文章目錄
- 細解 kafka 架構、應用場景及良好特性
- 什么是 kafka
- kafka 框架/組成
- kafka 資料流
- 訊息資料寫入 — 磁區策略
- 輪訓策略
- 隨機策略
- 按 key 哈希策略
- 訊息消費 — 分派策略
- rebalance
- range 策略
- 輪訓策略
- 策略缺陷
- 消費者推拉模式
- push 模式
- 缺點
- 優點:
- pull 模式
- 協調者
- KIP-500
- consumer offset 遷移
- 吞吐量高且速度快
- 順序讀寫
- 零拷貝
- sendfile
- mmap
- 讀寫
- 傳統技術
- 讀寫
- 流式處理中扮演的角色
- 附錄

細解 kafka 架構、應用場景及良好特性
文章涵蓋角度較廣,建議收藏備讀!
什么是 kafka
kafka 是一款由 Scala 和 Java 實作的,分布式流式處理平臺,
因為具備高吞吐、可持久化、可水平擴展等特性而被廣泛使用,也是軟體開發人員的進階必備技能!
本文就簡單聊 關于 kafka 具體的內部結構、作業原理、應用場景都有哪些?
kafka 框架/組成
- kafka 的框架或組成是什么?
這個問題比較籠統,仔細一想 kafka 不就是存盤 client 寫入的資料,然后吐給 consumer,難道是問 里面的資料是如何組成的嗎?其實不然,
放大來想,client 寫入 和 consumer 消費也是 kafka 的一部分,那么可以這樣回答:
kafka 可分為四部分:client 、代理[broker]、consumer、協調者[zookeeper],
- client 寫入資料到代理層[broker],代理層做資料的存盤,然后分發給 consumer;最后一部分是統籌管理 kafka,扮演協調者的 zookeeper ,
kafka 資料流
- kafka 中有這么幾個概念:topic、partition、consumer、consumer group、broker……
其中 topic 是訊息主題,屬于邏輯概念,關聯多個 partition[磁區] ;partition 所屬分布在不同的 broker[節點] 上;consumer 是消費者,以 group 區分為小組,小組可消費多個 topic…
資料流鏈路如下:
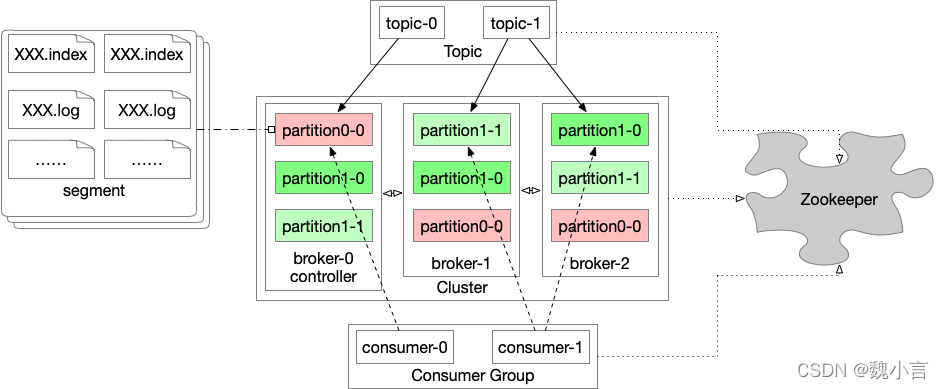
- client 將訊息資料寫入指定的 topic,實質寫入 topic 下關聯的多個 partition 中;
- partition 又可細分為多個體積一致的 segment 【partition 在分布式架構中會進行資料冗余的處理,確保資料/服務高可用,故會存在多個相同的 partition 分布在多個 broker 中】;
- segment 雖然體積一致,但訊息條數可不同,可分為 .index、.log 兩種型別檔案且一一對應;
- partition 又可細分為多個體積一致的 segment 【partition 在分布式架構中會進行資料冗余的處理,確保資料/服務高可用,故會存在多個相同的 partition 分布在多個 broker 中】;
- broker 收到資料之后,進行解壓縮等資料校驗的操作后,會依據分發策略為 consumer 提供資料指派;
- consumer 依據自身的消費能力,去消費 topic 所在的 broker 拉取相關資料;
訊息資料寫入 — 磁區策略
- 既然 topic 是邏輯概念,資料是寫入 partition 中,那么存在多個 partition 時,如何確認寫入的 partition ?
