賽事官方入口:https://codalab.lisn.upsaclay.fr/competitions/823#learn_the_details-overview
深度強化實驗室的中文說明:
http://deeprl.neurondance.com/d/583-ai
http://deeprl.neurondance.com/d/584-ai
賽題說明
現在商家想要將促銷策略從個性化促銷轉換為平等化促銷,執行的方式是發放優惠券,我們可以通過控制優惠券的數量和折扣來達成目標,通過對不同的消費者投放不同數量不同折扣的消費券來達成目的,
對于非平等化促銷策略,它輸入單個用戶狀態,輸出給單個用戶發放的促銷動作,因此每個人的促銷動作可以各不相同,要學習一個平等化促銷策略,它輸入的是全體用戶的狀態,輸出一個給全體用戶發放相同的促銷動作,
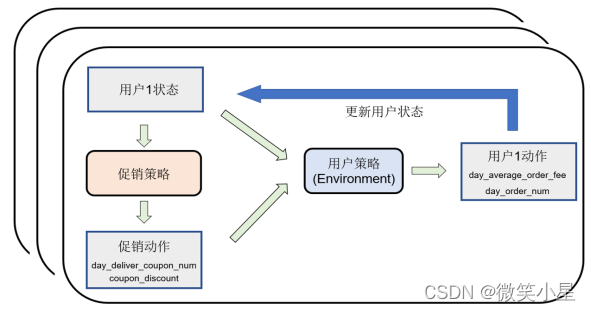
如圖所示,由于用戶的個體間存在的差異,用戶對于促銷策略的反應也不相同,反應這些用戶差異的資訊我們稱為用戶狀態,我們的網路模型接收這個用戶的狀態,然后輸出對應的促銷動作,如何優化這個策略網路使得促銷效果最好是我們本次比賽的任務,當用戶接收了我們的促銷動作之后,就會輸出對應的動作:即用戶當天訂單數以及訂單的平均金額,這時候用戶的狀態也會隨著更新而改變,也就是說,用戶相當于強化學習的環境本身,環境的輸入是用戶前一天的狀態以及促銷的動作,環境的輸出為用戶今天的狀態以及用戶對應的動作,用戶的動作可以視作環境的獎勵,
下面我們來看看官方提供的資料:
官方初賽的資料是一個csv檔案,里面包含了1000個用戶60天內的資料,總共有6000條資料,
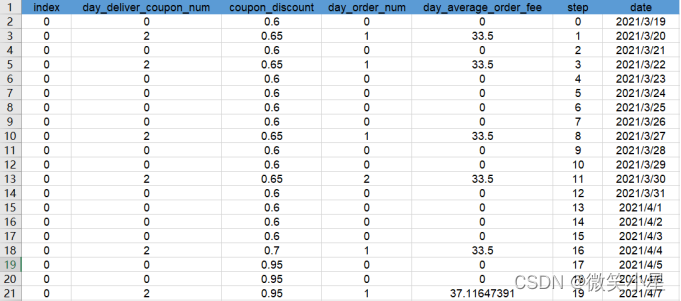
每一列代表的含義是:
index:用戶ID,
day_deliver_coupon_num:營銷平臺當天發放的優惠券張數,注意,每張優惠券的有效期為當日,
coupon_discount:營銷平臺當天發放的優惠券折扣,
day_order_num:用戶當天訂單次數,優惠券默認會隨著訂單使用,直到優惠券用完,
day_average_order_fee:用戶當天所有訂單折扣前的平均金額,
step:天數,范圍0-59,
date:日期,范圍為2021/03/19到2021/05/17,
我們需要自行定義用戶的狀態輸入來對我們的策略網路進行訓練,定義一個合理的狀態輸入對策略有著至關重要的影響,
評分規則:
目標:在Total_ROI>=6.5的前提下,最大化Total_GMV,
定義優惠訂單數(coupon_order_num)為:
c
o
u
p
o
n
_
o
r
d
e
r
_
n
u
m
=
m
i
n
(
d
a
y
_
d
e
l
i
v
e
r
_
c
o
u
p
o
n
_
n
u
m
,
d
a
y
_
o
r
d
e
r
_
n
u
m
)
coupon\_order\_num = min(day\_deliver\_coupon\_num , day\_order\_num)
coupon_order_num=min(day_deliver_coupon_num,day_order_num)
定義成本(coupon_order_fee)為:
c
o
u
p
o
n
_
o
r
d
e
r
_
f
e
e
=
c
o
u
p
o
n
_
o
r
d
e
r
_
n
u
m
?
d
a
y
_
a
v
e
r
a
g
e
_
o
r
d
e
r
_
f
e
e
?
