簡介
- 介紹計算框架對java開發的重要性
- 介紹flink的架構
- 介紹flink的編程模型:DataStream、DataSet、Table API、SQL
- 介紹flink的部署
計算框架
每個Java開發一定要懂至少一個流行的計算框架,因為現在的資料量越來越大,光靠資料庫或者手寫代碼去實作難度已經越來越大,不僅涉及到資源調度,還要考慮分布式,并且還要考慮高可用、容錯等等,因此我們需要借助現有的分布式計算框架來實作我們大規模分布式計算的目的,不僅能簡化我們的程式設計,使我們更關注業務,并且也能防止重復造輪子,
隨著資料規模的不斷增加,相應的計算框架也在不停的升級迭代中,計算框架經歷了如下幾個階段:
- 第一代批量計算框架MapReduce,計算模型檢查,延遲高,
- 第二代流式計算Storm、Spark,實時計算的控制有限,記憶體要求高,
- 第三代批流一體計算Flink,批處理和流處理統一結合,控制靈活,
flink可以說是繼承了歷代計算引擎的各種優點,拋棄各種缺點而造就的高性能實時計算框架,這也是目前flink框架比對火熱的原因,本文將主要介紹flink各個基本概念,讓開發能直接上手使用,
Flink架構
flink適應場景
-
事件驅動應用
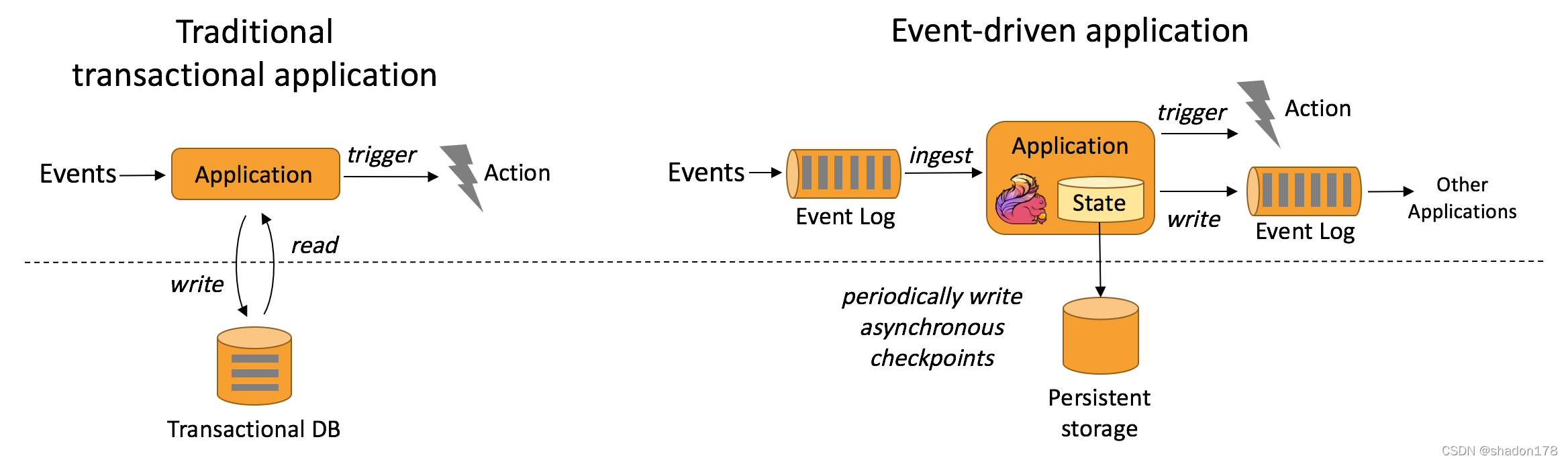
根據到來的資料和事件條件觸發計算的流程操作, -
流批分析:
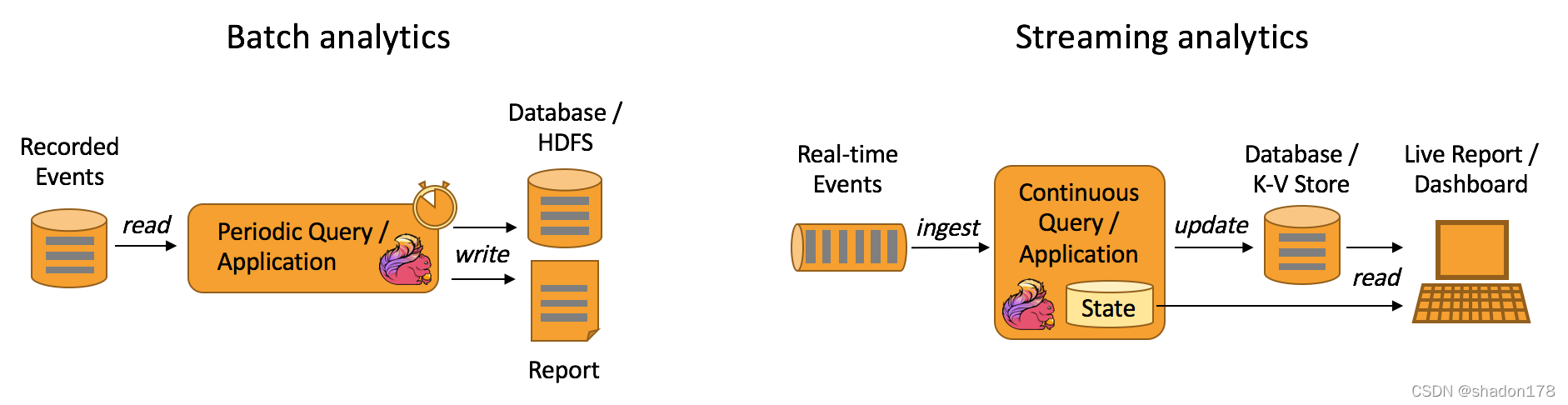
流式計算和批處理 -
資料管道 & ETL
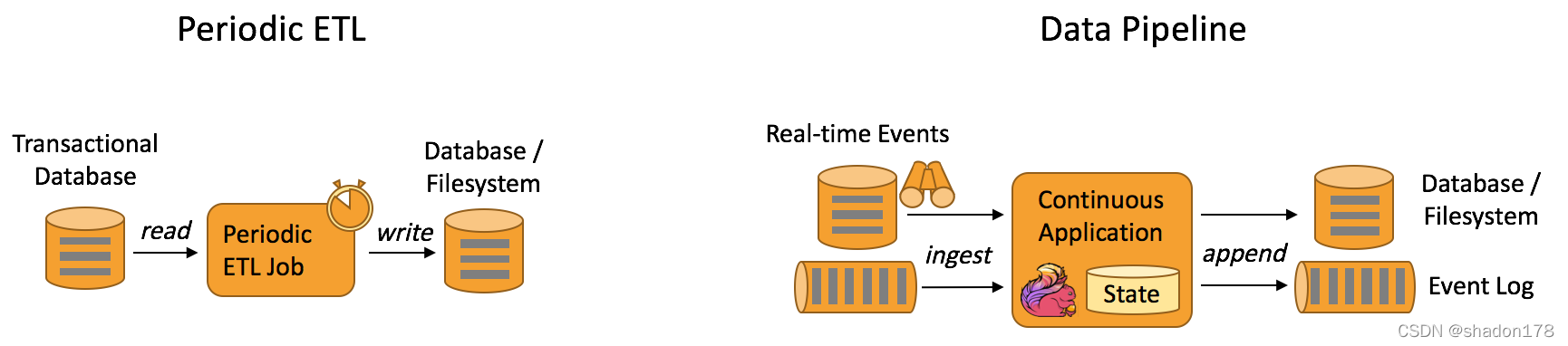
也是我們常說的ETL工具,也是目前我做資料抽取經常用到的工具,
集群架構
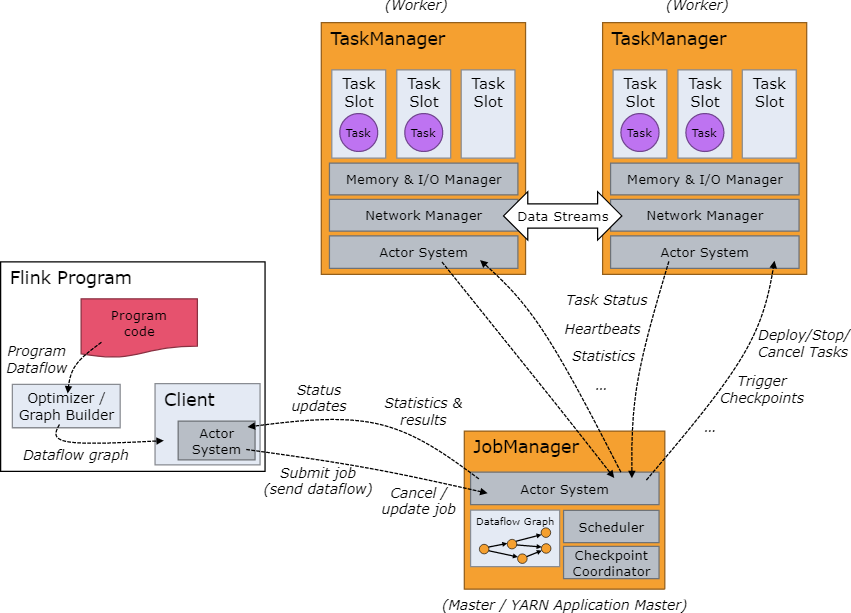
JobManager
Flink集群由一個JobManager行程和多個TaskManager行程組成,實際運行的JobManager只有一個,在高可用的環境下,可以存在多個JobManager,但是只有一個leader角色,其他都處于standby狀態,待leader宕機時再轉變成leader角色繼續服務,
JobManager負責任務的劃分、資源調度、分布式的協調等,其中又有3給主要組件組成:
- ResourceManager
ResourceManager 負責 Flink 集群中的資源調度、回收、分配 - 它管理任務槽(task slots),這是 Flink 集群中資源調度的單位,后面會詳細講解任務槽的概念, - Dispatcher
Dispatcher 用來接受客戶端提叫過來的計算程式,并為每個提交的作業啟動一個新的 JobMaster,此外,還提供一個web界面用于查看執行情況、日志、監控指標等, - JobMaster
JobMaster 負責管理單個任務集(JobGraph)的執行,Flink 集群中可以同時運行多個作業,每個作業都有自己的 JobMaster,
TaskManager
TaskManager負責執行作業中的任務,并且快取資料以及與其他taskmanger交換資料,
在TaskManager 中資源調度的最小單位是槽,TaskManager 中槽的數量表示并發處理任務的數量,請注意一個槽中可以執行多個算子,.
任務和算子鏈