kafka 除了支持訊息寫入時手動指定磁區外,還提供了三種策略進行資料 partition 的負載均衡,分別是 輪訓、隨機、按 key 哈希,
輪訓策略
輪訓 是一種常規的均衡機制,可保證磁區規模最大限度的均勻,
舉個例子,若當前 topic 有 三個磁區,partition 0、1、2;寫入時就會依次寫入 0、1、2……
隨機策略
隨機 是一種常規的均衡機制,其均勻性沒 輪訓策略程度高,
舉個例子,若當前 topic 有 三個磁區,partition 0、1、2;每次寫入會在 0-2 之間隨機出一磁區進行寫入操作……
按 key 哈希策略
哈希 是一種常規的均衡機制,可將相同 key 寫入同一磁區,
舉個例子,若當前 topic 有 三個磁區,partition 0、1、2;每次寫入會對訊息 key 進行
哈希;在同一磁區中,訊息具備保序特性;此策略可支持訊息保序策略……
訊息消費 — 分派策略
分派策略是指在消費者以群組形式消費時,partition 如何分派給消費實體的策略,觸發策略生效最常見的時機就是 rebalance,
rebalance
- 我們先弄明白什么時候才會 rebalance ?
三種情況會觸發 kafka 的 rebalance,分別是:
- 消費組實體數量發生變化:添加消費實體、實體下線
- 消費組訂閱主題數量發生變化:消費組可通過正則匹配訂閱主題
- 消費組訂閱主題的磁區數量發生變化:主題添加/刪減磁區
歸結起來兩部分:消費者規模變化 + 消費磁區規模變化 都會導致消費組的 rebalance,
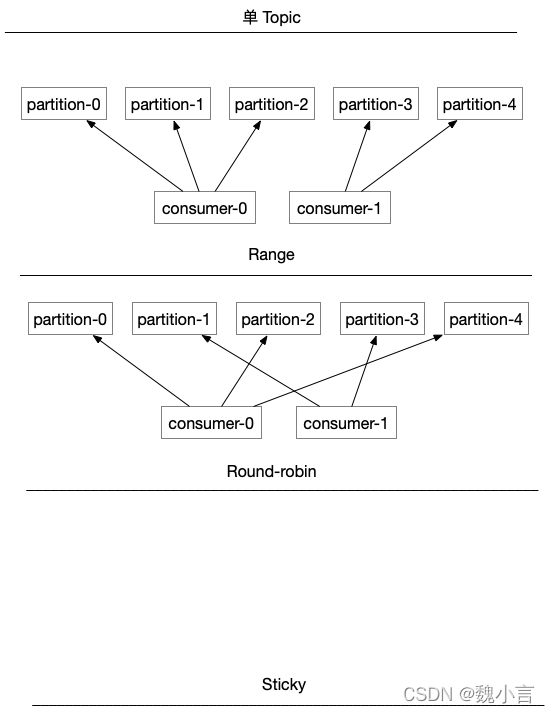
range 策略
range 是基于 區間分割的思想進行分派,
它會將單個 topic 的磁區按順序排列,將磁區劃分為 與消費者實體數量 一致的分塊,存在余數的場景會額外分派給第一個消費實體 進行消費,
舉個例子,topic-0 存在 5 個磁區 0-4,2個消費實體 0-1,
依據 range 策略,consumer-0 將被分派 partition0-2,consumer-1 將被分派 partition3-4 ;
輪訓策略
輪訓 是基于全部的 topic 磁區 做依次分發 給到 消費者實體,
舉個例子,topic-0/1 存在 2 個磁區
topic0/1-partition-0、topic0/1-partition-1,2個消費實體 0-1,
依據 輪訓策略,consumer-0 將被分派 topic0/1-partition-0,consumer-1 將被分派 topic0/1-partition-1;
策略缺陷
-
在 range 策略中,多 topic 主題下會導致資料的傾斜,單 topic 狀態是 ok 的;
-
在 輪訓 策略中,多 topic 主題下磁區數量的差異會導致資料的傾斜,多 topic 磁區規模一致狀態是 ok 的;
為什么會這樣呢?
