文章目錄
- 資料采集框架Flume
- Flume基本介紹
- 概述
- 運行機制
- Flume采集系統結構圖
- 1. 簡單結構
- 2. 復雜結構
- Flume實戰案例
- 采集網路埠資料
- 1. Flume的安裝部署
- 2. 開發組態檔
- 3. 啟動
- 4. 使用 telnet 測驗
- 采集目錄到HDFS
- 1. 需求分析
- 2. 開發組態檔
- 3. 啟動&測驗
- 采集檔案到HDFS
- 1. 需求分析
- 2. 開發組態檔
- 3. 啟動&測驗
- 實作斷點續傳
- 1. 需求分析
- 2. 開發組態檔
- 3. 啟動&測驗
- 兩個 agent 級聯
- 1. 需求分析
- 2. node02安裝flume
- 3. 開發組態檔
- 4. 啟動&測驗
- 更多source和sink組件
- Flume進階
- 高可用Flume-NG配置案例
- 1. 角色分配
- 2. 集群搭建
- 3. 配置flume collection
- 4. 啟動&測驗
資料采集框架Flume
- 在一個完整的離線大資料處理系統中,除了hdfs+mapreduce+hive組成分析系統的核心之外,還需要資料采集、結果資料匯出、任務調度等不可或缺的輔助系統,而這些輔助工具在hadoop生態體系中都有便捷的開源框架,
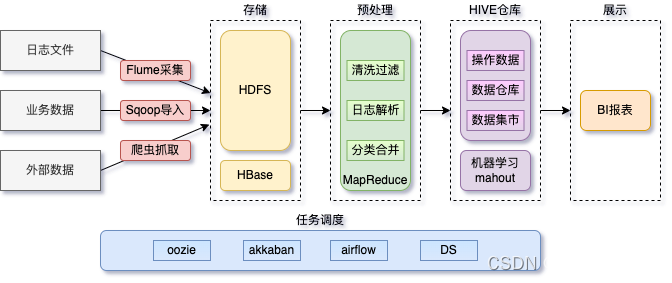
Flume基本介紹
概述
-
Flume是一個分布式、可靠、高可用的海量日志采集、聚合和傳輸的系統,
-
Flume可以采集檔案,socket資料包、檔案、檔案夾、kafka等各種形式源資料,又可以將采集到的資料(下沉sink)輸出到HDFS、hbase、hive、kafka等眾多外部存盤系統中
-
一般的采集需求,通過對flume的簡單配置即可實作
-
Flume針對特殊場景也具備良好的自定義擴展能力,因此,flume可以適用于大部分的日常資料采集場景
運行機制
-
Flume分布式系統中最核心的角色是agent,flume采集系統就是由一個個agent所連接起來形成的
-
每一個agent相當于一個資料傳遞員,內部有三個組件:
- Source:采集組件,用于跟資料源對接,以獲取資料
- Sink:下沉組件,用于往下一級agent傳遞資料或者往最終存盤系統傳遞資料
- Channel:傳輸通道組件,用于從 source 將資料傳遞到sink
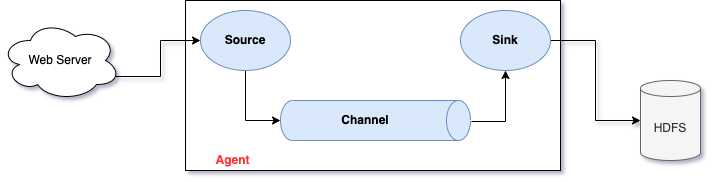
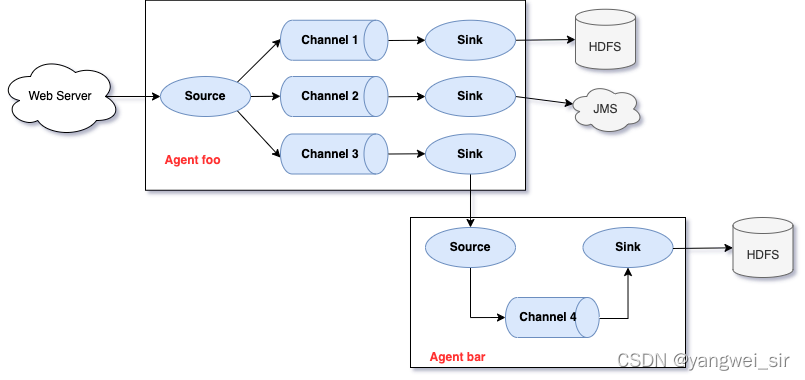
Flume采集系統結構圖
1. 簡單結構
- 單個 Agent 采集資料
2. 復雜結構
- 兩個 Agent 之間串聯
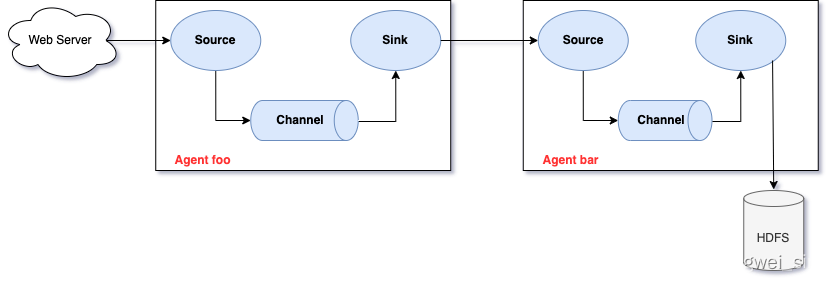
- 多個 Agent 之間串聯
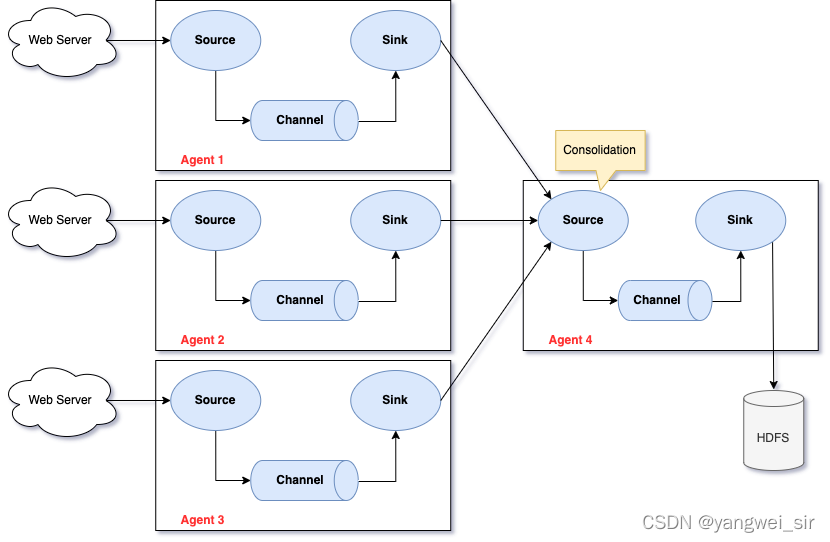
- 多級 channel
Flume實戰案例
- 需求:收集網路埠的資料,并將資料列印到linux的控制臺上面,
- 在 node02 上,通過
telnet node03 44444發送資料 - 在 node03 上,通過 flume 接收 44444 埠的資料并列印到控制臺
- 在 node02 上,通過
采集網路埠資料
1. Flume的安裝部署
- Flume的安裝非常簡單,只需要解壓即可,
- 上傳安裝包到資料源所在節點上,這里我們在第三臺機器 node03 來進行安裝
$ pwd
/bigdata/soft
$ tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /bigdata/install/
# 修改組態檔
$ cd /bigdata/install/apache-flume-1.9.0-bin/conf/
$ cp flume-env.sh.template flume-env.sh
$ vim flume-env.sh
export JAVA_HOME=/usr/apps/jdk1.8.0_241
- 解決 jar 包沖突:apache-flume-1.9.0-bin、hadoop-3.1.4都有guava包,但是版本不一致,會造成沖突
