首先放原文鏈接https://arxiv.org/pdf/1512.03385.pdf![]() https://arxiv.org/pdf/1512.03385.pdf
https://arxiv.org/pdf/1512.03385.pdf
Abstract
| Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8× deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions1 , where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation. | 越深的神經網路訓練起來越困難,為此,我們提出了一個殘差學習架構,去減輕網路訓練的壓力(這里的網路指相較于以往使用的網路都要深的網路),具體地,我們將層重新表示為引入層輸入的學習殘差的函式,而不是學習無參考的函式,(這里一開始看不懂,但通讀完文章后會發現表達的很清晰,)我們提供了全面的實驗證據,表明這些殘差網路更容易優化,并且可以從增加了相當多的深度下得到精確性,在ImageNet資料集上,我們評估了一個深達152層的殘差網路——相較于VGG深了8倍,但仍然有著比它低的計算復雜度,(接下來都是實驗結果......)這些殘差網路的集合在 ImageNet 測驗集上實作了3.57%的錯誤率, 該結果在ILSVRC 2015分類任務中獲得第一名,我們還對具有100層和1000層的CIFAR-10進行了分析,表示的深度對于許多視覺識別任務至關重要,只是由于我們極深的表示,我們在 COCO 物件檢測資料集上獲得了28%的相對改進,深度殘差網路是我們向ILSVRC & COCO 2015比賽提交的基礎,我們還在ImageNet檢測、ImageNet定位、COCO檢測和 COCO分割任務中獲得了第一名, |
第一句話就提出問題,然后介紹我們做了什么作業去解決這個問題,它如何可以解決這個問題,通過實效果(絕對精度+相對精度)證明我們的貢獻,
1 Introduction
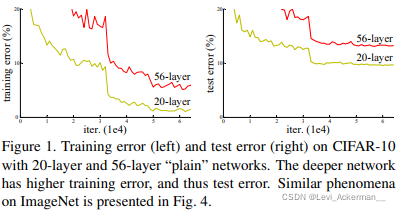
| Deep convolutional neural networks [22, 21] have led to a series of breakthroughs for image classification [21, 50, 40]. Deep networks naturally integrate low/mid/highlevel features [50] and classifiers in an end-to-end multilayer fashion, and the “levels” of features can be enriched by the number of stacked layers (depth). Recent evidence [41, 44] reveals that network depth is of crucial importance, and the leading results [41, 44, 13, 16] on the challenging ImageNet dataset [36] all exploit “very deep” [41] models, with a depth of sixteen [41] to thirty [16]. Many other nontrivial visual recognition tasks [8, 12, 7, 32, 27] have also greatly benefited from very deep models. Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22]. When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in [11, 42] and thoroughly verified by our experiments. Fig. 1 shows a typical example. The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution (or unable to do so in feasible time). | 深度卷積神經網路陳述句引領了影像分類任務中的許多突破,深的網路可以自然地融合低/中/高層次的特征以及端到端多層的分類器,并且,特征的層次可以通過堆疊層的數量(深度)去豐富,最近有證據揭示,網路深度十分重要,并且,在困難的ImageNet資料集上領先的結果都利用了“非常深”的網路,如16層到30層,(這里給非常深打引號我覺得非常有意思,更顯示出了作者的152層真是對于網路深度很大的突破,)許多其他的重要的視覺感知任務已經從非常深的模型中受益很多了,
收深度的重要性的驅動,一個問題產生了:學習更好的網路和堆疊更多的層一樣簡單嗎?回答這個問題的阻礙是臭名昭著的梯度消失和梯度爆炸問題,這從一開始就阻礙了模型的收斂,但是這個問題已經很大程度上被標準化初始化和中間歸一化層解決了,它們使數十層的網路能夠使用SGD通過BP演算法達到收斂,
