通過MindSpore進行線性回歸AI訓練
Demo1: 對50個離散點進行簡單線性函式擬合
from mindspore import context
context.set_context(mode=context.GRAPH_MODE, device_target="CPU") #設定為CPU模式
import numpy as np
import matplotlib.pyplot as plt
from mindspore import dataset as ds
from mindspore.common.initializer import Normal
from mindspore import nn
from mindspore import Tensor
from mindspore import Model
import time
from IPython import display
from mindspore.train.callback import Callback
#定義資料集生成函式
def get_data(num, w=3.0, b=4.0):
for _ in range(num):
x = np.random.uniform(-10.0, 10.0)
noise = np.random.normal(0, 1) #定義隨機噪聲干擾,浮動范圍0~1
y = x * w + b + noise #y=3x+4+noise
yield np.array([x]).astype(np.float32), np.array([y]).astype(np.float32)
#使用get_data生成50組測驗資料,并可視化
eval_data = list(get_data(50))
x_target_label = np.array([-10, 10, 0.1])
y_target_label = x_target_label * 3 + 4
x_eval_label, y_eval_label = zip(*eval_data)
#繪圖
plt.scatter(x_eval_label, y_eval_label, color="red", s=5)
plt.plot(x_target_label, y_target_label, color="green")
plt.title("Eval data")
plt.show()
#資料增強
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['data', 'label']) #將生成的資料轉換為MindSpore的資料集
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
#通過定義的create_dataset將生成的1600個資料增強為了100組shape為16x1的資料集
data_number = 1600
batch_number = 16
repeat_number = 1
#使用資料集增強函式生成訓練資料,并查看訓練資料的格式,
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number) #訓練資料集
print("The dataset size of ds_train:", ds_train.get_dataset_size())
dict_datasets = next(ds_train.create_dict_iterator())
print(dict_datasets.keys())
print("The x label value shape:", dict_datasets["data"].shape)
print("The y label value shape:", dict_datasets["label"].shape)
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(1, 1, Normal(0.02), Normal(0.02)) #并使用Normal算子隨機初始化權重
def construct(self, x):
x = self.fc(x)
return x
net = LinearNet()
model_params = net.trainable_params()
for param in model_params:
print(param, param.asnumpy())
x_model_label = np.array([-10, 10, 0.1])
y_model_label = (x_model_label * Tensor(model_params[0]).asnumpy()[0][0] +
Tensor(model_params[1]).asnumpy()[0])
plt.axis([-10, 10, -20, 25])
plt.scatter(x_eval_label, y_eval_label, color="red", s=5)
plt.plot(x_model_label, y_model_label, color="blue")
plt.plot(x_target_label, y_target_label, color="green")
plt.show()
#定義前向傳播網路
net = LinearNet()
net_loss = nn.loss.MSELoss()
#定義反向傳播網路
opt = nn.Momentum(net.trainable_params(), learning_rate=0.005, momentum=0.9)
model = Model(net, net_loss, opt) #關聯前向和反向傳播網路
def plot_model_and_datasets(net, eval_data):
weight = net.trainable_params()[0]
bias = net.trainable_params()[1]
x = np.arange(-10, 10, 0.1)
y = x * Tensor(weight).asnumpy()[0][0] + Tensor(bias).asnumpy()[0]
x1, y1 = zip(*eval_data)
x_target = x
y_target = x_target * 3 + 4
plt.axis([-11, 11, -20, 25])
plt.scatter(x1, y1, color="red", s=5)
plt.plot(x, y, color="blue")
plt.plot(x_target, y_target, color="green")
plt.draw()
plt.pause(0.1)# 間隔的秒數:6s
plt.close()
#定義回呼函式
class ImageShowCallback(Callback):
def __init__(self, net, eval_data):
self.net = net
self.eval_data = eval_data
def step_end(self, run_context):
plot_model_and_datasets(self.net, self.eval_data)
display.clear_output(wait=True)
epoch = 1 #訓練資料集
imageshow_cb = ImageShowCallback(net, eval_data)
model.train(epoch, ds_train, callbacks=[imageshow_cb], dataset_sink_mode=False) #資料集下沉模式,CPU計算平臺設定為False
plot_model_and_datasets(net, eval_data)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
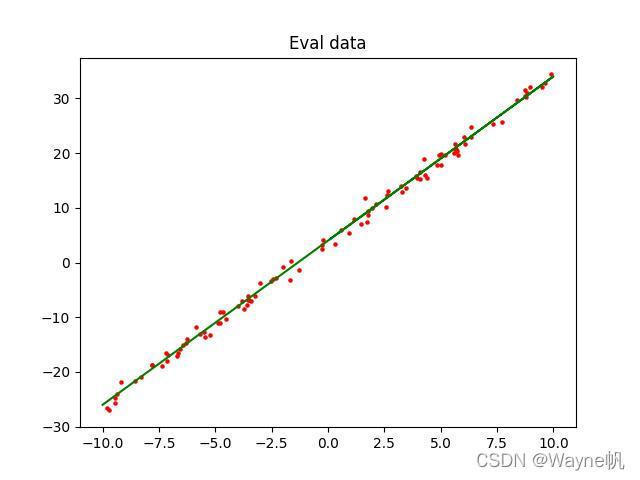
Answer1: 
可以看到通過訓練,藍色的線性函式不斷逼近綠色的目標函式,
模型初始化引數為:

訓練后回傳的引數為:

與目標函式
y
=
x
?