- 將 flume 中低版本的 guava 包替換成 hadoop 中高版本的 guava 包
$ pwd
/bigdata/install/apache-flume-1.9.0-bin
$ rm -rf lib/guava-11.0.2.jar
$ cp /bigdata/install/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar lib/
2. 開發組態檔
- 根據資料采集的需求配置采集方案,描述在組態檔中(檔案名可任意自定義)
- 需求:配置我們的網路收集的組態檔,從某socket埠采集資料,采集到的資料列印到console控制臺
- 在flume的conf目錄下新建一個組態檔(采集方案)
$ pwd
/bigdata/install/apache-flume-1.9.0-bin
$ vim conf/netcat-logger.conf
- 內容如下:
# 1. 定義這個agent中各組件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2. 描述和配置source組件:r1
a1.sources.r1.type = netcat
# 當前節點的ip地址
a1.sources.r1.bind = node03
a1.sources.r1.port = 44444
# 3. 描述和配置sink組件:k1
a1.sinks.k1.type = logger
# 4. 描述和配置channel組件,此處使用是記憶體快取的方式
a1.channels.c1.type = memory
# channel中存盤的event的最大個數
a1.channels.c1.capacity = 1000
# channel每次從source獲得的event最多個數或一次發往sink的event最多個數
a1.channels.c1.transactionCapacity = 100
# 5. 描述和配置source channel sink之間的連接關系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 對應型別組件的官網檔案
- netcat-tcp-source
- logger-sink
- memory-channel
3. 啟動
- 指定采集方案組態檔,在相應的節點上啟動flume agent
- 先用一個最簡單的例子來測驗一下程式環境是否正常
$ pwd
/bigdata/install/apache-flume-1.9.0-bin
$ bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的conf目錄中的組態檔
-f conf/netcat-logger.con 指定我們所描述的采集方案
-n a1 指定我們這個agent的名字
-Dflume.root.logger=INFO,console 將info級別的日志列印到控制臺

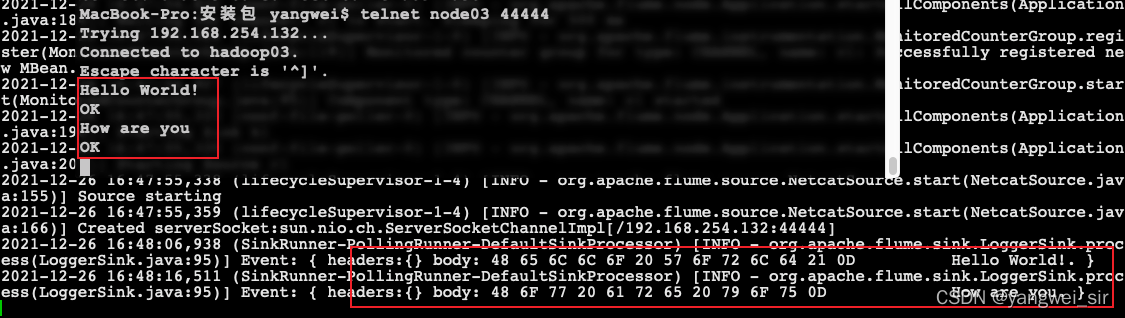
4. 使用 telnet 測驗
- 在node02機器上面安裝telnet客戶端,用于模擬資料的發送
sudo yum -y install telnet
telnet node03 44444 # 使用telnet模擬資料發送
采集目錄到HDFS
1. 需求分析
- 需求:某服務器的某特定目錄下,會不斷產生新的檔案,每當有新檔案出現,就需要把檔案采集到HDFS中去,
- 根據需求,首先定義三大要素
- 資料源組件:即 source,使用 spooldir 監控檔案目錄
- 下沉組件:即 sink,使用 HDFS 檔案系統
- 通道組件:即 channel,使用 file channel,也可以使用記憶體 channel
- spooldir特性:
- 監視一個目錄,只要目錄中出現新檔案,就會采集檔案中的內容
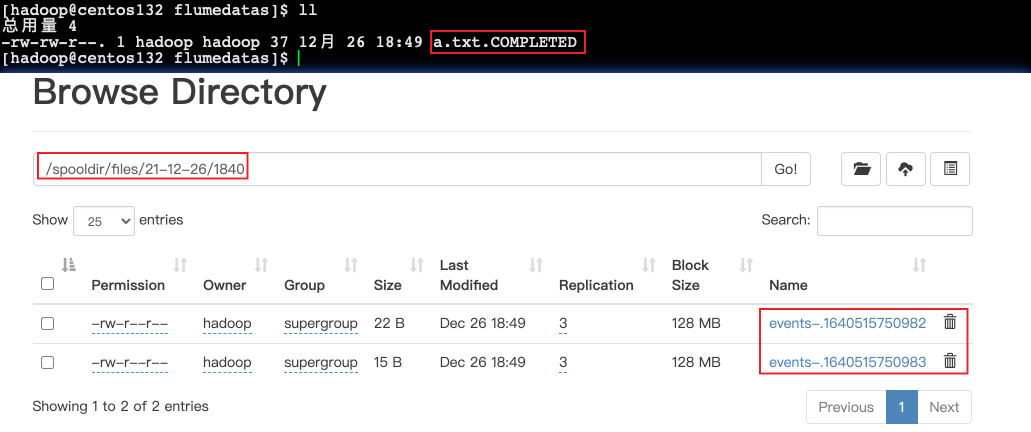
- 采集完成的檔案,會被agent自動添加一個后綴:COMPLETED
- 此source可靠,不會丟失資料,即使 flume 重啟或被 kill
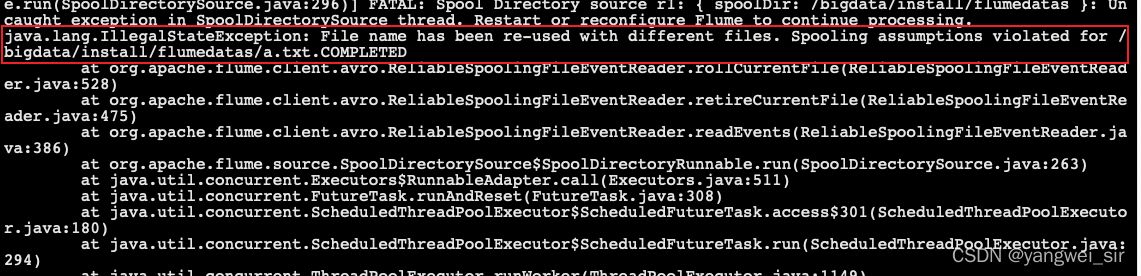
