TF-pytorch-caffe~CV/NLP/音頻-全生態CPU部署實戰演示-英特爾openVINO工具套件課程總結(下)
在上中兩篇中我們充分理解了openvino的基本原理以及其硬體基礎,在這篇博客中主要通過演示在Linux系統下實作多個實體模型的演示,操作語言選擇熟悉的python語言(C++、java都可以官方技術檔案中找到)這次將會僅僅使用到CPU,不需要使用GPU,就可以實作模型部署與使用,
如果你想要在自己的電腦上運行這些程式,就需要在linux的環境下安裝好openvino,下面是官方的教學檔案鏈接,總的來說不算很難,后期可以參考我的博客截圖教程,
https://docs.openvino.ai/latest/openvino_docs_install_guides_installing_openvino_linux.html
在這里我推薦大家使用CSDN的官方平臺進行同步嘗試,任意點開一個intel的實驗平臺都可以使用已經配置好環境的linux系統,可以更快速地開始學習
下面是云平臺的的鏈接,點進去都可以免費使用1000分鐘
https://lab.csdn.net/welcome
選擇上面第二個或者第三個都是沒有問題的
七個經典演示實體
這七個演示從多個角度包括視覺、音頻、文本理解、自然語言的處理全面地演示openvino是如何完成人體姿態識別、音頻處理、目標檢測、文本識別與自問自答等等,這些演示完全不需要GPU,全部都會在CPU上實作,
1.人體動作姿勢識別示例(CV-pytorch)
2.影像著色示例(CV- VGG caffe)
3.音頻識別示例(音頻處理-ACLnet)
4.手寫公式/列印公式識別(CV)
5.環境深度識別(CV-medasnet-pytorch)
6.6.目標識別道路車流監控示例(CV-YOLO/SSD-TF)
7.替你做英語閱讀理解(NLP)——自動回答問題
這七個實體都采用先整體認知,然后再給出所有步驟的源代碼,在云平臺上都保證能夠跑通,

1.人體動作姿勢識別示例
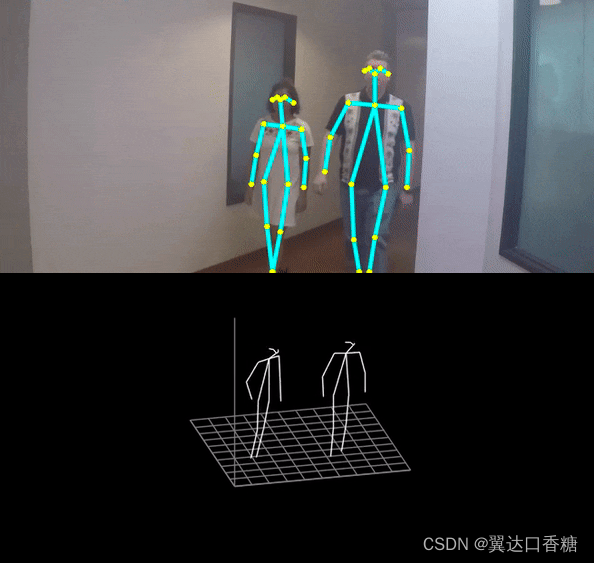
對人體姿勢或者動作的理解主要歸根于對人體關節點間關系的理解,下圖你可以看到黃色的小黃點就是檢測出來的人體關節點,人體姿態識別在安全、影視游戲甚至在現在的很火的一個熱詞–元宇宙中都有很廣泛的應用,

對于這個關節點的檢測雖然現在已經有了很多的演算法已經能夠實作,但是如果不使用GPU的條件下,能夠滿足FPS和精確度要求的可不算太多,在使用CPU的條件下,谷歌的mediapipe也擁有不俗
的性能,但是如果是對多路視頻流檢測,就很難保證FPS了,
openvino官方提供了一個標準的模型庫,下載后就可以直接使用人體檢測,當然后期我們更多會選擇把自己的模型轉化成部署在openvino上的模型,這是官方的下載模型的方法,需要的模型都可以通過下圖或者按照官網指導下載,這個在后面會直接給出下載器的代碼,

但是這些都可以在openVINO實作,以下是官方的產品檔案,你可以在下面鏈接中找到整套的操作方法,如果想要實作,還需要根據上面的地址提示安裝好openvino,
網址
https://docs.openvinotoolkit.org/latest/omz_demos_human_pose_estimation_3d_demo_python.html
二維碼

1、設定實驗路徑
設定OpenVINO的路徑:
export OV=/opt/intel/openvino_2021/
設定當前實驗的路徑:
export WD=~/OV-300/01/3D_Human_pose/
你還需要使用enable python 來構建示例,并且表示已經啟動了python,輸入以下的代碼
運行成功后如下圖
上面兩步簡單來說就是兩件事:導航到推理演示并且運行構建腳本,現在我們需要把庫添加到python路徑,如下圖的代碼
準備好后我們就可以使用python運行人體檢測姿態模型,- i 輸入的視頻可以選擇一段mp4的行人視頻就行,- d 這里表示選擇的設備,有顯卡可以使用GPU,沒顯卡或者想用CPU就填CPU,
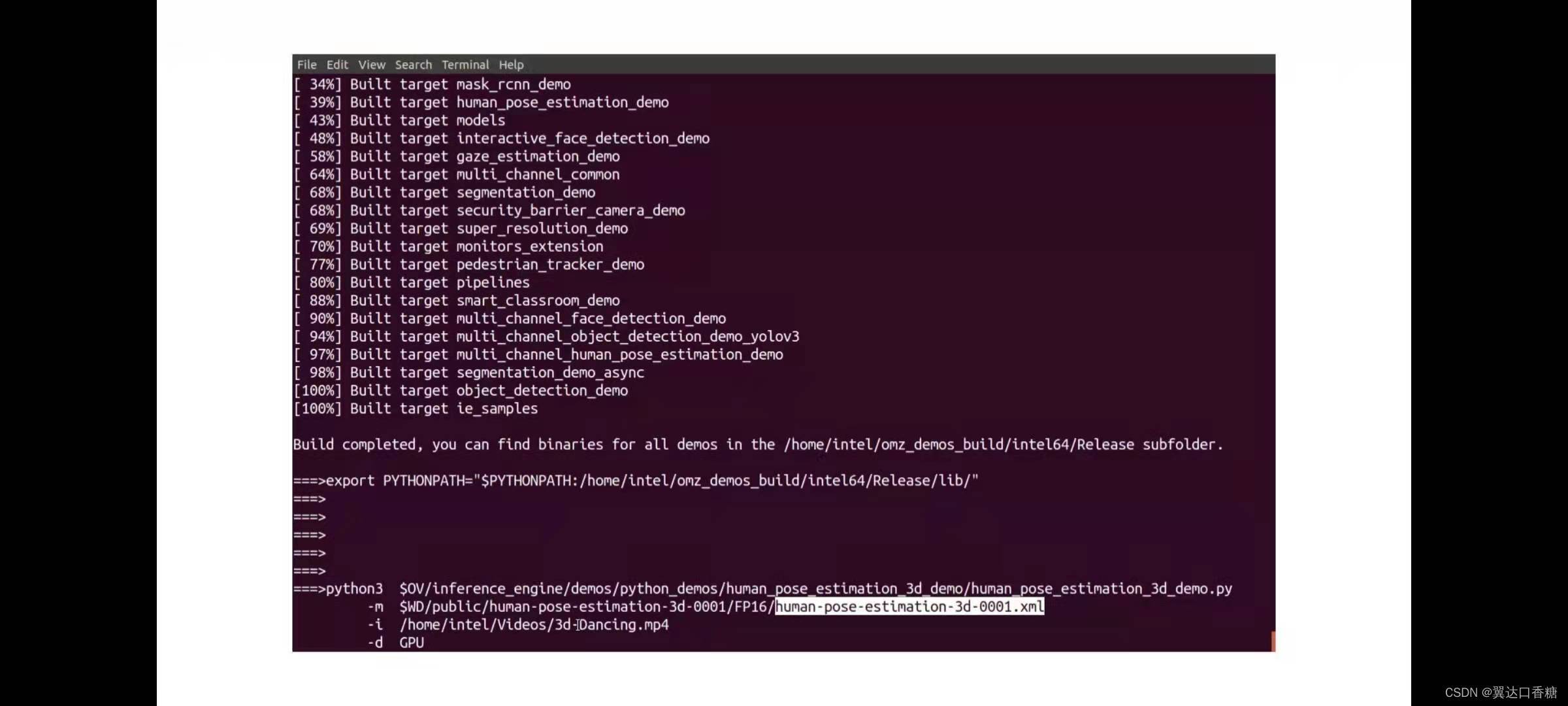
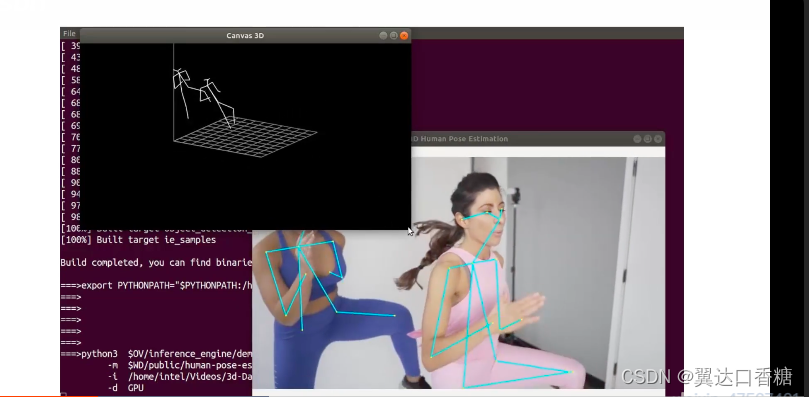
運行后你可以看到對人體檢測以及三位人體骨骼視圖
原始碼部分
1.人體動作姿勢識別示例
設定實驗路徑
設定OpenVINO的路徑:
export OV=/opt/intel/openvino_2021/
設定當前實驗的路徑:
export WD=~/OV-300/01/3D_Human_pose/
運行初始化OpenVINO的腳本
source $OV/bin/setupvars.sh
當你看到:[setupvars.sh] OpenVINO environment initialized 表示OpenVINO環境已經成功初始化,
運行OpenVINO依賴腳本的安裝
進入腳本目錄:
cd $OV/deployment_tools/model_optimizer/install_prerequisites/
安裝OpenVINO需要的依賴:
sudo ./install_prerequisites.sh
PS:這個步驟是模擬開發機本地進行OpenVINO使用的步驟,所以 之后你在本地使用OpenVINO之前需要遵循此步驟,
安裝OpenVINO模型下載器的依賴檔案
進入到模型下載器的檔案夾:
cd $OV/deployment_tools/tools/model_downloader/
安裝模型下載器的依賴:
python3 -mpip install --user -r ./requirements.in
安裝下載轉換pytorch模型的依賴:
sudo python3 -mpip install --user -r ./requirements-pytorch.in
安裝下載轉換caffe2模型的依賴:
sudo python3 -mpip install --user -r ./requirements-caffe2.in
PS:此步驟為模擬開發機本地進行OpenVINO使用的步驟,所以 之后你在本地使用OpenVINO之前需要遵循此步驟,
通過模型下載器下載人體姿勢識別模型
正式進入實驗目錄:
cd $WD
查看human_pose_estimation_3d_demo需要的模型串列:
cat /opt/intel/openvino_2021//deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
通過模型下載器下載模型:
python3 $OV/deployment_tools/tools/model_downloader/downloader.py --list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst -o $WD
使用模型轉換器把模型轉換成IR格式
OpenVINO支持把市面上主流的框架比如TensorFlow/Pytorch->ONNX/CAFFE等框架構建好的模型轉換為IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
值得注意的是,OpenVINO的推理引擎只能夠推理經過轉換完成的IR檔案,對市面上的語言框架是不能直接使用的,無法直接推理.pb/.caffemode/.pt等檔案,所以這一步不要遺漏了,
編譯OpenVINO的Python API
只需要編譯一次:
source $OV/inference_engine/demos/build_demos.sh -DENABLE_PYTHON=ON
如果你需要使用OpenVINO的PythonAPI,請加入如下編譯出來的庫地址(否則會找不到庫):
export PYTHONPATH="$PYTHONPATH:/home/dc2-user/omz_demos_build/intel64/Release/lib/"
播放待識別的實驗視頻
請手動輸入如下命令來播放視頻:
show 3d_dancing.mp4
(建議用鍵盤逐字母進行輸入)
運行人體姿勢識別Demo
python3 $OV/inference_engine/demos/human_pose_estimation_3d_demo/python/human_pose_estimation_3d_demo.py -m $WD/public/human-pose-estimation-3d-0001/FP16/human-pose-estimation-3d-0001.xml -i 3d_dancing.mp4 --no_show -o output.avi
時間會有幾分鐘的延遲,如果螢屏出現Inference Completed!! 則表示推理成功了,請輸入“ls”羅列當前檔案夾的所有檔案,轉換并播放識別結果視頻,
由于平臺限制,我們必須先將輸出結果視頻轉換為MP4格式,使用如下命令:
ffmpeg -i output.avi output.mp4
手動輸入如下命令進行推理結果視頻播放:
show output.mp4
影像著色
在這個演示中你可以運用模型使用任意一張灰度影像,將這張灰度圖片還原這張影像原來的顏色或者重新著色,

這其中所需要做的作業就是需要在沒有顏色的情況下,判斷出物體的顏色,對物體進行推測,一般來說馬皮不太可能是黃色,大概率是棕色白色黑色,樹葉是綠色的,這些都可以通過模型對大量訓練集的學習來實作,
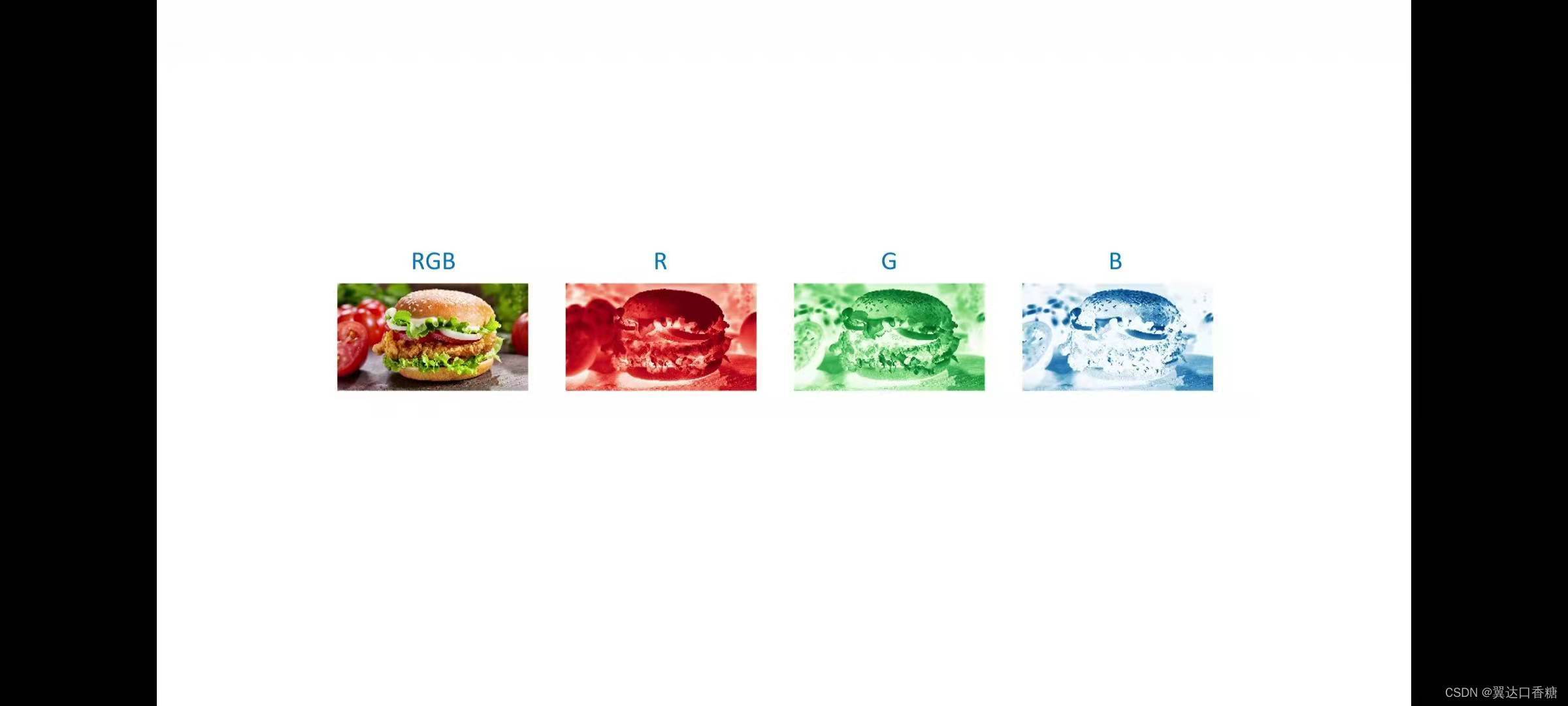
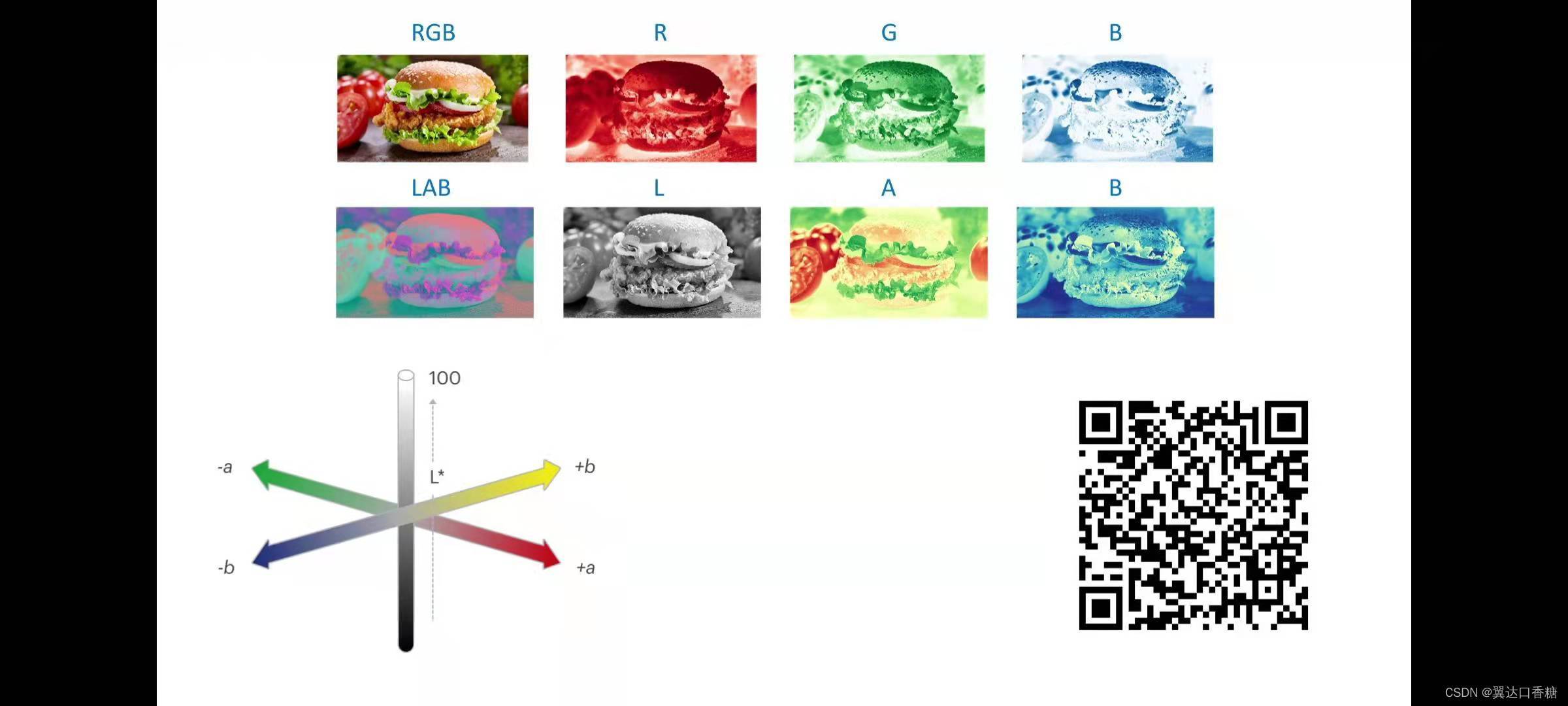
顏色在上篇有提到過圖片的顏色主要是由三色(RGB)組成的:紅黃藍三種顏色,這三種顏色組成了圖片的顏色通道,通過使用不同顏色的通道我們就可以合成任一種顏色,
同樣影像也可以通過LAB來表示,下面是LAB影像范例,他可以由L、A、B三種通道組成,A通道表示紅色和綠色的值,B通道表示黃色和藍色的值,L通道表示白到黑的值變化,
在這個演示中使用的是RGB影像輸入,然后提取L通道用作預測A和B通道,并且結合L通道重建RGB影像,掃描二維碼就二維碼可以獲取指導,
點開技術檔案你可以了解到官方提供這樣的可能模型有兩個,你可以查看模型,規格,準確性等等,
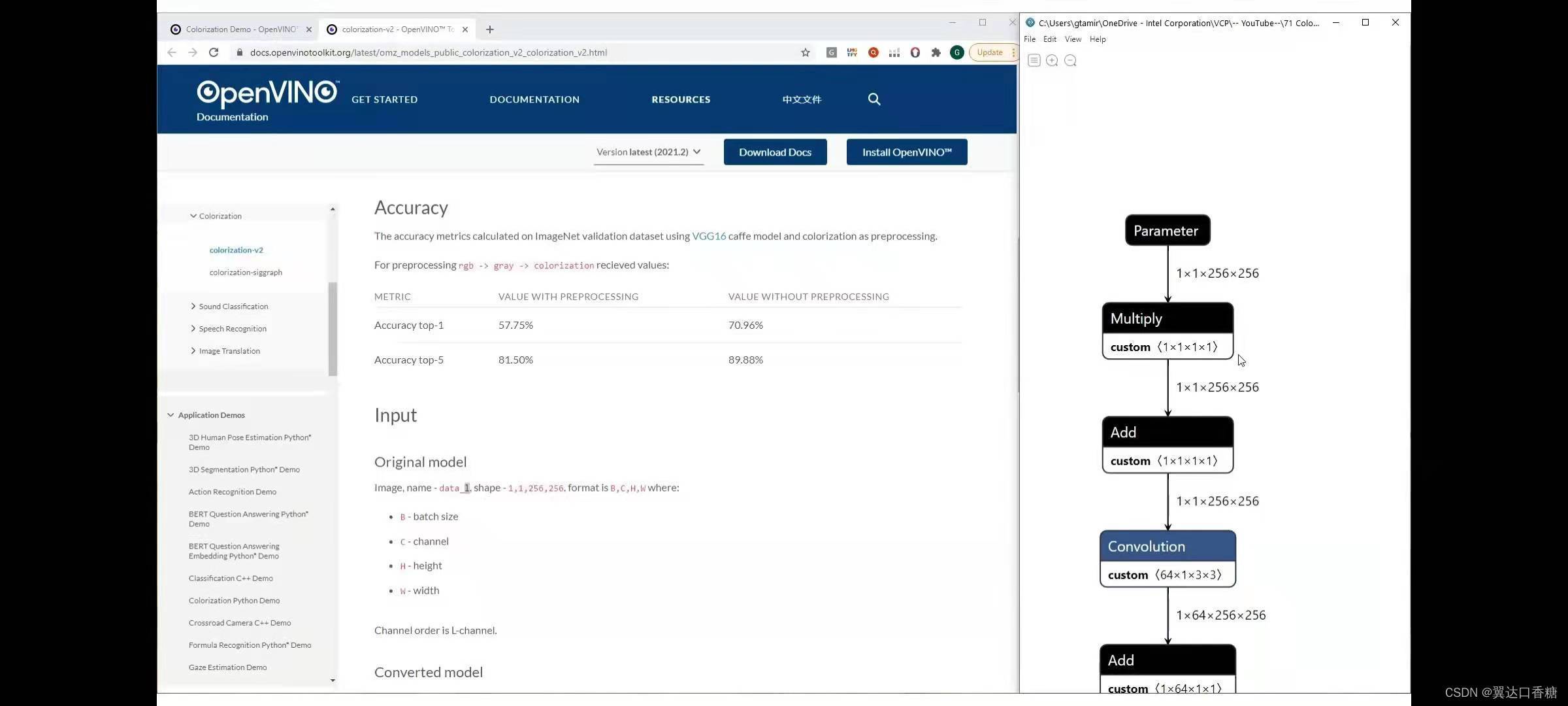
右邊這個圖是在前面介紹過的可以查看模型結構的程式,你可以在此處看到圖片的輸入是11256256(像素)通道影像,
當然,在這里我們使用L輸入,A和B通道也可以作為輸入的,
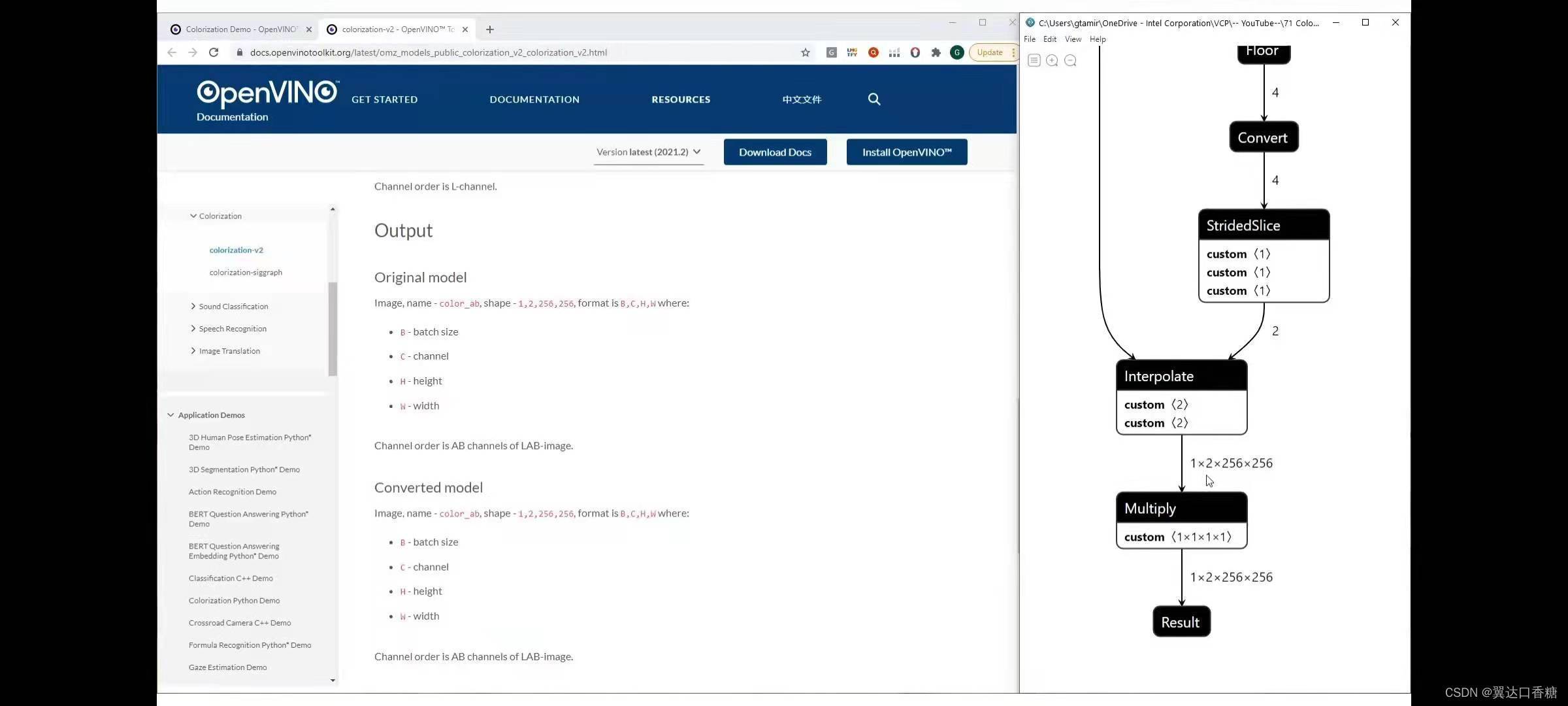
在模型的最后你講會得到一個12256256的輸出JPG圖片
下圖是官方的源代碼,你可以在這里看到影像rgb,這是原始輸入影像(img_rgb=*),我們正在提取lab(img_lab=)表示灰度影像,并使用(img_l_rs=**)調整大小的通道作為神經網路的輸入

