PartitionStateMachine磁區狀態轉換實作
1 我為何讀這原始碼?
PartitionStateMachine,磁區狀態機負責管理Kafka磁區狀態的轉換,類似ReplicaStateMachine,
很多面試官都愛問Leader選舉策略,學完本文,你不但能說出4種Leader選舉場景,還能總結出它們的共性,
2 簡介
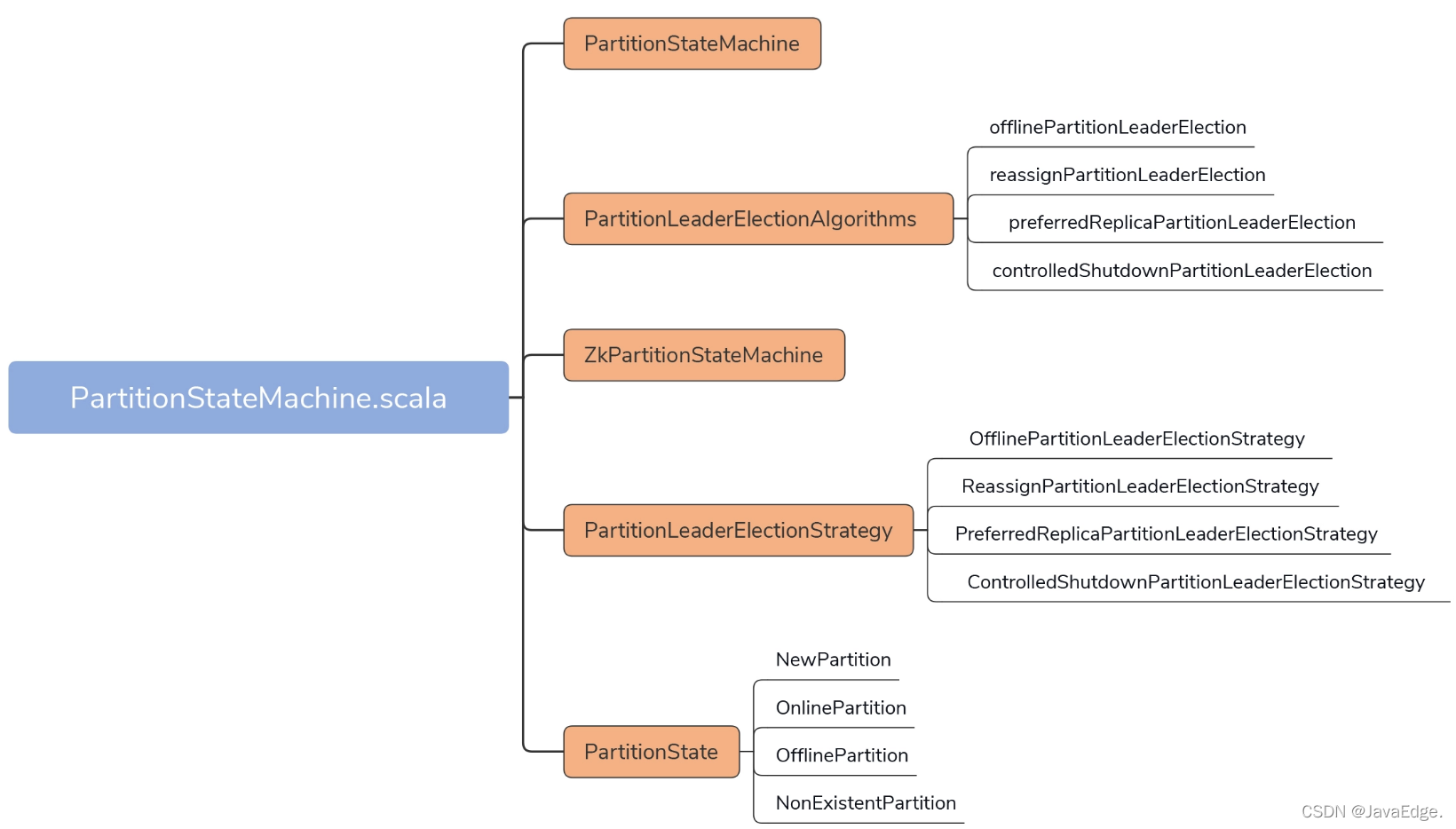
- PartitionStateMachine:定義如startup、shutdown公共方法及處理磁區狀態轉換入口方法handleStateChanges的簽名
- ZkPartitionStateMachine:PartitionSM目前唯一子類,實作磁區狀態機的主體邏輯功能,類似ZkReplicaStateMachine,重寫了父類的handleStateChanges,和私有的doHandleStateChanges協作完成磁區狀態轉換
- PartitionState介面及其實作物件:定義4類磁區狀態及相互流轉關系
- PartitionLeaderElectionStrategy介面及其實作物件:定義4類磁區Leader選舉策略,發生Leader選舉的4種場景
- PartitionLeaderElectionAlgorithms:磁區Leader選舉的演算法實作,既然定義了4類選舉策略,就一定有相應的實作代碼,PartitionLeaderElectionAlgorithms就提供了這4類選舉策略的實作代碼,
3 類定義與欄位
類似ReplicaSM:
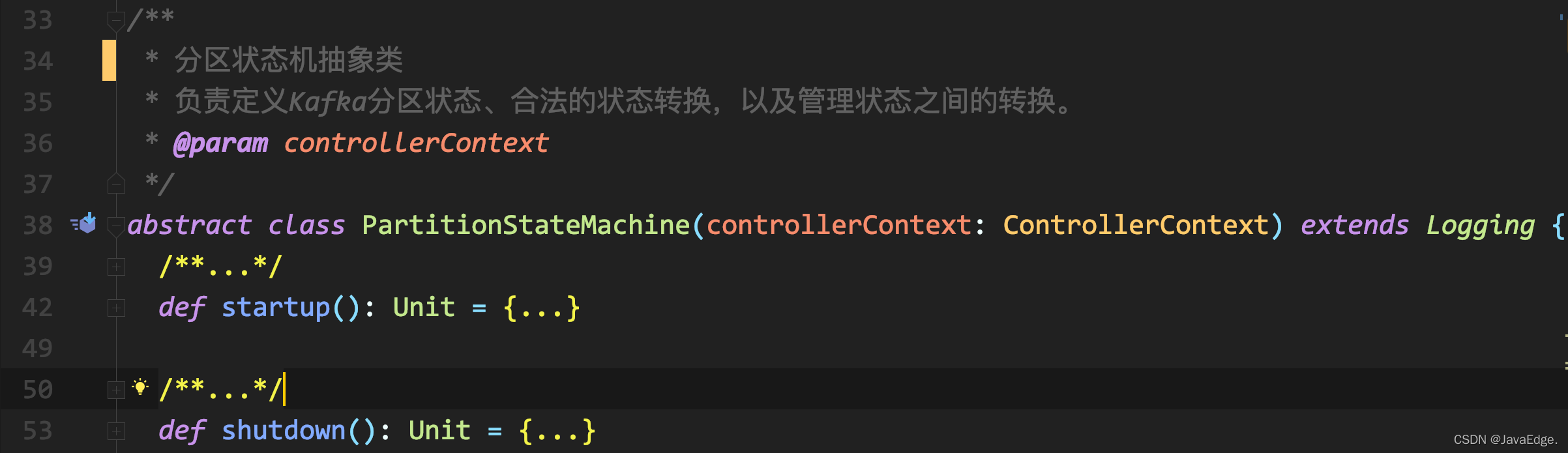

類定義一樣!尤其是ZkPartitionSM和ZKReplicaSM,所接收欄位串列都一致,所以功能其實也差不多,
