😸在上一節中,我們學習了MaxComputer SQL的DML語言,并用DataWork給大家演示了一遍,今天我們進入內置函式的學習,這一部分中,我們接觸到的內置函式比較多,大家只要記住一些常用的,其他的函式知道有這么一個功能存在就行,對往期內容感興趣的小伙伴可以參考下面的文章👇:
- hadoop專題: hadoop系列文章.
- spark專題: spark系列文章.
- 阿里云系列: 阿里云MaxComputer SQL學習之DDL.
- 阿里云系列: 阿里云MaxComputer SQL學習之DML.
👀 今天所有的內置函式依舊會在DataWorks上給大家演示,讓大家了解內置函式的同時,也了解阿里云的大資料平臺,好了,讓我們開啟今日份的學習吧!
目錄
- 1. 內置函式的內容
- 2. 測驗資料表的建立
- 3. 各型別內置函式的介紹
- 3.1 值函式
- 3.1.1 數學運算函式
- 3.1.2 字串處理函式
- 3.1.3 日期型別函式
- 3.2 視窗函式
- 3.3 聚合函式和其他型別的函式
- 4. 總結
- 5. 參考資料
1. 內置函式的內容
內置函式主要包括以下幾個部分的函式:
- 值函式:數學運算、字串處理、日期處理函式
- 視窗函式:常見統計量類、排名類、偏移定位類、分組抽樣類
- 聚合函式:常見統計量類、字串類
- 其他函式:型別轉換函式、分支判別函式、其他
2. 測驗資料表的建立
依舊是建立一個臨時查詢
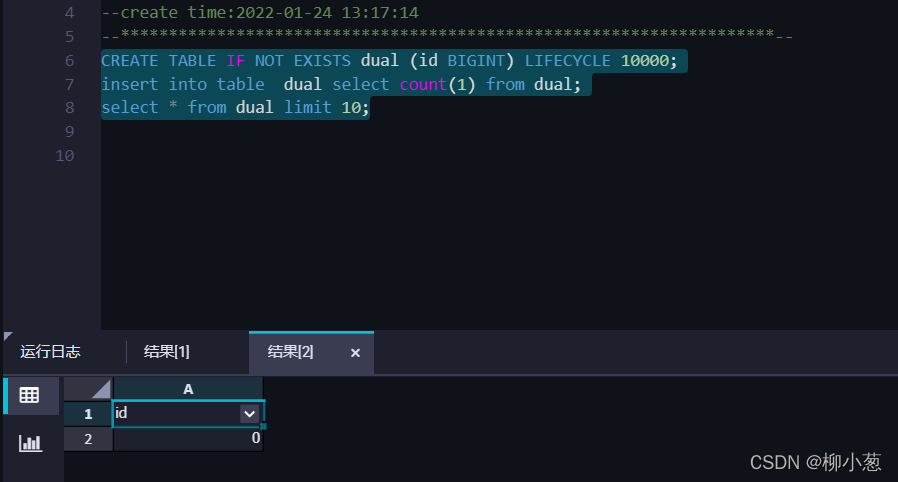
- 創建dual表,并插入資料
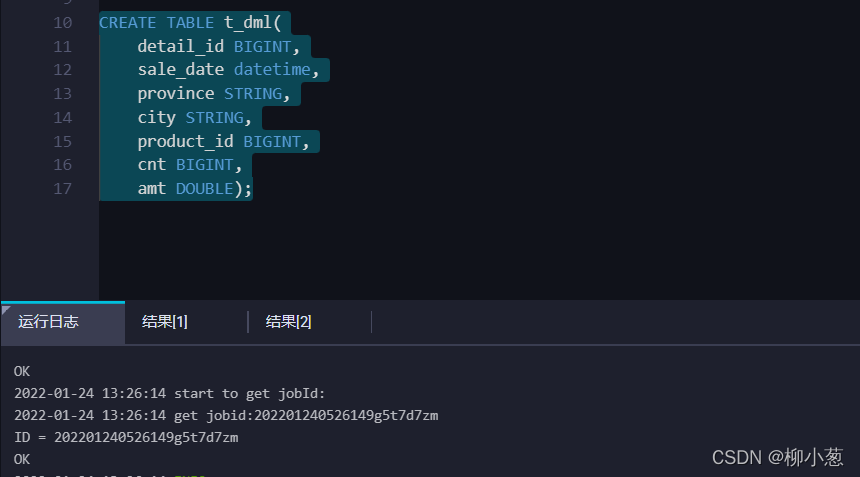
- 創建實驗測驗表t_dml
客戶端上傳資料
查看資料

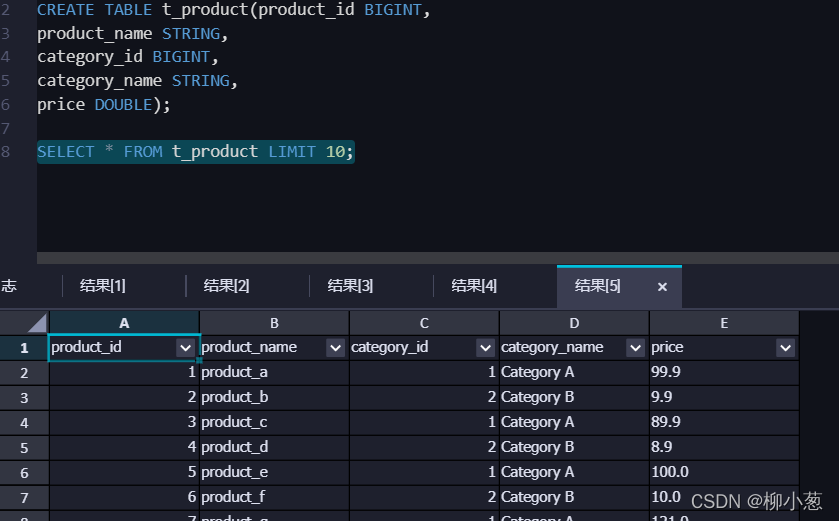
- 創建實驗測驗t_product表(程序同上)
- 創建實驗測驗t_sign表
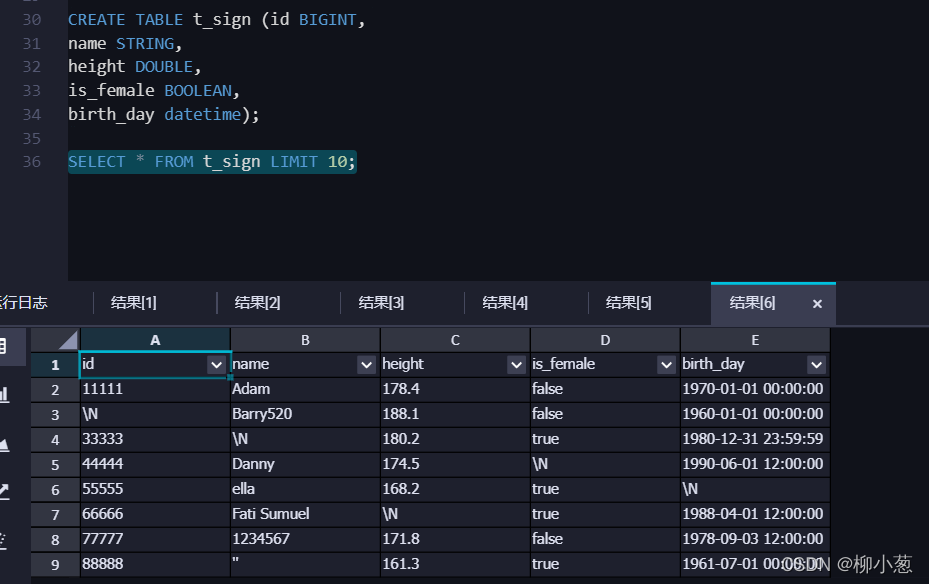