這是我們下達的推理指令
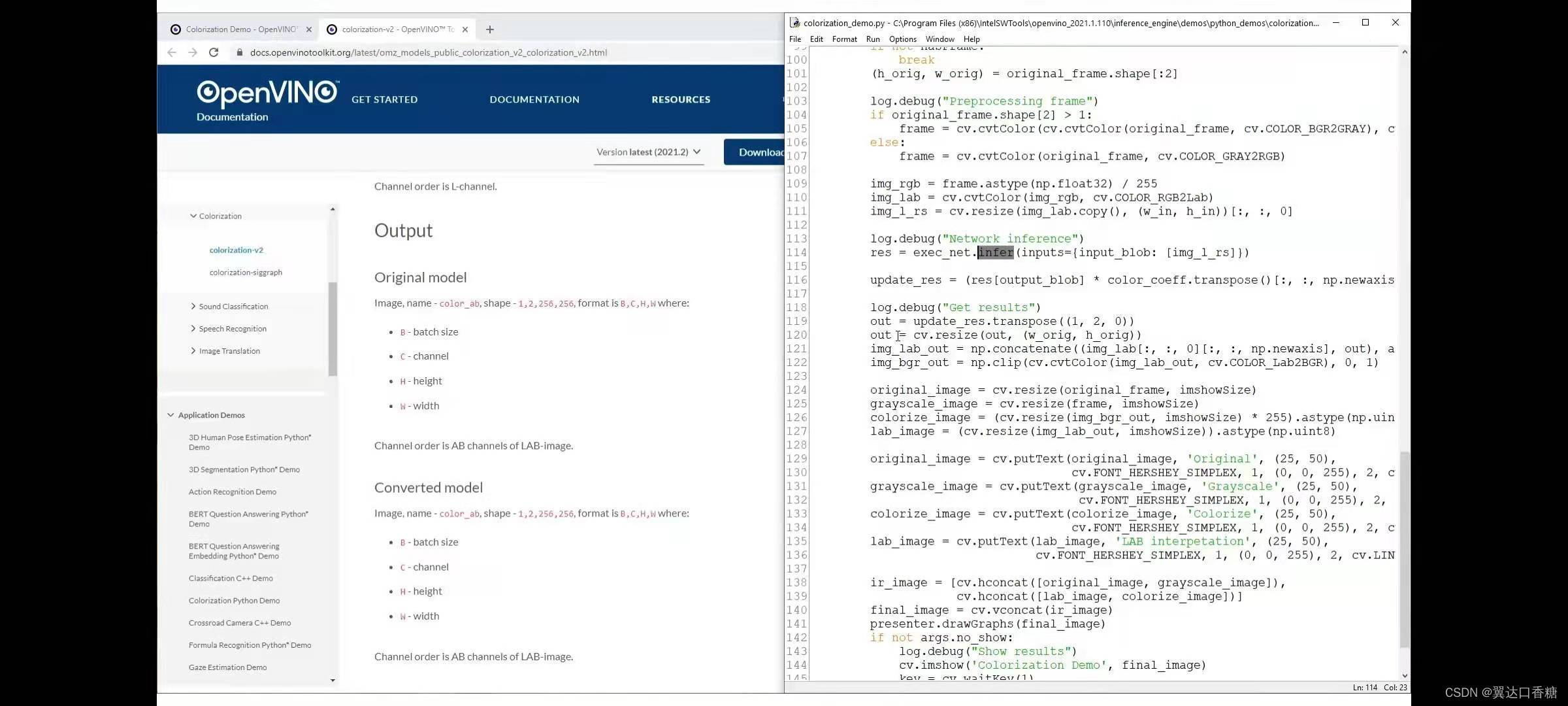
我們為了對比多個影像的效果,構建輸出lab顯示,輸出rgb或bgr
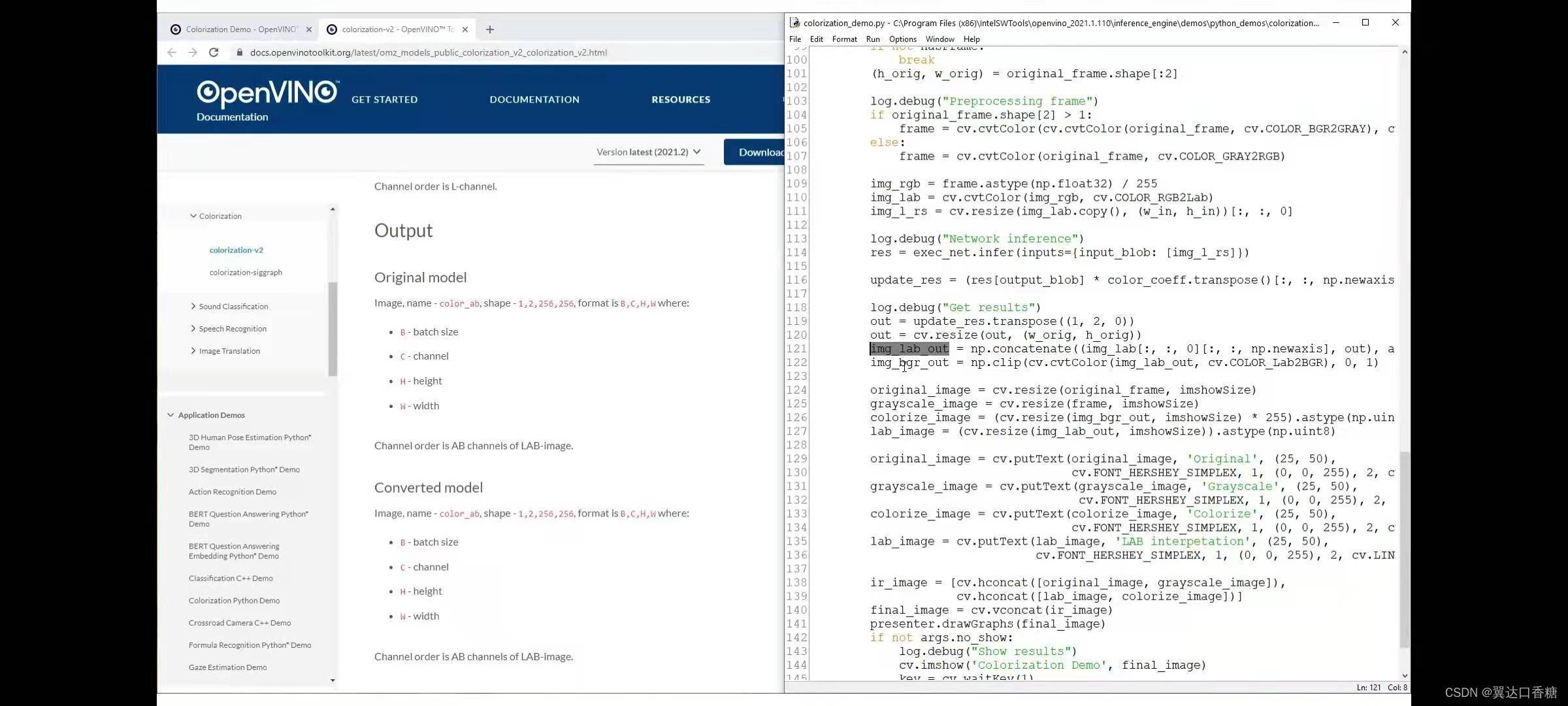
這里如果是銜接著第一個實驗實驗的話就可以不用初始化openVINO(source指令)和定義OV、WD(非必須),這里直接進入了作業目錄,使用cat可以查看demo的所需模型
你可以看到目錄下的模型
呼叫模型下載器下載兩個模型,并將他們放在我們的作業目錄中下載第一個模型和第二個模型
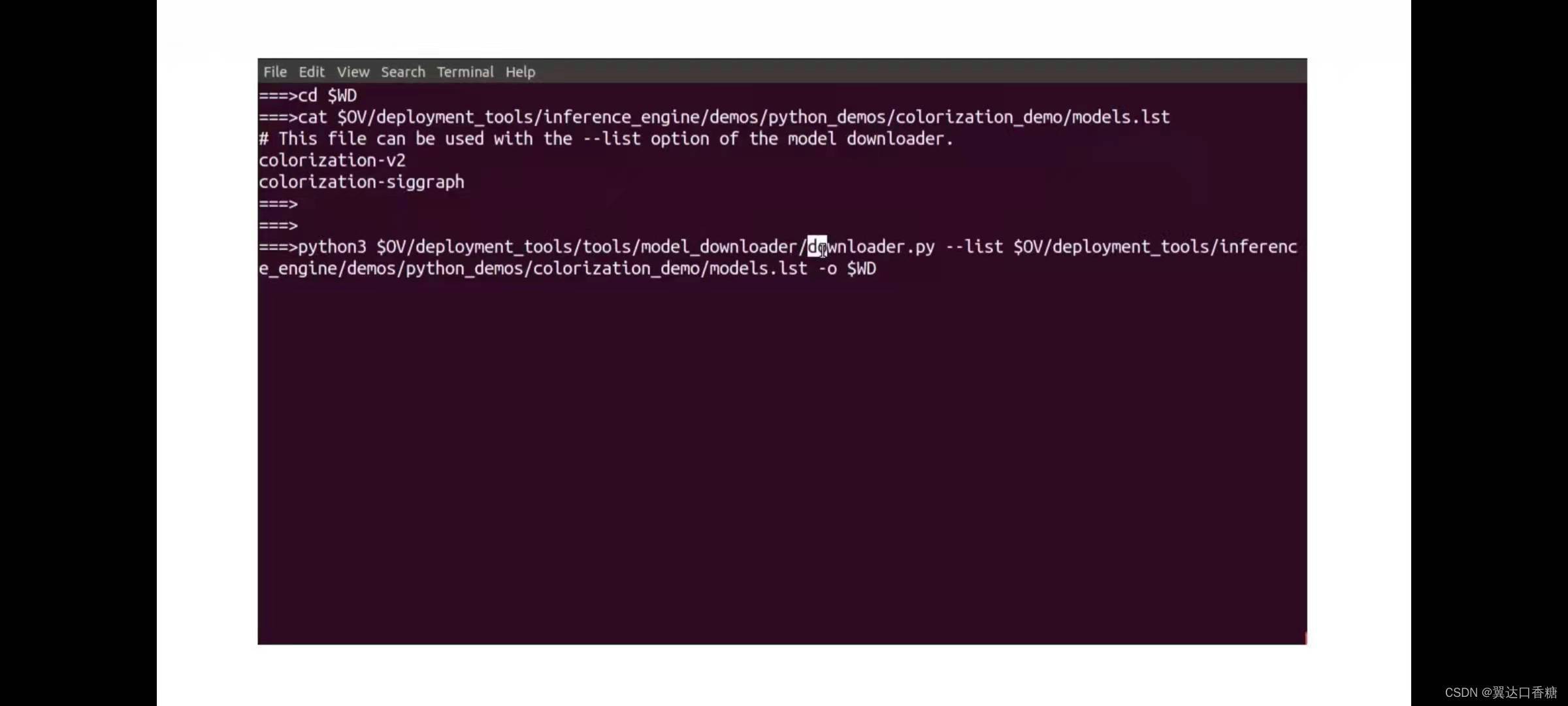
下載成功后如下圖
你可以在上面提示的路徑中找到這兩個模型
現在進行模型轉化,將兩個模型都轉化為onex和IR,
然后運行著色演示就可以給灰度影像上色,

原始碼
2.影像著色示例
設定實驗路徑
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Colorization/
初始化OpenVINO
source $OV/bin/setupvars.sh
開始實驗
正式進入作業目錄:
cd $WD
查看該demo的所需模型:
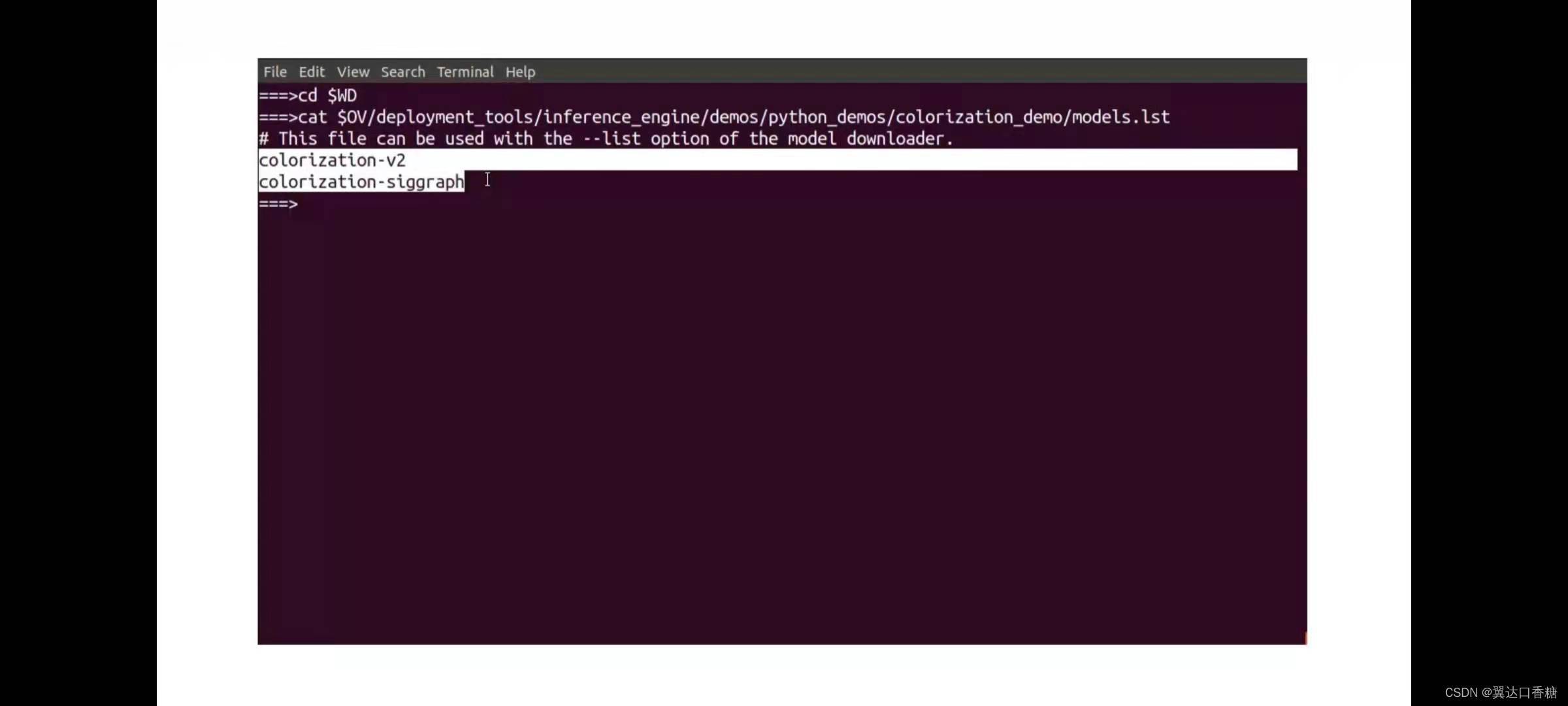
cat $OV/deployment_tools/inference_engine/demos/colorization_demo/python/models.lst
由于該實驗模型較大,模型已經提前下載好了,請繼續下一步,
查看原始視頻
所有show命令都請手動輸入:
show butterfly.mp4
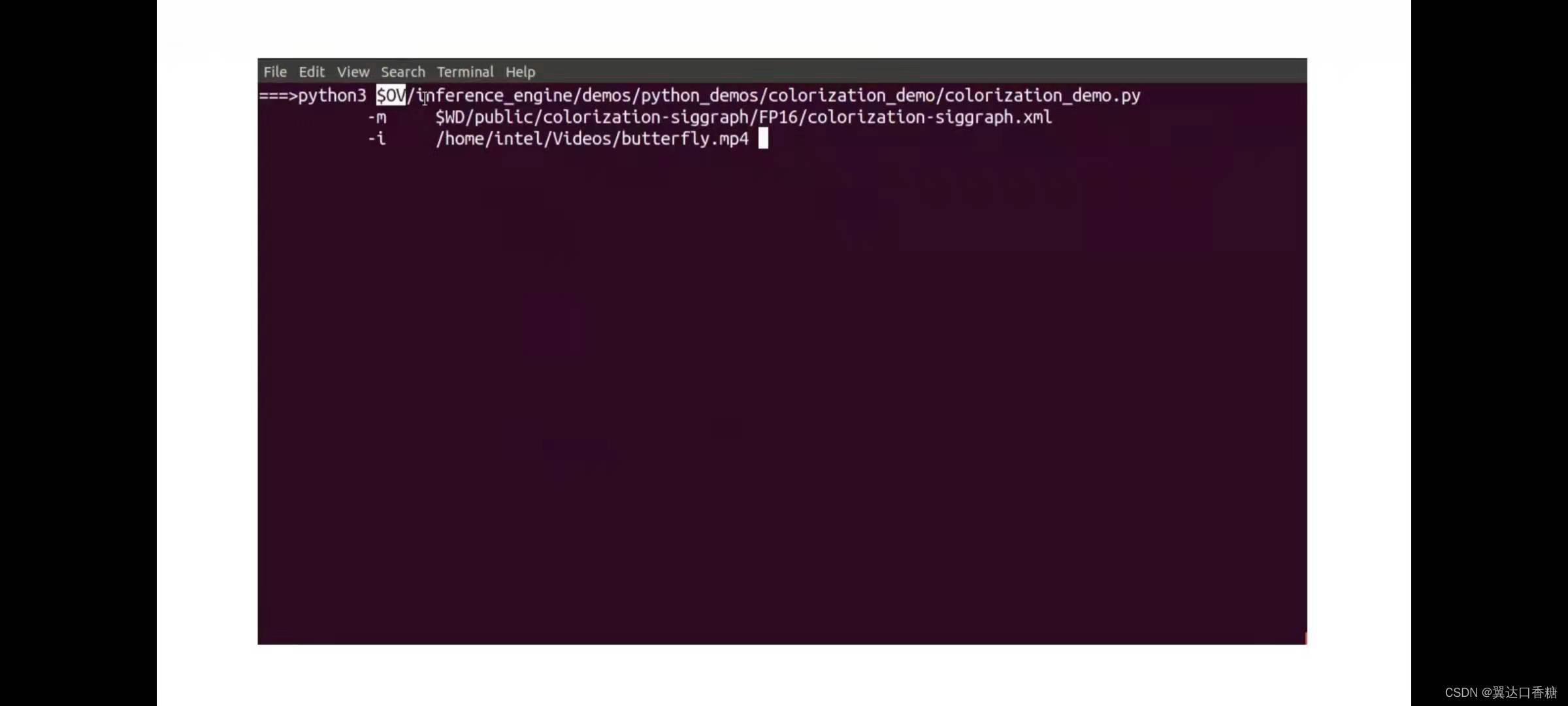
運行著色Demo
python3 $OV/inference_engine/demos/colorization_demo/python/colorization_demo.py -m $WD/public/colorization-siggraph/colorization-siggraph.onnx -i butterfly.mp4 --no_show -o output.avi
這需要幾分鐘時間,你將會看到“Inference Completed”的字樣,輸出avi將保存于當前檔案夾,使用小寫“LL”命令查看當前檔案夾,
查看著色實驗的輸出結果視頻
請先使用ffmpeg將.avi轉換為.mp4格式:
ffmpeg -i output.avi output.mp4
手動輸入播放視頻的指令:
show output.mp4
三、音頻識別示例(音頻處理)
官方檔案的資料可以掃描下方的二維碼進入技術檔案

