個狀態相當于輸入的特征,專家輸出的動作相當于Label(標簽),我們只需要讓模型的輸出接近我們的Label即可,
在這里,BC通常用作預訓練,因此我們需要先進行BC,再進行強化學習,
現在我們看看組態檔中的引數是怎么設定的,
behavioral_cloning:
demo_path: Project/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
steps: 50000
strength: 1.0
samples_per_update: 0
在使用BC之前,應當確保自己已經錄制了演示檔案(后面會講怎么錄制演示),其中的引數含義如下:
demo_path:演示檔案的路徑,
strength:默認為1,表示模仿學習相對于PPO演算法的學習率,表示了BC改變策略的強度,
steps:通常BC應當在模仿學習進行到智能體能夠獲取獎勵時停止,從而正式進入強化學習,當運行的步數大于steps的時候,模仿學習的學習率將為0,也就是不再起作用,如果設為0,那么將會在整個程序中持續進行BC,
batch_size:默認為強化學習使用的batch_size,表示一次性使用多少條資料進行梯度遞減,推薦:512-5120
num_epoch:默認為PPO設定,梯度下降期間需要從經驗池中抽取多少次,推薦:512-5120
samples_per_update:默認為0,每次更新期間使用的最大樣本數,0表示每次拿所有演示資料進行訓練,如果演示資料非常大,應當降低此值防止過擬合,
Generative Adversarial Imitation Learning
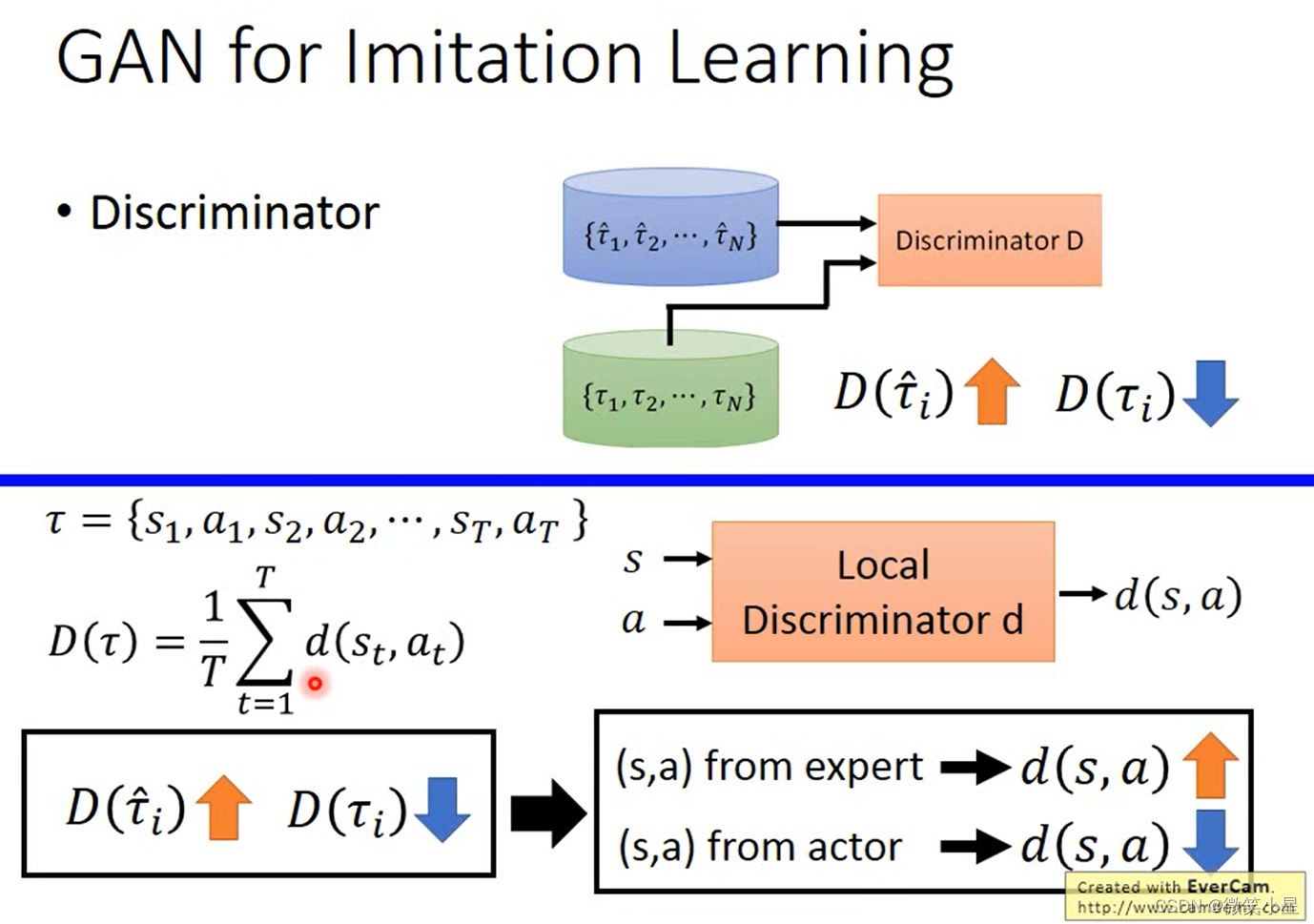
Generative Adversarial Imitation Learning(生成對抗模仿學習),簡稱GAIL,這是受到了生成對抗網路(簡稱GAN)的啟發,對應有一個生成模型和一個判別模型 ,生成模型的目標是生成與真人操作相類似的資料欺騙判別模型,判別模型的任務是盡可能區分哪些是真實資料,哪些是生成的假資料,即是一個輸出reward的網路,我們要盡量保持真實的資料擁有比生成資料更高的累計reward,在彼此對抗中,兩個網路能成長為能夠生成超接近于人類資料的生成模型,以及能夠判別非常解決人類資料的生成資料的判別模型,
GAIL屬于Inverse RL的范疇,即逆強化學習,原本的強化學習是環境給定Reward和下一個狀態 s t + 1 s_{t+1} st+1?,我們用來學習最優的策略,現在,我們需要自己學習出一個輸出Reward網路,即給定 s t s_t st?和 a t a_t at?的情況下,輸出Reward,然后我們在通過這個自己訓練出來的Reward函式來訓練我們的策略模型,這種做法的好處是策略不是直接監督學習的,因此使得學習到的策略更加通用,
策略模型可以通過各種的演算法來訓練,這部分屬于強化學習的領域,論文中使用了TRPO演算法,
GAIL相當于另外的一個內在獎勵,是可以和強化學習的外部獎勵加在一起進行訓練的,專家獎勵設得越高,智能體在環境中就越趨向于模仿專家的行為,合理設定其獎勵上限,智能體就會在一定程度上模仿專家行為的同時,更多地去探索環境,尋找更好的策略,金字塔案例中設為了環境獎勵的0.01,