單 topic 主題下,range 、輪訓 策略狀態如下:
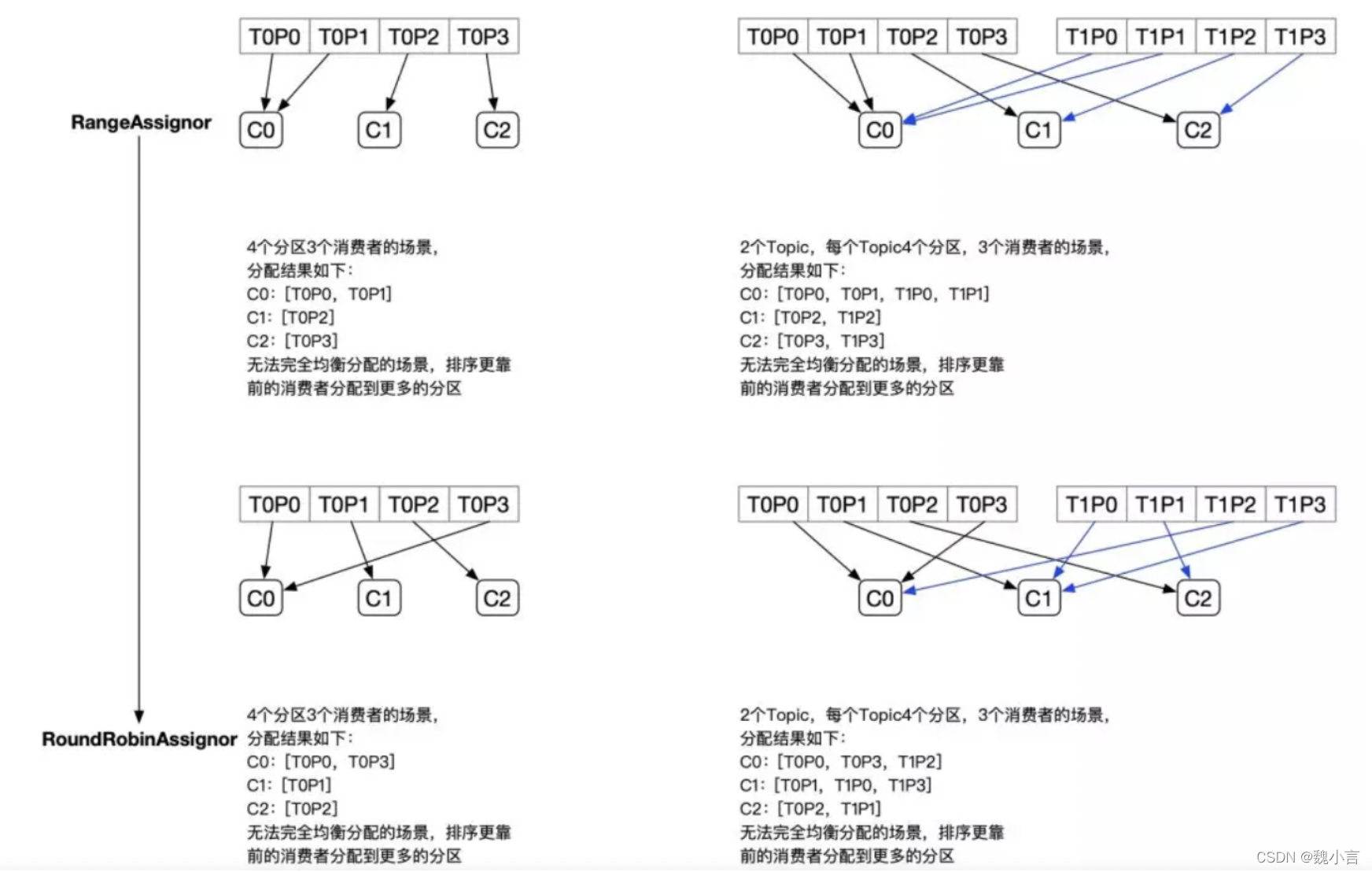
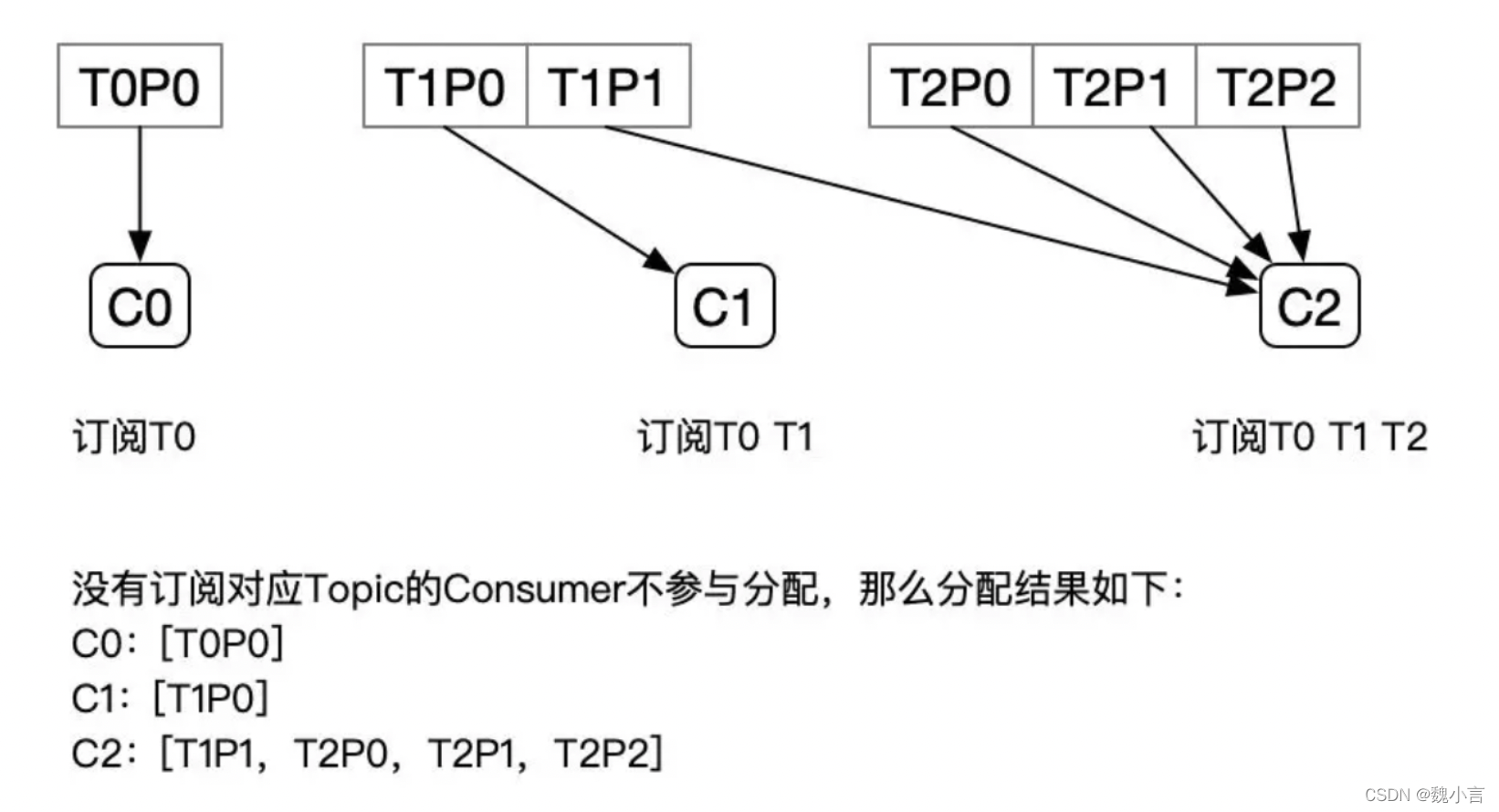
多 topic 主題下磁區數量的差異狀態下,輪訓策略狀態如下:
消費者推拉模式
作為訊息中間件,我們了解有兩種訊息處理方式:pull or push…
那么 kafka 消費者為什么就保留了 pull 模式呢?