Demo,如何運行基于dl streaming的聲音檢測和分類,音頻信號有時進入模型訓練或者推理時需要大量的預處理,但是這個演示的一個亮點是音頻是不需要與處理的,這里用的是wave檔案,用作神經網路的輸入,幾乎沒有預處理,只是在我們需要的時候,重新采樣智所需的速率ACLnet是我們用于實驗室的神經網路
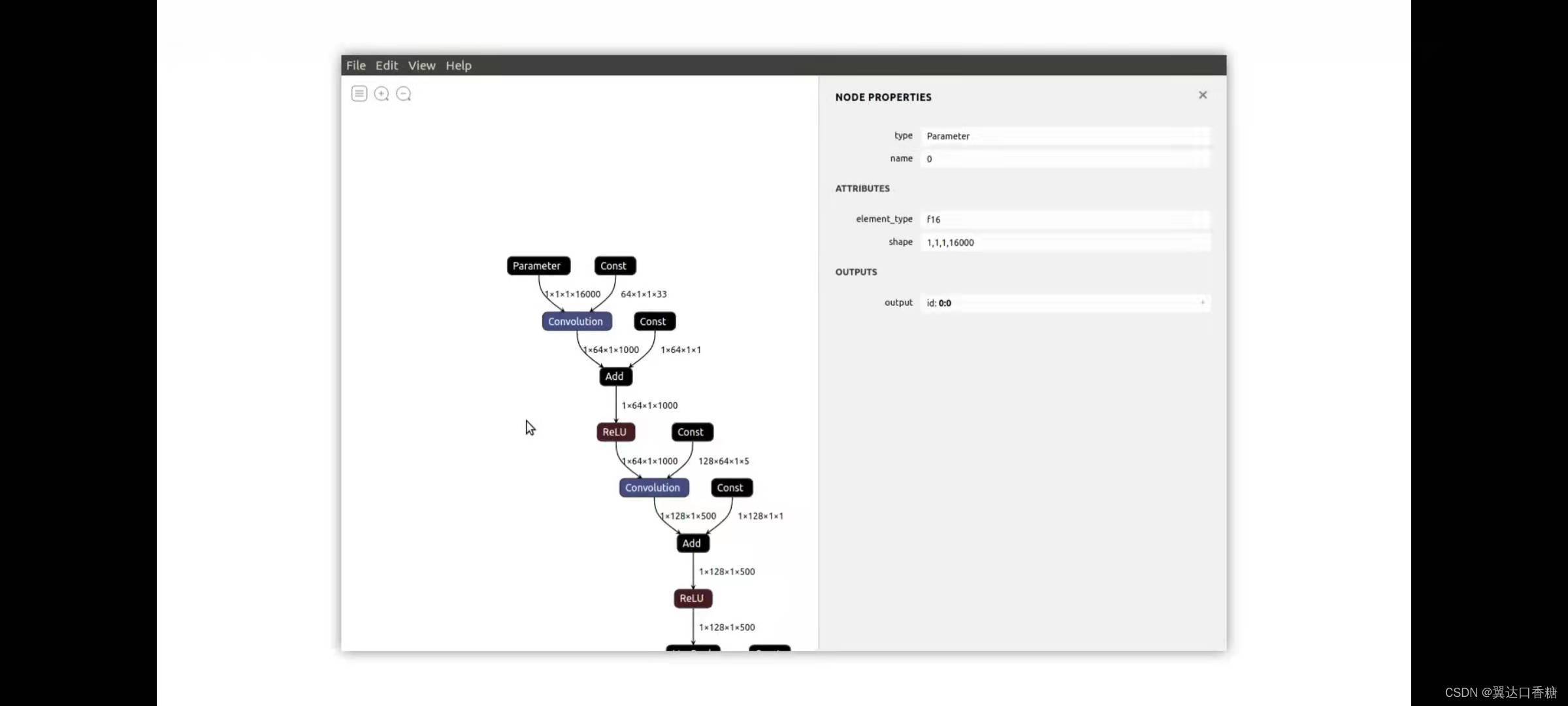
通程序式可以查看acl net神經網路的概況

CLAnet將時域中包含16000個示例的向量作為輸入前兩個卷積層提取低級光譜特征,接下來是高級特征,在中篇中我們提到過聲音是先轉化成光譜再進行處理的,
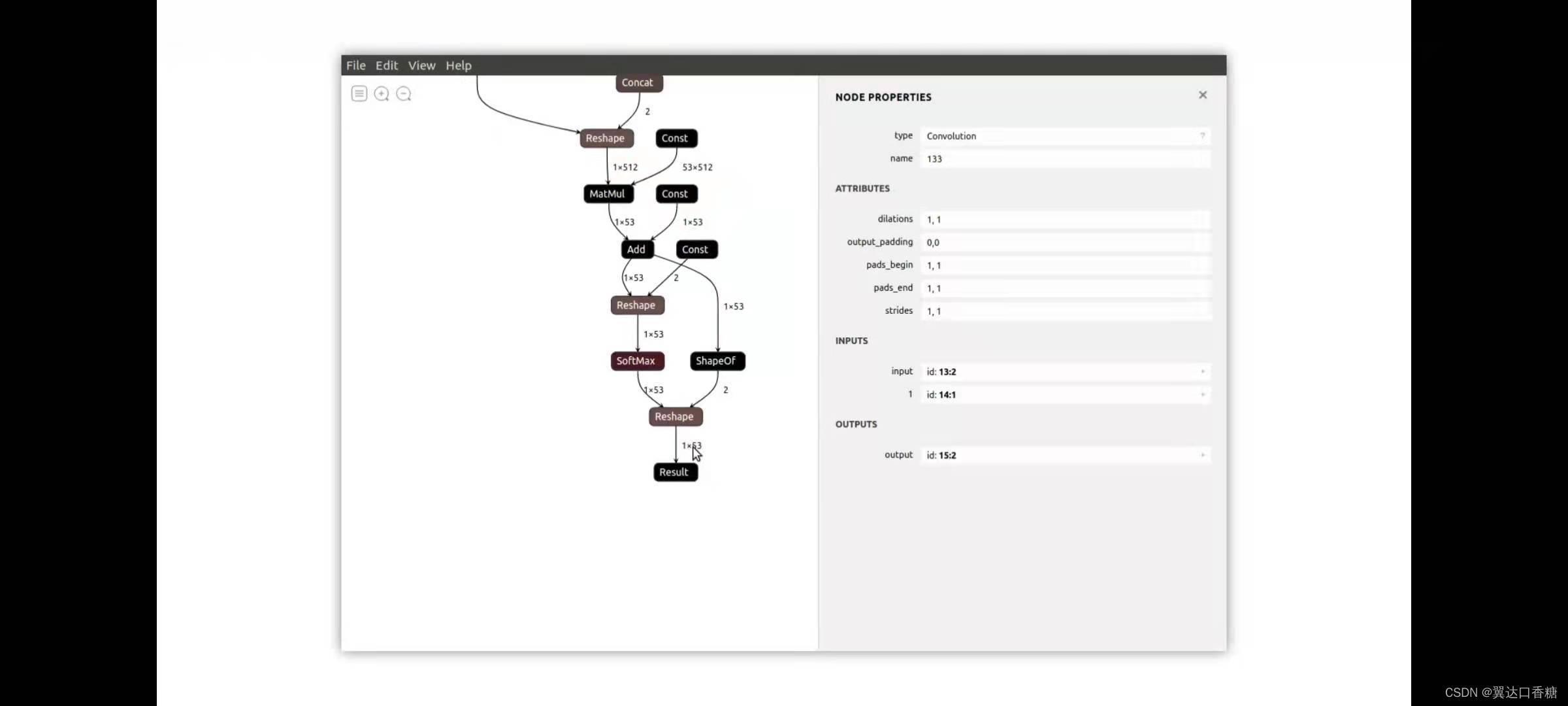
最后一程提供了所有53個類別的概率,看看這個聲音是屬于小貓小狗還是青蛙人類的,
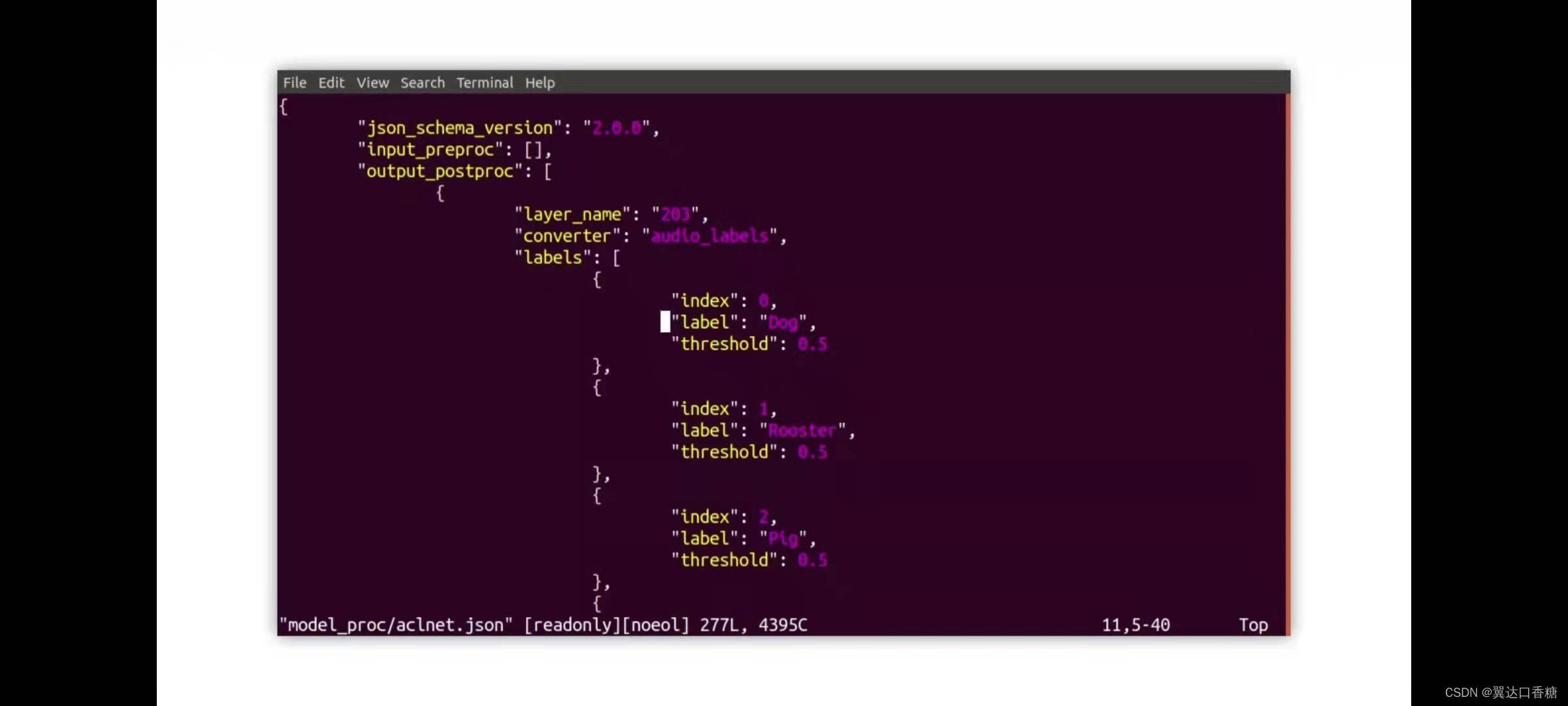
你可以查看標簽檔案,它是基于官方的資料集的,你可以用下圖的指令去打開看下類別,
每行是一個類別,類別零是狗,然后是其余的農場動物,直到類別53是speech的聲音
首先是運行這個demo實體,然后定義一個OV的路徑,可以簡化后面的資料表達,
source是初始化openvino,將其轉到處理dl stream實體,然后你可以進入到cd 這個路徑下的檔案夾,去看下我們的素材
輸入ll查看檔案夾下的檔案,可以停下分析音頻什么樣子,

你也可以使用vi 進入到檔案的內部,比如說下面的代碼你可以進入到標簽檔案去查看一下,
運行我們的示例
你會得到一系列的運行分析結果,下面三張圖都是分析聲道中所含有的聲音,你可以看到有一些小動物生物,然后可能是來自于背景聲音,
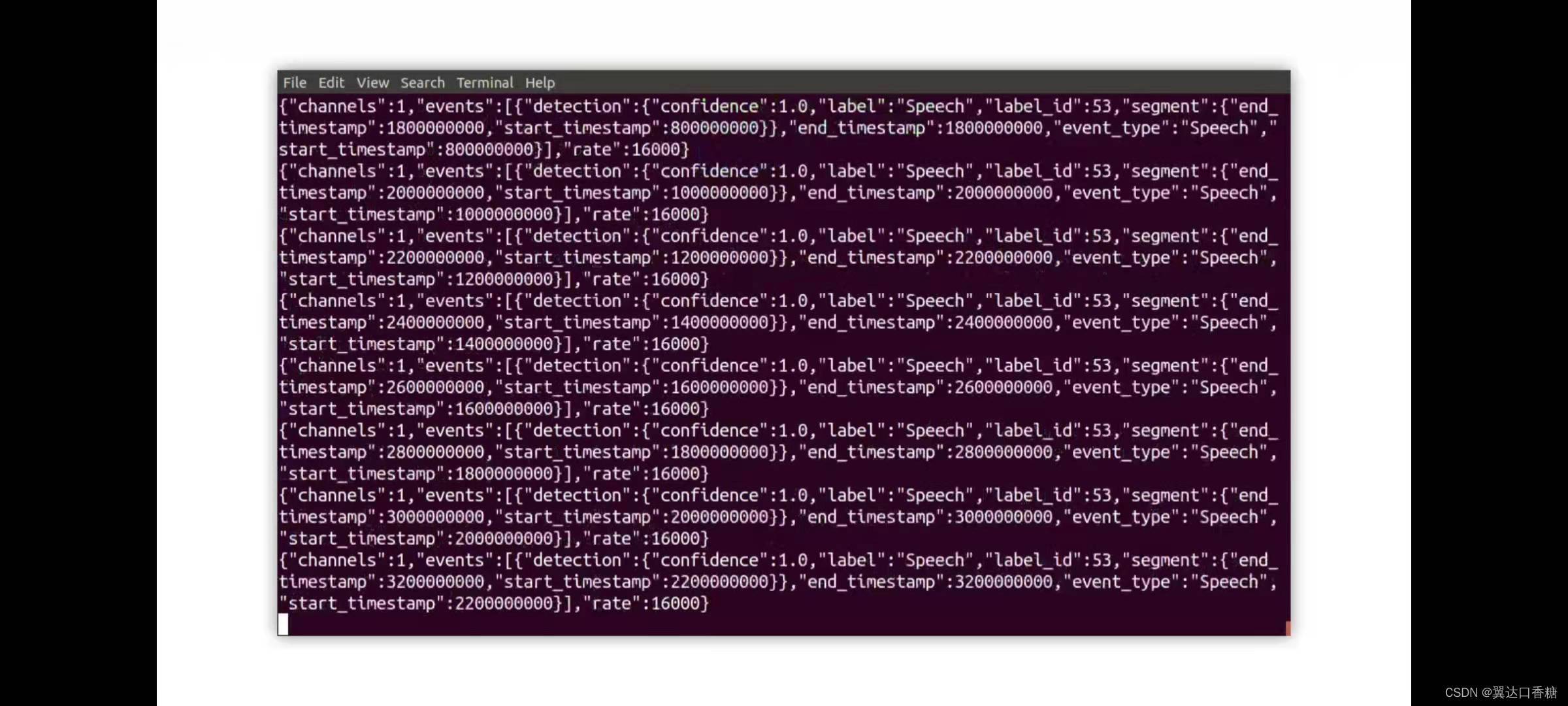
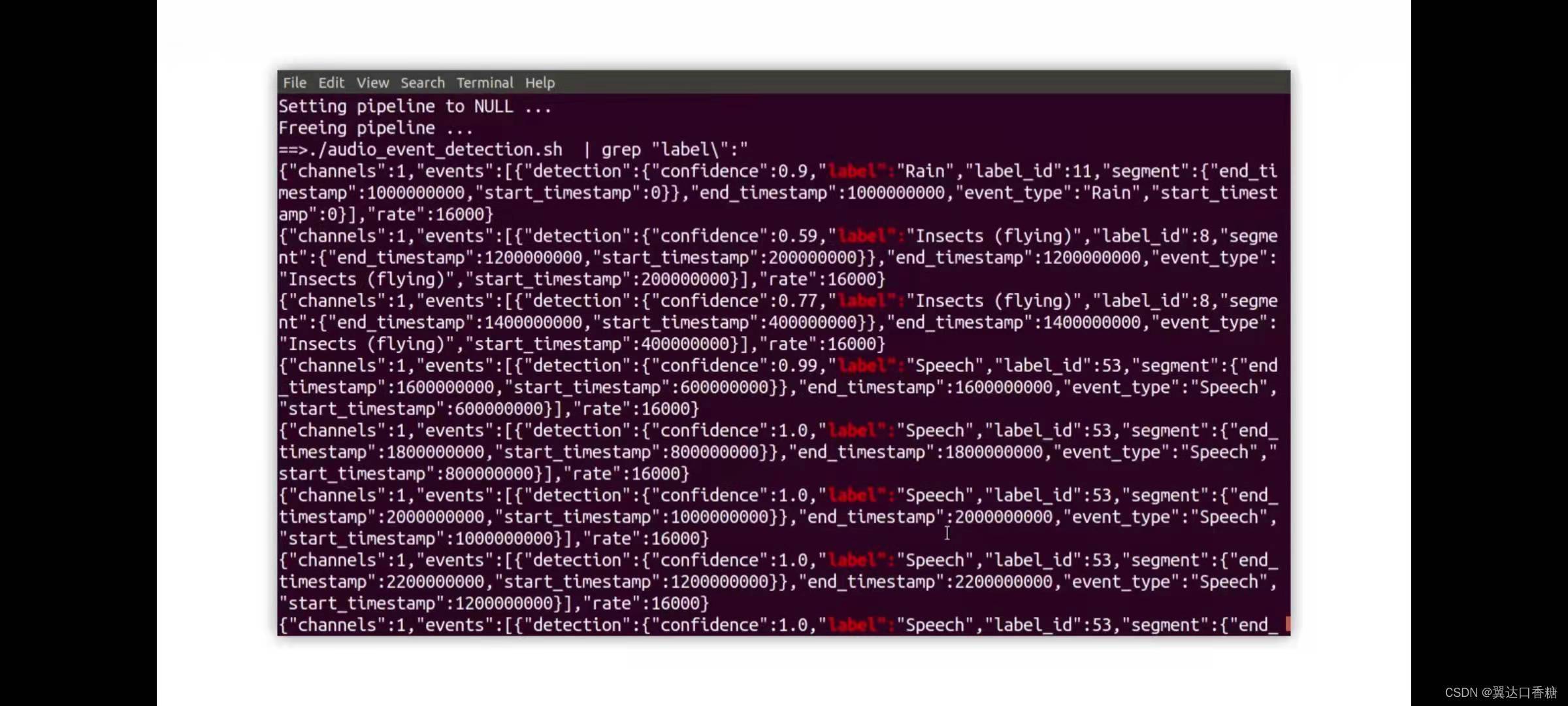
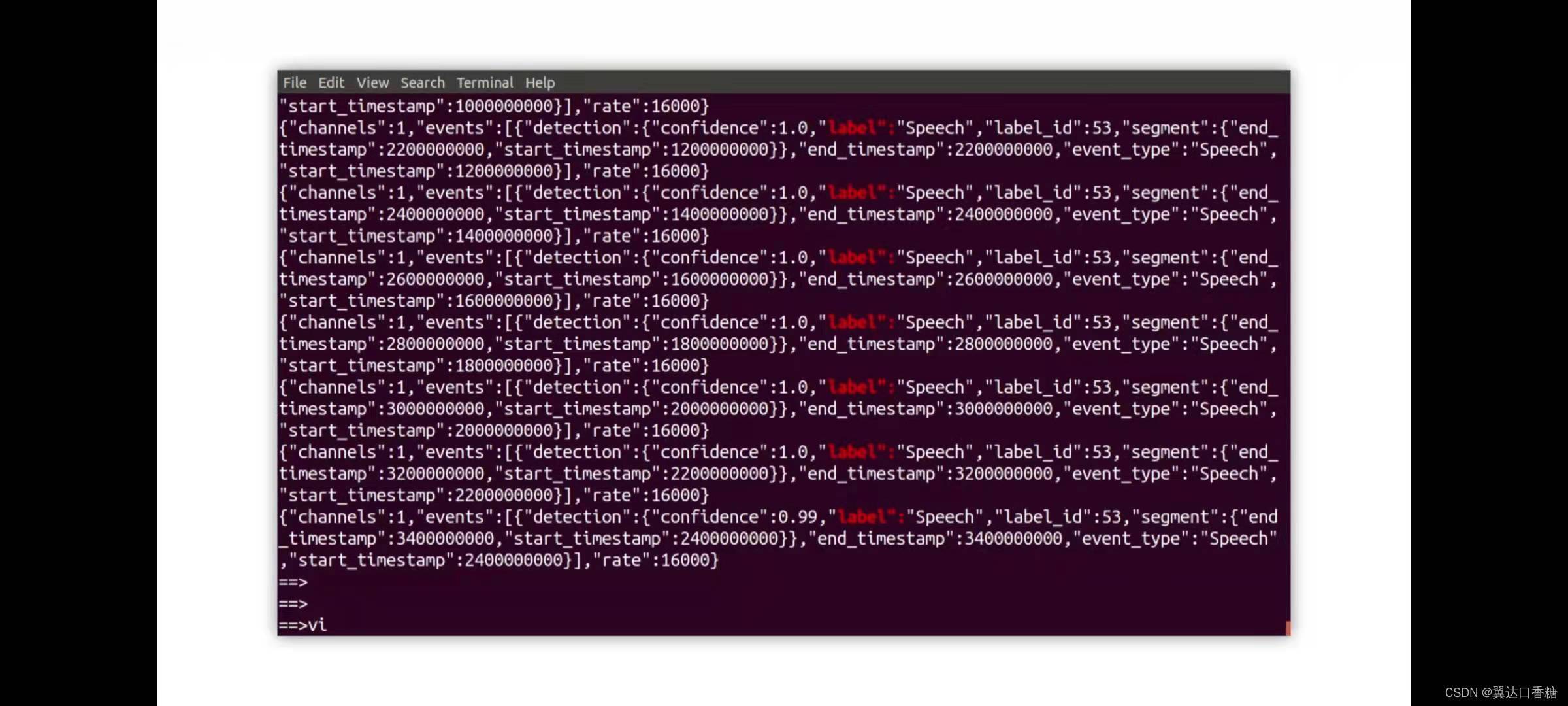
原始碼
3.音頻檢測示例
初始化環境
#初始化作業目錄
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Audio-Detection/
#初始OpenVINO
source $OV/bin/setupvars.sh
進入音頻檢測目錄
#進入OpenVINO中自帶的音頻檢測示例:
cd $OV/data_processing/dl_streamer/samples/gst_launch/audio_detect
#你可以查看檢測的標簽檔案
vi ./model_proc/aclnet.json
#你也可以播放待會待檢測的音頻檔案
show how_are_you_doing.mp3
運行音頻檢測
#運行示例
bash audio_event_detection.sh
分析音頻檢測結果
#結果并不是很適合觀察,你可以運行如下命令
bash audio_event_detection.sh | grep "label\":" |sed 's/.*label"//' | sed 's/"label_id.*start_timestamp"://' | sed 's/}].*//'
#現在你可以看到在時間戳600000000的時候,我們檢測到語音了,但并不知道內容是什么,因為它知識一個檢測示例,并不是一個識別示例:“Speech”,600000000
4.手寫公式/列印公式識別
第四個模型是運用模型去檢測手寫公式或latex撰寫的公式