w
+
b
y = x ·w + b
y=x?w+b 引數
w
=
3
,
b
=
4
w=3, b=4
w=3,b=4 非常接近,
Demo2: 將訓練物件修改為輸入100組測驗資料,擬合線性函式 y = 2 ? x + 3 y=2·x+3 y=2?x+3
def get_data(num, w=2.0, b=3.0):
for _ in range(num):
x = np.random.uniform(-10.0, 10.0)
#使用get_data生成100組測驗資料,并可視化
eval_data = list(get_data(100))
x_target_label = np.array([-10, 10, 0.1])
y_target_label = x_target_label * 2 + 3
x_eval_label, y_eval_label = zip(*eval_data)
def plot_model_and_datasets(net, eval_data):
weight = net.trainable_params()[0]
bias = net.trainable_params()[1]
x = np.arange(-10, 10, 0.1)
y = x * Tensor(weight).asnumpy()[0][0] + Tensor(bias).asnumpy()[0]
x1, y1 = zip(*eval_data)
x_target = x
y_target = x_target * 2 + 3
#相應調成其余相關的引數即可
訓練后回傳的引數為:

仍可得到不錯的擬合效果,
Demo3: 二次函式曲線擬合
from mindspore import context
context.set_context(mode=context.GRAPH_MODE, device_target="CPU") #設定為CPU模式
import numpy as np
import matplotlib.pyplot as plt
from mindspore import dataset as ds
from mindspore.common.initializer import Normal
from mindspore import nn
from mindspore import Tensor
from mindspore import Model
import time
from mindspore.train.callback import LossMonitor
def get_data(num, w=2.0, b=4.0, c=3.0): #資料生成函式
for _ in range(num):
x = np.random.uniform(-1, 1)
noise = np.random.normal(0, 1)
y = w * x ** 2 + b * x + c + noise
# 回傳引數的時候壓縮在一個陣列內
yield np.array([x**2,x]).astype(np.float32), np.array([y]).astype(np.float32)
def get_data2(num, w=2.0, b=4.0, c=3.0): #生成散點圖資料
for _ in range(num):
x = np.random.uniform(-10.0, 10.0)
noise = np.random.normal(0, 1)
y = w * x ** 2 + b * x + c + noise
yield np.array([x]).astype(np.float32), np.array([y]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1): #資料增強函式
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['x','y'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 1600
batch_number = 16
repeat_number = 2
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
dict_datasets = next(ds_train.create_dict_iterator())
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
# 神經網路的input和output維度設定為2,1
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
eval_data = list(get_data(200))
eval_data2 = list(get_data2(200))
def plot_model_and_datasets(net, eval_data): #畫圖函式
weight = net.trainable_params()[0]
bias = net.trainable_params()[1]
x = np.arange(-10, 10, 0.1)
y = x*x*Tensor(weight).asnumpy()[0][0] +x * Tensor(weight).asnumpy()[0][1]+ Tensor(bias).asnumpy()[0]
x_eval_label, y_eval_label = zip(*eval_data2)
x_target = x
y_target = 2*x_target*x_target +4*x_target+3
np.linspace(start = 0, stop = 100, num = 5)
plt.axis([-11, 11, -1, 100])
plt.scatter(x_eval_label, y_eval_label, color="red", s=5)
plt.plot(x, y, color="blue")
plt.plot(x_target, y_target, color="green")
plt.show()
time.sleep(0.2)
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
net_loss = nn.loss.MSELoss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.005, momentum=0.9)
model = Model(net, net_loss, optim)
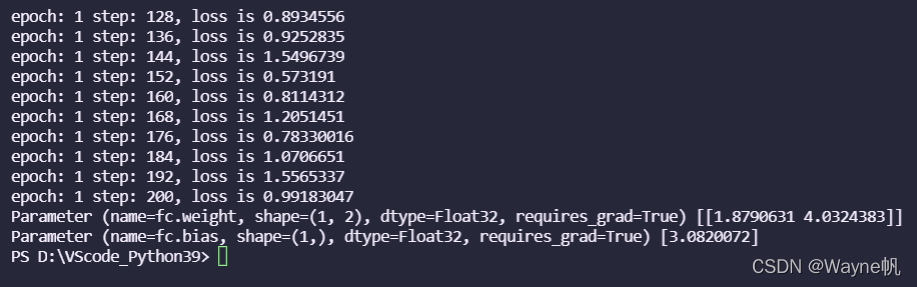
epoch = 1 #訓練資料集
model.train(epoch, ds_train, callbacks=[LossMonitor(8)], dataset_sink_mode=False) #資料集下沉模式,CPU計算平臺設定為False
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
plot_model_and_datasets(net, eval_data)
Answer3:
目標函式為
y
=
2
?
