目錄
0. 前言
1. 資料增強處理
2. 為什么要資料增強?
3. 模型訓練
4. 測驗集上的性能
5. 小結
0. 前言
本文(以及接下來的幾篇)介紹如何搭建一個卷積神經網路用于影像分類的深度學習問題,尤其是再訓練資料集比較小的場合,通常來說,深度學習需要大量的資料進行訓練,尤其是像在影像處理這種通常資料維度非常高的場合,但是當你沒有一個足夠大的資料集進行訓練的時候應該怎么辦呢?
解決訓練資料集太小的方法通常有兩種:
(1) 使用資料增強策略
(2) 使用預訓練模型
上一篇我們搭建一個了小型卷積神經網路從頭開始訓練用于貓狗資料集的影像分類,僅利用了原始的貓狗資料集有25000張圖片中的3000張圖片(包括訓練集和測驗集),實驗表明在訓練集、驗證集以及測驗集上分別得到了99.5%, 77.3%和66.6%的accuracy,參見:深度學習筆記:在小資料集上從頭訓練卷積神經網路
從這個結果來看,很明顯地存在嚴重的過擬合,考慮到我們只用了3000張圖片,對于影像(大小為180*180*3)分類問題來說這個非常小的一個資料集,這個結果并不令人驚訝,
在本篇中,我們來看看使用資料增強策略看看其效果如何,
在下一篇,我們將進一步考慮基于(已經在大資料集上訓練過的)預訓練模型的基礎上,在小資料集上進一步訓練得到最終模型的效果如何,
1. 資料增強處理
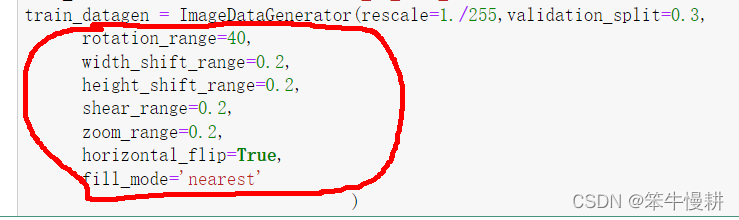
tf.keras.preprocessing.image.ImageDataGenerator提供了豐富的影像資料的資料增強處理功能,具體的各種引數如何的使用解說不是本文目的,有興趣的小伙伴可以自行參考tensorflow在線檔案(tf.keras.preprocessing.image.ImageDataGenerator | TensorFlow Core v2.7.0). 本文所對ImageDataGenerator的呼叫與上一篇的差別如下圖所示(上一篇沒有紅線圈住部分表示沒有資料增強處理),各引數的意思也幾乎是不言自明,這里就不一一解釋了,
我們可以看看資料增強對圖片所起的效果:
fig,ax = plt.subplots(2,4, figsize=[16,8])
np.random.seed(42)
cnt = 0
for new_batch in train_generator:
img1 = new_batch[0][np.random.randint(32)]
img2 = new_batch[0][np.random.randint(32)]
ax[cnt//4][cnt%4].imshow(img1)
ax[cnt//4][cnt//4].imshow(img2)
cnt += 1
if cnt == 8:
break
從以上圖片中應該不難看出資料增強所帶來的一些效果(扭曲、填充、旋轉等) ,
2. 為什么要資料增強?