(
1
?
c
o
u
p
o
n
_
d
i
s
c
o
u
n
t
)
coupon\_order\_fee = coupon\_order\_num * day\_average\_order\_fee * (1-coupon\_discount)
coupon_order_fee=coupon_order_num?day_average_order_fee?(1?coupon_discount)
定義單人應收(Per_GMV)為:
P
e
r
_
G
M
V
=
d
a
y
_
o
r
d
e
r
_
n
u
m
?
d
a
y
_
a
v
e
r
a
g
e
_
o
r
d
e
r
_
f
e
e
?
c
o
u
p
o
n
_
o
r
d
e
r
_
f
e
e
Per\_GMV = day\_order\_num * day\_average\_order\_fee - coupon\_order\_fee
Per_GMV=day_order_num?day_average_order_fee?coupon_order_fee
總營收(Total_GMV):
T
o
t
a
l
_
G
M
V
=
∑
P
e
r
_
G
M
V
Total\_GMV = \sum Per\_GMV
Total_GMV=∑Per_GMV
總成本(Total_Cost):
T
o
t
a
l
_
C
o
s
t
=
∑
c
o
u
p
o
n
_
o
r
d
e
r
_
f
e
e
Total\_Cost = \sum coupon\_order\_fee
Total_Cost=∑coupon_order_fee
總盈利率(Total_ROI):
T
o
t
a
l
_
R
O
I
=
T
o
t
a
l
_
G
M
V
/
m
a
x
(
T
o
t
a
l
_
C
o
s
t
,
1
)
Total\_ROI = Total\_GMV \ / \ max(Total\_Cost,1)
Total_ROI=Total_GMV / max(Total_Cost,1)
因此,用戶輸出的動作決定了我們強化學習的獎勵,若Total_ROI<6.5,得分為0,也就是說我們訓練的策略網路決不能讓用戶的動作去越過這條紅線,在此基礎上,得分為Total_GMV,也就是說滿足一定利率的情況下,盡最大可能提高應收總額,
提交方式
參賽者基于大賽提供的介面,上傳測評代碼以及相關模型壓縮檔案, 解壓后專案最外層目錄定義好入口檔案policy_validation.py, 并根據我們提供的模板,實作抽象類PolicyValidation,完成policy_validation.py,
policy_validation.py內容如下,參賽者主要需實作:
get_next_states (cur_states, coupon_action, user_actions)
輸入當天所有用戶的動作,輸出由參賽者自行定義的次日用戶狀態,注意這里和一般強化學習不同的地方在于,下一個狀態是需要自己定義的,環境負責輸出的是一個用戶的動作,這個用戶的動作包含了獎勵以及下一個狀態的資訊,如何運用這個用戶的動作及其它資料來構成下一個狀態是一個值得研究的課題,
get_action_from_policy (user_states)
輸入當天用戶狀態,由參賽者策略輸出當天所有用戶的促銷動作,這個就是我們需要訓練的策略網路模型,
下面是一個模板:
class PolicyValidation:
"""定義評測程式所需介面的虛擬類,
"""
"""initial_states 是參賽者根據離線資料定義的評測第一天(自5月18日開始)的用戶狀態,
"""
initial_states: Any = None
@abstractmethod
def __init__(self, *args, **kwargs):
"""根據自身需求初始化模型所需變數,參賽者可以為此建構式提供一些形參,
但必須在 get_pv_instance() 函式中自行填充策略類所需的實參,
"""
@abstractmethod
def get_next_states(self, cur_states: Any, coupon_action: np.ndarray, user_actions: List[np.ndarray]) -> Any:
"""基于當天全體用戶狀態、當天的發券動作、與當天回應的用戶動作, 生成次日用戶狀態,
Args:
cur_states (Any): 當天全體用戶狀態,具體形式由參賽者定義,
coupon_action (np.ndarray): 當天發券動作,
example: np.array([2.0, 0.70]), 即當天給所有用戶發2張7折優惠券,
user_actions (List[np.ndarray]): 環境回傳的當天所有用戶動作, 具體形式和離線資料中一致,
example: [np.array([1.0, 22.34]), np.array([0, 0]), ... , np.array([2.0, 54.21])], 串列大小
