文章目錄
- 前言
- 一、從DFT到DCT
- 二、從CTFT到STFT
- 三、K-L變換與降維思想
- 四、K-L變換實體:人臉識別(含代碼和詳細注釋)
- 五、參考資料
前言
??之前學信號和DSP的時候,除了常見的離散傅里葉變換之外,還看過諸如離散余弦變換(DCT),短時傅里葉變換(STFT),小波變換等等,這些變換看似繁多且雜亂無章,但其實其背后的思想都是變換域的思想,引入某種變換,通常是正交變換,將時間相關的信號序列變換到另一個域上來進行分析,其實我覺得理解了這個思想之后,不需要太關注公式的推導,大致了解思想簡單推導一下即可,畢竟有很多的包和函式都是集成化的,特此在這里做一個思路和代碼的總結,由于小波變換相對沒有那么常用,此處總結DCT,STFT和K-L變換,
一、從DFT到DCT
??DCT全名為離散余弦變換,當然與之相對應的有離散正弦變換,事實上,DCT變換族中有16個成員,包括8種DST和8種DCT,具體對其進行劃分的方式則是根據原始序列做對稱的方式的不同來進行劃分,例如:對稱點兩側的序列是對稱還是反對稱,是軸對稱還是中心對稱,對稱點是在離散序列的采樣點上還是不在……總之,不同的對稱形式決定了不同的DCT形式,這個公式具體的推導可以去參考一下比較經典的數字信號處理的教材,其公式推導的核心思想也就是運用了DFT中旋轉因子的對稱性,但是在本篇博客中主要關注的還是對思想的理解,以及結果代碼的實作,
??我們先來回顧一下經典的DFT公式的表達形式,其中:
W
N
k
n
=
e
?
j
2
π
N
k
n
W_N^{kn}=e^{-j\frac{2π}{N}kn}
WNkn?=e?jN2π?kn
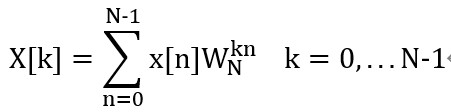
??其對應的展開形式如下:
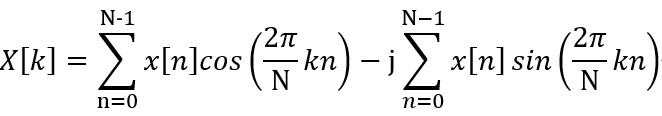
??而在各種DCT和DST中,最常見的是2型DCT,因為其具有較好的能量壓縮性質,因此接下來主要討論2型的DCT,其公式如下:
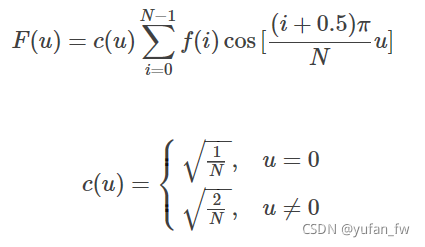
??這也屬于一種正交變換,其本質原因是因為DCT的正交基還是沒有脫離三角函式系,其采用的是余弦正交基,而余弦,正弦和復指數基本身就具有正交性,
??我們可以比較一下DCT和DFT的展開形式,很容易發現:DCT中全為實數,沒有復數,且只有余弦項,這降低了數值計算的復雜度,仔細分析就會發現,其實DCT中之所以只有實數,恰恰是因為利用了離散序列的對稱性,類似于
e
j
w
n
+
e
?
