目錄
- Lecture 1: Introduction
- Lecture 2: Properties and Random Graph
- Degree Distribution
- Path Length
- Clustering Coefficient
- Connectivity
- Erdos-Renyi Random Graph Model
- Small-World Model
- Kronecker Graph Model
最近在看 Stanford 的 Machine Learning with Graphs,然后在網上找相關的筆記或者其他人的理解,發現大部分內容是照搬并翻譯 slides, 沒有一些個人的理解,而且很多地方只有前幾個 lecture,所以打算自己整理一個系列的筆記供以后反復溫習,也歡迎大家指正,共同學習,
轉自本人:https://blog.csdn.net/New2World/article/details/105277863
Lecture 1: Introduction
Jure 提出了兩個概念 Network 和 Graph,這兩者的界限很模糊,但大致上我們可以將 Network 視為現實中的圖,而 Graph 是一種更數學的描述方式,在很多復雜的系統之下都有錯綜復雜的關系網,比如食物鏈、化學物質的相互反應等,
課程標題很明確的表示了這個學科研究的是圖,那么怎么研究,主要通過4個方面:
- node classification
- link prediction
- community detection
- network similarity
每一個方面后面當然會涉及到,所以即使現在不知所云也請稍安勿躁,
之前學的關于圖的知識都沒有進行這樣的劃分,但 Jure 提到這里不同的術語之間有微妙的區別(雖然感覺不是那么重要):
| Objects | Interactions | System |
|---|---|---|
| nodes | links | network |
| vertices | edges | graph |
| \(N\) | \(E\) | \(G(N,E)\) |
其他的關于圖的基本知識不再贅述,不清楚的朋友可以先去溫習一下圖的基礎部分,
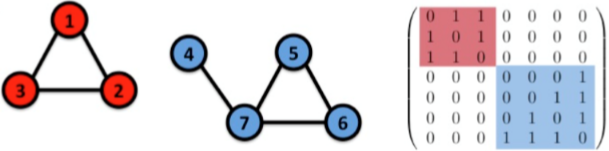
對于無向圖的連通性有個有趣的現象之前沒有注意過:若按一定順序排列節點用鄰接矩陣表示圖的話,非連通圖是嚴格的對角分塊矩陣,
Lecture 2: Properties and Random Graph
描述一個圖的特征一般有這樣幾個:
- degree distribution: \(P(k)\)
- path length: \(h\)
- clustering coefficient: \(C\)
- connected components: \(s\)
Degree Distribution
簡單來說就是度的直方圖,歸一化后就是:\(P(k)=N_k / N\),\(N_k\) 是有 \(k\) 個度的節點個數,
一般來說,圖的度分布是傾斜的,因此在可視化的時候可以選擇用對數坐標,即 \(10^1, 10^2, 10^3 ...\)
Path Length
一般意義上,路徑長度指兩個節點間的最短路徑,而一個圖中最長的最短路徑定義為這個圖的直徑(diameter),然而某些奇奇怪怪的圖可能會有一條很長很長很長的路徑,那么會導致直徑很大,這樣會對圖的描述產生傾斜或者說是偏差,因此一般用平均路徑長度來描述路徑長度,
\[\bar{h}=\frac1{2E_{max}}\sum_{i,j \neq i}h_{ij} \]
\(E_{max}\) 是最大可能的邊數,即 \((n-1)n/2\),然而一般地,只計算存在的邊算,而忽略不相通的節點對,
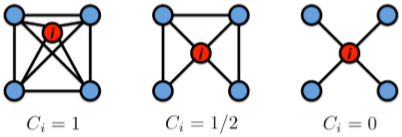
Clustering Coefficient
這個特征是用來衡量一個節點周圍的鄰接節點的互連關系的,簡單來說就是一個節點的一個鄰接節點多大程度上了解其他鄰接節點,表示為
\[C_i=\frac{2e_i}{k_i(k_i-1)} \]
\(e_i\) 是節點 \(i\) 的鄰接節點之間的邊的數量
Connectivity
連通性這個概念很廣泛,包括連通子圖的個數、最大連通子圖的大小等
在有了這些衡量一個圖的特征后,這些指標對我們來說只是一串數字而已,我們想知道這些值是“情理之中”還是“意料之外”,那么就需要一個參照來進行對比,
Erdos-Renyi Random Graph Model
這是一種最簡單的隨機圖模型,它有兩種定義方式:
- 給定 \(n\) 個節點,然后按同一概率 \(p\) 去生成每組節點對的邊
- 給定 \(n\) 個節點,按均勻分布選 \(m\) 條邊
那么通過這樣的模型產生的隨機圖有怎樣的性質呢?