下面的演示階段
3. 各型別內置函式的介紹
3.1 值函式
3.1.1 數學運算函式
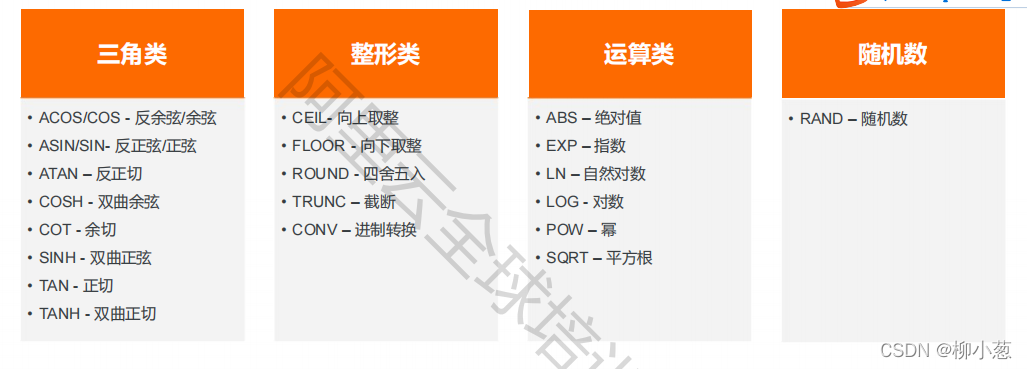
實驗
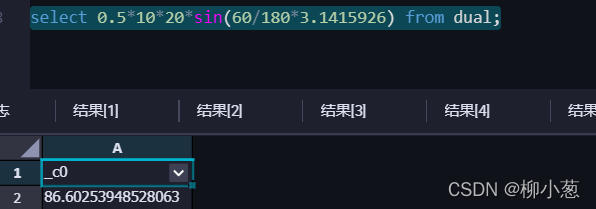
1.已知三角形兩邊長度為10,20,夾角為60度,求三角形面積?
2.對數字進行加工處理,請分別顯示數字 3.1415926 的向上取整值、向下取整值、四舍五入保留3位小數的值、截掉小數位的值以及用二進制來表示該值,

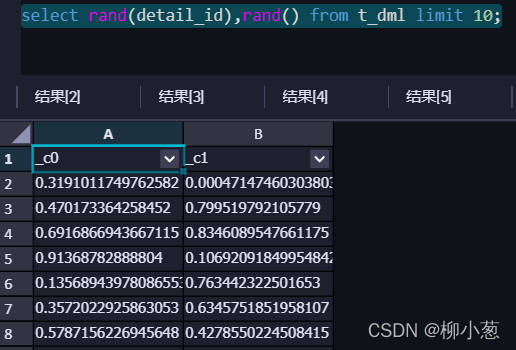
3.隨機函式
3.1.2 字串處理函式

實驗
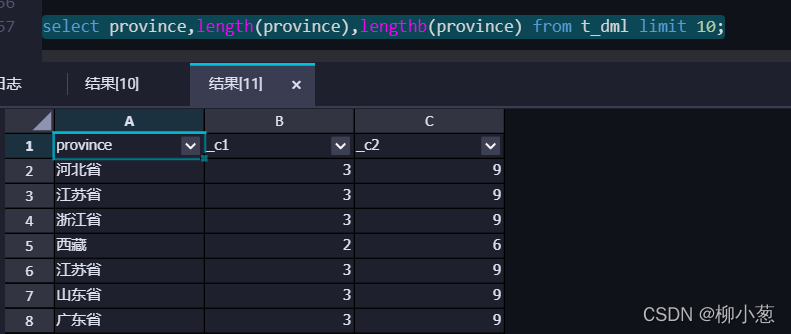
1.查看欄位字符、位元組長度
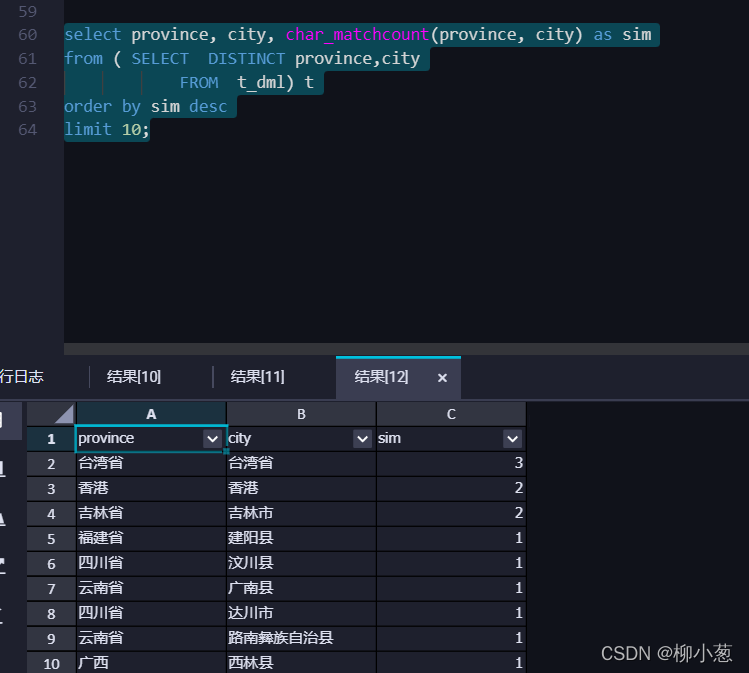
2.查找目前銷售記錄中,哪些省、市名字比較接近?
