為了深入學習各種深度學習網路和強化學習的結合,實作了一下下列文章:
Research on Adaptive Job Shop Scheduling Problems Based on Dueling Double DQN | IEEE Journals & Magazine | IEEE Xplore
狀態、動作、獎勵函式及實驗的簡單介紹可參考:
基于深度強化學習的自適應作業車間調度問題研究_松間沙路的博客-CSDN博客_強化學習調度
整體代碼復現可見個人Github:Aihong-Sun/DQN-DDQN-Dueling_networ-D3QN-_for_JSP: pytorch implementation of DQN/DDQN/Dueling_networ/D3QN for job shop scheudling problem (github.com)
1 狀態特征提取
首先從特征提取開始,原文的狀態特征為3個網格矩陣,如下:
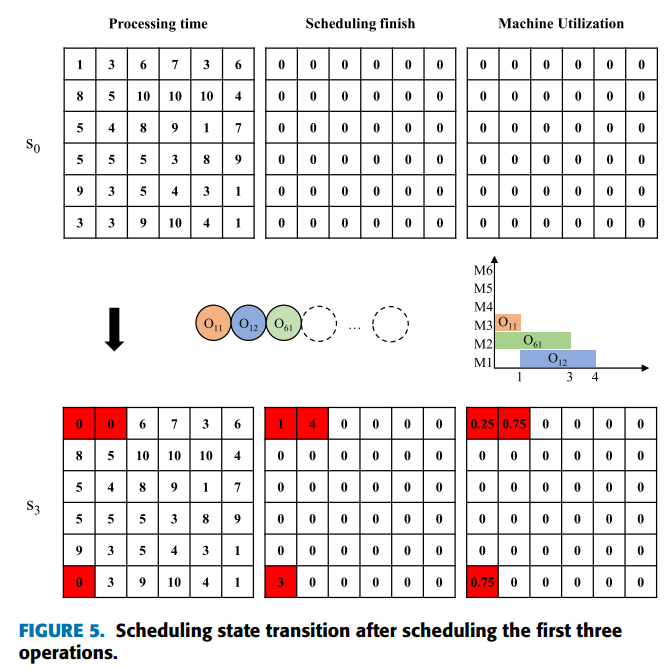
于是搭建CNN進行特征提取:
不太了解CNN的可以參考:卷積神經網路(CNN)詳解 - 知乎 (zhihu.com)
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=6,
kernel_size=3,
stride=1,
padding=1,
), # output shape (3,J_num,O_max_len)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,ceil_mode=False)
)1.1 卷積層
上訴狀態可看作是長、寬為工件數、工件最大工序數(若不相等時取最大,但原文涉及的算例都為工序數相等),深度為3的一個影像,于是in_channels=3,out_channels可按自己的需求進行設計,這里我設為6,即有6個卷積核,輸出的影像的深度就為6,為保證圖片的長寬不變(便于后面針對不同工件數、工序數的全連接層的計算),用0在影像邊緣處進行填充,計算方法如下:

假設Jnum=6,O_max_len=6,于是,令卷積核kernel_size=3,stride=1,padding=1,此時,W2=(6-3+2)/1+1=6,H2=(6-3+2)/1+1=6,于是圖片大小沒變,
1.2 池化層
它的作用是用來逐漸降低資料體的空間尺寸,這樣的話就能減少網路中引數的數量,使得計算資源耗費變少,也能有效控制過擬合,
池化層使用 MAX 操作,對輸入資料體的每一個深度切片獨立進行操作,改變它的空間尺寸,最常見的形式是匯聚層使用尺寸2x2的濾波器,以步長為2來對每個深度切片進行降采樣,
這里設定kernel_size=2,即對影像縮小一般,ceil_mode=False,即針對工件為奇數的情況,比如Jnum=7,Omax_len=7,影像縮小邊緣的數則不取,于是生成新的影像大小為(3,3),若ceil_mode=False,生成新的影像大小則為(4,4).