和離線資料中用戶數一致, 且按順序一一對應,即 user_actions[0] 對應離線資料中 index 為0的用戶,
Return:
next_states (Any): 次日全體用戶狀態,具體形式由參賽者定義,
"""
@abstractmethod
def get_action_from_policy(self, user_states: Any) -> np.ndarray:
"""基于當天全體用戶狀態輸出當天發券動作
Args:
user_states (Any): 當天全體用戶狀態,具體形式由參賽者定義,
Return:
coupon_action (np.ndarray): 當天由參賽者策略給出的發券動作(所有用戶相同), 具體形式和離線資料保持一致,
example: np.array([2.0, 0.70]), 即當天給所有用戶發兩張7折優惠券,
"""
class MyPolicyValidation(PolicyValidation):
"""在此繼承 PolicyValidation 介面類,實作參賽者自己的策略模型,
"""
pass
def get_pv_instance() -> PolicyValidation:
"""回傳一個符合 PolicyValidation 介面類的實體,該函式會被評測程式呼叫,用于獲取參賽者的策略實作,"""
return MyPolicyValidation()
策略評估
平臺的策略測驗評估核心代碼如下:
def validate(self, pv):
"""在平臺真實環境中評估策略性能
Args:
pv (PolicyValidation): 參賽者實作的型別為PolicyValidation的實體化物件
Return:
Total_ROI, Total_GMV: 參賽者的策略在測驗期的總ROI和總GMV
"""
Total_GMV = 0.0
Total_Cost = 0.0
user_states = pv.initial_states
for day_index in range(self.validation_length):
print('Day', day_index+1)
self.reset()
coupon_action = pv.get_action_from_policy(user_states)
Cost, GMV, user_actions = self.step(coupon_action)
user_states = pv.get_next_states(user_states, coupon_action, user_actions)
Total_GMV += GMV
Total_Cost += Cost
Total_ROI = Total_GMV / max(Total_Cost, 1)
return Total_ROI, Total_GMV
如此,在函式的輸出Total_ROI不小于6.5下,Total_GMV就代表了最終的分數,
baseline提交與代碼講解
定義單個用戶狀態
為了學習用戶模型,我們首先需要定義用戶狀態(即用戶畫像),作為baseline,我們采取最簡單(而非最好)的方式來定義每個用戶的狀態,
比賽資料提供了歷史60天的促銷動作和用戶動作,每一個用戶收到的促銷動作每天各不相同,我們僅取60天中的前30天資料去定義用戶的初始狀態,后30天的資料將用于學習用戶模型,
我們定義了如下表所示的三維特征,來表示每一個用戶的初始狀態,值得注意的是,表1所定義的用戶狀態是最簡單的一種方式,參賽者為了獲得更好的效果需要自定義更復雜的用戶狀態,
| 特征名 | 說明 |
|---|---|
| total_num | 用戶歷史總訂單數 |
| average_num | 用戶歷史單日訂單數的平均(不考慮為0的天) |
| average_fee | 用戶歷史單日訂單均價的平均(不考慮為0的天) |
上面的三個數構成的三維向量代表了用戶的狀態,根據這個狀態,我們需要訓練一個策略網路,輸入該狀態,輸出需要發放的優惠券的數量和折扣,當用戶得到了優惠券的數量和折扣后,就會輸出一個用戶的動作,即當天的訂單數以及訂單的平均金額,這是由環境決定的,屬于不可控因素的一部分,但我們可以另外訓練一個環境的模型來擬合用戶的行為,
注意:用戶的狀態可能還與促銷的動作相關,但在baseline中沒有把這個因素考慮進去,
當得到用戶當前的狀態和用戶采取的動作之后,我們可以定義用戶的下一個狀態:
import numpy as np
next_state = np.empty(state.shape)
size = (state[0] / state[1]) if state[1] > 0 else 0
next_state[0] = state[0] + act[0]
next_state[1] = state[1] + 1 / (size + 1) * (act[0] - state[1]) * float(act[0] > 0.0)
next_state[2] = state[2] + 1 / (size + 1) * (act[1] - state[2]) * float(act[1] > 0.0)
