文章目錄
- 前言
- 系列文章
- 矢量化選股回測概述
- 要點1:資料格式
- 要點2:股票池
- 要點3:剔除ST股、停盤股、漲跌停書評
- 要點4: 倉位構建
- 要點5:回測
- 資料準備
- 單因子檢測
- 樣例
前言
本菜狗現在是哈工大威海校區計算機學院的大四本科生,也是量化投資的初學者,因為本科學校中做量化的前輩喝同伴極少,缺少與業界的交流,在很長一段時間,本菜狗一直認為量化就是MACD等技術指標的或者是用一些炫酷的DL模型來預測(因為國內很多量化書籍都是“Python基礎語法+技術指標+機器學習”),
好在沒有放棄嘗試,終于在經過相當一段時間的焦慮和摸索中,開始對量化行業有了比較符合客觀但并不全面的認識,于是開啟量化方法論系列博客的創作,把自己的學習總結、分享出來,以和需要的同伴交流,
因為本人能力和精力有限,所創作的內容難免有瑕疵乃至紕漏,歡迎批評指正,
若您對我所做的作業感興趣,歡迎聯系我:cai_jinhang@foxmail.com
系列文章
本文是量化投資方法論之多因子選股系列文章的第一篇,分享資料準備(基于Tushare)和單因子檢驗模塊,
矢量化選股回測概述
提示:若看不太懂,可結合后面的代碼理解
要點1:資料格式
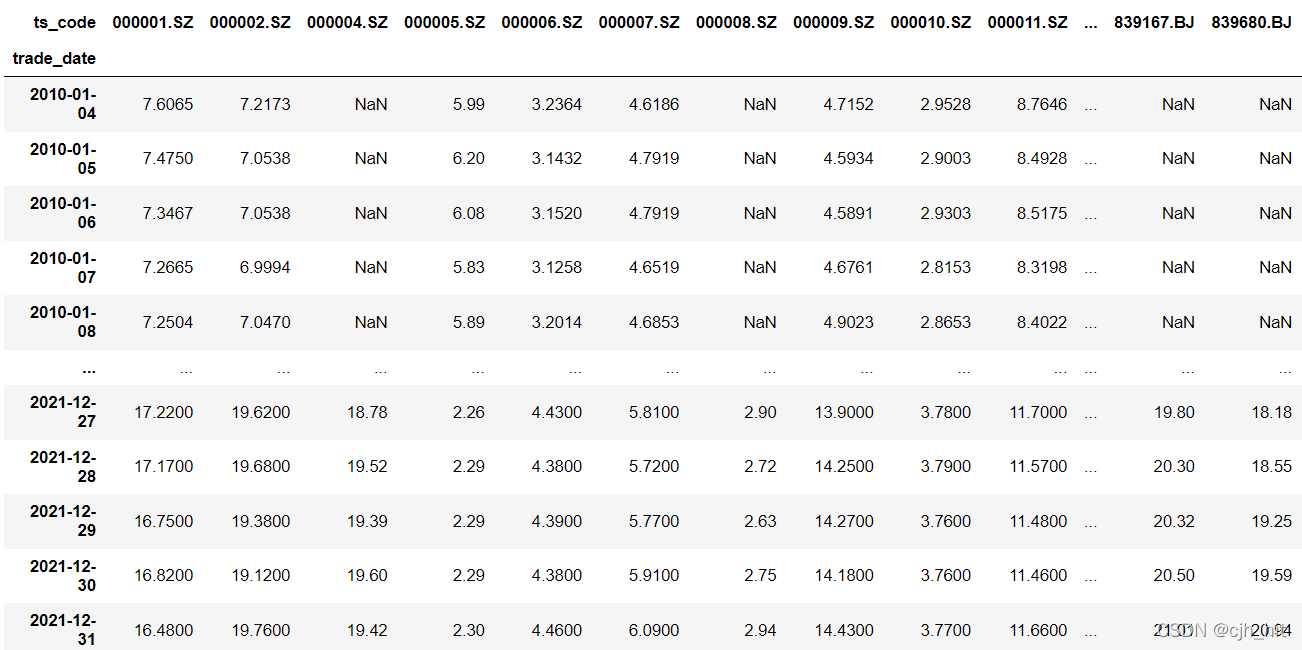
把資料處理成特定的DataFrame格式:(di,ii)格式,即columns為股票代碼、index為日期,value為資料(如收盤價、成交量、各種因子等),每一個指標是單獨的一個df,
但也不是所有資料都要DataFrame,一些只有一維的資料使用Series即可,如特定指數收益率序列,
如下圖,是10年到21年A股復權后的close資料,
要點2:股票池
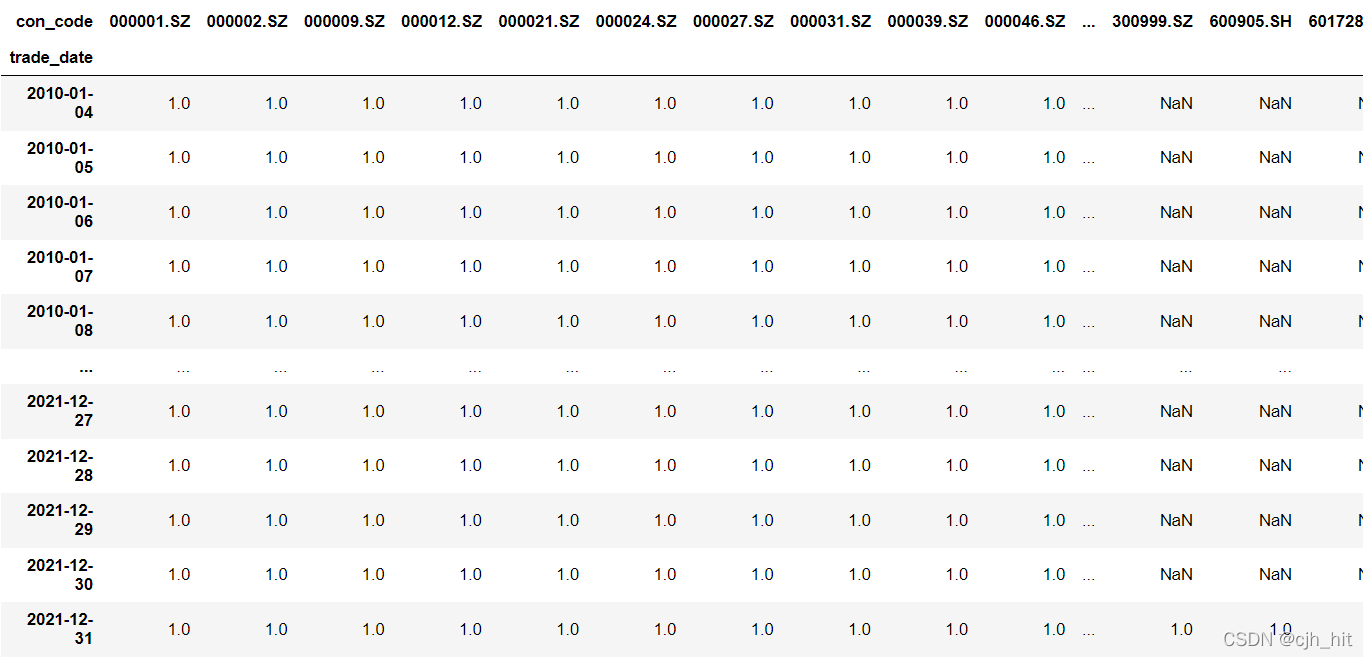
股票池一般取常用指數的成分股矩陣(或者其組合,如滬深300+中證500),一般命名為univ_a\univ_data,univ_a的列名只有現在或歷史上曾經是該指數成分股的股票代碼,
univ_a[stk_code][trade_date]=1即股票stk_code在trade_date這一天是該指數的成分股,否則univ_a[stk_code][trade_date]=NaN