2 動作
動作為17條規則,具體可見上訴給出的個人Github

3DQN/DDQN/Dueling Network/D3QN
3.1 DQN與DDQN
下面第一個式子為DQN的目標函式,第二個式子為DDQN的目標函式:
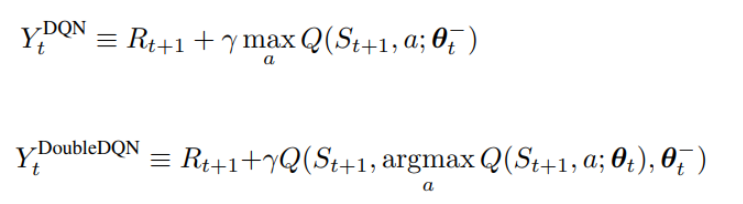
DDQN與DQN大部分都相同,只有一步不同,那就是在選擇Q(s_{t+1},a_{t+1})的程序中,DQN總是選擇Target Q網路的最大輸出值,而DDQN不同,DDQN首先從Q網路中找到最大輸出值的那個動作,然后再找到這個動作對應的Target Q網路的輸出值,這么做的原因是傳統的DQN通常會高估Q值得大小,兩者代碼差別如下:
if self.double: #當為DQN時
# q_eval
q_eval = self.eval_net(batch_state).gather(1, batch_action)
q_next_eval=self.eval_net( batch_next_state).detach()
q_next = self.target_net(batch_next_state).detach()
q_a=q_next_eval.argmax(dim=1)
q_a=torch.reshape(q_a,(-1,len(q_a)))
q_target = batch_reward + self.GAMMA * q_next.gather(1, q_a)
else: #當為DDQN時
#q_eval
q_eval = self.eval_net(batch_state).gather(1,batch_action)
q_next = self.target_net(batch_next_state).detach()
q_target = batch_reward + self.GAMMA * q_next.max(1)[0].view(self.BATCH_SIZE, 1)
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()3.2 DQN 與Dueling Network
Dueling network 是一篇來自2015年的論文,這篇論文提出了一個新的網路架構,這個架構不但提高了最終效果,而且還可以和其他的演算法相結合以獲取更加優異的表現,
之前的DQN網路在將圖片卷積獲取特征之后會輸入幾個全連接層,經過訓練直接輸出在該state下各個action的價值也就是Q(s,a),而Dueling network則不同,它在卷積網路之后引出了兩個不同的分支,一個分支用于預測state的價值,另一個用于預測每個action的優勢,最后將這兩個分支的結果合并輸出Q(s,a),兩者的網路結構如下(上為DQN,下為Dueling network)
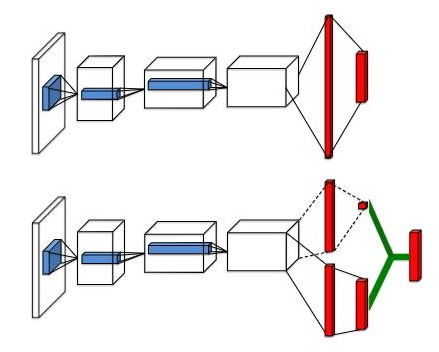
代碼上的區別:
DQN:
class CNN_FNN(nn.Module):
"""docstring for Net"""
def __init__(self,J_num,O_max_len):
super(CNN_FNN, self).__init__()
# summary(self.conv1,(3,6,6))
self.fc1 = nn.Linear(6*int(J_num/2)*int(O_max_len/2), 258)
self.fc2 = nn.Linear(258,258)
self.out = nn.Linear(258,17)
def forward(self,x):
x=self.conv1(x)
x=x.view(x.size(0),-1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
action_prob = self.out(x)
return action_probDueling Network:
class CNN_dueling(nn.Module):
def __init__(self,J_num,O_max_len):
super(CNN_dueling, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=3, #input shape (3,J_num,O_max_len)
out_channels=6,
kernel_size=3,
stride=1,
padding=1, #使得出來的圖片大小不變P=(3-1)/2,
), # output shape (3,J_num,O_max_len)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,ceil_mode=False) #output shape: (6,int(J_num/2),int(O_max_len/2))
)
# summary(self.conv1,(3,6,6))
self.val_hidden = nn.Linear(6*int(J_num/2)*int(O_max_len/2), 258)
self.adv_hidden=nn.Linear(6*int(J_num/2)*int(O_max_len/2), 258)
self.val=nn.Linear(258,1)
self.adv = nn.Linear(258,17)
def forward(self,x):
x=self.conv1(x)
x=x.view(x.size(0),-1)
val_hidden = self.val_hidden(x)
val_hidden = F.relu(val_hidden)
adv_hidden = self.adv_hidden(x)
adv_hidden = F.relu(adv_hidden)
val = self.val(val_hidden)
adv = self.adv(adv_hidden)
adv_ave = torch.mean(adv, dim=1, keepdim=True)
x = adv + val - adv_ave
return xDueling架構的好處:
(1)Dueling network與DQN最主要的不同就是將State與action進行了一定程度的分離,雖然最終的輸出依然相同,但在計算的程序中,state不再完全依賴于action的價值來進行判斷,可以進行單獨的價值預測,這其實是十分有用的,模型既可以學習到某一個state的價值是多少,也可以學習到在該state下不同action的價值是多少,它可以對環境中的state和action進行相對獨立而又緊密結合的觀察學習,可以進行更靈活的處理,同時在某些state中,action的選擇并不會對state產生影響,這時候Dueling模型就可以有更加強大的表現,
(2)在具有多個冗余或者近似的動作時,Dueling可以比DQN更快的識別出策略中的正確操作,
作者在論文中給出了兩個不同的改進公式,需要提前說明的是,這兩個公式的最終效果是類似的,都可以使用:
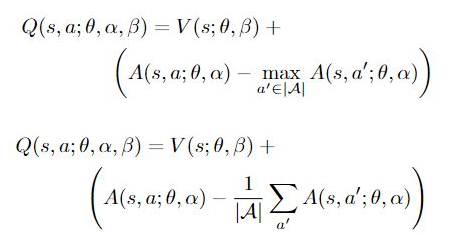
