【跨年博客/輕松向】Pytorch卷積神經網路影像識別
- 導語
- 注意
- 程式
- 需要匯入的庫
- 設定資料集
- 定義網路
- 訓練
- 預測
- 一些閑談
寫于2021-12-31 23:04,2021年最后一篇博客了,也是2022年第一篇博客,
今年的格言:有一分熱,發一分光,就令螢火一般,也可以在黑暗里發一點光,不必等候炬火,此后如竟沒有炬火,我便是唯一的光,
導語
前幾天不是發了一個MNIST影像識別的文章嗎,但那篇還是有一些東西沒講的很好,MNIST影像是灰度影像,很多小伙伴想看看RGB的寫法,這次拿RGB圖做一個細胞分類吧~
注意
此篇博客是對上篇博客的修正、補充以及拓展,
請先參閱上期博客:【Pytorch】MNIST 影像分類代碼 - 超詳細解讀_CSDN_千魚干的博客
有地方看不懂沒事,看完后看這篇的補充內容,
程式
需要匯入的庫
import torch
import torch.nn as nn
from torch.nn import Sequential
from matplotlib import pyplot as plt
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
torch庫就不解釋了,
torch.nn庫是一個包含了神經網路的Modules和用來繼承的包以及一些函式方法,比如nn.functional,因為我們之后定義網路時是從nn.Module繼承的,還用了nn里面的卷積、激活函式等等,所以這個庫必不可少,
Sequential(中文:序列)是torch.nn里面“整合”層用的,就相當于餅干盒,把餅干“像序列一樣”裝進去,
matplotlib在這里是一個顯示影像的庫,我們引入了pyplot,用來顯示影像,
torchvision包含一些資料集、模型、影像處理方法,這里用datasets來處理資料集(我們自己的圖片),
torch.utils.data里面的DataLoader是用來將資料集裝載用的,以便訓練,
torchvision.transforms在這里用于定義資料集處理形式,往下看就知道,
設定資料集
這里假設我們資料集的路徑是當前你的python檔案所在檔案夾下data/CELLS/,這個檔案夾下有兩個子檔案夾,一個叫“linba”,另一個叫“xianxingli”
插播一句,現在是2022-1-1 0:00,這篇博客寫了一年(笑)
也就是說,我們的資料集分為淋巴細胞和線性粒細胞兩種細胞的圖片,
所以我們要設定兩個類別:classes = [“linba”, “zhongxingli”]
我們這里設定一下批次大小位64,迭代250次,學習率0.001,
學習率選一個小小的數,這樣有助于梯度下降,具體原因見上一篇博客,
這里還要寫一個get_variable()函式以獲取cuda加速后的自動求導結果,
這里 再次 詳細解釋一下epochs和batch_szie:
->batch_size表示每輪迭代訓練時每次訓練的資料量;
->epochs表示訓練幾輪,
每一次迭代(Iteration)都是一次權重更新,每一次權重更新需要batch_size個資料進行正向傳遞(Forward)運算得到損失函式,再通過反向傳導(Backward)更新引數(注意,在這個程序中需要把梯度(Grad)設定為0,這個后面再講),1個迭代等于使用batch_size個樣本訓練一次,比如有256個樣本資料,完整訓練完這些樣本資料需要:
->batch_size=64;
->迭代4次;
->epochs=1,
而通常會將epochs設為不僅1次,這就跟磨面一樣,磨完一輪不夠,磨多輪才能得到更加精細的面粉,
這時候因為我們處理的是圖片,而我們處理的應該是張量(Pytorch處理的是張量,類似向量,矩陣),我們怎么讓資料集圖片變成資料集矩陣呢?
這時就要設定transform(翻譯:轉換)了,
同時,我們的圖片不能太大,否則會讓訓練很慢,
所以我們首先將圖片轉化為張量,然后將裁剪為
w
?
h
=
128
?
