目錄
- 1.spark 基礎
- 1.1 spark 發展歷程
- 1.2 spark 與 mapreduce 對比
- 1.3 spark 運行模式
- 1.4 spark 常用命令
- 1.5 spark 底層執行原理
- 2.sparkcore
- 2.1 SparkContext 介紹
- 2.2 RDD 介紹
- 2.3 RDD 資料磁區
- 2.4 RDD 操作
- 2.4.1 RDD 構建
- 2.4.2 RDD 重磁區
- 2.4.3 RDD 算子
- 2.4.4 RDD 快取操作
- 2.4.5 RDD 容錯機制 Checkpoint
- 2.5 閉包
- 2.6 累加器與廣播變數
- 2.6.1 累加器
- 2.6.2 廣播變數
- 3.sparksql
- 3.1 sparksql 介紹
- 3.2 sparksql 發展歷程
- 3.3 sparksql 優點
- 3.4 sparksql 架構
- 3.4.1 基礎架構
- 3.4.2 執行流程
- 3.4.3 catalyst 決議與優化
- 3.5 SparkSession
- 3.6 DataFrame 與 Dataset
- 3.7 sparksql 操作
- 3.7.1 DSL
- 3.7.2 SQL
- 3.8 DF、Ds、RDD 對比
1.spark 基礎
1.1 spark 發展歷程
spark 是加州大學伯克利分校 AMP 實驗室開發的基于記憶體的通用并行計算框架,
發展歷程:
- 2009 年誕生于美國加州大學伯克利分校 AMP 實驗室;
- 2010 年通過 BSD 許可協議開源發布;
- 2013 年 6 月進入 Apache 范訓器專案;
- 2014 年 2 月成為 Apache 的頂級專案(僅8個月時間);
- 2014 年 5 月 spark1.0.0 發布;
- 2016 年 7 月 spark2.0.0 發布;
- 2020 年 6 月 spark3.0.0 發布;
既然已經有了 mapreduce,為什么還會流行 spark?
1.2 spark 與 mapreduce 對比
Spark 產生之前,已經有 MapReduce 這類非常成熟的并行計算框架存在了,并提供了高層次的 API(map/reduce),它在集群上進行計算并提供容錯能力,從而實作分布式計算,
所以為什么 spark 會流行呢?
- 原因 1:優秀的資料模型和豐富的算子
雖然 MapReduce 提供了對資料訪問和計算的抽象,但是對于資料的復用就是簡單的將中間資料寫到一個穩定的檔案系統中(例如 HDFS),所以會產生資料的復制備份,磁盤的 I/O 以及資料的序列化,所以在遇到需要在多個計算之間復用中間結果的操作時效率就會非常的低,而這類操作是非常常見的,例如迭代式計算,互動式資料挖掘,圖計算等,
所以在認識到這個問題后,AMPLab 提出了一個新的模型,叫做 RDD(彈性分布式資料集),RDD 是一個可以容錯且并行的資料結構(其實可以理解成分布式的集合,操作起來和操作本地集合一樣簡單),它可以讓用戶顯式的將中間結果資料集保存在記憶體中,并且通過控制資料集的磁區來達到資料存放處理最優化,同時 RDD 也提供了豐富的算子 API (map、reduce、filter、foreach、redeceByKey…)來操作資料集,后來 RDD 被 AMPLab 放在一個叫做 Spark 的框架中并開源,
簡而言之,Spark 借鑒了 MapReduce 思想發展而來,保留了其分布式并行計算的優點并改進了其明顯的缺陷,讓中間資料存盤在記憶體中提高了運行速度、并提供豐富的操作資料的 API 提高了開發速度,
- 原因2:fullstack-完善的生態圈

spark 目前主要由五個組件構成, sparkcore 提供記憶體計算,sparksql 提供即時查詢,spark streaming 提供實時計算,mlib提供機器學習,graphx提供圖處理,spark 其他四個組件都會依賴于核心專案 sparkcore 中的組件模塊,
- 原因3:運行模式多樣化
由上圖可知,spark 可以運行在多個資源管理調度平臺上,其中包括 spark standalone、spark on yarn、mesos、k8s等,下面將對其中幾個運行模式進行說明
1.3 spark 運行模式
- 本地模式
spark 本地模式是在一臺計算機上的運行模式,一般用于學習與測驗,例如在idea中:
var conf=new SparkConf().setMaster("local[*]").setAppName("test1")
var sc:SparkContext=...
sc.操作
sc.stop()
其中設定本地模式有三種方式:
setMaster(“local”) 表示用單執行緒來運行
setMaster(“local[number]”) 表示用 number 個執行緒并行
setMaster(“local[*]”) 表示該計算機的 cpu 核數個執行緒并行
- spark on yarn
spark on yarn 模式是在 yarn 集群中運行,適用于生產環境,其中包含 cluster 與 client 兩種模式
i. spark on yarn 的 cluster 模式,指的是 driver 程式運行在 yarn 集群上,當用戶提交了作業后,可以關閉 client,作業會繼續在 yarn 上運行,
ii. spark on yarn 的 client 模式,指的是 driver 程式運行在提交任務的客戶端上,當用戶提交了作業后會在 client 上生成 sparksubmit 行程,client 不能中途離開,
兩種模式的本質區別是:driver 程式運行的位置
- k8s
k8s是 spark 上全新的集群管理和調度系統,spark2.3 后 spark 可以部署在 k8s 上
常用有兩種方法可以將 spark 應用提交到 k8s 上:
i. 通過 spark 原生的 spark-submit 提交
ii. 通過谷歌提供的 spark-on-k8s operator 提交
兩種模式區別是:spark-on-k8s operator 可以通過一系列的內置工具獲取很多作業相關的資訊,而spark-submit 則無法查看作業的運行資訊,
- why spark on k8s?
spark on yarn 與 spark on k8s 都可以用于實際生產,但為什么很多大公司更傾向于 k8s 呢?
yarn 是資源管理工具,用于管理 cpu 與 memory 的資源隔離;
k8s 是容器編排工具,顯然資源管理是其功能之一;
如果按照“編排”的概念方向去理解 yarn,那么 yarn 就是一個 JVM 負載的編排工具,而 k8s 是容器負載的編排工具,這么一比較,k8s 顯然勝出一籌,因為容器在應用的支持方面更廣泛,更不要說 k8s 能夠實作比 yarn 好得多的多的隔離了,
簡而言之,用了 k8s 之后,不僅僅可以在這個集群運行 spark 負載,顯然也可以運行其他所有的基于容器的負載,那么只需要把應用都進行容器化即可,比如 BI 工具、報表工具、查詢工具等都可以在一個 k8s 集群上運行,而 spark 只是作為其中的應用之一,
so why not k8s?
1.4 spark 常用命令
- spark-shell
spark 提供的終端命令,允許在終端中使用 scala、java、python 等語言撰寫 spark 程式,
- spark-sql
spark 提供的終端命令,允許在終端使用 sql 語言操作資料,
- spark-submit
spark 提供的終端作業提交命令,允許將打包好的程式提交到集群中運行,
常用語法:
1.spark-submit [options] <app jar | python file | R file> [app arguments]
2.spark-submit --kill [submission ID] --master [spark://...]
3.spark-submit --status [submission ID] --master [spark://...]