過擬合的原因是學習樣本太少,導致無法訓練出能夠泛化到新資料的模型,如果擁有無限的資料,那么模型能夠觀察到資料分布的所有內容,這樣就永遠不會過擬合,資料樣本是從現有的訓練樣本中生成更多的訓練資料,其方法是利用多種能夠生成可信影像的隨機變化來增加樣本,新增加的樣本雖然是在原有的樣本的基礎進行變換而得,但是的確是有變化,因此訓練器不會看到完全相同的影像樣本,訓練器籍此可以觀察并提取資料中更多的內容,從而具有更好的泛化能力,
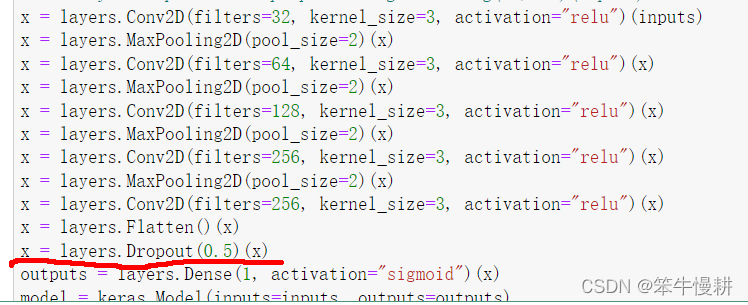
當然,由于新的資料樣本畢竟是基于原有的資料樣本變化而得,因此和原樣本之間是存在相關性的(即不是完全獨立的),你無法生成新的資訊,而只能混合現有資訊,因此,這種方法可能不足以完全消除過擬合,為了能夠充分取得降低過擬合的效果,還需要向模型中添加一個Dropout層,添加到Dense層之前(But Why ?),如下圖所示(紅線所劃部分):
3. 模型訓練
相對于上一篇的模型代碼,本文中的兩處關鍵代碼如上所述,這里就不再一一解釋,為了方便,這里將所有代碼串在一起(方便有興趣的小伙伴復制下載試運行),資料目錄cats_vs_dogs_small的生成代碼這里就忽略了(需要的話從上一篇中復制即可)
from tensorflow import keras
from tensorflow.keras import layers
# Model construct
inputs = keras.Input(shape=(180, 180, 3))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.summary()
# Configuring the model for training
model.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])
# Data generators
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
train_dir = os.path.join('F:\DL\cats_vs_dogs_small', 'train')
test_dir = os.path.join('F:\DL\cats_vs_dogs_small', 'test')
train_datagen = ImageDataGenerator(rescale=1./255,validation_split=0.3,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode="binary",
subset='training',
shuffle=True,
seed=42
)
valid_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode="binary",
subset='validation',
shuffle=True,
seed=42
)
test_generator = test_datagen.flow_from_directory(
directory=test_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode='binary',
shuffle=False,
seed=42
)
# Training
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch_with_augmentation.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
x = train_generator,
validation_data=valid_generator,
steps_per_epoch = train_generator.n//train_generator.batch_size,
validation_steps = valid_generator.n//valid_generator.batch_size,
epochs=100,
callbacks=callbacks)
# Displaying curves of loss and accuracy during training
import matplotlib.pyplot as plt
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, "bo", label="Training accuracy")
plt.plot(epochs, val_accuracy, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()我的訓練結果如下所示:

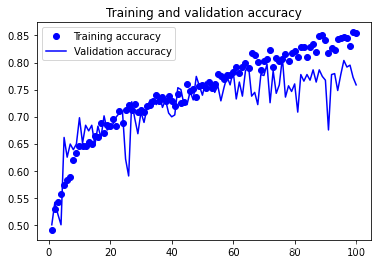
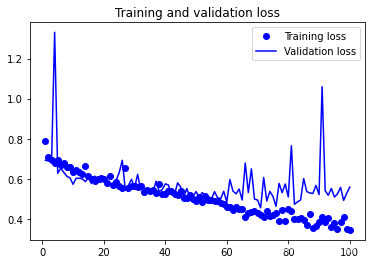
需要注意的是,基于資料增強得到了更多的資料樣本,相應地所需要的訓練的輪數也大大增加,在以上訓練中訓練了100輪,而上一篇中只訓練了30輪,但是即便是100輪,至少在訓練集上還沒有看到accuracy完全到頂的跡象,另一個值得注意的是,驗證集上的accracy和loss都顯示除了較大的波動,這個是為什么?
4. 測驗集上的性能
最后,來看看這個新訓練出來的模型在測驗集上表現如何,
test_model = keras.models.load_model("convnet_from_scratch_with_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_generator)
print(f"Test accuracy: {test_acc:.3f}")
雖然新的模型在訓練集和驗證集上分別只有85%和80%不到一點,但是在測驗集上卻達到了82.6%,在上一篇的原始模型中只有66%!在測驗集上accuracy的相對提升高達40%!雖然新的模型在訓練上花了更多的時間,但是仍然必須承認這是一個巨大的提升!
5. 小結
本篇中我們看到資料增強帶來了不錯的效果,雖然,82.6%仍然不夠好,通過進一步地使用正則化和調節網路引數(比如說每個卷積層的過濾器個數,或網路中的層數),有可能得到更高的精度,但是靠從頭開始訓練自己的卷積神經網路,想要提升到90%以上非常困難,因為可用的資料太少了,想要在這個問題上進一步提高精度,下一步需要使用預訓練模型,這是下一篇的重點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401506.html
標籤:其他
上一篇:Matlab機器學習入門(一)