128
w*h=128*128
w?h=128?128(w是width,寬;h是height,高;c是channel,通道,就是顏色通道,RGB是紅綠藍三通道)大小的張量,同時我們還要讓每個像素數值服從標準為0.5的正態分布,
因為我們需要訓練集和測驗集兩部分,所以將資料集分成兩個處理內容,最后將訓練集和測驗集裝載,資料集處理完畢,
最后,我們展示一下某張資料集圖片轉換為向量并處理之后的樣子(可選),
全部代碼如下:
path = "./data/CELLS/"
classes = ["linba", "zhongxingli"]
def get_variable(x):
x = torch.autograd.Variable(x)
return x.cuda() if torch.cuda.is_available() else x
batch_size = 64
epochs = 250
lr = 0.001
test_path = "./data/CELLS/"
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((128, 128)),
transforms.CenterCrop(128),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
])
data_train = datasets.ImageFolder(root=path, transform=transform)
train_loader = DataLoader(data_train, batch_size=batch_size, shuffle=True)
data_test = datasets.ImageFolder(root=test_path, transform=transform)
test_loader = DataLoader(data_test, batch_size=batch_size, shuffle=True)
# -----------------------展示資料集---------------------------
images, labels = next(iter(train_loader))
img = images[0].numpy().transpose(1, 2, 0)
plt.imshow(img)
plt.title(labels[0])
plt.show()
# -----------------------展示資料集---------------------------
定義網路
網路結構如下圖:

注意,輸入出的“?x128x128x3”的意思是“?”張圖片,“128x128x3”是
w
?
h
?
c
=
128
?
128
?
3
w*h*c=128*128*3
w?h?c=128?128?3,
怎樣定義網路呢?首先我們要從nn.Module繼承,然后“裝填”入我們的架構,最后在前向計算(forward)函式中進行前向計算,
這里注意一下:forward函式不需要顯式呼叫,因為nn.Module類中有一個函式會自動呼叫forward,
上一篇博客沒寫明這里每層的引數是怎么計算的,這一部分相當重要,因為最后傳入全連接層時必須要求輸入和輸出匹配,但這里我上篇沒細講,