論文原文:
Generative Adversarial Imitation Learning
參考資料:https://proceedings.neurips.cc/paper/2016/file/cc7e2b878868cbae992d1fb743995d8f-Paper.pdf
【強化學習】GAIL生成對抗模仿學習詳解《Generative adversarial imitation learning》
【論文筆記】GAIL與MAGAIL(1)
GAIL,基于GAN的一種模仿學習方法
現在我們看看組態檔中的引數是怎么設定的,
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
gamma: 0.99
strength: 0.01
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
可以看到GAIL是屬于額外的獎勵信號的一部分,在使用GAIL之前,應當確保自己已經錄制了演示檔案(后面會講怎么錄制演示),其中的引數含義如下:
strength:原始的GAIL獎勵乘以strength就是實際的GAIL獎勵,如果演示資料并不是非常完美應當設得較低(0.01 - 0.1),使得智能體能夠專注于外部獎勵而不是完全復制演示資料,推薦范圍:0.01 - 1
gamma:GAIL獎勵的折扣因子,
demo_path:演示檔案的路徑,
learning_rate:更新判別器的學習率,如果GAIL訓練不穩定,應當減少,
network_settings:判別器的網路規范,
normalize:是否對輸入進行標準化,
hidden_units:隱藏層中節點的個數,推薦范圍:32 - 512
num_layers:神經網路中隱藏層的層數,推薦范圍:1 - 3
vis_encode_type:對應于可視化觀測進行編碼的編碼器型別,選項包含:simple(默認):兩個卷積層組成的簡單編碼器,nature_cnn:三個卷積層組成,詳見https://www.nature.com/articles/nature14236,resnet:由三個堆疊的層構成,是比其他兩個更大的網路,詳見https://arxiv.org/abs/1802.01561,
use_actions:判別器是獲取狀態和動作進行輸入,還是只獲取狀態作為輸入,如果希望智能體模仿演示中的動作,應當設為true,如果只是希望能夠到達相同的狀態但保留動作的多樣性,應當設為false,設為false會比較穩定,但學習較慢,
use_vail:對判別器的性能進行額外的約束,迫使判別器學習一種更一般的表示,降低了其在辨別方面的過擬合,使學習更加穩定,但也會增加訓練時間,如果模仿學習不成功,可以啟用這個功能,詳情參見論文:https://arxiv.org/abs/1810.00821,我也對此做過相應的講解:論文閱讀:Variational Discriminator Bottleneck
錄制演示
首先需要將Demonstration Recorder這個組件添加到智能體身上:

其中引數的含義如下:
Record表示是否開啟錄制,Num Steps To Record表示錄制到多少步自動停止(如果設為0那么只有自己點擊停止運行才能停止),Demostration Name表示生成的檔案名是什么,Demostration Directory表示生成檔案放在什么目錄,
點擊開始游戲之前,如果自己手動操作,那就不要給智能體掛上策略模型,然后在智能體代碼中添加上Heuristic方法用以控制模型的輸出:
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
if (Input.GetKey(KeyCode.D))
{
discreteActionsOut[0] = 3;
}
else if (Input.GetKey(KeyCode.W))
{
discreteActionsOut[0] = 1;
}
else if (Input.GetKey(KeyCode.A))
{
discreteActionsOut[0] = 4;
}
else if (Input.GetKey(KeyCode.S))
{
discreteActionsOut[0] = 2;
}
}
同時我們也可以自己寫一個硬編碼的控制智能體的腳本,或者之前有訓練較好的策略網路拖進智能體中,我們就可以讓智能體自己進行操作,
演示完成后,ML-Agents會在對應的位置生成一個.demo檔案,在Unity中會顯示如下資料:
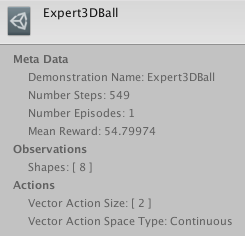
其中顯示出錄制的輸入,輸出,錄制了多少步數,平均獎勵是多少,運行了多少個episode等資料,
實戰分析
推箱子案例
相應環境說明參見之前的文章:ML-Agents案例之推箱子游戲
之前的文章采用了強化學習演算法PPO和SAC以及MA-POCA來訓練智能體,訓練步數超過幾十萬個step達到比較滿意的效果,現在我們采用強化學習 + BC + GAIL來訓練智能體,首先我們需要錄制好對應的演示檔案,并修改組態檔如下:
behaviors:
PushBlock:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
gamma: 0.99
strength: 0.01
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project-new/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
keep_checkpoints: 5
max_steps: 100000
time_horizon: 64
summary_freq: 2500
behavioral_cloning:
demo_path: Project-new/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
steps: 50000
strength: 1.0
samples_per_update: 0
可以看到相比于平常的PPO強化學習演算法,組態檔中加入了behavioral_cloning和gail兩個部分,配置了對應的引數,現在開啟訓練,訓練效果如下:
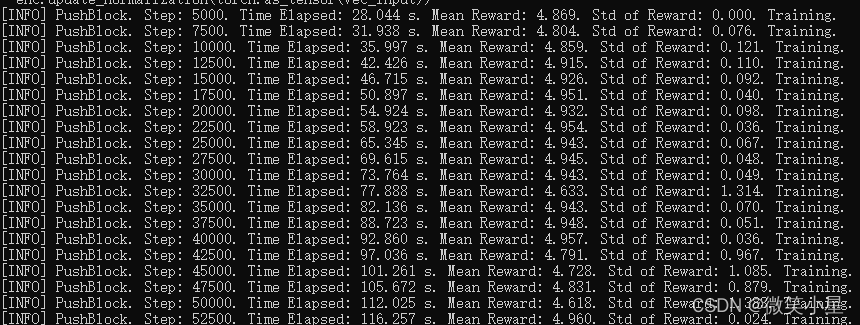
可以看到僅僅經過5000個step,就能達到滿意的效果,訓練時間是直接使用強化學習的幾十分之一,