當更深的網路能夠收斂時,又出現了一個衰退問題:隨著網路深度的增加,精度達到飽和后迅速下降,出乎意料的是,根據文獻的報道以及我們充分的實驗證明,這樣的衰退不是由過擬合導致的,向適當深度的模型添加更多層會導致更高的訓練錯誤,Figure 1中給出了一種典型的例子,
訓練準確度的衰退表明不是所有系統都同樣易于優化, 讓我們考慮一下一個較淺的架構以及在它上面加更多層的更深對應部分,有一個解決上述問題的方案:添加層是恒等映射,其他層都復制淺層模型中的學習結果,這種解決方案的存在表明,更深的模型不應產生比其淺層對應模型更高的訓練誤差,但實驗表明,我們現有的求解器無法找到與上述解決方案相當或更好的解決方案,或者說是無法在可行的時間內找到, |
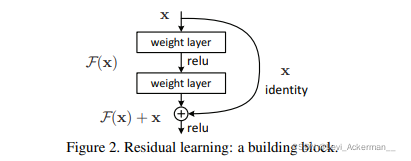
| In this paper, we address the degradation problem by introducing a deep residual learning framework. Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of F(x) := H(x)?x. The original mapping is recast into F(x)+x. We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers. The formulation of F(x) +x can be realized by feedforward neural networks with “shortcut connections” (Fig. 2). Shortcut connections [2, 34, 49] are those skipping one or more layers. In our case, the shortcut connections simply perform identity mapping, and their outputs are added to the outputs of the stacked layers (Fig. 2). Identity shortcut connections add neither extra parameter nor computational complexity. The entire network can still be trained end-to-end by SGD with backpropagation, and can be easily implemented using common libraries (e.g., Caffe [19]) without modifying the solvers. We present comprehensive experiments on ImageNet [36] to show the degradation problem and evaluate our method. We show that: 1) Our extremely deep residual nets are easy to optimize, but the counterpart “plain” nets (that simply stack layers) exhibit higher training error when the depth increases; 2) Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks. Similar phenomena are also shown on the CIFAR-10 set [20], suggesting that the optimization difficulties and the effects of our method are not just akin to a particular dataset. We present successfully trained models on this dataset with over 100 layers, and explore models with over 1000 layers. On the ImageNet classification dataset [36], we obtain excellent results by extremely deep residual nets. Our 152- layer residual net is the deepest network ever presented on ImageNet, while still having lower complexity than VGG nets [41]. Our ensemble has 3.57% top-5 error on the ImageNet test set, and won the 1st place in the ILSVRC 2015 classification competition. The extremely deep representations also have