文章目錄
- 一、引言
- 1.1 什么是LSTM
- 二、回圈神經網路RNN
- 2.1 為什么需要RNN
- 三、長短時記憶神經網路LSTM
- 3.1 為什么需要LSTM
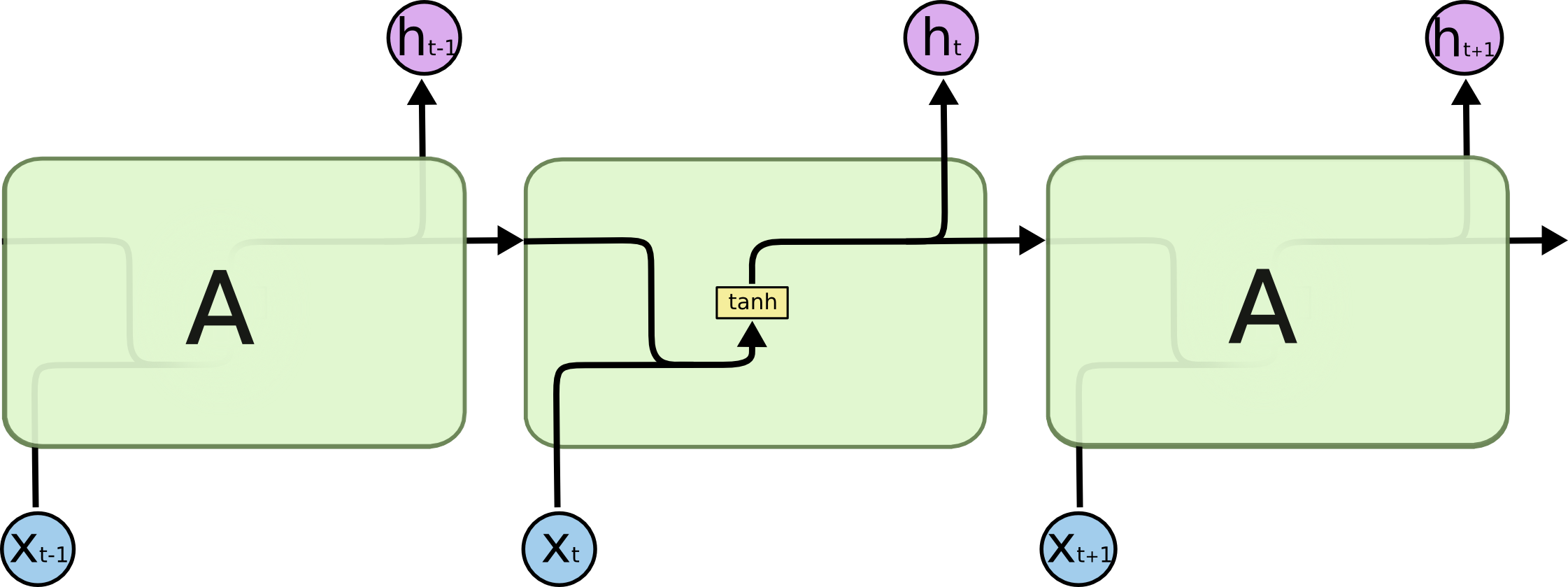
- 3.2 LSTM結構分析
- 3.3 LSTM背后的核心思想
- 3.4 LSTM的運行機制
- 3.5 LSTM如何避免梯度下降
- 四、入門例子
- 五、總結
- 六、參考資料
一、引言
1.1 什么是LSTM
首先看看百科的解釋,
長短期記憶(英語:Long Short-Term Memory,LSTM)是一種時間回圈神經網路(RNN),論文首次發表于1997年,由于獨特的設計結構,LSTM適合于處理和預測時間序列中間隔和延遲非常長的重要事件,1
為了更好地理解長短期記憶網路 - LSTM(下文簡稱LSTM),可以先了解回圈神經網路-RNN(下文簡稱RNN)的相關知識,這里有一些相關的文章,LSTM只是RNN的一個變種,LSTM是為了解決RNN中的梯度消失的問題而提出的,
二、回圈神經網路RNN
2.1 為什么需要RNN
人的思想是有記憶延續性,比如當你在閱讀這篇文章,你會根據你曾經對每個字的理解來理解這篇文章的字,而不是每次都要思考一個字在這篇文章的語境下到底如何理解(從一個字或詞的多種解釋來選擇一個符合當下語境的解釋),
舉個例子:要識別這么一個句子:
The cat, which already ate cakes, () full.2
假設對其中的單詞從左到右一個一個地處理,前面已經cat的識別結果是一個單數名詞,到后邊()里的內容,到底是填were 還是 was,那么就需要根據前邊cat的識別結果進行判斷,這就是RNN需要做的,