不同點在于,第一個公式是每一個A都減去A的最大值,第二個公式是每一個A都減去A的平均值,這樣即使V和A都分別加減同樣的的常數,最終的結果也不會相同,
3.3 D3QN
D3QN(Dueling Double DQN)是結合了Dueling DQN和Double DQN的優點,
4 調參及相關說明
關于這種自定義環境,收斂是需要通過不斷調參實作的,之前看到一篇文章比較好的講了調參程序,大家可以參考一下:
啟人zhr:強化學習中的調參經驗與編程技巧(on policy 篇)
5 部分代碼展示
5.1 JSP_Env.py
import copy
import matplotlib.pyplot as plt
import numpy as np
def Gantt(Machines):
plt.rcParams['font.sans-serif'] = ['Times New Roman'] # 如果要顯示中文字體,則在此處設為:SimHei
plt.rcParams['axes.unicode_minus'] = False # 顯示負號
M = ['red', 'blue', 'yellow', 'orange', 'green', 'palegoldenrod', 'purple', 'pink', 'Thistle', 'Magenta',
'SlateBlue', 'RoyalBlue', 'Cyan', 'Aqua', 'floralwhite', 'ghostwhite', 'goldenrod', 'mediumslateblue',
'navajowhite', 'navy', 'sandybrown', 'moccasin']
Job_text = ['J' + str(i + 1) for i in range(100)]
Machine_text = ['M' + str(i + 1) for i in range(50)]
for i in range(len(Machines)):
for j in range(len(Machines[i].start)):
if Machines[i].finish[j] - Machines[i].start[j]!= 0:
plt.barh(i, width=Machines[i].finish[j] - Machines[i].start[j],
height=0.8, left=Machines[i].start[j],
color=M[Machines[i]._on[j]],
edgecolor='black')
plt.text(x=Machines[i].start[j]+(Machines[i].finish[j] - Machines[i].start[j])/2 - 0.1,
y=i,
s=Job_text[Machines[i]._on[j]],
fontsize=12)
plt.show()
class Machine:
def __init__(self,idx):
self.idx=idx
self.start=[]
self.finish=[]
self._on=[]
self.end=0
def handling(self,Ji,pt):
s=self.insert(Ji,pt)
# if self.end<=Ji.end:
# s=Ji.end
# else:
# s=self.end
e=s+pt
self.start.append(s)
self.finish.append(e)
self.start.sort()
self.finish.sort()
self._on.insert(self.start.index(s),Ji.idx)
if self.end<e:
self.end=e
Ji.update(s,e)
def Gap(self):
Gap=0
if self.start==[]:
return 0
else:
Gap+=self.start[0]
if len(self.start)>1:
G=[self.start[i+1]-self.finish[i] for i in range(0,len(self.start)-1)]
return Gap+sum(G)
return Gap
def judge_gap(self,t):
Gap = []
if self.start == []:
return Gap
else:
if self.start[0]>0 and self.start[0]>t:
Gap.append([0,self.start[0]])
if len(self.start) > 1:
Gap.extend([[self.finish[i], self.start[i + 1]] for i in range(0, len(self.start) - 1) if
self.start[i + 1] - self.finish[i] > 0 and self.start[i + 1] > t])
return Gap
return Gap
def insert(self,Ji,pt):
start=max(Ji.end,self.end)
Gap=self.judge_gap(Ji.end)
if Gap!=[]:
for Gi in Gap:
if Gi[0]>=Ji.end and Gi[1]-Gi[0]>=pt:
return Gi[0]
elif Gi[0]<Ji.end and Gi[1]-Ji.end>=pt:
return Ji.end
return start
class Job:
def __init__(self,idx,max_ol):
self.idx=idx
self.start=0
self.end=0
self.op=0
self.max_ol=max_ol
self.Gap=0
self.l=0
def wether_end(self):
if self.op<self.max_ol:
return False
else:
return True
def update(self,s,e):
self.op+=1
self.end=e
self.start=s
self.l=self.l+e-s
class JSP_Env:
def __init__(self,n,m,PT,M):
self.n,self.m=n,m
self.O_max_len=len(PT[0])
self.PT=copy.copy(PT)
self.M=M
self.finished=[]
self.Num_finished=0
self.g=0
def Create_Item(self):
self.Jobs=[]
for i in range(self.n):
Ji=Job(i,len(self.PT[i]))
self.Jobs.append(Ji)
self.Machines=[]
for i in range(self.n):
Mi=Machine(i)
self.Machines.append(Mi)
def C_max(self):
m=0
for Mi in self.Machines:
if Mi.end>m:
m=Mi.end
return m