這個識別任務分為兩個獨立模型的模型來完成,第一個模型稱為編碼器,是一個卷積神經網路,用于影像中提取特征,一般來說,基本上是識別字母或符號的邊界框,
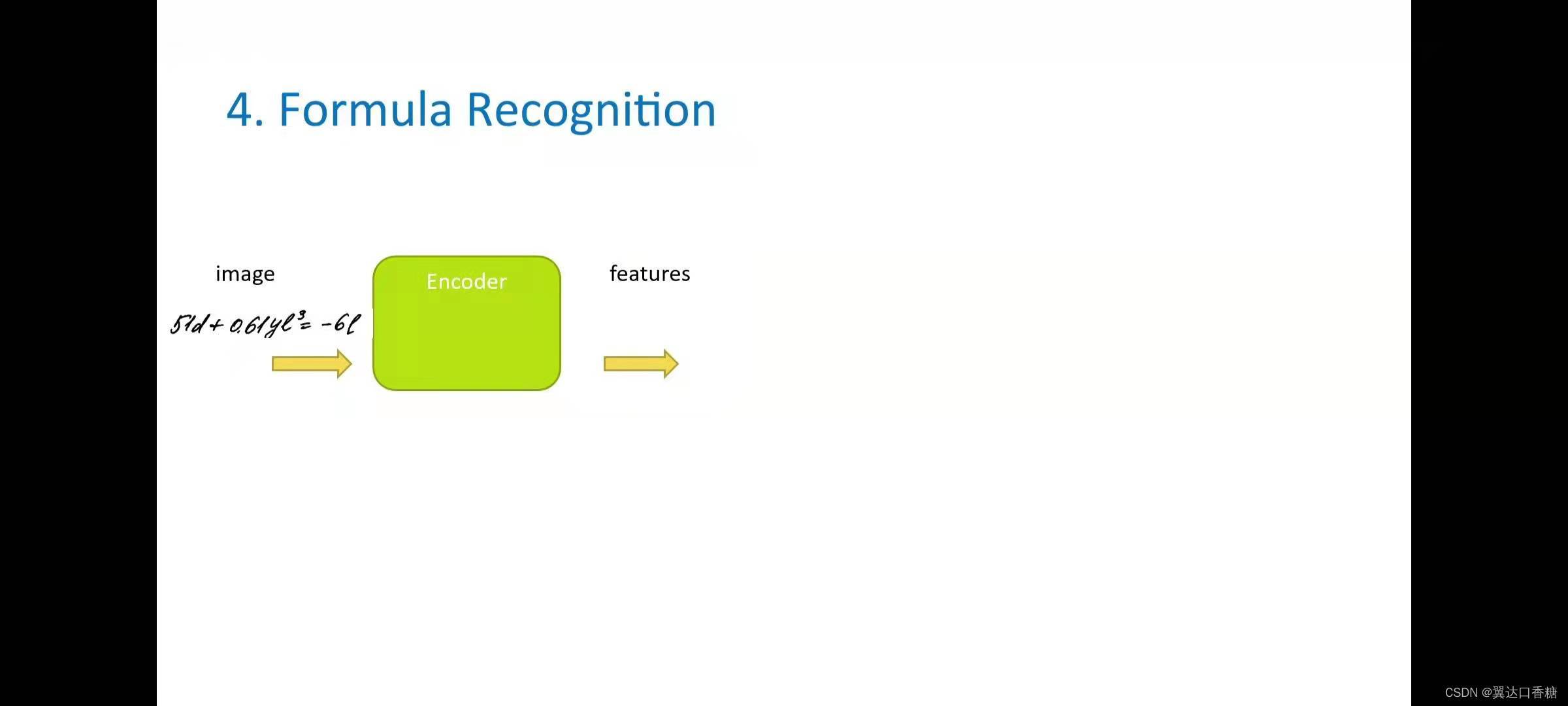
第二個模型是LSTM模型,因為背景關系特征很重要,所以我們需要一個可以記住這些符號的模型,并了解完整的序列和符號歷史,所以在達到可以在命令列中定義的最大公式長目之前,他將前一個編碼器模型提供的模型輸入去查找下一個符號,
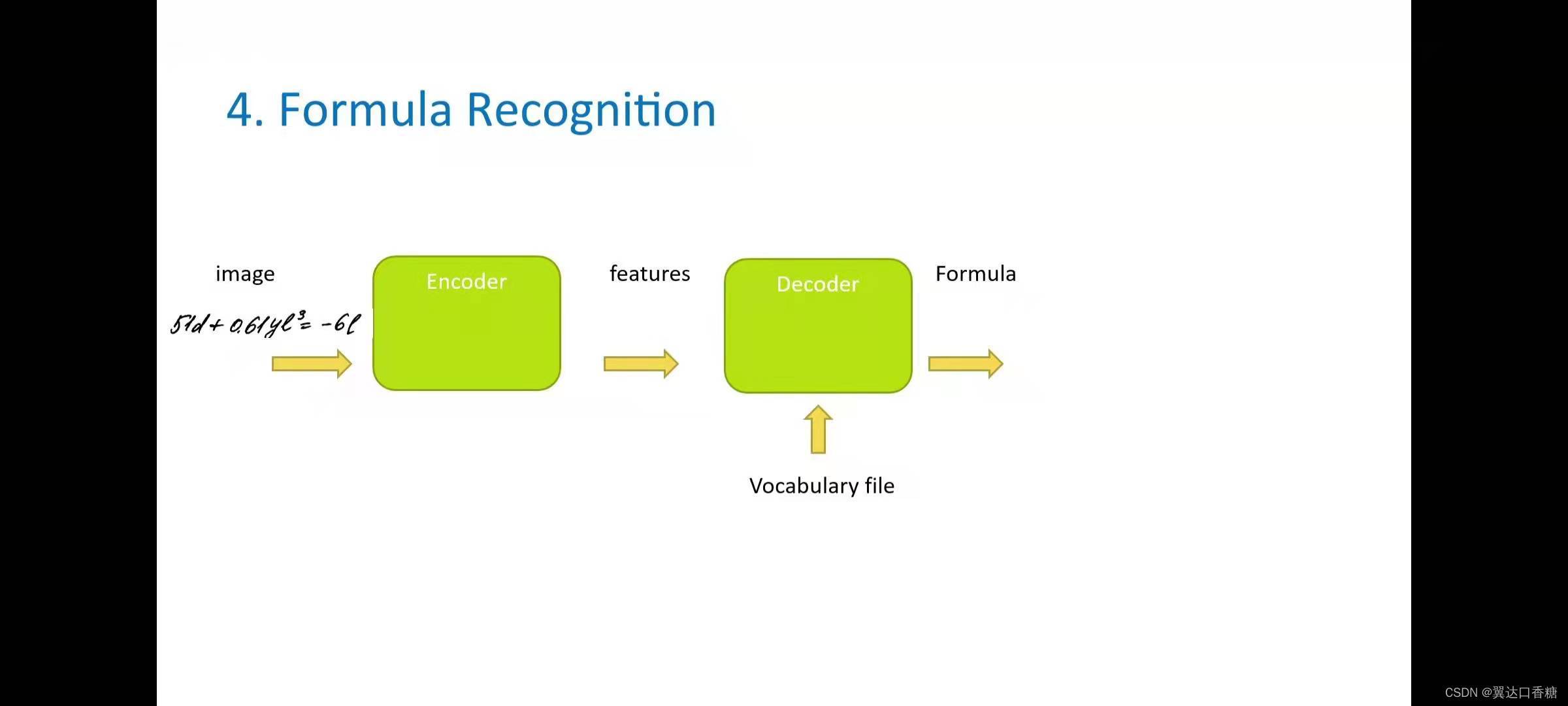
官方提供了多個不同的任務linux模型:latex模型可以檢測大小寫字母、英文、數字和一些數學函式,手寫模型可以預測手寫模型的數學字符
首先還是定義作業目錄OV和WD,方便后面的路徑使用,初始化openvino,
初始化成功
接下里你可以切換路徑到SWD
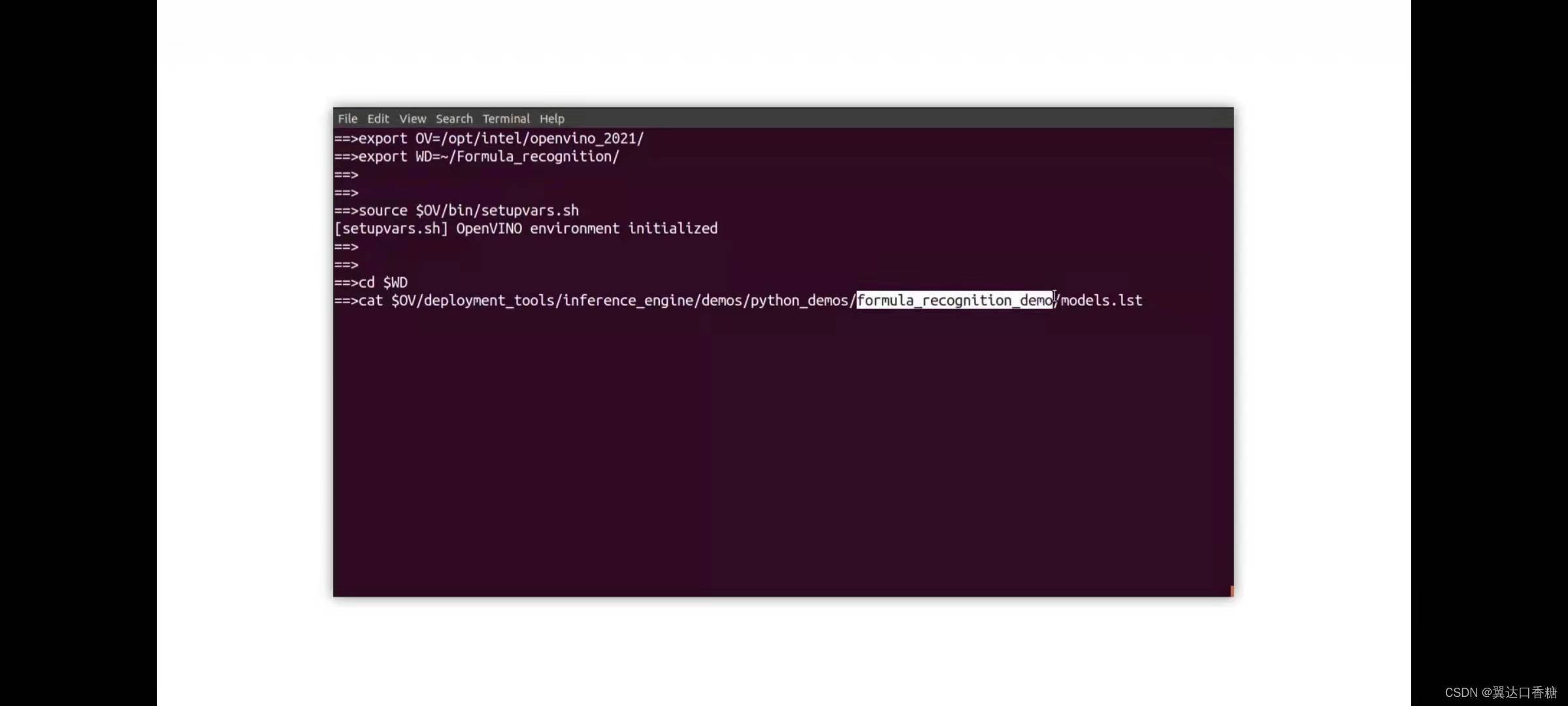
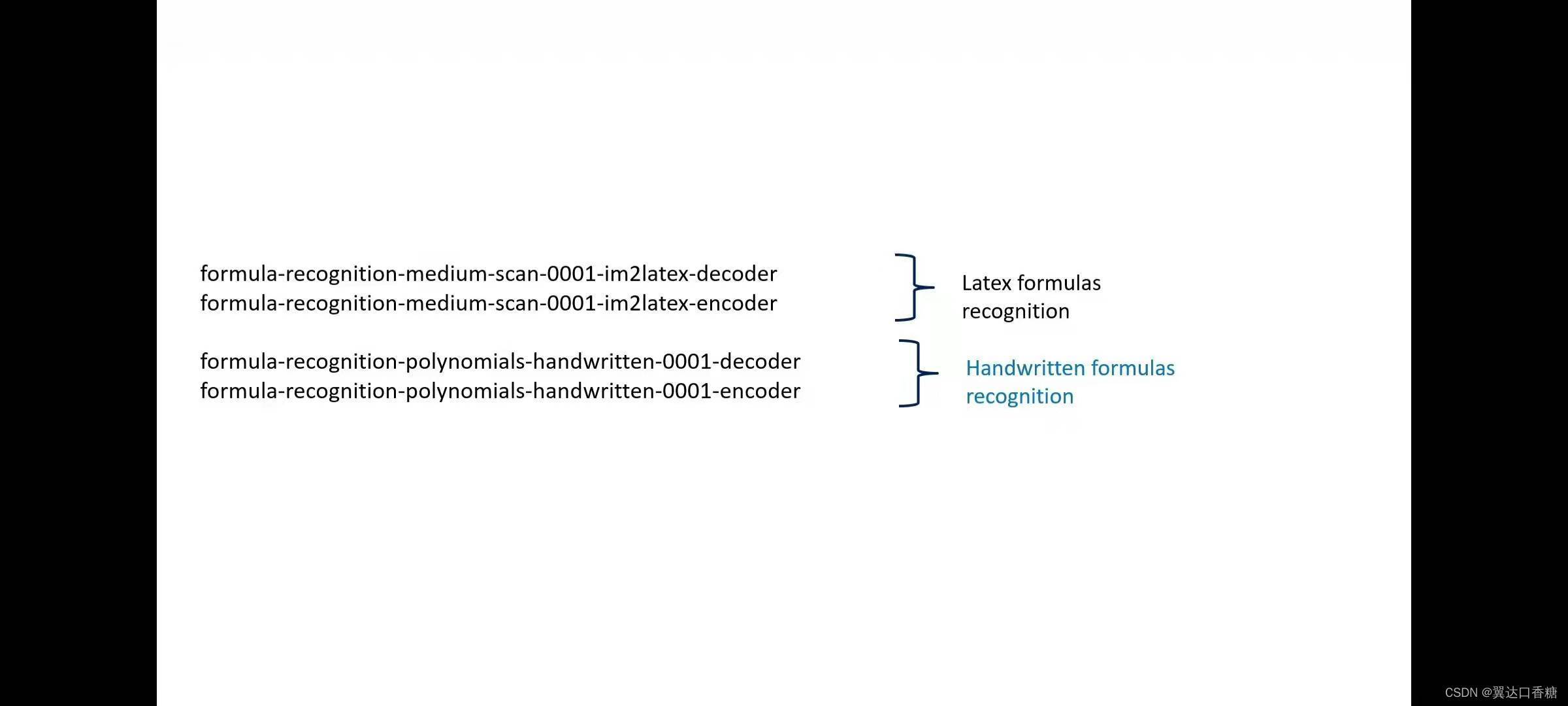
在這里你可以看到latex和手寫識別模型檔案
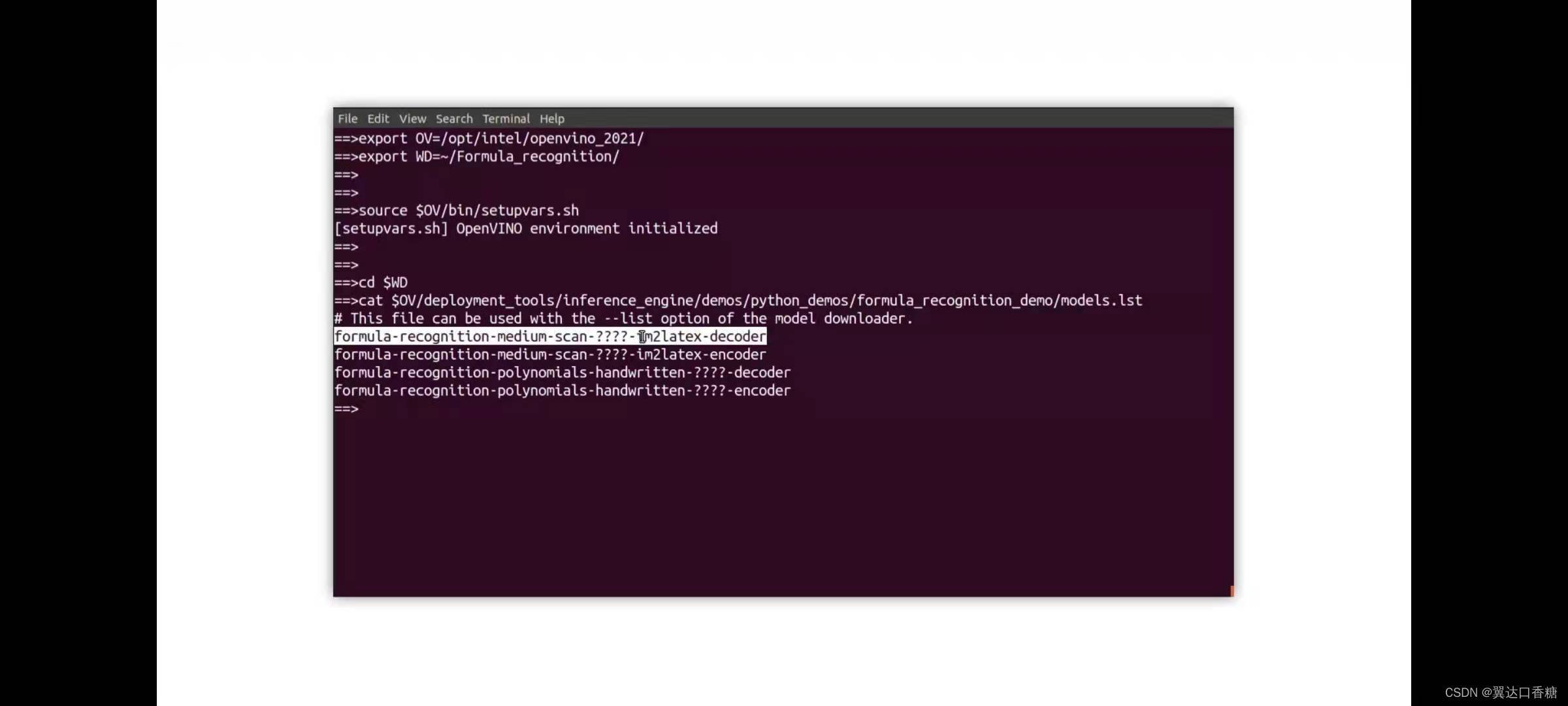
然后使用模型下載器下載這些檔案,特別地,這里將模型下載為F16的模型,這里說下這個模型格式,不同的模型格式在不同的硬體上支持是不一樣的,但是CPU支持所有格式的模型,但是GPU和VPU不一定都支持,
下載成功后的頁面,接下來就是我們的兩個詞匯檔案,把他們添加到作業目錄,
畫白的地方就是其中一個的對應地址
到這里所有的準備作業就完成了,
當你再打開作業目錄時就可以發現有兩個latex影像和自由格式的書寫公式,模型等
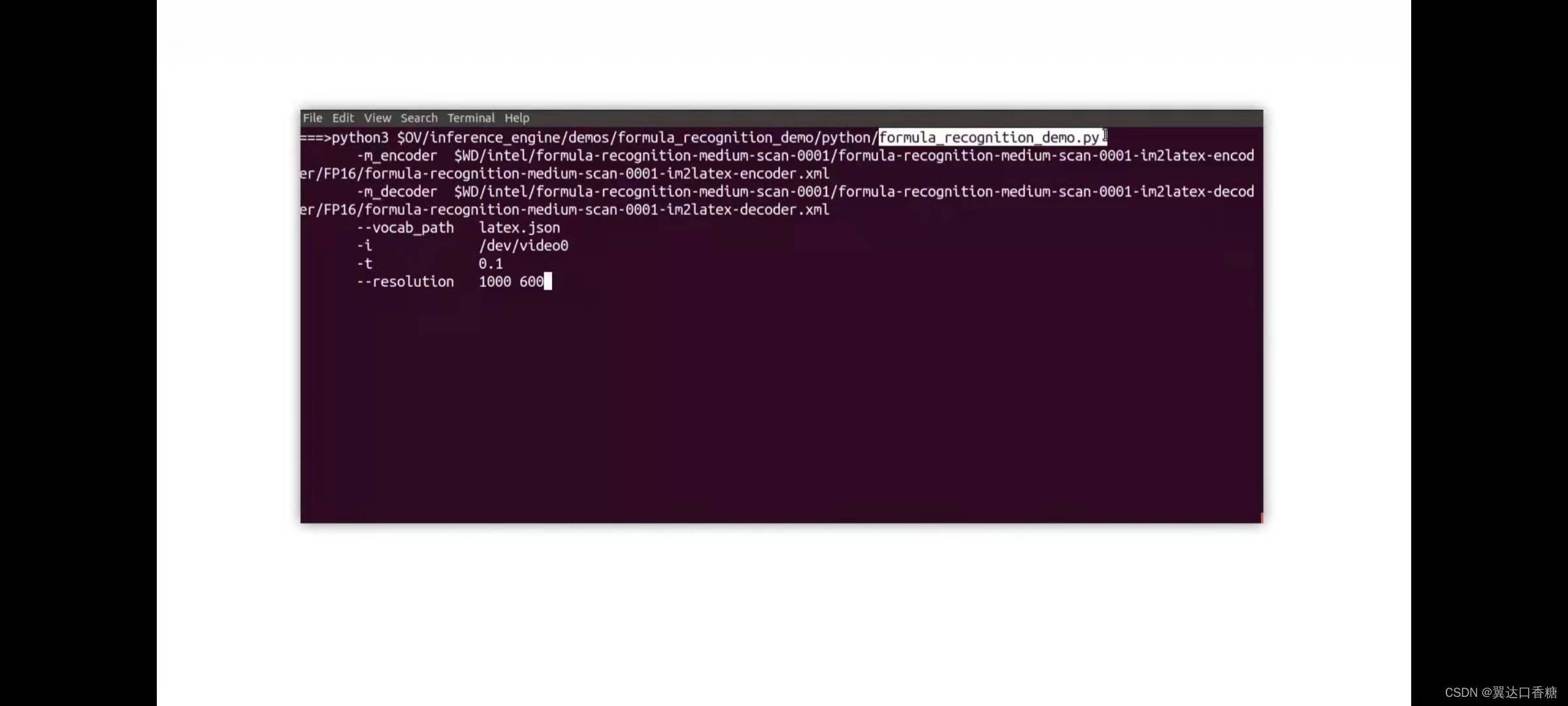
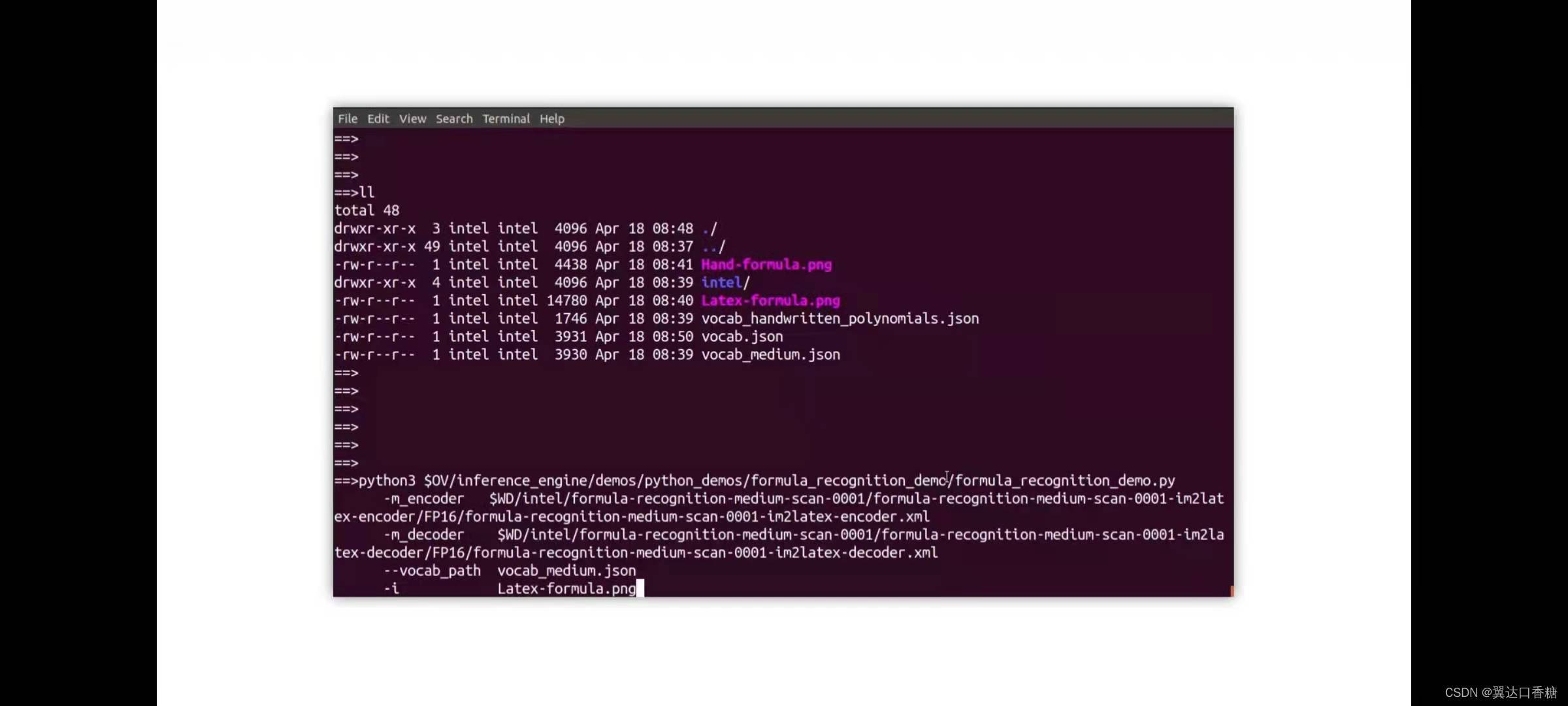
我們開始運行我們的編碼器和解碼器模型
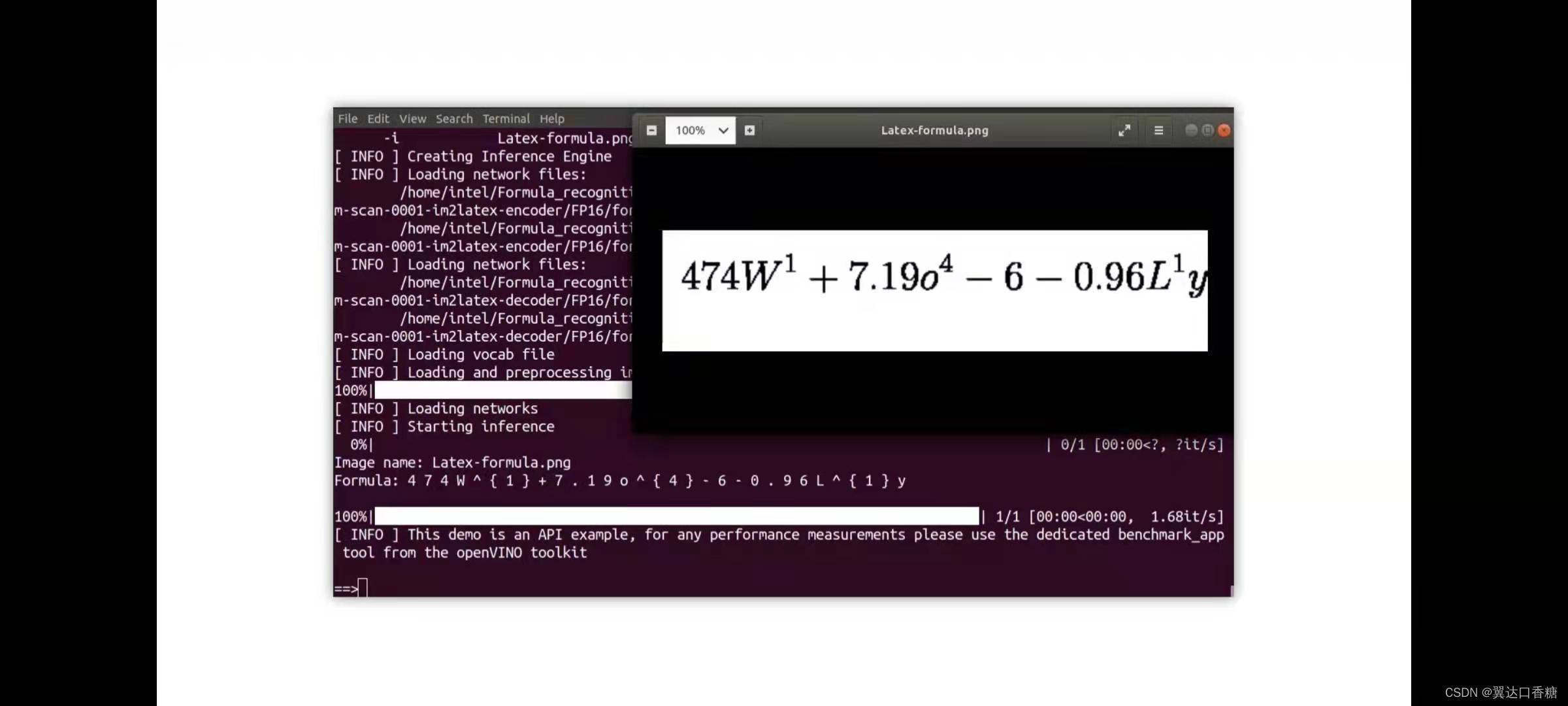
latex效果
我們接下來運行手寫模型
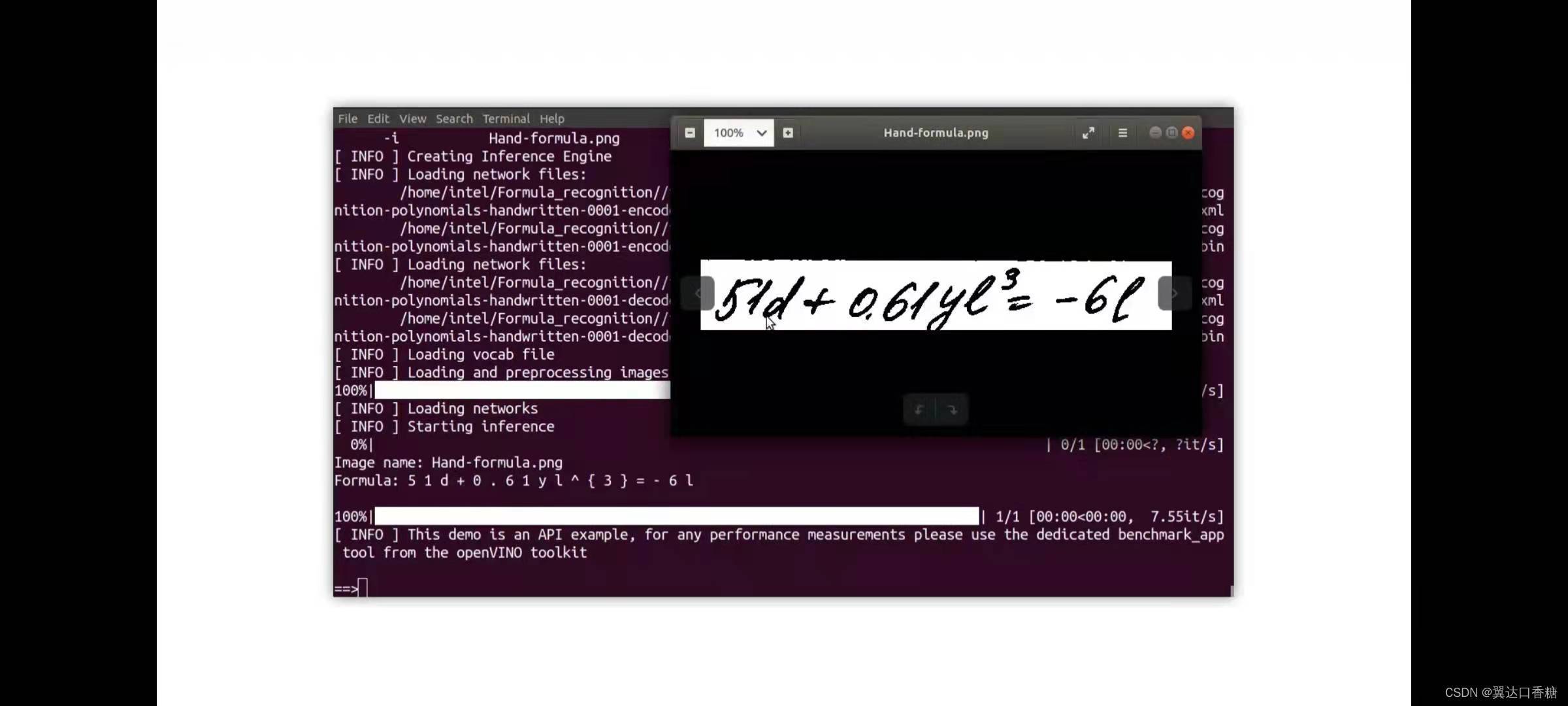
手寫模型
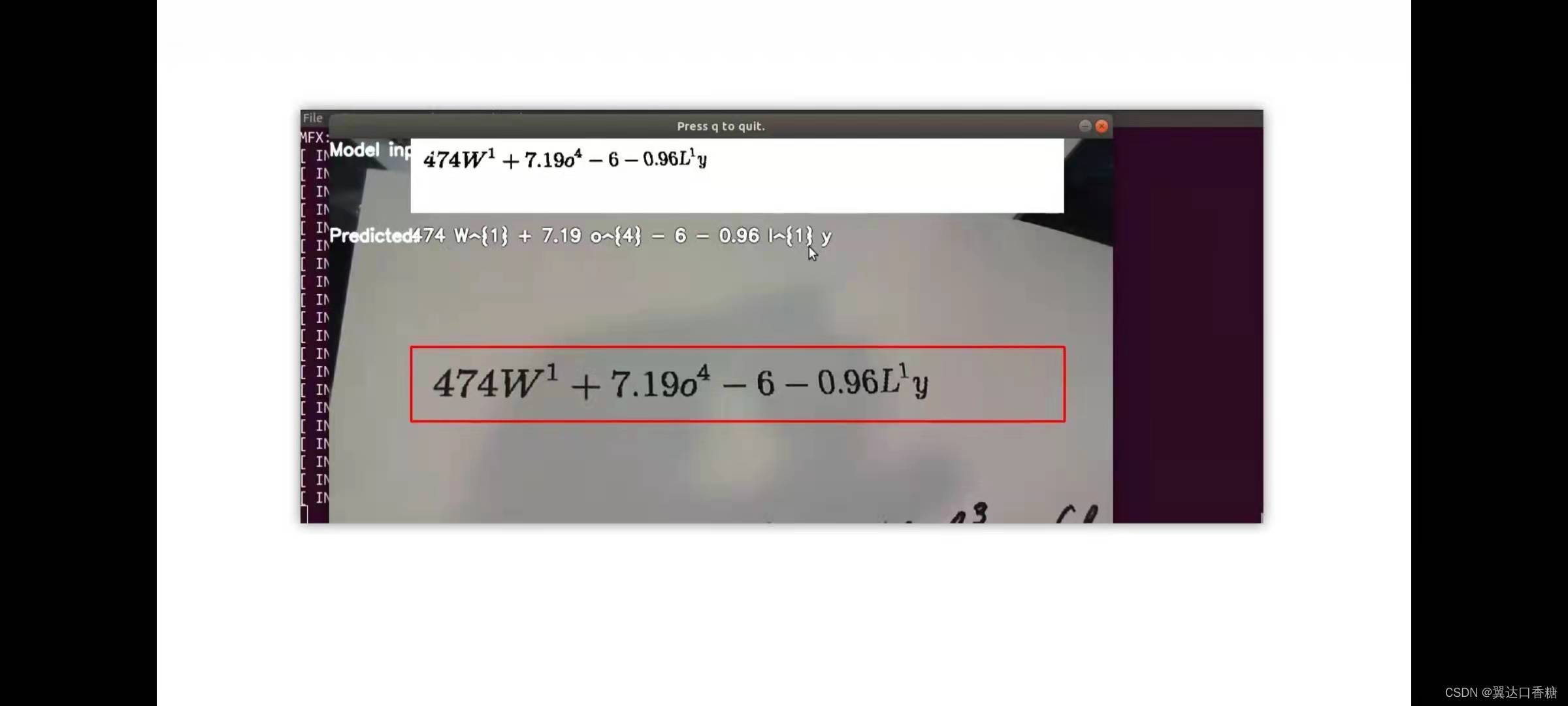
你也可以試試用攝像頭的來接入識別的影像