使用神經網路來預測句子中下一個字的解釋,傳統的神經網路在模型訓練好了以后,在輸入層給定一個x,通過網路之后就能在輸出層得到特定的y,利用這個模型可以通過訓練擬合任意函式,但是只能單獨的取處理一個個的輸入,前一個輸出和后一個輸出是完全沒有關系的,
神經網路的結構如下:
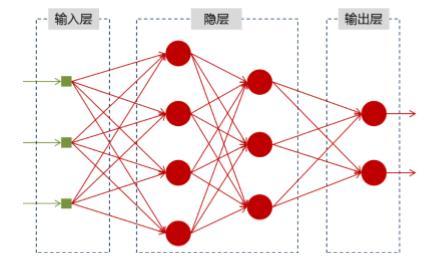
但是,在理解一句話的意思的時候,一個字的意思是跟前面的字相關聯的,即前面的輸出和后面的輸出是有關系的,所以僅僅利用這樣的模型是不夠的的,為了解決這個問題,有人提出了RNN,
RNN模型構造:
RNN神經網路示意圖:
藍色部分的是隱藏層,RNN利用隱藏層將資訊向后傳遞,
我們來看看RNN隱藏層里發生了什么,將上圖按時間線展開3:
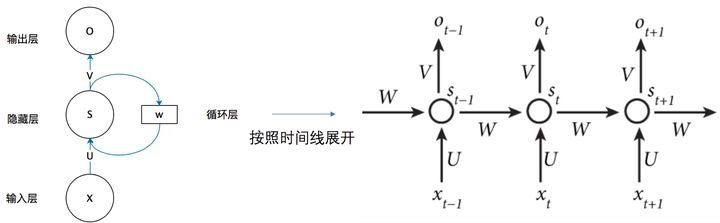
| 符號 | 意義 |
|---|---|
| X | 一個向量,輸入層的值 |
| S | 一個向量,隱藏層的值 |
| O | 一個向量,輸出層的值 |
| U | 輸入層到隱藏層的權重矩陣 |
| V | 隱藏層到輸出層的權重矩陣 |
| W | 隱藏層上一次的值作為這一次輸入的權重 |
再給出一個更具體的圖,給出各層元素的對應關系
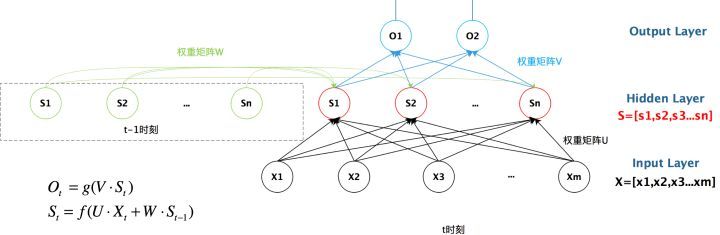
現在看上去就比較清楚了,這個網路在 t 時刻接收到輸入
x
t
x_t
xt? 之后,隱藏層的值是
s
t
s_t
st? ,輸出值是
o
t
o_t
ot? ,關鍵一點是,
s
t
s_t
st? 的值不僅僅取決于
x
t
x_t
xt? ,還取決于
s
t
?