多個算子操作可以形成算子鏈,例如:map().keyBy().windows().apply().sink(),有5個算子,其中map、keyBy().windows().apply()、sink形成3個任務,每個任務由單獨的執行緒執行,在執行程序中又將任務劃分為具體的子任務,每個子任務負責部分資料的執行,如圖所示:
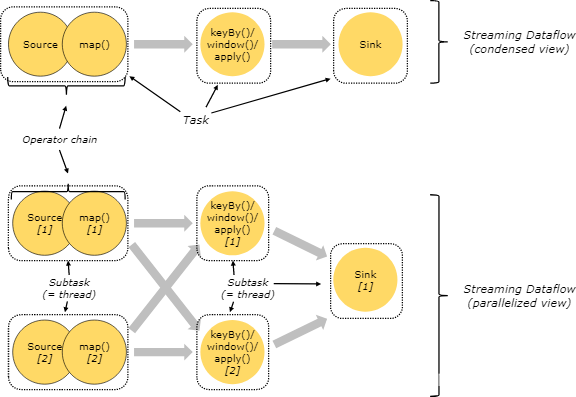
圖的上半部分為任務視角,下半部分為行程視角,請仔細揣摩,
槽和資源劃分
每個TaskManager都是一個 JVM 行程,可以在單獨的執行緒中執行一個或多個子任務,為了控制一個 TaskManager 中接受多少個 任務,就有了所謂的槽,
每個槽平分TaskManager的托管記憶體,注意槽只分配給某個作業的任務,因此不同的作業任務執行時不會共用槽,也就形成了作業之間的資源隔離,但是一個作業的任務是可以公用槽的,槽只是隔離了記憶體使用,并沒有隔離CPU資源,
通過調整槽的數量,用戶可以定義子任務如何互相隔離,如果每個 TaskManager 有一個槽,這意味著每個 task 組都在單獨的 JVM 中運行,更多個槽意味著更多子任務共享同一 JVM,同一 JVM 中的 task 共享 TCP 連接(通過多路復用)和心跳資訊,它們還可以共享資料集和資料結構,從而減少了每個 task 的開銷,
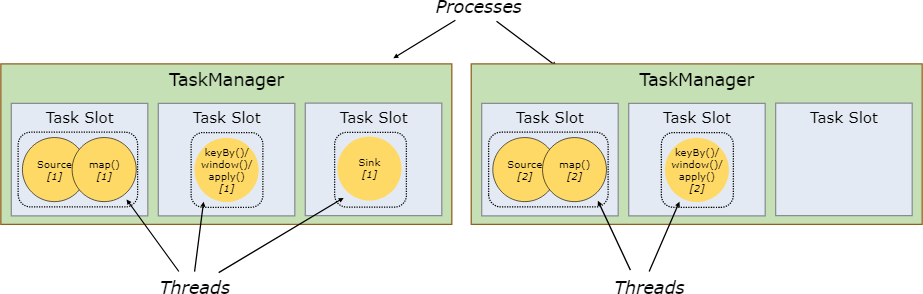
默認情況下,Flink 允許子任務共享槽,即便它們是不同的任務的子任務,但是必須是同一個作業,可以將整個作業的子任務都放入到一個槽中執行,允許槽共享有兩個主要優點:
Flink 集群所需的槽和作業中使用的最大并行度恰好一樣,無需計算程式總共包含多少個任務(具有不同并行度),
容易獲得更好的資源利用,如果沒有槽共享,非密集 子任務(source/map())將阻塞和密集型 子任務(window) 一樣多的資源,通過槽的共享,我們示例中的基本并行度從 2 增加到 6,可以充分利用分配的資源,同時確保繁重的子任務在 TaskManager 之間公平分配,

Flink集群環境(flink on yarn)
flink有多種集群的執行環境,大家必須根據不同的任務需要,選擇適當的集群環境進行執行,
Flink Session 集群
集群生命周期:在 Flink Session 集群中,客戶端連接到一個預先存在的、長期運行的集群,該集群可以接受多個作業提交,即使所有作業完成后,集群(和 JobManager)仍將繼續運行直到手動停止 session 為止,因此,Flink Session 集群的壽命不受任何 Flink 作業壽命的約束,
資源隔離:TaskManager槽由 ResourceManager 在提交作業時分配,并在作業完成時釋放,由于所有作業都共享同一集群,因此在集群資源方面存在一些競爭 — 例如提交作業階段的網路帶寬,此共享設定的局限性在于,如果 TaskManager 崩潰,則在此 TaskManager 上運行 task 的所有作業都將失敗;類似的,如果 JobManager 上發生一些致命錯誤,它將影響集群中正在運行的所有作業,
其他注意事項:擁有一個預先存在的集群可以節省大量時間申請資源和啟動 TaskManager,有種場景很重要,作業執行時間短并且啟動時間長會對端到端的用戶體驗產生負面的影響 — 就像對簡短查詢的互動式分析一樣,希望作業可以使用現有資源快速執行計算,
任務提交方式:
./bin/flink run -t yarn-session \
-Dyarn.application.id=application_XXXX_YY \
./examples/streaming/TopSpeedWindowing.jar
Flink pre-Job 集群
集群生命周期:在 Flink Job 集群中,可用的集群管理器(例如 YARN)用于為每個提交的作業啟動一個集群,并且該集群僅可用于該作業,在這里,客戶端首先從集群管理器請求資源啟動 JobManager,然后將作業提交給在這個行程中運行的 Dispatcher,然后根據作業的資源請求惰性的分配 TaskManager,一旦作業完成,Flink Job 集群將被拆除,
資源隔離:JobManager 中的致命錯誤僅影響在 Flink Job 集群中運行的一個作業,
其他注意事項:由于 ResourceManager 必須應用并等待外部資源管理組件來啟動 TaskManager 行程和分配資源,因此 Flink Job 集群更適合長期運行、具有高穩定性要求且對較長的啟動時間不敏感的大型作業,
以前,Flink Job 集群也被稱為 job (or per-job) 模式下的 Flink 集群,
Kubernetes 不支持 Flink Job 集群,
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
detached 引數表明任務一旦提交,客戶端行程就終止了,集群會繼續負責執行,
detached模型下如果需要繼續查詢任務執行情況,可以使用如下命令:
# 查詢集群上運行的任務
./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
# 取消正在運行的任務
./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
Flink Application 集群
集群生命周期:Flink Application 集群是專用的 Flink 集群,僅從 Flink 應用程式執行作業,并且 main()方法在集群上而不是客戶端上運行,提交作業是一個單步驟程序:不需要先啟動 Flink 集群,然后將作業提交到現有的 session 集群;相反,將應用程式邏輯和依賴打包成一個可執行的作業 JAR 中,并且由flink集群(ApplicationClusterEntryPoint)負責呼叫 main()方法來提取 JobGraph,例如,這允許你像在 Kubernetes 上部署任何其他應用程式一樣部署 Flink 應用程式,因此,Flink Application 集群的壽命與 Flink 應用程式的壽命有關,
資源隔離:在 Flink Application 集群中,ResourceManager 和 Dispatcher 作用于單個的 Flink 應用程式,相比于 Flink Session 集群,它提供了更好的隔離,
Flink Job 集群可以看做是 Flink Application 集群”客戶端運行“的替代方案,
任務提交方式:
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
Flink的編程模型
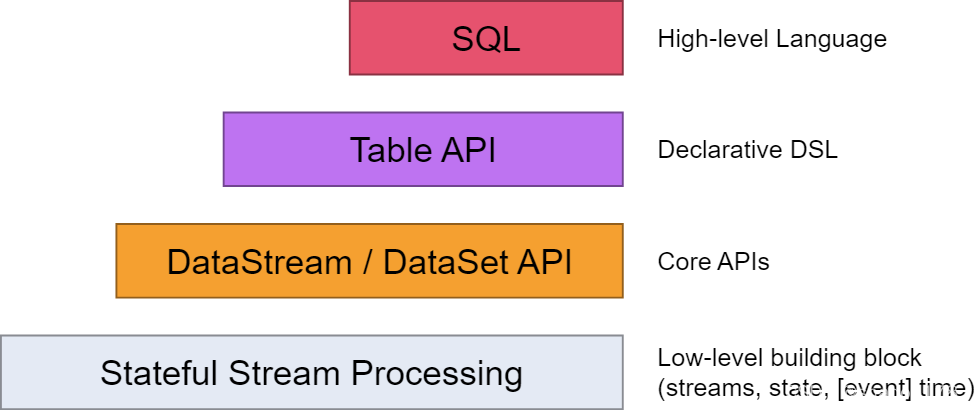