這里貼出nn.Conv2d()在Pytorch官方檔案里的圖:
–>猛戳我 - 原文鏈接<–

注意這里的符號,
H
o
u
t
H_{out}
Hout?是進行的向下取整,
定義類的方式和上一篇相似,
代碼:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv3 = Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv4 = Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.dense = Sequential(
nn.Linear(8 * 8 * 256, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(128, 2)
)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
x4 = self.conv4(x3)
x5 = x4.view(-1, 8 * 8 * 256)
out = self.dense(x5)
return out
訓練
這一部分我上一篇講的很詳細了,我只貼出代碼:
cnn = CNN()
if torch.cuda.is_available():
cnn = cnn.cuda()
lossF = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=lr)
cnn.train()
loss_pth = 999999999.99
i_pth = 0
for epoch in range(epochs):
running_loss = 0.0
running_correct = 0.0
print("Epochs [{}/{}]".format(epoch, epochs))
for data in train_loader:
X_train, y_train = data
X_train, y_train = get_variable(X_train), get_variable(y_train)
outputs = cnn(X_train)
_, predict = torch.max(outputs.data, 1)
# ----------------------------------
optimizer.zero_grad()
loss = lossF(outputs, y_train)
loss.backward()
optimizer.step()
# ----------------------------------
running_loss += loss.item()
running_correct += torch.sum(predict == y_train.data)
testing_correct = 0.0
for data in test_loader:
X_test, y_test = data
X_test, y_test = get_variable(X_test), get_variable(y_test)
outputs = cnn(X_test)
_, predict = torch.max(outputs.data, 1)