excellent generalization performance on other recognition tasks, and lead us to further win the 1st places on: ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation in ILSVRC & COCO 2015 competitions. This strong evidence shows that the residual learning principle is generic, and we expect that it is applicable in other vision and non-vision problems. | 本文中,我們通過引入一個深度殘差學習框架解決了該退化問題,我們讓堆疊層去你和一個殘差映射,而不是讓他直接去擬合需要的底層映射(就是最終我們需要的映射),我們將需要的底層映射表示為H(x),讓堆疊的非線性層去擬合F(x):=H(x)-x的映射,原始的底層映射H(x)即被表示為F(x)+x,我們假定相較于優化原始底層映射,優化殘差映射會更加簡單,極端一點來說,如果一個恒等映射是最優的,對于堆疊的非線性層來說,相較于擬合一個恒等映射,將殘差向零推進會更加的簡單,F(x)+x這個公式可以被帶有shortcut connection(殘差/跳躍/捷徑鏈接)的前驅神經網路實作,shortcut connection,也就是跳躍了一層或多層的連接,在我們的案例中,殘差連接只是使用了一個恒等映射,殘差連接的輸出被加入到堆疊層的輸出當中,恒等的殘差鏈接既不會增加引數的個數,也不會提高模型的演算法復雜度(因為它只是一個加法而已),整個網路可以被使用SGD的端到端的BP演算法訓練出來,并且可以使用通用庫輕松實作,無需修改求解器,
我們在 ImageNet上進行了全面的實驗,展示了衰退問題并評估了我們的方法,我們展示出:1)我們極深的殘差網路很容易優化,當深度增加時,對應的“普通”網路(簡單的無殘差連接的堆疊層)表現出了更高的訓練誤差;2)我們的深度殘差網路可以很容易地隨著網路深度的大幅度增加,獲得準確度的提升,產生的結果比以前的網路要好得多, 同樣的現象在CIFAR-10的資料集上也體現了出來,這表明,深層網路優化的困難和我們方法的效果不是僅僅局限于一個特定的資料集,我們在這個資料集上展現出了超過100層的成功訓練的模型,并探索了超過1000層的模型,
接下里的都是實驗結果......表現出了殘差網路模型的高準確性和很好的泛化能力, |
2 Related Work
| Residual Representations. In image recognition, VLAD [18] is a representation that encodes by the residual vectors with respect to a dictionary, and Fisher Vector [30] can be formulated as a probabilistic version [18] of VLAD. Both of them are powerful shallow representations for image retrieval and classification [4, 48]. For vector quantization, encoding residual vectors [17] is shown to be more effective than encoding original vectors. In low-level vision and computer graphics, for solving Partial Differential Equations (PDEs), the widely used Multigrid method [3] reformulates the system as subproblems at multiple scales, where each subproblem is responsible for the residual solution between a coarser and a finer scale. An alternative to Multigrid is hierarchical basis preconditioning [45, 46], which relies on variables that represent residual vectors between two scales. It has been shown [3, 45, 46] that these solvers converge much faster than standard solvers that are unaware of the residual nature of the solutions. These methods suggest that a good reformulation or preconditioning can simplify the optimization. Shortcut Connections. Practices