Degree Distribution
度的分布服從伯努利分布,即
\[P(k)=\begin{pmatrix}n-1\\k\end{pmatrix}p^k(1-p)^{n-k-1} \]
那么根據伯努利分布的性質,其均值和方差分別為
- \(\bar{k}=p(n-1)\)
- \(\sigma^2=p(1-p)(n-1)\)
這里 slide 上給出了一個運算式
\[\frac{\sigma}{\bar{k}}=\big[\frac{1-p}p\frac1{n-1}\big]^{1/2} \]
Jure 的原話是:you can then ask how does the variance change as a function of the average degree.
也就是說這里服從大數定理,當圖的規模足夠大時,度的分布會變得很“窄”,即可以視作所有節點都有 \(\bar{k}\) 的度
Clustering Coefficient
根據 clustering coefficient 的定義,我們需要知道節點的鄰接節點間的邊的數量,由于在 ER 隨機圖中邊是 i.i.d. 的,所以期望為
\[E[C_i]=\frac{E[e_i]}{k_i(k_i-1)}=\frac{p\frac{k_i(k_i-1)}{2}}{k_i(k_i-1)}=p=\frac{\bar{k}}{n-1}\approx\frac{\bar{k}}{n} \]
也就是說,隨著圖的規模增大,clustering coefficient 的值不斷減小,
Path Length
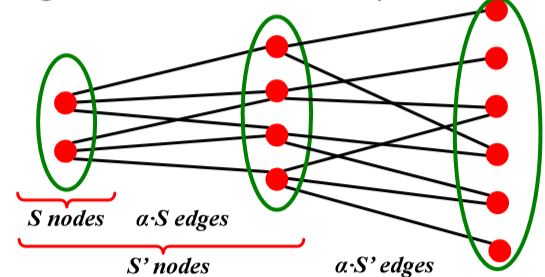
在討論路徑長度之前要先引入一個概念:Expansion \(\alpha\)
\[\forall S \subseteq V:\#(edges\ leaving\ S)\geq\alpha\min(|S|,|V\text{\textbackslash}S|) \]
這個定義很數學,通俗地解釋就是把一個圖的節點分成兩堆,使得連接兩部分的邊最少,那么通過這個我們怎么推導路徑呢?
我們先回憶下 BFS 的作業原理,如下圖,從一個點出發開始遍歷整個圖,如果圖是連通的,那么第二層應該是初始點的鄰接點,然后依次展開直到覆寫圖中所有點,假設遍歷的是這里的 ER 隨機圖,那么這棵樹的深度就應該是 \(\log_{np}n=\log n / \log np\)
但這里沒有涉及到 expansion 這個概念呀!應該說沒有顯示地說明這個概念,因為我們限制了 ER 圖,更一般的圖的度不一定是 \(np\),因此需要用 expansion 的 \(\alpha\) 來替換這里特殊的 average degree,如此一來,將平均路徑長度推廣為 \(O((\log n) / \alpha)\)
Connectivity
在邊的概率 \(p\) 逐漸增大程序中可以發現,當 \(p=1/(n-1)\) 時,即平均度為 \(1\) 時,giant component 開始出現,
這樣我們就有了一個可以與真實網路進行對比的模型了
- [x] average path length
- [x] giant connected component
- [ ] clustering coefficient
- [ ] degree distribution
通過對比我們可以發現這個隨機圖模型的特征只在路徑長度和最大連通子圖上和真實網路差不多,但其余性質上差得很遠,這樣也說明了真實世界的網路不是隨機的,其背后有復雜的關系等待我們去發現,