我們一般在計算因子時計算全部的A股資料,在做選股回測時再考慮股票池,方法為:
factor_df = factor_df.reindex_like(univ_a)*univ_a
其中factor_df為因子資料,reindex_like把factor_df的行、列與univ_a統一,
滬深300的股票池資料示例
要點3:剔除ST股、停盤股、漲跌停書評
構造矩陣ST_valid,ST_valid[stk_code][trade_date]==1即stk_code在trade_date這一天不是ST股,通過了ST股篩選,否則是NaN
構造矩陣suspend_valid、limit_valid,同ST,
forbid_days = suspend_valid*limit_valid 只有股票在當天同時通過三種篩選,其數值才為1
在做剔除操作時,只需要將倉位矩陣*forbid_days,沒有通過篩選的股票的資料就成了NaN
要點4: 倉位構建
step1:橫截面排序,按照比例篩選股票,再進行倉位權重歸一化,得到初始倉位pos_1
step2:若考慮調倉周期,假設是月頻率調倉,就是隔20個交易日調倉,
pos_2 = pos_1.reindex(pos_1.index[::20]).fillna(0).reindex(pos_1.index).ffill()
即截取調倉日的倉位,擴充其他日期的倉位先設定為nan,再ffill().
這里有一個fillna(0),因為如果不在擴展之前fillna,則可能會出現 某一期一只股票被選上,后面這只股票的倉位原本都應該是NaN,但經過ffill之后卻都繼承了這個倉位、
step3:考慮調倉日不可交易股票(見to_final_position)
這里有一點要強調,即我們的是factor_df轉換成倉位pos_df時,需要shift(1).因為factor是當天收盤后;利用了當天和之前的資料計算的,而交易最早發生在后一個交易日,
要點5:回測
處理好的倉位fin_pos.shift(1)*rtn_df再橫向求和就是倉位的日收益,其中rtn_df是股票收益矩陣.