原始碼
4.公式識別
初始化環境
#初始化環境
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Formula_recognition/
#初始化OpenVINO
source $OV/bin/setupvars.sh
查看可識別的字符
cd $WD
#手寫字符:
vi hand.json
#列印字符:
vi latex.json
查看待識別的公式
#進入材料目錄
cd $WD/…/Materials/
#查看列印公式
show Latex-formula.png
#查看手寫公式
show Hand-formula.png
運行公式識別
cd $WD
識別列印公式
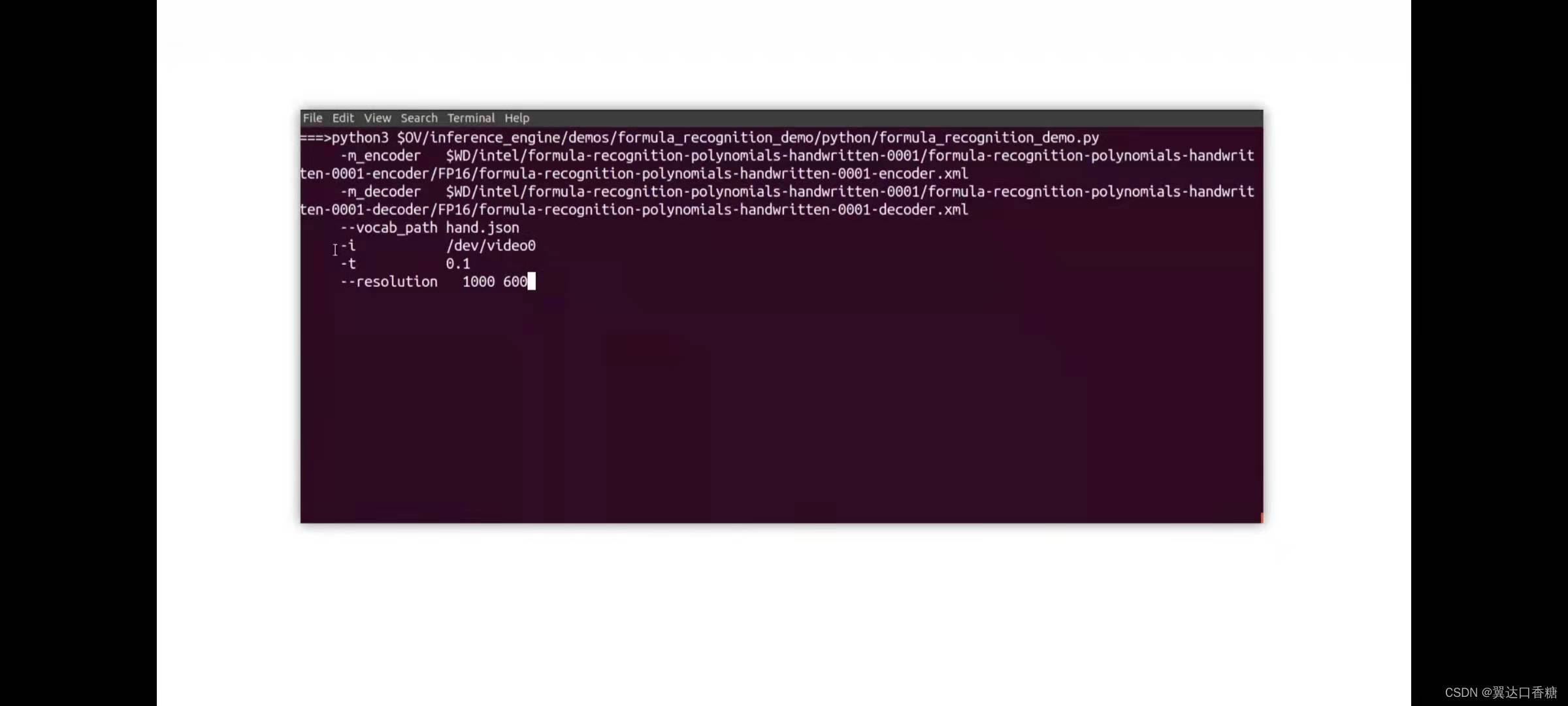
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-encoder/FP16/formula-recognition-medium-scan-0001-im2latex-encoder.xml -m_decoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/FP16/formula-recognition-medium-scan-0001-im2latex-decoder.xml --vocab_path latex.json -i $WD/…/Materials/Latex-formula.png -no_show
識別手寫公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-encoder/FP16/formula-recognition-polynomials-handwritten-0001-encoder.xml -m_decoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-decoder/FP16/formula-recognition-polynomials-handwritten-0001-decoder.xml --vocab_path hand.json -i $WD/…/Materials/Hand-formula.png -no_show
#對比原始圖片,檢查識別是否正確,
5.環境深度識別
在這個實體中你可以從一個簡單的影像中創建一個具有三維深度的3D影像,想要更深入的資訊,可以掃描二維碼,找到完整檔案,

