SeAFusion:首個結合高級視覺任務的影像融合框架
論文:https://doi.org/10.1016/j.inffus.2021.12.004
代碼:https://github.com/Linfeng-Tang/SeAFusion
寫在前面
最近Information Fusion 接收了一篇題為《Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network》的文章,在此之前,影像融合領域一直徘徊在魔改網路,設計loss,引入新的范式等,但是卻似乎忘記了一個一直被強調,但一直未被重視的點,即影像融合如何才能有效地促進高級視覺任務的性能提升?
接觸影像融合已經兩年左右了,從一個有一定研究基礎的角度來學習這篇文章,可以發現文章的并沒有在網路架構或者學習范式上進行很大的創新,但是卻以一種新的視角來審視影像融合任務, 即利用高級視覺任務來驅動影像融合,
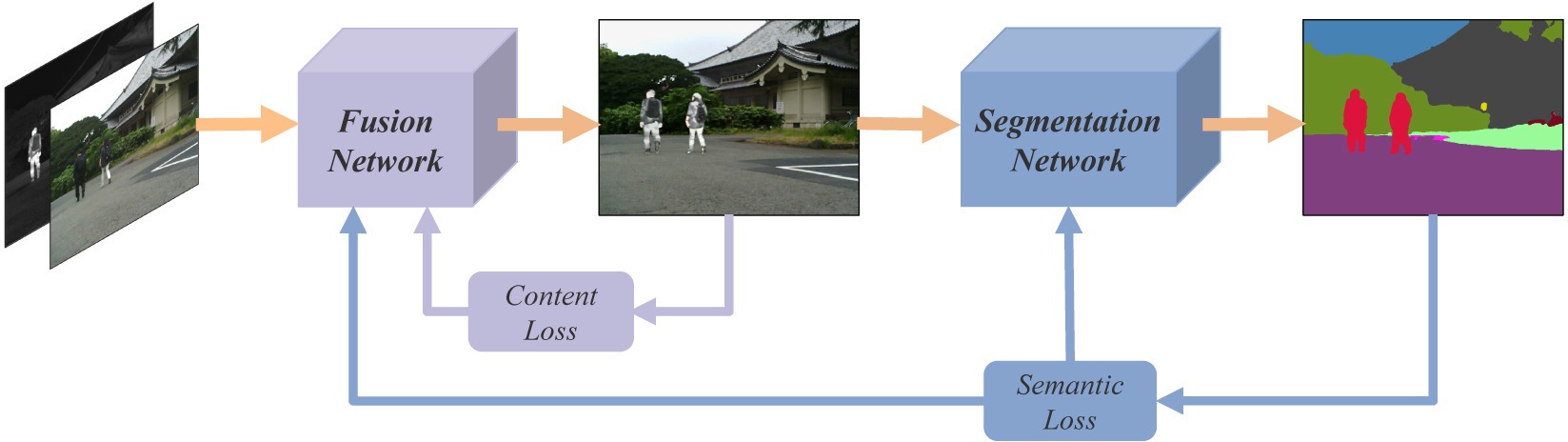
源影像經過融合網路生成融合影像,而融合網路影像在經過一個分割網路得到分割結果,分割結果與labels構造語意損失,融合影像與源影像之前構造內容損失,其中語意損失只用于約束分割網路,而內容損失與語意損失共同約束融合網路的優化,這樣語意損失能夠將高級視覺任務(分割)所需的語意資訊反傳回融合網路從而促使融合網路能夠有效地保留源影像中的語意資訊,
再回顧一下SeAFusion的highlights:
- We bridge the gap between IR/VIS image fusion and high-level vision tasks.
- We propose a semantic-aware IR/VIS image fusion network, termed SeAFusion.
- We devise GRDB to boost the description ability for fine-grained detail.
- SeAFusion is a light-weight model that can achieve real-time image fusion.
- We evaluate various fusion methods from the perspective of high-level tasks.
以及其Contribution:
- We devise a novel semantic-aware infrared and visible image fusion framework, which effectively achieves superior performance in both image fusion and high-level vision tasks.
- A gradient residual dense block is designed to boost the description ability of the network for fine-grained detail and achieve feature reuse.