shift()的原因是:rtn_df是當天收盤價(開盤價)比上前一天的收盤價(開盤價),而我們是當天非前一天下的單,所以我們吃不到下單第一天的rtn,
資料準備
本人嘗試基于tushare(需要積分)獲取研究所需要的常用資料(如股票行情資料、指數成分股資料、st股、漲跌停等)并處理成前文所示的(di,ii)格式,
與資料下載、存盤、讀取相關的代碼如下,
但tushare的介面對調取頻率、單次調取資料量有限制,因精力有限,并沒有對代碼進行完全的優化,故部分代碼比較啰嗦,運行效率低,
另,因為部分方法使用了多行程并行下載,故無法在jupyter notebook等互動式環境下運行,請在pycharm等IDE下執行main()函式,
資料準備部分主要有三個類,
資料下載的DataDownloader,從tushare介面獲取資料并整理成特定格式,
資料更新存盤的DataWriter,呼叫DataDownloader將資料下載、更新、存盤到本地,
資料讀取的DataReader,讀取資料,
import tushare as ts
import numpy as np
import pandas as pd
from multiprocessing import Manager, Pool
import datetime
import os
import pickle
import warnings
warnings.filterwarnings('ignore')
ts.set_token('')
pro = ts.pro_api(timeout=5)
global dataBase
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = curPath[:curPath.find("多因子框架\\")+len("多因子框架\\")]
dataBase = rootPath+'\\data\\'
def read_pickle(path):
with open(path, 'rb') as handle:
return pickle.load(handle)
def update_pickle(text, path):
with open(path, 'wb') as handle:
pickle.dump(text, handle)
class DataDownloader:
def __init__(self,start_date='20100101',end_date = None):
self.start_date = start_date
self.end_date = end_date
self.trade_dates = self.get_trade_dates()
self.stk_codes = self.get_stks()
#self.template_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes)
def get_trade_dates(self,start_date = None,end_date = None):
if start_date == None:
start_date = self.start_date
end_date = datetime.datetime.now().strftime('%Y%m%d') if end_date == None else self.end_date
df = pro.trade_cal(exchange='SSE', start_date=start_date,end_date=end_date)
df[df['is_open']==1]['cal_date'].drop_duplicates()
return df[df['is_open']==1]['cal_date'].to_list()
def get_stks(self):
stk_set = set()
for list_status in ['L','D','P']:
stk_set |= set(pro.stock_basic(list_status=list_status,fileds='ts_code')['ts_code'].to_list())
return sorted(list(stk_set))
def get_IdxWeight(self,idx_code):
'''
指數成分股
'''
start_date = pd.to_datetime(self.trade_dates[0]) - datetime.timedelta(days=32)
start_date = start_date.strftime('%Y%m%d')
trade_dates = self.get_trade_dates(start_date)
df_ls = []
while start_date < trade_dates[-1]:
end_date = pd.to_datetime(start_date) + datetime.timedelta(days=32)
end_date = end_date.strftime('%Y%m%d')
raw_df = pro.index_weight(index_code=idx_code, start_date=start_date,end_date=end_date)
df_ls.append(raw_df.pivot(index = 'trade_date',columns = 'con_code',values='weight'))
start_date = end_date
res_df = pd.concat(df_ls)
res_df = res_df[~res_df.index.duplicated(keep='first')]
res_df = res_df.reindex(trade_dates)
res_df = res_df.ffill().reindex(self.trade_dates)
return res_df.sort_index()
def get_ST_valid(self):
'''
ST股
'''
res_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes).fillna(1)
df = pro.namechange(fields='ts_code,name,start_date,end_date')
df = df[df.name.str.contains('ST')]
for i in range(df.shape[0]):
ts_code = df.iloc[i,0]
if ts_code not in self.stk_codes:
continue
s_date = df.iloc[i, 2]
e_date = df.iloc[i, 3]
if e_date == None:
res_df[ts_code].loc[s_date:]=np.nan
else:
res_df[ts_code].loc[s_date:e_date]=np.nan