可選配置:
--master 運行模式,默認為 local[*]
--class 主方法所在類名
--name 應用名稱
--deploy-mode 指定 sparkonyarn 的客戶端/集群模式,默認為 client,可以設定為 cluster
--executor-memory 執行器記憶體大小,默認為1g
--num-executors 執行器個數,默認為2
--executor-cores 每個執行器的 cpu 個數,默認為1
--driver-cores 驅動器的 cpu 個數,默認為1,只支持在 cluster 模式下修改
--jars 額外依賴的第三方 jar 包
--files 需要分發到各節點的資料檔案
--total-executor-cores 執行器的 cpu 個數,默認為集群中全部可用的 cpu 個數
1.5 spark 底層執行原理
- 常用名詞說明
RDD:一組分布式的存盤在節點記憶體中的只讀性資料集,spark 的基本計算單元
DAG:有向無環圖,反應了 RDD 之間的依賴關系
STAGE:一個 stage 包含一組相同的 task,也叫做taskset,stage 包含的 task 個數取決于磁區個數,一個磁區對應一個 task
DAG Scheduler:有向無環圖調度器,負責將 DAG 根據寬依賴劃分 stage,并將 stage 交給 taskscheduler
taskscheduler:任務調度器,負責將 task 分發給 executor 執行
- spark 作業運行流程
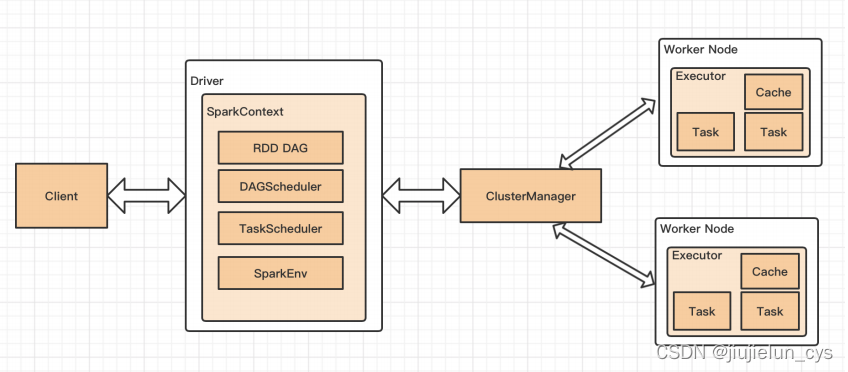
1.用戶在客戶端 spark-submit 提交 spark 程式給 clustermanager;
2.clustermanager 接收到程式之后會找一個 worker 啟動 driver ,driver 開始運行 spark 程式的主函式;
3.然后 driver 創建 sparkcontext,將其作為資源調度的總入口,還會初始化 DAGscheduler 與 taskScheduler 以及 sparkenv;
4.driver 開始執行 spark 程式中的各種算子,根據 action 算子劃分 job,一個 job 產生一個 DAG,一個 DAG 交給一個 DAGscheduler,根據寬依賴劃分 stage(stage 就是 task 集合),然后一個 stage 交給一個 taskscheduler,它會將每個 task 交給 worker 上的 executor 去執行,并且執行器會開啟執行緒去執行這些 task;
5.sparkenv 會啟動一些控制組件,進行 shuffle 管理或者廣播變數等的管理;
6.當所有 task 完成后,driver 關閉 sc,spark 作業結束,
- stage 劃分
Spark 的計算發生在 RDD 的 Action 操作,而對 Action 之前的所有 Transformation,Spark 只是記錄下 RDD 生成的軌跡,而不會觸發真正的計算,
劃分依據:Stage 劃分的依據就是寬依賴,像 reduceByKey,groupByKey 等產生shuffle的算子,會導致寬依賴的產生,
窄依賴:父 RDD 的一個磁區只會被子 RDD 的一個磁區所使用,即一對一的關系,常見的產生窄依賴的算子有:map、filter、union、mapPartitions等,
寬依賴:父 RDD 的一個磁區會被子 RDD 的多個磁區所使用(涉及到 shuffle),即一對多的關系,常見的產生寬依賴的算子有 groupByKey、reduceByKey、join等,
核心演算法:回溯演算法
從后往前回溯,遇到窄依賴就加進當前 Stage,遇見寬依賴進行 Stage 切分,
Spark 內核會從觸發 Action 操作的那個 RDD 開始從后往前推,首先會為最后一個 RDD 創建一個 Stage,然后繼續倒推,如果發現它對某個 RDD 是寬依賴,那么就會將寬依賴的那個 RDD 創建一個新的 Stage,那個 RDD 就是新的 Stage 的最后一個 RDD,然后依次類推,繼續倒推,根據寬依賴進行 Stage 的劃分,直到所有的 RDD 全部遍歷完成為止,
例如:
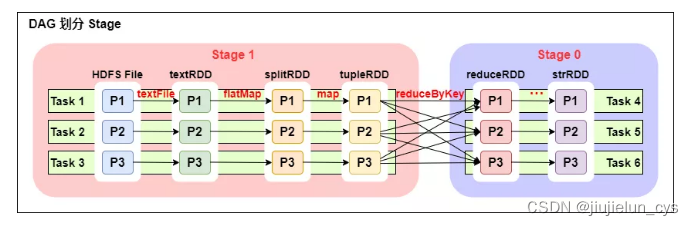
一個 Spark 程式可以有多個 DAG(有幾個 Action,就有幾個 job ,就有幾個 DAG,上圖最后只有一個 Action(圖中未標出),那么就是一個 DAG),
一個 DAG 可以有多個 Stage(根據寬依賴/shuffle 進行劃分),
同一個 Stage 可以有多個 Task 并行執行(task 數=磁區數,如上圖,Stage1 中有三個磁區 P1、P2、P3,對應的也有三個 Task),
可以看到這個 DAG 中只有 reduceByKey 操作是一個寬依賴,Spark 內核會以此為邊界將其前后劃分成不同的 Stage,
同時我們可以注意到,在圖中 Stage1 中,從 textFile 到 flatMap 到 map 都是窄依賴,這幾步操作可以形成一個流水線操作,通過 flatMap 操作生成的 partition 可以不用等待整個 RDD 計算結束,而是繼續進行 map 操作,這樣大大提高了計算的效率,
2.sparkcore
2.1 SparkContext 介紹
Sparkcontext 是整個 spark 應用程式的背景關系,控制應用的生命周期,它負責與 clustermanager 進行通信,并負責對資源的申請與任務分配,最重要的是它可以用來創建 RDD、累加器、廣播變數,詳情見原始碼
- sparkcore編程流程:
兩種思路:
一種是在 idea 中撰寫 spark 代碼,構建 Sparkcontext,然后 sc 進行各種操作(構建 RDD、呼叫一系列算子操作、關閉sc),打包上傳到 spark client 上提交作業,
還一種是終端 spark-shell 中撰寫 spark 代碼,不需要創建 sparkcontext,直接進行算子操作,
2.2 RDD 介紹
彈性分布式資料集是 spark 中最基本的資料抽象,主要屬性包括:
1.資料磁區
用來查看當前 rdd 的磁區串列
2.計算函式
該函式由 spark 開發人員使用,用來撰寫 rdd 計算函式(如 map、flatMap 等算子)
3.依賴關系
展示磁區間的依賴關系,可以用來構建血緣系統,當資料磁區丟失后通過磁區間的依賴關系進行恢復
4.磁區方式
類似 mapreduce 的磁區,默認采用 hashpartitioner ,鍵值對型別的 rdd 才會有磁區方式
5.最佳位置
rdd 磁區放置的最佳位置
資料磁區、磁區方式、最佳位置,這三個屬性其實說的就是資料集在哪,在哪計算更合適,如何磁區;
計算函式、依賴關系,這兩個屬性其實說的是資料集怎么來的,
2.3 RDD 資料磁區
- 資料磁區:站在資料的角度思考 RDD,它是由資料磁區組成,這些磁區運行在集群中的不同節點上,一個 RDD 可以包含多個磁區,一個磁區被封裝成一個 task,例如:
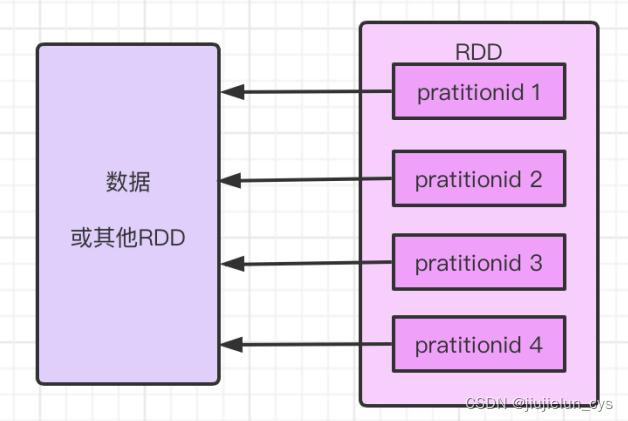
所以資料磁區存盤的是真正的資料嗎?