- The proposed SeAFusion is a light-weight model that can achieve real-time image fusion. This allows it to be deployed as a pre-processing module for high-level vision tasks.
- We propose a task-driven evaluation manner that evaluates the performance of image fusion from the perspective of high-level vision tasks.
總之,該方法首次提出考慮高級視覺任務與影像融合之前的鴻溝,并提出了一個語意感知的影像融合框架,同時考慮到作為一個預處理的操作對實時性的要求,在網路設計方面設計了一個輕量級的網路,而且為了增強網路對細粒度細節特征的描述,設計了一個Gradient Residual Dense Block(GRDB),最后,考慮到現有的評估指標僅利用EN,MI,SF等統計指標來衡量影像融合的好壞,作者還提出了一種任務驅動的評估方式,即利用融合結果在高級視覺任務上的表現來衡量融合結果的質量,
方法設計
接下來進一步聚焦到SeAFusion的方法設計,
網路架構
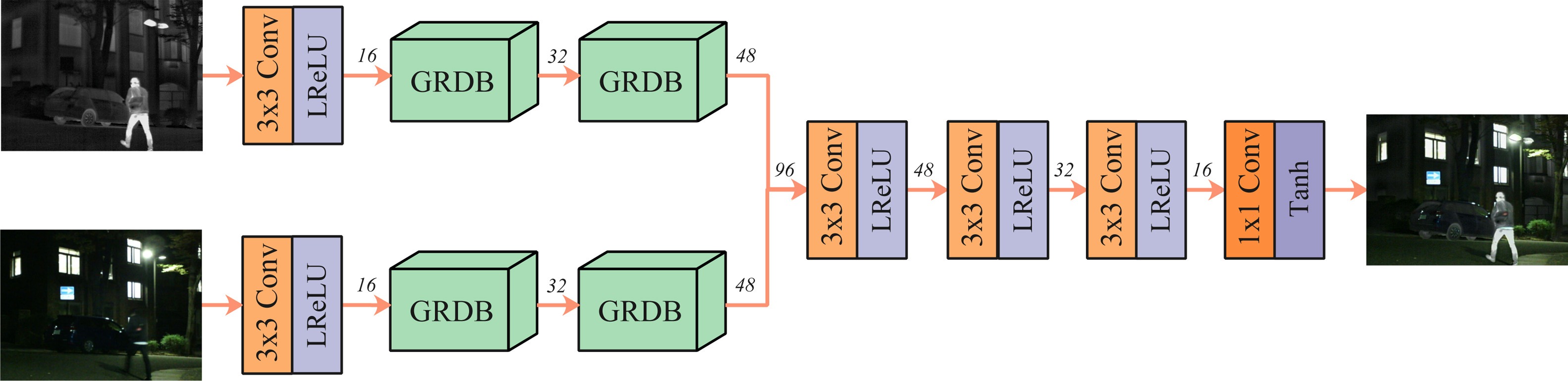
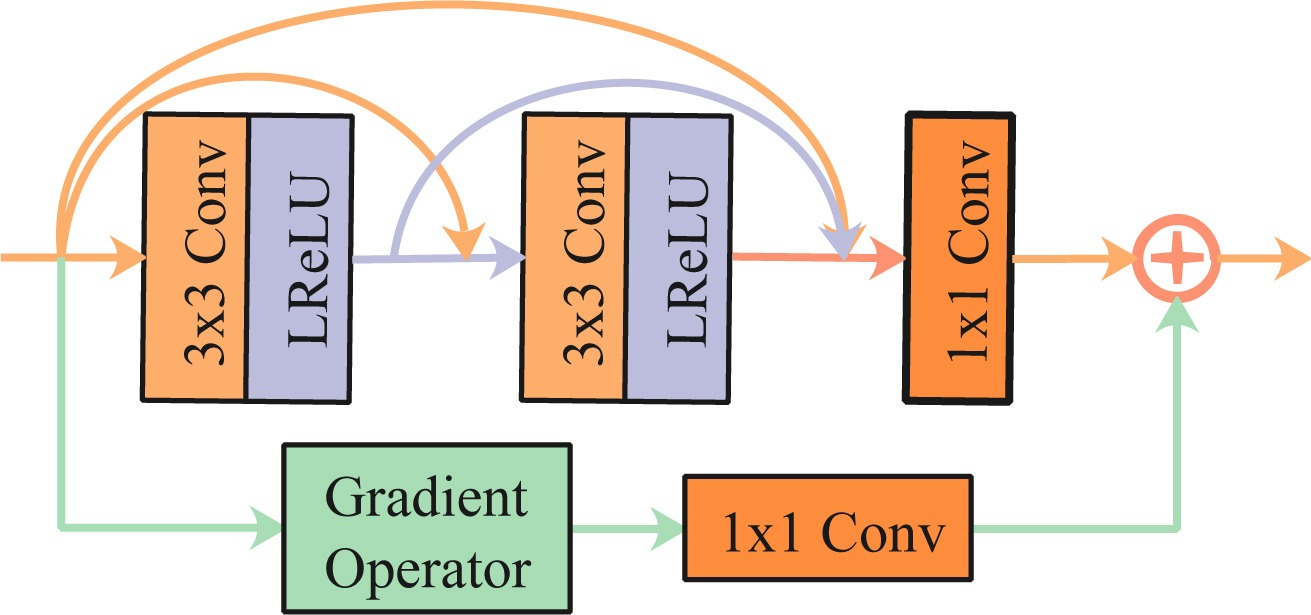
在整體框架設計方面SeAFusion采用的是比較經典的雙分支特征提取再Concat融合后 重建影像這樣的框架,而在GRDB中利用梯度算子提取的特征作為殘差連接能夠強化網路對于細節特征的提取,
損失函式
在loss設計方面,首先是傳統的內容損失設計,主要包括強度損失和紋理損失,強度損失用于約束融合結果的整體表觀強度,而紋理損失則約束融合影像盡可能多的包含紋理細節資訊,
內容損失:
L
c
o
n
t
e
n
t
=
L
i
n
t
+
α
L
t
e
x
t
u
r
e
\mathcal{L}_{content} = \mathcal{L}_{int} + \alpha \mathcal{L}_{texture}