and theories that lead to shortcut connections [2, 34, 49] have been studied for a long time. An early practice of training multi-layer perceptrons (MLPs) is to add a linear layer connected from the network input to the output [34, 49]. In [44, 24], a few intermediate layers are directly connected to auxiliary classifiers for addressing vanishing/exploding gradients. The papers of [39, 38, 31, 47] propose methods for centering layer responses, gradients, and propagated errors, implemented by shortcut connections. In [44], an “inception” layer is composed of a shortcut branch and a few deeper branches. Concurrent with our work, “highway networks” [42, 43] present shortcut connections with gating functions [15]. These gates are data-dependent and have parameters, in contrast to our identity shortcuts that are parameter-free. When a gated shortcut is “closed” (approaching zero), the layers in highway networks represent non-residual functions. On the contrary, our formulation always learns residual functions; our identity shortcuts are never closed, and all information is always passed through, with additional residual functions to be learned. In addition, high way networks have not demonstrated accuracy gains with extremely increased depth (e.g., over 100 layers). | 殘差表示 在影像識別領域,VLAD是一種由殘差向量相對于字典進行編碼的表示,Fisher Vector可以表示為 VLAD 的概率版本,它們都是面向影像檢索和分類任務的強大的淺層表示, 對于矢量量化,編碼殘差向量被證明比編碼原始矢量更有效,
在低層次視覺和計算機圖形學中,為了求解偏微分方程 PDE,被廣泛使用的多重網格方法Muiltigrid將系統重新表述為多個尺度的子問題,其中每個子問題負責粗粒度尺度和細粒度尺度間的殘差解,Multigrid的一種替代方法是分層基礎預處理,它依賴于兩個尺度間殘差向量的變數,有研究已經表明這些求解器的收斂速度比未利用殘差性質的標準求解器快得多,這些方法表明,好的重構或預處理可以簡化優化程序,
殘差鏈接 關于殘差連接的實踐和理論已經被研究了很長一段時間,一個訓練多層感知器MLP的早期實踐是添加一個連接輸入到輸出的線性層 ,在[44, 24]中,一些中間層被直接連接到輔助分類器來解決梯度消失/爆炸問題, [39, 38, 31, 47]的論文提出了一個通過殘差連接實作的層回應、梯度和傳播誤差的居中方法,在[44]中,一個“原始”層由一個shortcut分支和一些更深的分支組成, 在我們的作業的同時,highway networks展示了帶有門控功能的殘差連接,這些門控函式依賴于資料并且帶來了額外的引數,而與我們的恒等殘差連接與之相反,是無參的,當門控捷徑關閉(接近零)時,highway networks中的層代表為無殘差函式,相反,我們的公式總是在學習殘差函式,我們的恒等殘差連接永遠不會關閉,所有資訊總是連帶著額外的待學習的殘差函式被傳輸,此外,highway networks沒有表現出隨著深度增加的準確性提升(如超過 100 層), |
Multigrid:多重網格法,一種多解析度演算法,原理是通過不同尺度、疏密的網格去消除不同波長的誤差分量,由于直接在高解析度(細粒度尺度)上求解釋,影像低頻不分收斂較慢,與間隔的的平方成反比,所以就在低解析度(粗粒度尺度)上先進行求解,然后再進行插值,提高解析度,在對粗粒度尺度的網格進行修正之前,要先對細粒度尺度的網格進行光華迭代,消除高頻誤差,
3 Deep Residual Learning
3.1 Residual Learning