同理,ZkPartitionSM實體的創建和啟動時機也和ZkReplicaSM完全相同:每個Broker行程啟動時,會在創建KafkaController物件的程序中,生成ZkPartitionSM實體,而只有Controller組件所在Broker,才會啟動磁區狀態機,
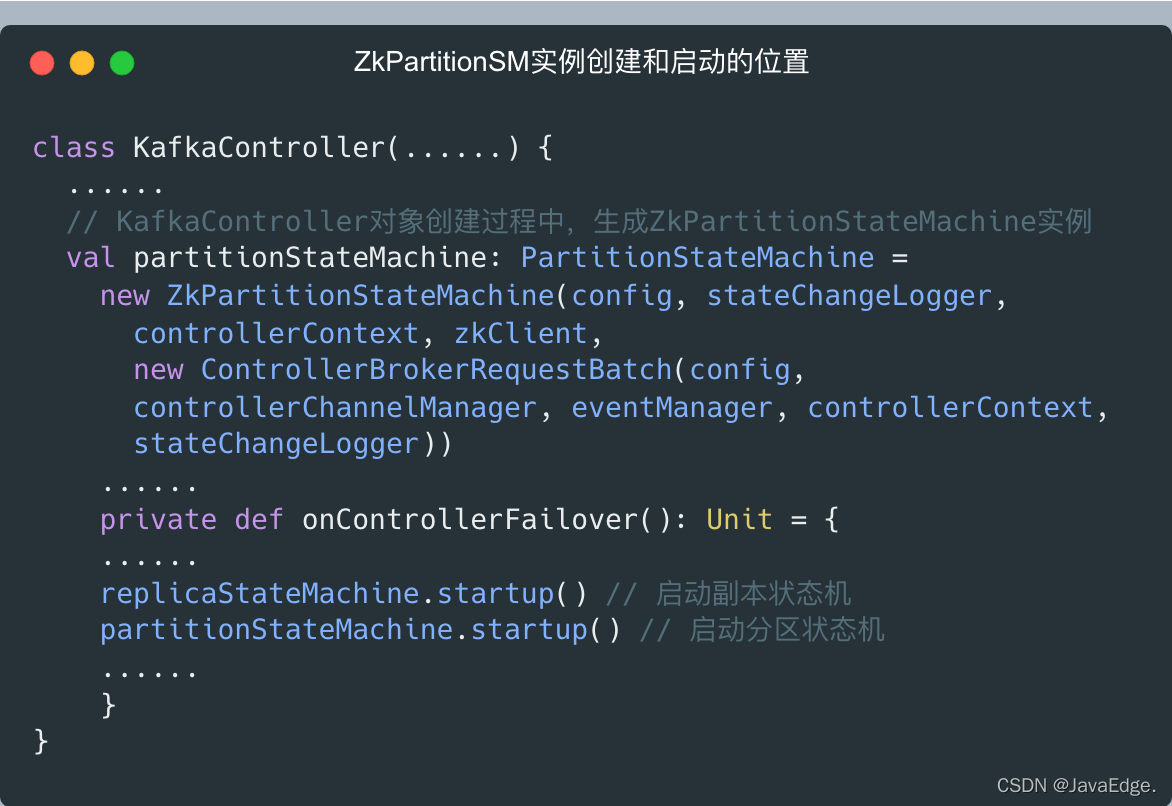
每個Broker啟動時,都會創建對應磁區狀態機和副本狀態機實體,但只有Controller所在的Broker才會啟動它們,若Controller變更到其他Broker:
- 老Controller所在Broker要呼叫這些狀態機的shutdown方法關閉它們
- 新Controller所在的Broker呼叫狀態機的startup方法啟動它們
4 磁區狀態
PartitionState定義了磁區的狀態空間及流轉規則,以OnlinePartition態為例:


磁區狀態列舉
- NewPartition:磁區被創建后被設定成這個狀態,表明是全新的磁區物件,Kafka認為是“未初始化”的初生牛犢子,因此不能競選Leader
- OnlinePartition:磁區正式提供服務時所處態
- OfflinePartition:磁區下線后所處態
- NonExistentPartition:磁區被洗掉,并且從磁區狀態機移除后所處態
磁區狀態轉換規則
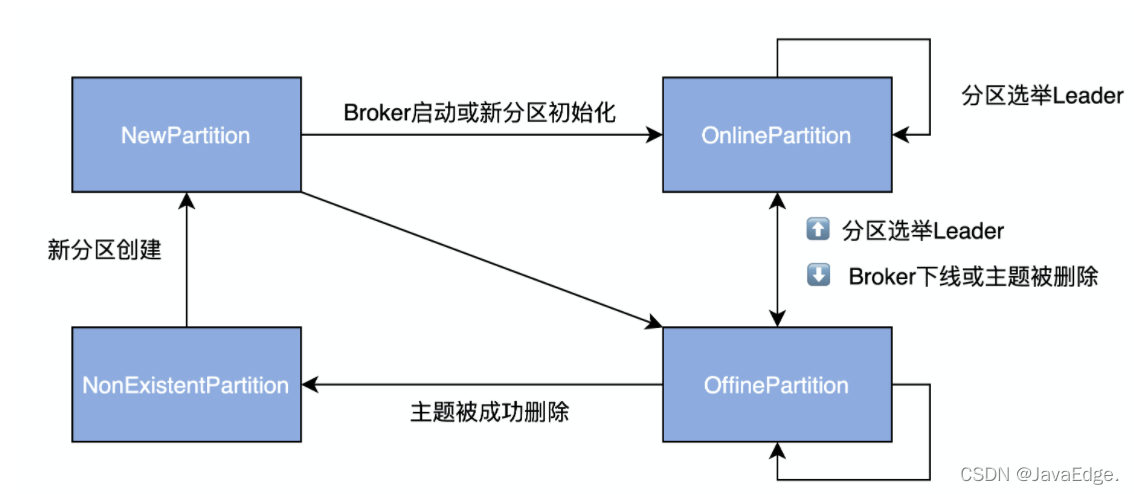
OnlinePartition和OfflinePartition都有一根箭頭指向自己,表明OnlinePartition切換到OnlinePartition的操作是允許的,當磁區Leader選舉發生的時候,就可能出現,
5 磁區Leader選舉場景
磁區Leader選舉,PartitionStateMachine的特有功能,每個磁區都得選舉出Leader,才能正常提供服務,因此,對于磁區,Leader副本很重要,所以必須熟悉Leader選舉的流程實作,
Kafka定義了哪些推選策略,何時執行Leader選舉?