Lcontent?=Lint?+αLtexture?
強度損失:
L
i
n
t
=
1
H
W
∥
I
f
?
max
?
(
I
i
r
,
I
v
i
)
∥
1
\mathcal{L}_{int} = \frac{1}{HW}\left\|I_f - \max(I_{ir}, I_{vi})\right\|_1
Lint?=HW1?∥If??max(Iir?,Ivi?)∥1?
紋理損失:
L
t
e
x
t
u
r
e
=
1
H
W
∥
∣
?
I
f
∣
?
max
?
(
∣
?
I
i
r
∣
,
∣
?
I
v
i
∣
)
∥
1
\mathcal{L}_{texture} = \frac{1}{HW}\left\| |\nabla I_f| - \max(|\nabla I_{ir}|, |\nabla I_{vi }|)\right\|_1
Ltexture?=HW1?∥∣?If?∣?max(∣?Iir?∣,∣?Ivi?∣)∥1?
更多關于內容損失的描述可以參見原文,
除了內容損失,語意損失是SeAFusion的重要創新之一,值得一提的是作者采用了一個現有的語意分割框架來構造語意損失,因此其語意損失的構造與所采用的分割網路息息相關,關于其采用的分割網路,請參閱SeAFusion以及分割網路原文,
主語意損失:
L
m
a
i
n
=
?
1
H
×
W
∑
h
=
1
H
∑
w
=
1
W
∑
c
=
1
C
L
s
o
(
h
,
w
,
c
)
log
?
(
I
s
(
h
,
w
,
c
)
)
\mathcal{L}_{main} = \frac{-1}{H \times W} \sum_{h = 1}^{H}\sum_{w = 1}^{W} \sum_{c = 1}^{C} L_{so}^{(h, w, c)}\log(I_s^{(h, w, c)})
Lmain?=H×W?1?h=1∑H?w=1∑W?c=1∑C?Lso(h,w,c)?log(Is(h,w,c)?)
輔語意損失:
L
a
u
x
=
?
1
H
×
W
∑
h
=
1
H
∑
w
=
1
W
∑
c
=
1
C
L
s
o
(
h
,
w
,
c
)
log
?
