一、演算法原理
(1)基本演算法
決策樹(Decision Tree),基于“樹”結構進行決策:
每個內部結點對應一個屬性測驗;
每個分支對應屬性測驗的一種可能取值;
每個葉結點對應一個決策結果,
學習程序:通過對訓練樣本的分析來確定“劃分屬性”(即內部結點所對應的屬性),
預測程序:將測驗示例從根結點開始,沿著劃分屬性所構成的“判定測驗序列”下行,直到葉結點,
策略:分而治之(Divide-and-Conquer)
自根至葉遞回;
在每個內部結點尋找一個劃分(或測驗)屬性,
遞回停止條件:
當前結點包含的樣本全屬于同一類別,無需劃分;
當前屬性集為空, 或是所有樣本在所有屬性上取值相同,無法劃分;
當前結點包含的樣本集合為空,不能劃分,

(2)劃分
①資訊增益
資訊熵(Entropy):度量樣本集合“純度”最常用的一種指標,
假定當前樣本集合D中第k類樣本(k=1, 2, …, |y|)所占的比例為![]() ,則D的資訊熵定義為:
,則D的資訊熵定義為:
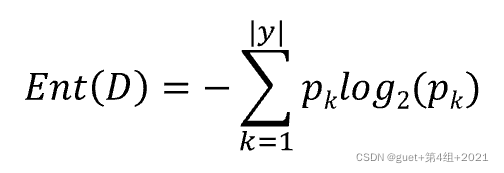
Ent(D)的值越小,則D的純度越高:
Ent(D)的最小值:0,此時D中只有一類;
最大值![]() ,此時D中每個樣本都是一類,
,此時D中每個樣本都是一類,
資訊增益(Information Gain):劃分帶來純度的提升,資訊熵的下降,
離散屬性a的取值:![]()
![]() :D中在a上取值等于
:D中在a上取值等于![]() 的樣本集合
的樣本集合
以屬性a對資料集D進行劃分所獲得的資訊增益為:
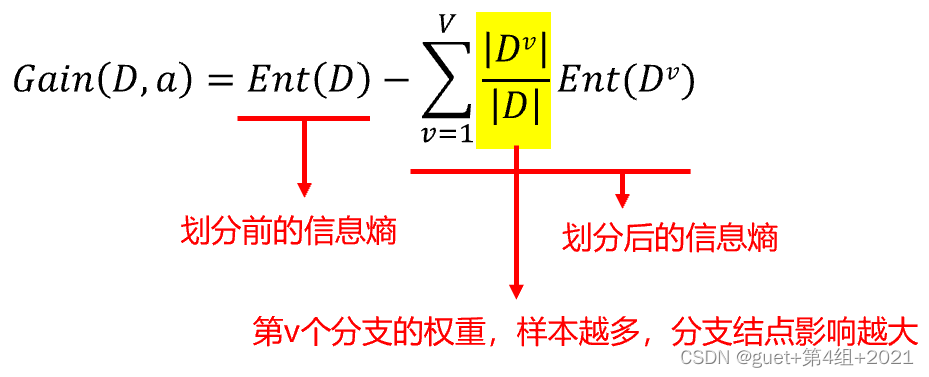
資訊增益越大,意味著使用屬性a來進行劃分所獲得的“純度提升”越大,
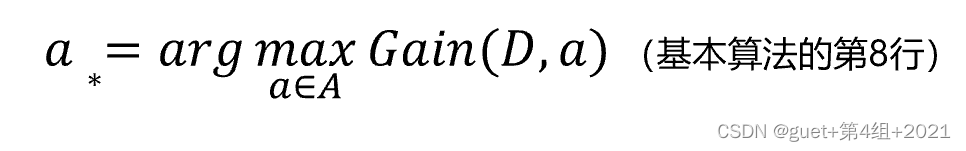
ID3決策樹演算法:在候選屬性集合中選取資訊增益最高的屬性,
舉例:西瓜資料集(后面以該資料集為例)
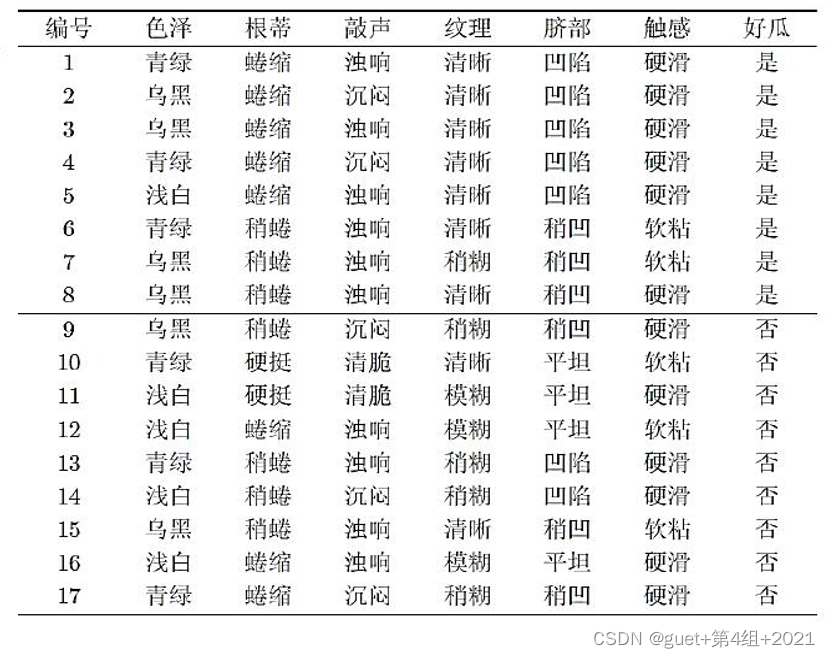
