1 引言
在深度強化學習-策略梯度演算法推導博文中,采用了兩種方法推導策略梯度演算法,并給出了Reinforce演算法的偽代碼,可能會有小伙伴對策略梯度演算法的形式比較疑惑,本文就帶領大家剖析其中的原理,深入理解策略梯度演算法的公式,本文主要參考了百度飛槳的視頻Policy Gradient演算法有興趣的小伙伴可以看看,我覺得講的非常透徹,
2 手寫數字識別
我們先來看一下手寫數字識別案列,采用LeNet網路,其輸入為一張手寫數字照片,輸出為0-9每個數字對應的概率,LeNet網路結構不是本文介紹的重點,我們主要看損失函式部分,
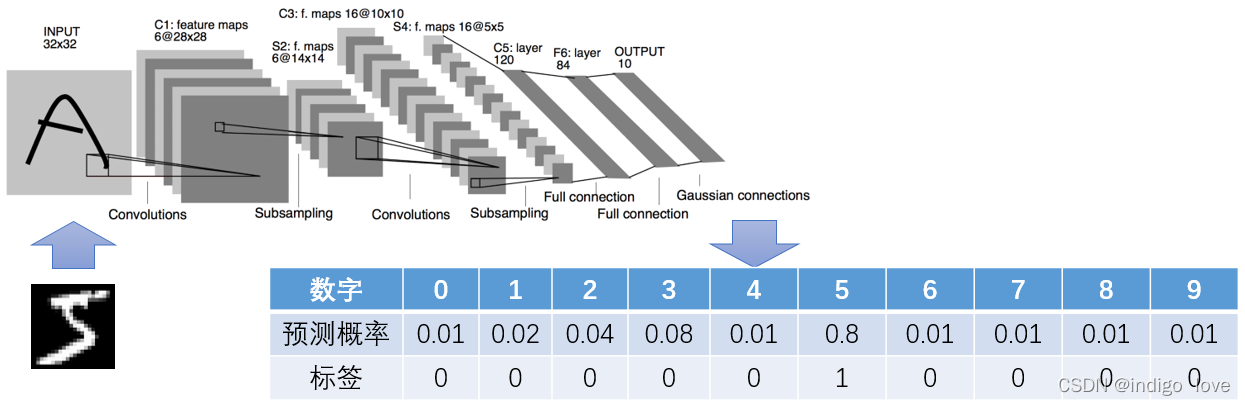
假設網路的輸入為數字5,標簽為one-hot編碼形式,即數字5對應概率值為1,其余為0,網路的輸出如上圖所示,對于分類問題,通常采用交叉熵(Cross Entropy) 損失函式
交叉熵:
和
分別表示兩個不同的分布,交叉熵可以衡量兩個分布的差距,通過最小化交叉熵損失,就可以縮小兩個分布之間的距離,將標簽看作分布
,預測概率看作分布
,根據交叉熵公式,計算上圖中的交叉熵
將其作為損失進行梯度反傳,更新網路引數,從而讓預測概率分布更加接近標簽,
3 策略梯度演算法
看完手寫數字識別案列后,回到策略梯度演算法,單步損失和策略梯度的形式為
單步損失:
策略梯度:
假設智能體的動作空間為離散形式,包括“左、停、右”三個動作,策略網路的輸入為狀態
,輸出為每個動作對應的概率,如下圖所示
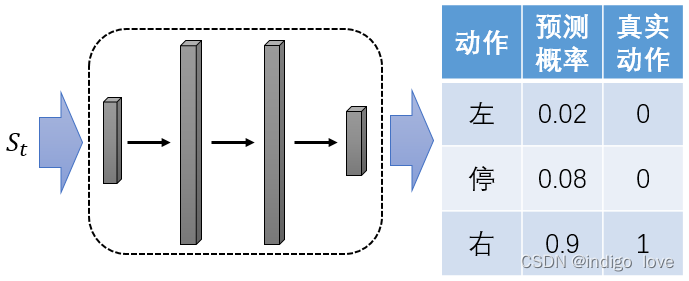
其中預測概率為網路輸出的概率分布,真實動作為智能體真正執行的動作,但是它并一定是一個正確的動作,無法作為標簽,計算預測概率與真實動作之間的交叉熵,得到
發現它與單步損失中的形式一致,由于真實動作不一定是正確的標簽,所以加上累積獎勵
作為權重,
越大,對應的損失越需要重視,反之
越小,對應的損失就不那么重要,
可以認為是一個縮放因子,始終為正數,并不影響梯度的方向,因此可以忽略,綜上,單步損失具體可以表示為
其中表示真實動作,對單步損失求梯度即為策略梯度的蒙特卡洛近似,通過梯度反傳不斷優化策略網路引數,讓網路輸出的概率分布接近累積回報較大的動作,
4 總結
本文利用離散動作模型剖析了策略梯度公式,發現它與分類模型類似,對于連續動作模型也是同樣的道理,利用交叉熵衡量網路預測的概率分布與真實動作的概率分布,并采用累積獎勵加權作為單步損失,對損失求梯度,然后沿著梯度的反方向不斷更新策略網路引數,從而不斷提升策略,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402583.html
標籤:其他
上一篇:SeAFusion:首個結合高級視覺任務的影像融合框架
下一篇:影像卷積的理解