push 模式
push 模式支持訊息佇列主動向下游推送訊息,那么中間件需要知曉這些下游接收狀態:
- 什么時候可以發送訊息
- 哪些訊息都是發送給哪些下游
- …
知道了這些狀態,訊息以來就可以立即發送給下游服務,
這樣的機制存在些問題,優缺點十分明顯,
缺點
- 從架構設計上來講,
- 中間件與下游服務耦合嚴重;
- 中間件需保持下游服務狀態,不利于承接大規模的下游服務;
- 從業務上來講,
- 中間件無法預測發送速率,每個下游的消費能力不同,過大的視窗會壓垮下游;太小的視窗,下游利用率不足;
優點:
訊息處理實時性好;
pull 模式
pull 模式支持下游服務主動向中間件拉訊息,
此模式良好的解決了 push 模式缺陷問題,但也缺失了其優點問題,除了 push 模式相關的特性,pull 模式還有額外的特點:
- 由于訊息存在處理延遲問題,所以 pull 模式支持資料的聚合和批量拉取的特征;
kafka 支持了 pull 模式,也是其分布式高可擴展性的經典設計,從設計方案選型來講,兩種模式都有不同的優缺點,適用于各自的業務場景,當場出了這兩種模式,逐漸還衍生出其他的模式,如 long-polling……等等,后續介紹,這里不做重點,
協調者
- 在 kafak 架構/組成中,存在 zookeeper 組件作為協調者,
那么協調者具體的作用是什么呢?或者說 kafka 中的 zookeeper 發揮了什么作用呢?
- kafka 主要利用 zookeeper 的共識演算法,保證資料的一致性特點,
拆開來講,- 存盤元資料
zookeeper 存盤了 kafka 集群的 broker集群資訊、消費組資訊、主題資訊及磁區、ISR 同步集合、… 等原資料; - 資料的一致性
zookeeper 不僅僅對資料做存盤,還要動態更新資料、保障對外一致性; - Leader 選舉
kafka 通過提供多副本機制完成資料的冗余,為服務高可用提供支持,其副本之間的選主策略由 zookeeper 提供實作,此功能也可以叫做 分布式鎖;
- 存盤元資料
KIP-500
KIP-500 是 kafka 社區正在逐步實作的一個提案,主旨是接觸對 zookeeper 的依賴,為什么這樣做呢?
總體概括有這么幾點,
- 維護成本:需維護 kafka 、zookeeper 兩個服務;
- 存盤成本:資料割裂,主要元資料依賴外部服務且、磁區及節點動態變更頻繁時,zookpeer 壓力大對 kafka 服務性能有影響;
- Leader 選舉:大規模資料場景下,zookeeper 遷移 controll 時,存在 kafka 暫不可用問題;
KIP-500 用 Quorum Controller 代替之前的 Controller,Quorum 中每個 Controller 節點都會保存所有元資料,通過 KRaft 協議保證副本的一致性,
這樣即使 Quorum Controller 節點出故障了,新的 Controller 遷移也會非常快,
consumer offset 遷移
KIP-500 提案,一些已經逐步落地,
比如,新版本中已經將 消費者提交的 offset 及 消費組資訊 由原來的 zookeeper 替換至了 kafka 的 consumer_offset 主題存盤….