(
I
s
a
(
h
,
w
,
c
)
)
\mathcal{L}_{aux} = \frac{-1}{H \times W} \sum_{h = 1}^{H}\sum_{w = 1}^{W} \sum_{c = 1}^{C} L_{so}^{(h, w, c)}\log(I_{sa}^{(h, w, c)})
Laux?=H×W?1?h=1∑H?w=1∑W?c=1∑C?Lso(h,w,c)?log(Isa(h,w,c)?)
語意損失:
L
s
e
m
a
n
t
i
c
=
L
m
a
i
n
+
λ
L
a
u
x
\mathcal{L}_{semantic} =\mathcal{L}_{main} + \lambda \mathcal{L}_{aux}
Lsemantic?=Lmain?+λLaux?
最終用于約束融合網路的loss表達如下:
L
j
o
i
n
t
=
L
c
o
n
t
e
n
t
+
β
L
s
e
m
a
n
t
i
c
\mathcal{L}_{joint} =\mathcal{L}_{content} + \beta \mathcal{L}_{semantic}
Ljoint?=Lcontent?+βLsemantic?
訓練策略
由于影像融合的特殊性,無法利用融合結果預訓練一個分割模型來指導融合網路的訓練,為此作者借鑒生成對抗網路的訓練方式提出了Joint low-level and high-level adaptive training strategy,該訓練策略能夠有效地維持low-level任務(影像融合)以及high-level視覺任務(語意分割)之間的性能平衡,即在保證高級視覺任務性能的同時不降低融合網路的性能,

簡而言之,通過交替訓練融合網路以及分割網路,從而維持影像融合以及語意分割之間的性能,而避免像訓練GAN時出現的模式坍塌(Model Collapse),
實驗驗證
在實驗設計方面,作者首先在MFNet,RoadScene,TNO資料集上進行了定量和定性的對比實驗,然后給出了任務驅動的評估結果,以及不同演算法運行效率的對比分析和相關的消融實驗,
定量&定性實驗
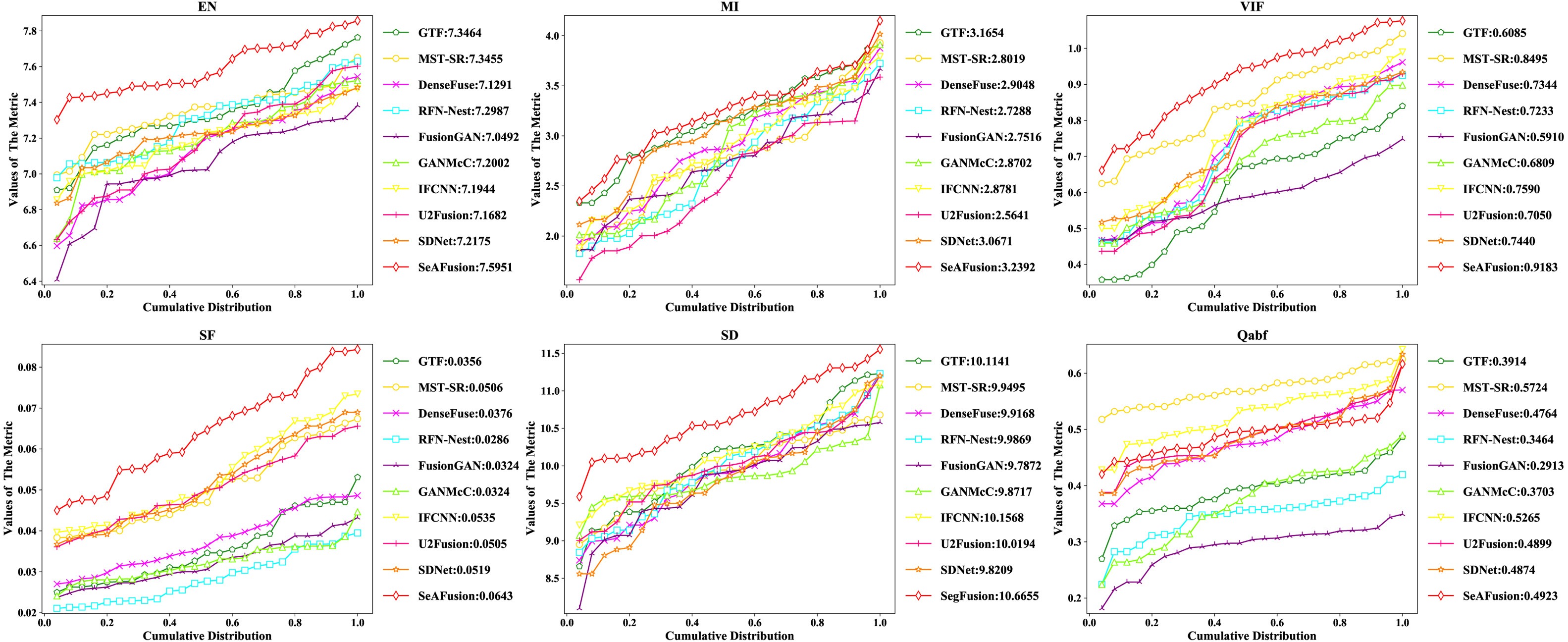
MFNet資料集


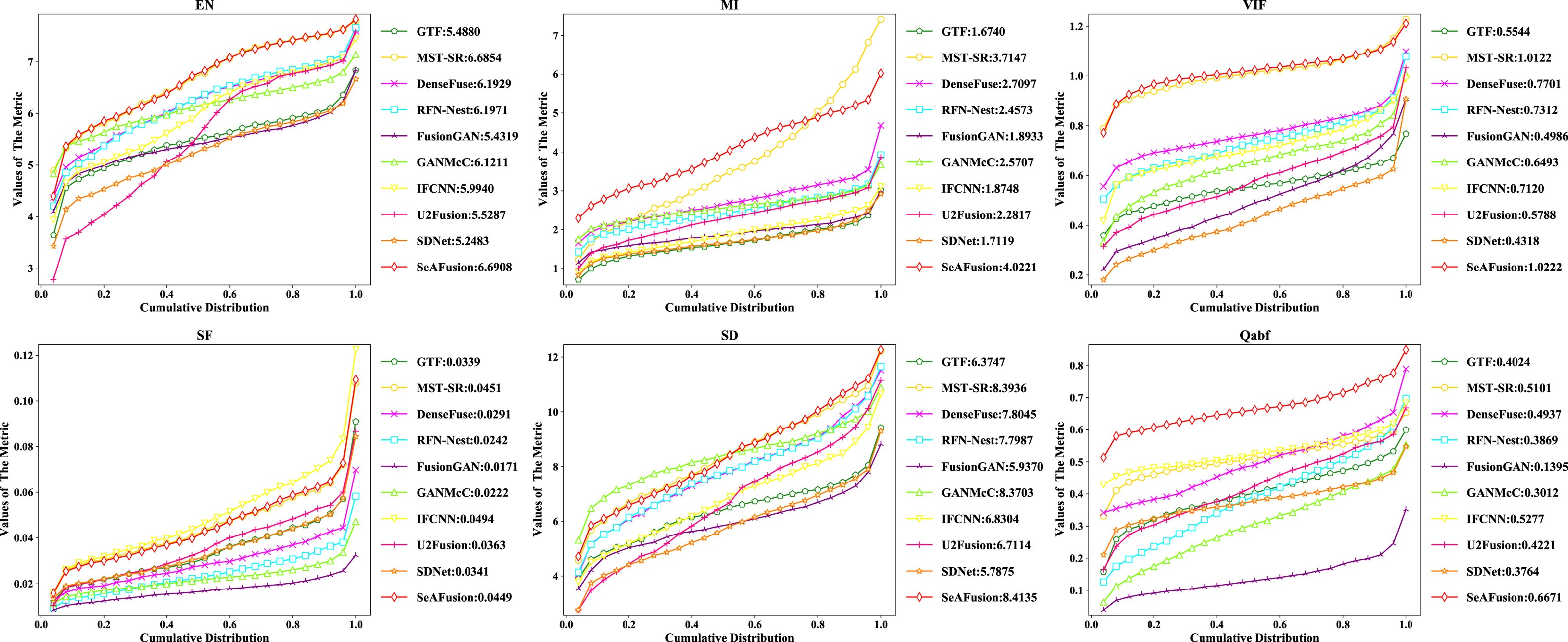
RoadScene資料集


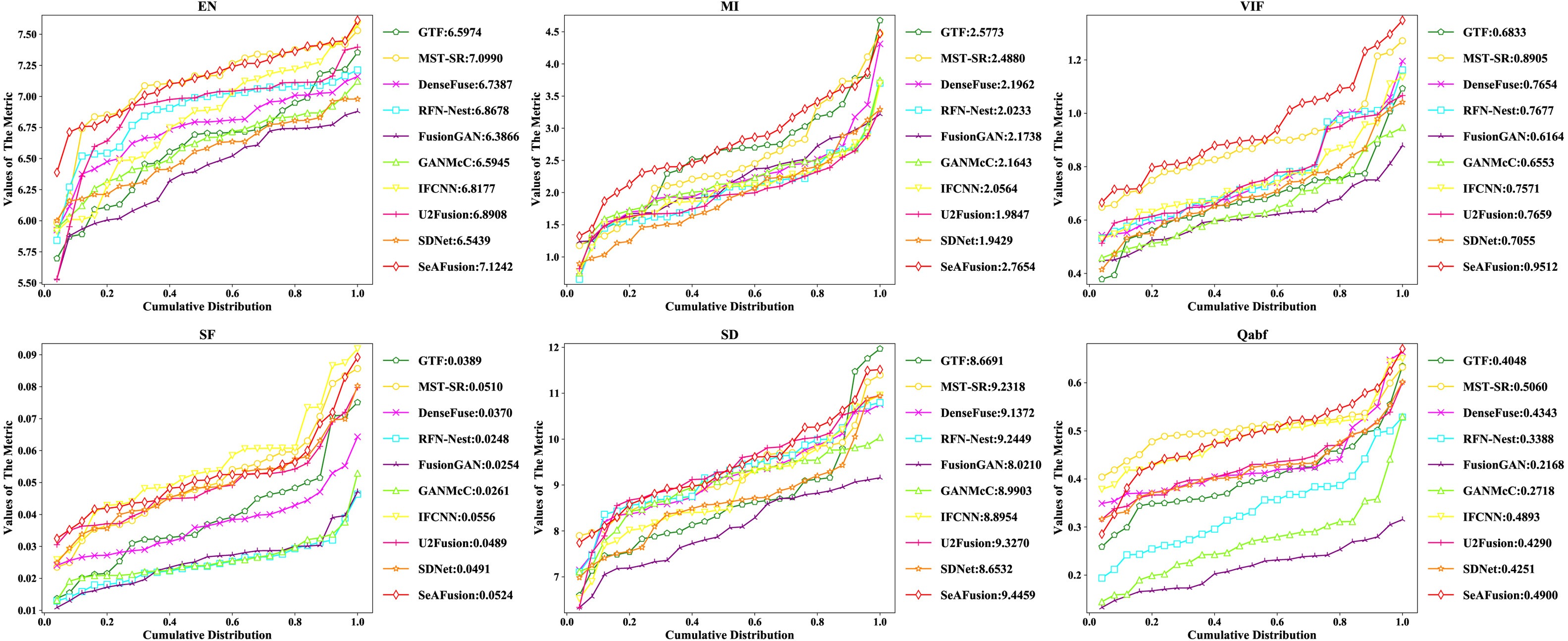
TNO資料集

任務驅動評估
語意分割


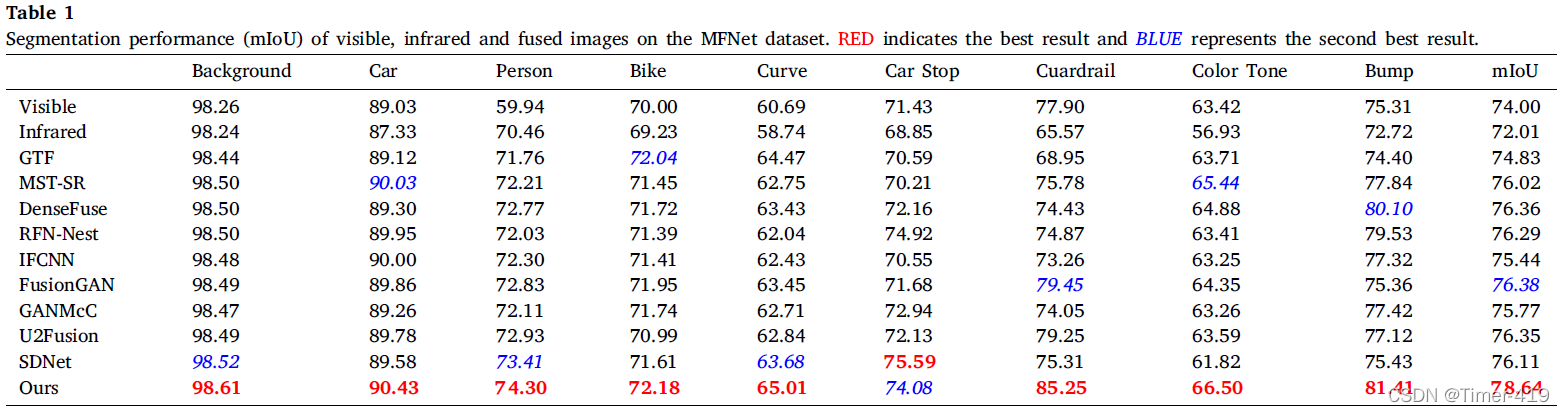
目標檢測


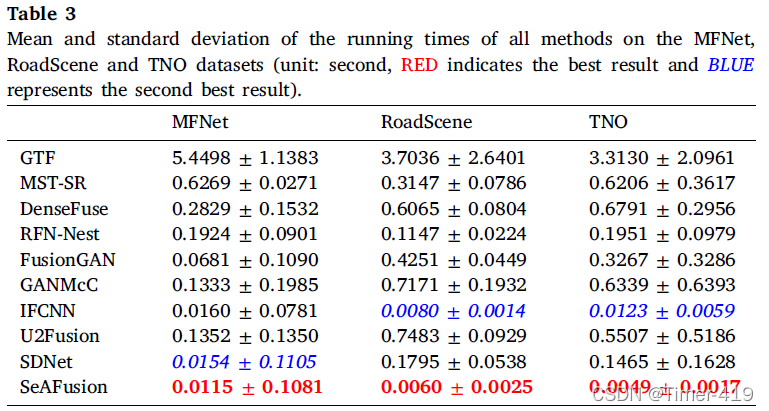