testing_correct += torch.sum(predict == y_test.data)
print("Loss: {} Training Accuracy: {}% Testing Accuracy:{}%".format(
running_loss,
100 * running_correct / len(data_train),
100 * testing_correct / len(data_test)
))
if running_loss < loss_pth:
loss_pth = running_loss
torch.save(cnn, "./models/cell_classify_%d.pth" % i_pth)
i_pth = i_pth + 1
torch.save(cnn, "cell_classify.pth")
print("訓練完成!最小損失為:%f" % loss_pth)
預測
這一部分我在上一篇博客也是講得比較詳細,我只貼出代碼,
這里設pics檔案夾下還有一個檔案夾,里面有待預測圖片:
import torch
import torch.nn as nn
from torch.nn import Sequential
from matplotlib import pyplot as plt
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
model_path = "./models/cell_classify.pth"
test_path = "./pics/"
classes = ["linbaxibao", "zhongxinglixibao"]
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((128, 128)),
transforms.CenterCrop(128),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
])
data_test = datasets.ImageFolder(root=test_path, transform=transform)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv3 = Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv4 = Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.dense = Sequential(
nn.Linear(8 * 8 * 256, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(128, 2)
)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
x4 = self.conv4(x3)
x5 = x4.view(-1, 8 * 8 * 256)
out = self.dense(x5)
return out
net = torch.load(model_path)
net.eval()
def get_variable(x):