| Let us consider H(x) as an underlying mapping to be fit by a few stacked layers (not necessarily the entire net), with x denoting the inputs to the first of these layers. If one hypothesizes that multiple nonlinear layers can asymptotically approximate complicated functions2 , then it is equivalent to hypothesize that they can asymptotically approximate the residual functions, i.e., H(x) ? x (assuming that the input and output are of the same dimensions). So rather than expect stacked layers to approximate H(x), we explicitly let these layers approximate a residual function F(x) := H(x) ? x. The original function thus becomes F(x)+x. Although both forms should be able to asymptotically approximate the desired functions (as hypothesized), the ease of learning might be different. This reformulation is motivated by the counterintuitive phenomena about the degradation problem (Fig. 1, left). As we discussed in the introduction, if the added layers can be constructed as identity mappings, a deeper model should have training error no greater than its shallower counterpart. The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers. With the residual learning reformulation, if identity mappings are optimal, the solvers may simply drive the weights of the multiple nonlinear layers toward zero to approach identity mappings. In real cases, it is unlikely that identity mappings are optimal, but our reformulation may help to precondition the problem. If the optimal function is closer to an identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one. We show by experiments (Fig. 7) that the learned residual functions in general have small responses, suggesting that identity mappings provide reasonable preconditioning. | 讓我們把H(x)看作幾個人堆疊層(不一定是整個網路)擬合的底層映射,其中x表示這些層中第一個層的輸入,如果假設多個非線性層可以逐漸逼近復雜函式,那么就等價于假設它們可以逐漸逼近殘差函式,即H(x)?x(假設輸入和輸出的維度相同),因此,與其期望堆疊層逼近H(x),我們讓這些層去逼近殘差函式F(x):=H(x)?x,初始的函式H(x)也就因此變成了F(x)+x,盡管這兩種形式都能夠逐漸逼近我們需要的函式(如假設所述),但學習的難易程度可能是不同的,
這種重構表示的想法的是由上述違反直覺的衰退問題現象所啟發的,正如我們在引入中所討論的,如果添加的層可以構建為恒等映射,那么更深的模型的訓練誤差應該不大于它對應的較淺的模型,衰退問題表明求解器可能難以通過多個非線性層去逼近恒等映射,通過殘差學習的表示重構,如果恒等映射是最優的,求解器可以簡單地將多個非線性層的權重推向零以接近恒等映射,
在實際情況下,恒等映射不可能是最優的,但我們的重構表示可能有助于先決問題,如果最優函式更接近恒等映射而不是零映射,那么求解器就應該更容易參考恒等映射找到擾動項,而不是把待求解函式當作新函式去學習, 我們通過實驗表明,學習到的殘差函式通常具有較小的回應,這表明恒等映射提供了合理的預處理, |
3.2 Identity Mapping by Shortcuts
我們將殘差學習應用到了每一個少量的堆疊層上,模塊構建如Figure 2,通常,我們會將一個模塊表示為:
其中, 分別表示相關模塊的輸入向量和輸出向量,
表示待學習的殘差映射,對應Figure 2的雙層模塊,j即為
,其中,
表示ReLU函式,即
,這里為了簡化符號表示,我們省去了bias偏差項,
的操作我們通過殘差連接和element-wise(逐元素)的加法去實作,我們在執行完連接后使用才第二個激活函式,
殘差連接沒有引入任何額外的引數和計算復雜度,這不僅非常易于實踐,對于我們普通網路和殘差網路的對比也十分重要,(因為保證了兩者引數個數相同,而不是因為引數的增加才得到了更好的效果,)我們公平地比較了這兩種網路的效果,保證了同樣的引數個數、深度、寬度和計算代價(除了可忽略的element-wise加法復雜度),
在我們給出的情況中, 和
的維度必須是相同的,如果是在其他情況下,比如改變輸入輸出通道時,我們可以通過一個線性映射
來將殘差連接匹配為輸出維度,即:
我們也可以在殘差連接中使用線性映射,但我們將會在后面的實驗中證明這一步是多余的,恒等映射對于解決衰退問題來說已經足夠了,并且相對來說省去了很大一部分的計算代價,因此我們只在需要匹配維度時,才使用線性映射,
殘差函式 的表示是靈活的,本文中的殘差函式涉及到了兩到三個層,其實用更多的層也是可以的,但是如果
只有一層,那么他的形式就和普通線性層沒什么區別了,即
,因此我們在實驗中對于這一方式沒有觀察到明顯優勢,
我們也指出,盡管上述符號為了簡便起見表示為了全連接層,但是它們同樣適用于卷積層,函式 可以表示多個卷積層,element-wise addition將在兩個特征圖上逐通道地進行,
3.3 Network Architectures
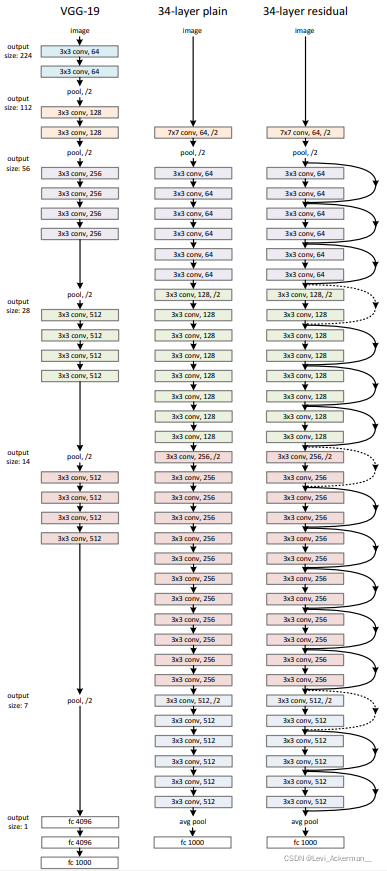
| | 我們測驗了各種普通/殘差網路,觀察到了一致的現象,為了提供討論的實體,我們在下文描述了進行ImageNet任務的兩個模型: 普通網路 我們的普通網路基礎架構主要受 VGG 網路的思想啟發,卷積層大多使用的是 3×3 的過濾器,并遵循兩個簡單的設計規則:(i)對于相同的輸出特征圖大小,層具有相同數量的過濾器; (ii) 如果特征圖大小減半,就通過過濾器數量的加倍來保持每層的時間復雜度,我們直接通過步長為 2 的卷積層進行下采樣,整個網路以全域平均池化層和帶有 softmax的1000類全連接層結束,加權層的總數為 34,
值得注意的是,相比于VGG網路,我們的模型具有更少的過濾器和更低的計算復雜度,我們的34層基礎架構有36億次FLOP(乘加),僅為 VGG-19(196 億次 FLOP)的 18%,
殘差網路 基于上述普通網路,我們添加了殘差連接,將網路轉換為其對應的殘差版本,當輸入和輸出的維度相同時(Figure 3 中的實線殘差連接),可以直接使用恒等映射方式進行殘差連接,當維度增加時(Figure 3 中的虛線殘差連接),我們考慮兩種選擇:(A)殘差連接仍然執行恒等映射,填充額外的零以增加維度,這個選項沒有引入額外的引數; (B) 對恒等映射進行投影用于匹配維度(由 1×1 卷積完成),對于這兩個選項,當殘差連接跨越兩種尺寸的特征圖時,它們將由步長為2的卷積完成尺寸適配, |
3.4 Implementation
我們在針對ImageNet任務的模型的實作遵循[21, 41]中的做法,影像較短的邊在[256, 480]中隨機采樣以進行縮放,從而被調整大小,224×224 的裁剪是從原始影像或者其水平翻轉影像中隨機采樣的,然后減去每個像素的平均值(也就是標準化),使用了[21]中的標準顏色增強方法,我們按照[16]中的方法,在每次卷積之后和激活之前采用層歸一化BN (Batch Normalization),我們按照[13]中的方法初始化權重,并從頭開始訓練所有普通/殘差網路,我們使用 SGD ,每個mini-batch大小為256,學習率從0.1開始,當誤差趨于穩定時除以10,模型最多訓練60×104次迭代(這里一般會說多少個epoch),遵循[16]中的做法,我們使用0.0001的權重衰減和0.9的動量,且不使用dropout,
在測驗中,對于比較研究,我們采用標準的10-crop 測驗,為了獲得最佳結果,我們采用[41, 13]中的完全卷積形式,并取得多個尺度上的平均得分(調整影像大小,使最短邊分別為 {224, 256, 384, 480, 640}),
weight decay:權重衰減(L2正則化),即在代價函式的后面增加一個L2正則項,
即為權重衰減系數,其目的是防止過擬合,
4 Experiments
4.1 ImageNet Classification
我們在包含1000個類別的ImageNet 2012分類資料集上評估我們的方法, 模型在128萬張訓練影像上進行訓練,并在5萬張驗證影像上進行評估,我們還獲得了測驗服務器報告的10萬測驗影像的最終結果,在這里我們將評估top-1和top-5錯誤率,
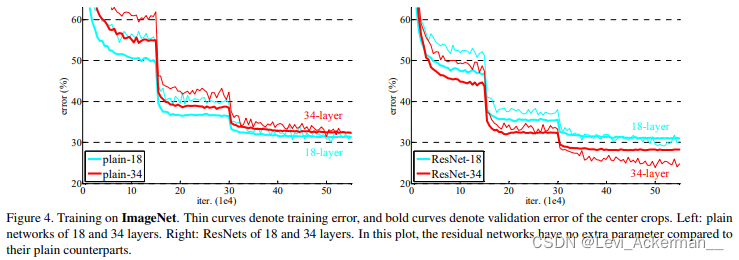
Plain Networks
我們首先評估了18層和34層的普通網路,結果表明,相較于18層更深的34層普通網路反而有更高的驗證誤差,為了揭露這一現象的理由,我們比較了它們訓練程序中的訓練/驗證誤差,我們觀察到了衰退問題——34層的普通網路相較于18層的普通網路,在整個訓練程序中都表現出更高的訓練誤差,盡管18層的普通網路是34層普通網路的一個子集!
