U-Net論文詳解
UNet演算法Pytorch實作:https://github.com/codecat0/CV/tree/main/Semantic_Segmentation/UNet
U-Net結構由一個用于捕獲背景關系資訊的壓縮路徑和一個支持精確定位的對稱擴展路徑構成,實驗結果表明可以從很少的影像進行端到端的訓練,并在ISBI挑戰上優于先前最優的方法(滑動視窗卷積網路),并獲得了冠軍
1. 背景介紹
卷積網路的典型應用是分類任務,其中影像的輸出是一個單一的類標簽,然而在許多視覺任務中,特別是生物醫學影像處理中,期望的輸出應該包含定位,即給每一個像素點分配一個類標簽,
于是滑動視窗卷積網路通過提供像素點周圍的區域區域來預測每個像素的類別標簽,但是這樣的方法存在兩個缺點:
- 速度特別慢,網路必須為每一個視窗單元單獨運行,并且視窗單元重合而導致大量冗余
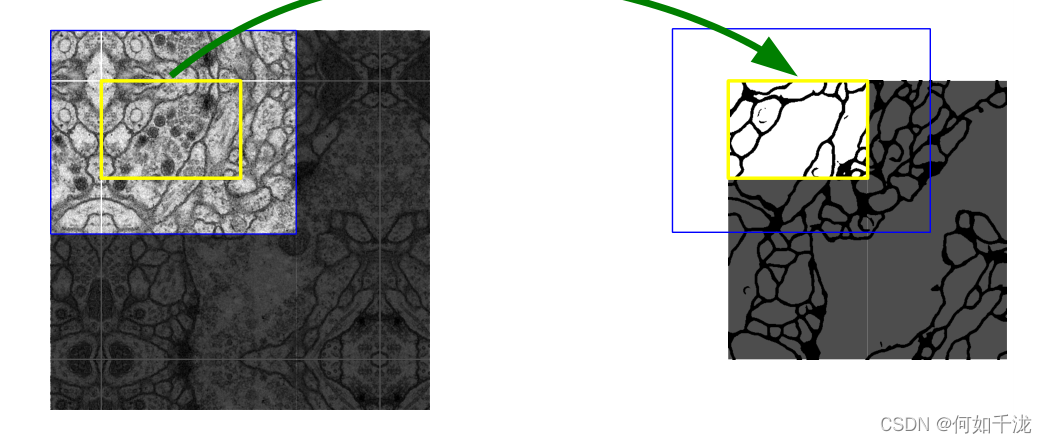
- 在定位精度和背景關系資訊之間的權衡,大的視窗單元需要更多的max pooling層,這會降低精度;而小的視窗單元捕獲的背景關系資訊較少,
于是本文提出了U-Net網路
2. U-Net網路架構

網路是一個經典的全卷積網路,網路的輸入是一張572x572經過鏡像操作的影像,為了使得每次下采樣后特征圖的尺寸為偶數,
網路的左側為壓縮路徑,由4個block構成,每個block由2個未padding的卷積和一個最大池化構成,其中每次卷積特征圖的尺寸為減小2,最大池化后會縮小一半,
現在大部分采用same padding的卷積,這樣就不用對輸入進行鏡像操作,而且在拼接壓縮路徑與對應的擴展路徑也不用進行裁剪,而且裁剪會使得特征圖不對稱
網路的右側為擴展路徑,同樣由4個block構成,每個block開始之前通過反卷積將特征圖的尺寸擴大一倍,然后與壓縮路徑對應的特征圖拼接,由于采用未padding的卷積,左側壓縮路徑的特征圖的尺寸比右側擴展路徑的特征圖的大,所以需要先進行裁剪,使其大小相同,然后拼接,然后經過兩次未padding的卷積進一步提取特征
最后根據自己的任務,輸出對應大小的預測特征圖
現在大部分采用雙線性插值代替反卷積,而且效果會更好
3. 資料增強
我們主要通過平移和旋轉不變性以及灰度值的變化來增強模型的魯棒性,特別地,任意的彈性形變對訓練非常有幫助,
4. Pytorch實作
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, in_channels, out_channels):
super(Encoder, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.block2 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x_pooled = self.pool(x)
return x, x_pooled
class Decoder(nn.Module):
def __init__(self, in_channels, out_channels):
super(Decoder, self).__init__()
self.up_sample = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.block2 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x_prev, x):
x = self.up_sample(x)
x_shape = x.shape[2:]
x_prev_shape = x.shape[2:]
h_diff = x_prev_shape[0] - x_shape[0]
w_diff = x_prev_shape[1] - x_shape[1]
# padding
x_tmp = torch.zeros(x_prev.shape).to(x.device)
x_tmp[:, :, h_diff//2: h_diff+x_shape[0], w_diff//2: x_shape[1]] = x
x = torch.cat([x_prev, x_tmp], dim=1)
x = self.block1(x)
x = self.block2(x)
return x
class UNet(nn.Module):
# https://arxiv.org/abs/1505.04597
def __init__(self, num_classes=2):
super(UNet, self).__init__()
self.down_sample1 = Encoder(in_channels=3, out_channels=64)
self.down_sample2 = Encoder(in_channels=64, out_channels=128)
self.down_sample3 = Encoder(in_channels=128, out_channels=256)
self.down_sample4 = Encoder(in_channels=256, out_channels=512)
self.mid1 = nn.Sequential(
nn.Conv2d(512, 1024, 3, bias=False),
nn.ReLU(inplace=True)
)
self.mid2 = nn.Sequential(
nn.Conv2d(1024, 1024, 3, bias=False),
nn.ReLU(inplace=True)
)
self.up_sample1 = Decoder(in_channels=1024, out_channels=512)
self.up_sample2 = Decoder(in_channels=512, out_channels=256)
self.up_sample3 = Decoder(in_channels=256, out_channels=128)
self.up_sample4 = Decoder(in_channels=128, out_channels=64)
self.classifier = nn.Conv2d(64, num_classes, 1)
def forward(self, x):
x1, x = self.down_sample1(x)
x2, x = self.down_sample2(x)
x3, x = self.down_sample3(x)
x4, x = self.down_sample4(x)
x = self.mid1(x)
x = self.mid2(x)
x = self.up_sample1(x4, x)
x = self.up_sample2(x3, x)
x = self.up_sample3(x2, x)
x = self.up_sample4(x1, x)
x = self.classifier(x)
return x
if __name__ == '__main__':
input = torch.rand(1, 3, 384, 384)
model = UNet(2)
out = model(input)
print(out.shape)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/396351.html
標籤:其他