x
2
+
4
x
+
3
y = 2·x^2+4x+3
y=2?x2+4x+3,
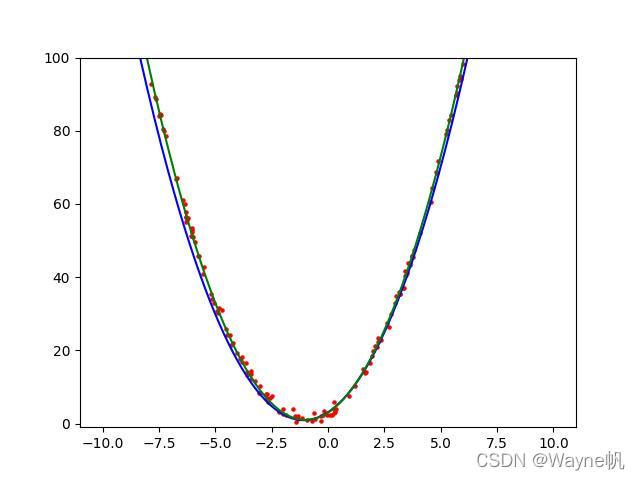
回傳引數為:
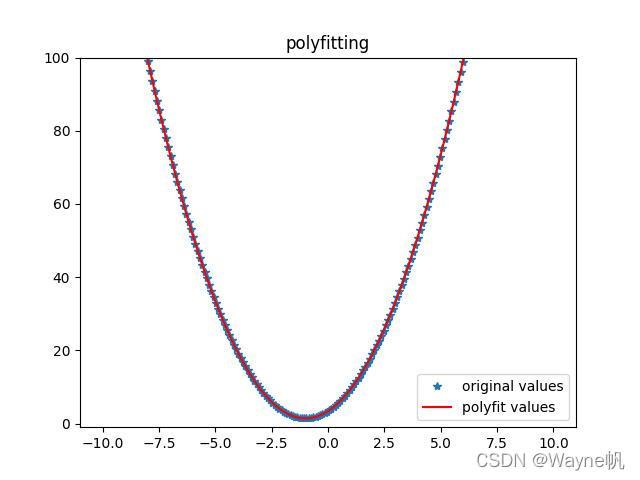
Demo4: 對于較小的資料量,另一種簡便的方法是利用ployfit多項式擬合,資料量較大的話需要分段進行擬合后再拼接,
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(start = -10, stop = 10, num = 200)
noise = np.random.normal(0, 1)
y = y = 2 * x ** 2 + 4 * x + 3 + noise
z1 = np.polyfit(x, y, 100) # 用3次多項式擬合
p1 = np.poly1d(z1)
print(p1) # 在螢屏上列印擬合多項式
yvals=p1(x) # 也可以使用yvals=np.polyval(z1,x)
plot1=plt.plot(x, y, '*',label='original values')
plot2=plt.plot(x, yvals, 'r',label='polyfit values')
plt.axis([-11, 11, -1, 100])
plt.legend(loc=4) # 指定legend的位置,讀者可以自己help它的用法
plt.title('polyfitting')
plt.show()
Answer4:
Tips:
- 除錯程序中發現的兩個小bug——用MindSpore進行擬合時,
x*x*Tensor(weight).asnumpy()[0][0]這種平方項無法用(x**2)*Tensor(weight).asnumpy()[0][0]替代,否則只能擬合從0開始的正半軸部分; - 在Demo3擬合的程序中
x = np.random.uniform(-1, 1)理論上畫出的散點圖只有一小段,但改成x = np.random.uniform(-10, 10)后訓練回傳的引數都是Nan.
參考檔案:
簡單線性函式擬合
基于MindSpore實作二次函式的擬合
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421845.html
標籤:AI
上一篇:即便學會了Markdown,也沒想到還可以這么干 —> 學會==提高效率
下一篇:TF/pytorch/caffe-CV/NLP/音頻-全生態CPU部署實戰演示-英特爾openVINO工具套件課程總結(下)