對于人類來說,我們從三維視角觀察世界,我們都認為我們可以看到的深度是我們大腦判斷的結果,我們的大腦正接收兩只眼睛捕捉的略有不同的影像病,推斷深度,但是即使你閉上一只眼睛看那個影像,你也可以清楚的識別深度,因為我們已經學會了根據陰影大小來確定深度,

這個演示專案是基于intel實驗室的研究,這個專案能夠混合不同的3D資料集,可以參考下圖的左側,單對于openvino而言,深度學習模型和加載的運行方式是完全相同的,你可以在這個檔案中找到模型詳細資訊,該模型稱為midasnet

你可以官網查看這個模型的詳細資訊,輸入輸出、模型結構、精確度等等,
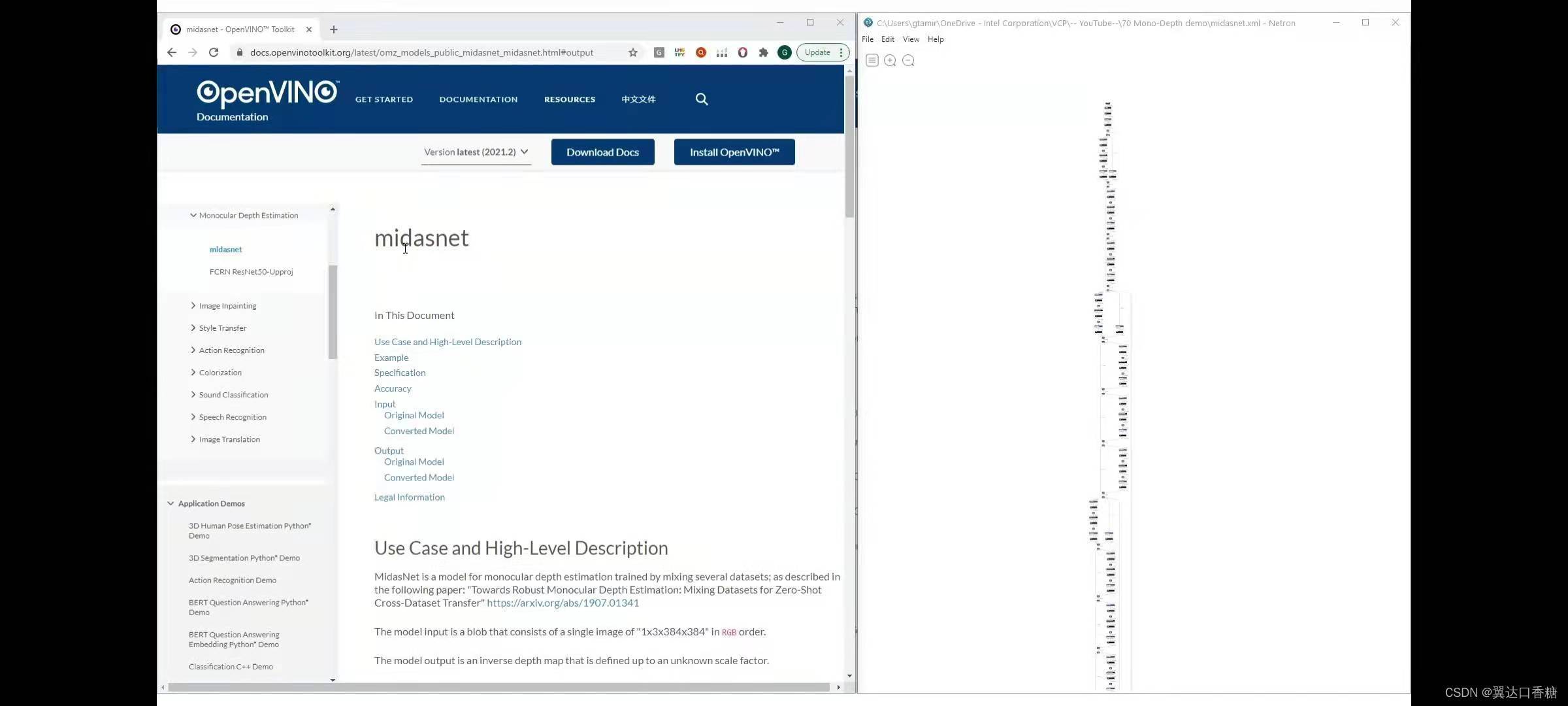
你可以在這里找到規格和準確度模型的輸入,是rgb影像
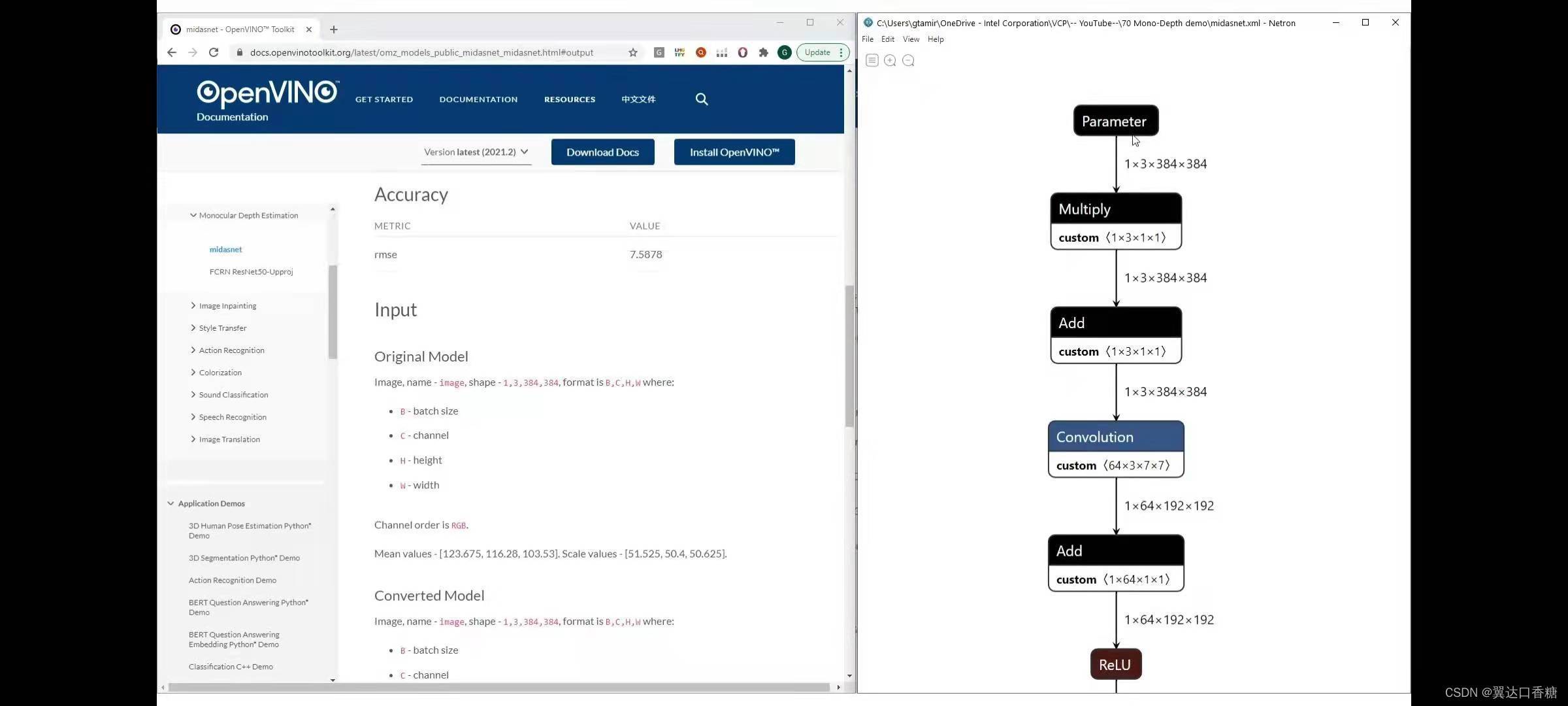
最終輸出的是逆向深度影像,所以你在這里得到一個陣列,與輸入影像的大小相同,影像中每個像素具有逆向深度值
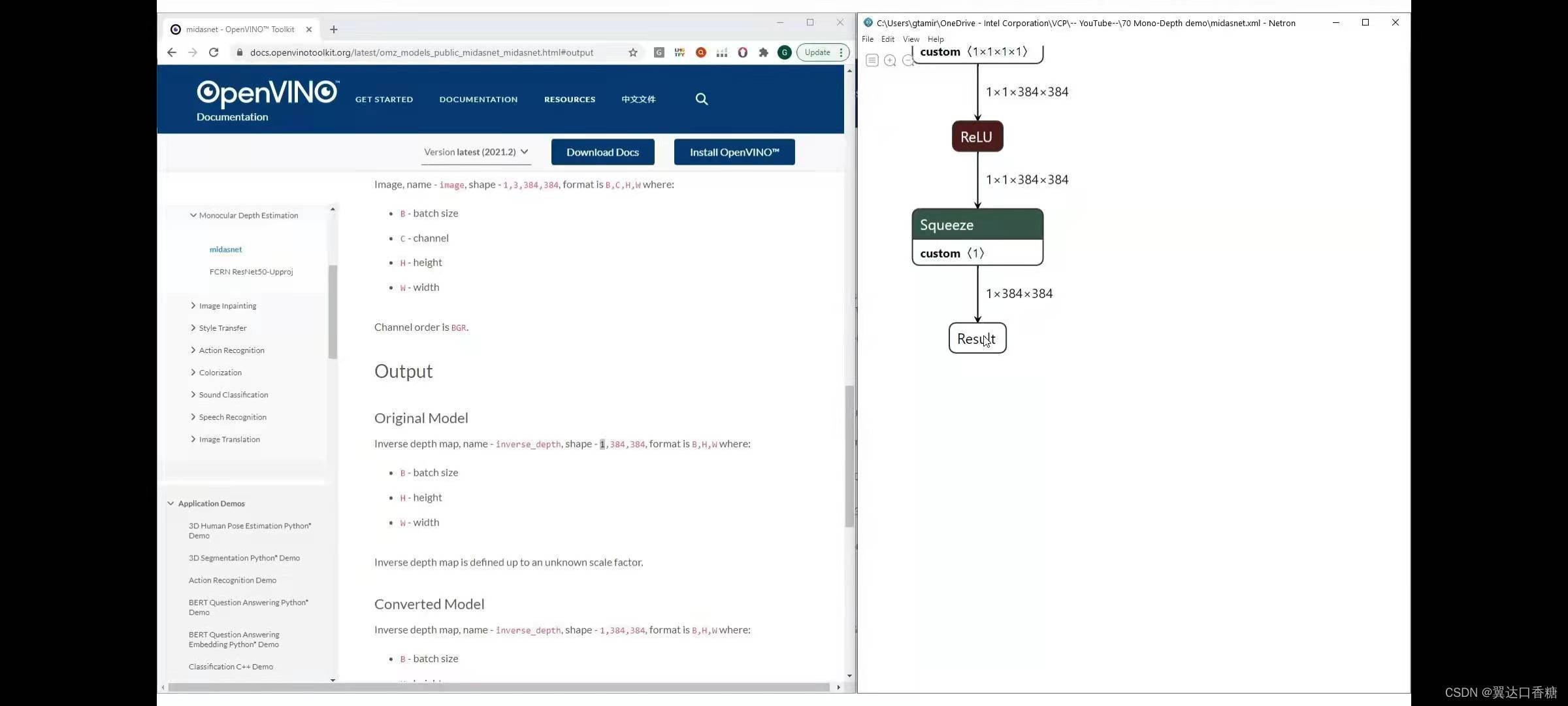
在monodepth_demo下,你可以找到python的腳本和模型串列
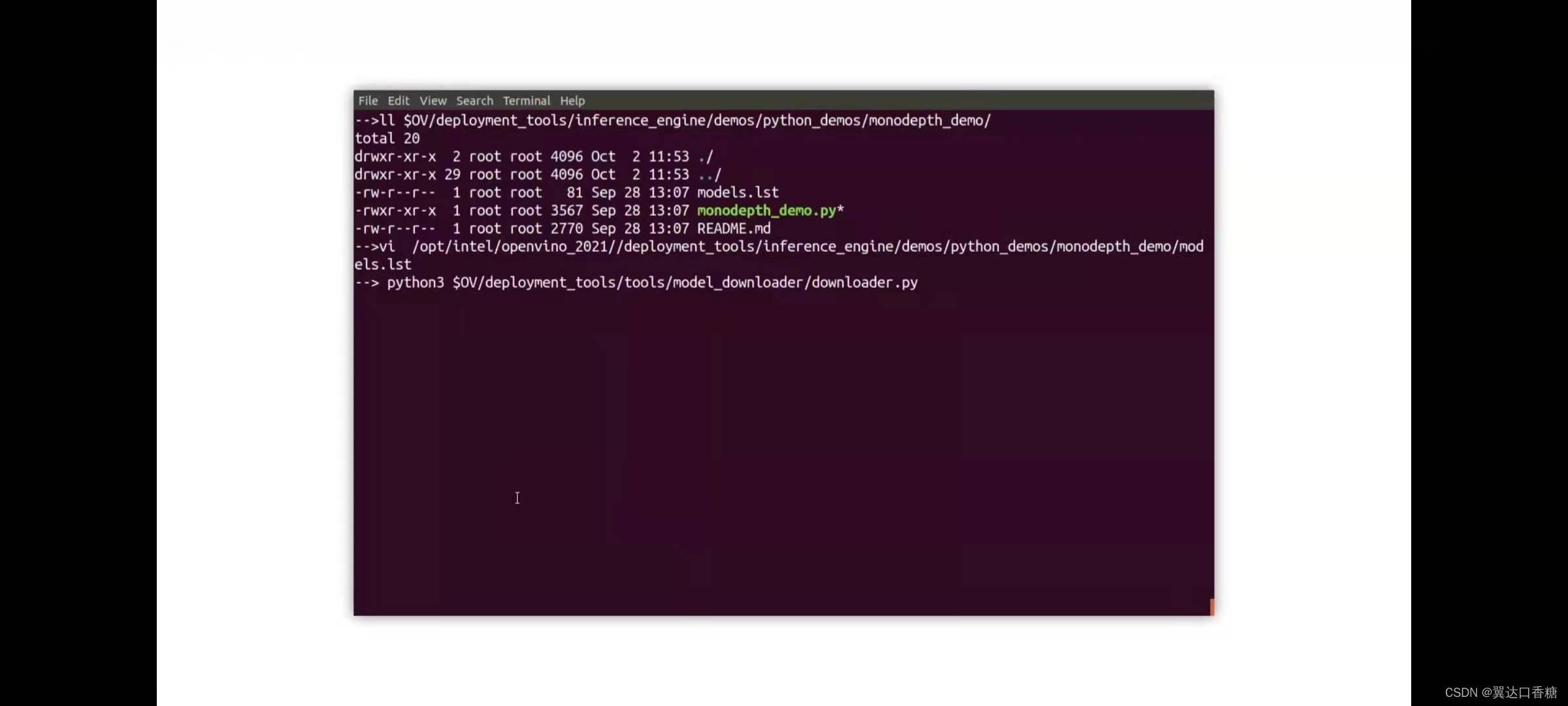
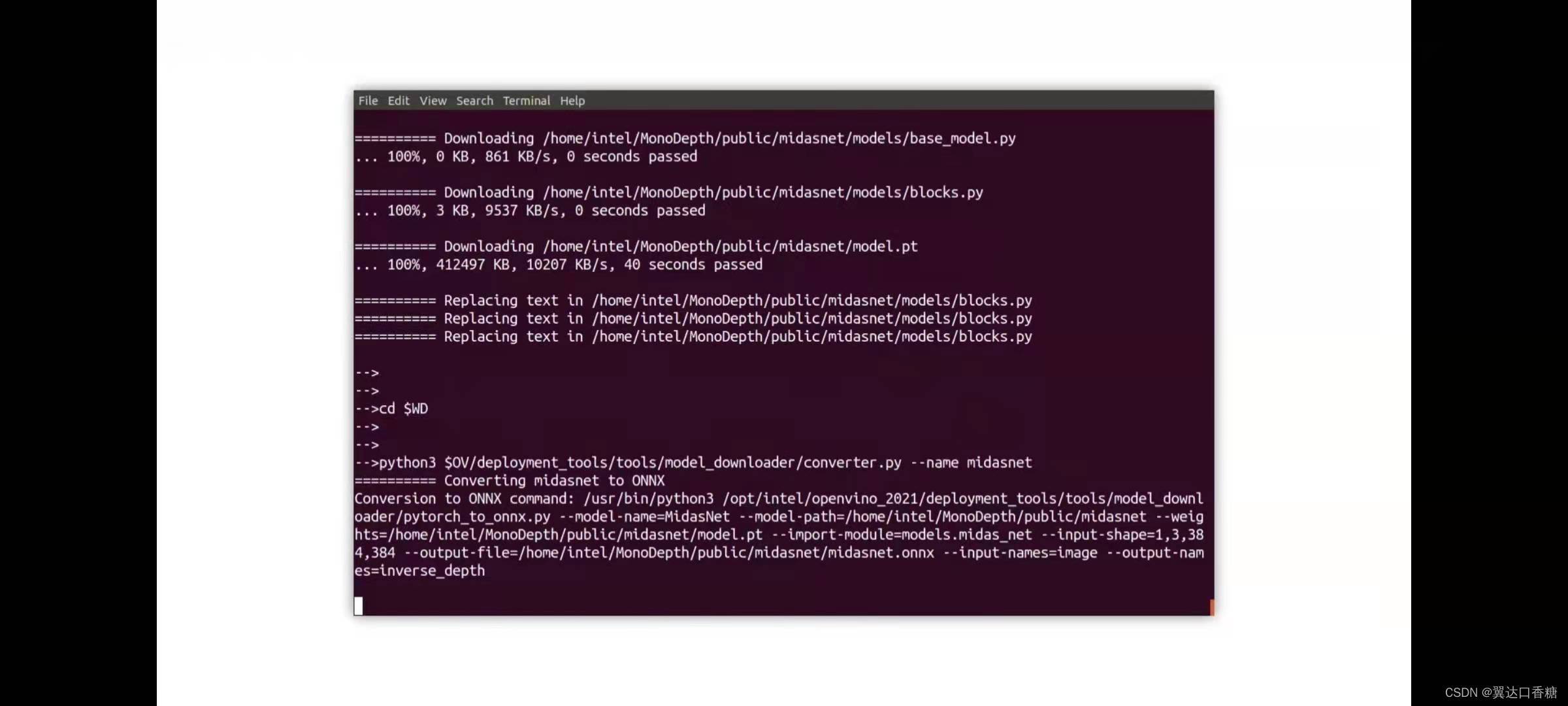
讓我們使使用模型下載器下載這個模型,成功后如下圖
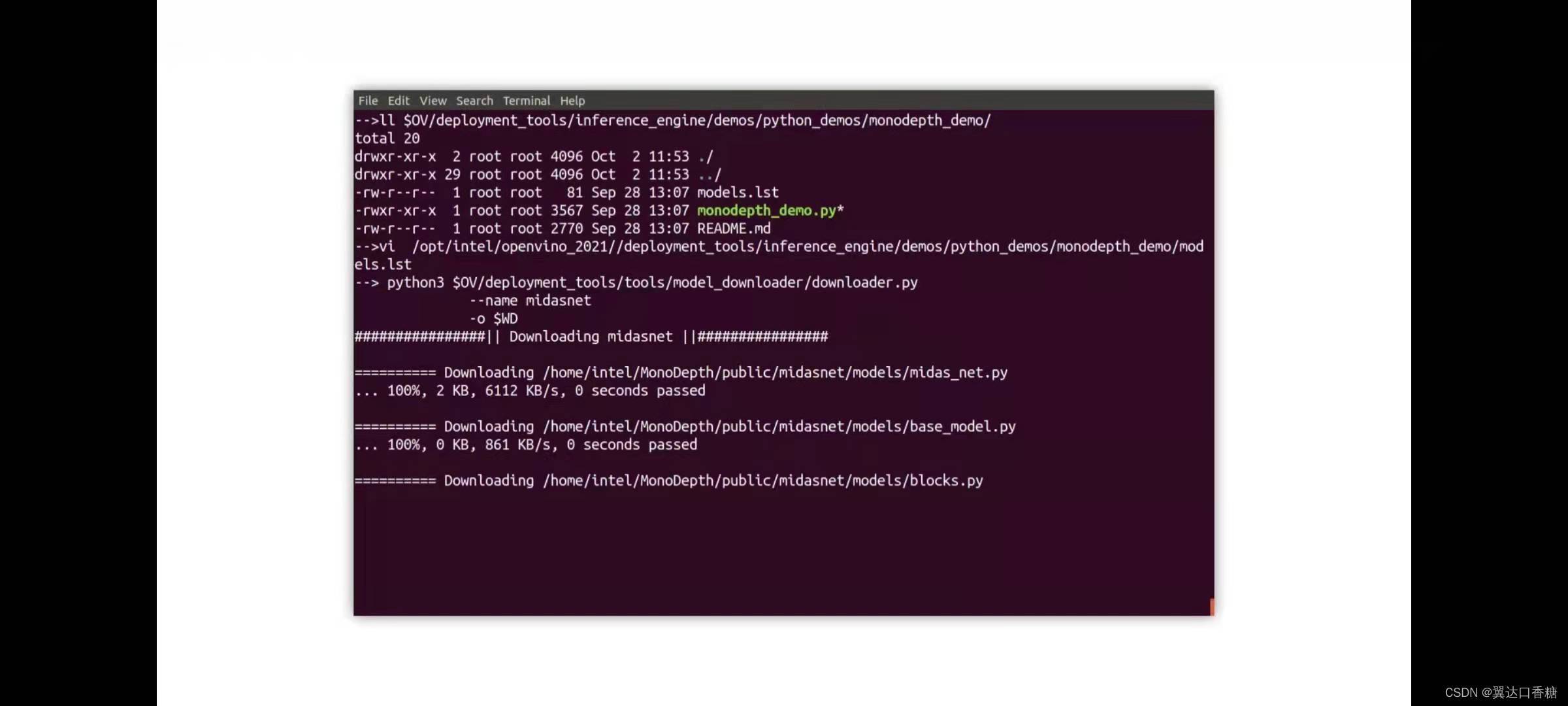
然后我們輸入如下命令進行模型轉化,pytorch轉成IR模型
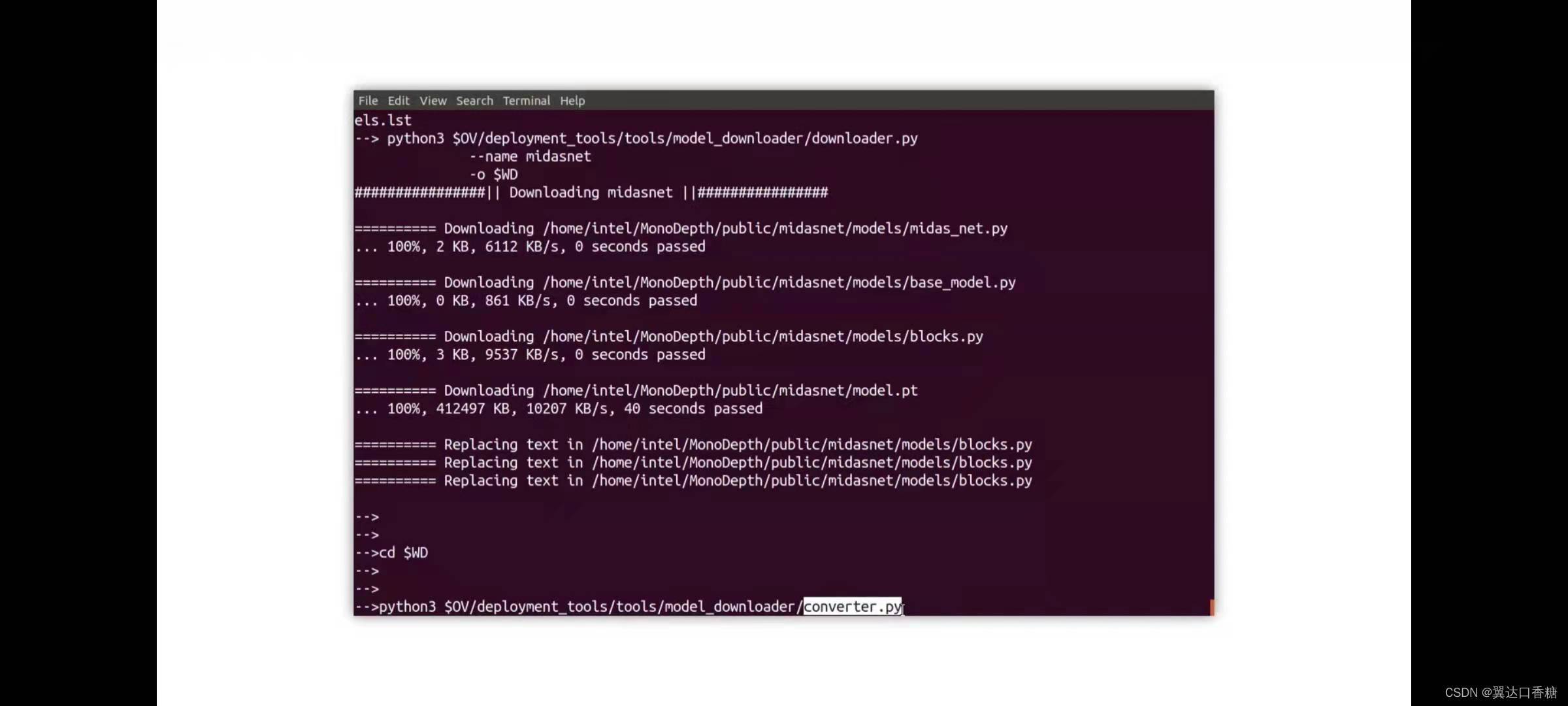
運行演示,這里影像自備一張
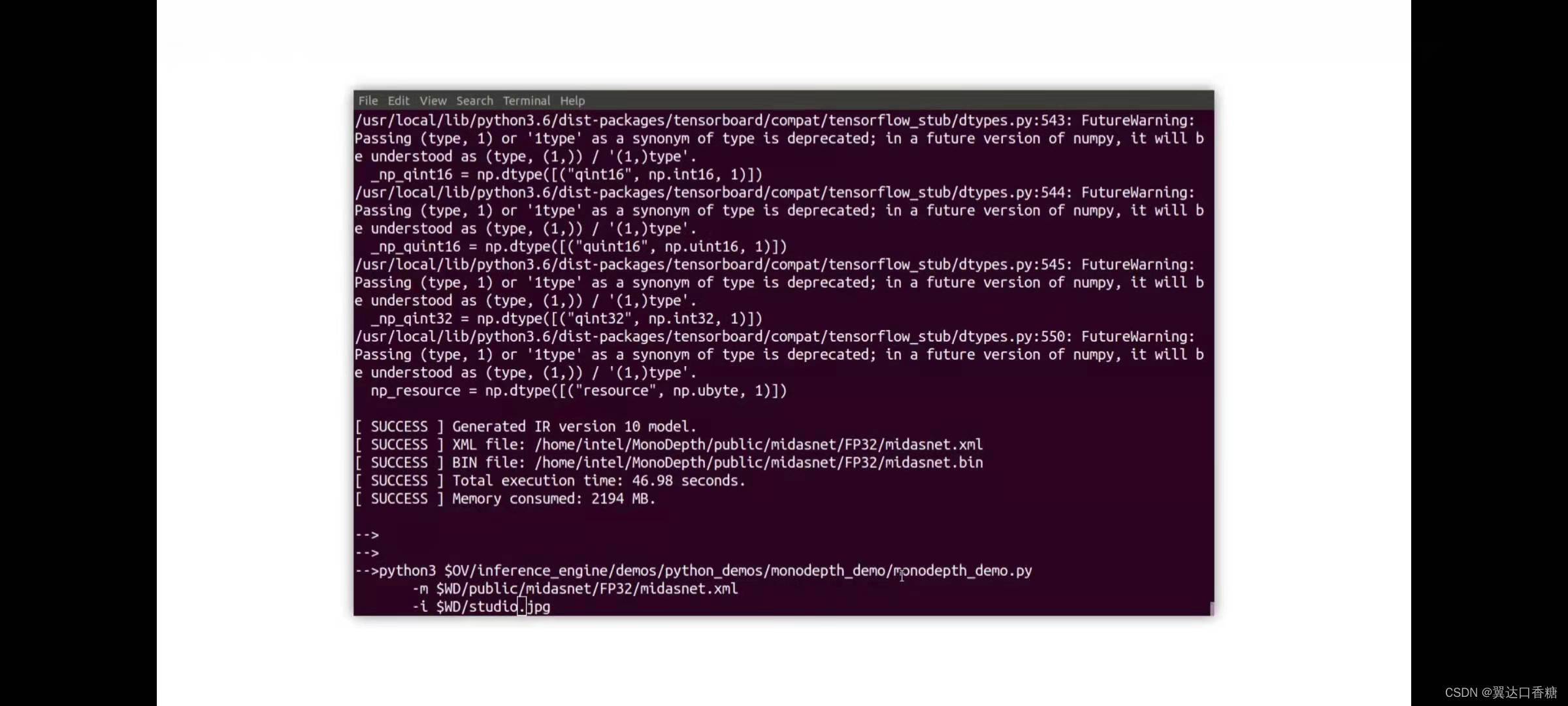
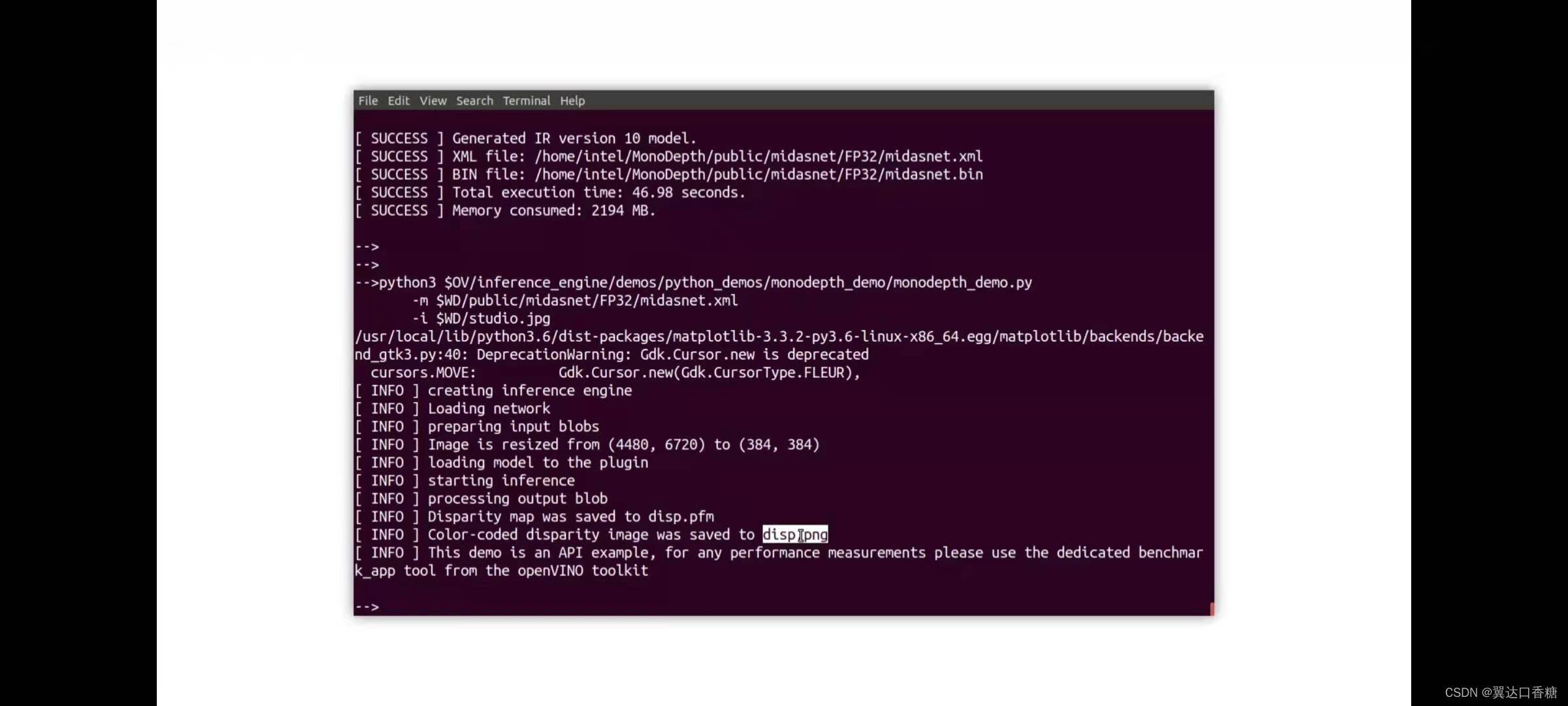
運行成功如下圖,然后下方是運行的結果與保存的路徑
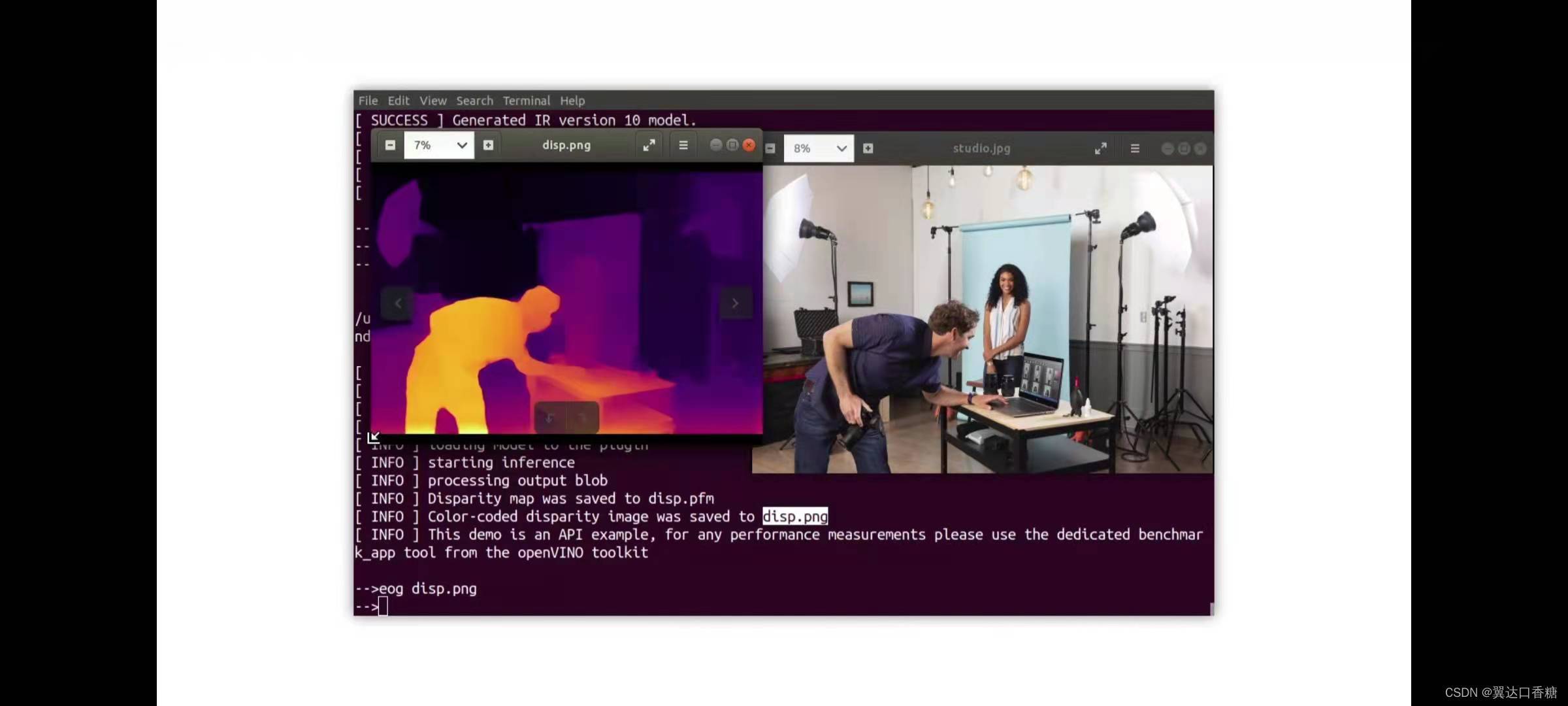
根據設定的路徑找到兩張圖形
我們可以看下運行后的3D影像
5.環境深度識別
初始化環境
#環境目錄
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/MonoDepth_Python/
#初始化OpenVINO
source $OV/bin/setupvars.sh
轉換原始模型檔案為IR檔案
進入作業目錄
cd $WD
#下載好的模型為TensorFlow格式,使用converter準換為IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --list $OV/deployment_tools/inference_engine/demos/monodepth_demo/python/models.lst
查看需要被識別的原始圖片
#查看原始檔案
show tree.jpeg
運行深度識別示例
#進入作業目錄
cd $WD
#運行示例,該示例的作用是自動分離圖片中景深不同的地方:
python3 $OV/inference_engine/demos/monodepth_demo/python/monodepth_demo.py -m $WD/public/midasnet/FP32/midasnet.xml -i tree.jpeg
查看顯示結果
show disp.png
6.目標識別道路車流監控示例
在這個演示中將使用多個不同的神經網路架構運行物件檢測推理,可以選擇YOLO,SSD或其他并下載該框架匹配的模型,更多資訊可以關注二維碼