我們把前30天的用戶資料作為第31天的用戶狀態,我們可以通過第31天~第60天的用戶動作,我們就可以去生成第32天到第61天的用戶狀態,
Revive SDK 工具
Revive SDK支持通過撰寫yaml檔案來描述決策流程,
metadata:
graph:
action_1:
- state
action_2:
- state
- action_1
next_state:
- action_2
- state
columns:
- total_num:
dim: state
type: discrete
max: 199
min: 0
num: 200
- average_num:
dim: state
type: continuous
- average_fee:
dim: state
type: continuous
- day_deliver_coupon_num:
dim: action_1
type: discrete
max: 5
min: 0
num: 6
- coupon_discount:
dim: action_1
type: discrete
max: 0.95
min: 0.6
num: 8
- day_order_num:
dim: action_2
type: discrete
max: 99
min: 0
num: 100
- day_average_order_fee:
dim: action_2
type: continuous
以graph開頭的部分負責描述決策流程,其中state、action_1、action_2、next_state是自定義的變數名,在此處分別代表當天用戶狀態、促銷動作、用戶動作和次日用戶狀態,從yaml檔案我們可以看出action_1的結果受state影響,對應決策圖就是當天用戶狀態指向促銷動作,也可以理解為action_1是輸出,state是對應的輸入,同理,action_2的結果受state、action_1影響,next_state的結果受state和action_2的影響,
在graph的下方就是定義state、action_1、action_2各個維度的含義,其中state包含三個維度,其中,一個離散變數0到199的總訂單數total_num,一個連續變數歷史單日訂單數的平均average_num,一個連續變數歷史單日訂單均價的平均average_fee,action_1包含兩個維度,其中,一個0到5的離散變數表示當日發放優惠券數day_deliver_coupon_num,一個0.6到0.95的離散變數表示優惠券折扣coupon_discount,action_2格子包含兩個離散變數,其中,一個離散變數表示用戶當天的訂單數day_order_num,一個連續變數表示用戶當天的平均訂單花費day_average_order_fee,
定義好yaml檔案后,配置好有關訓練資料和訓練引數就可以呼叫演算法包開始訓練,訓練完成后我們可以得到我們需要的用戶策略模型venv_model,venv_model模型的使用方式是:
import numpy as np
def venv_model_use_demo(states, coupon_actions):
"""呼叫用戶策略模型
Args:
states(np.array):用戶狀態
coupon_actions(np.array):發券動作
Return:
user_actions(np.array):用戶動作
"""
out = venv_model.infer_one_step({'state':states, 'action_1':coupon_actions})
return out['action_2']
基于虛擬環境的平等化促銷策略學習
對于非平等化促銷策略,它輸入單個用戶狀態,輸出給單個用戶發放的促銷動作,因此每個人的促銷動作可以各不相同,要學習一個平等化促銷策略,它輸入的是全體用戶的狀態,輸出一個給全體用戶發放相同的促銷動作,全體用戶的狀態如果直接拼接成一維陣列,是一個非常高維的輸入,所以在輸入平等化促銷策略前,需要降維處理,這里我們采用最簡單的方式,去計算當天全體用戶狀態每一維的統計量,并額外引入了兩維實時統計量,實作代碼如下:
import numpy as np
def _states_to_obs(states: np.ndarray, day_total_order_num: int=0, day_roi: float=0.0):
"""將所有用戶狀態的二維陣列降維為一維的用戶群體的狀態
Args:
states(np.ndarray): 包含每個用戶各自狀態的二維陣列
day_total_order_num(int): 全體用戶前一天的總訂單數,如果是初始第一天,默認為0
day_roi(float): 全體用戶前一天的ROI,如果是初始第一天,默認為0.0
Return:
用戶群體的狀態(np.array)
"""
assert len(states.shape) == 2