j
w
n
e^{jwn}+e^{-jwn}
ejwn+e?jwn的形式得到的就是實數序列,
// 一維DCT函式代碼如下,輸入一個向量,得到一個向量,因此就不專門寫主函式了
function output = dct(input)
%The One-dimensional DCT,input is a vector
N = length(input);
for i = 0:N-1
if i==0
a = sqrt(1/N);
else
a = sqrt(2/N);
end
sum = 0;
for j = 0:N-1
sum = sum+input(j+1)*cos(pi*(j+0.5)*i/N);
end
output(i+1) = a * sum;
end
end
??仿真結果部分,這里參考了一位同學匯報的PPT,下圖是原信號的時域離散波形:
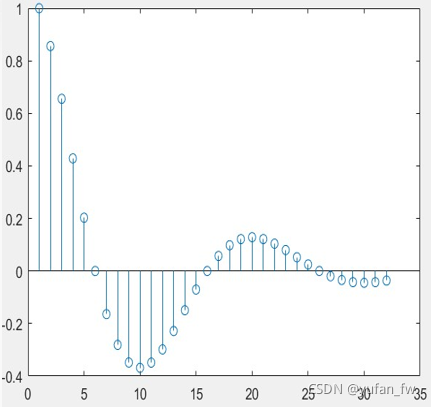
??而下圖則為該信號進行了DFT和DCT之后的結果:
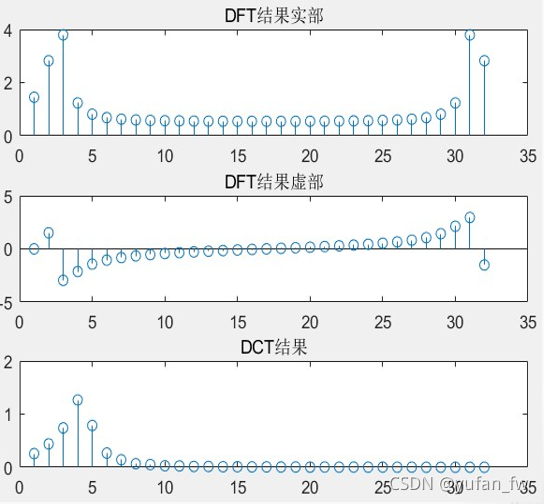
??我們可以看到,有限長序列的2型DCT的系數通常比使用DFT得到對應的系數,更多集中在較低序號(對應較低頻率)的部分(這個個人覺得可以從另一個角度去理解,做FFT時,高頻部分一定會存在有低頻部分的鏡像分量,如上圖“DFT實部和虛部“”的結果所示,但DCT可以避免這個問題),且我們發現在一般情況下,往往剩余部分的系數趨近于0,如上圖的“DCT結果”部分所示,因此,說明DCT往往比DFT具有更好的能量壓縮性質,因此,二維的DCT往往用于影像的壓縮,例如我們熟悉的 影像JPEG標準,
??接下來,我們從一維DCT過度到二維DCT,二維DCT的公式如下:
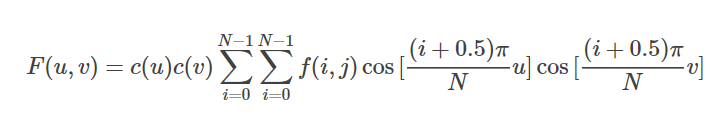
??類比一維DCT,將上式寫成矩陣形式,其中
c
(
i
)
c(i)
c(i)的取值同一維情況:
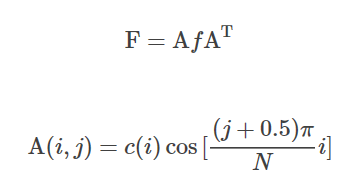
??同樣給出二維DCT的函式:
function output= dct2(input)
% Two-Dimensional DCT,input is a matrix
[height,width] = size(input);
if height==width %滿足方陣的條件
N = height;
A = zeros(N);
for i=0:N-1
if i==0
c = sqrt(1/N);
else
c = sqrt(2/N);
end
for j=0:N-1
A(i+1,j+1) = c*cos(pi*(j+0.5)*i/N);
end
end
output= A*input*A';
else
disp('Error:input must be a square matrix !');
output=0;
end
二、從CTFT到STFT
??我們熟悉的傅里葉變換只能反映出信號在頻域的特性,無法在時域內對信號進行分析,為了將時域和頻域相聯系,短時傅里葉變換(short-time Fourier transform,簡稱為STFT)便應運而生,其實質是加窗的傅里葉變換,可以去看看參考資料中一篇關于STFT的博客(鏈接在最后),
?? 我拜讀之后,簡單做了總結,并加了一些理解和補充說明,信號x(t)的短時傅里葉變換定義如下,對比普通的連續傅里葉變換(CTFT),STFT在做傅里葉變換之前對
x
(
τ
)
x(\tau)
x(τ)先進行加窗,其窗函式的為有限長的
h
(
τ
)
h(\tau)
h(τ),當
h
(
τ
)
h(\tau)
h(τ)變為
h
(
τ
?