運行效率對比
消融實驗
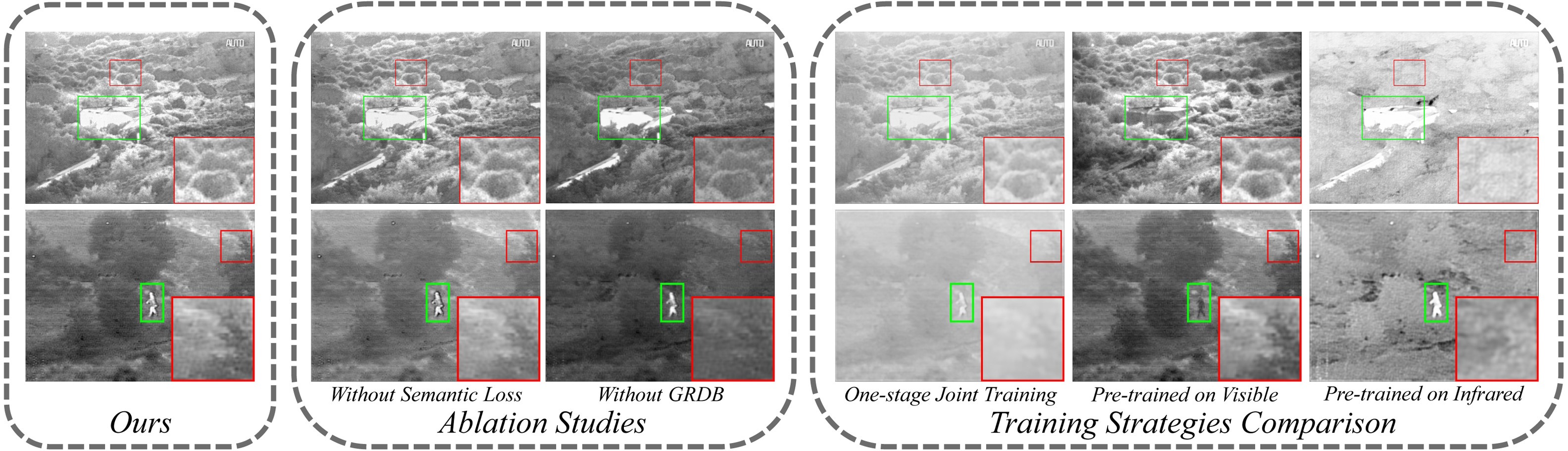
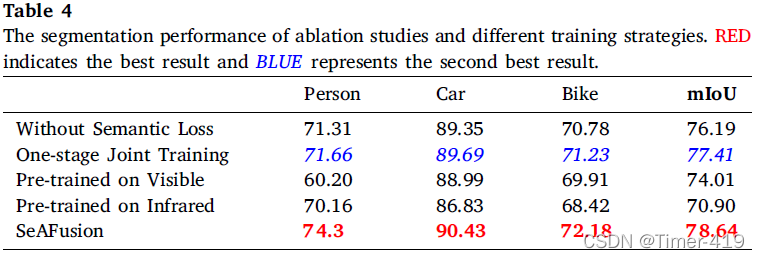
更多的實驗設計以及實驗分析,請參閱SeAFusion 原論文,
結論
在這項研究中,我們提出了一個語意感知的影像融合框架,即SeAFusion,以實作紅外和可見光影像的實時融合,一方面,設計了一個梯度殘差密集塊來提高融合網路對細粒度細節的描述能力,結合精心設計的內容損失,我們的融合網路有效地實作了突出目標強度的維護和紋理細節的保留,另一方面,我們引入了語意損失,以提高融合結果對高層視覺任務的促進作用,更具體地說,語意損失允許高層語意資訊回流到影像融合模塊,這有利于高層視覺任務在融合結果上取得優異的表現,此外,我們提出了一種low-level和high-level的聯合自適應訓練策略,以便在影像融合和各種高層次視覺任務中同時取得優異的表現,充分的比較和泛化實驗證明了我們的SeAFusion在主觀效果和定量指標上都優于state-of-the-arts,此外,豐富的任務驅動評估實驗揭示了我們的框架在促進高層視覺任務方面的天然優勢,此外,在運行效率方面的顯著優勢使我們的演算法可以很容易地作為高級視覺任務的預處理模塊進行部署,
寫在最后