return res_df.sort_index()
def get_suspend_oneDate(self,trade_date,m_ls):
'''
tushare的介面一次最多回傳5000條資料,所以按天調取,用并行加速,
'''
try:
df = pro.suspend_d(suspend_type='S',trade_date=trade_date)
m_ls.append([trade_date,df])
except:
df = pro.suspend_d(suspend_type='S',trade_date=trade_date)
m_ls.append([trade_date,df])
def get_suspend_valid(self):
'''
停牌股
'''
res_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes).fillna(1)
m_ls = Manager().list()
pools = Pool(4)
for date in self.trade_dates:
pools.apply_async(self.get_suspend_oneDate,
args=(date,m_ls)
)
pools.close()
pools.join()
m_ls = list(m_ls)
for date,df in m_ls:
print(date,df)
res_df.loc[date,df['ts_code'].to_list()] = np.nan
return res_df.sort_index()
def get_limit_oneDate(self,trade_date,m_ls):
'''
tushare的介面一次最多回傳5000條資料,所以按天調取,用并行加速,
'''
try:
df = pro.limit_list(trade_date=trade_date)
m_ls.append([trade_date,df])
except:
df = pro.suspend_d(trade_date=trade_date)
m_ls.append([trade_date,df])
def get_limit_valid(self):
'''
停牌股
'''
res_df = pd.DataFrame(index=self.trade_dates,columns=self.stk_codes).fillna(1)
m_ls = Manager().list()
pools = Pool(3)
for date in self.trade_dates:
pools.apply_async(self.get_limit_oneDate,
args=(date,m_ls)
)
pools.close()
pools.join()
m_ls = list(m_ls)
for date,df in m_ls:
res_df.loc[date,df['ts_code'].to_list()]=np.nan
return res_df.sort_index()
def get_dailyMkt_oneStock(self,ts_code,m_ls):
'''
前復權的行情資料
因為tushare下載復權行情介面一次只能獲取一只股票
所以使用多進行并行
'''
try:
#偶爾會因為網路問題請求失敗,報錯重新請求
df = ts.pro_bar(ts_code=ts_code, adj='qfq', start_date=self.start_date,end_date=self.end_date)
m_ls.append(df)
except:
df = ts.pro_bar(ts_code=ts_code, adj='qfq', start_date=self.start_date,end_date=self.end_date)
m_ls.append(df)
def get_dailyMkt_mulP(self):
m_ls = Manager().list()
pools = Pool(3)#開太多會有訪問頻率限制
for ts_code in self.stk_codes:
pools.apply_async(self.get_dailyMkt_oneStock,
args=(ts_code,m_ls))
pools.close()
pools.join()
m_ls = list(m_ls)
raw_df = pd.concat(m_ls)
res_dict = {}
for data_name in ['open','close','high','low','vol','amount']:
res_df = raw_df.pivot(index='trade_date',columns='ts_code',values=data_name)
res_dict[data_name] = res_df.sort_index()
return res_dict
class DataWriter:
@staticmethod
def commonFunc(data_path,getFunc,cover,*args,**kwds):
if not os.path.exists(data_path) or cover:
t1 = datetime.datetime.now()
print(f'--------{data_path},第一次下載該資料,可能耗時較長')
newData_df = eval(f'DataDownloader().{getFunc}(*args,**kwds)')
newData_df.to_pickle(data_path)
t2 = datetime.datetime.now()
print(f'--------下載完成,耗時{t2-t1}')
else:
savedData_df = pd.read_pickle(data_path)
savedLastDate = savedData_df.index[-1]
print(f'---------{data_path}上次更新至{savedLastDate},正在更新至最新交易日')
lastData_df = eval(f'DataDownloader(savedLastDate).{getFunc}(*args,**kwds)')
newData_df = pd.concat([savedData_df,lastData_df]).sort_index()
newData_df = newData_df[~newData_df.index.duplicated(keep='first')]
newData_df.to_pickle(data_path)
print(f'---------已更新至最新日期{newData_df.index[-1]}')
newData_df.index = pd.to_datetime(newData_df.index)
return newData_df
@staticmethod
def update_IdxWeight(stk_code,cover=False):