def reset(self):
self.u=0
self.P = 0 # total working time
self.finished=[]
self.Num_finished=0
done=False
self.Create_Item()
self.S1_Matrix = np.array(copy.copy(self.PT))
self.S2_Matrix = np.zeros_like(self.S1_Matrix)
self.S3_Matrix = np.zeros_like(self.S1_Matrix)
self.s=np.stack((self.S1_Matrix,self.S2_Matrix,self.S3_Matrix),0)
# s=self.s.flatten()
return self.s,done
def Gap(self):
G=0
for Mi in self.Machines:
G+=Mi.Gap()
return G/self.C_max()
def U(self):
C_max = self.C_max()
return self.P/(self.m*C_max)
def step(self,action):
# print(action)
done=False
# if action in self.finished:
# s=self.s.flatten()
# return s,-999,done
Ji=self.Jobs[action]
op=Ji.op
# print('a',action,op)
pt=self.PT[action][op]
self.P+=pt
self.s[0][action][op] = 0
Mi=self.Machines[self.M[action][op]]
Mi.handling(Ji,pt)
self.s[1][action][op]=Ji.end
if Ji.wether_end():
self.finished.append(action)
self.Num_finished+=1
if self.Num_finished==self.n:
done=True
Gap=self.Gap()
self.s[2][action][op] =Gap
u=self.U()
r=u-self.u
self.u=u
# s=self.s.flatten()
return self.s,r,done
if __name__=="__main__":
from Dataset.data_extract import change
from Actor_Critic_for_JSP.action_space import Dispatch_rule
import random
n, m, PT, MT = change('ft', 6)
print(PT)
print()
jsp=JSP_Env(n, m, PT, MT)
os1=[]
for i in range(len(PT)):
for j in range(len(PT[i])):
os1.append(i)
s,done=jsp.reset()
while not done:
a=random.randint(0,16)
print('dispatch rule',a)
a=Dispatch_rule(a,jsp)
print('this is action',a)
s, r, done=jsp.step(a)
print(r)
print(done)
os1.remove(a)
shape=len(s)
Gantt(jsp.Machines)
print(jsp.C_max())
5.2 RL_network.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class CNN_FNN(nn.Module):
"""docstring for Net"""
def __init__(self,J_num,O_max_len):
super(CNN_FNN, self).__init__()
# summary(self.conv1,(3,6,6))
self.fc1 = nn.Linear(6*int(J_num/2)*int(O_max_len/2), 258)
self.fc2 = nn.Linear(258,258)
self.out = nn.Linear(258,17)
def forward(self,x):
x=self.conv1(x)
x=x.view(x.size(0),-1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
action_prob = self.out(x)
return action_prob
class CNN_dueling(nn.Module):
def __init__(self,J_num,O_max_len):
super(CNN_dueling, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=3, #input shape (3,J_num,O_max_len)
out_channels=6,
kernel_size=3,
stride=1,
padding=1, #使得出來的圖片大小不變P=(3-1)/2,
), # output shape (3,J_num,O_max_len)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,ceil_mode=False) #output shape: (6,int(J_num/2),int(O_max_len/2))
)
# summary(self.conv1,(3,6,6))
self.val_hidden = nn.Linear(6*int(J_num/2)*int(O_max_len/2), 258)
self.adv_hidden=nn.Linear(6*int(J_num/2)*int(O_max_len/2), 258)
self.val=nn.Linear(258,1)
self.adv = nn.Linear(258,17)
def forward(self,x):
x=self.conv1(x)
x=x.view(x.size(0),-1)
val_hidden = self.val_hidden(x)
val_hidden = F.relu(val_hidden)
adv_hidden = self.adv_hidden(x)
adv_hidden = F.relu(adv_hidden)
val = self.val(val_hidden)
adv = self.adv(adv_hidden)
adv_ave = torch.mean(adv, dim=1, keepdim=True)
x = adv + val - adv_ave
return x5.3 Agent.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from Actor_Critic_for_JSP.Agent.RL_network import CNN_FNN,CNN_dueling