個人感覺SeAFusion的出現很大程度上受益于新發現的資料集即MFNet,其中提供了場景中的語意標簽,而且場景特別豐富(包含1600對左右的場景),這為訓練性能優異的融合網路提供了可能,此外就是其所使用的分割網路也能夠有較強的性能,
在SeAFusion發表之前,關于影像融合的研究一直在魔改網路,設計loss function, 調整學習范式中徘徊,SeAFusion給與了我們新的啟發,即聯系高級視覺任務來研究影像融合,盡管SeAFusion的方法設計還比較簡單,但是這也給了我們更多的優化空間,此外之前感覺大家覺得紅外和可見光影像融合都已經沒啥可做的,主要是TNO資料集的資料集的局限性,導致不同方法都各有各的優勢,但是隨著一些新的資料集的發布,影像融合依舊任重而道遠,
個人感覺紅外和可見光影像融合未來的研究方向可能包括但不限于
- 未配準影像融合
- 高級視覺任務驅動的影像融合
- 跨解析度的影像融合
- 實時影像融合
- 極端條件下的影像融合(過曝或欠曝)
- 全面的評估準則
SeAFusion原論文: Tang, L., Yuan, J., Ma, J., 2022. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Information Fusion URL: https://www.sciencedirect.com/science/article/pii/S1566253521002542, doi:https://doi.org/10.1016/j.inffus.2021.12.004.
MFNet資料集:Ha, Q., Watanabe, K., Karasawa, T., Ushiku, Y., Harada, T., 2017. Mfnet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes, in: Proceedings of the IEEE International Conference on Intelligent Robots and Systems, pp.5108–5115.
分割網路:Peng, C., Tian, T., Chen, C., Guo, X., Ma, J., 2021. Bilateral attention decoder: A lightweight decoder for real-time semantic segmentation. Neural Networks 137, 188–199.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402582.html
標籤:其他
上一篇:影像處理Opencv(六)