data_path = dataBase+f'daily/idx_cons/{stk_code}.pkl'
return DataWriter.commonFunc(data_path,'get_IdxWeight',cover,stk_code)
@staticmethod
def update_ST_valid(cover=False):
data_path = dataBase+f'daily/valid/ST_valid.pkl'
return DataWriter.commonFunc(data_path,'get_ST_valid',cover)
@staticmethod
def update_suspend_valid(cover=False):
data_path = dataBase+'daily/valid/suspend_valid.pkl'
return DataWriter.commonFunc(data_path,'get_suspend_valid',cover)
@staticmethod
def update_limit_valid(cover=False):
data_path = dataBase+'daily/valid/limit_valid.pkl'
return DataWriter.commonFunc(data_path,'get_limit_valid',cover)
@staticmethod
def update_dailyMkt(cover=False):
'''
需要保證已存盤的ochlv資料的日期一致
'''
if not os.path.exists(dataBase+f'daily/mkt/open.pkl') or cover:
print(f'--------Mkt,第一次下載該資料,可能耗時較長')
res_dict = DataDownloader().get_dailyMkt_mulP()
for data_name,df in res_dict.items():
data_path = dataBase+f'daily/mkt//{data_name}.pkl'
df.to_pickle(data_path)
else:
savedData_df = pd.read_pickle(dataBase+f'daily/mkt/open.pkl')
savedLastDate = savedData_df.index[-1]
print(f'---------Mkt,上次更新至{savedLastDate},正在更新至最新交易日')
res_dict = DataDownloader(savedLastDate).get_dailyMkt_mulP()
new_df = pd.DataFrame()
for data_name,last_df in res_dict.items():
data_path = dataBase+f'daily/mkt//{data_name}.pkl'
new_df = pd.concat([savedData_df,last_df]).sort_index()
new_df = new_df[~new_df.index.duplicated(keep='first')]
new_df.to_pickle(data_path)
print(f'---------已更新至最新日期{new_df.index[-1]}')
class DataReader:
@staticmethod
def commonFunc(data_path):
if not os.path.exists(data_path):
print(f'{data_path}不存在,請先呼叫DataWriter().update_xx')
return
df = pd.read_pickle(data_path)
df.index = pd.to_datetime(df.index)
return df
@staticmethod
def read_IdxWeight(stk_code):
data_path = dataBase+f'daily/idx_cons/{stk_code}.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_ST_valid():
data_path = dataBase+f'daily/valid/ST_valid.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_suspend_valid():
data_path = dataBase+'daily/valid/suspend_valid.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_limit_valid():
data_path = dataBase + 'daily/valid/limit_valid.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_dailyMkt(data_name):
data_path = dataBase+f'daily/mkt/{data_name}.pkl'
return DataReader.commonFunc(data_path)
@staticmethod
def read_index_dailyRtn(index_code,start_date = '20100101'):
df = pro.index_daily(ts_code=index_code, start_date= start_date).set_index('trade_date').sort_index()
df.index = pd.to_datetime(df.index)
return df['pct_chg']/100
@staticmethod
def read_dailyRtn():
df = DataReader.read_dailyMkt('close')
return df.pct_change()
if __name__ == '__main__':
DataWriter.update_ST_valid(cover=True)
DataWriter.update_suspend_valid(cover=True)
DataWriter.update_IdxWeight('399300.SZ',cover=True)
DataWriter.update_dailyMkt(cover=True)
DataWriter.update_limit_valid(cover=True)
單因子檢測
主要有
1.夏普、年化、最大回撤等指標的實作,
2.to_finnal_position函式,將選出的股票進行股票池、st股、limit等處理,見注釋,
3.factor_group分組回測,默認進行十等分,畫出凈值圖和收益率柱狀圖,
4.ICIR相關,計算IC、IR,畫出累計IC圖,
5.calc_daily_pnl計算倉位收益,
6.factor_stats綜合,最終直接呼叫該函式,