t
)
h(\tau-t)
h(τ?t)時,即相當于對窗函式進行了平移,即可以形象的認為是取出信號在分析時間點 t 附近的一個切片:
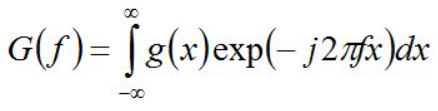
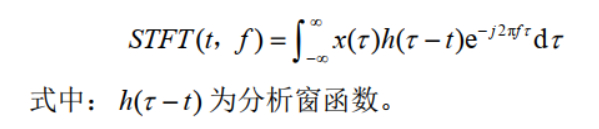
?? 但是,以上的公式針對的都是連續信號,得到的
f
f
f在頻域的取值也是無窮多個,然而在MATLAB仿真的程序中,只能進行數字信號處理,先給出代碼,再進行說明,代碼如下:
clc,clear;
%% 產生信號
fs = 1000; % 采樣頻率1KHz
N=1024;%對應傅里葉變換的點數
t = 0:1/fs:(N-1)/fs;
f1=20;
f2=60;
f3=150;
x=3*cos(2*pi*f1*t)+2*cos(2*pi*f2*t)+5*cos(2*pi*f3*t);%三個正弦信號的疊加
%% 短時傅里葉變換
window_length=500;%設定視窗長度,視窗越長時間解析度越差,
step=1;%每次平移的步長,最小為1,步長越小時間精度越好,
h=hamming(window_length);%設定海明窗的窗長
%wlen-hop代表每次重疊的部分的點數
%F代表頻率向量,F的取值為N/2+1;T代表時間向量,step為1時,T的取值為N-wlen+1
[B, F, T, P] = spectrogram(x,h,window_length-step,N,fs); % B是F行T列的頻率峰值,P是對應的能量譜密度
figure;
imagesc(T,F,P);%畫圖函式
set(gca,'YDir','normal')%讓Y軸刻度順序設定為正常
colorbar;
xlabel('時間 t/s');
ylabel('頻率 f/Hz');
title('短時傅里葉時頻圖');
??接下來分析以上代碼,呼叫這個函式之后,回傳的向量F代表頻率軸,而回傳的向量T代表時間軸,而矩陣P則代表了相應的幅度(功率值),P的
s
i
z
e
size
size由向量F和T決定,那么F和T的
s
i
z
e
size
size又是多少呢?我們先看T,由于系統需要滿足因果性,我們假定時刻t從0開始,那么一開始窗函式的區間就是從
0
0
0-window_length,假設step為1,即每次向右平移1個,那些就有
N
?
w
l
e
n
+
1
N-wlen+1
N?wlen+1個時間,再看F,如剛才所說,F的區間是連續的,如何將其離散化,那么需要確定頻率解析度以及頻率的分布區間,首先根據奈奎斯特采樣定理,采樣率
f
s
fs
fs一定的時候,如果我們不想使其發生混疊,信號的頻率不會超過
0.5
f
s
0.5fs
0.5fs,因此這即為我們考慮的區間上限(下限為0),同時頻率解析度為
f
s
N
\frac{fs}{N}
Nfs?,即采樣率和變換點數一定的時候,頻率解析度就已經確定了,因此,F的size即為
N
2
+
1
\frac{N}{2}+1
2N?+1,對應
N
2
\frac{N}{2}
2N?個間隔,(也可以這么理解,N點序列作傅里葉變換后得到N點序列,而后面的N/2個點就是前面N/2個點的鏡像分量,沒有必要考慮)
三、K-L變換與降維思想
??在machine learning中,我們經常需要防止資料的維度過高,而這就需要用到降維的思想,常見的降維有:直接降維,線性降維和非線性降維,而線性降維中常見的方法則是PCA(主成分分析,也稱為K-L變換,以下統稱用PCA),
??PCA的核心思想即為將一組線性相關的變數,通過正交變換,變換成一組線性無關的變數,從信號空間理論的角度可以理解為對原始特征空間的重構,在PCA中,有最大投影方差和最小重構距離兩種主流思路,最終可推匯出相同的結果,事實上,也可以從概率的角度對PCA進行展開,限于篇幅,只給出最終結論,具體請參考AI圣經:PRML,
??對于一組資料集{
x
n
x_n
xn?},其中的每個
x
n
x_n
xn?都在一個
D
D
D維空間中,即研究如何將資料投影到
M
<
D
M<D
M<D的
M
M
M維空間中,具體方法如下:定義
x
n
x_n
xn?為樣本集合的均值,即
x
ˉ
=
∑
n
=
1
N
x
n
\bar{x}=\sum_{n=1}^Nx_n
xˉ=∑n=1N?xn?,而定義資料的協方差矩陣(covariance matrix):
S
=
1
N
?