我們常用的Flink編程API有DataStream、DataSet、Table、SQL,每種API的抽象級別如圖所示,最底層的Stateful Stream Processing是flink內部核心API,一般我們不會用到,之上就是我們常用的DataStream和DataSet API,分別代表流式和批處理的API,但隨著Flink的批流一體,已經基本都是用DataStream來代替DataSet來使用了,在此之上就是Table API,可以像操作資料庫表一樣來進行關聯、統計、聚合等操作,最上層就是我們比較熟悉的SQL陳述句了,可以用簡單的SQL陳述句完成資料的處理操作,
DataStream
常用算子
1、map
DataStream → DataStream
簡單的轉換操作,將一個輸入轉換成一個輸出,
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
2、flatMap
DataStream → DataStream
簡單的轉換操作,將一個輸入轉換成0個或多個輸出,
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
3、Filter
DataStream → DataStream
過濾操作,只保留回傳true的資料,
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
4、KeyBy
DataStream → KeyedStream
磁區操作,根據指定的函式對所有資料進行磁區,函式回傳值相同的資料歸為一個磁區,
注意:由于結果取hash進行磁區,因此key必須要實作hashcode,且不能使用陣列,
dataStream.keyBy(value -> value.getSomeKey());
dataStream.keyBy(value -> value.f0);
5、Reduce
KeyedStream → DataStream
根據指定的操作將多個資料項合并成一個,
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
return value1 + value2;
}
});
6、Window
KeyedStream → WindowedStream
將已經磁區的資料,根據時間視窗再進行劃分,例如:根據第一個欄位進行磁區,然后根據資料到來時間,每隔5秒形成一個子磁區,代碼如下:
dataStream
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)));
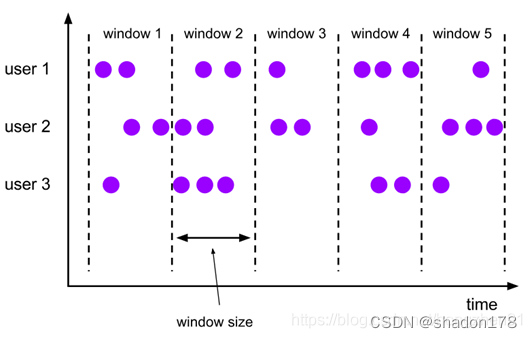
7、WindowAll
DataStream → AllWindowedStream
類似window操作,但是不需要提前磁區,可以作用于整個資料流(DataStream)上
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
8、Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
對每個時間磁區進行具體操作,例如計算每個時間磁區內的總和:
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {
public void apply (Tuple tuple,
Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {
public void apply (Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
引數介紹:
- tuple: 代表上一步的key
- windows: 代表當前視窗
- values: 代表當前視窗內的所有資料
- out: 用于輸出資料
9、WindowReduce
WindowedStream → DataStream
在每個時間視窗磁區上進行reduce操作,也就是合并操作,例如求和、取平均等等操作,
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {
public Tuple2<String, Integer> reduce(
Tuple2<String, Integer> value1,
Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);
}
});
10、Union
DataStream* → DataStream
將所有流的資料合并起來,形成一個流,如果相同的流合并會導致資料重復一遍,只能對相同型別資料的流進行合并,
dataStream.union(otherStream1, otherStream2, ...);
11、Window Join
DataStream,DataStream → DataStream
Join two data streams on a given key and a common window.
將2個流根據指定條件join起來,類似于資料庫中2個表的join操作,然后再形成時間視窗:
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...});
12、Interval Join
KeyedStream,KeyedStream → DataStream
將2給KeyedStream流用相同的key在指定的時間間隔內join起來,2個流的時間間隔滿足條件:
e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound.
// join后的流滿足條件:
// key1 == key2 && leftStream.Timestamp - 2s < rightStream.Timestamp < leftStream.Timestamp + 2s
leftStream.intervalJoin(rightStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // 指定時間誤差上限和下限
.upperBoundExclusive(true) // 可選引數:不包含上限
.lowerBoundExclusive(true) // 可選引數:不包含下限
.process(new IntervalJoinFunction() {...});
13、Window CoGroup
DataStream,DataStream → DataStream
與join類似,但是它在一個流中沒有找到與另一個匹配的資料還是會輸出,