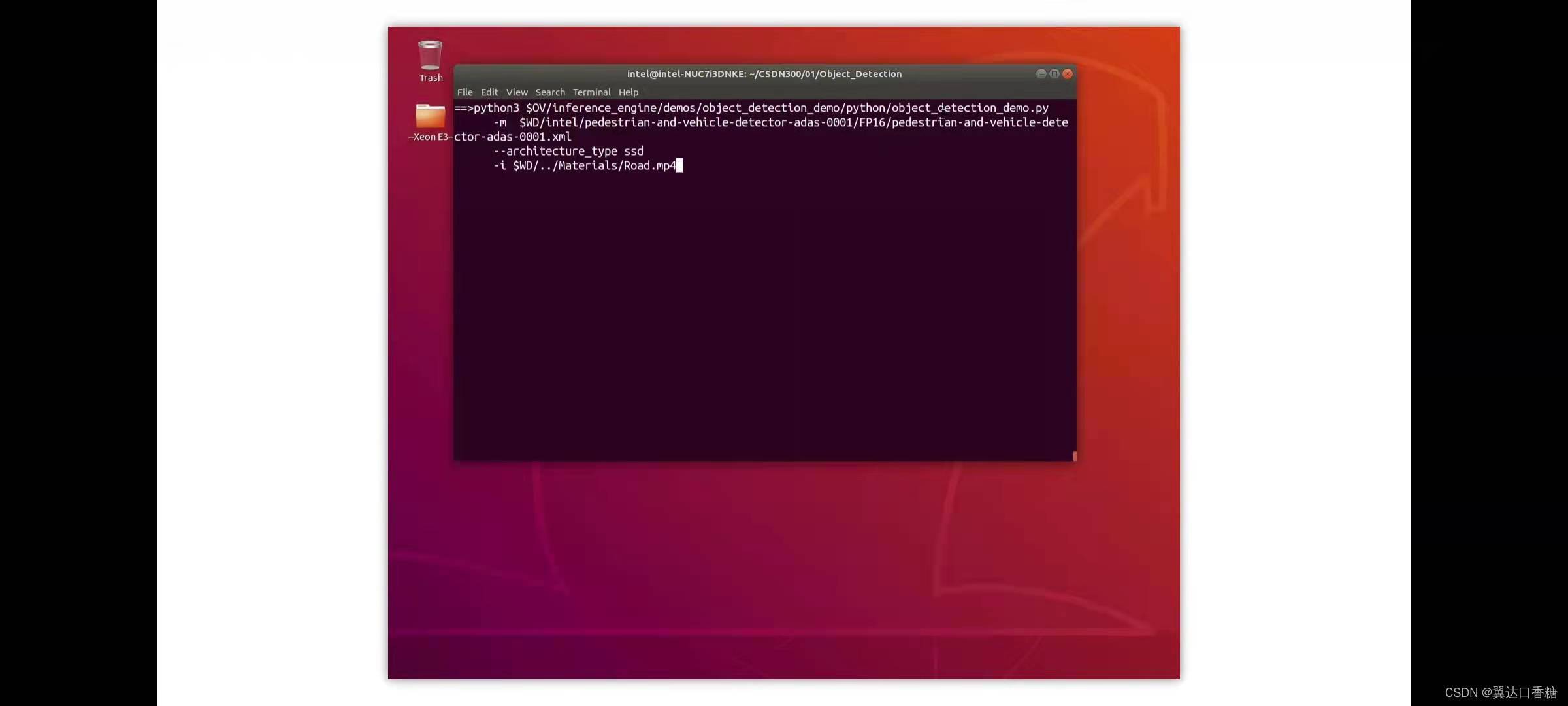
讓我們運行演示,第一個用的架構是ssd,所以需要一個基于ssd的模型使用接警視頻作為輸入
檢測到了很多汽車行人的物件
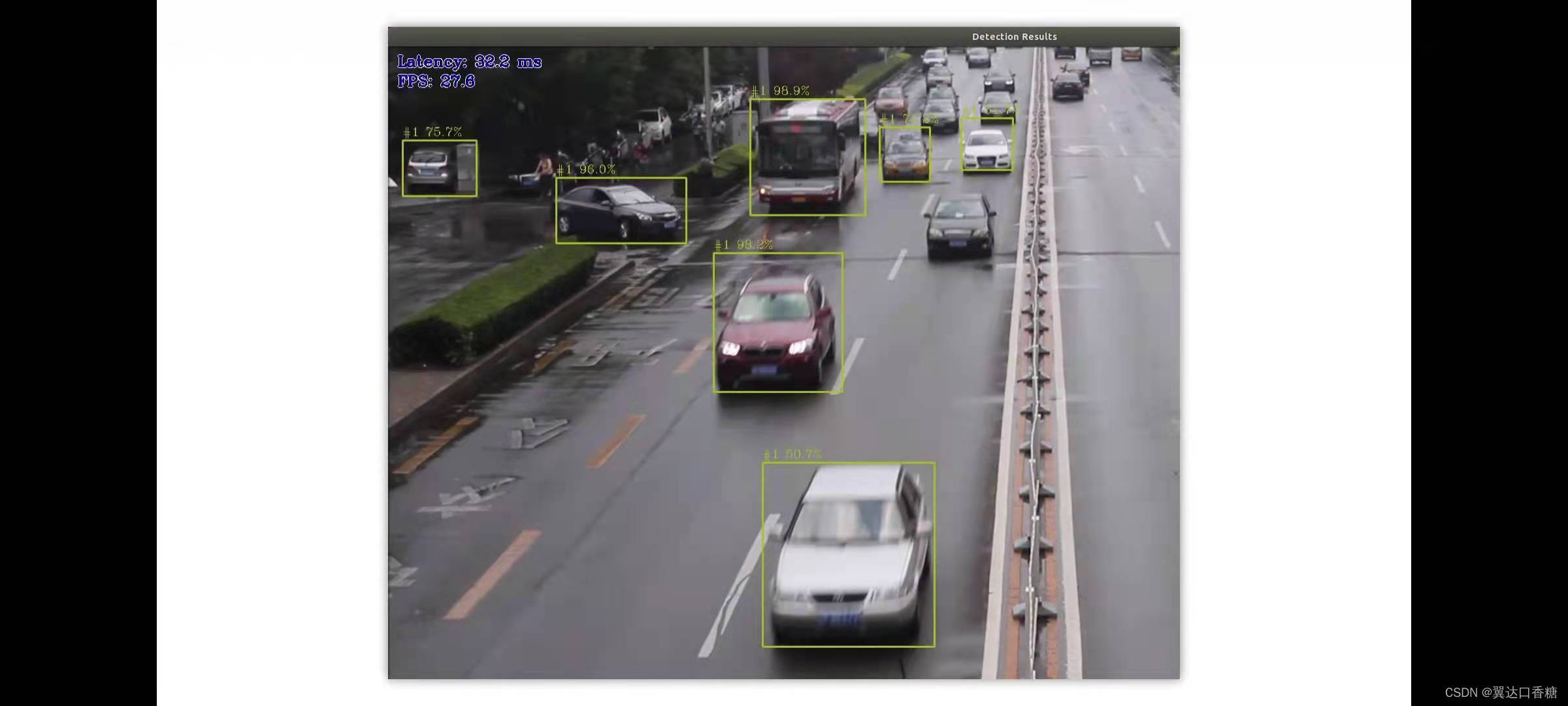
將把架構更改為YOLO的模型
稍微更改一下檢測域值
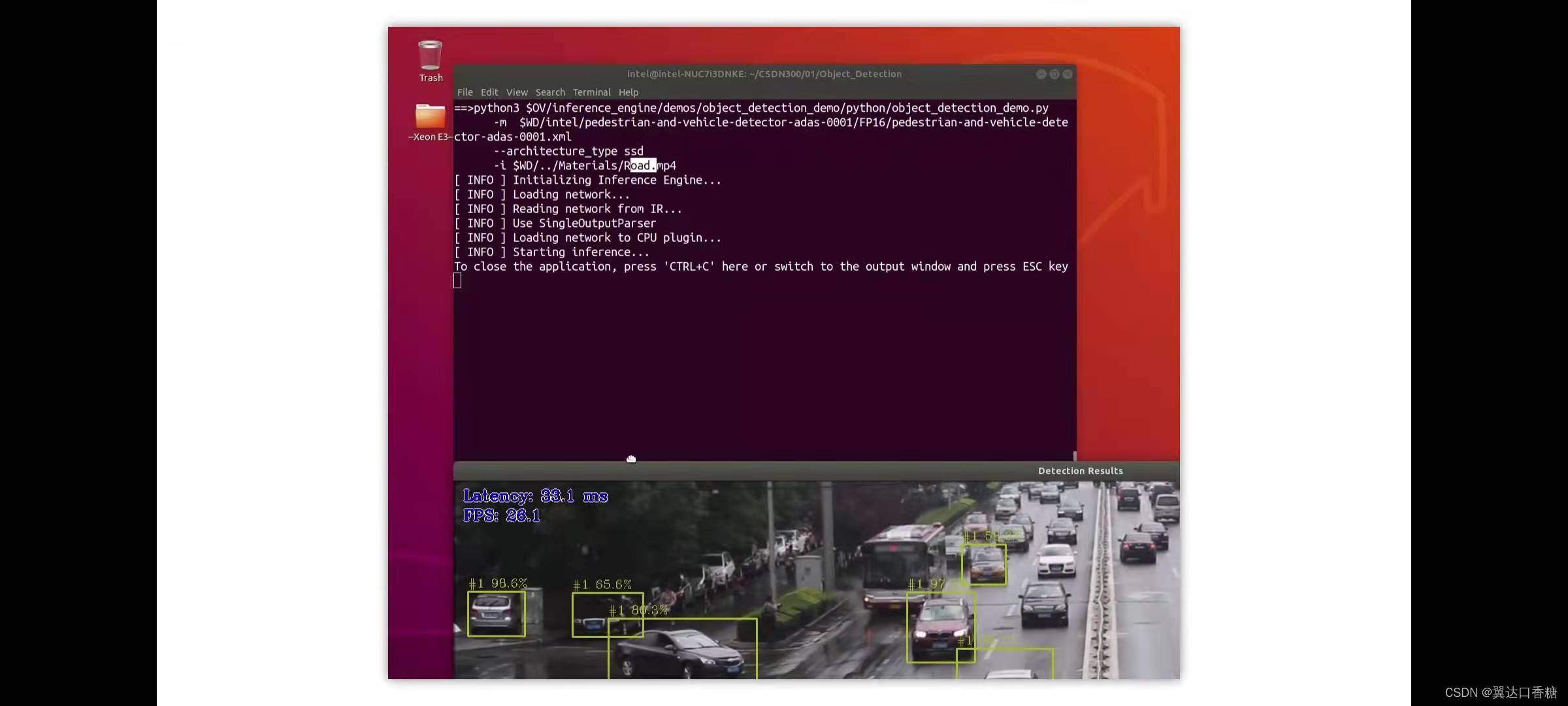
運行成功,所有檢測到的汽車行人,這是完全不同的拓撲結構,但是效果還是相當理想的,
6.目標識別示例
初始化環境
#定義OpenVINO 目錄
export OV=/opt/intel/openvino_2021/
#定義作業目錄
export WD=~/OV-300/01/Object_Detection/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#進入作業目錄
cd $WD
選擇適合你的模型
#由于支持目標檢測的模型較多,你可以在不同拓撲網路下選擇適合模型:
vi $OV/inference_engine/demos/object_detection_demo/python/models.lst
注:關于SSD, Yolo, centernet, faceboxes or Retina拓撲網路的區別,本課程不會繼續深入,有興趣的同學可以自行上網了解,在OpenVINO中的deployment_tools/inference_engine/demos/的各個demo檔案夾中都有model.lst列出了該demo支持的可直接通過downloader下載使用的模型
轉換模型至IR格式
#本實驗已經事先下完成:pedestrian-and-vehicle-detector-adas 與 yolo-v3-tf
#使用Converter進行IR轉換,由于pedestrian-and-vehicle-detector-adas 為英特爾預訓練模型,已經轉換IR完成,只需要對yolo-v3進行轉換:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --name yolo-v3-tf
查看待檢測的視頻
cd $WD/…/Materials/Road.mp4
#播放視頻:
show Road.mp4
使用SSD模型運行目標檢測示例
cd $WD
#運行 OMZ (ssd) model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/intel/pedestrian-and-vehicle-detector-adas-0001/FP16/pedestrian-and-vehicle-detector-adas-0001.xml --architecture_type ssd -i $WD/…/Materials/Road.mp4 --no_show -o $WD/output_ssd.avi
#轉換為mp4格式進行播放
ffmpeg -i output_ssd.avi output_ssd.mp4
show output_ssd.mp4
運行Yolo-V3下的目標檢測示例
#運行 the Yolo V3 model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/public/yolo-v3-tf/FP16/yolo-v3-tf.xml -i $WD/…/Materials/Road.mp4 --architecture_type yolo --no_show -o $WD/output_yolo.avi
#轉換為mp4格式進行播放
ffmpeg -i output_yolo.avi output_yolo.mp4
show output_yolo.mp4
!請對比兩個模型在相同代碼下的檢測性能
7.替你做英語閱讀理解(NLP)——自動回答問題
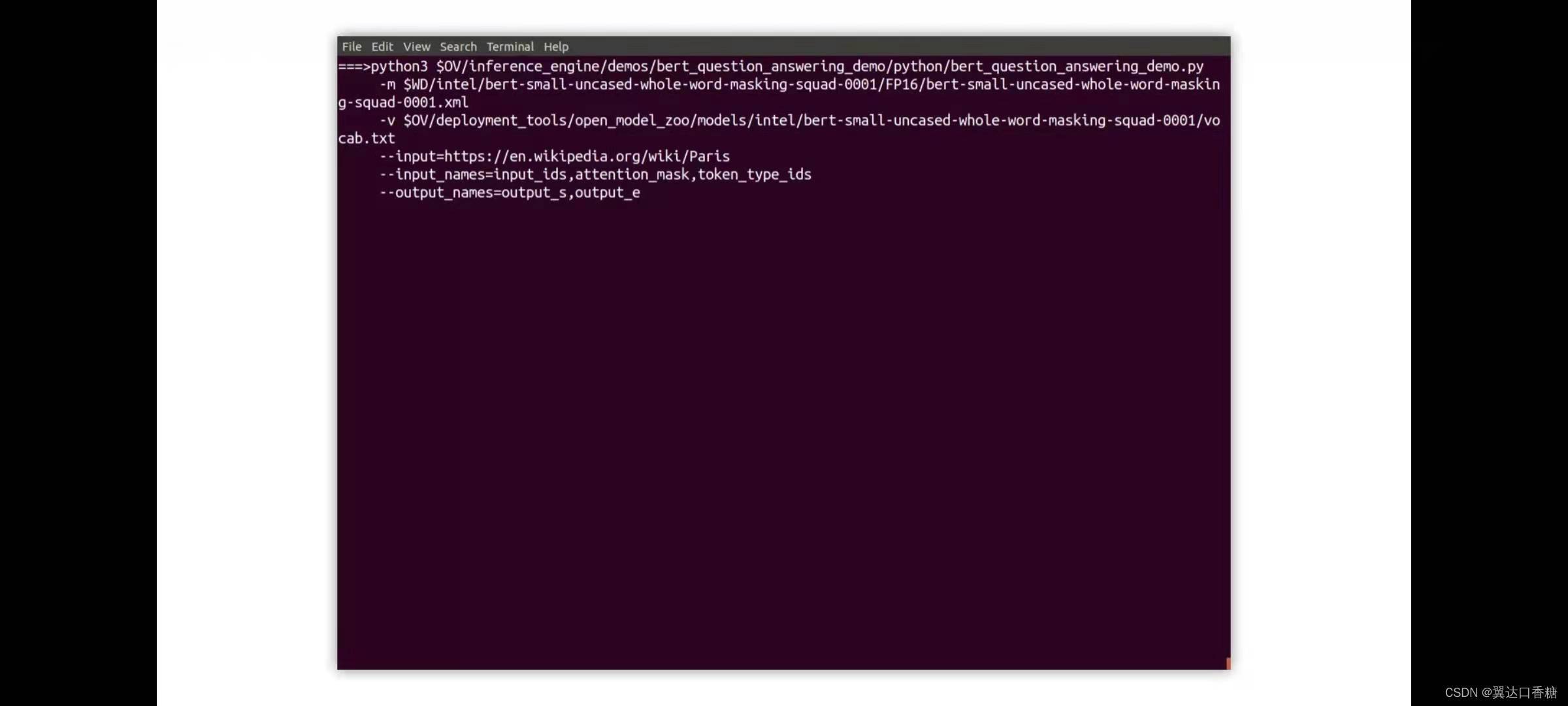
最后一個是NLP(自然語言處理)部分,這個演示使用bert模型來處理檔案,并根據文本內容使用模型自動回答問題,這里可以使用任何你喜歡的文本