from Actor_Critic_for_JSP.Memory.Memory import Memory
from Actor_Critic_for_JSP.Memory.PreMemory import preMemory
class Agent():
"""docstring for DQN"""
def __init__(self,n,O_max_len,dueling=False,double=False,PER=False):
self.double=double
self.PER=PER
self.GAMMA=1
self.n=n
self.O_max_len=O_max_len
super(Agent, self).__init__()
if dueling:
self.eval_net, self.target_net = CNN_dueling(self.n,self.O_max_len), CNN_dueling(self.n,self.O_max_len)
else:
self.eval_net, self.target_net = CNN_FNN(self.n, self.O_max_len), CNN_FNN(self.n, self.O_max_len)
self.Q_NETWORK_ITERATION=100
self.BATCH_SIZE=256
self.learn_step_counter = 0
self.memory_counter = 0
if PER:
self.memory = preMemory()
else:
self.memory = Memory()
self.EPISILO=0.8
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=0.00001)
self.loss_func = nn.MSELoss()
def choose_action(self, state):
state=np.reshape(state,(-1,3,self.n,self.O_max_len))
state=torch.FloatTensor(state)
# print(state.size())
# state = torch.unsqueeze(torch.FloatTensor(state), 0) # get a 1D array
if np.random.randn() <= self.EPISILO:# greedy policy
action_value = self.eval_net.forward(state)
action = torch.max(action_value, 1)[1].data.numpy()[0]
# action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
else: # random policy
action = np.random.randint(0,17)
# action = action if ENV_A_SHAPE ==0 else action.reshape(ENV_A_SHAPE)
self.EPISILO=min(0.001,self.EPISILO-0.00001)
return action
def PER_error(self,state, action, reward, next_state):
state = torch.FloatTensor(np.reshape(state, (-1, 3, self.n, self.O_max_len)))
next_state= torch.FloatTensor(np.reshape(next_state, (-1, 3, self.n, self.O_max_len)))
p=self.eval_net.forward(state)
p_=self.eval_net.forward(next_state)
p_target=self.target_net(state)
if self.double:
q_a=p_.argmax(dim=1)
q_a=torch.reshape(q_a,(-1,len(q_a)))
qt=reward+self.GAMMA*p_target.gather(1,q_a)
else:
qt=reward+self.GAMMA*p_target.max(1)[0].view(self.BATCH_SIZE, 1)
qt=qt.detach().numpy()
p=p.detach().numpy()
errors=np.abs(p[0][action]-qt[0][0])
return errors
def store_transition(self, state, action, reward, next_state):
if self.PER:
errors=self.PER_error(state, action, reward, next_state)
self.memory.remember((state, action, reward, next_state), errors)
self.memory_counter += 1
else:
self.memory.remember((state, action, reward, next_state))
self.memory_counter+=1
def learn(self):
#update the parameters
if self.learn_step_counter % self.Q_NETWORK_ITERATION ==0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter+=1
batch=self.memory.sample(self.BATCH_SIZE)
#sample batch from memory
batch_state=np.array([o[0] for o in batch])
batch_next_state= np.array([o[3] for o in batch])
batch_action=np.array([o[1] for o in batch])
batch_reward=np.array([o[1] for o in batch])
batch_action = torch.LongTensor(np.reshape(batch_action, (-1, len(batch_action))))
batch_reward = torch.LongTensor(np.reshape(batch_reward, (-1, len(batch_reward))))
batch_state=torch.FloatTensor(np.reshape(batch_state, (-1, 3, self.n, self.O_max_len)))