演示操作得越完美,那么訓練時間就能縮短越多,
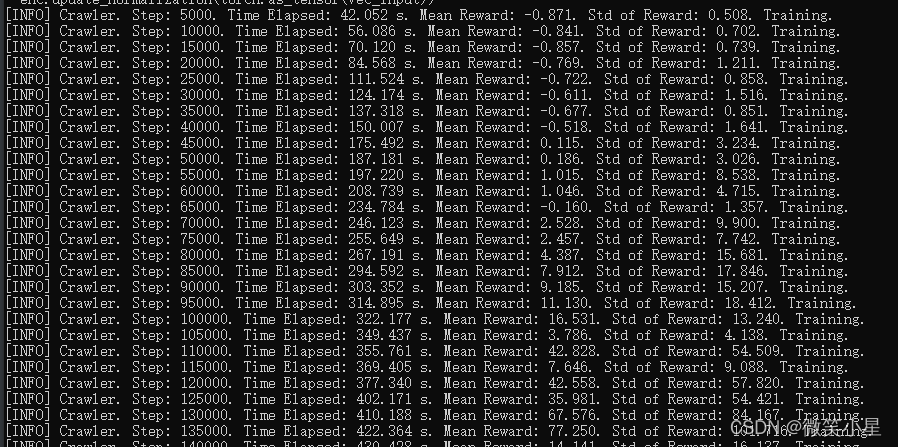
爬蟲案例
相應環境說明參見之前的文章:ML-Agents案例之Crawler
這里甚至不用采用外部獎勵,只用了GAIL + BC就能進行訓練,訓練時長甚至比純強化學習更短,
behaviors:
Crawler:
trainer_type: ppo
hyperparameters:
batch_size: 2024
buffer_size: 20240
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
gail:
gamma: 0.99
strength: 1.0
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project/Assets/ML-Agents/Examples/Crawler/Demos/ExpertCrawler.demo
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 1000
summary_freq: 5000
behavioral_cloning:
demo_path: Project/Assets/ML-Agents/Examples/Crawler/Demos/ExpertCrawler.demo
steps: 50000
strength: 0.5
samples_per_update: 0
金字塔案例
相應環境說明參見之前的文章:ML-Agents案例之金字塔
組態檔如下:
behaviors:
Pyramids:
trainer_type: ppo
time_horizon: 128
max_steps: 1.0e7
hyperparameters:
batch_size: 128
beta: 0.01
buffer_size: 2048
epsilon: 0.2
lambd: 0.95
learning_rate: 0.0003
num_epoch: 3
network_settings:
num_layers: 2
normalize: false
hidden_units: 512
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
curiosity:
strength: 0.02
gamma: 0.99
network_settings:
hidden_units: 256
gail:
strength: 0.01
gamma: 0.99
demo_path: Project/Assets/ML-Agents/Examples/Pyramids/Demos/ExpertPyramid.demo
behavioral_cloning:
demo_path: Project/Assets/ML-Agents/Examples/Pyramids/Demos/ExpertPyramid.demo
strength: 0.5
steps: 150000
可以看到,這里采用了 RL + Curosity + GAIL + BC,四大元素齊聚,每一樣都為我們訓練提供了很大的幫助,效果如下:
