輸入為網頁有向圖的鄰接表:

通過統計輸入檔案的行數,即可得之網頁總數為4
每個網頁的初值為1/N,即0.25
第一行輸入經過map處理后,得到如下結果:
B 0.0833
C 0.0833
D 0.0833
同理,第二三四行經過map處理后,得到:
A 0.125
D 0.125
C 0.25
B 0.125
C 0.125
系統會自動對map的輸出進行shuflle處理,即對key進行排序,將相同key的value合并成一個串列,
即
A 0.125
B 0.0833 0.125
C 0.0833 0.25 0.125
D 0.0833 0.125 0.125
此時出現一個疑問:
為什么要進行這一步,而不是直接將相同key的value進行加和呢?
是為了MapReduce編程的可擴展性,在已知PageRank任務的前提下,我們知道要對相同key的value進行加和,如果是求最大值的任務呢?
所以把對value串列的操作交給reduce,我們要怎么操作這些串列,只要對reduce進行撰寫即可,
為解決網頁間的終止點問題和陷阱問題,需要在reduce中進行如下處理(網頁沒有出鏈或者出鏈只有自己,pr值迭代后只增不減)
假設:上網者通過出鏈訪問其他網頁的概率為a,通過地址欄隨機訪問頁面的概率為(1-a)
所以,在reduce程序,某網頁pr變換為:
a *(接收其他網頁發送來的pr值) + (1-a) * 1/N
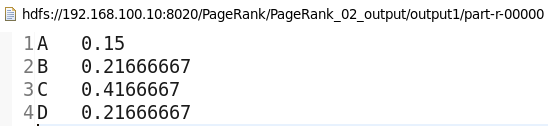
經過reduce處理后,網頁的pr值為
A = 0.8 * 0.125 + 0.2 * 0.25 = 0.15
B = 0.8 * (0.0833 + 0.125) + 0.2 * 0.25 = 0.216
C = 0.8 * (0.0833 + 0.25) + 0.2 * 0.25 = 0.416
D = 0.8 * (0.0833 + 0.125 + 0.125) + 0.2 * 0.25 = 0.216
此時一輪迭代結束,將reduce的結果輸出
那么何時停止迭代呢?
要么到達最大迭代次數,要么pr值的變化已經收斂(pr值的曲線圖趨于水平)
如何判斷pr值收斂:
設定一個引數epi,若 max | Pi j - P i j-1| < epi ,則說明pr值的變化已經收斂,
完整的程式如下:(支持eclipse Run on Hadoop,不支持yarn -jar運行,因為yarn -jar運行時,只能訪問類中static變數的初始值,若在程式運行時對static變數的值進行更改,則map/reduce中得到的變數值還是舊值)
package test02;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class PageRank_02 {
private static int N = 1;
private static float a = 0.8f;
private static int maxIteration = 40;
private static float epi = 0.000001f;
private static HashMap<String, Float> map;
private static HashMap<String, Float> old_map;
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: <in> <out> [max_iteration] [epi]");
System.err.println(" max_iteration -- Integer, default 40");
System.err.println(" epi -- Float, default 0.000001f");
System.exit(2);
}
String input = "";
if (otherArgs.length > 0)