資料磁區內部并不會存盤具體的資料,原始碼如下:

由上圖知,磁區包含一個index欄位,表示了該磁區在 RDD 內的編號,通過 RDD 編號和磁區編號可以唯一確定該磁區對應的塊編號,進而可以從存盤介質(比如hdfs)中提取出磁區對應的資料,并且磁區方式采用的是hashpartitioner,
- 磁區方式:
spark 通過控制 RDD 磁區方式來減少通信開銷,只有 kv 型別的 RDD 才會有磁區,默認采用hashpartitioner(類似 mapreduce 的磁區)
2.4 RDD 操作
2.4.1 RDD 構建
- 讀取外部資料集
常用 textFile、wholeTextFiles、sequenceFile等
sc.textFile(path[,minPartitions])
sc.wholeTextFiles(path[,minPartitions])
sc.sequenceFile(path,keyClass,valueClass[,minPartitions])
例如:
var rdd:RDD[String] = sc.textFile("a.txt",2)
path 可以是檔案也可以是目錄,也可以是帶正則的路徑
minpartitions 指定最小磁區數
keyClass、valueClass 是指資料檔案中 kv 的資料型別

- 集合并行化
sc.makeRDD(seq[,numPartition])
sc.parallelize(seq[,numPartition])
例如:
var rdd = sc.makeRDD(Array(1,2,3,4,5,6),2)
seq指集合,numpartition磁區個數(并行度)
磁區個數會決定 stage 中 task 的個數,代表了 spark 作業的并行度,那么磁區個數可以變嗎?
2.4.2 RDD 重磁區
通過創建 RDD 我們可以指定磁區個數,若我們需要調整磁區個數時則需要進行重磁區操作
常見重磁區方法如下:


區別?
repartition 默認shuffle,網路開銷大
coalesce 可以設定是否shuffle
如何使用?
調大磁區數的時候需要將磁區內的資料打亂再分發到多個磁區,要shuffle,可以采用 repartition
而調小磁區數可以直接讓多個磁區合并為一個大磁區,沒必要shuffle,可以采用coalesce,減小網路開銷
2.4.3 RDD 算子
RDD 算子分為兩大類,transform 算子與 action 算子
常用的轉化算子如下:
- 基于元素進行操作

常規操作
- 基于磁區進行操作

連接資料庫時可以采用基于磁區操作的算子,每個磁區創建一個連接物件,避免創建大量連接物件!
- 聚合操作
- 分組操作
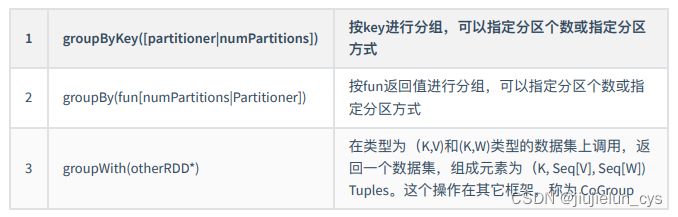
- 連接操作
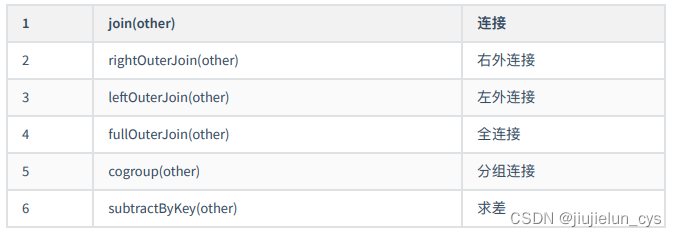
- 排序操作

常用的 action 算子如下:
只有 action 算子執行后,transform 算子才會生效!
- 獲取部分元素

- 規約操作

- 輸出到外部系統

- 其他操作

2.4.4 RDD 快取操作
如果某個 RDD 頻繁被使用,可以將 RDD 快取在記憶體中,這樣后續的其他操作就可以重用 RDD,以此來提高查詢速度,快取操作屬于 transform 算子,需要 action 算子執行后才會生效,
常用方法:
- cache():只存盤在記憶體中
- persist(持久化級別):指定一個持久化級別進行存盤
常用持久化級別:

RDD 快取可以把資料放在記憶體中,雖然很快,但同時也不可靠,我們也可以把資料放在磁盤上,但也不是完全可靠的,因為磁盤可能會壞!那 RDD 怎樣才能保證容錯呢?
2.4.5 RDD 容錯機制 Checkpoint
Checkpoint 的產生就是為了更加可靠的資料持久化,在 Checkpoint 的時候一般把資料放在在 HDFS 上,這就天然的借助了 HDFS 天生的高容錯、高可靠來實作資料最大程度上的安全,實作了 RDD 的容錯和高可用,
例如:
SparkContext.setCheckpointDir("目錄") //HDFS的目錄
RDD.checkpoint
總結:
- 開發中如何保證資料的安全性性及讀取效率:可以對頻繁使用且重要的資料,先做快取操作,再做 checkpoint 操作,
- 持久化和 Checkpoint 的區別:
- 位置:Persist 和 Cache 只能保存在本地的磁盤和記憶體中(或者堆外記憶體中),Checkpoint 可以保存資料到 HDFS 這類可靠的存盤上,
- 生命周期:Cache 和 Persist 的 RDD 會在程式結束后會被清除或者手動呼叫 unpersist 方法,Checkpoint 的 RDD 在程式結束后依然存在,不會被洗掉,
所以,講到這里可以總結一下 MapReduce 與 spark 的區別:
1.spark 把運算的中間結果保存在記憶體,迭代計算的效率更高,mr 中間結果保存在磁盤
2.spark 的容錯性高,它采用彈性分布式資料集 RDD 實作高效容錯( 快取操作和 checkpoint 機制),某一部分資料如果丟失,可以通過整個計算程序的血緣關系(依賴關系)進行重建,而 mr 的容錯只能重新計算,
3.spark更通用,它提供了 transform 算子和 action 算子這兩大類 api 算子,而 mr 只有 map 和 reduce 兩種方法,
2.5 閉包
運行如下代碼,看看現象如何:
class Hello {
val param = 1
def work(rdd: RDD[Int]) {
rdd.map(x => x + param).foreach(println)
}
}
object BibaoTest {
def main(args:Array[String])={
//1.獲取SparkConf物件
val conf=new SparkConf().setMaster("local[*]").setAppName("BibaoTest")
//2.獲取SparkContext物件
val sc:SparkContext=SparkContext.getOrCreate(conf)
sc.setLogLevel("warn")
//3.構建rdd
val rdd=sc.makeRDD(1 to 10)
//4.構建物件呼叫方法
val rdd1=new Hello
rdd1.work(rdd)
sc.stop()
}
}
該程式產生例外:NotSerializableException
分析:
-
出現例外的原因:閉包
? 1. 如果 RDD 相關操作需要傳遞函式,而該函式需要訪問外部變數,則此時會產生閉包,
? 2. 閉包需要遵循—定的規則(閉包內的物件必須可以進行序列化),否則會拋出運行時例外,
-
閉包函式傳入到從節點時,需要經過下面的步驟:
? 1. 驅動程式,通過反射,運行時找到閉包訪問的所有變數,并封裝成一個物件,然后序列化該物件;
? 2. 將序列化后的物件通過網路傳輸到 worker 節點;
? 3. worker 節點反序列化閉包物件;
? 4. worker 節點執行閉包函式;
簡而言之,通過網路,傳遞閉包函式,然后執行閉包函式,本地執行時,仍然會按照以上四步進行,
- 解決辦法
1.讓閉包所在的類實作序列化介面;
class Hello extends Serializable {
val param = 1
def work(rdd: RDD[Int]) {
rdd.map(x => x + param).foreach(println)
}
}
2.盡量避免在閉包中使用全域變數;
class Hello {
val param = 1
def work(rdd: RDD[Int]) {
val _param = this.param
rdd.map(x => x + _param).foreach(println)
}
}
2.6 累加器與廣播變數
首先,以分割字串的程序中統計 RDD 中空行出現的次數為例:
val file=sc.textFile("a.txt")
var blankLines=0
val callSigns=file.flatMap(
line => {
if (line == ""){
blankLines +=1
}
line.split(" ")
})
callSigns.saveAsTextFile("output.txt")
println("Blank lines:"+blankLines)
結果為?