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def Col_zscore(df, n, cap=None, min_periods=1, check_std=False):
df_mean = df.rolling(window=n,min_periods=min_periods).mean()
df_std = df.rolling(window=n, min_periods=min_periods).std()
if check_std:
df_std = df_std[df_std >= 0.00001]
target = (df - df_mean) / df_std
if cap is not None:
target[target > cap] = cap
target[target < -cap] = -cap
return target
def Row_zscore(df, cap=None, check_std=False):
df_mean = df.mean(axis=1)
df_std = df.std(axis=1)
if check_std:
df_std = df_std[df_std >= 0.00001]
target = df.sub(df_mean, axis=0).div(df_std, axis=0)
if cap is not None:
target[target > cap] = cap
target[target < -cap] = -cap
return target
def MaxDrawdown(asset_series):
return asset_series - np.maximum.accumulate(asset_series)
def Sharpe_yearly(pnl_series):
return (np.sqrt(250) * pnl_series.mean()) / pnl_series.std()
def AnnualReturn(pos_df, pnl_series, alpha_type):
temp_pnl = (1+pnl_series).prod()
if alpha_type == 'ls_alpha':
temp_pos = pos_df.abs().sum().sum() / 2
else:
temp_pos = pos_df.abs().sum().sum()
if temp_pos == 0:
return .0
else:
return round(temp_pnl ** (250 / temp_pos) - 1,2)
def IC(signal, pct_n, min_valids=None, lag=0):
signal = signal.shift(lag)
corr_df = signal.corrwith(pct_n, axis=1,method='spearman').dropna()
if min_valids is not None:
signal_valid = signal.count(axis=1)
signal_valid[signal_valid < min_valids] = np.nan
signal_valid[signal_valid >= min_valids] = 1
corr_signal = corr_df * signal_valid
else:
corr_signal = corr_df
return corr_signal
def IR(signal, pct_n, min_valids=None, lag=0):
corr_signal = IC(signal, pct_n, min_valids, lag)
ic_mean = corr_signal.mean()
ic_std = corr_signal.std()
ir = ic_mean / ic_std
return ir, corr_signal
# def to_weighted_position(selected_df,weights_df = None):
# if weights_df is None:
# weights_df = pd.DataFrame().reindex_like(selected_df).fillna(1)
#
# weights_df = weights_df.reindex_like(selected_df)
# selected_weights_df = selected_df * weights_df
# weighted_position_df = selected_weights_df.div(selected_weights_df.sum(axis=1), axis=0)
# return weighted_position_df
def to_final_position(factor_score, forbid_day):
'''
factor_score:DataFrame,可以是因子值,也可以是根據因子值排序選出來的初始倉位矩陣
forbid_day:DataFrame,是否可交易(由ST股、停盤相乘得到),1代表該股票該日可以交易,不可交易則是NaN
return:
pos_fin:DataFrame,最終倉位
'''
#因為因子df中,index為x的數值是用x日收盤后更新的資料計算的,所以x日不能交易,需要等到下一天交易,所以要shift(1)
pos_fin = factor_score.shift(1).replace(np.nan, 0) * forbid_day
#這里的ffill的效果是,若某只需要交易的股票在調倉日無法交易,那么經過上一個步驟后,其對應位置是nan,而ffill就是讓其先繼承前一個交易日的倉位
pos_fin = pos_fin.ffill()
return pos_fin
def calc_daily_pnl(factor_df, univ_data, rtn_df, idx_rtn,forbid_days,method):
'''
:param factor_df: 因子/倉位矩陣
:param univ_data: 股票池矩陣(如滬深300成分股、中證500成分股等等)
:param idx_rtn: 指數rtn序列
:param forbid_days: 合法交易矩陣
:param rtn_df: 股票rtn矩陣
:param method_func: feature/factor/ls_alpha/hg_alpha
:return: 倉位矩陣+每日倉位收益率序列
'''
factor_sel = factor_df.copy()
factor_sel = factor_sel.reindex_like(univ_data)*univ_data
forbid_days = forbid_days.reindex_like(factor_sel)
return_df = rtn_df.reindex_like(factor_sel)
if method == 'feature' or method == 'factor':