計算根結點的資訊熵Ent(D):
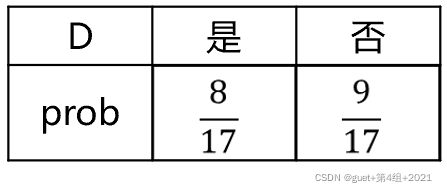
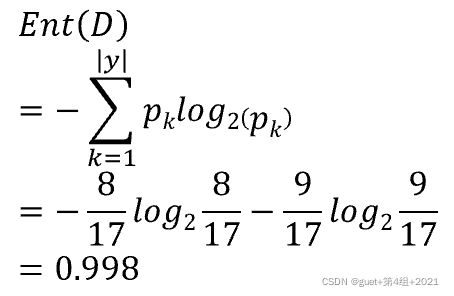
當前屬性集合A={色澤,根蒂,敲聲,紋理,臍部,觸感}
以屬性“色澤”為例,其對應的3個資料子集為:
![]() (色澤=青綠),
(色澤=青綠),![]() (色澤=烏黑),
(色澤=烏黑),![]() (色澤=淺白)
(色澤=淺白)
以子集![]() 為例,其包含6個樣例,{1,4,6,10,13,17},占總樣例數的6/17,其中正例占
為例,其包含6個樣例,{1,4,6,10,13,17},占總樣例數的6/17,其中正例占![]() 樣例數p1=3/6,反例占D1樣例數p2=3/6 ,因此
樣例數p1=3/6,反例占D1樣例數p2=3/6 ,因此
![]()
同理,
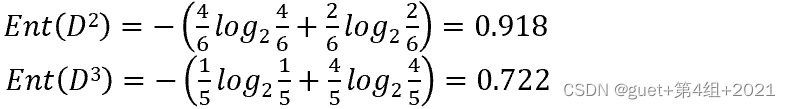
屬性“色澤”的資訊增益為:
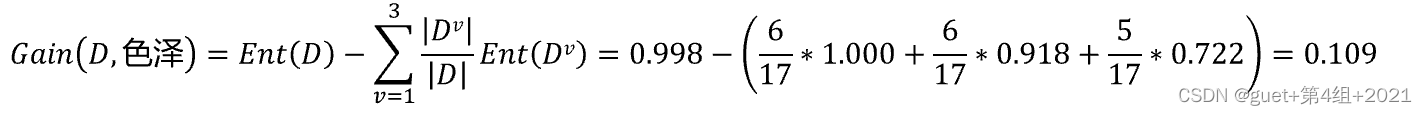
全部屬性的資訊增益為:

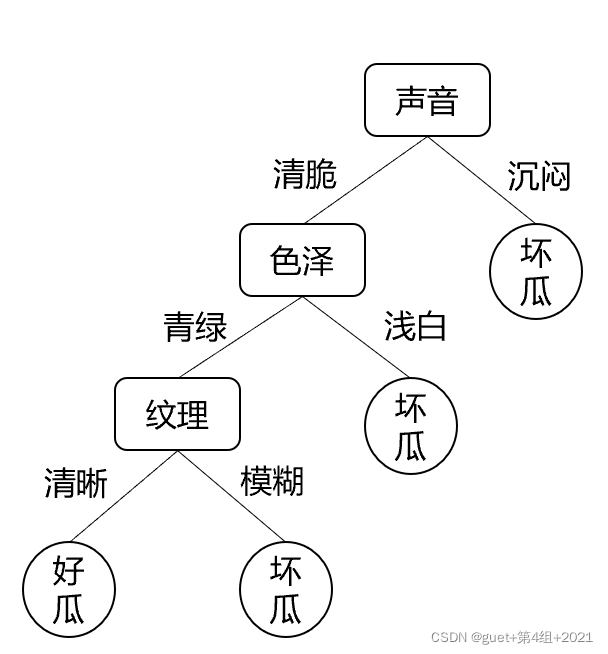
屬性“紋理”的資訊增益最大,被選為劃分屬性
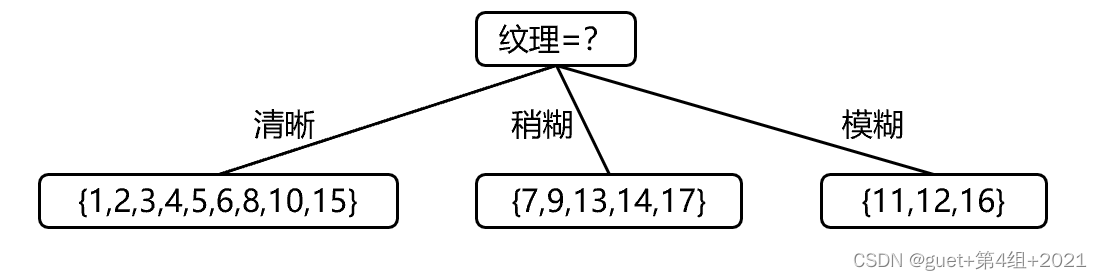
對每個分支結點根據資訊增益準則做進一步劃分,得到決策樹:

資訊增益準則對可取值數目較多的屬性有所偏好,
②增益率
增益率(Gain Ratio):
![]()
屬性a的固有值(Intrinsic Value):
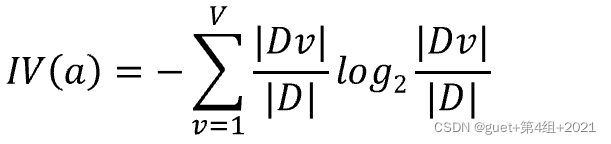
屬性a的可能取值數目越多,即 V 越大,則IV(a)的值通常就越大,
增益率準則對可取值數目較少的屬性有所偏好,
C4.5決策樹演算法:從候選屬性集合中找出資訊增益高于平均水平的,再從中選取增益率最高的,
③基尼指數
基尼值(Gini):度量資料集D的純度
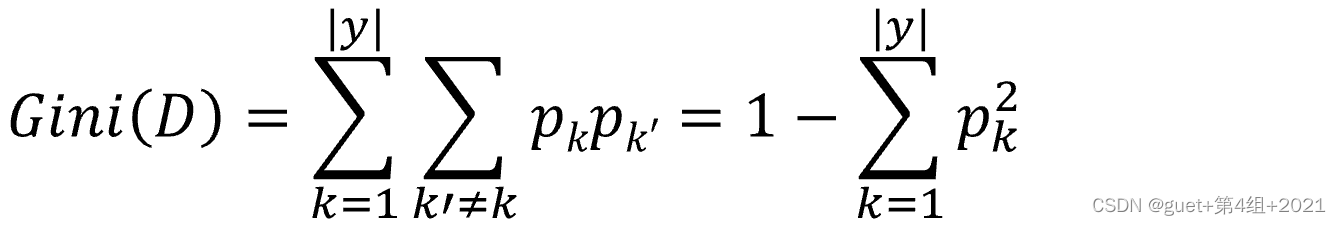