1
s_{t-1}
st?1? , 我們可以用下面的公式來表示RNN的計算方法:
用公式表示如下:
O
t
=
g
(
V
?
S
t
)
O_t = g(V·S_t)
Ot?=g(V?St?)
S
t
=
f
(
U
?
X
t
+
W
?
S
t
?
1
)
S_t = f(U·X_t + W ·S_{t-1})
St?=f(U?Xt?+W?St?1?)
注意:為了簡單說明問題,偏置都沒有包含在公式里面,
這樣,就可以做到的在一個序列中根據前面的輸出來影響后面的輸出,
三、長短時記憶神經網路LSTM
3.1 為什么需要LSTM
回到我們的例子:
The cat, which already ate …, () full.
這個例子與之前的例子稍微有一些不同,這里的cat 和()之間已經相隔了較長的一段距離,這時候用RNN來處理這樣的長期資訊就不太合適,
因為RNN在反向傳播階段有梯度消失等問題不能處理長依賴問題,這里的梯度消失是由于RNN在計算程序中使用鏈式法則,
具體來說,RNN使用覆寫的方式來計算狀態: S t = f ( S t ? 1 , x t ) S_t = f(S_{t-1},x_t) St?=f(St?1?,xt?),這類似于復合函式,根據鏈式求導的法則,復合函式求導:設 f f f 和 g g g 為 x x x 的可導函式,則 ( f ° g ) ′ ( x ) = f ′ ( g ( x ) ) g ′ ( x ) (f \circ g)'(x) = f'(g(x))g'(x) (f°g)′(x)=f′(g(x))g′(x),這是一種連乘的方式,如果導數小于或大于1,會發生梯度下降以及梯度爆炸,梯度爆炸可以通過剪枝演算法解決,但是梯度消失卻沒辦法解決,
梯度消失可能不太好理解,可以簡單理解為RNN中后邊輸入的資料影響越大,前面的資料的影響小,因此不能處理長期資訊,后來,有學者在一篇論文Long Short-Term Memory 4 提出了LSTM,LSTM通過選擇性地保留資訊,有效地緩解了梯度消失以及梯度下降的問題,可以說LSTM正是為了適合學習長期依賴而產生的,
3.2 LSTM結構分析
回顧一下RNN的模型構造:
可以看到,RNN回圈網路模型的鏈式結構非常簡單,通常僅含有一個tanh層,
LSTM模型構造:
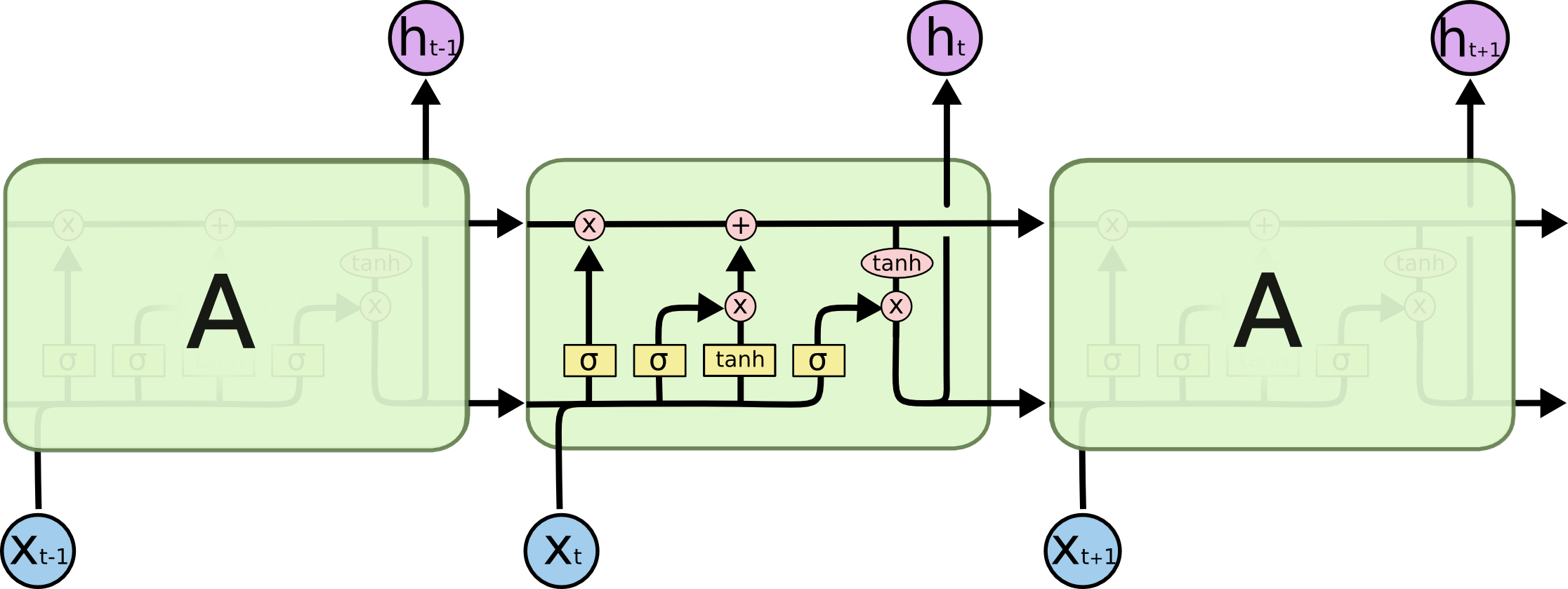
而LSTM的鏈式結構中,回圈單元結構不同,里邊有四個神經網路層,