- 注意:所監視的目錄中不允許有同名的檔案;且檔案被放入spooldir后,就不能修改
- ① 如果檔案放入spooldir后,又向檔案寫入資料,會列印錯誤及停止
- ② 如果有同名的檔案出現在spooldir,也會列印錯誤及停止
2. 開發組態檔
vim conf/spooldir.conf,內容如下:
# 1. Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2. Describe/configure the source
# 注意:不能往監控目中重復丟同名檔案
a1.sources.r1.type = spooldir
# 監控的路徑
a1.sources.r1.spoolDir = /bigdata/install/flumedatas
# Whether to add a header storing the absolute path filename
# 檔案絕對路徑放到header
a1.sources.r1.fileHeader = true
# 3. Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
# 采集到的資料寫入到此路徑
a1.sinks.k1.hdfs.path = hdfs://node01:8020/spooldir/files/%y-%m-%d/%H%M/
# 指定在hdfs上生成的檔案名前綴
a1.sinks.k1.hdfs.filePrefix = events-
# timestamp向下取整round down
a1.sinks.k1.hdfs.round = true
# 按10分鐘,為單位向下取整;如55分,舍成50;38 -> 30
a1.sinks.k1.hdfs.roundValue = 10
# round的單位
a1.sinks.k1.hdfs.roundUnit = minute
# 每3秒滾動生成一個檔案;默認30;(0 = never roll based on time interval)
a1.sinks.k1.hdfs.rollInterval = 3
# 每x位元組,滾動生成一個檔案;默認1024;(0: never roll based on file size)
a1.sinks.k1.hdfs.rollSize = 20
# 每x個event,滾動生成一個檔案;默認10; (0 = never roll based on number of events)
a1.sinks.k1.hdfs.rollCount = 5
# 每x個event,flush到hdfs
a1.sinks.k1.hdfs.batchSize = 1
# 使用本地時間
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 生成的檔案型別,默認是Sequencefile;可選DataStream,則為普通文本;可選CompressedStream壓縮資料
a1.sinks.k1.hdfs.fileType = DataStream
# 4. Use a channel which buffers events in memory
a1.channels.c1.type = memory
# channel中存盤的event的最大數目
a1.channels.c1.capacity = 1000
# 每次傳輸資料,從source最多獲得event的數目或向sink發送的event的最大的數目
a1.channels.c1.transactionCapacity = 100
# 5. Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
-
對應型別組件的官網檔案
- spooling directory source
- hdfs sink
- memory channel
-
Channel引數解釋:
- capacity:默認該通道中最大的可以存盤的 event 數量
- trasactionCapacity:每次最大可以從 source 中拿到或者送到 sink 中的 event 數量
- keep-alive:event 添加到通道中或者移出的允許時間