反映了從D中隨機抽取兩個樣例,其類別標記不一致的概率,
Gini(D)越小,資料集D的純度越高,
屬性a的基尼指數(Gini Index):
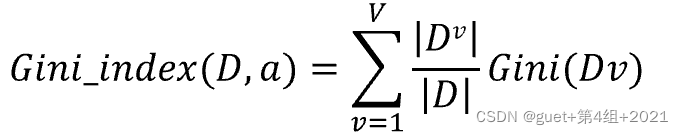
CART決策樹演算法:在候選屬性集合中選取使劃分后基尼指數最小的屬性,
![]()
總結

(3)剪枝
為了盡可能正確分類訓練樣本,有可能造成分支過多,從而導致過擬合,
剪枝(Pruning):是決策樹預防過擬合的主要手段,可通過主動去掉一些分支來降低過擬合的風險,
劃分:劃分選擇對決策樹的尺寸有較大影響,但對泛化性能的影響很有限,
剪枝:剪枝方法和程度對決策樹泛化性能的影響更為顯著,
剪枝的兩種策略:
預剪枝(Pre-pruning):提前終止某些分支的生長(自上而下),
后剪枝(Post-pruning):生成一棵完全樹,再回頭剪枝(自下而上),
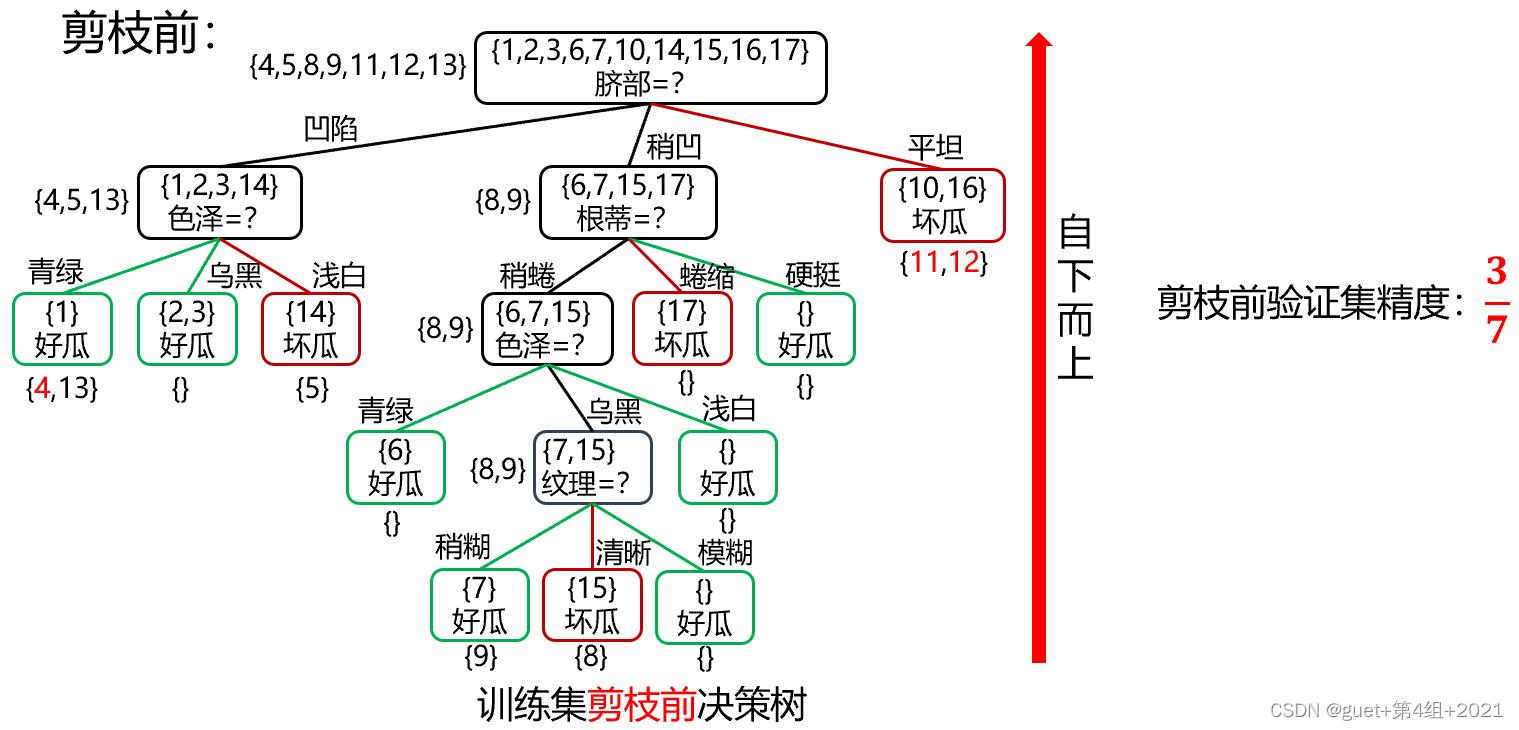
舉例:
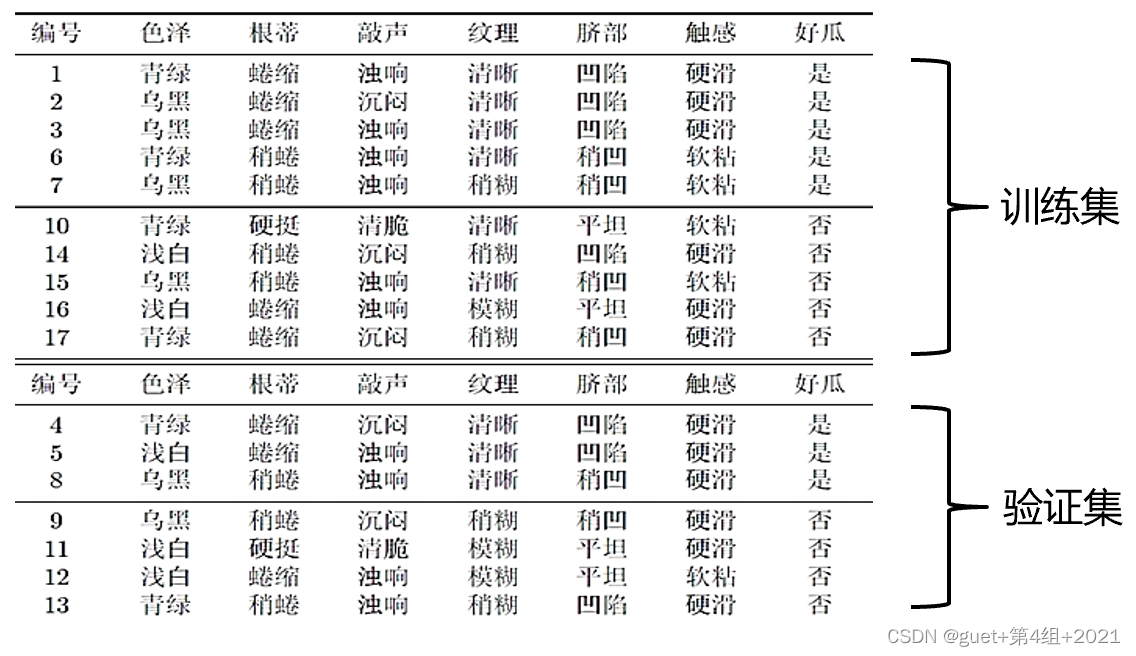
根據資訊增益準則將訓練集生成未剪枝決策樹:
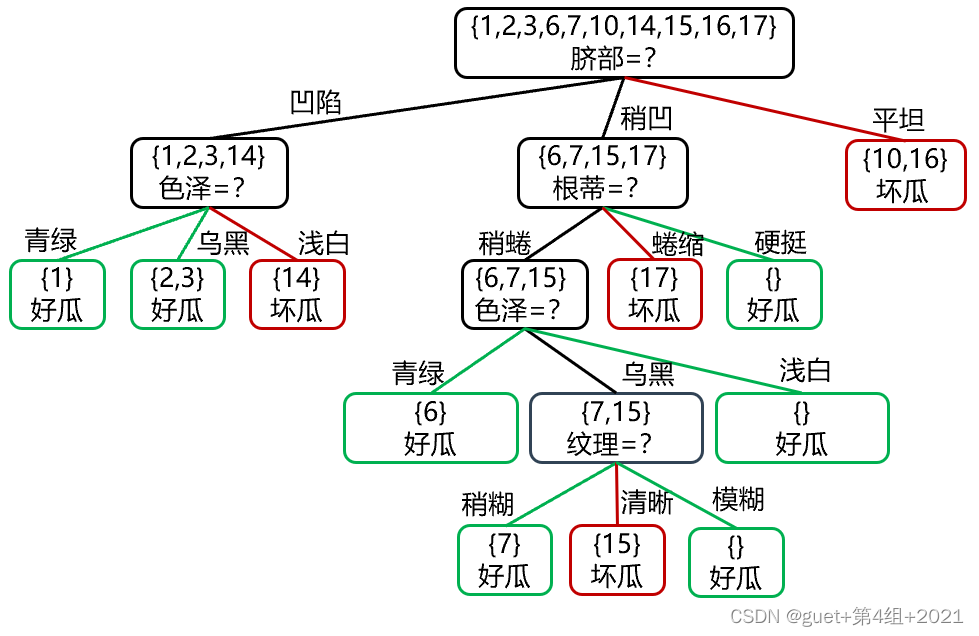
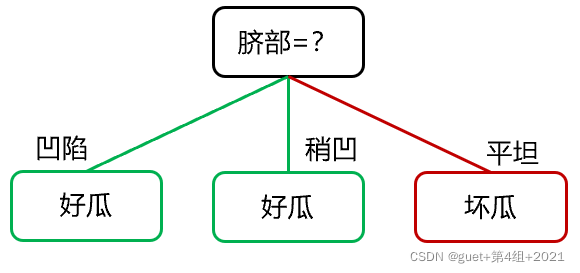
①預剪枝

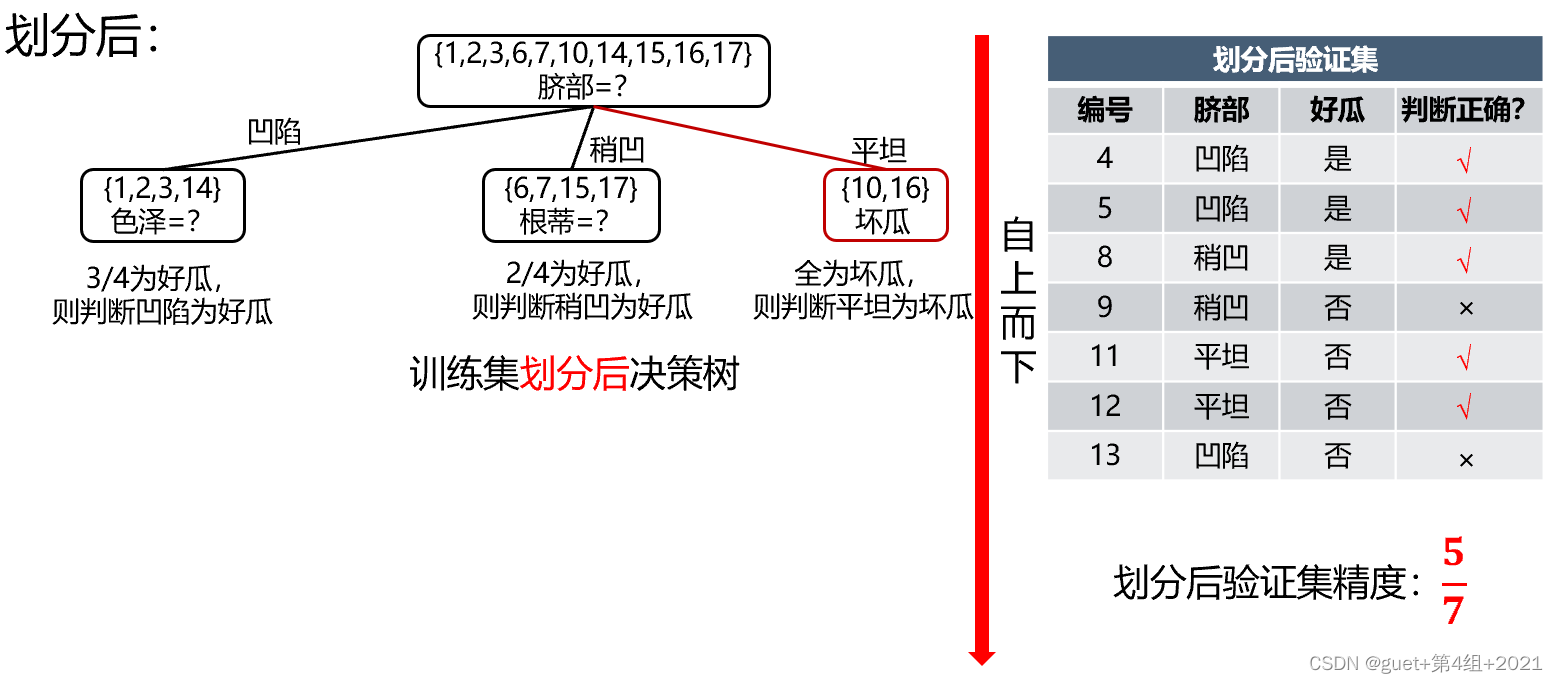
預剪枝決策判斷:
劃分前驗證集精度:3/7 > 劃分后驗證集精度:5/7
劃分后精度提高,保留劃分;
精度降低或不變,禁止劃分,
②后剪枝
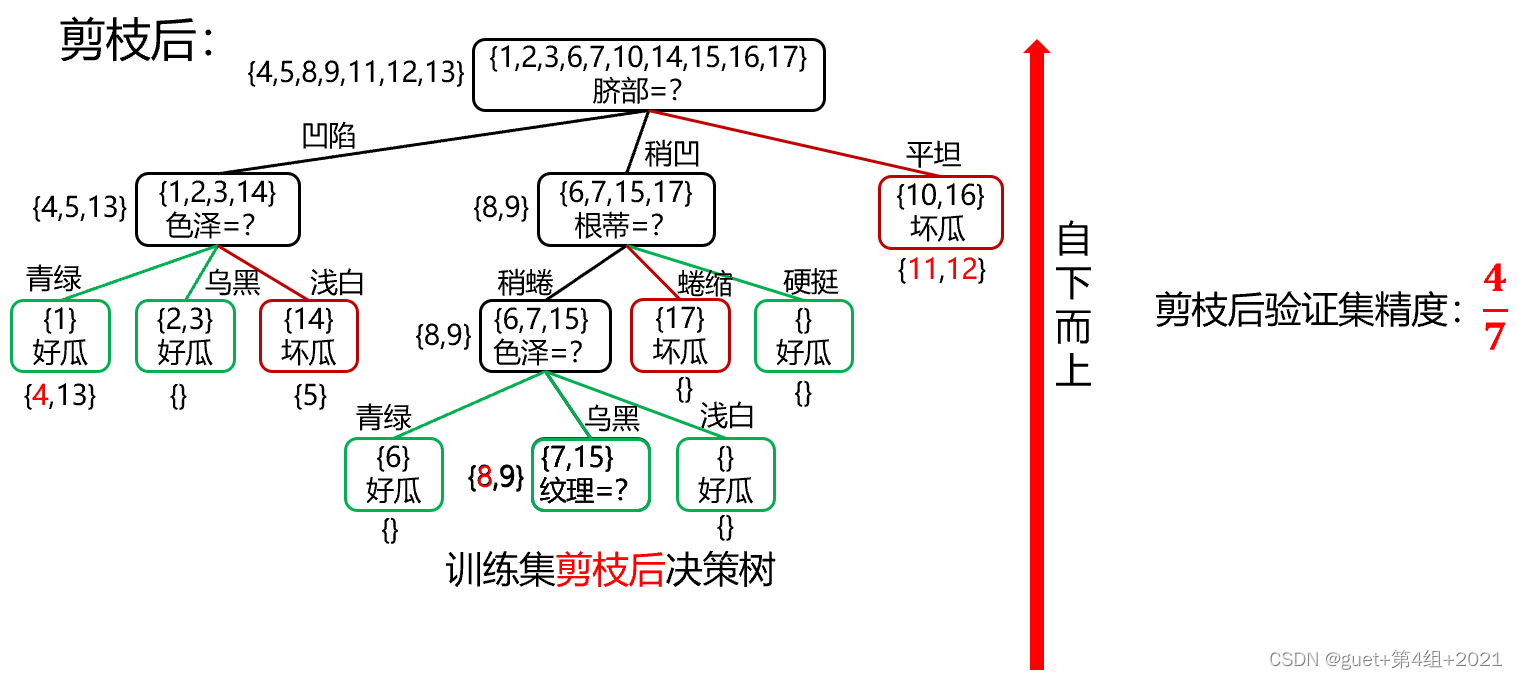
后剪枝決策判斷:
剪枝前驗證集精度:3/7 < 剪枝后驗證集精度:4/7
剪枝后精度提高,進行剪枝;
精度降低或不變,不剪枝,
(奧卡姆剃刀準則(Occam’s Razor):如無必要,勿增物體,Entities should not be multiplied unnecessarily.)