-
分析:外部變數在閉包內的修改不會被反饋到驅動程式
-
解決方法:使用共享變數解決該問題
spark 支持兩種共享變數:
-
累加器
對資料資訊進行聚合(聚合到驅動器程式中);
-
廣播變數
用來高效分發較大的只讀物件;
2.6.1 累加器
- 累加器型別:
-
LongAccumulator
-
DoubleAccumulator
-
CollectionAccumulator
-
自定義累加器(繼承抽象類 AccumulatorV2)
- 累加器方法(借助于 SparkContext 類中的方法):
構造:
-
longAccumulator(name:String): LongAccumulator
-
doubleAccumulator(name:String): DoubleAccumulator
-
collectionAccumulator[T] (name:String): CollectionAccumulator[T]
(推薦在構造累加器的時候指定名字,這樣在 spark web 界面就可以看到累加器了)
使用:
-
執行器代碼可以使用累加器的 add 方法增加累加器的值
-
驅動器程式可以呼叫累加器的 value 屬性來訪問累加器的值
- 上述案例代碼修改:
val file=sc.textFile("src/SparkTestFiles/count1.txt")
//var blankLines=0
val blankLines=sc.longAccumulator("blankLines");
val callSigns=file.flatMap(
line => {
if (line == ""){
//blankLines +=1
blankLines.add(1);
}
line.split(" ")
})
callSigns.saveAsTextFile("src/SparkTestFiles/output.txt")
println("Blank lines:"+blankLines.value)
2.6.2 廣播變數
將一個只讀資料(非 RDD)通過廣播的形式廣播到各個執行器節點,并將該資料序列化快取到節點上,
- 廣播方法:
broadcast[T: ClassTag] (value: T): Broadcast[T]
(傳入一個變數,將其變為廣播變數)
- 廣播用法:
觀察如下代碼:
//大資料集合
val list=1 to 100;
//獲取RDD
val rdd=sc.parallelize(List(1,300,10,33,24,51,67,112,346,14,5))
//第一個job
rdd.filter(num=>{
list.contains(num)
}).foreach(println)
println("----")
//第二個job
rdd.map(num=>{
list.contains(num)
}).foreach(println)
說明:
-
兩個 job 中使用了匿名函式的非區域變數 list
-
非區域變數 list 是一個較大的只讀值
使用廣播變數優化:
//為list創建廣播變數
val list=1 to 100;
val broadcast=sc.broadcast(list);
//獲取RDD
val rdd=sc.parallelize(List(1,300,10,33,24,51,67,112,346,14,5))
//第一個job
rdd.filter(num=>{
val list=broadcast.value
list.contains(num)
}).foreach(println)
println("----")
//第二個job
rdd.map(num=>{
val list=broadcast.value
list.contains(num)
}).foreach(println)
說明:
-
引數只會被廣播到各個節點一次,應作為只讀值處理,不應該再修改,
-
通過 Broadcast 物件的 value 屬性訪問該引數的值,
對比以上兩種代碼,可以得知廣播變數的優缺點:
優點︰避免多次資料傳輸,進而減少通信的開銷提高計算效率
缺點∶使用廣播會使代碼不夠簡潔
- 廣播優化:
當廣播一個比較大的值時,選擇既快又好的序列化格式非常重要,
Spark 支持的序列化:
-
JavaSerializer 序列化