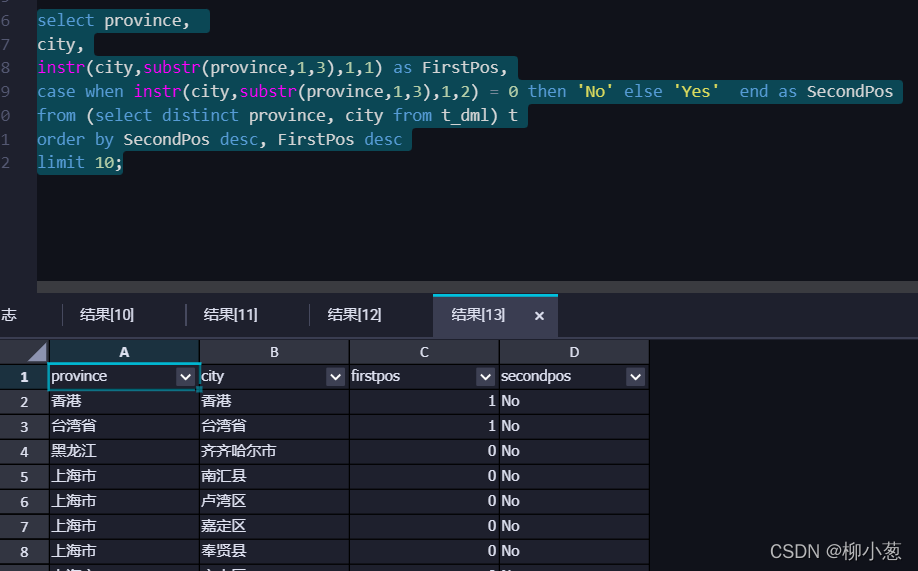
3.目前銷售記錄中,省份的第一個字在城市名中是否出現?有沒有出現多次的?
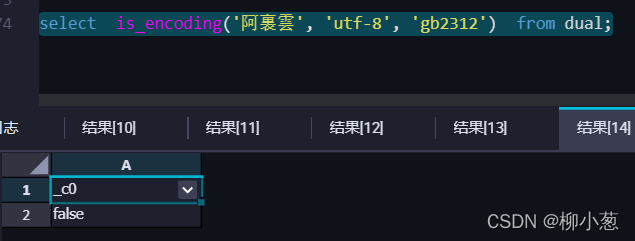
4.要把資料從一個編碼為 utf8 的庫匯入到一個字符集為 gb2132 的庫中,其中有些繁體字,如“阿裏雲”等字樣,請問會出現亂碼的情況嗎?