5.1 PartitionLeaderElectionStrategy
磁區Leader選舉:為Kafka主題的某個磁區推選Leader副本,當前磁區Leader選舉有如下場景:

5.2 PartitionLeaderElectionAlgorithms
針對以上場景,磁區狀態機的PartitionLeaderElectionAlgorithms定義如下方法分別負責為每種場景選舉Leader副本:
- offlinePartitionLeaderElection;
- reassignPartitionLeaderElection;
- preferredReplicaPartitionLeaderElection;
- controlledShutdownPartitionLeaderElection,
其中屬offlinePartitionLeaderElection最復雜:
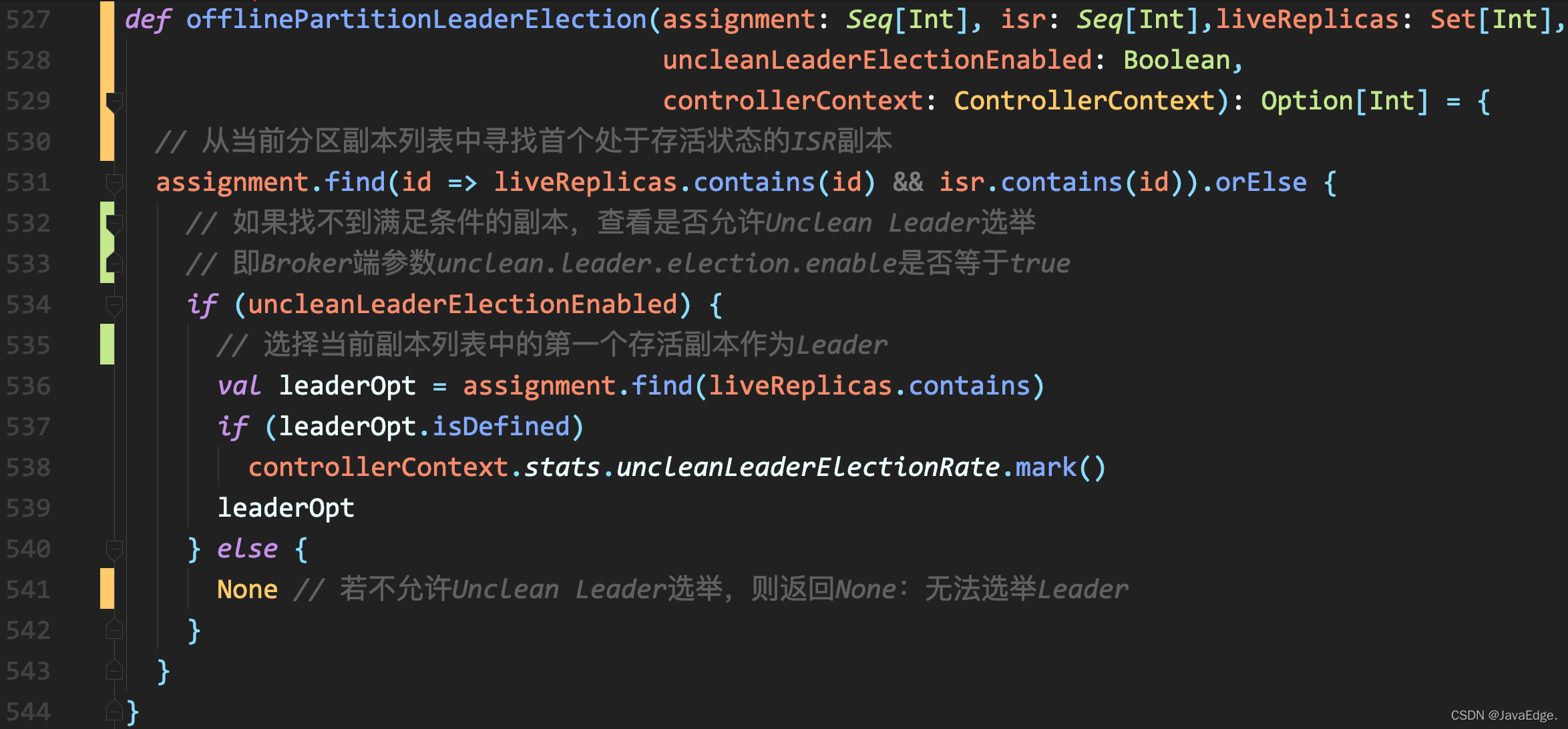
該方法接收如下引數:
1.assignments
磁區的副本串列:Assigned Replicas,AR,創建主題后,使用kafka-topics腳本查看主題時,可見Replicas列資料:主題下每個磁區的AR,assignments引數型別是Seq[Int],說明AR有序,不一定和ISR順序相同
2.isr