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...});
14、Connect
DataStream,DataStream → ConnectedStream
connect類似于union操作,將2給流的資料合并,但是union只能對同型別的流進行操作,而connect可以對不同型別的流進行合并,此外,可以在2給流之間共享狀態,
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
15、CoMap, CoFlatMap
ConnectedStream → DataStream
類似map和flatMap操作,但是只能作用于ConnectedStream上,也即是在執行過connect的流上操作,
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) { // 第一個流的map操作
return true;
}
@Override
public Boolean map2(String value) { // 第二個流的map操作
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) { // 第一個流的flatMap操作
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) { // 第二個流的flatMap操作
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
16、Iterate
DataStream → IterativeStream → ConnectedStream #
迭代計算,多用于圖計算、機器學習等特殊領域,
// 定義一個迭代流
IterativeStream<Long> iteration = initialStream.iterate();
// 定義每個迭代的具體操作,每個迭代都會執行
DataStream<Long> iterationBody = iteration.map (/*do something*/);
// 定義繼續迭代的資料需要滿足的條件,滿足條件的資料會繼續下一次迭代,
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
// 指定繼續迭代的條件
iteration.closeWith(feedback);
// 繼續處理跳過迭代的資料
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});
在實作特殊演算法的時候可能需要用到迭代計算,具體細節可以參考:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/iterations/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/overview/#iterations
這里暫不具體介紹迭代計算,感興趣的同學可以百度一下,
DataSet
Table API
SQL
參考檔案
Flink官方檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/420477.html
標籤:其他
上一篇:ElasticSearch