文章目錄
- 1.寫在最前面
- 2.什么是機器學習
- 3.機器學習面臨的挑戰
- 3.1過擬合
- 3.2克服過擬合
- 4.機器學習的型別
1.寫在最前面
從零開始接觸機器學習,寒假將做一系列Matlab的學習筆記,以此來記錄一個通信工程的學生接觸Matlab的全程序,
2.什么是機器學習
機器學習是針對資料的一種建模技術,這里的資料指資訊,如檔案、音頻、影像等,“模型”則是機器學習的最終產品,機器學習的誕生就是為了解決那些難以得出決議模型的問題,其技術的核心思想就是在無法使用公式及定理得到滿意結果時,利用訓練資料來建立模型,
3.機器學習面臨的挑戰
訓練資料與輸入資料之間存在差異時機器學習面臨的結構性挑戰,是機器學習所存在的一切問題的根源,
機器學習和深度學習均無法基于錯誤的訓練資料來實作預期目標,因此,對于機器學習而言,獲取能夠充分反映實際領域資料特征的無偏訓練資料至關重要,
泛化(generalization)是確保模型對于訓練資料與輸入資料能夠獲得一致性能的處理程序,機器學習能否成功很大程度上取決于泛化的有效程度,
3.1過擬合
泛化程序失效的主要誘因之一就是過擬合(overfitting),示例如下圖,
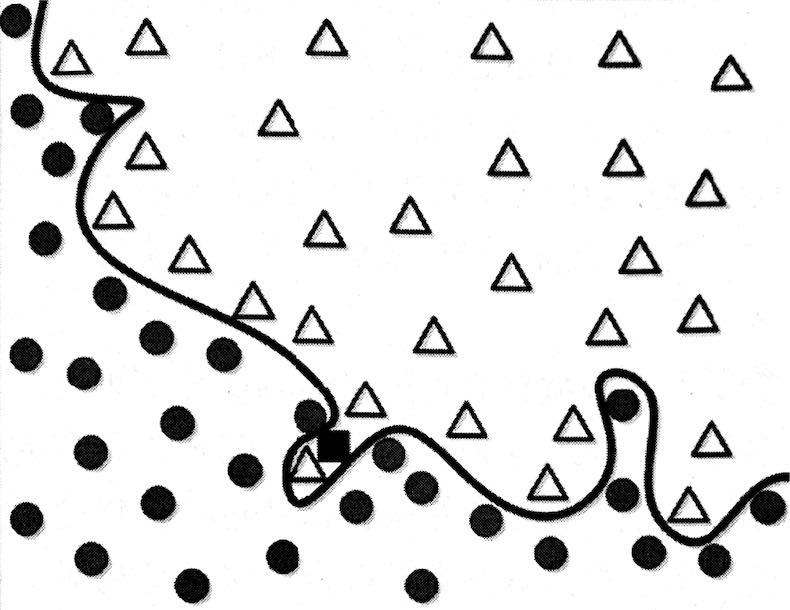
顯然由訓練資料的一般趨勢可以反映出該模型是有問題的,我們仔細看資料點,會發現某些例外資料點穿過了邊界進入另一分類所對應的區域,換言之,這些資料中包含一些噪聲,問題是機器學習無法區分噪聲,如果機器學習考慮包括噪聲的所有資料,它將生成一個不合理的模型(如上圖曲線),
由此可知,訓練資料不是完美無瑕的,其中可能包含不同程度的噪音,如果認為訓練資料中的每一個元素都是準確的,并且精確匹配模型,將得到一個普適性較低的模型,即過擬合,
機器學習的本源特性是竭盡所能地從訓練資料中抽象出一個優質模型,但適用于訓練資料的模型可能無法有效地應用于實際資料, 這并不意味著應該有意降低模型對訓練資料的準確性,那將會違背機器學習的基本原則,
3.2克服過擬合
有兩種辦法可以實作,為正則和驗證,
正則化(Regularization)是一種構建極簡模型的數值方法,精簡后的模型能以較小的性能代價,避免過擬合的影響,簡單曲線雖然未能正確劃分部分資料點,但能更好地反映各分類的總體特征,
驗證(validation)的存在為了確定由訓練建立的模型是否存在過擬合,通過預留一部分訓練資料來監控模型的性能,驗證資料集不參與訓練程序,
4.機器學習的型別
根據訓練方法的不同,機器學期技術可以分為以下三種型別:
監督學習(supervised learning)
無監督學習(unsupervised learning)
增強學習(reinforcement learing)
監督學習與人類學習事物的程序非常相似,在監督學習中,每個訓練資料集均由輸入與標準輸出構成的資料對構成,標準輸出是模型對該輸入應生成的預期結果,監督學習的學習程序即是對模型自身進行一系列修正,以降低模型依據輸入所生成的輸出與標準輸入之間的差異的程序,如果模型訓練得很完善,就能對輸入訓練資料生成該資料對應的標準輸出,
監督學習最常見的兩類應用是分類(classification)與回歸(regression)分類問題所關注的就是尋找資料所屬的類別,資料中的類別即作為對應輸入的標準輸出;回歸則是預測數值,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401505.html
標籤:其他