x = torch.autograd.Variable(x)
return x.cuda() if torch.cuda.is_available() else x
def inference_model(test_img):
for data in test_loader:
test, _ = data
img, _ = data
test = get_variable(test)
outputs = net(test)
rate, predict = torch.max(outputs.data, 1)
for i in range(len(data_test)):
print("It may be %s." % classes[predict[i]])
img0 = img[i]
img0 = img0.numpy().transpose(1, 2, 0)
plt.imshow(img0)
plt.title("It may be %s." % classes[predict[i]])
# plt.title("It may be %s, probability is %f." % (classes[predict[i]], rate[i]))
plt.show()
inference_model(test_path)
結果(預測結果在圖片上方和console里):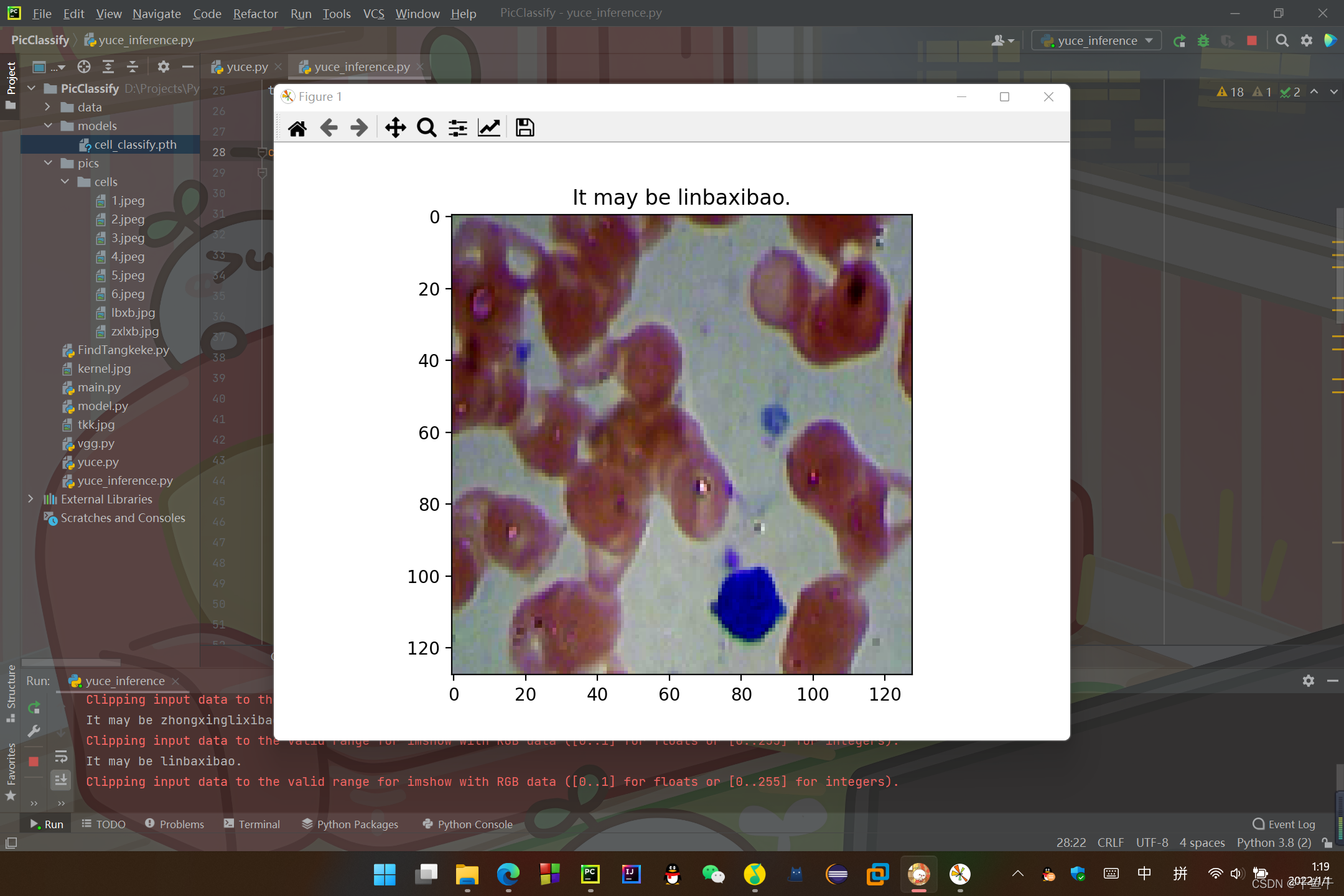
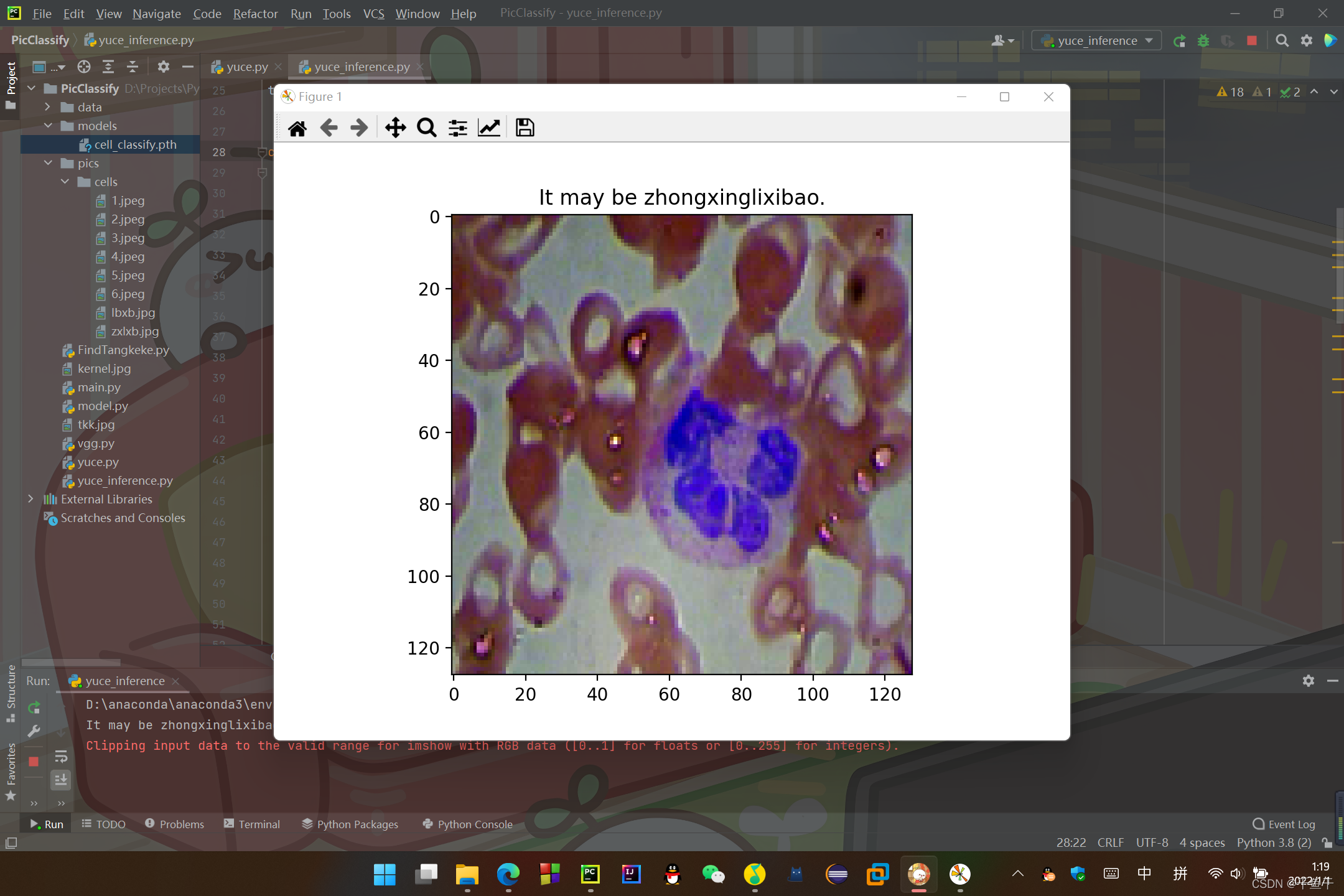
可以看到預測還是蠻準的嘛~
一些閑談
現在已經是2022年1月1日1:24了,我又長大了一歲(唉,我又老了)
回首2021年,我2021年4月19日突發感想 腦瓜一熱 記下了這么一句話:

可惜的是,這個愿望只實作了,但沒完全實作(誰說人工智能就一定只是會聊天的機器人啊(~o ̄3 ̄)~),我的初衷是做一個和小愛同學一樣的人工智能…
目前在做超解析度重構,
2021年初,我報名了CSDN上的一個深度學習課,當時只是打算聽著玩,誰知道聽的感興趣了,就自己自學,沒人指導,走了不少彎路,但還是走下來了,
筆者小時候最討厭電腦了(小學6年級之前),可是六年級一次電腦課上我接觸了畫畫,我就覺得很好玩,就去研究怎么下載這樣的軟體,結果接觸了Photoshop,誰知道這東西收費,就自己去學怎么破解,初中一年級我想為什么我自己不能編一個這樣的程式呢?我就這樣接觸了編程,(后來還因為進了某網站后臺差點惹出事,幸虧自己懸崖勒馬),
筆者從前并不喜歡數學,從前數學一直是我最討厭的科目之一,因為我覺得我學的數學知識沒有什么用到的地方,很枯燥,不理解為什么有人那么喜歡數學(我從前單純覺得這些人是騙人的)(盡管為了高考要自我欺騙我很愛數學),大學在某普通本科讀計算機科學與技術,大一學了半年ACM,但是并不能聽懂(嗚嗚嗚),大一上學期的寒假接觸的機器學習,有趣的是,從接觸機器學習開始,我發現數學原來這么實用,和編程結合后,似乎孕育出了某種神奇的力量,
啊,已經1:47了啊,以后再聊吧,我睡了(),
最后祝大家:
2022 新年快樂!
貼一張喜歡的圖(侵刪):

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400412.html
標籤:其他