factor_z = Row_zscore(factor_sel, cap=4.5)
pos_final = to_final_position(factor_z, forbid_days)
daily_pnl_final = (pos_final.shift(1) * return_df).sum(axis=1)
return pos_final,daily_pnl_final
elif method == 'ls_alpha':
pos_final = to_final_position(factor_sel, forbid_days)
daily_pnl_final = (pos_final.shift(1) * return_df).sum(axis=1)
return pos_final,daily_pnl_final
elif method == 'hg_alpha':
pos_final = to_final_position(factor_sel, forbid_days)
daily_pnl_final = (pos_final.shift(1) * return_df).sum(axis=1) - idx_rtn
return pos_final,daily_pnl_final
def factor_group(factor_df,forb_day,rtn_df,idx_rtn,univ_data,split_pct_ls):
'''
分組回測
'''
factor_df = factor_df.reindex_like(univ_data)*univ_data
factor_score = factor_df
factor_rank_pct = factor_score.rank(ascending=False, pct=True, axis=1)
annual_rtn_ls = list()
plt.figure(figsize=(12, 6))
for split_pct in split_pct_ls:
pos_selected = factor_score[(factor_rank_pct > split_pct[0])&(factor_rank_pct <= split_pct[1])]
pos_selected = pos_selected.where(pd.isnull(pos_selected), 1)
pos = pos_selected.div(pos_selected.sum(axis=1), axis=0)
pos = to_final_position(pos, forb_day).reindex(factor_df.index)
daily_rtn = (pos.shift(1) * rtn_df).sum(axis=1).reindex(factor_df.index)
annual_rtn = AnnualReturn(pos,daily_rtn,'factor')
annual_rtn_ls.append(annual_rtn)
plt.plot((daily_rtn+1).cumprod(), label=str(split_pct))
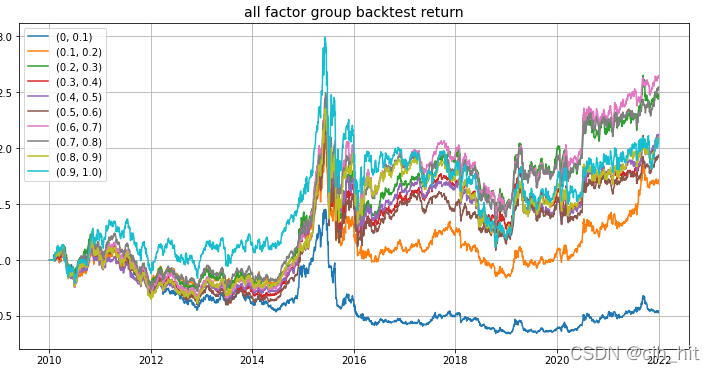
plt.title('all factor group backtest return',fontsize = 14)
plt.legend()
plt.grid()
plt.show()
xticks = range(len(split_pct_ls))
plt.figure(figsize=(12, 6))
p = plt.subplot(111)
p.bar(x = xticks,height = annual_rtn_ls)
p.set_xticks(xticks)
p.set_xticklabels([x[1]*10 for x in split_pct_ls])
plt.title('factor group annual return',fontsize = 14)
plt.grid()
plt.show()
def factor_stats(
factor_df=None,
chg_n=1,#調倉時間間隔
univ_data=None,
rtn_df=None,
idx_rtn=None,
forbid_days = None,
method='factor',#factor\ls_alpha\hg_alpha
group_split_ls=[(0,0.1),(0.1,0.2),(0.2,0.3),(0.3,0.4),(0.4,0.5),(0.5,0.6),(0.6,0.7),(0.7,0.8),(0.8,0.9),(0.9,1.0)]
):
if method=='factor':
# plt.figure(figsize=(16, 12))
plt.figure(figsize=(12, 6))
pos_final,daily_pnl = calc_daily_pnl(factor_df, univ_data, rtn_df, idx_rtn,forbid_days,method)
plt.plot(daily_pnl.cumsum())
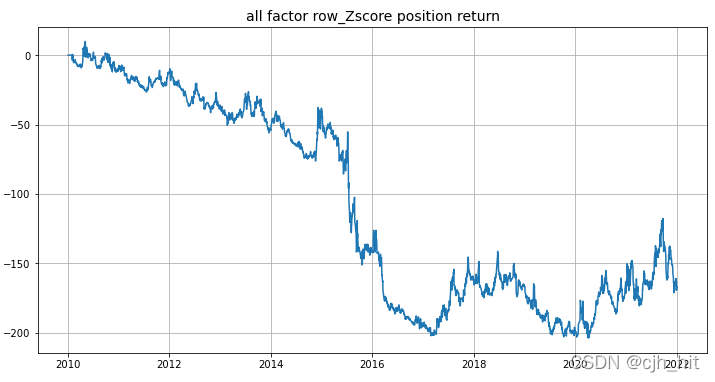
plt.title('all factor row_Zscore position return',fontsize = 14)
plt.grid(1)
plt.show()
factor_group(
factor_df,
forbid_days,
rtn_df,
idx_rtn,
univ_data,
split_pct_ls=group_split_ls
)
pct_n = rtn_df.rolling(window=chg_n).sum()
ir,IC_series = IR(factor_df, pct_n, lag=chg_n)
plt.figure(figsize=(12, 6))
plt.plot(IC_series.cumsum(),label=f'IR:{round(ir,2)},IC_mean:{round(IC_series.mean(),2)}')
plt.title('IC cumsum',fontsize = 14)
plt.legend()
plt.grid(1)
plt.show()
else:
plt.figure(figsize=(16, 6))
p1 = plt.subplot(111)
pos = factor_df.reindex(factor_df.index[::chg_n])#初步倉位,沒有剔除St股票 也沒有shift
pos = pos.reindex(factor_df.index).ffill()
pos_final,daily_pnl = calc_daily_pnl(pos, univ_data, rtn_df, idx_rtn,forbid_days,method)
sharpe = round(Sharpe_yearly(daily_pnl),2)