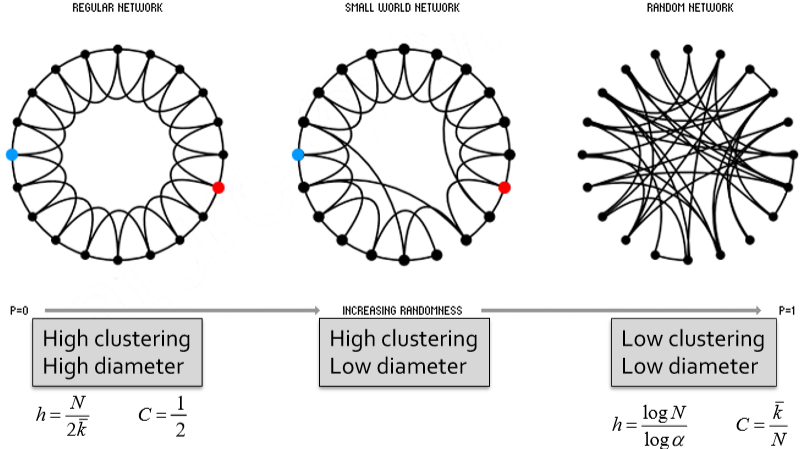
Small-World Model
通過對 ER 圖的分析我們發現這種簡單的隨機圖丟失了聚類資訊,即 local structure,然而,單純的加上 local connections 會導致圖的平均路徑增加而破壞我們原本已經吻合了的性質,因此提出了這個 Small-World 模型,
這里 Jure 對為什么 triadic closure 會導致網路直徑增加的解釋有點不清楚,按理說朋友的朋友就是我的朋友這一點能縮短路徑長度呀,我的理解是這里應該突出的是 local 這一條件,以交通網為例,如果現在只有相鄰城市間有交通線路,那么我從四川到北京就得途經“四川-陜西-山西-河北-北京”,但如果我有四川到北京的直飛線路呢?那直觀上不就直接“四川-北京”了嗎,
這個 Small-World 模型首先為了確保有 local structure,將自己初始化為下圖的樣子(regular ring lattice),然后依概率將一條邊的一個端點連接到任意一個不同節點上,如此,初始化保證了 clustering coefficient,而 rewiring 引入了隨機性從而縮減了網路直徑,

但是這里需要注意的是如果 rewiring 的概率太高或太低都不行,
- 太低,約等于不做
- 太高,破壞了區域結構
雖然小世界模型能比較好的模擬真實網路的區域結構,但它沒法吻合度的分布情況,
Kronecker Graph Model
這個模型有兩個突出的優勢
- 可并行,快,適合生成大規模的圖
- 遵從一些真實網路的“規則”
Idea:遞回地生成一張圖
每個公司內都有很多部門,各個部門有管理層和不同的事業群,每個事業群內又有組長和員工,這樣的結構在大部分公司里都差不多,那么推廣這個規律,我們先定義一個小群體內的網路結構,然后遞回地使用這樣的結構來構建更大的圖,
定義 Kronecker product
\[C=A \otimes B \doteq \begin{pmatrix} a_{1,1}B & a_{1,2}B & ... & a_{1,m}B \\ a_{2,1}B & a_{2,2}B & ... & a_{2,m}B \\ & ... & ... \\ a_{n,1}B & a_{n,2}B & ... & a_{n,m}B \end{pmatrix}\]
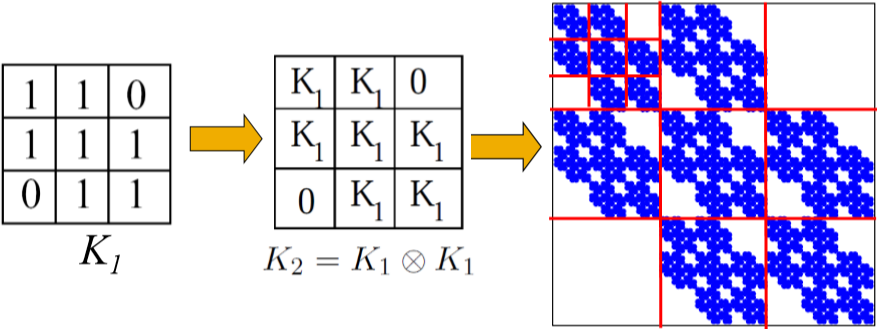
如果用鄰接矩陣來直接生成那太死板了,所以為引入隨機性將鄰接矩陣換成概率矩陣,即矩陣的每個元素表示對應節點對右邊的概率,這樣通過 Kronecer product 最終得到整個網路的邊的概率分布圖,然后我們再通過每個區域的概率遞回地選擇邊來得到圖的一個 realization,
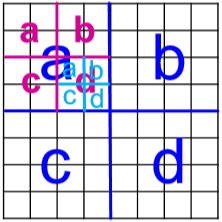
這種方法選邊時不可避免地會遇到重復邊,但概率很小,就算遇到了,reinsert 就行了,無傷大雅,
需要確定邊的條數,而這一般依賴經驗
實驗證明 Kronecker 圖在各種性質上都能較好地擬合真實的網路,但這個模型生成的圖的 degree distribution 并不是平滑的,直觀上說,按初始定義的 block structure 進行遞回所得到的圖可能的確存在這個問題,即某些部分連接緊密有些地方稀疏,而這種差異并不連續,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41276.html
標籤:其他