先來解釋一下圖中符號含義:

| 符號 | 含義 |
|---|---|
| 黃色矩形 | 神經網路層 |
| 粉色圓 | 結點操作,比如向量相加 |
| 箭頭 | 從一個結點的輸出到另外的結點的輸入 |
| 箭頭合并 | 鏈接 |
| 箭頭分叉 | 內容復制后副本流向不同的位置 |
LSTM結構(圖右)和普通RNN的主要輸入輸出區別如下所示:
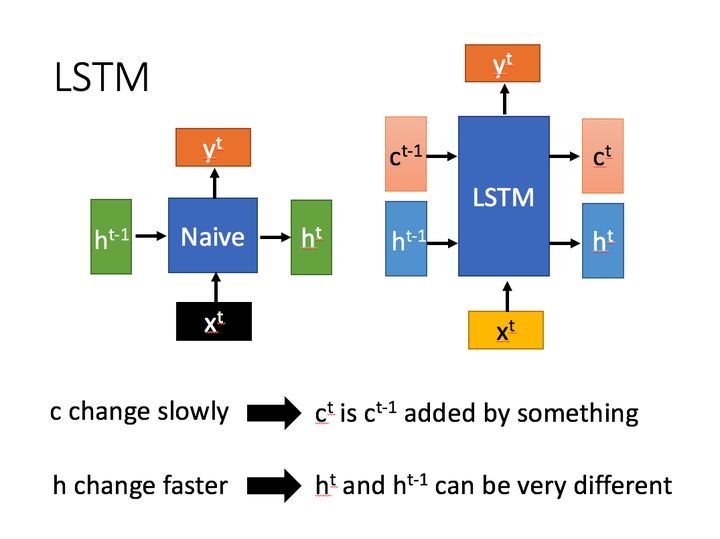
相比RNN只有一個傳遞狀態
h
t
h^t
ht , LSTM有兩個傳輸狀態,一個
c
t
c^t
ct (cell state), 和一個
h
t
h^t
ht (hidden state),(RNN中的
h
t
h^t
ht 對應LSTM中的
C
t
C^t
Ct)
3.3 LSTM背后的核心思想
LSTM的核心思想,LSTM的關鍵是細胞狀態(cell state),即下圖中上邊的水平線,cell state像是一條傳送帶,它貫穿整條鏈,其中只發生一些小的線性作用,資訊流過這條線而不改變是非常容易的,5 改變cell state需要三個門的相互配合,
如下圖所示:
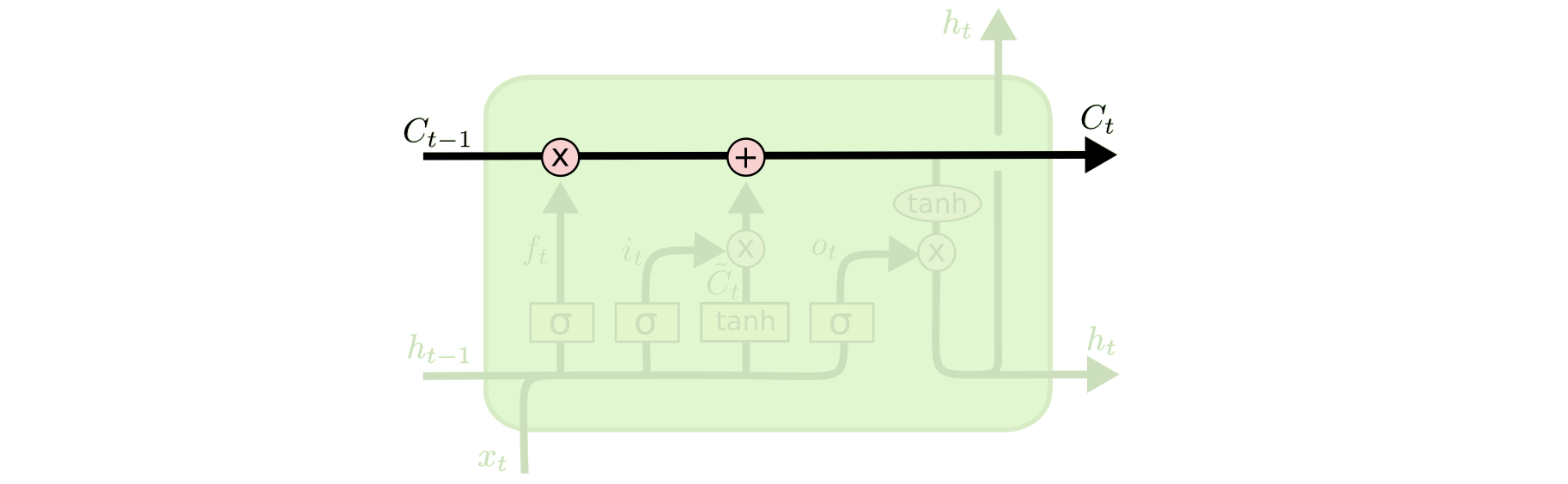