mean_obs = np.mean(states, axis=0)
std_obs = np.std(states, axis=0)
max_obs = np.max(states, axis=0)
min_obs = np.min(states, axis=0)
day_total_order_num, day_roi = np.array([day_total_order_num]), np.array([day_roi])
return np.concatenate([mean_obs, std_obs, max_obs, min_obs, day_total_order_num, day_roi], 0)
降維之后得到的的用戶群體的狀態是平等化促銷策略的真正輸入,策略的動作空間則和比賽資料中保持一致,我們可以通過以下的方式定義獎勵函式:
from gym import Env
class VirtualMarketEnv(Env):
MAX_ENV_STEP = 14 # 評估天數,作為環境的步長, 初賽14, 復賽30
ROI_THRESHOLD = 7.5 # 考慮虛擬環境誤差, 評估的總ROI閾值取7.5, 比實際線上6.5要高1.0
ZERO_GMV = 81840.0763705537 #在評估環境中, 在評估天數里, 不發券帶來的總GMV
# self.total_gmv: 評估期間總的GMV, self.total_cost: 評估期間總的成本
def step(self, action):
...
# 稀疏reward, 評估最后一天回傳最終的reward, 前面的天reward都是0
if (self.current_env_step+1) < VirtualMarketEnv.MAX_ENV_STEP:
reward = 0
else:
total_roi = self.total_gmv / self.total_cost
if total_roi >= VirtualMarketEnv.ROI_THRESHOLD:
# 超過ROI閾值, (總GMV/基線總GMV)作為回報
reward = self.total_gmv / VirtualMarketEnv.ZERO_GMV
else: # 未超過ROI閾值, (總ROI - ROI閾值)作為回報
reward = total_roi - VirtualMarketEnv.ROI_THRESHOLD
確定好整個問題的MDP后,可以使用任何可行的強化學習演算法,Baseline中直接使用了Proximal Policy Optimization(PPO)來訓練最終的平等化促銷策略,需要注意PPO訓練的是隨機策略,如果直接提交隨機策略,有可能造成每次評估的結果有隨機擾動,
策略提交
訓練好平等化促銷策略后,需要上傳策略進行在線評估,上傳的策略是一個打包好的zip檔案,其中以policy_validation.py作為入口點,并通過metadata檔案指定線上評估所需要的環境(我們支持:pytorch-1.8, pytorch-1.9, pytorch-1.10),
在policy_validation.py中,有一個PolicyValidation介面類,以及一個呼叫后回傳一個PolicyValidation實體的get_pv_instance()函式,提交策略后,線上環境會呼叫get_pv_instance(),并根據PolicyValidation定義好的介面規范對選手的策略進行評估,選手則需要繼承PolicyValidation介面類,實作需要的抽象方法與成員,并在get_pv_instance()的實作中回傳自己繼承的子類實體,
PolicyValidation類需要實作:
* 以第61天的用戶狀態資料,初始化PolicyValidation類的全體用戶的初始狀態(對應評估的第一天的用戶狀態),
* 根據當天全體用戶的狀態、促銷動作和當天回應的用戶動作,回傳次日全體用戶的狀態,
* 據當天全體用戶的狀態,回傳當天的促銷動作,
import os
import numpy as np
from abc import abstractmethod
from typing import Any, List
# 抽象類
class PolicyValidation:
# 初始化的用戶狀態由我們之前訓練的60天的資料得到
initial_states: Any = None
@abstractmethod
def __init__(self, *args, **kwargs):
"""可以定義你自己的引數以及初始化網路模型等
但必須自己在 get_pv_instance 函式中填寫引數,
"""
@abstractmethod
def get_next_states(self, cur_states: Any, coupon_action: np.ndarray, user_actions: List[np.ndarray]) -> Any:
"""利用今日的用戶狀態,用戶的動作,優惠券的動作,回傳次日的用戶狀態."""