3. 啟動&測驗
bin/flume-ng agent -c conf -f conf/spooldir.conf -n a1 -Dflume.root.logger=INFO,console
- 將不同的檔案上傳到下面目錄里面去,注意檔案不能重名
cd /bigdata/install/flumedatas
# vim a.txt 加入如下內容
ab cd ef
english math
hadoop alibaba
- 然后觀察flume的console動靜、hdfs webui生成的檔案
- 如果將同名檔案再次放到
/bigdata/install/flumedatas就會報錯:
cp a.txt /bigdata/install/flumedatas
采集檔案到HDFS
1. 需求分析
- 比如業務系統使用log4j生成的日志,日志內容不斷增加,需要把追加到日志檔案中的資料實時采集到hdfs
- 根據需求,首先定義三大要素
- 資料源組件:即 source,使用
exec 'tail -F file'監控檔案內容更新 - 下沉組件:即 sink,使用 HDFS 檔案系統
- 通道組件:即 channel,使用 file channel,也可以使用記憶體 channel
- 資料源組件:即 source,使用
2. 開發組態檔
vim conf/tail-file.conf,內容如下:
# 1. Name the components on this agent
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 2. Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /bigdata/install/flumedatas/taillogs/access_log
agent1.sources.source1.channels = channel1
# 3. Describe sink
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://node01:8020/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
# 允許打開的檔案數;如果超出5000,老檔案會被關閉
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 4. Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
# 向channel添加一個event或從channel移除一個event的超時時間
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# 5. Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
- 對應型別組件的官網檔案
- hdfs sink
- memory channel
3. 啟動&測驗
bin/flume-ng agent -c conf -f conf/tail-file.conf -n agent1 -Dflume.root.logger=INFO,console
- 寫一個腳本,定義追加一些內容到指定檔案:
vim tail-file.sh
#!/bin/bash
while true
do
date >> /bigdata/install/flumedatas/taillogs/access_log;
sleep 0.5;
done
- 啟動腳本
chmod u+x tail-file.sh
./tail-file.sh
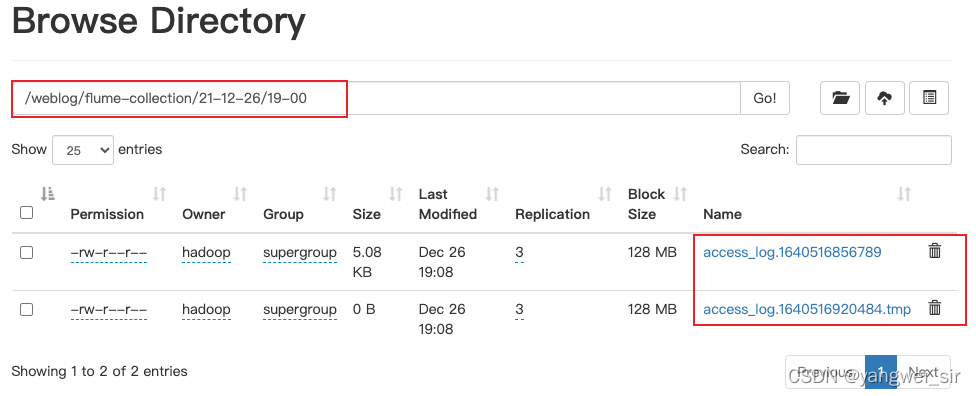
實作斷點續傳
- 不管是上面的 spoolDir 還是 exec Source dir 都有一個缺陷就是沒法實作斷點續傳的功能,為此在flume1.7當中特地新增加一個 source 叫做 tail-dir source,專門用于解決斷點續傳的問題,tail-dir source可以監控檔案或者檔案夾,允許我們使用正則運算式的方式來對我們的檔案或者檔案夾進行監聽,
1. 需求分析
