HDFS是一個分布式檔案存盤系統,可以支持數千臺以上規模的集群,單臺節點發生故障的概率比較低,但是當集群中節點非常多的時候,集群中有節點發生故障的概率就很高了,因此需要有效的手段來及時檢查出慢節點,指導我們進行故障排查、硬體維修、慢節點規避等等,
本文就來簡要介紹一下HDFS中關于慢節點檢測的相關功能,
介紹慢節點之前,我們得先回顧一下HDFS寫pipeline的模型,如下圖所示:
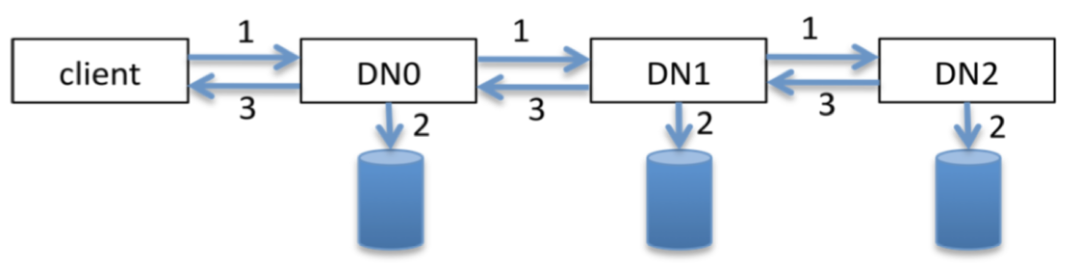
在寫pipeline的程序中,如果出現了網路慢節點,步驟1的耗時會明顯增加,如果出現的是磁盤慢節點,步驟2的耗時會明顯增加,因此,HDFS的慢節點監控,主要是監控步驟1和步驟2的耗時,網路慢節點用Slow Peer指代,磁盤慢節點用Slow Disk指代,
一、Slow Peer(網路慢節點)
網路慢節點的匯總報告資訊由SlowPeerReports類表示,
SlowPeerReports里面有個Map資料結構,映射關系是:
DataNode’s DataNodeUUID -> its aggregate latency as seen by the reporting node.
翻譯過來是:Datanode的DataNodeUUID -> 此datanode被觀察到的聚合后的延遲,
SlowPeerReports類的構造方法是私有的,因此不能直接new,不過它提供了一個static型別的create方法,用來在其他類中創建SlowPeerReports物件,如下圖:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402689.html
標籤:其他