max_drawdown = round(MaxDrawdown((daily_pnl+1).cumprod()),2)
annual_return = round(AnnualReturn(pos_final,daily_pnl,method),2)
p1.plot(daily_pnl.cumsum(),label=f'SP:{sharpe},MD:{max_drawdown.min()},AR:{annual_return}')
p1.set_title('selected position return')
p1.grid(1)
p1.legend()
plt.show()
樣例
以20日收益率因子為例,展示單因子檢測內容,
本人本地的目錄如下圖所示,
from my_lib.data_download.data_io import DataReader
from my_lib.factor_evaluate.factor_evaluate import factor_stats
import pandas as pd
import numpy as np
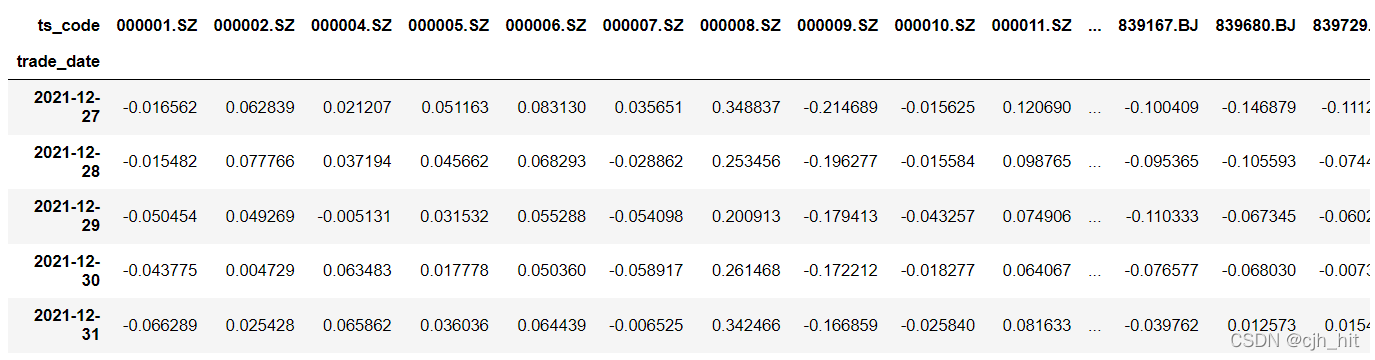
def calc_factor():
#這里是計算因子的,把因子處理成特定的(di,ii)格式,
close_df = DataReader.read_dailyMkt('close')
return close_df.pct_change(20)
計算因子
factor_df = calc_factor()
factor_df.tail(5)
股票池
univ_a = DataReader.read_IdxWeight('399300.SZ')#滬深300
univ_a = univ_a.where(pd.isnull(univ_a),1)
univ_a
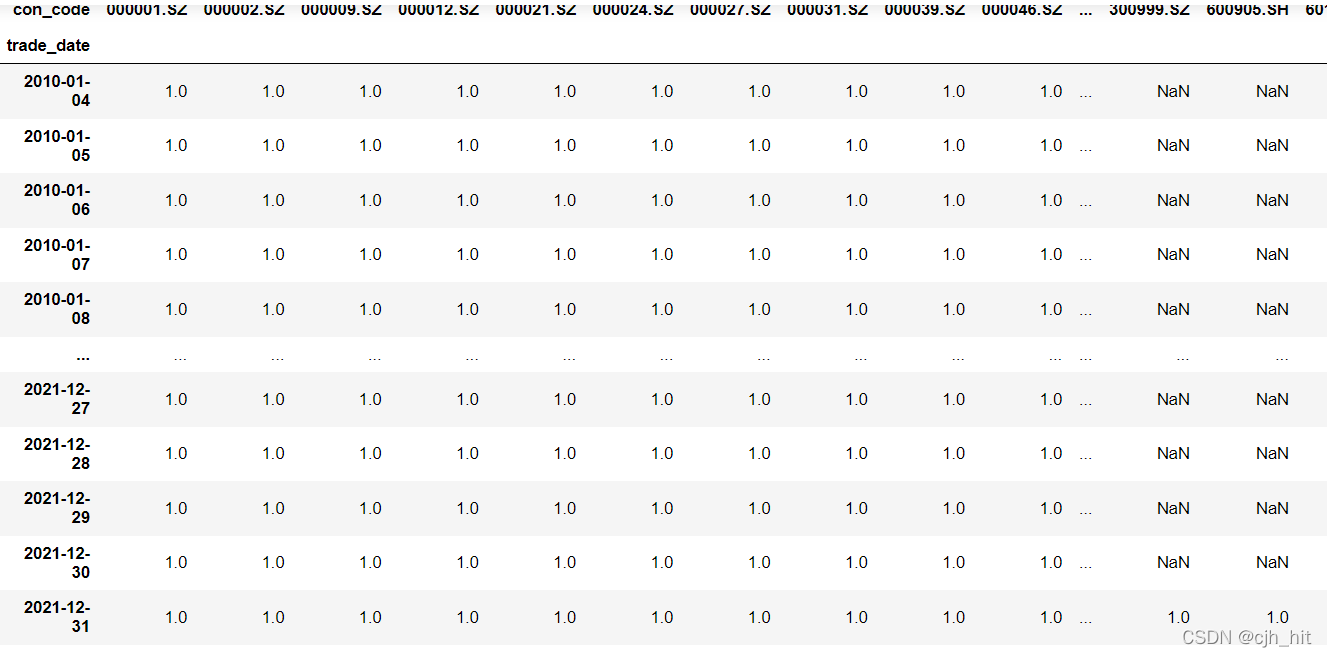
st股、停牌、漲跌停
ST_valid = DataReader.read_ST_valid()
suspend_valid = DataReader.read_suspend_valid()
limit_valid = DataReader.read_limit_valid()
forb_days = ST_valid*suspend_valid*limit_valid
forb_days.tail(5)
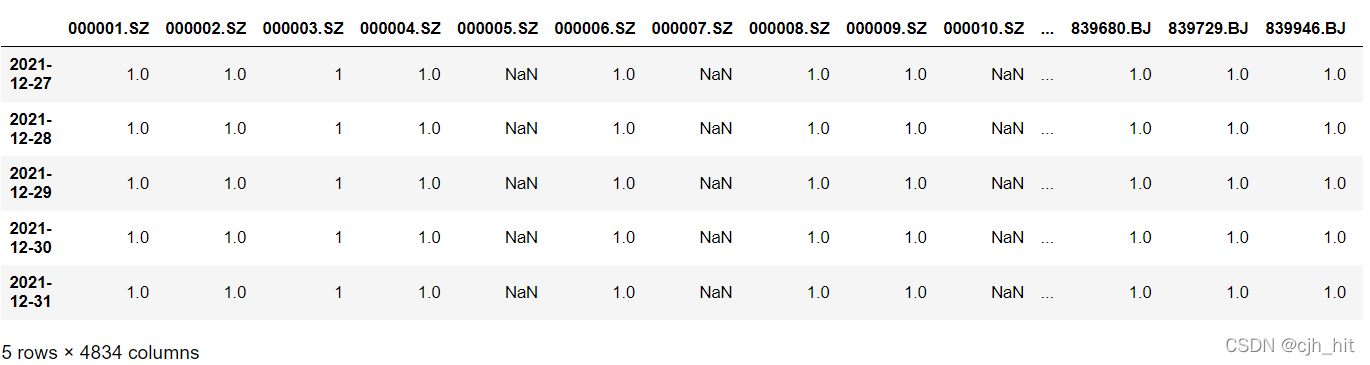
每日收益率矩陣
rtn_df = DataReader.read_dailyRtn()
rtn_df.tail(5)
因子測驗與回測
原始因子
idx_rtn = DataReader.read_index_dailyRtn('399300.SZ')#指數收益序列
factor_stats(
factor_df=factor_df,#因子或者倉位矩陣
chg_n=20,#調倉周期
univ_data=univ_a,#股票池
rtn_df=rtn_df,#股票每日收益矩陣
idx_rtn=idx_rtn,#因子收益序列(用來hg對沖)
forbid_days=forb_days,#st*suspend*limit
method='factor',#factor\ls_alpha\hg_alpha(原始因子、指數對沖、多空對沖)
group_split_ls=[(0,0.1),(0.1,0.2),(0.2,0.3),(0.3,0.4),(0.4,0.5),(0.5,0.6),(0.6,0.7),(0.7,0.8),(0.8,0.9),(0.9,1.0)]#分組回測引數
)
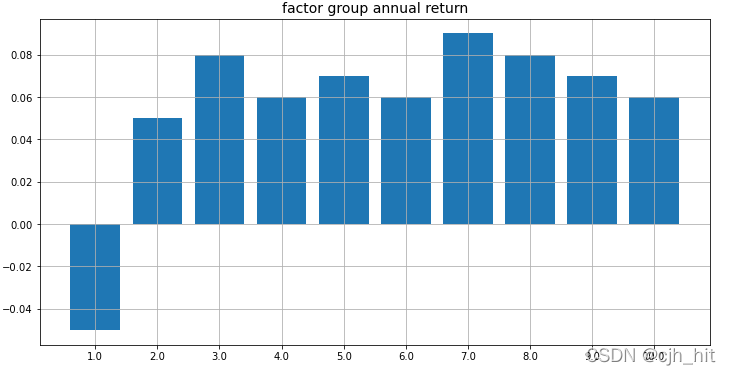
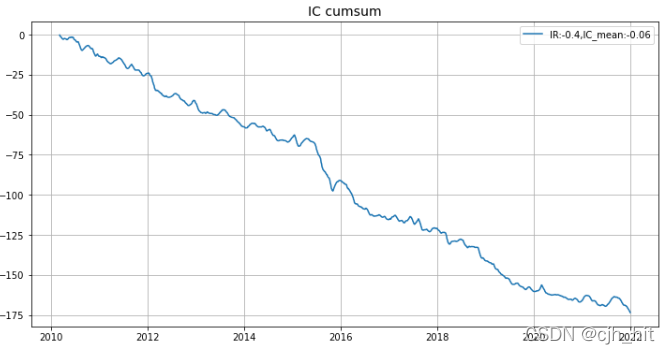
指數對沖
#排序選股,構建倉位
factor_rank_pct = factor_df.rank(ascending=False, pct=True, axis=1)
factor_selected = factor_df[factor_rank_pct>0.8]
factor_selected = factor_selected.where(pd.isnull(factor_selected), 1)
pos = factor_selected.div(factor_selected.sum(axis=1), axis=0)
pos = pos.fillna(0)#重要,否則ffill會出錯
factor_stats(
factor_df = pos,
chg_n=20,
univ_data=univ_a,
rtn_df=rtn_df,
idx_rtn=idx_rtn.replace(np.inf,np.nan).replace(-np.inf,np.nan),
forbid_days=forb_days,
method='hg_alpha',#factor\ls_alpha\hg_alpha
)
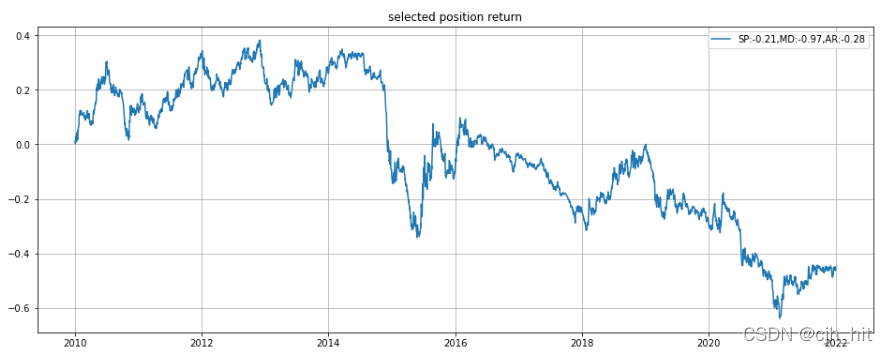
多空對沖
factor_df = factor_df.reindex_like(univ_a)*univ_a
factor_rank_pct = factor_df.rank(ascending=False, pct=True, axis=1)
#多頭倉位
factor_selected = factor_df[factor_rank_pct>0.8]
factor_selected = factor_selected.where(pd.isnull(factor_selected), 1)
pos_long = factor_selected.div(factor_selected.sum(axis=1), axis=0).fillna(0)
#空頭倉位
factor_selected = factor_df[factor_rank_pct<0.2]
factor_selected = factor_selected.where(pd.isnull(factor_selected), 1)
pos_short = factor_selected.div(factor_selected.sum(axis=1), axis=0).fillna(0)
factor_stats(
factor_df = pos_long.fillna(0) - pos_short.fillna(0),
chg_n=20,
univ_data=univ_a,
rtn_df=rtn_df,
idx_rtn=idx_rtn.replace(np.inf,np.nan).replace(-np.inf,np.nan),
forbid_days=forb_days,
method='ls_alpha',#factor\ls_alpha\hg_alpha
)
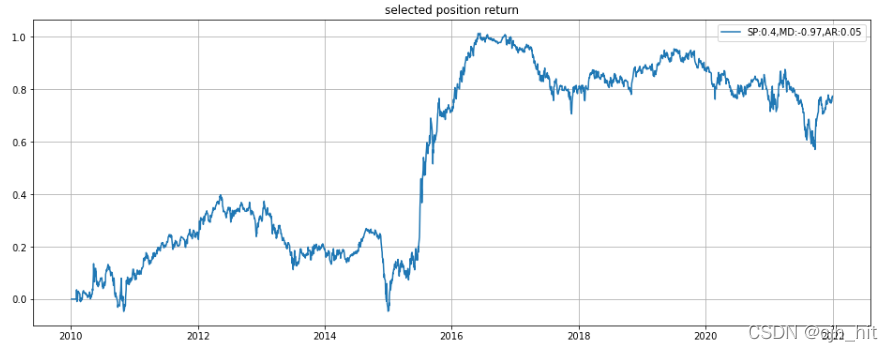
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402631.html
標籤:AI