i. Spark 的 Scala 和 Java 的 API 默認使用 JAVA 的序列化進行序列化
ii. JavaSerializer 除基本型別以及基本型別的陣列之外,其他型別都比較低效
-
KryoSerializer [k’ra???] 序列化
Kryo 是一個快速且高效的針對 Java 物件序列化的框架,
特點:
i. 序列化的性能非常高
ii. 序列化結果體積較小
iii. 提供了簡單易用的 API
用法:
conf.set(“spark.serializer”,“org.apache.spark.serializer.KryoSerializer”)
conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2] ))
-
自定義序列化
Spark-Sql 中的核心抽象模型 Dataset 使用 Encoder[T] 專業編碼器來替換序列化,
3.sparksql
3.1 sparksql 介紹
Spark SQL 是 Spark 中處理結構化資料的模塊,提供了一種新的編程抽象 DataFrame/Dataset,并且可以充當分布式 SQL 查詢引擎,
- 集成:無縫地將 SQL 查詢集成到 Spark 程式中,
- 統—資料訪問:使用統一的方式連接到常見資料源,
- Hive兼容:通過配置可以直接兼容 Hive,運行查詢 Hive 資料,
- 標準的連接:通過 JDBC、ODBC 連接,Spark SQL 包括具有行業標準 JDBC 和 ODBC 連接的服務器模式,
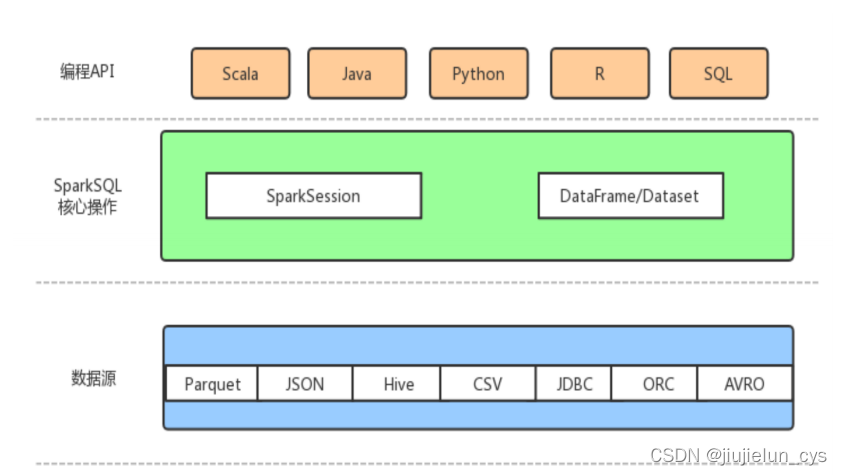
3.2 sparksql 發展歷程
Hive
Hive 是基于 Hadoop 的一個資料倉庫工具
- 可以將結構化的資料檔案映射為一張資料庫表;
- 可以提供簡單的 SQL 查詢功能;
- 可以將 SQL 陳述句轉換為 MapReduce 任務并行運算;
Hive 計算引擎依賴于 MapReduce 框架
- 隨著時代的發展,對資料提取轉化加載(ETL)需求越來越大;
- 因此開發一個更加高效的 SQL-on-Hadoop 工具更加的迫切;
shark
Shark 便是其中之一
- 修改了 Hive 中記憶體管理、物理計劃、執行這三個模塊,運行在 Spark 引擎上,使得 SQL 查詢的速度得
到10-100倍的提升,
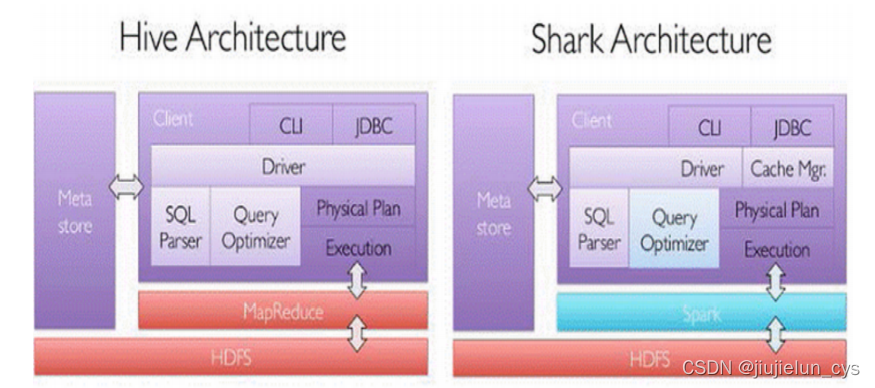
隨著 Spark 的發展
- Shark 對于 Hive 太多依賴
- 制約了 Spark 各個組件的相互集成
- 所以提出了 SparkSQL 專案
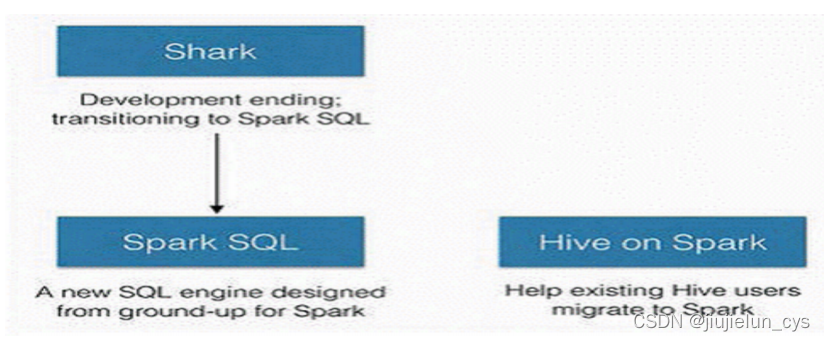
- 2014年宣布:停止開發 shark,至此 Shark 的發展畫上了句號
- SparkSQL 作為 Spark 生態的一員繼續發展
- 不再受限于 Hive,只是兼容 Hive
Hive on Spark 是 Hive 的發展計劃
-
該計劃將 Spark 作為 Hive 的底層引擎之一
-
也就是說,Hive 將不再受限于一個引擎,可以采用 MapReduce、Spark 等引擎
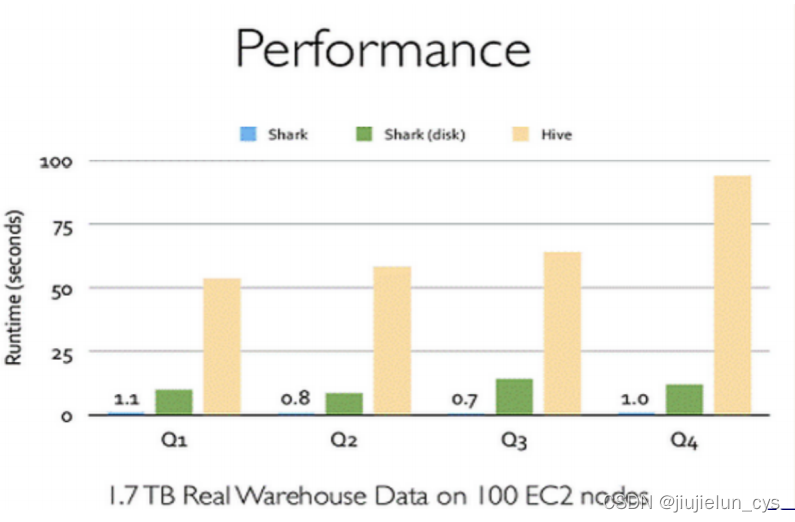
Shark 的出現,使得 SQL-on-Hadoop 的性能比 Hive 有了10-100倍的提高,
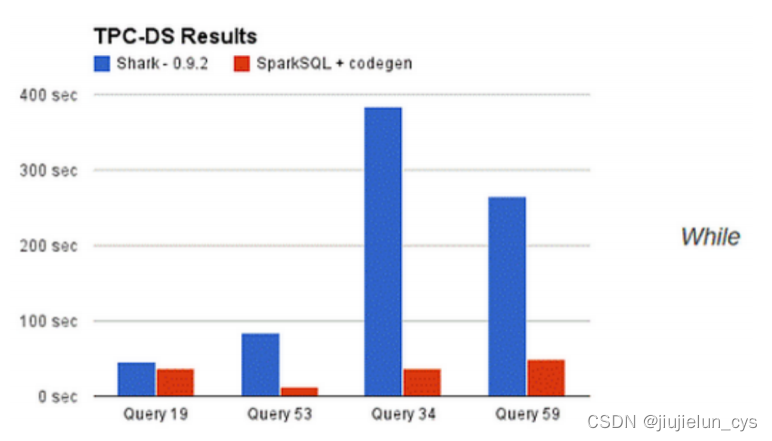
擺脫了 Hive 的限制,SparkSQL 的性能與 Shark 對比,也有很大的提升,
為什么 sparksql 的性能會得到如此大的提升呢?
3.3 sparksql 優點
SparkSQL 主要是在以下三點做了優化(主要是與 Sparkcore 對比):
-
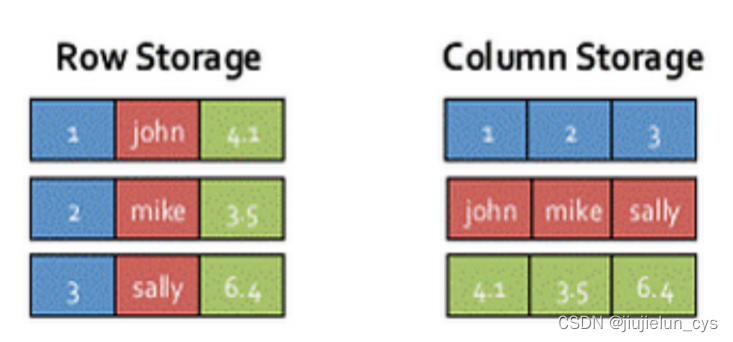
記憶體列存盤(In-Memory Columnar Storage)
- SparkSQL 的表資料在記憶體中存盤不是采用原生態的 JVM 物件存盤方式,而是采用記憶體列存盤,如下圖所示,
-
采用了記憶體列存盤之后,減少了對記憶體的消耗,減少 JVM 的 GC 性能開銷,
-
位元組碼生成技術(bytecode generation,即 CG)