LSTM洗掉或添加資訊到cell state,是由被稱為門的結構控制的,LSTM中有三個門,“遺忘門” “輸入門” 以及“輸出門”,用來保護和更新cell的狀態,
門是篩選資訊的方法,由一個sigmoid網路層和一個點乘操作組成,
如下圖:
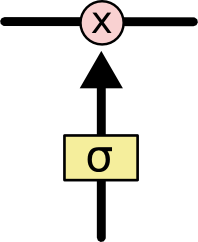
sigmoid層作為激活函式,將輸出控制在(0,1)區間內,Sigmoid的函式圖形如下:
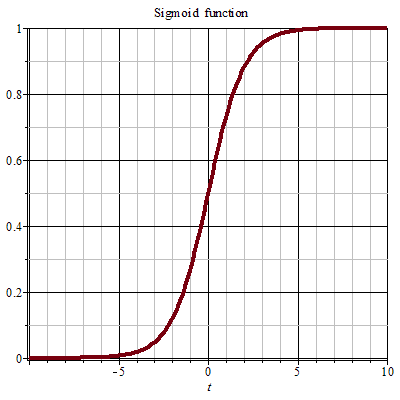
可以看到,絕大多數的值都是接近0或者接近1的,利用這一個性質,0 表示不允許任何通過,1 表示允許一切通過,
3.4 LSTM的運行機制
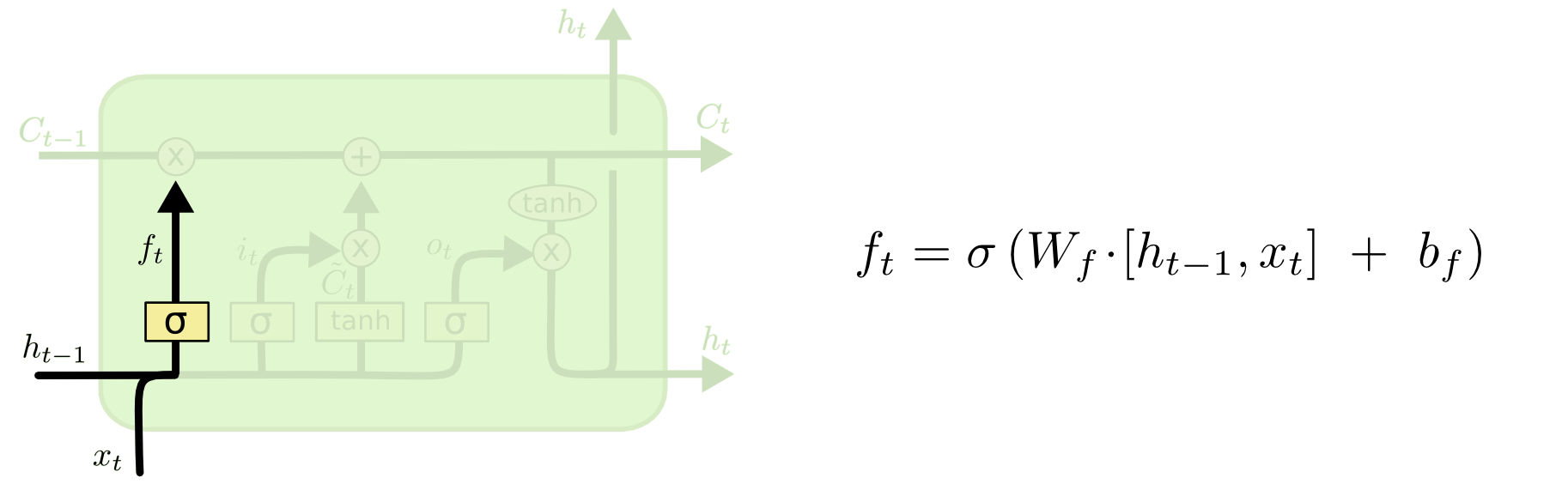
第一步,需要決定從cell state中丟棄什么樣的資訊,這個由“遺忘門”的sigmoid層決定,根據輸入 h t ? 1 h_{t-1} ht?1? 和 x t x_t xt?,得到的輸出是0和1之間的數,0 代表“完全保留這個值”,1代表“完全丟棄這個值”,