- 采集需求,使用tail-dir source監聽某個目錄下的多個檔案,并且實作檔案的斷點續傳功能
2. 開發組態檔
vim conf/tail-dir.conf,內容如下:
# 1. Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2. Describe/configure the source
a1.sources.r1.type = TAILDIR
# 以json格式,記錄讀取的每個檔案及讀取的position
a1.sources.r1.positionFile = /bigdata/install/apache-flume-1.9.0-bin/taildir_position.json
# 每個filegroup代表一系列待tail的檔案
a1.sources.r1.filegroups = f1
# 指定filegroup的絕對路徑
a1.sources.r1.filegroups.f1 = /bigdata/install/flumedatas/dirfile/.*log.*
# 此項用于控制從一個檔案連續讀取資料的批次;比如有A、B、C多個檔案,如果向A檔案寫入的頻率非常高,導致一直回圈的從A中采集獲取資料,而B、C的資料不被處理;可將此值調低;每個批次由屬性batchSize控制,默認500行
a1.sources.r1.maxBatchCount = 1000
# 3. Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://node01:8020/taildir/files/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 5000
a1.sinks.k1.hdfs.rollCount = 50000
# 每x個event flush到hdfs
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的檔案型別,默認是Sequencefile,可用DataStream,則為普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# 4. Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 5.Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 對應型別組件的官網檔案
- tail dir
3. 啟動&測驗
bin/flume-ng agent -c conf -f conf/tail-dir.conf -n a1 -Dflume.root.logger=INFO,console
- node03 執行以下命令創建檔案到指定檔案夾下
echo "Hello World" >> /bigdata/install/flumedatas/dirfile/file.log
echo "How are you" >> /bigdata/install/flumedatas/dirfile/file1.log
echo "How old are you" >> /bigdata/install/flumedatas/dirfile/file2.log
- 可觀察下
taildir_position.json檔案中記錄的內容
$ cat /bigdata/install/apache-flume-1.9.0-bin/taildir_position.json
[{"inode":50817895,"pos":12,"file":"/bigdata/install/flumedatas/dirfile/file.log"},{"inode":50817897,"pos":12,"file":"/bigdata/install/flumedatas/dirfile/file1.log"},{"inode":50817898,"pos":16,"file":"/bigdata/install/flumedatas/dirfile/file2.log"}]
兩個 agent 級聯
1. 需求分析
- 第一個agent負責收集檔案當中的資料,通過網路發送到第二個agent當中去;