∑
n
=
1
N
(
x
n
?
x
ˉ
)
(
x
n
?
x
ˉ
)
T
S=\frac{1}{N} \cdot \sum_{n=1}^N (x_n-\bar{x})(x_n-\bar{x})^T
S=N1??∑n=1N?(xn??xˉ)(xn??xˉ)T.對矩陣
S
S
S進行特征值分解,對于降維到
M
M
M維空間的情況,則選出
M
M
M個最大的特征值對應的特征向量,即可得到新的
M
M
M維空間中的一組基,
??以上就是PCA的理論部分,但是當涉及到具體實作的時候,我們就會發現,往往原有的空間維數
D
D
D是遠遠高于樣本數量
N
N
N的,就拿我們最常見的影像為例,可能一個影像有100萬個像素點,但是樣本個數只有大概100個,這樣的話,如果直接運行PCA就變的行不通了,因為會遇到
D
?
D
D \cdot D
D?D 超大矩陣求逆的世界難題,同時,我們會發現這樣得到的特征值至少有
D
?
N
+
1
D-N+1
D?N+1個為0,因為N個資料點的線性子空間的維數最多為
N
?
1
N-1
N?1,因此,我們需要采樣如下的方法,具體推導可以參考PRML的高維PCA部分,這里給出最終結論:
??1.定義
X
X
X為
D
?
N
D\cdot N
D?N維中心資料矩陣,它的第
n
n
n列即為
(
x
n
?
x
ˉ
)
(x_n-\bar{x})
(xn??xˉ),
?? 2.求解
S
1
=
X
T
?
X
S_1=X^T \cdot X
S1?=XT?X,此時
S
1
S1
S1的維度為
N
?
N
N \cdot N
N?N,對其進行奇異值分解,得到特征值
λ
i
\lambda_{i}
λi?的集合和特征向量
v
i
v_{i}
vi?的集合,每一個
v
i
v_{i}
vi?都為
N
N
N維向量,
?? 3.
u
i
=
1
λ
i
?
X
?
v
i
,
i
=
0
,
1
,
2
,
?
?
,
p
u_i=\frac{1}{\sqrt{\lambda_{i}}}\cdot X \cdot v_{i}, i=0,1,2, \cdots, p
ui?=λi?