保存了磁區所有與Leader副本保持同步的副本串列,Leader副本自己也在ISR中,作為Seq[Int]型別的變數,isr自身也是有順序的,
3.liveReplicas
保存該磁區下所有存活狀態的副本,
-
怎知副本是否存活?
根據Controller元資料快取中的資料,所有在運行中的Broker上的副本,都認為是活的,
4.uncleanLeaderElectionEnabled
默認只要不是由AdminClient發起的Leader選舉,該引數為false:Kafka不允許執行Unclean Leader選舉,
Unclean Leader選舉:在ISR串列為空時,Kafka選擇一個非ISR副本作為新Leader,由于存在丟資料風險,Broker端引數unclean.leader.election.enable默認值為false,禁掉Unclean Leader選舉,
2.4.0.0版本正式支持在AdminClient端為給定磁區選舉Leader:若Leader選舉由AdminClient觸發,默認開啟Unclean Leader選舉,
5.3 具體流程
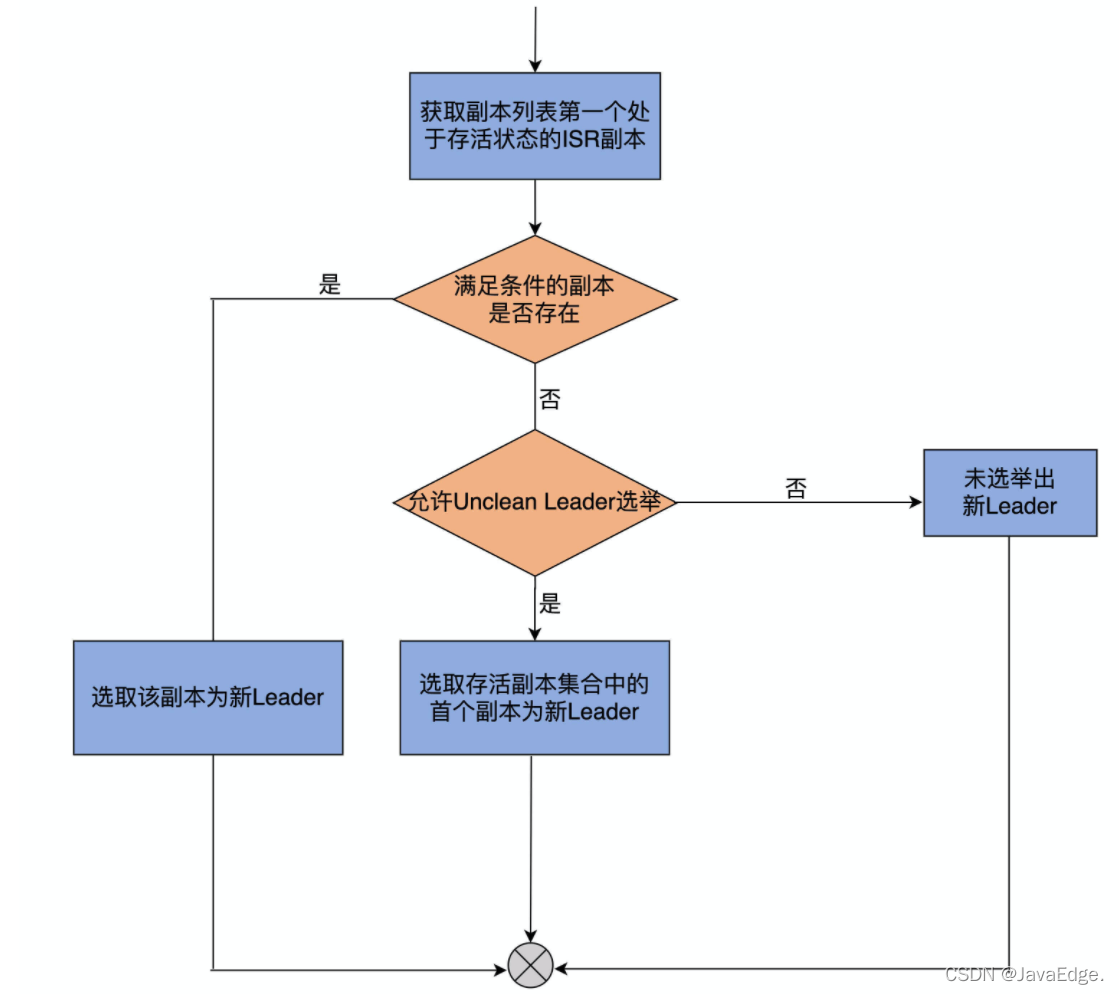
順序搜索AR串列,將第一個滿足如下條件的副本作為新Leader回傳:
- 該副本為存活狀態,即副本所在Broker依然在運行中
- 該副本在ISR串列