回到開始的例子,原來的主語是"cat",之后遇到了一個新的主語"cats",這時需要把之前的"cat"給忘掉,以便確定接下來是要使用"were",而不是"was",如下圖:
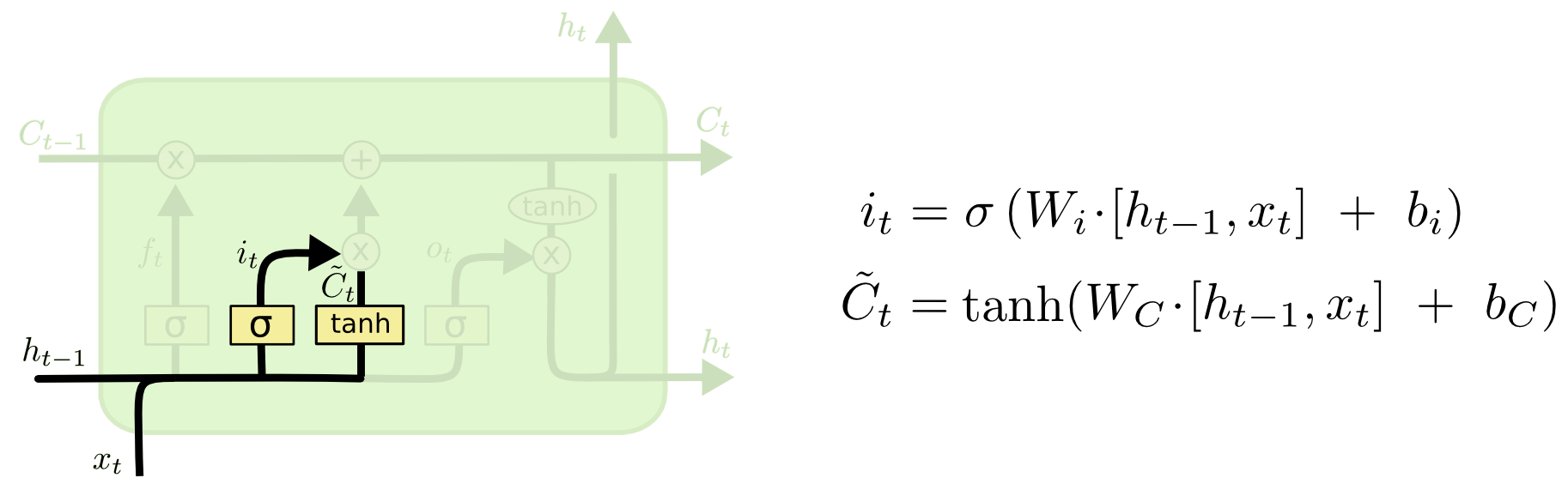
第二步,需要決定在cell state里存盤什么樣的資訊,這一步劃分為兩個部分,一是稱為“輸入門”的sigmoid層決定哪些資料需要更新,然后,tanh層創建一個新的候選值向量
C
~
t
\widetilde{C}_t
C
t?,這些值能加入state中,第二部分,需要將這兩個部分合并以實作對state的更新,
在例子中,這里對應于把新的"cats"加入到"cell state"中,以替代需要遺忘的"cat",如下圖:
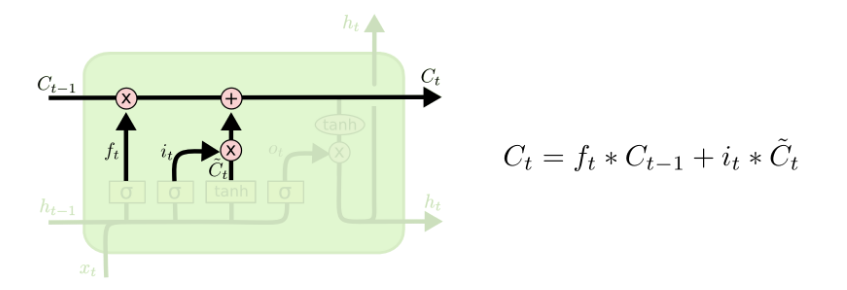
在決定好需要遺忘的以及需要加入的記憶之后,就可以把舊的cell state
C
t
?
1
C_{t-1}
Ct?1?更新到新的cell state
C
t
C_t
Ct?, 這一步中,把舊的state
C
t
?
1
C_{t-1}
Ct?1? 與
f
t
f_t
ft? 相乘,遺忘先前決定遺忘的東西,之后加上新的記憶資訊
i
t
?