- Spark SQL 在其 catalyst 模塊的 expressions 中增加了 codegen 模塊,
- 對于 SQL 陳述句中的計算運算式,比如 select num + num from t 這種的 sql,就可以使用動態位元組碼生成技術來優化其性能,
-
Scala 代碼優化
-
使用 Scala 撰寫的代碼,對可能造成較大性能開銷的代碼,Spark SQL 底層會使用更加復雜的方式進行重寫,來獲取更好的性能,
-
比如 option 樣例類、for 回圈、map/filter/foreach 等高階函式,以及不可變物件,都改成了用 null、while 回圈等來實作,并且重用可變的物件,
3.4 sparksql 架構
3.4.1 基礎架構
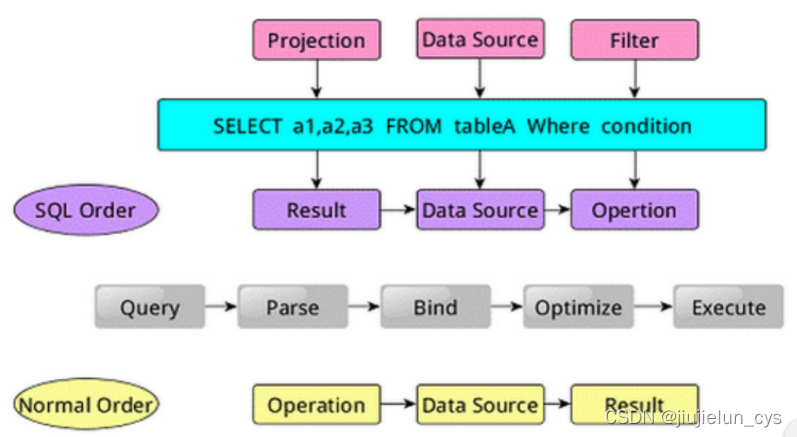
SparkSQL 陳述句由三部分組成,分別對應 SQL 查詢程序中的 Result、Data Source、Operation,
- Projection (a1,a2,a3)
- Data Source (tableA)
- Filter (condition)
SQL 陳述句按 Result–>Data Source–>Operation 的次序描述,
3.4.2 執行流程
執行 SQL 陳述句的一般順序為∶
1.對讀入的 SQL 陳述句進行決議(Parse)
- 分辨出 SQL 陳述句中哪些詞是關鍵詞(如 SELECT、FROM、WHERE) ;
- 哪些是運算式;
- 哪些是 Projection;
- 哪些是 Data Source 等;
- 從而判斷 SQL 陳述句是否規范;
2.將 SQL 陳述句和資料庫的資料字典(列、表、視圖等等)進行系結(Bind),
- 如果相關的 Projection、Data Source 等都是存在的話,就表示這個 SQL 陳述句是可以執行的,
3.一般資料庫會提供幾個執行計劃,這些計劃一般都有運行統計資料,資料庫會在這些計劃中選擇一個最優計劃(Optimize),
4.計劃執行(Execute),按 Operation–>Data Source–>Result 的次序來進行,
- 在執行程序有時候甚至不需要讀取物理表就可以回傳結果,
- 比如重新運行剛運行過的 SQL 陳述句,可能直接從資料庫的緩沖池中獲取回傳結果,
3.4.3 catalyst 決議與優化
Catalyst 是 Spark SQL 執行優化器的代號,所有 Spark SQL 陳述句最終都能通過它來決議、優化,最終生成可以執行的 Java 位元組碼,catalyst 采用的資料結構是 Tree 和 Rule,數和規則構成了 catalyst 決議優化器:
- Catalyst 最主要的資料結構是樹,所有 SQL 陳述句都會用樹結構來存盤,樹中的每個節點都擁有特定的資料型別,以及0或多個子節點,Scala 中定義的新的節點型別都是 TreeNode 這個類的子類,
- Catalyst 另外一個重要的資料結構是規則,基本上,所有優化都是基于規則的,可以用規則對樹進行操作,樹中的節點是只讀的,所以樹也是只讀的,規則中定義的函式可能實作從一棵樹轉換成一顆新樹,
優化策略:
-
RBO(Rule-based optimization) 基于規則的優化
- 優化思路主要是減少參與計算的資料量以及計算本身的代價,
-
CBO(Cost-based optimization) 基于代價優化策略
- 它充分考慮了資料本身的特點(如大小、分布)以及操作算子的特點(中間結果集的分布及大小)及代價,從而更好的選擇執行代價最小的物理執行計劃,即 SparkPlan,
整個Catalyst 的執行程序主要分為以下5個階段:
- 決議階段,決議出關鍵字,生成邏輯語法樹
- 分析階段,分析邏輯樹,解決參考;
- 邏輯優化階段;
- 物理計劃階段,Catalyst 會生成多個計劃,并基于成本進行對比;
- 代碼生成階段;
具體程序:

sparksql 程式經過 catalyst 的決議與優化后,最侄訓以 RDD 的方式(轉變為 job、dag、stage)去執行 Physical Plan,
下面通過一個簡單的示例進行解釋:
Parser
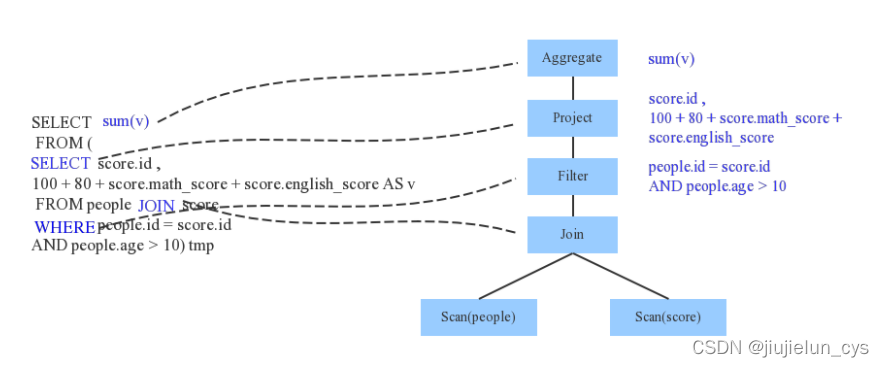