我們認為優化的難點不可能在于梯度消失問題,這些普通網路都是由BP演算法訓練的來,這保證了前向傳播的信號具有非零方差,我們也證明了,經過Batch Normalization的反向傳播梯度表現出了健康的規范,所以不管是前向傳播還是反向傳播,信號都不會消失,事實上,34層的普通網仍然能夠達到比較有競爭力的精度,這表明求解器在一定程度上是有效的, 我們推測深度普通網路的收斂速度可能是指數級低的,這會影響訓練誤差的下降,這種優化難點的原因會在后面研究,
Residual Networks
我們評估了18層和34層的殘差網路,除了對于每一對3×3過濾器都加上一個殘差連接之外,它們的基線架構和其對應的普通網路版本是一樣的,在第一個比較中,我們使用恒等映射做所有的殘差連接,并且使用zero-padding去補全維度,所以它們相較于對應的普通網路版本,不會添加額外的引數,
我們將三個主要的觀察結果都放在了圖表中,首先,殘差網路學習的效果使得衰退現象發生了逆轉——34層的殘差網路以2.8%的優勢超過了18層的殘差網路,更重要的是,34層的殘差網路表現出相當低的訓練誤差,并且可以泛化到驗證資料集上,這表明衰退問題這樣的配置下得到了很好的解決,并且我們從增加的深度中獲得了精度的提升,
其次,與普通版本的網路相比,34層的殘差網路通過成功地降低訓練誤差減少了3.5%的top-1誤差,這一對比證明了殘差學習在極深的網路架構體系中的有效性,
最后,我們也發現18層普通/殘差網路在準確度上相當,但18層的殘差網路收斂速度更快,當網路“不太深”(這里是 18 層)的時候,目前的SGD求解器仍然能夠找到面向普通網路的較好的解決方案, 在這種情況下,我們的殘差網路在早期提供更快的收斂,從而使得整個網路優化程序更加輕松,
Identity vs Projection Shortcuts
殘差連接中恒等映射和投影映射的對比,
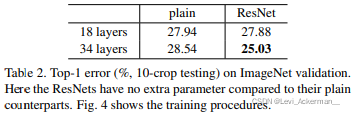
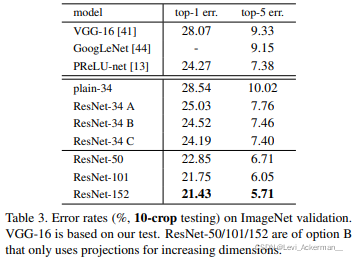
我們已經表明了無參的恒等映射殘差連接有助于訓練,接下來我們將研究投影映射殘差連接,在表 3 中,我們比較了三個選項:(A)使用基于zero-padding的殘差連接增加維度,并且所有的殘差連接都是無參的;(B) 使用投影映射殘差連接增加維度,其余殘差連接則為恒等映射;(C) 所有的殘差連接都是投影映射殘差連接,
Table 3顯示以上所有三個選項都比普通網路的訓練效果好得多,B略好于A,我們認為這是因為A中的zero-padding維度實際上沒有進行殘差學習,C略好于B,我們認為原因在于十三個投影映射殘差連接方式為模型引入了額外的引數,但是A/B/C之間的微小差異表明投影映射殘差連接對于解決我們發現的衰退問題并不是必須的,所以我們在本文的其余部分不使用選項C,以減少模型的大小,從而減少空間復雜度和時間復雜度,恒等映射殘差連接不會增加下面介紹的瓶頸架構復雜性,因而十分重要,
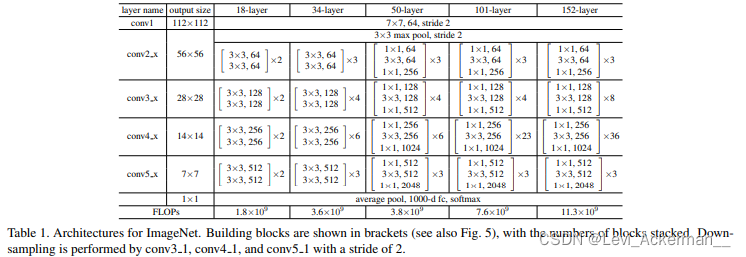
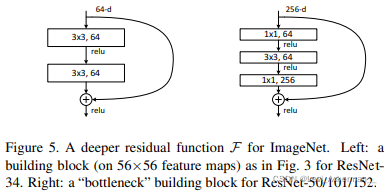
Deeper Bottleneck Architectures
