RCNN, Fast RCNN, Faster RCNN
剛涉足目標檢測,向通過寫博客來記錄一下自己的學習程序,也希望可以給大家的學習帶來一些幫助,今天的2021年的最后一天,希望看到我文章的朋友們,在新的一年里都能學有所成,學有所獲!

R-CNN演算法最早在2013年被提出,它的出現打開了運用深度學習進行目標檢測的大門,從此之后,目標檢測的精準度與實時性被不斷重繪,R-CNN系列演算法自提出之際,就非常引人注目,以至于在之后的很多經典演算法中,如SSD、YOLO系列、Mask R-CNN中都能看到它的影子,
R-CNN、Fast R-CNN采用的還是傳統的SS演算法(selective search)生成推薦區域,計算非常耗時,達不到實時檢測的效果,直到Faster R-CNN才使用RPN代替了原來的SS演算法,才使得目標檢測的時間大大縮短,達到實時性的效果,
本篇博客先會對R-CNN、Fast R-CNN、Faster R-CNN進行一個簡明扼要地講解,之后,會寫博客著重講解R-CNN 系列的靈魂之作——Faster R-CNN,而這部分才是大家需要著重了解的,
一、RCNN(Region with CNN feature)
論文:
RCNN可以說是利用深度學習進行目標檢測的開山之作,作者Ross Girshick多次在PASCAL VOC目標檢測競賽中折桂,這種演算法的平均精確度比之前在VOC2012資料集上的最好測驗效果還要高30%,并且,由該演算法提出的論文《Rich feature hierarchies for accurate object detection and semantic segmentation》獲得了世界計算機視覺頂會CVPR2014的最佳論文獎,
RCNN演算法流程,可分為4步:
1.一張圖片生成1K~2K個候選區域(SS演算法)
利用SS演算法通過影像分割的方法得到一些原始區域,然后使用一些合并策略將這些區域合并,得到一個層次化的區域結構,而這些結構就包含著可能需要的物體,

2.對每一個候選區域,都使用深度神經網路(AlexNet)提取特征,得到1*4096的特征向量,
將2000個候選區域縮放到227×227pixel,接著將候選區域輸入事先訓練好的AlexNet CNN網路中獲取4096維的特征得到2000×4096維矩陣,
3.將每一個特征向量送入每一類的SVM分類器,判斷是否屬于該類
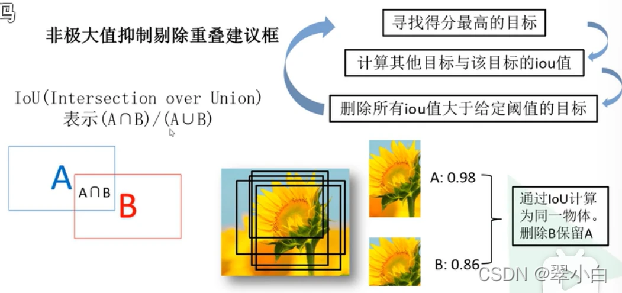
SVM是一個二分類器,所以它針對每一個類別都有一個專門的分類器,針對PASCAL VOC來說,它有20個類別,所以就有20個分類器,將2000×4096的特征矩陣與20個SVM組成的權值矩陣4096×20相乘,獲得2000×20的概率矩陣,每一行代表一個建議框歸于每個目標類別的概率,分別對上述2000×20維矩陣中每一列即每一類進行非極大值抑制剔除重疊建議框,得到該列即該類中得分最高的一些建議框,
非極大值抑制
4.對已分類的推薦框進行線性回歸,對這些框進行精細地調整,得到更加準確的邊界框坐標,
對非極大值抑制(NMS)處理后剩余的建議框進一步篩選,接著分別對20個回歸器對上述20個類別中剩余的建議框進行回歸操作,最終得到每個類別的修正后的得分最高的bounding box,
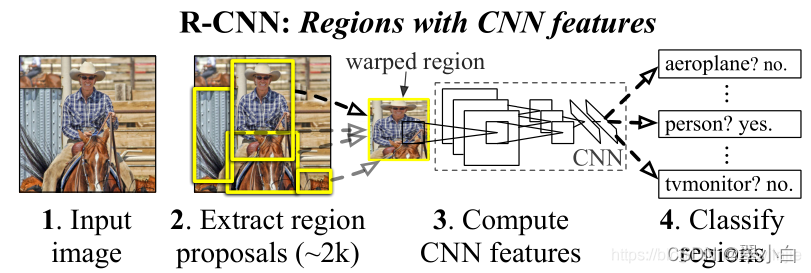
R-CNN演算法的檢測效果很好,但是檢測速度很慢,因此總體效率不高,其主要原因在于:
提取特征操作非常冗余,檢測時,需要將每個推薦區域都送入訓練好的模型(AlexNet)進行前向傳播,因此每張圖片大約要進行1000~2000次前向傳播,
訓練速度慢,程序繁瑣,要單獨分別訓練三個不同的模型:CNN用來提取影像特征、SVM分類器用來預測類別、回歸器精細修正建議框的位置,分開訓練,耗時耗力,
使用Selective Search演算法生成推薦區域,這個程序大約耗時2s,也是它不能達到實時性檢測的一個重要原因,
通過以上講解,我們可以發現RCNN的基本框架
| Region proposal(Selective Search) |
| Feature extraction(CNN)|