Parser 簡單來說是將 SQL 關鍵詞切分成一個一個 Token,再根據一定語意規則決議為一棵語法樹(根據關鍵字),Parser 模塊目前基本都使用第三方類別庫 ANTLR 進行實作,比如 Hive、 Presto、SparkSQL 等,下圖是一個示例性的 SQL 陳述句(有兩張表,其中 people 表主要存盤用戶基本資訊,score 表存盤用戶的各種成績),通過 Parser 決議后的 AST 語法樹如下圖所示:
Analyzer
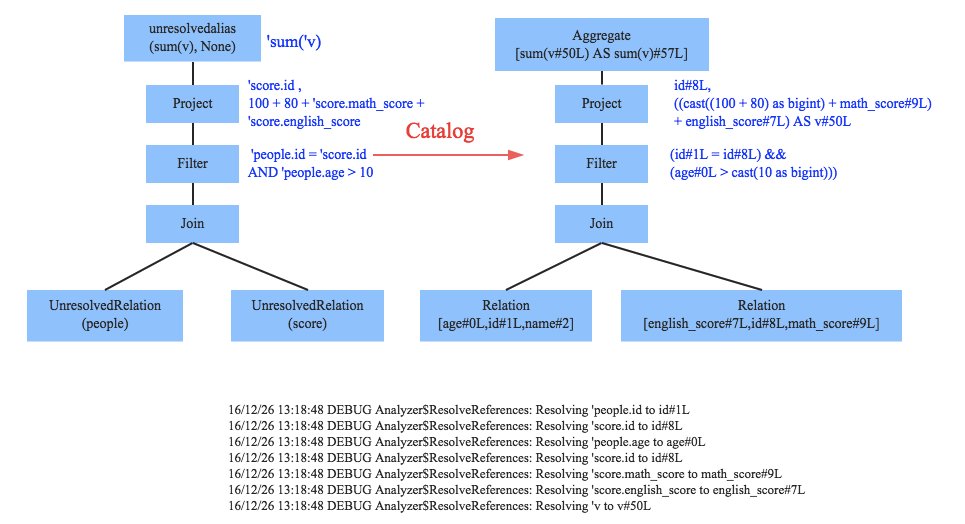
通過決議后的邏輯執行計劃基本有了骨架,但是系統并不知道 score、people 這些都是些什么玩意兒,此時需要基本的元資料資訊(catalog)來表達這些名詞,最重要的元資料資訊主要包括兩部分:表的 Schema 和基本函式資訊,表的 schema 主要包括表的基本定義(列名、資料型別)、表的資料格式(Json、Text)、表的物理位置等,基本函式資訊主要指函式的類資訊(聚合函式、udf),
Analyzer 會再次遍歷整個語法樹,對樹上的每個節點進行資料型別系結以及函式系結,比如 people 這個詞會根據元資料表資訊決議為包含 age、id 以及 name 三列的表,people.age 會被決議為資料型別為 int 的變數,sum 會被決議為特定的聚合函式,如下圖所示:
Optimizer
優化器是整個 Catalyst 的核心,上面提到優化器分為基于規則優化和基于代價優化兩種,此處先介紹基于規則的優化策略,基于規則的優化策略實際上就是對語法樹進行一次遍歷,模式匹配能夠滿足特定規則的節點,再進行相應的等價轉換,因此,基于規則優化說到底就是一棵樹等價地轉換為另一棵樹,SQL 中經典的優化規則有很多,下文結合示例介紹三種比較常見的規則:謂詞下推(Predicate Pushdown)、常量累加(Constant Folding)和列值裁剪(Column Pruning),
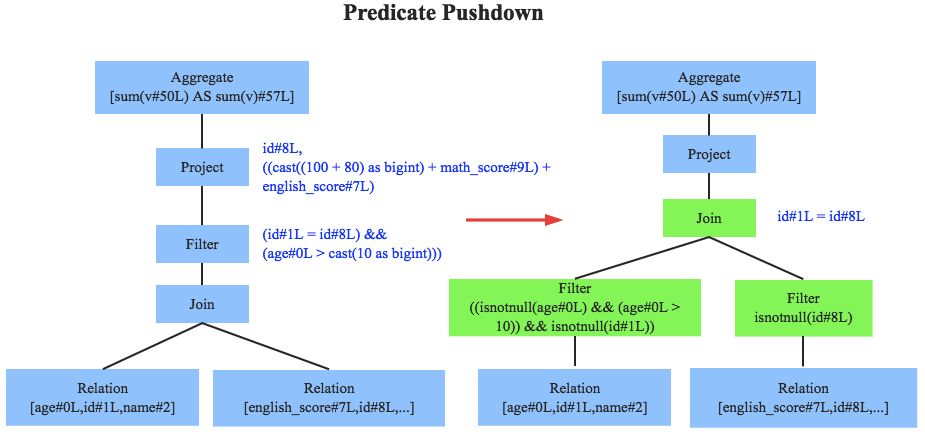
上圖是經過 Analyzer 決議后的語法樹,語法樹中兩個表先做 join,之后再使用 age>10 對結果進行過濾,我們知道 join 算子通常是一個非常耗時的算子,耗時多少一般取決于參與 join 的兩個表的大小,如果能夠減少參與 join 兩表的大小,就可以大大降低 join 算子所需時間,謂詞下推就是這樣一種功能,它會將過濾操作下推到 join 之前進行,上圖中過濾條件 age>0 以及 id!=null 兩個條件就分別下推到了 join 之前,這樣,系統在掃描資料的時候就對資料進行了過濾,參與 join 的資料量將會得到顯著的減少,join 耗時必然也會降低,
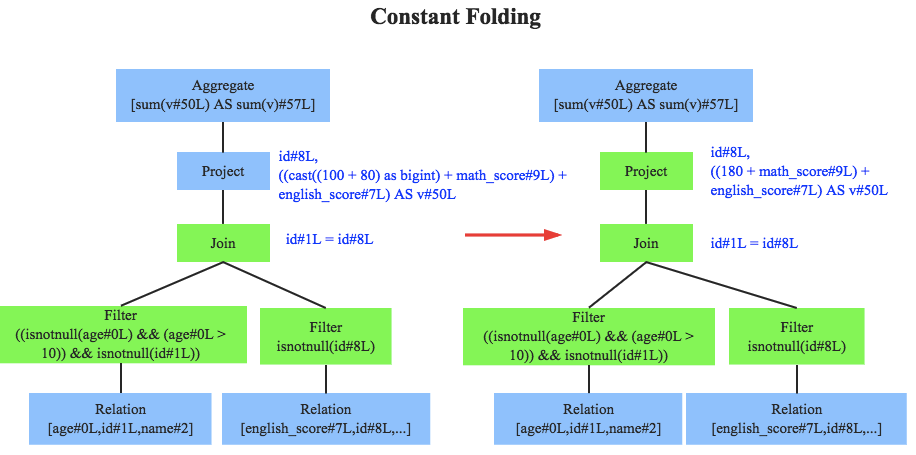
常量累加其實很簡單,就是上文中提到的規則 x+(1+2) -> x+3,雖然是一個很小的改動,但是意義巨大,示例如果沒有進行優化的話,每一條結果都需要執行一次100+80的操作,然后再與變數 math_score 以及 english_score 相加,而優化后就不需要再執行 100+80 操作,
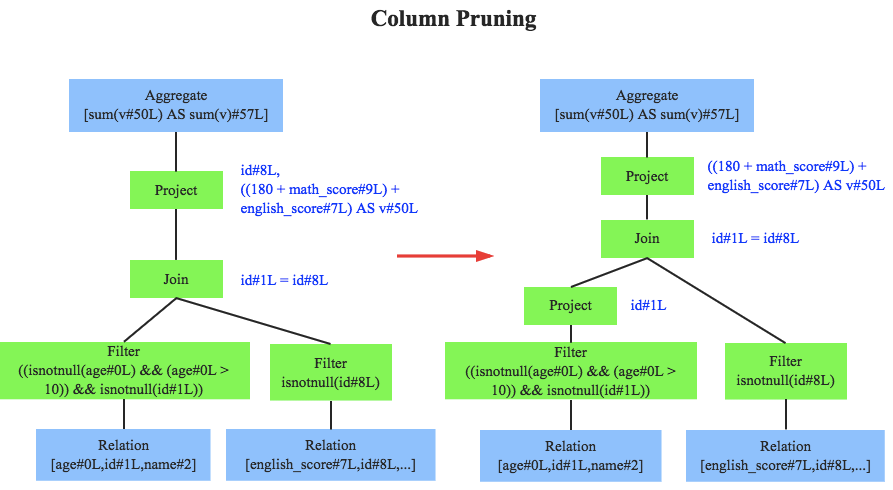
列值裁剪是另一個經典的規則,示例中對于 people 表來說,并不需要掃描它的所有列值,而只需要列值id,所以在掃描 people 之后需要將其他列進行裁剪,只留下列 id,這個優化大幅度減少了網路、記憶體資料量消耗,
至此,邏輯執行計劃已經得到了比較完善的優化,然而,邏輯執行計劃依然沒辦法真正執行,他們只是邏輯上可行,實際上 Spark 并不知道如何去執行這個東西,比如 Join 只是一個抽象概念,代表兩個表根據相同的 id 進行合并,然而具體怎么實作這個合并,邏輯執行計劃并沒有說明,

此時就需要將邏輯執行計劃轉換為物理執行計劃,將邏輯上可行的執行計劃變為Spark可以真正執行的計劃,比如 Join 算子,Spark 根據不同場景為該算子制定了不同的演算法策略,有 BroadcastHashJoin、ShuffleHashJoin 以及 SortMergeJoin 等(可以將 Join 理解為一個介面,BroadcastHashJoin 是其中一個具體實作),物理執行計劃實際上就是在這些具體實作中挑選一個耗時最小的演算法實作,
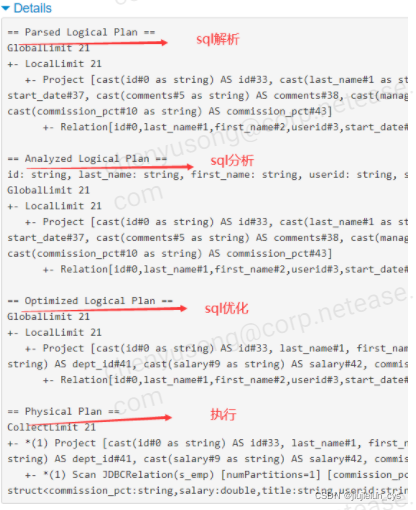
如何查看catalyst決議優化的整個程序?