接下來,我們將描述我們針對ImageNet任務設計的更深的網路,為了減少訓練時間,我們將模塊修改為bottlenect瓶頸設計,對于每個殘差函式 ,我們使用3層堆疊而不是2層,這三層分別是1×1、3×3和1×1卷積,其中1×1層負責減少然后增加/恢復維度,使3×3層成為輸入/輸出維度較小的瓶頸,Figure 5中展示了一個示例,這兩種模塊設計具有相似的時間復雜度,但卻實作了更維度的殘差函式學習,
無參的恒等映射殘差連接對于瓶頸架構尤為重要, 如果將Figure 5中的殘差連接從恒等映射替換為投影映射,隨著兩個高維端的殘差連接,整個時間復雜度和模型大小都會增加一倍,因此,恒等映射殘差連接為bottleneck設計帶來了更有效的模型,
50-layer ResNet
我們使用選項B來連接不用維度的層,這個模型有著38億次的乘加,
101-layer and 152-layer ResNets
Comparisons with State-of-the-art Methods
以上都是介紹了模型引數和實驗結果,這里不過多贅述,
4.2 CIFAR-10 and Analysis
略,
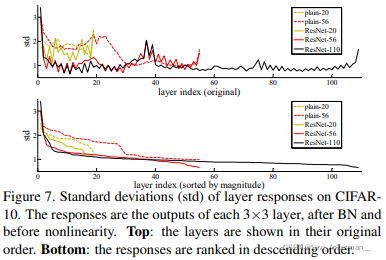
Analysis of Layer Responses
Figure 7 顯示了層回應的標準差std,回應指是每個 3×3 層的輸出,在Batch Normalization之后和其他非線性(ReLU/addition)之前, 對于殘差網路,該分析揭示了殘差函式的回應強度,Figure 7顯示殘差網路的回應通常比它們對應的普通網路要小,這些結果支持了我們的基本假定,即殘差函式通常比非殘差函式更接近于零,我們還注意到,更深的殘差網路會具有更小的回應量級,如Figure 7中ResNet-20、56和110之間的比較所證明的那樣,當有更多層時,殘差網路的單個層往往會更少地修改信號,
Exploring Over 1000 layers
1202層的殘差網路能夠達到低至0.1%的訓練誤差,它的測驗誤差也相當不錯,
但是在如此深的模型上仍然存在未解決的問題,這個1202層的殘差網路的測驗結果比我們110層的殘差網路要差,盡管兩者都有相似的訓練誤差,我們認為這是過擬合導致的,對于CIFAR-10這個小資料集,1202 層網路可能會大的有點沒必要了(包含19.4M個引數),所以應用強正則化(如maxout或dropout)以獲得該資料集上的最佳結果,在本文中,我們沒有使用 maxout/dropout,只是簡單地通過設計深而纖細的架構去強加正則化,沒有分散對優化難點的關注,但是結合更強的正則化可能會使得結果進一步改善,我們將在未來繼續研究這一問題,
4.3 Object Detection on PASCAL and MS COCO
略,
5 Conclusion
無,
本文并沒有來得及加上一個結論部分,但是整篇文章看下來已經足夠清晰明確,首先引入觀察到的奇怪的衰退現象,然后屆時其原因,從而介紹為什么要引入殘差網路、怎么引入殘差網路、引入殘差網路的幾種方法的比較和一些實作細節,非常流暢且清晰,不斷強調殘差學習對于整個優化收斂程序的重要性,并用強有力的實驗資料證明了文中提出的假設,牛!
結束!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/396348.html
標籤:其他
上一篇:函式影像畫法(一)