若找不到這樣的副本,檢查是否開啟Unclean Leader選舉:
- 若開啟,則降低標準,只要滿足上面第一個條件
- 若未開啟,則本次Leader選舉失敗,無新Leader被選出
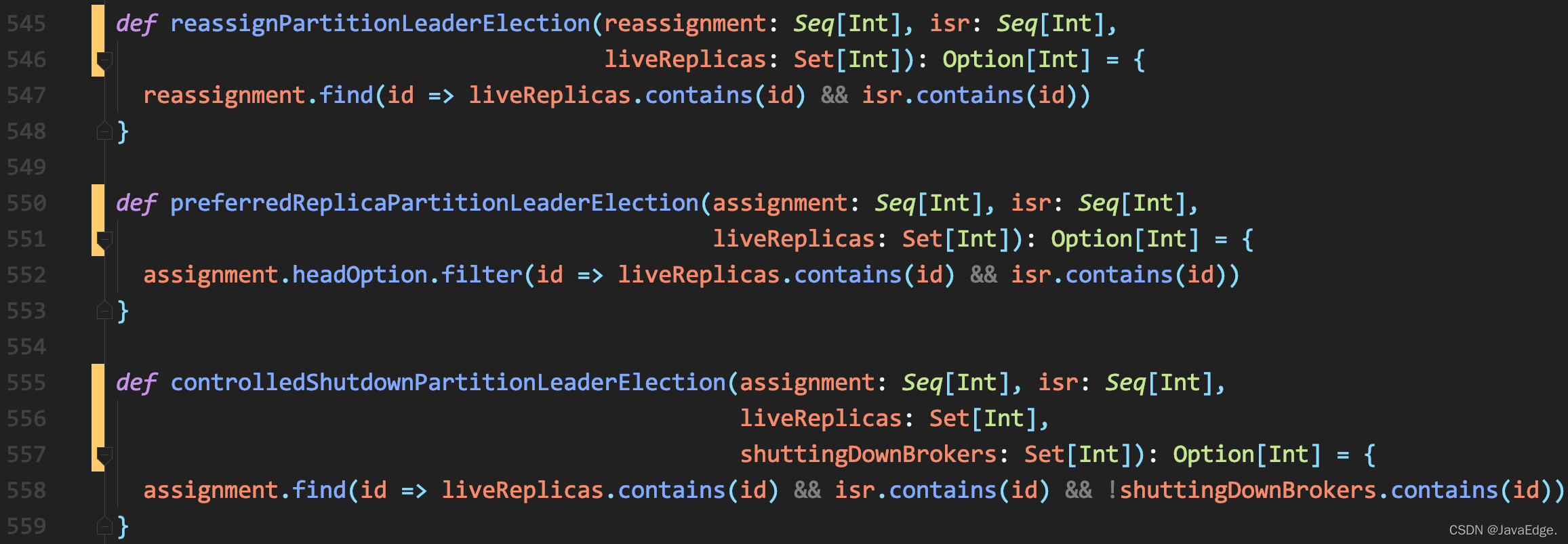
其它選舉策略幾乎相同,都是從AR或給定副本串列中尋找存活狀態的ISR副本,
所以Kafka為磁區選舉Leader就是:AR串列(或給定副本串列)中首個處于存活狀態,且在ISR串列的副本,
6 磁區狀態轉換
PartitionSM的作業原理,
handleStateChanges
入口方法簽名:
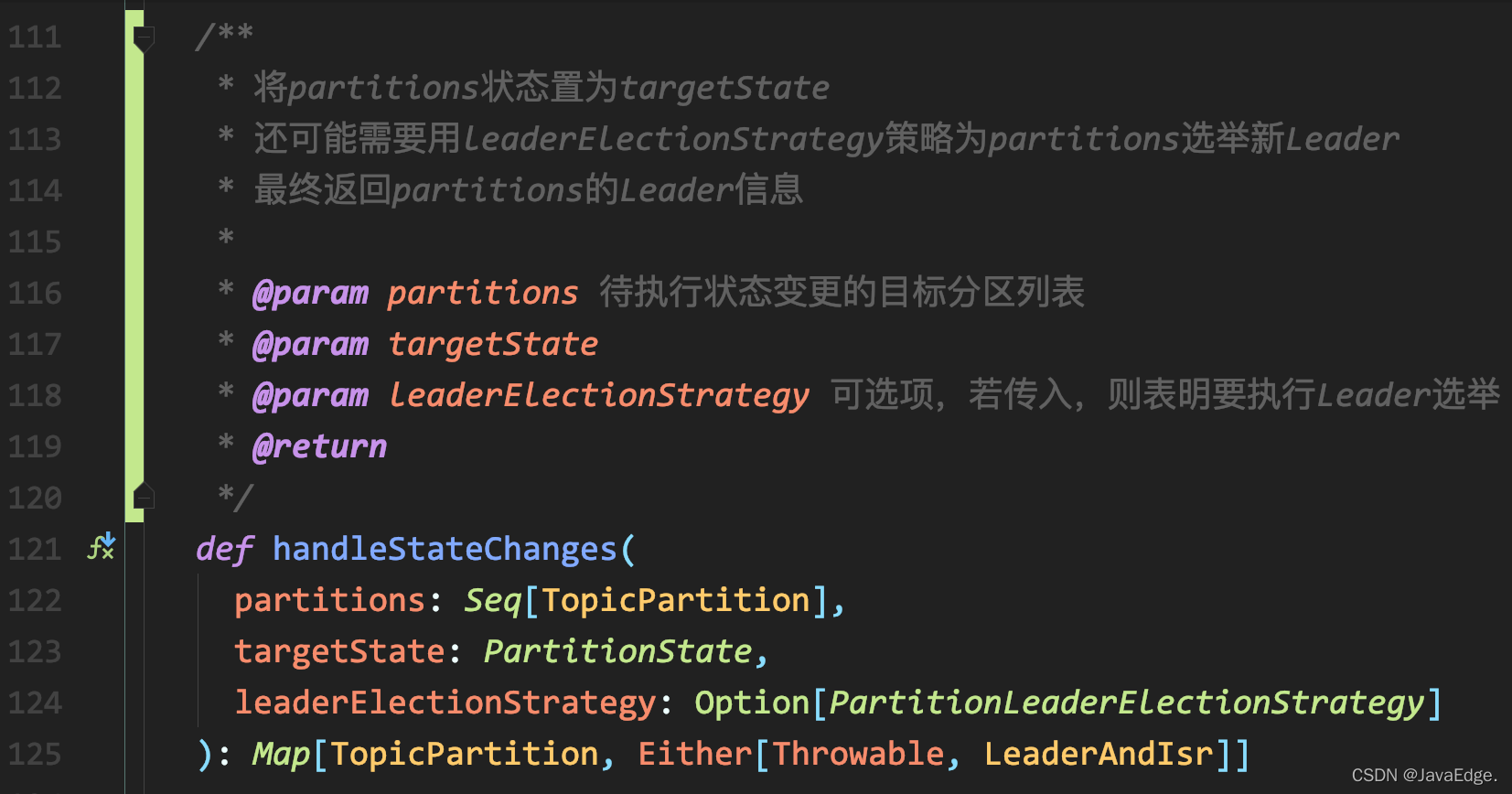
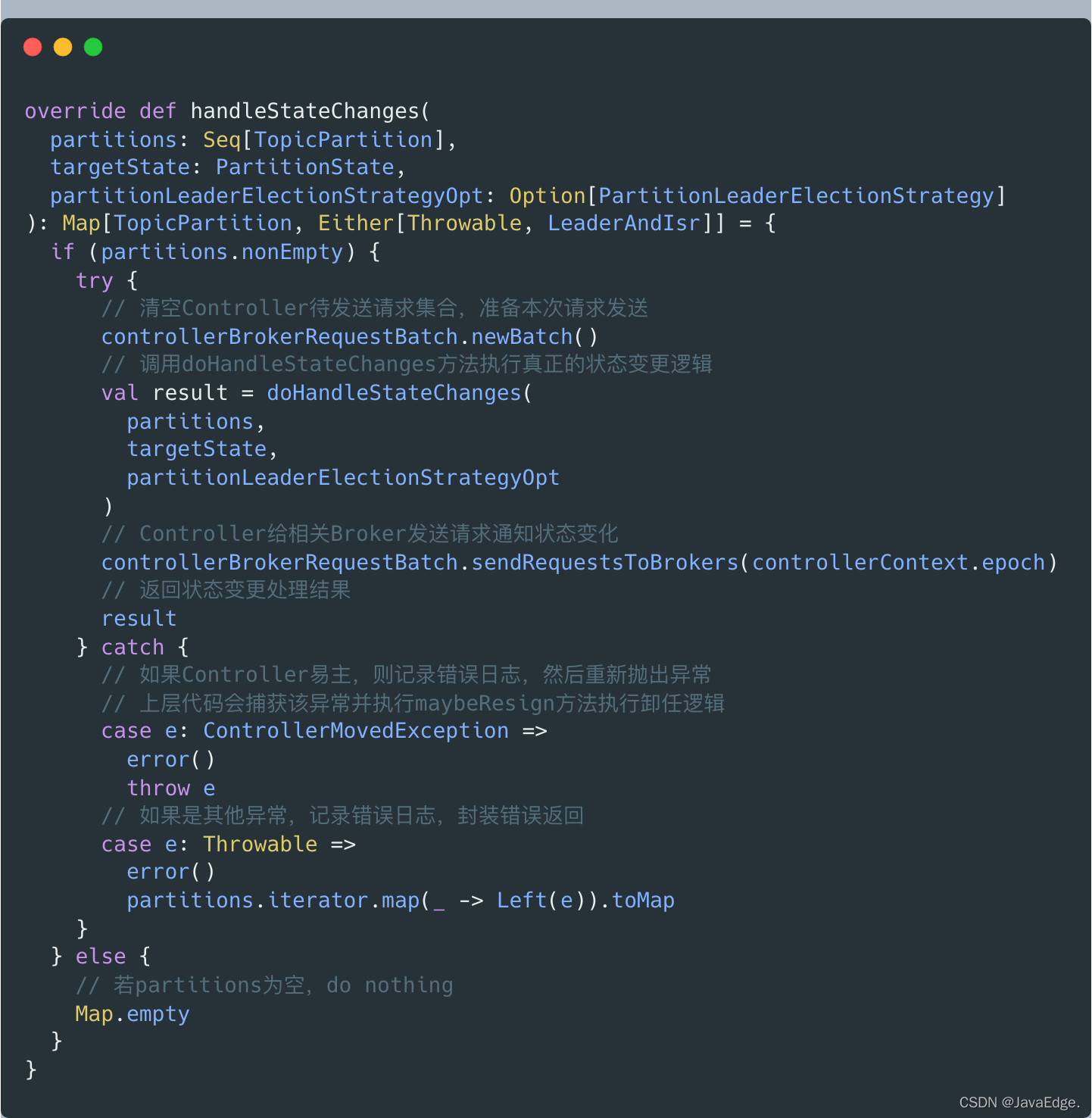
-
呼叫doHandleStateChanges執行磁區狀態轉換
包含確認哪些Broker屬于下一步的相關Broker,給Broker發送哪些請求
-
Controller給相關Broker發送請求,告知它們這些磁區的狀態變更
重點還是
doHandleStateChanges
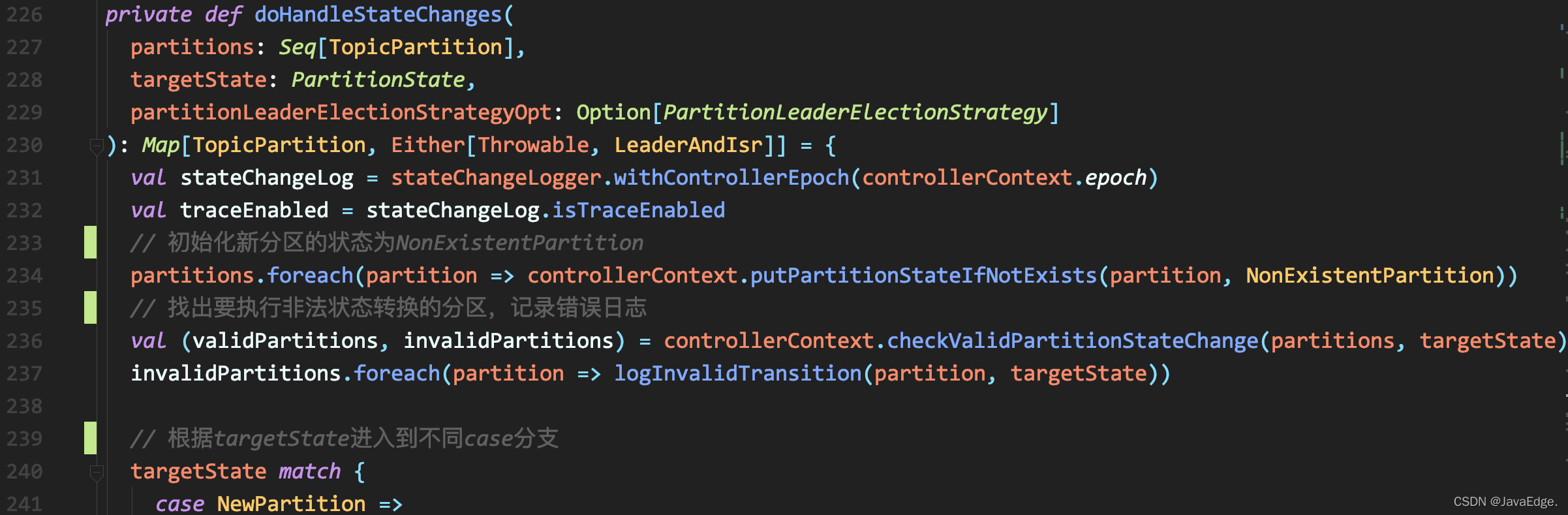
- 首先狀態初始化,即在方法呼叫時,不在【元資料快取】中的所有磁區的狀態被初始化為NonExistentPartition