- 第二個agent負責接收第一個agent發送的資料,并將資料保存到hdfs上面去,
2. node02安裝flume
- 將node03機器上面解壓后的flume檔案夾拷貝到node02機器上面去
scp -r apache-flume-1.9.0-bin/ node02:$PWD
3. 開發組態檔
- node02 上開發 flume 組態檔:
vim conf/tail-avro-logger.conf,內容如下
# 1. Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2. Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /bigdata/install/flumedatas/taillogs/access_log
a1.sources.r1.channels = c1
# 3. Describe the sink
# sink端的avro是一個資料發送者
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 4141
# 每一批次發送的event的數目
a1.sinks.k1.batch-size = 10
# 4. Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 5. Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 對應型別組件的官網檔案
- avro sink
- node02 上開發 flume 組態檔:
vim conf/avro-hdfs.conf,內容如下
# 1. Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2. Describe/configure the source
# source中的avro組件是一個接收者服務
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node03
a1.sources.r1.port = 4141
# 3. Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/avro/hdfs/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 200
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 生成的檔案型別,默認是Sequencefile,可用DataStream,則為普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# 4. Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 5. Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 對應型別組件的官網檔案
- avro source
4. 啟動&測驗
- 啟動順序:先啟動下游agent,目前資料是從 node02 上的 agent 發往 node03 上的 agent,所以先啟動 node03 的 agent
# node03
bin/flume-ng agent -c conf -f conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
# node02
bin/flume-ng agent -c conf -f conf/tail-avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
- 將node03下面的腳本和資料拷貝到node02即可,node03機器上執行以下命令
# node03
$ pwd
/bigdata/install/flumedatas/taillog
$ scp -r tail-file.sh node02:$PWD
# node02
./tail-file.sh
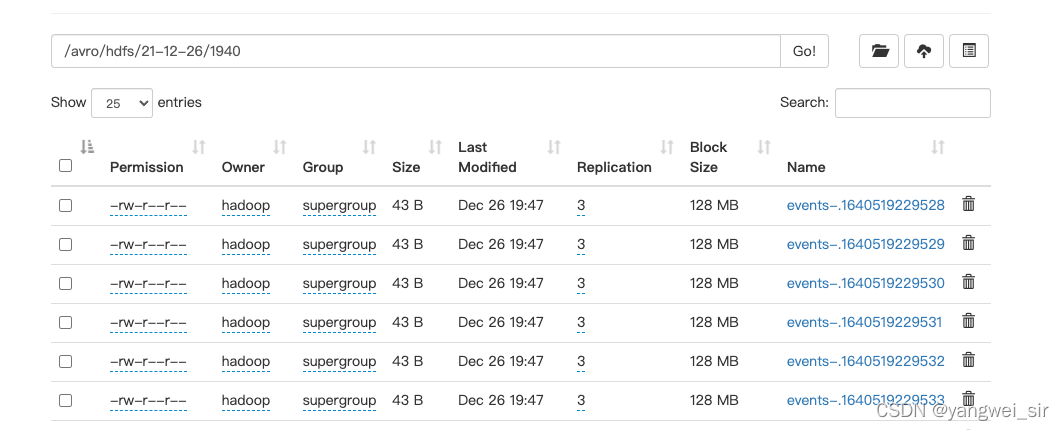