這里以有關巴黎的維基百科頁面,(下面有官網),首先需要加載模型,并將其轉換為ir,然后運行演示
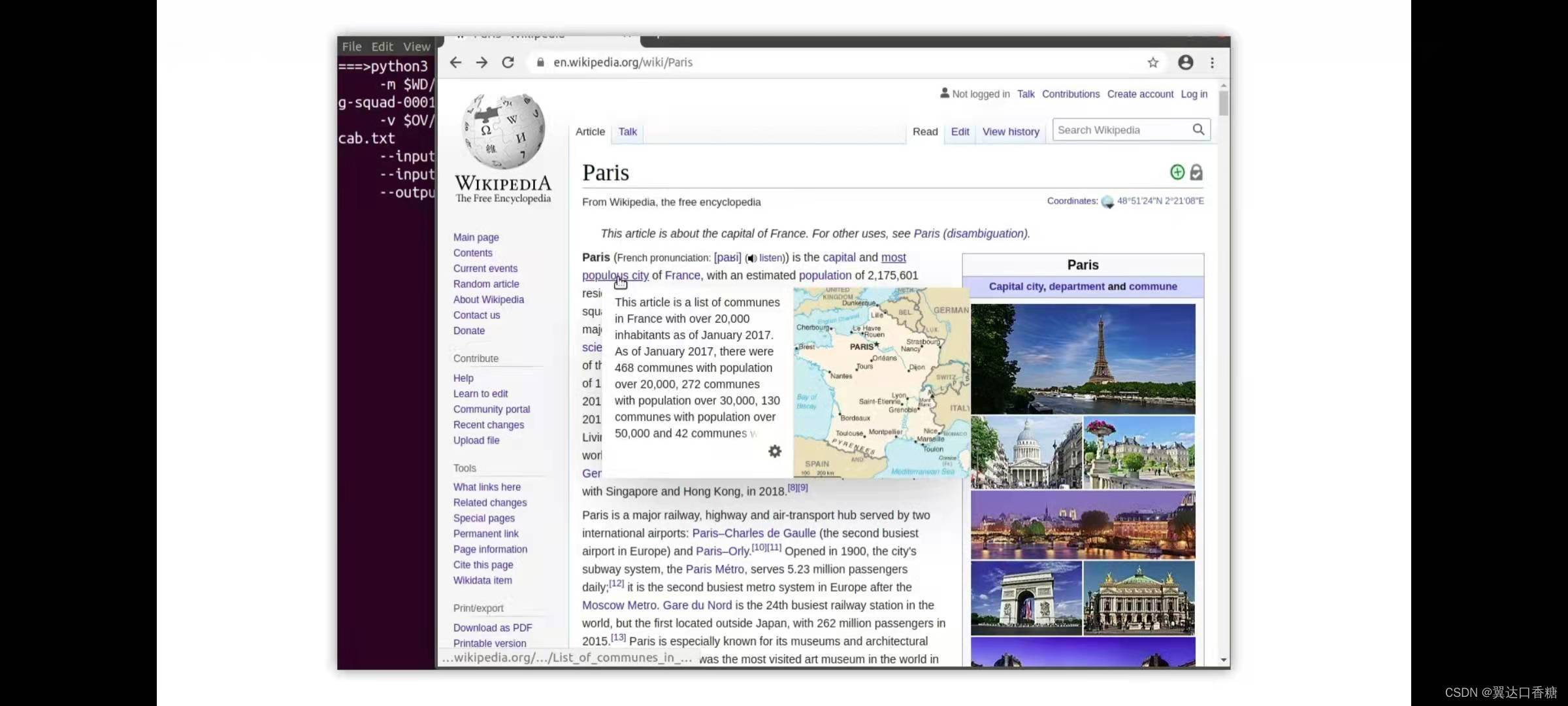
輸入是維基百科、模型、配置引數等,和上面六個演示一樣
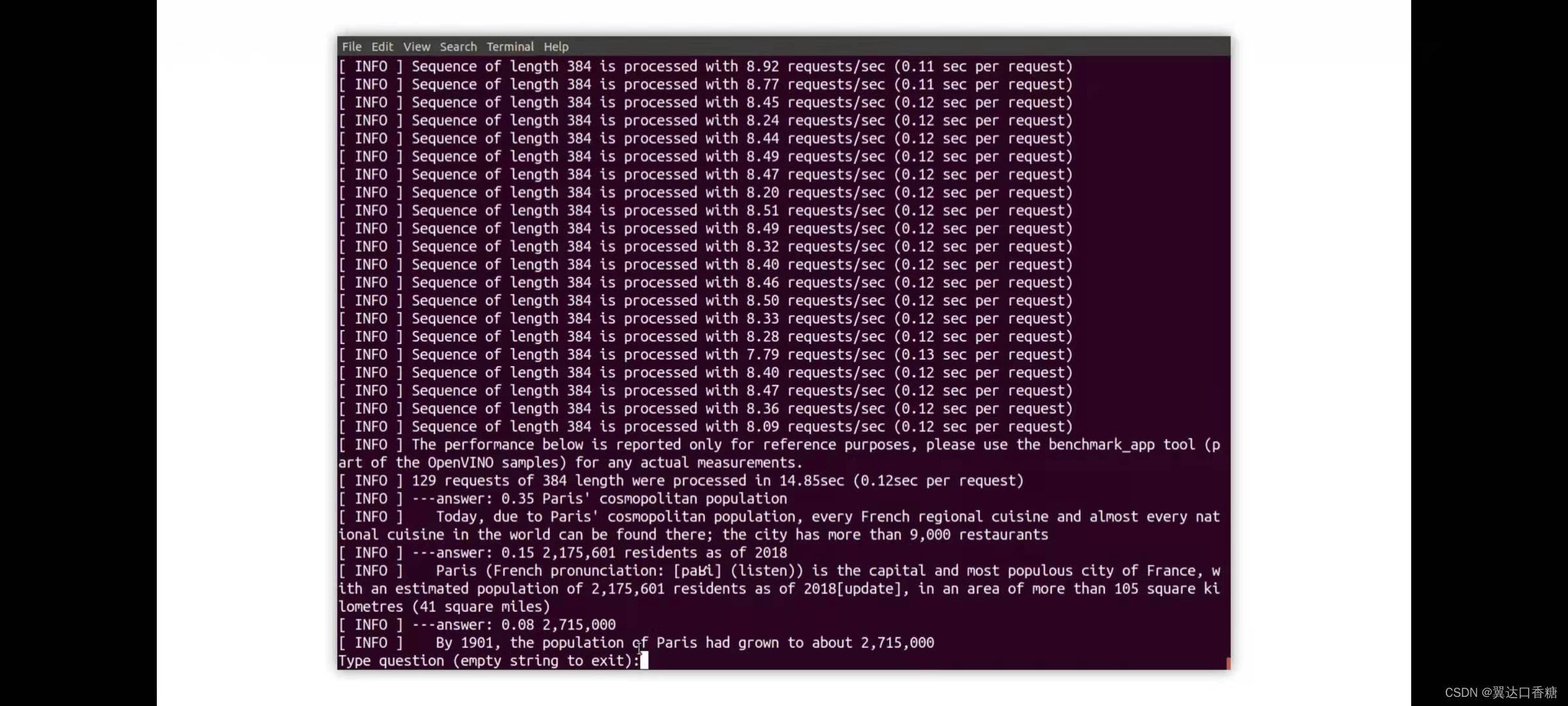
一旦我們運行演示文本就會被處理,現在也是正在等待一個問題,現在我們可以提出一些問題,例如,巴黎的人口是多少?模型正在作業,因為這是一個長文本,每384個單詞,就會呼叫一次模型,所以你可以看到很多解釋,其中你可以看到有幾個可能的答案以及概率
最后從下面那句資訊中知道巴黎的人口略多于200萬人
7.自然語言處理示例(NLP)——自動回答問題
初始化環境
#定義作業目錄
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/NLP-Bert/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#進入目錄
cd $WD
查看支持的模型串列
#可用串列:
cat $OV/deployment_tools/inference_engine/demos/bert_question_answering_demo/python/models.lst
注:在OpenVINO中的deployment_tools/inference_engine/demos/的各個demo檔案夾中都有model.lst列出了該demo支持的可直接通過downloader下載使用的模型,且我們已經事先下載好全部模型為IR格式,
打開待識別的網址
#使用瀏覽器打開一個英文網址進行瀏覽,例如Intel官網:https://www.intel.com/content/www/us/en/homepage.html
運行NLP示例
python3 $OV/inference_engine/demos/bert_question_answering_demo/python/bert_question_answering_demo.py -m $WD/intel/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.xml -v $OV/deployment_tools/open_model_zoo/models/intel/bert-small-uncased-whole-word-masking-squad-0001/vocab.txt --input=https://www.intel.com/content/www/us/en/homepage.html --input_names=input_ids,attention_mask,token_type_ids --output_names=output_s,output_e
#在Type question (empty string to exit): 輸入core,即可查看當前對于core(酷睿)的可知資訊,例如: Intel? Core? processors provide a range of performance from entry-level to the highest level ,當然你也可以輸入別的問題,對比網站上的相關描述
注:–input=https://www.intel.com/content/www/us/en/homepage.html 為我們需要訪問的英文網站
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421846.html
標籤:AI