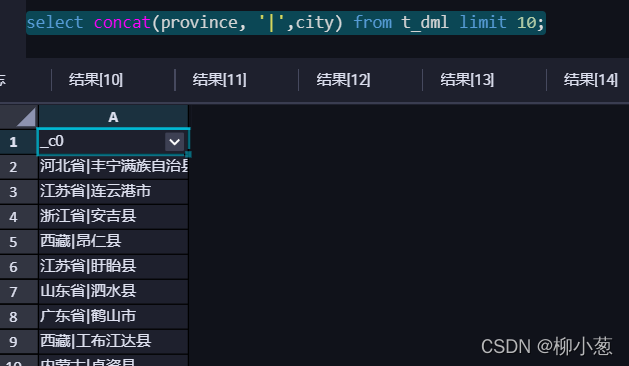
5.拼接字符,將省和市拼接起來,并用‘|’隔開
3.1.3 日期型別函式

實驗
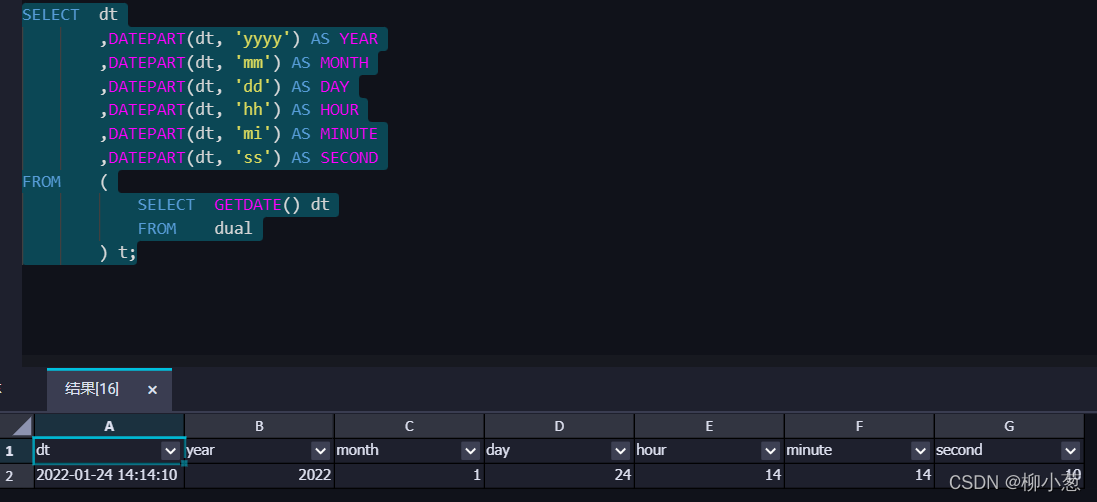
1.日期獲取:根據日期,截取部分資訊,截取年、月、日、時、分、秒
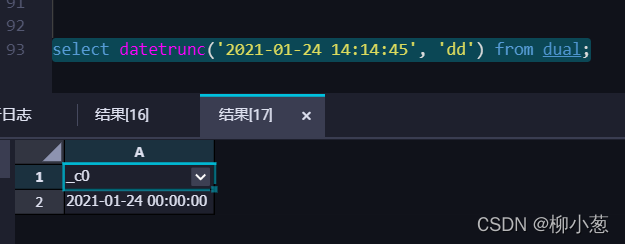
2.日期截取,截取天
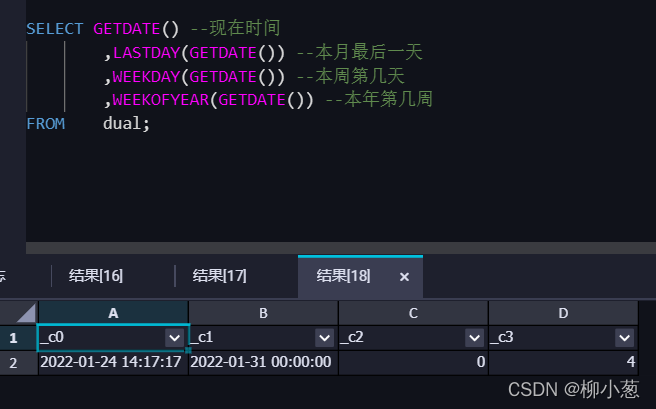
3.獲得具體日期
4.字串轉成日期, 日期轉換成字串
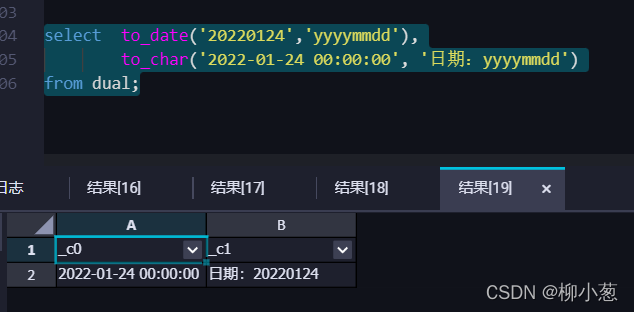
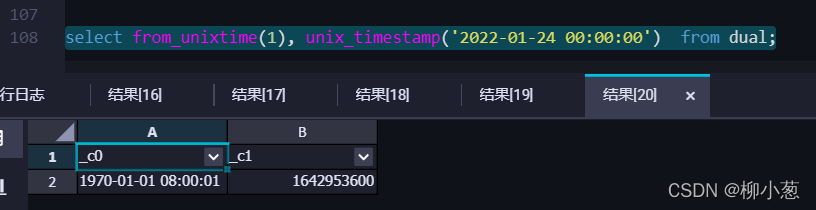
5.Unix時間和ODPS時間互轉