| Classification(SVM) | Bounding-box regression(regression)
二、Fast RCNN
2015年,Ross Girshick等人在R-CNN的基礎上進行了改進,解決了上述影響R-CNN效率的前兩個問題,與R-CNN相比,訓練速度快了9倍;測驗速度快了213倍;在Pascal VOC資料集上,準確率從62%提升到了66%,
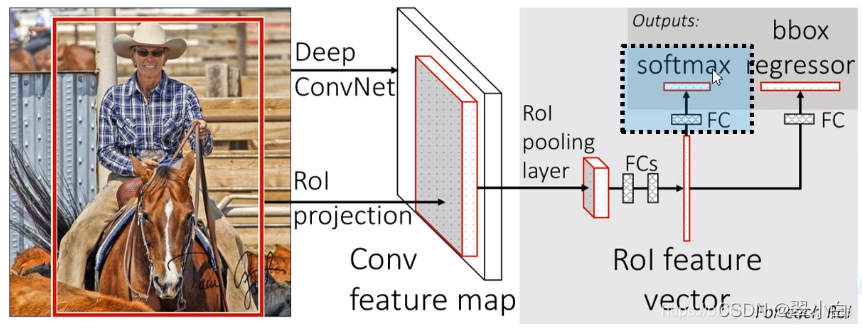
如上圖所示,Fast R-CNN演算法的流程主要分為下面三個步驟:
1.依然先使用SS(Selective Search)方法,使一張圖片生成1000~2000個候選區域,
2.將影像輸入到一個CNN(VGG-16)得到相應的特征圖,然后將已經生成的候選框投影到特征圖上獲得相應的特征矩陣,
3.將每個特征矩陣通過ROI Pooling層縮放到7*7大小,然后將特征圖展平,在通過一系列全連接層得到預測的類別資訊和目標邊界框資訊,(ROI:Region of Interest)
Fast R-CNN基本框架:
| Region proposal(Selective Search) |
| Feature extraction(CNN)|
| Classification(SVM) |
| Bounding-box regression(regression)|
Fast R-CNN的改進點:
ROI Pooling層,這個方法是針對R-CNN的第一個問題提出來的,用來解決提取特征操作冗余的問題,避免每個推薦區域都要送入CNN進行前向計算,核心思路是:將影像只輸入CNN提取特征,只進行一次前向計算,得到的特征圖由全部推薦區域共享,然后再將推薦區域(SS演算法得到)投影到特征圖上,獲得每個推薦區域對應的特征圖區域,最后使用ROI Pooling層將每個特征圖區域下采樣到7*7大小,
將原來三個模型整合到一個網路,易與訓練,R-CNN演算法使用三個不同的模型,需要分別訓練,訓練程序非常復雜,在Fast R-CNN中,直接將CNN、分類器、邊界框回歸器整合到一個網路,便于訓練,極大地提高了訓練的速度,
三、Faster RCNN
Faster R-CNN演算法將Region Proposal Networks與Fast R-CNN進一步合并為一個單個網路,是作者Ross Girshick繼Fast RCNN后的又一力作,同樣使用VGG16作為網路的backbone,推理速度在GPU上達到5fps,準確率也有進一步的提升,在2015年的ILSVRC以及COCO競賽中獲得多個專案的第一名,
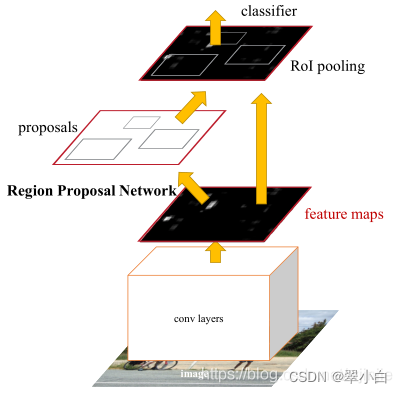
如上圖所示,Faster R-CNN演算法流程主要有以下4個步驟:
Conv layers,首先將影像輸入到CNN(VGG-16)提取影像特征,得到的feature maps 將被共享用于后面的RPN和ROI Pooling,
Region Proposal Networks,RPN用于生成推薦區域,該網路通過softmax判斷anchors屬于positive還是negative,再利用邊界框回歸修正anchors獲得精確的推薦框proposals,
ROI Pooling,該層以feature maps和proposals同時作為輸入,綜合這些資訊后提取proposal feature maps,送入后續全連接層判定目標類別,
Classifer,將proposal feature maps輸入全連接層與預測proposals的類別;同時再次進行邊界框回歸,獲得檢測框最終的精確位置,
相比Fast-RCNN,改進后的Faster R-CNN演算法不僅速度上很很大提升,基本可以達到實時的檢測幀率;檢測精度也有所提高,
接下來會詳細的學一下Faster RCNN,學完之后會更新博客,謝謝大家~
參考資料:https://blog.csdn.net/wjinjie/article/details/105930512
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400394.html
標籤:其他
上一篇:[劍指offer] 第二層