在云原生的背景下,使用 Zookeeper 給 Kafka 的運維和集群性能造成了很大的壓力,去除 Zookeeper 的必然趨勢!
吞吐量高且速度快
上文了解了 kafka 構成組件的功能實作及目前社區發展趨勢,那么為什么 kafak 大收市場青睞呢?
幾十上百萬的吞吐量及毫秒級的資料處理等特性是收市場歡迎的主要因素之一,
順序讀寫
在 product 寫入資料時,在磁區的 segment 檔案中是以追加的形式進行,并且會給每個訊息分配唯一的 offset 標識;在 consumer 讀資料時,以 offset 作為偏移量,順序讀出資料;
- 現在感覺順序讀寫好像理應就應該這樣設計,下面給出一組資料對比一下,就知道這種設計是多么的優越!
當磁盤順序讀或寫的速度可達 400M/s,而 隨機讀寫的速度只有 幾十到幾百 K/s,兩者差距極大!
順序讀寫可最大程度的利用磁盤的存盤特性提速,
零拷貝
介紹零拷貝之前,先介紹兩種 Linux 技術,分別是 sendfile、mmap,
sendfile
sendfile :可直接將資料從網卡讀至記憶體[內核空間],反之亦然;互動程序省略應用快取區[用戶空間]的資料暫存,
mmap
mmap:建立磁盤檔案與記憶體的映射關系,記憶體變更將反射至磁盤[資料記憶體會暫存,實際落地由系統 flash 時機決定];實作修改記憶體即變更磁盤,
讀寫
通過兩種技術的結合,可實作 kafka 訊息資料讀寫磁盤的零拷貝,吞吐量較使用傳統技術提升 3倍以上,
在 product 寫入資料時,broker 直接從 socket 緩沖區讀出資料利用 sendfile 技術寫入 記憶體,而利用 mmap 技術可完成記憶體與磁盤的狀態映射,此刻就已經完成了資料的寫入;反之,當 consumer 讀資料時,直接把 磁盤資料 讀至 網卡[socker]即可,
傳統技術
在傳統的技術中,磁盤資料的讀寫,至少需要經歷四個程序……
讀寫
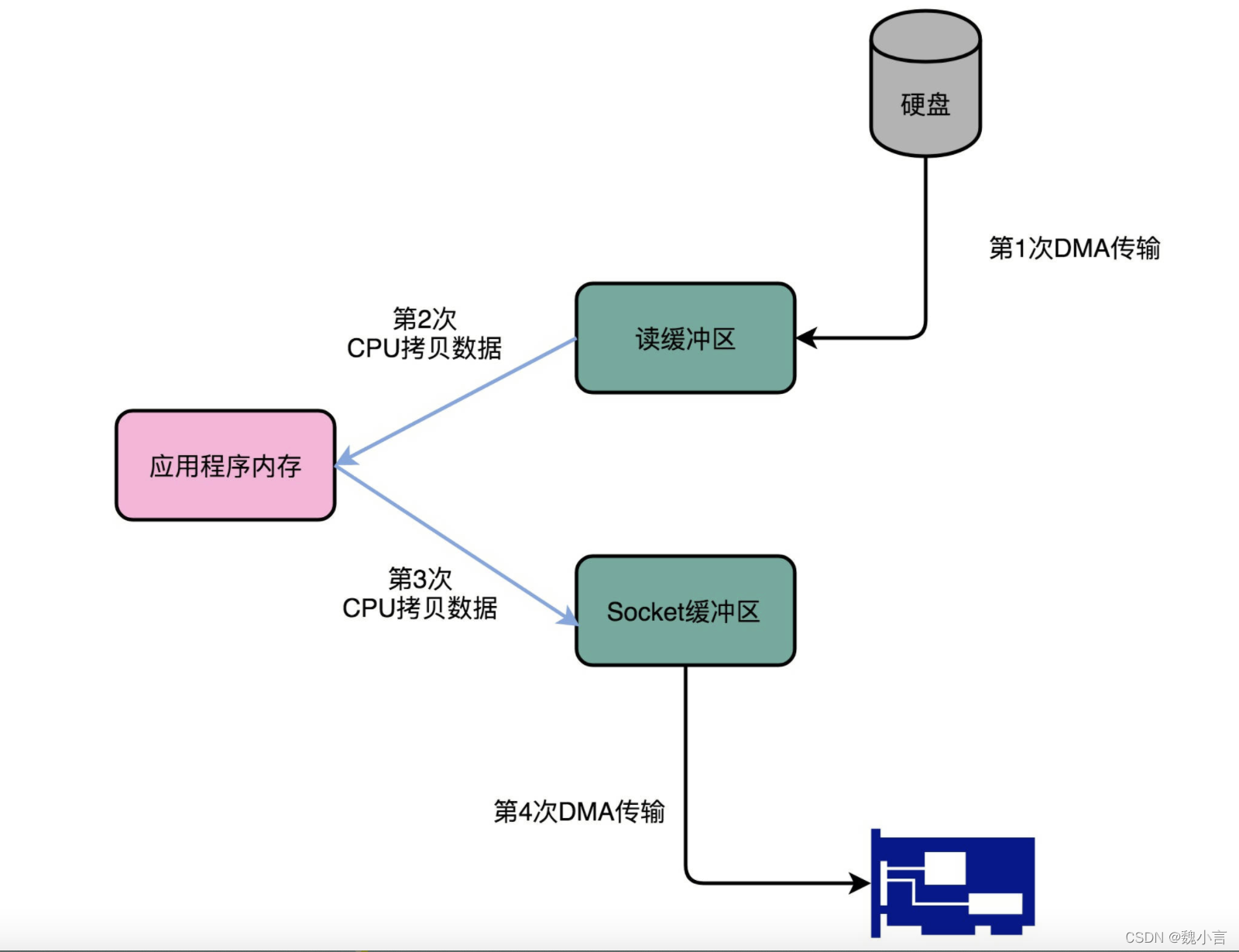