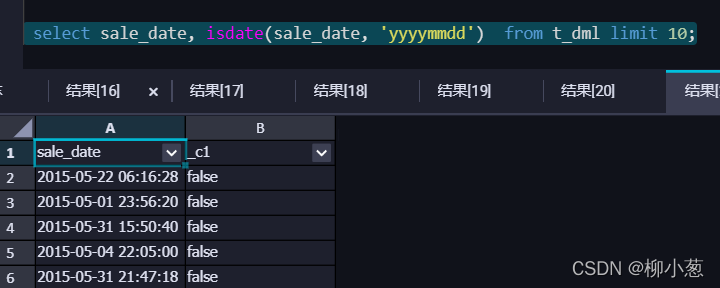
6.判斷字串是否滿足預定義的日期格式
7.日期運算:統計5月1日從產品5第一次成交后一小時三十分鐘內(含),產品5銷量(含第一次成交)占同期總銷量的比例:

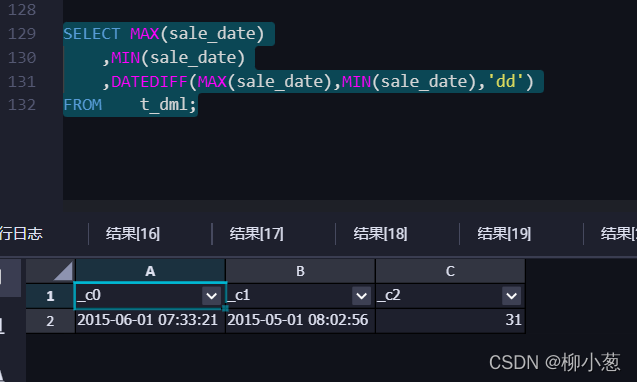
8.日期相減
3.2 視窗函式

實驗
1.根據5月份銷售資料,統計出日銷量波動最小的產品(即標準差最小),
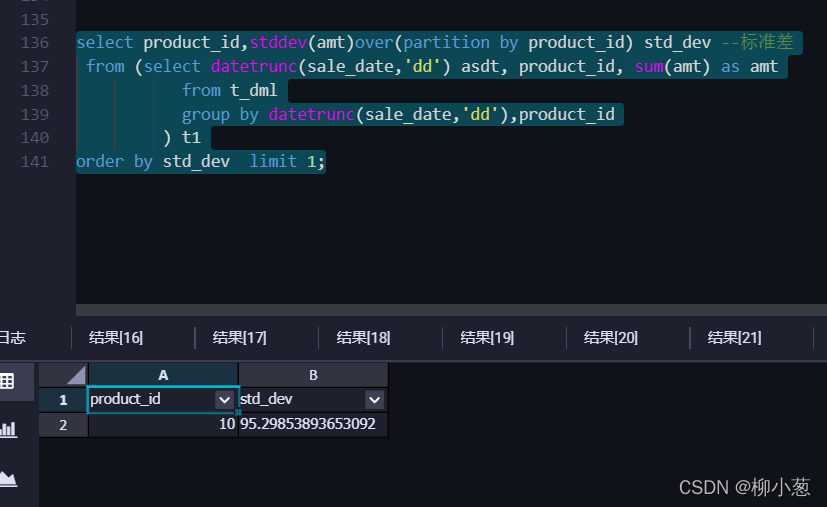
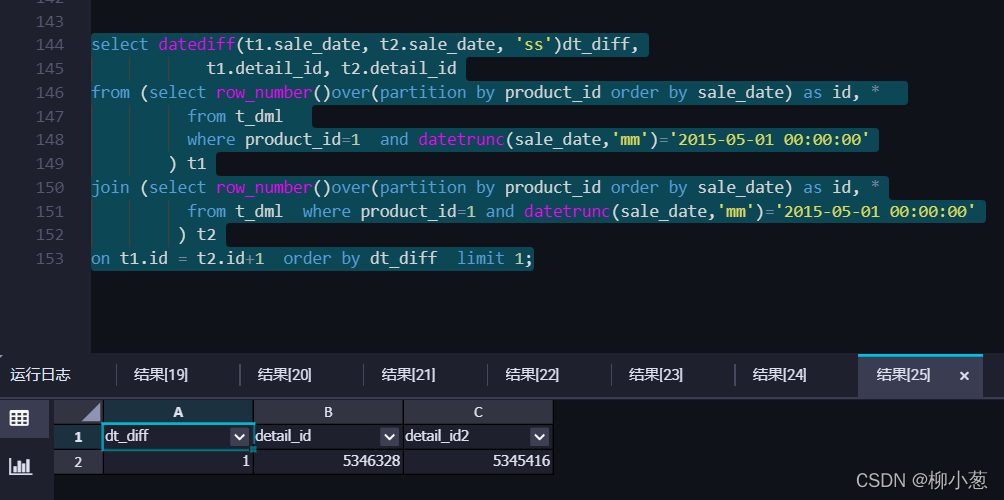
2.根據5月份銷售資料,統計出同一產品成交最短時間間隔(以產品1為例,列出出兩次成交時間差最小的記錄),
3.3 聚合函式和其他型別的函式

實驗