?1??X?vi?,i=0,1,2,?,p,此時每一個
u
i
u_{i}
ui?都為
D
D
D維向量,即為
p
p
p個
D
D
D維向量構成了高維空間的線性子空間的一組基,
??K-L變換的具體應用請看下一節的人臉識別實體,
四、K-L變換實體:人臉識別(含代碼和詳細注釋)
%% 兩組影像資料的讀取
clear,clc;
train_files = dir('F1');%回傳目錄中的檔案()
all_train = [];%樣本矩陣
first_number=3;
last_number=102;
image_number = last_number-first_number+1;%圖片總共的數目
for i = first_number : last_number
train_file_name = train_files(i).name;%讀圖片名
train_file_name=strcat('F1','\',train_file_name);%字符拼接函式
sample_figure= imread(train_file_name);%從指定的檔案讀取一幅影像
[row,col]=size(sample_figure);
pixel_number=row*col;%圖片像素點數目
temp=reshape(sample_figure,pixel_number,1);%回傳一個m*1的矩陣temp,將二維影像資料變成一維列向量
all_train=[all_train,temp];%將所有圖片資料變成一個樣本矩陣,一個列向量對應一個高維空間
end
test_files = dir('F2');%回傳目錄中的檔案()
all_test = [];%測驗矩陣
for i = first_number : last_number
test_file_name = test_files(i).name;
test_file_name=strcat('F2','\',test_file_name);
test = imread(test_file_name);
[row,col]=size(test);
test_temp=reshape(test,row*col,1);%回傳一個m*1的矩陣temp,將二維影像資料變成一維列向量
all_test=[all_test,test_temp];%將所有圖片資料變成一個樣本矩陣
end
%% 主成分分析(PCA)
average_train= mean(all_train,2); %回傳行的平均值,即100個圖片的平均值
%計算每個影像與均值的差
for i=1:image_number
A(:,i)=double(all_train(:,i))-average_train;%需要先將allsample轉化為雙精度(double)型別
end
%計算協方差矩陣的特征矢量和特征值
L =(A'*A); %由SVD理論構造矩陣L=A'*A用于計算特征值和特征向量
%本來是A*A',由于復雜度過高,提出改進演算法
[V,D] = eig(L);%計算矩陣A的特征值D和特征向量矩陣V,特征向量得到的是歸一化特征向量
d1=diag(D);%會自動按升序排序
% 按特征值大小以降序排列
d_sort = flipud(d1);%實作上下翻轉
v_sort = fliplr(V);%實作左右翻轉,實作特征值和特征向量矩陣的對應
%以下選擇80%的能量
d_sum = sum(d_sort);%將陣列中元素進行求和
d_sum_temp = 0;
main_number = 0;%特征值主分量個數
while( d_sum_temp/d_sum < 0.8)
main_number = main_number + 1;
d_sum_temp = sum(d_sort(1:main_number));
end
%計算新空間中的基
for i=1:main_number
U(:,i)=(d_sort(i)^(-1/2))*A*v_sort(:,i); %PRML公式12.30,此處沒有N是因為之前SVD的時候沒有帶N
end
%U即為新空間中的一組基,每一個列向量代表一個基,main_number個基張成高維空間的線性子空間
%% 對測驗集中的人臉進行識別
for i=1:image_number
test_A(:,i)=double(all_test(:,i))-average_train;%此處應該是減去average_train,因為需要相同的映射規則
end
%計算訓練集中人臉在特征空間中的投影表示,每一列代表一個圖片在新空間中的坐標
train_projection=U'*A; %可理解為做內積
%計算測驗集中人臉在特征空間中的投影表示,每一列代表一個圖片在新空間中的坐標
test_projection=U'*test_A;
%測驗集中人臉和訓練集中人臉相似性進行匹配
projection_match=zeros(main_number,image_number);
success_number=0;%sum1為匹配成功的數目
position=zeros(image_number,1);
temp_vector=zeros(main_number,image_number);
diffrence_vector=zeros(image_number,1);%用于存盤一個特定的測驗資料坐標和之前每一個訓練資料坐標的距離
for i=1:image_number %測驗集中的第i個圖片資料
for j=1:image_number
temp_vector(:,j)=test_projection(:,i)-train_projection(:,j);
diffrence_vector(j)=norm(temp_vector(:,j), 2);
end
[~,position(i)]=min(diffrence_vector);%找到最小距離對應訓練集中的位置,存在position(i)中
if(i==position(i))
success_number=success_number+1;
end
end
accuracy_rate=(success_number/image_number);
display(accuracy_rate);%輸出準確率
%% 隨機抽取5個圖形做代表顯示匹配效果
%兩組圖片的相同編號,對應同一個人兩張不同的圖
for i=1:5
ri=(round(100*rand(1,1)));
figure(i);
subplot(121);
r=all_train(:,ri);
imshow(reshape(r,142,120));
title(train_files(ri).name,'FontWeight','bold','Fontsize',15,'color','red');
subplot(122);
k=position(ri);
imshow(reshape(all_test(:,k),142,120));
title(test_files(k).name,'FontWeight','bold','Fontsize',15,'color','red');
end
五、參考資料
1.二維DCT變換
2.STFT.
3.PCA做人臉識別.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395263.html
標籤:其他
上一篇:C#實作回合制游戲模擬