C
~
t
i_t \ast \widetilde{C}_t
it??C
t?,這里為了體現對狀態值的更新度是有限制的,可以把
i
t
i_t
it?當成一個權重,如下圖:
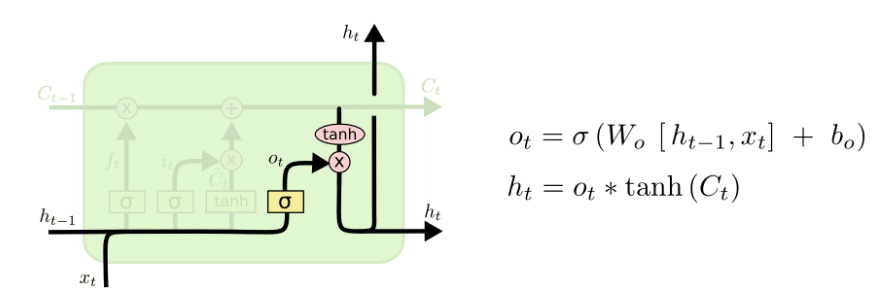
最后,需要決定輸出,這個輸出將會基于cell state ,這是一個過濾后的值,首先,使用“輸出門”的sigmoid層決定輸出cell state的哪些部分的,然后,將cell state放入tanh(將數值限制在-1到1),最后將結果與sigmoid門的輸出相乘,這樣就可以只輸出需要的部分,如下圖:
3.5 LSTM如何避免梯度下降
上邊提到了RNN中的梯度下降以及梯度爆炸問題,是是因為在計算程序中使用鏈式法則,使用了乘積,而在LSTM中,狀態是通過累加的方式來計算, S t = ∑ τ = 1 t Δ S τ S_t = \sum_{\tau =1}^t \Delta S_{\tau} St?=∑τ=1t?ΔSτ?,這樣的計算,就不是復合函式的形式,它的導數也就不是乘積的形式,就不會發生梯度消失的情況,
四、入門例子
下面給出LSTM的一個入門實體-根據前9年的資料預測后3年的客流6,感謝原作者的代碼,完整的代碼見GithubYonv1943,這里簡單說一下這個代碼實體的結果,需要了解更加詳細的代碼細節可以看看原作者的原文詳解,
考慮有一組某機場1949年~1960年12年共144個月的客流量資料,使用這個資料中的前9年的客流量來預測后3年的客流量,再和實際的資料進行比對,可以看出LSTM的對這類具有時序關系的擬合效果,
結果圖:

- 資料:機場1949~1960年12年共144個月的客流量資料,資料具有三個維度[客運量,年份,月份],其中前75%(前9年)的資料作為訓練集,后25%(后3年)的資料作為測驗集,
- 縱坐標:標準化處理:變數值與平均數的差除以標準差,給出數值的相對位置,橫坐標為月數,
- 圖解釋:豎直黑線左邊是訓練集(前9年),右邊(后3年)紅色的是預測數值,藍色的是實際數值,
可以看到在這個LSTM對這個資料集的擬合效果是比較好的,在這樣的實際場景中,可以利用LSTM這樣的工具來對客流量做一個預測,以便對客運高峰等情況做好預備方案,
五、總結
- RNN的計算中存在多個偏導數連乘,導致梯度消失或梯度爆炸,難以處理長依賴的資訊,
- LSTM通過三個選擇性地保留資訊,可以選擇最近的資訊或者很久之前的資訊,
- LSTM更新cell state是采用了線性求和的計算,因此不會出現梯度消失問題,可以處理長期依賴的資訊,
六、參考資料
長短期記憶 ??
吳恩達深度學習課程 ??
一文搞懂RNN(回圈神經網路)基礎篇 ??
Long Short-Term Memory ??
Understanding LSTM Networks ??
LSTM入門例子:根據前9年的資料預測后3年的客流(PyTorch實作) ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402633.html
標籤:AI
下一篇:多標簽學習之白話版