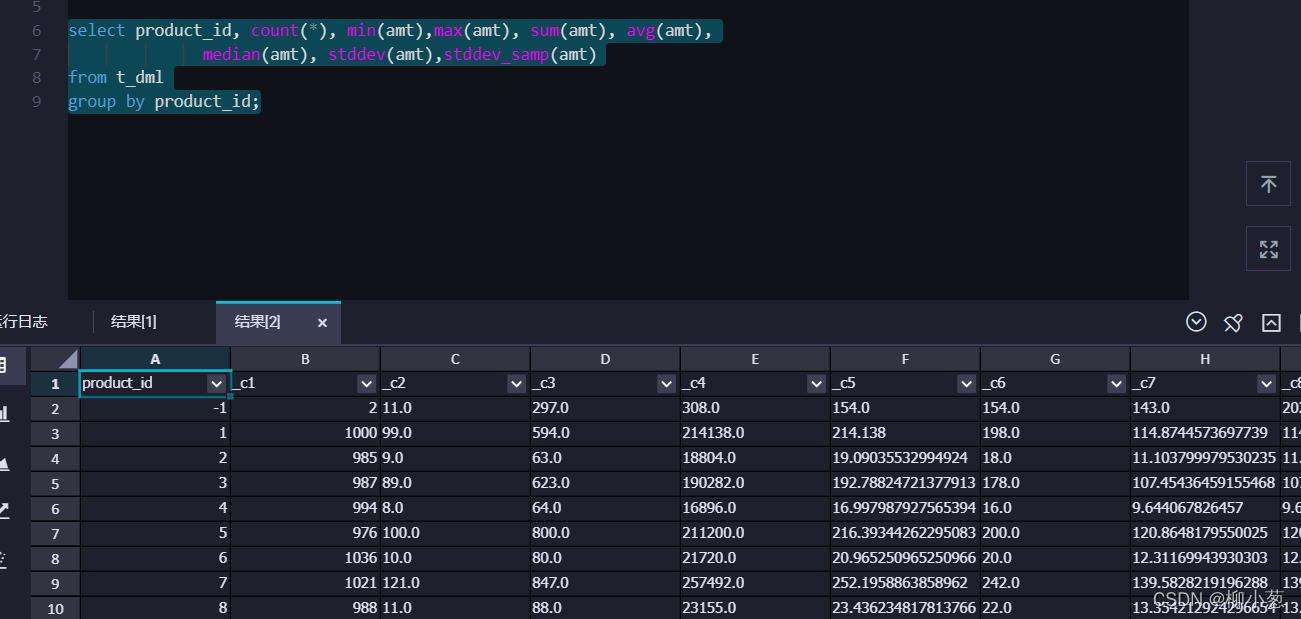
1.給出銷售資訊表t_dml中的不同產品的銷售金額的基本統計資訊,
2.將產品標稱單價在50-100元的,生成一個清單,不同產品名稱之間用|分隔開,

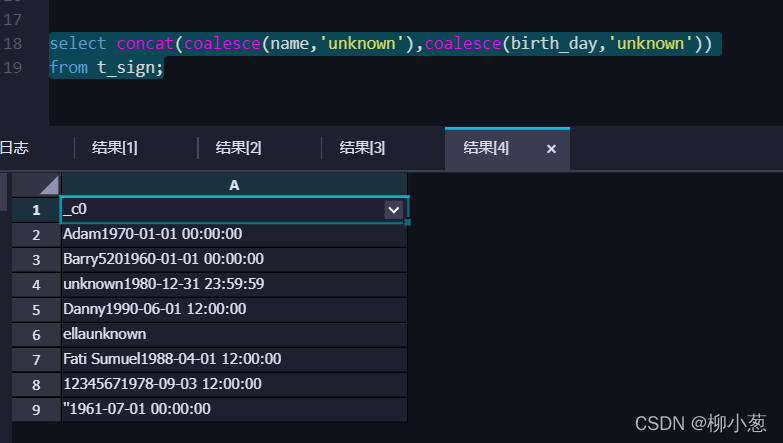
3.COALESCE 處理NULL值:將 t_sign 中的名字(name)和生日(birth_day)拼成一個串
4.decode 分支函式:將銷售記錄t_dml中浙江、上海和北京的銷量單獨統計出來:(實作if else的分支功能)

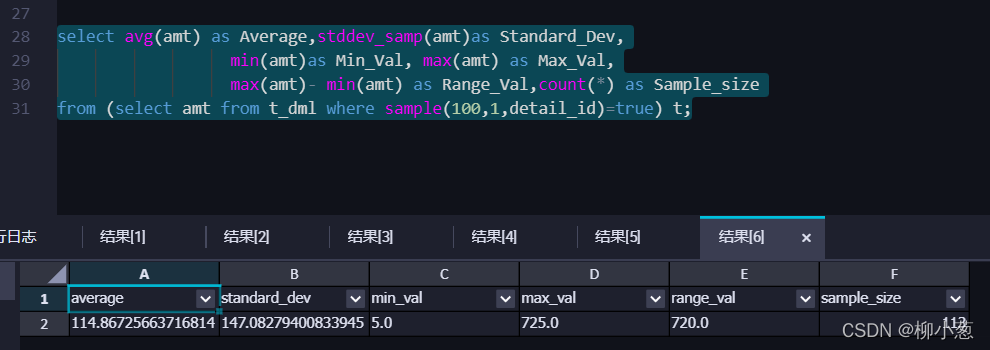
5.sample 采樣函式:通過采樣分析的手段,從銷售記錄表t_dml中得到1/100的資料,分析采樣樣本,試著推斷總體的銷售金額的平均值、標準差、極值、極差等,然后從總體中計算出這些統計量進行驗證,調整采樣比例,重復上述推斷程序,找到一個準確程度和樣本體量的平衡點,進一步思考:這個平衡點有多大參考價值?(100份取一份,)
4. 總結
在這些函式中,我的實驗部分使用的都是比較常用的函式,足以應付大多數的開發任務,如果上述函式滿足不了業務需求,可以嘗試自己撰寫函式,我們這里主要要記住以下部分:
- 平均值、最大最小值、常用的計算
- 日期格式轉換、相加減
- 磁區排序
- 字串處理空值、截取字符、處理正則等
5. 參考資料
《阿里云全球培訓中心》
《阿里云DataWorks使用手冊》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/420480.html
標籤:其他
下一篇:訊息佇列:RabbitMQ