@abstractmethod
def get_action_from_policy(self, user_states: Any) -> np.ndarray:
"""利用今日用戶的狀態,回傳優惠券動作"""
def get_pv_instance() -> PolicyValidation:
"""該函式由評估方運行,回傳一個策略驗證類,用來評估參與者策略效果
"""
from baseline_policy_validation import BaselinePolicyValidation
# os.path.split回傳路徑和檔案名,os.path.abspath(__file__)獲取當前腳本的完整路徑
submission_dir, _ = os.path.split(os.path.abspath(__file__))
return BaselinePolicyValidation(f"{submission_dir}/data/evaluation_start_states.npy", f"{submission_dir}/data/rl_model.zip")
接下來看看繼承這個抽象類的BaselinePolicyValidation是怎么實作的:
import numpy as np
# 通過typing引入注解型別,就能標注函式的回傳型別和引數型別了
from typing import List, Optional
from stable_baselines3 import PPO
from policy_validation import PolicyValidation
class BaselinePolicyValidation(PolicyValidation):
# 初始化
def __init__(self, initial_states_path, policy_model_path):
# 匯入初始用戶狀態
self.initial_states = np.load(initial_states_path)
# 匯入訓練模型
self.policy_model = PPO.load(policy_model_path)
# 資料清零
self.cur_day_total_order_num = 0
self.cur_day_roi = 0.0
# 對用戶的狀態進行整體的降維
def _states_to_obs(self, states: np.ndarray):
assert len(states.shape) == 2
mean_obs = np.mean(states, axis=0)
std_obs = np.std(states, axis=0)
max_obs = np.max(states, axis=0)
min_obs = np.min(states, axis=0)
day_total_order_num, day_roi = np.array([self.cur_day_total_order_num]), np.array([self.cur_day_roi])
return np.concatenate([mean_obs, std_obs, max_obs, min_obs, day_total_order_num, day_roi], 0)
# 計算用戶的下一個狀態
def get_next_states(self, cur_states: Optional[List[np.ndarray]], coupon_action: np.ndarray, user_actions: List[np.ndarray]):
# 獲取相應的資料
user_actions_array = np.array(user_actions)
day_order_num, day_avg_fee = user_actions_array[:, [0]], user_actions_array[:, [1]]
coupon_num, discount = coupon_action[0], coupon_action[1]
# 下面幾行是由一維陣列拓展成二維陣列的下一個狀態計算方式
next_states = np.empty(cur_states.shape)
size_array = np.array([[x[0] / x[1] if x[1] > 0 else 0] for i, x in enumerate(cur_states)])
next_states[:, [0]] = cur_states[:, [0]] + day_order_num
next_states[:, [1]] = cur_states[:, [1]] + 1 / (size_array + 1) * (day_order_num - cur_states[:, [1]]) * (day_order_num > 0.0).astype(np.float32)
next_states[:, [2]] = cur_states[:, [2]] + 1 / (size_array + 1) * (day_avg_fee - cur_states[:, [2]]) * (day_avg_fee > 0.0).astype(np.float32)
self.cur_day_total_order_num = np.sum(day_order_num)
day_coupon_used_num = np.min(np.concatenate([day_order_num, coupon_num * np.ones(day_order_num.shape)], -1), -1, keepdims=True)
cost_array = (1 - discount) * day_coupon_used_num * day_avg_fee
gmv_array = day_avg_fee * day_order_num - cost_array
self.cur_day_roi = np.sum(gmv_array) / max(np.sum(cost_array), 1)
return next_states
def get_action_from_policy(self, user_states: Optional[List[np.ndarray]]=None):
# 獲取所有用戶狀態降維后得到的神經網路的輸入
obs = self._states_to_obs(user_states)
# 通過我們訓練的模型得到我們的優惠券動作
action, _ = self.policy_model.predict(obs, deterministic=False)
action = action.astype(np.float32)
action[1] = 0.95 - 0.05 * action[1]
return action
賽題本身的內容和baseline提交方式講解完畢,后面我會講解詳細的訓練程序,以及嘗試更好的方案,敬請期待!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401526.html
標籤:AI
上一篇:Linux系統配置(檔案管理)