input = otherArgs[0];
String output = "";
if (otherArgs.length > 1)
output = otherArgs[1];
if (otherArgs.length > 2)
setMaxIteration(Integer.parseInt(otherArgs[2]));
if (otherArgs.length > 3)
setEpi(Float.parseFloat(otherArgs[3]));
// 統計input檔案行數,即網頁個數
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = fs.open(new Path(input));
BufferedReader d = new BufferedReader(new InputStreamReader(in));
int count = 0;
String line;
while ((line = d.readLine()) != null) {
count += 1;
}
System.err.println("Numbers of pages: " + count);
setN(count);
d.close();
in.close();
for (int i = 0; i < getMaxIteration(); i++) {
map = new HashMap<String, Float>();
Job job = Job.getInstance(conf, "page rank");
job.setJarByClass(PageRank_02.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(input));
String new_output = output + (i + 1);// 把下一次的輸出設定成一個新地址,
// 輸出路徑存在,則洗掉
Path new_output_path = new Path(new_output);
if (fs.exists(new_output_path)) {
fs.delete(new_output_path, true);
}
FileOutputFormat.setOutputPath(job, new_output_path);
job.waitForCompletion(true);
float max_delta = -1.0f;
if (i > 0) {
for (String key : map.keySet()) {
max_delta = Math.max(max_delta, Math.abs(map.get(key) - old_map.get(key)));
}
}
System.err.println("iteration: " + i + " , MaxIteration: " + getMaxIteration());
System.err.println("N: " + getN());
System.err.println("a: " + getA());
System.err.println("max_delta: " + max_delta);
System.err.println("epi: " + getEpi());
if (max_delta < epi && i > 0)
break;
old_map = map;
}
System.exit(0);
}
/* map程序 */
public static class PageRankMapper extends Mapper<Object, Text, Text, Text> {
private String id;
private float pr;
private int count;
private float average_pr;