- 然后,檢查哪些磁區執行的狀態轉換非法&&記錄錯誤日志
- 據合法狀態轉換的磁區串列,進入case分支,磁區狀態只有4個,其case分支代碼遠比ReplicaSM的簡單,且只有OnlinePartition分支較復雜,其余3路僅是將磁區狀態置成目標狀態
重點看OnlinePartition分支:
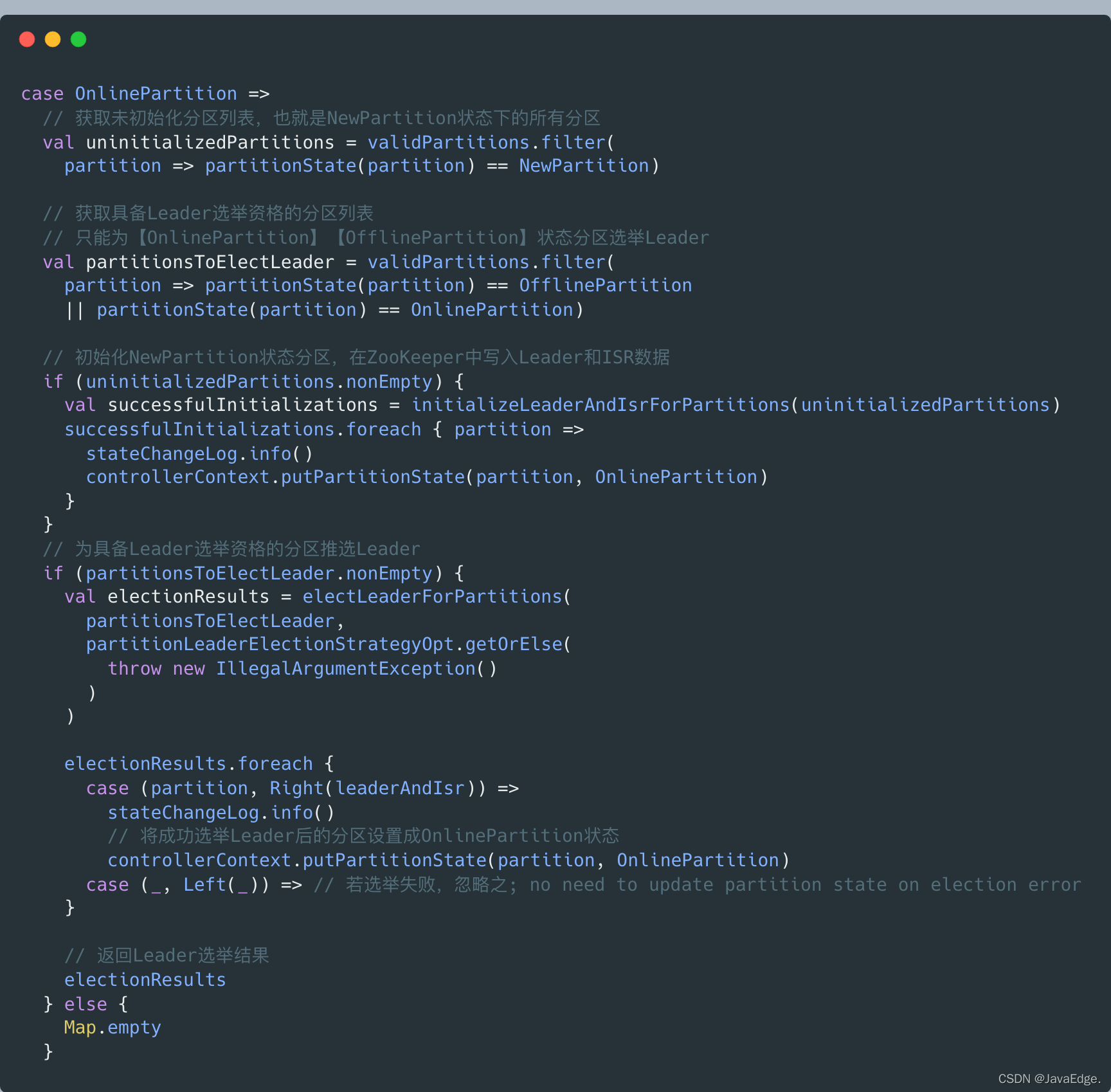
-
初始化NewPartition態的磁區,即在zk中,創建并寫入磁區節點資料,
節點位置:
/brokers/topics/<topic>/partitions/<partition>,每個節點都要包含磁區的Leader和ISR,Leader和ISR的確定規則:
- 選擇存活副本串列的第一個副本作為Leader
- 選擇存活副本串列作為ISR
詳見initializeLeaderAndIsrForPartitions:
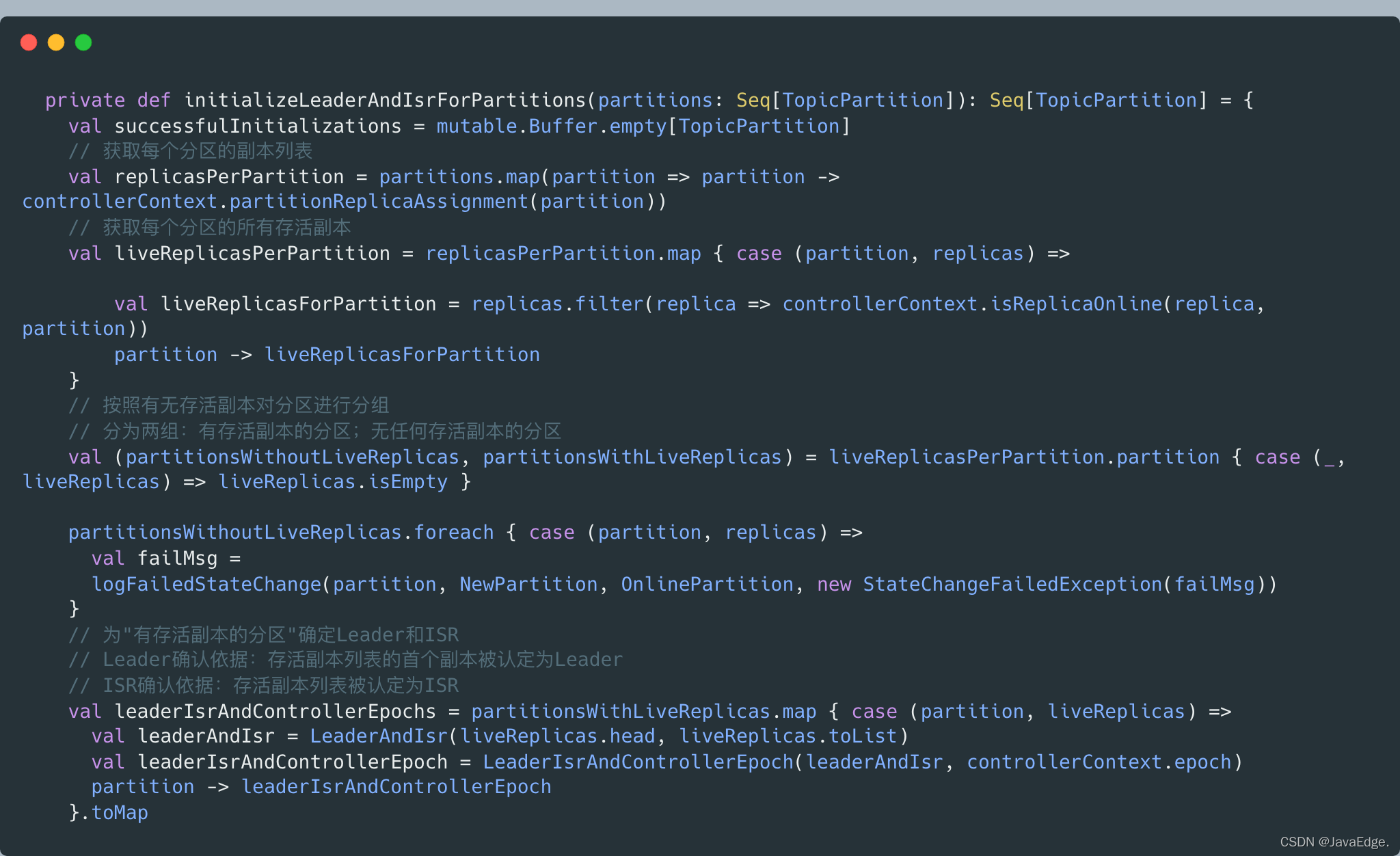
- 為具備Leader選舉資格的磁區推選Leader,呼叫electLeaderForPartitions實作:不斷嘗試為多個磁區選舉Leader,直到所有磁區都成功選出Leader,
選舉Leader的核心代碼:
doElectLeaderForPartitions
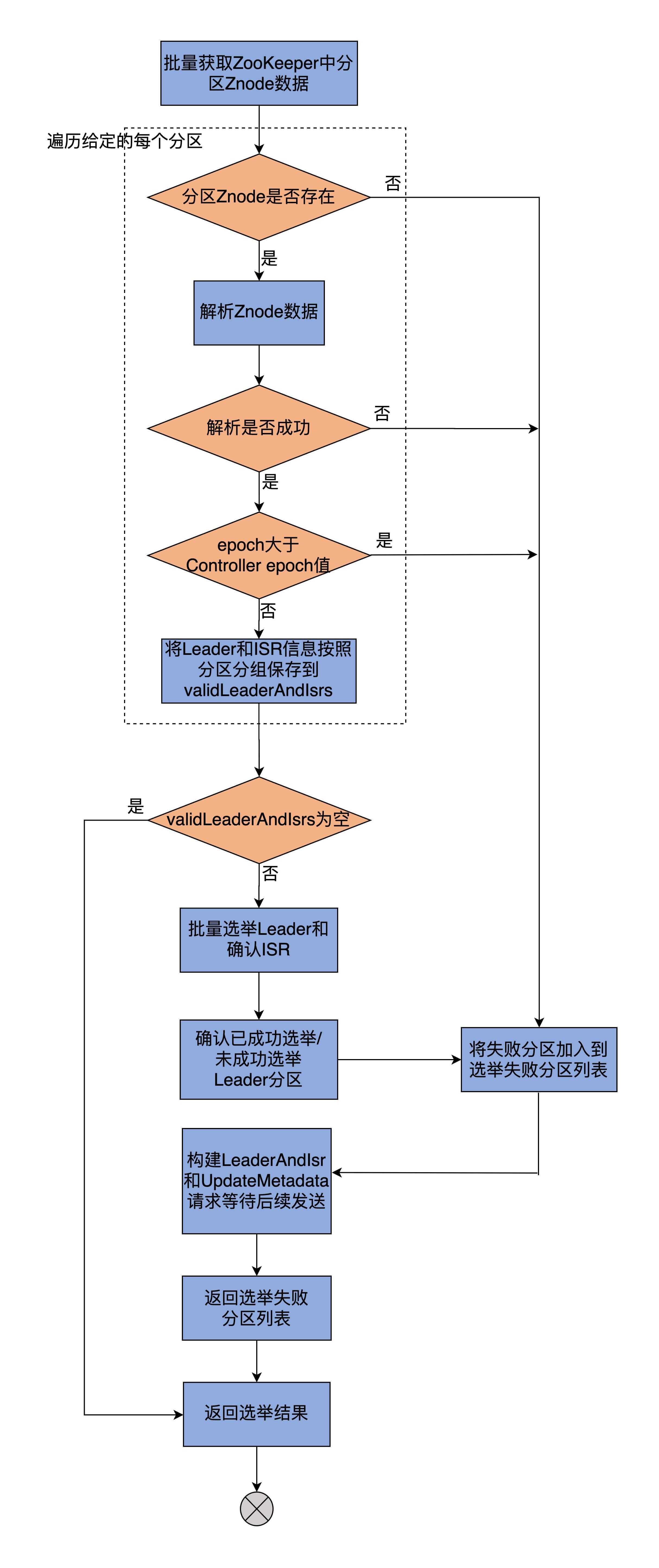