在 讀資料 的時候,先把資料從 磁盤 寫入 內核緩沖區;再從 內核緩沖區 寫入 應用程式緩沖區;再由 應用程式緩沖區 寫入 socker 緩沖區;最后由 soccer 緩沖區 寫入 網卡緩沖區……反之寫資料亦然,
這個時候,你可以回過頭看看這個程序,我們只是要“搬運”?份資料,結果卻整整搬運了四次,而且這里面,其實都是把同一份資料在記憶體里面搬運來搬運去,特別沒有效率!
流式處理中扮演的角色
- Kafka 在 監控系統框架 ELK[Elasticsearch + Logstash + Kibana] 中扮演著重要的角色!
- 隨著 trace 技術的不斷發展、業務資料規模的膨脹,傳統的監控框架 ELK [Elasticsearch + Logstash + Kibana] 不足點日漸顯露,
其中組件 logstash 由 JRuby 實作,負責日志的收集、加工[規則聚合、過濾…]、資料傳輸至 elasticsearch,
實作語言的巨大記憶體消耗、日志加工對節點機器性能的影響、大規模資料中的最終精讀……等問題促使了新的組件 filebeat、kafka 的介入,
通過 Filebeat 部署進行日志收集,促使模塊解耦,組件部署更加簡單且輕量的同時,資料收集更加實時、準確;
通過引入 kakfa 組件實作資料的冗余備份的同時,也支撐了整個框架的橫向擴展;更是對資料進行了消峰填谷,提升服務可用性,
所以說,由于 filebeat 、 kafka 組件其出色的設計和特性,對傳統監控框架的性能等各方面具有極大的提升,
附錄
不要用戰術的勤奮來掩蓋戰略的懶惰
附:
Filebeat 詳細解讀
Elasticsearch 原理刨析
什么是云原生 & 市場真正敏捷力量
深度刨析分布式鎖 & 詳細設計
基于 Consul 實作決議分布式鎖
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421864.html
標籤:其他