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer str = new StringTokenizer(value.toString());// 對value進行決議
id = str.nextToken();// id為決議的第一個詞,代表當前網頁
if(old_map!=null && old_map.containsKey(id)) {
pr = old_map.get(id);
} else {
pr = 1.0f / N;
}
count = str.countTokens();// count為剩余詞的個數,代表當前網頁的出鏈網頁個數
average_pr = pr / count;// 求出當前網頁對出鏈網頁的貢獻值
while (str.hasMoreTokens()) {
String linkid = str.nextToken();
context.write(new Text(linkid), new Text(average_pr + ""));// 輸出的是<出鏈網頁,獲得的貢獻值>
}
}
}
/* reduce程序 */
public static class PageRankReduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
float pr = 0;
for (Text val : values) {
pr += Float.parseFloat(val.toString());
}
pr = getA() * pr + (1 - getA()) * (1.0f / getN());// 加入跳轉因子
map.put(key.toString(), pr);
context.write(key, new Text(pr + ""));
}
}
public static float getEpi() {
return epi;
}
public static void setEpi(float epi) {
PageRank_02.epi = epi;
}
public static float getA() {
return a;
}
public static void setA(float a) {
PageRank_02.a = a;
}
public static int getMaxIteration() {
return maxIteration;
}
public static void setMaxIteration(int maxIteration) {
PageRank_02.maxIteration = maxIteration;
}
public static int getN() {
return N;
}
public static void setN(int n) {
PageRank_02.N = n;
}
}
程式輸入引數分別為:輸入檔案 輸出檔案 Max_iteration epi
Run Configurations設定如下
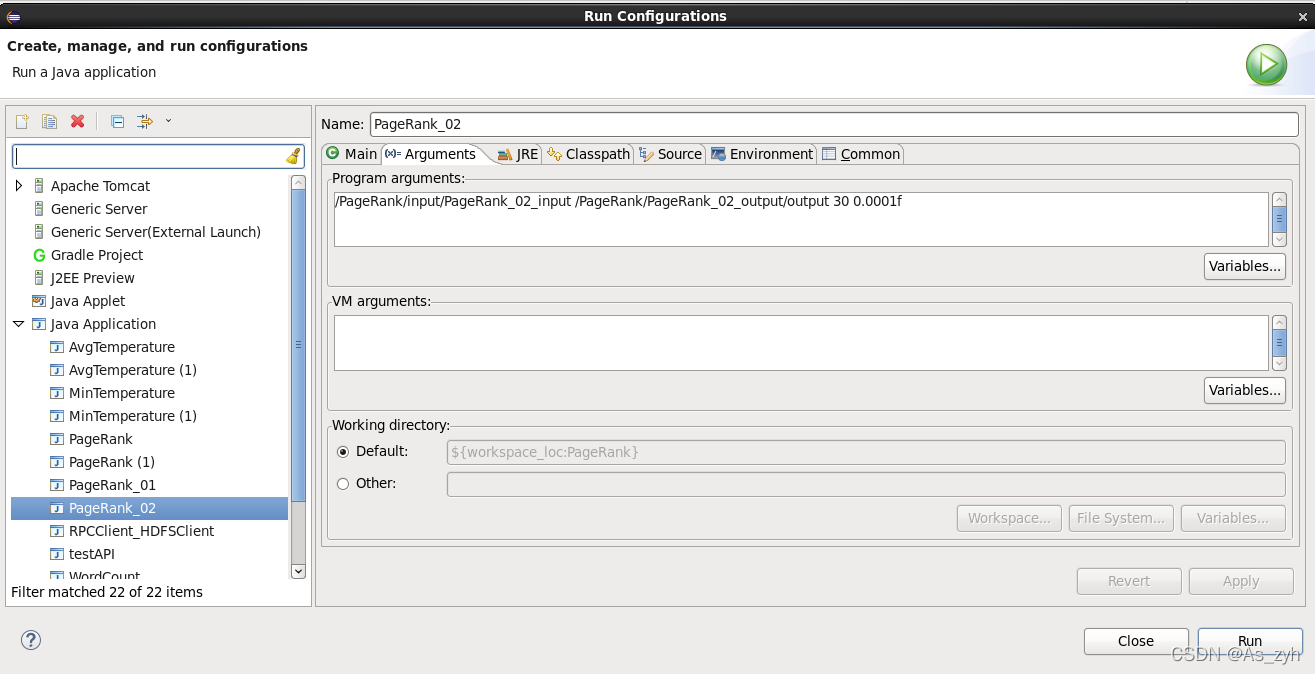 按照如圖配置運行程式
按照如圖配置運行程式
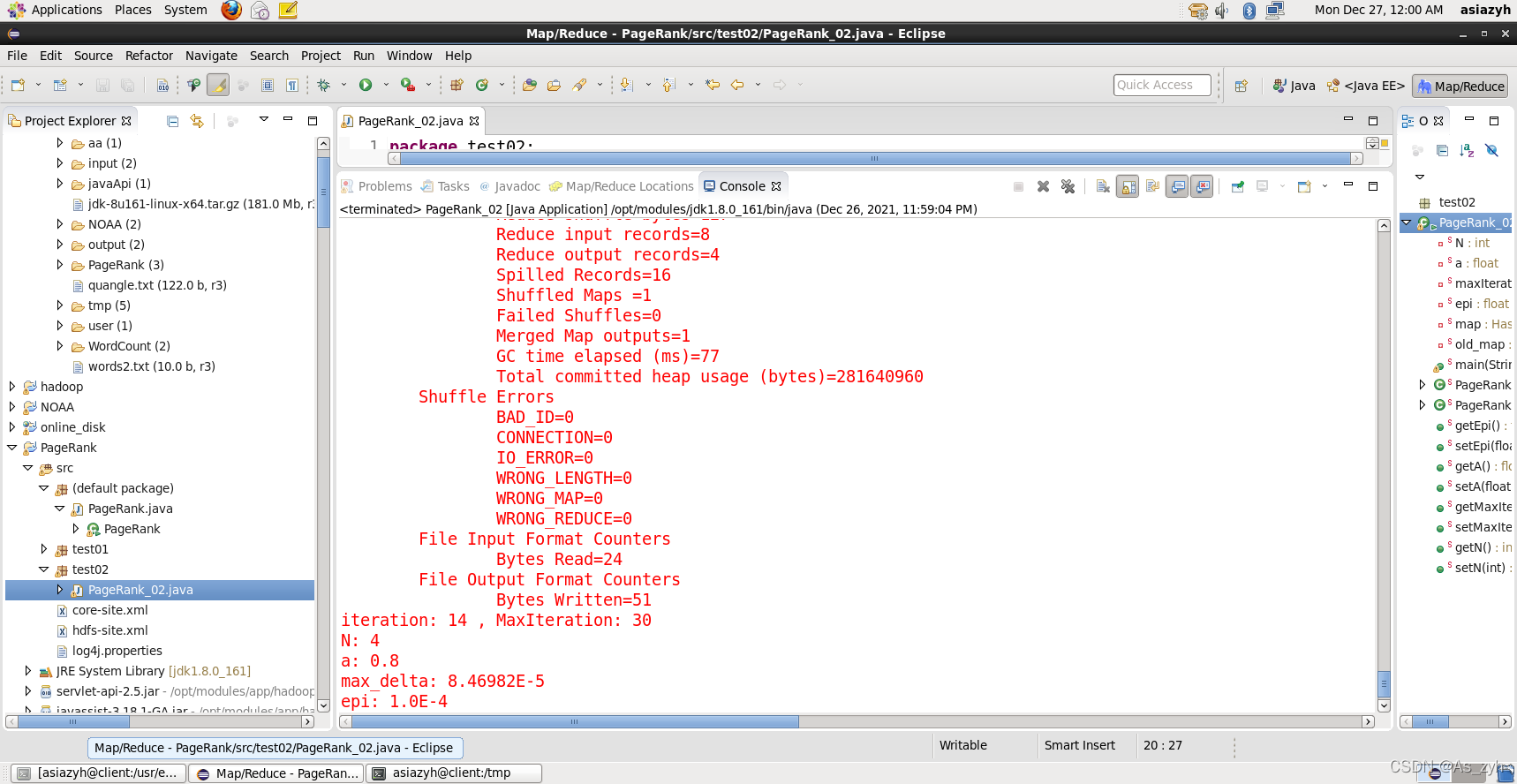
在iteration: 14時,程式退出回圈
pr值變化的最大值:
max_delta = 0.0000846
設定的引數epi:
epi = 0.0001
max_delta < epi
即pr值已收斂
參考文獻:
1.MapReduce 之PageRank演算法概述、設計思路和原始碼分析https://blog.csdn.net/u010414589/article/details/51404971
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395075.html
標籤:其他