batch_next_state =torch.FloatTensor(np.reshape(batch_next_state, (-1, 3, self.n, self.O_max_len)))
if self.double:
# q_eval
q_eval = self.eval_net(batch_state).gather(1, batch_action)
q_next_eval=self.eval_net( batch_next_state).detach()
q_next = self.target_net(batch_next_state).detach()
q_a=q_next_eval.argmax(dim=1)
q_a=torch.reshape(q_a,(-1,len(q_a)))
q_target = batch_reward + self.GAMMA * q_next.gather(1, q_a)
else:
#q_eval
q_eval = self.eval_net(batch_state).gather(1,batch_action)
q_next = self.target_net(batch_next_state).detach()
q_target = batch_reward + self.GAMMA * q_next.max(1)[0].view(self.BATCH_SIZE, 1)
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()5.4 train.py
from Actor_Critic_for_JSP.JSP_env import JSP_Env,Gantt
import matplotlib.pyplot as plt
from Actor_Critic_for_JSP.Dataset.data_extract import change
from Actor_Critic_for_JSP.action_space import Dispatch_rule
from Actor_Critic_for_JSP.Agent.Agent import Agent
def main(Agent,env,batch_size):
Reward_total = []
C_total = []
rewards_list = []
C = []
episodes = 8000
print("Collecting Experience....")
for i in range(episodes):
print(i)
state,done = env.reset()
ep_reward = 0
while True:
action = Agent.choose_action(state)
a=Dispatch_rule(action,env)
try:
next_state, reward, done = env.step(a)
except:
print(action,a)
Agent.store_transition(state, action, reward, next_state)
ep_reward += reward
if Agent.memory_counter >= batch_size:
Agent.learn()
if done and i%1==0:
ret, f, C1, R1 = evaluate(i,Agent,env)
Reward_total.append(R1)
C_total.append(C1)
rewards_list.append( ep_reward)
C.append(env.C_max())
if done:
# Gantt(env.Machines)
break
state = next_state
x = [_ for _ in range(len(C))]
plt.plot(x, rewards_list)
# plt.show()
plt.plot(x, C)
# plt.show()
return Reward_total,C_total
def evaluate(i,Agent,env):
returns = []
C=[]
for total_step in range(10):
state, done = env.reset()
ep_reward = 0
while True:
action = Agent.choose_action(state)
a = Dispatch_rule(action, env)
try:
next_state, reward, done = env.step(a)
except:
print(action,a)
ep_reward += reward
if done == True:
fitness = env.C_max()
C.append(fitness)
break
returns.append(ep_reward)
print('time step:',i,'','Reward :',sum(returns)/10 ,'','C_max:',sum(C) /10)
return sum(returns) / 10,sum(C) /10,C,returns
if __name__ == '__main__':
import pickle
import os
n, m, PT, MT = change('la', 16)
f=r'.\result\la'
if not os.path.exists(f):
os.mkdir(f)
f1=os.path.join(f,'la'+'16')
if not os.path.exists(f1):
os.mkdir(f1)
print(n, m, PT, MT)
env = JSP_Env(n, m, PT, MT)
# (0,0)CNN+FNN+DQN (1,0):CNN+Dueling network+DQN (0,1):CNN+FNN+DDQN (1,1):CNN+Dueling network+DDQN
agent=Agent(env.n,env.O_max_len,1,1)
Reward_total,C_total=main(agent,env,100)
print(os.path.join(f1, 'C_max' + ".pkl"))
with open(os.path.join(f1, 'C_max' + ".pkl"), "wb") as f2:
pickle.dump(C_total, f2, pickle.HIGHEST_PROTOCOL)
with open(os.path.join(f1, 'Reward' + ".pkl"), "wb") as f3:
pickle.dump(Reward_total, f3, pickle.HIGHEST_PROTOCOL)轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395017.html
標籤:AI
上一篇:模仿學習與強化學習的結合(原理講解與ML-Agents實作)
下一篇:R語言dplyr包使用bind_rows函式縱向合并兩個dataframe(行生長)、使用bind_cols函式橫向合并兩個dataframe(列生長)