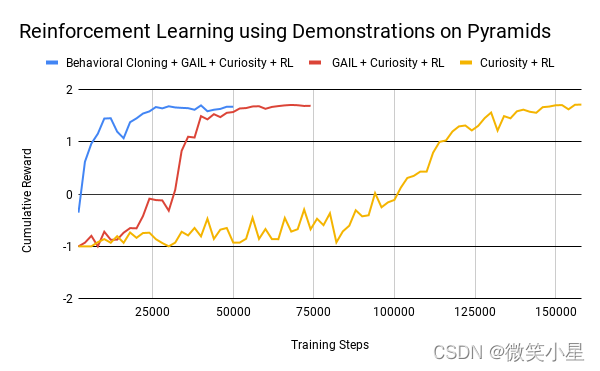
在最初我們訓練成功時,需要至少150000個step才能勉強達到效果,加入GAIL后,只需要50000個step,再加入BC,更是縮短到了25000個step,可見模仿學習和強化學習的能夠產生奇妙的反應,達到1 + 1大于2的效果,
在訓練智能體解決相對困難的任務時,我們往往就需要用這種模仿學習+強化學習的方法解決問題,
看圖配對案例
相應環境說明參見之前的文章:[ML-Agents案例之看圖配對](https://blog.csdn.net/tianjuewudi/article/details/121692539)
組態檔如下:
behaviors:
Hallway:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 1024
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory:
sequence_length: 64
memory_size: 256
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
gamma: 0.99
strength: 0.01
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project/Assets/ML-Agents/Examples/Hallway/Demos/ExpertHallway.demo
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 64
summary_freq: 10000
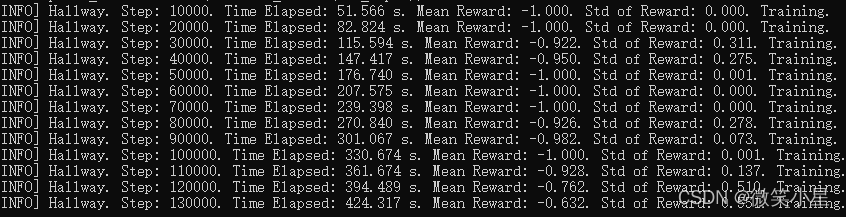
可以看到,我們這里只增加了一個GAIL,但對訓練速度的提升仍然十分顯著,在這種需要記憶的環境下,僅僅十萬個step就使Loss迅速減少:
總結
Behavioral Cloning和Generative Adversarial Imitation Learning相當于強化學習上的兩個掛件,能夠十分顯著得增強強化學習的效果,其中Behavioral Cloning相當于一個預訓練,只在前期使用;而Generative Adversarial Imitation Learning則可以貫穿整個強化學習的始終,相當于又增加了一個內部獎勵,和專家演示的策略越接近,這個獎勵越大,但這個獎勵不能蓋過外部獎勵,以便智能體能探索更多的最優解,
相關文章:
模仿學習(Imitation Learning)入門
ML-Agents案例之Crawler
ML-Agents案例之推箱子游戲
ML-Agents案例之金字塔
ML-Agents案例之看圖配對
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395016.html
標籤:AI
上一篇:【預測模型】基于麻雀演算法改進廣義回歸神經網路(GRNN)實作資料預測matlab代碼
下一篇:(pytorch復現)基于深度強化學習(CNN+dueling network/DQN/DDQN/D3QN)的自適應車間調度(JSP)