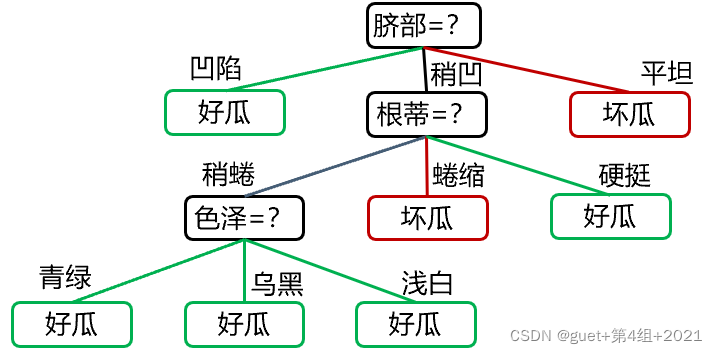
總結

二、演算法實驗
(1)任務
泰坦尼克乘客生存預測,
(2)步驟
①問題描述
泰坦尼克海難是著名的十大災難之一,究竟多少人遇難,各方統計的結果不一,
資料集:
train.csv:訓練資料集,包含特征資訊和存活與否的標簽,
test.csv:測驗資料集,只包含特征資訊,
訓練集欄位:
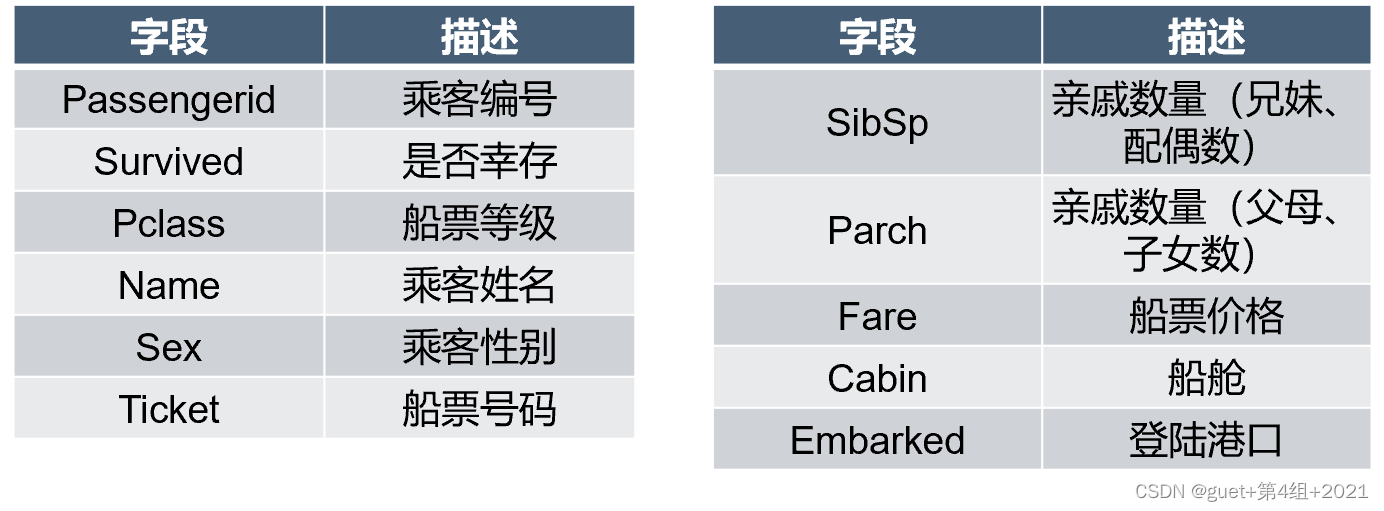
②準備程序
- 資料探索:
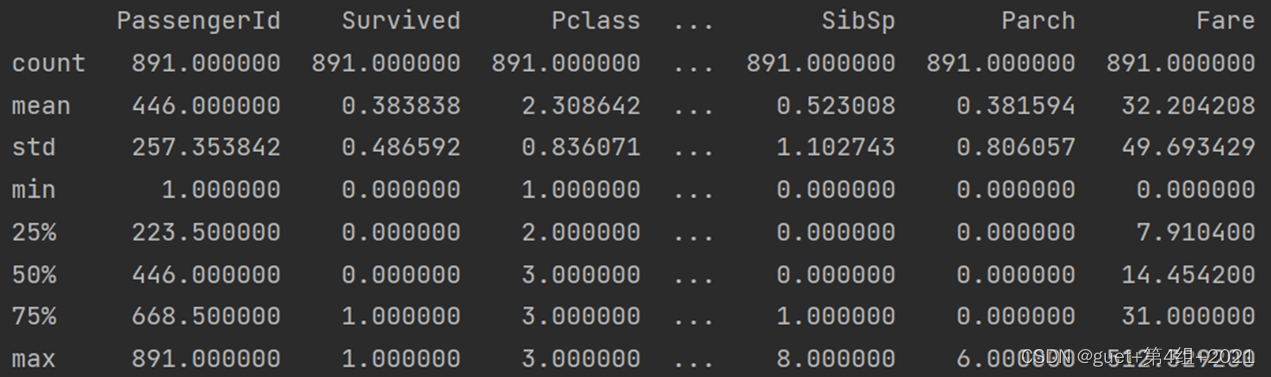
1、了解資料表的基本情況:行數、列數、每列的資料型別、資料完整度,
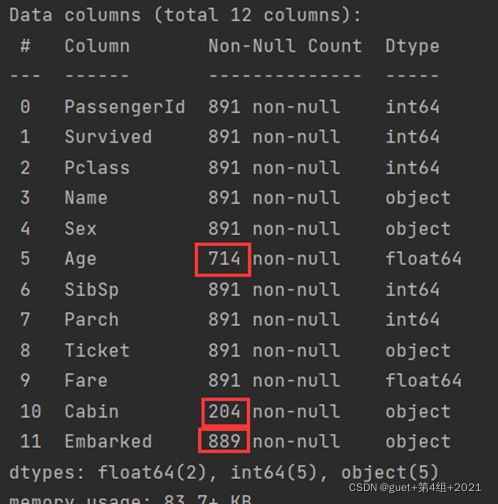
2、了解資料表的統計情況:總數、平均值、標準差、最小值、最大值等,
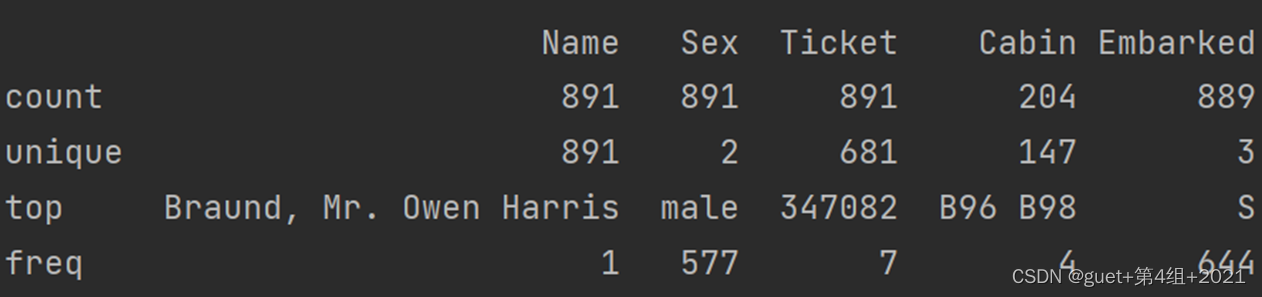
3、查看字串型別(非數字)的整體情況,
- 資料清洗:
1、Age、Embarked和 Cabin 這三個欄位的資料有所缺失,
2、Age 為年齡欄位,是數值型,通過平均值進行補齊,
3、Cabin 為船艙,有大量的缺失值,無法補齊,
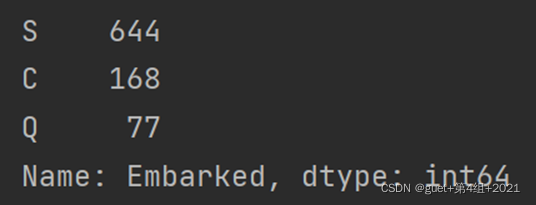
4、Embarked 為登陸港口,有少量的缺失值,將其余缺失的 Embarked 數值均設定為 S(一共3個登陸港口,S港人數最多),
- 特征選擇