- 查看HDFS目錄
/avro/hdfs
更多source和sink組件
- Flume支持眾多的source和sink型別,詳細手冊可參考官方檔案
Flume進階
高可用Flume-NG配置案例
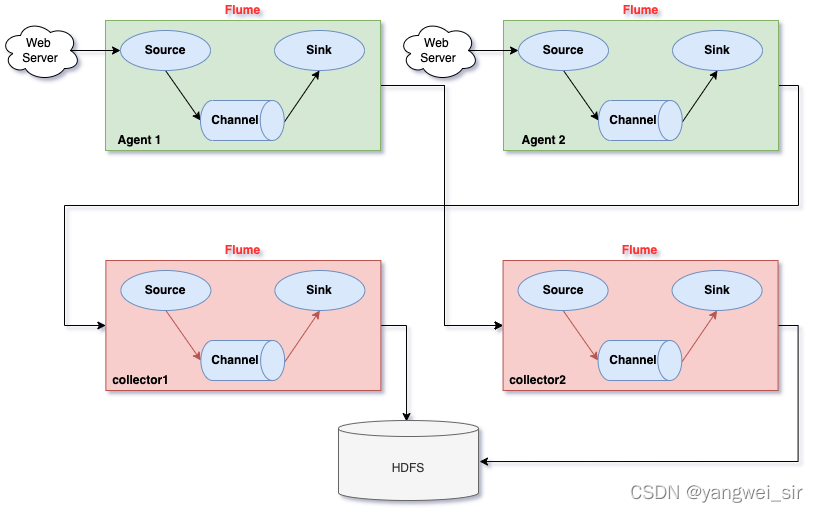
- 高可用的Flume NG集群,架構圖如下:
1. 角色分配
| 名稱 | HOST | 角色 |
|---|---|---|
| Agent1 | node01 | Web Server |
| Collector1 | node02 | AgentMstr1 |
| Collector2 | node03 | AgentMstr2 |
- 圖中所示,Agent1資料分別流入到Collector1和Collector2,Flume NG本身提供了Failover機制,可以自動切換和恢復,在上圖中,有3個產生日志服務器分布在不同的機房,要把所有的日志都收集到一個集群中存盤,
2. 集群搭建
- 前面我們已經在 node02、node03 安裝好了 flume,接下來將在 node01 上也安裝上 flume
# node01
mkdir -p /bigdata/install/flumedatas/taillogs
# node03
cd /bigdata/install
scp -r apache-flume-1.9.0-bin/ node01:$PWD
$ pwd
/bigdata/install/flumedatas/taillogs
$ scp -r tail-file.sh node01:$PWD
- 開發 node01 機器的 agent 組態檔:
vim conf agent.conf,內容如下
# agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
## set gruop
agent1.sinkgroups = g1
## set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
# 配置source
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /bigdata/install/flumedatas/taillogs/access_log
# interceptor 攔截器;與source結合,對event進行修改或丟棄
agent1.sources.r1.interceptors = i1 i2
# 靜態攔截器在所有的event的header中,增加一個kv對,key是下邊屬性key對應的值,value是屬性value對應的值
agent1.sources.r1.interceptors.i1.type = static
# 被創建的header的名字
agent1.sources.r1.interceptors.i1.key = Type
# 靜態的值;key與value對應
agent1.sources.r1.interceptors.i1.value = LOGIN
# timestamp攔截器對event的header中增加kv對,key是timestamp,value是對應的時間戳的值
agent1.sources.r1.interceptors.i2.type = timestamp
## set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node02
agent1.sinks.k1.port = 52020
## set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = node03
agent1.sinks.k2.port = 52020
## set sink group
agent1.sinkgroups.g1.sinks = k1 k2
## sink processor處理器;可用于sink的負載均衡或故障轉移
agent1.sinkgroups.g1.processor.type = failover
# priority值高的sink,擁有較高的權限;并且必須是唯一不重復的
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