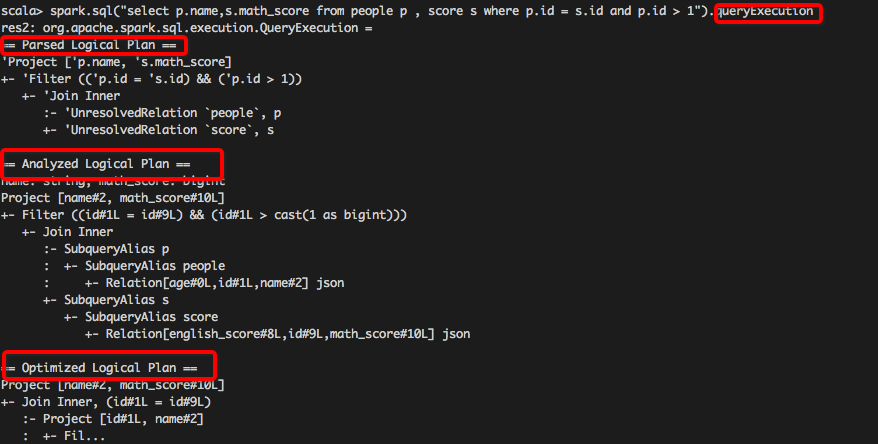
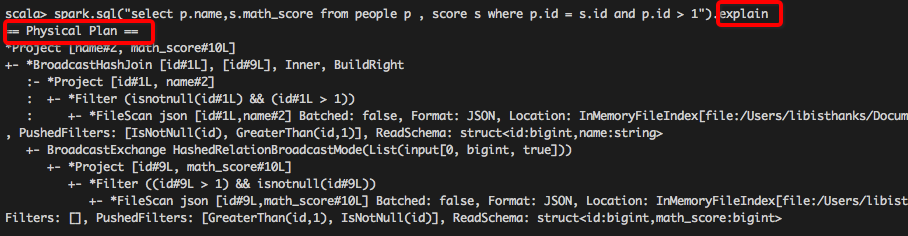
1.使用 queryExecution 方法查看邏輯執行計劃,使用 explain 方法查看物理執行計劃,分別如下所示:
2.使用Spark WebUI進行查看,如下圖所示:
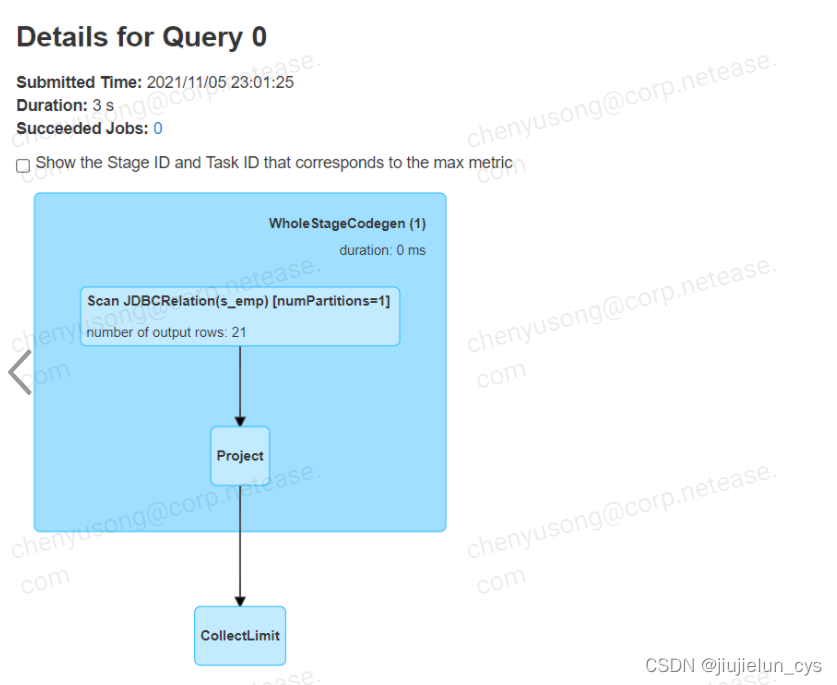
3.5 SparkSession
詳情見 sparksql 官方檔案
https://spark.apache.org/docs/latest/sql-programming-guide.html
3.6 DataFrame 與 Dataset
詳情見 sparksql 官方檔案
https://spark.apache.org/docs/latest/sql-programming-guide.html
3.7 sparksql 操作
詳情見 sparksql 官方檔案
https://spark.apache.org/docs/latest/sql-programming-guide.html
3.7.1 DSL
3.7.2 SQL
3.8 DF、Ds、RDD 對比
抽象模型RDD的優缺點:
-
優點
1.功能強大
內置很多函式操作,group、map、filter 等方便處理結構化或非結構化資料
2.面向物件編程
直接存盤物件型別轉化也安全
-
缺點
1.通用性強
因此沒有針對特殊場景的優化,比如對于結構化資料處理相對于 SQL 來比非常麻煩,
2.序列化結果較大
默認采用的是 Java 序列化方式,而且資料存盤在 Java 堆記憶體中,導致GC比較頻繁,
DataFrame 引入了 schema 和 off-heap
-
schema
1.結構資訊
2.Spark 通過 scheme 能讀懂資料
-
off-heap
1.指 JVM 堆以外的記憶體,直接受作業系統管理(而不是 JVM )
2.Spark 能夠將資料按照二進制的形式序列化到 off-heap 中
DataFrame的優缺點
-
優點
1.處理結構化資料非常方便,
2.采用堆外記憶體,gc 開銷小
3.與 Hive 兼容,且支持 HQL、UDF 等
-
缺點
1.編譯時不能進行型別轉化安全檢查,運行時才能確定是否有問題,
2.序列化開銷仍需要改進,
3.對于物件支持不友好
? RDD 內部資料直接以物件形式存盤
? DataFrame 存盤的是 Row 物件而不能是自定義物件
Dataset
-
Spark1.6 之后新添加的特性,優化了 Spark SQL 執行引擎,
-
API 目前只支持 Scala 和 Java,
-
結合了 RDD 和 DataFrame 的優點,并引入一個新的概念 Encoder ,
當序列化資料時, Encoder 產生位元組碼與 off-heap 進行互動,能夠達到按需訪問資料的效果,而不用反序列化整個物件,Spark 目前還沒有提供自定義 Encoder 的 API,
Datasets 與 RDDs是很相似的,不同的是在網路中傳輸物件時
- RDD 使用 Java 序列化或 Kryo 序列化方式
- Datasets 使用專業 Encoder
編碼器與序列化
-
相同之處
編碼器和序列化都負責將物件轉換為位元組
-
不同之處
編碼器是動態生成的代碼,不需要將位元組反序列化為物件,
Spark 就可以直接執行許多操作(filter、sort 和 shuffle 等),
Dataset的優點
-
Dataset 整合了 RDD 和 DataFrame 的優點,支持結構化和非結構化資料;
-
和 RDD —樣,支持自定義物件存盤;
-
和 DataFrame —樣,支持結構化資料的 SQL 查詢;
-
采用堆外記憶體存盤,GC 友好; 型別轉化安全,代碼友好;
三者總結
RDD API 是函式式的,強調不變性,在大部分場景下傾向于創建新物件而不是修改老物件,
- 優點:帶來了干凈整潔的 API
- 缺點:在運行期傾向于創建大量臨時物件,對 GC 造成壓力
為了解決上述缺點
- 可以利用 mapPartitions 方法來多載 RDD 單個分片內的資料創建方式
- 可以利用可復用的可變物件的方式來減小物件分配和 GC 的開銷
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/420478.html
標籤:其他