1、PassengerId、Name對分類沒有作用,放棄,
2、Cabin 欄位缺失值太多,放棄,
3、Ticket 欄位為船票號碼,雜亂無章且無規律,放棄,
4、其余的欄位包括:Pclass、Sex、Age、SibSp、Parch 和 Fare,可能會與乘客的生存預測分類有關系,
5、將特征值中為字串的轉成數值型別,如:sex用0,1表示,
![]()
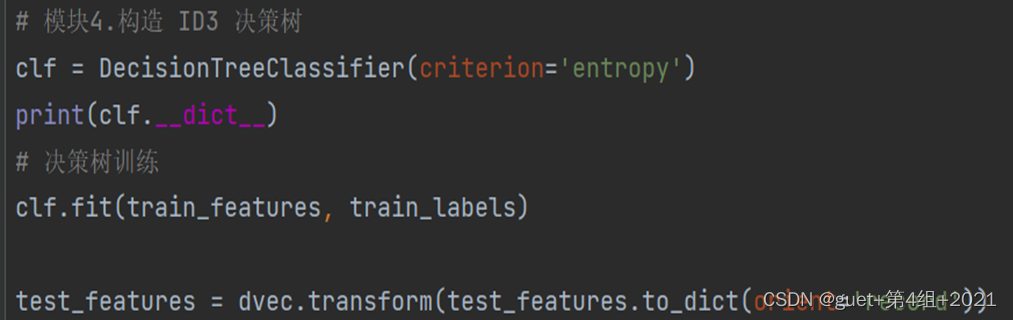
- 生成決策樹
1、使用sklearn生成決策樹模型并訓練,
2、criterion=‘entropy’意為基于資訊熵標準建立決策樹,
③模型預測及評估
- 決策樹模型
1、由于沒有測驗集的實際結果,因此無法用測驗集的預測結果與實際結果相對比,
2、使用K折交叉驗證的方式,用大部分樣本進行訓練,少量的用于分類器的驗證,
3、運行結果:
![]()
- 總結
1、特征選擇是分類模型好壞的關鍵,選擇什么樣的特征,以及對應的特征值矩陣,決定了分類模型的好壞,通常情況下,特征值不都是數值型別,可以使用 DictVectorizer 類進行轉化,
2、模型準確率需要考慮是否有測驗集的實際結果可以做對比,當測驗集沒有真實結果可以對比時,需要使用 K 折交叉驗證,
- 代碼地址
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401532.html
標籤:AI
上一篇:蒙特卡羅法(Python實作)
下一篇:機器學習期末考試復習