# maxpenalty 對于故障的節點最大的黑名單時間 (in millis 毫秒)
agent1.sinkgroups.g1.processor.maxpenalty = 10000
- 對應型別組件的官網檔案
- static interceptor靜態攔截器
- timestamp攔截器
- sink processor處理器
3. 配置flume collection
- node02、node03 機器修改組態檔
vim conf/collector.conf,內容相同
# set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
## set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
## set source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 52020
a1.sources.r1.channels = c1
# 攔截器
a1.sources.r1.interceptors = i1
#a1.sources.r1.interceptors.i1.type = static
#a1.sources.r1.interceptors.i1.key = Collector
#a1.sources.r1.interceptors.i1.value = node02
# 在header中添加的kv對的key默認是host
a1.sources.r1.interceptors.i1.type = host
a1.sources.r1.interceptors.i1.hostHeader=hostname
## set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://node01:8020/flume/failover/%{hostname}
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
4. 啟動&測驗
- 順序啟動
# node03
bin/flume-ng agent -n a1 -c conf -f conf/collector.conf -Dflume.root.logger=DEBUG,console
# node02
bin/flume-ng agent -n a1 -c conf -f conf/collector.conf -Dflume.root.logger=DEBUG,console
# node01
bin/flume-ng agent -n agent1 -c conf -f conf/agent.conf -Dflume.root.logger=DEBUG,console
- node01 啟動檔案產生腳本
$ pwd
/bigdata/install/flumedatas/taillogs
$ ./tail-file.sh
- 然后去hdfs查看生成檔案
- 將node02的agent停掉,自動切換到node03上的agent
- 再將node02的agent啟動,由于node02的優先級高,自動切換回node02上的agent
- 下面我們來測驗下Flume NG集群的高可用(故障轉移),場景如下:
- 我們在Agent1節點上傳檔案,由于我們配置Collector1的權重比Collector2大,所以 Collector1優先采集并上傳到存盤系統,然后我們kill掉Collector1,此時有Collector2負責日志的采集上傳作業,之后,我 們手動恢復Collector1節點的Flume服務,再次在Agent1上傳檔案,發現Collector1恢復優先級別的采集作業,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395076.html
標籤:其他
上一篇:PageRank演算法的MapReduce實作(輸入有向圖,迭代收斂)
下一篇:五十七、centos創建hadoop用戶(修改hadoop用戶密碼,目錄賦予hadoop用戶權限等......)