大體分為如下步驟:
- 從zk獲取給定磁區的Leader、ISR資訊,將結果封裝進validLeaderAndIsrs:
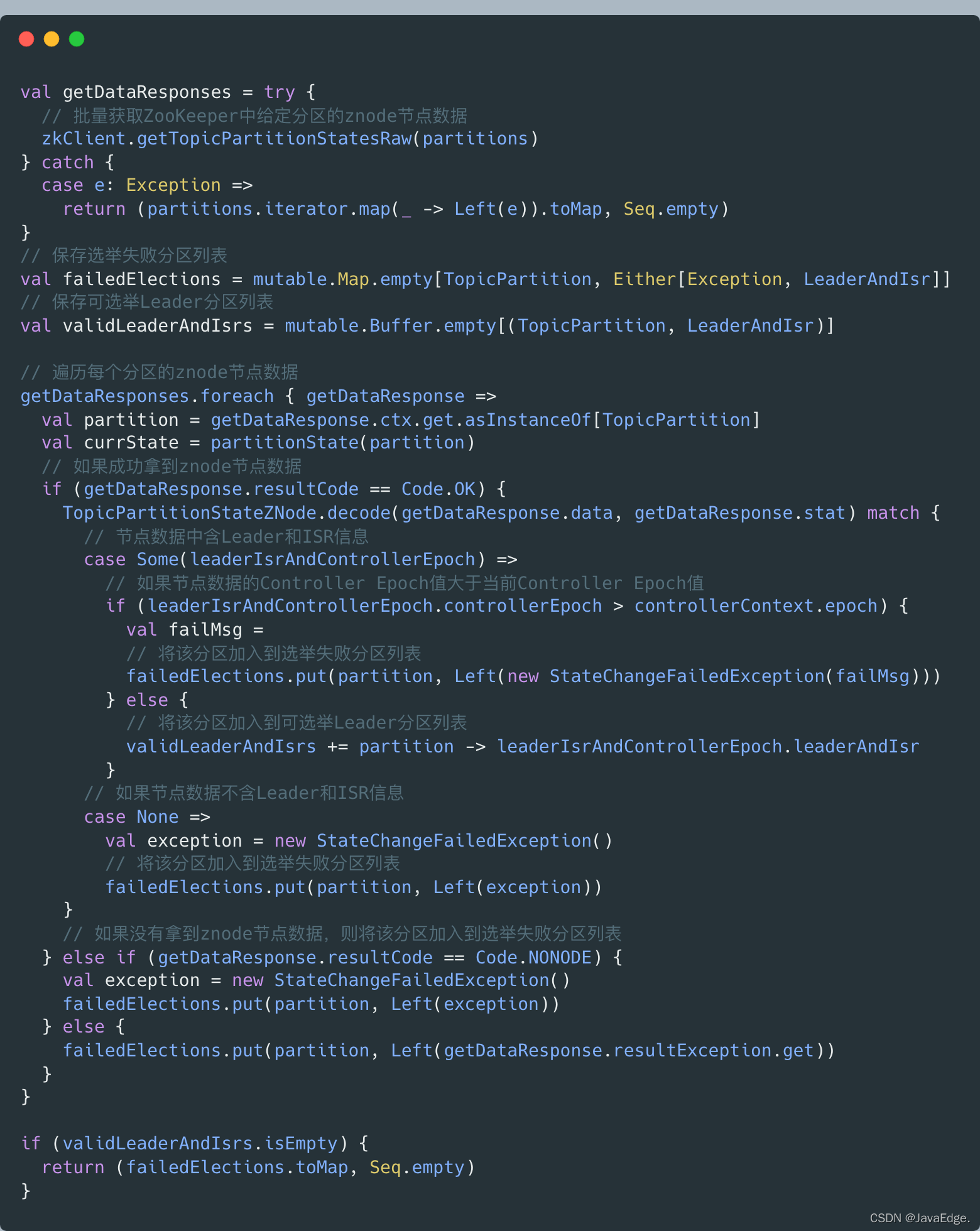
-
開始選舉Leader,并根據有無Leader將磁區進行磁區
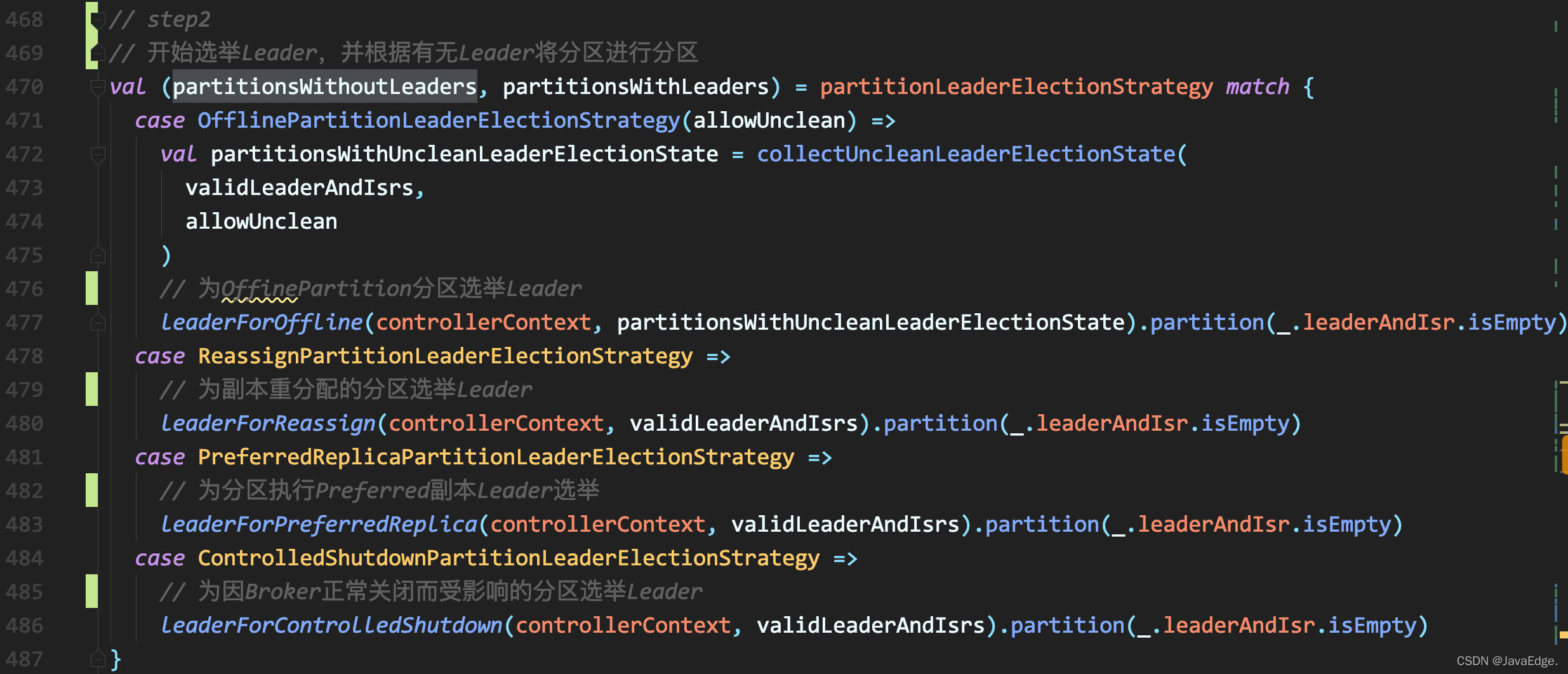
根據給定的PartitionLeaderElectionStrategy,呼叫PartitionLeaderElectionAlgorithms的不同方法執行Leader選舉,同時,區分出成功選舉Leader和未選出Leader的磁區,
4種不同策略定義了4個專屬方法執行Leader選舉,選擇Leader的規則:副本集合中首個存活&&處于ISR中的副本,
-
更新zk節點資料及Controller端元資料快取資訊:
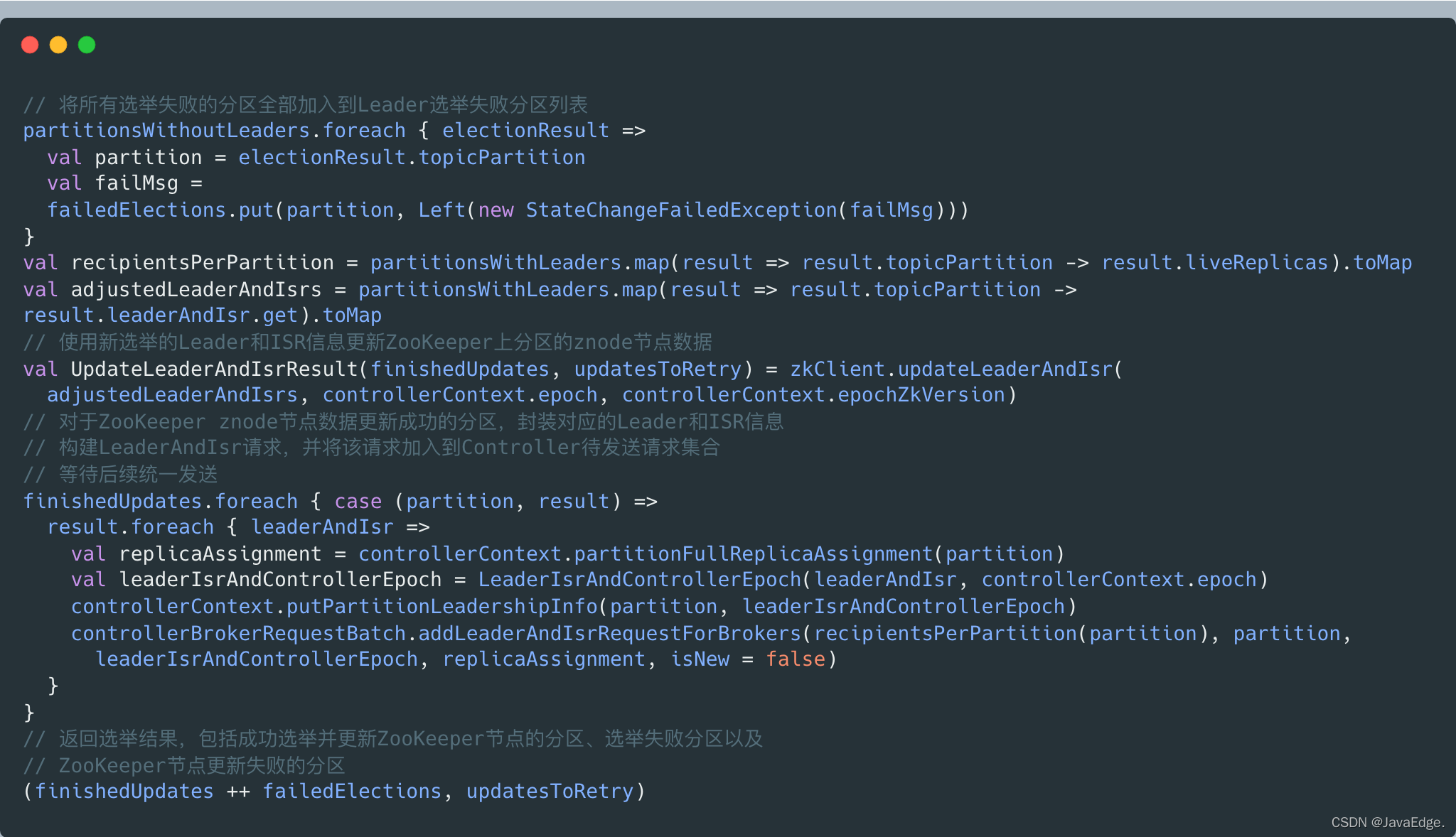
聯想到handleStateChanges的step2是Controller給相關的Broker發送請求:

7 總結
本文深入研究了Kafka磁區狀態機的構造原理和作業機制,
Kafka目前提供4種Leader選舉策略:
- 磁區下線后的Leader選舉
- 磁區執行副本重分配時的Leader選舉
- 磁區執行Preferred副本Leader選舉
- Broker下線時的磁區Leader選舉
這4類選舉策略在選擇Leader上,幾乎都是選擇當前副本有序集合中的、首個處于ISR集合中的存活副本作為新Leader,
PartitionSM是Kafka Controller端定義的磁區狀態機,負責定義、維護和管理合法的磁區狀態轉換,每個Broker啟動時都會實體化一個磁區狀態機物件,但只有Controller所在的Broker才會啟動它,
Kafka磁區有4類狀態:
-
NewPartition
未初始化狀態,處于該狀態下的磁區尚不具備選舉Leader的資格
-
OnlinePartition
磁區正常作業時的狀態
-
OfflinePartition
-
NonExistentPartition
Leader選舉有4類場景:
-
Offline
-
Reassign
-
Preferrer Leader Election
-
ControlledShutdown
每類場景都對應于一種特定的Leader選舉策略,handleStateChanges是入口方法,內部呼叫doHandleStateChanges執行實際Leader選舉功能
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402690.html
標籤:其他
下一篇:011 大資料之Hive