資料匯入HBase中常用的有三種方式:sqoop, HBase importTsv, HBase Bulkload,這三種方式,各有優缺點,下面將逐一介紹這三種方案的優缺點.
1. Sqoop直接匯入
可以使用
SQOOP
將
MySQL
表的資料匯入到
HBase
表中,指定
表的名稱、列簇及
RowKey
,范
例如下所示:
引數含義解釋:
知識拓展:如何使用SQOOP進行增量匯入資料至HBase表,范例命令如下:
例一:
/export/servers/sqoop/bin/sqoop import \
-D sqoop.hbase.add.row.key=true \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_users \
--hbase-create-table \
--hbase-table tbl_users \
--column-family detail \
--hbase-row-key id \
--num-mappers 2
1
、
-D sqoop.hbase.add.row.key=true
是否將
rowkey
相關欄位寫入列族中,默認為
false
,默認情況下你將在列族中看不到任何
row
key
中的欄位,注意,該引數必須放在
import
之后,
2
、
--hbase-create-table
如果
hbase
中該表不存在則創建
3
、
--hbase-table
對應的
hbase
表名
4
、
--hbase-row-key hbase
表中的
rowkey,
注意格式
5
、
--column-family hbase
表的列族
例二:
/export/servers/sqoop/bin/sqoop import \
-D sqoop.hbase.add.row.key=true \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_logs \
--hbase-create-table \
--hbase-table tag_logs \
--column-family detail \
--hbase-row-key id \
--num-mappers 20 \
--incremental lastmodified \
--check-column log_time \相關增量匯入引數說明:
使用
SQOOP
匯入資料到
HBase
表中,有一個限制:
需要指定
RDBMs
表中的某個欄位作為
HBase
表的
ROWKEY
,如果
HBase
表的
ROWKEY
為多
個欄位組合,就無法指定,所以此種方式有時候不能使用,
2. HBase ImportTSV
ImportTSV
功能描述:
將tsv(也可以是csv,每行資料中各個欄位使用分隔符分割)格式文本資料,加載到HBase表中,
1)、采用Put方式加載匯入
2)、采用BulkLoad方式批量加載匯入
使用如下命令,查看
HBase
官方自帶工具類使用說明:
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf ${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0- cdh5.14.0.jar
執行上述命令提示如下資訊:
其中
importtsv
就是將文本檔案(比如
CSV
、
TSV
等格式)資料匯入
HBase
表工具類,使用
說明如下:
An example program must be given as the first argument.
Valid program names are:
CellCounter: Count cells in HBase table.
WALPlayer: Replay WAL files.
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster.
export: Write table data to HDFS.
exportsnapshot: Export the specific snapshot to a given FileSystem.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table.
verifyrep: Compare the data from tables in two different clusters.Usage: importtsv -Dimporttsv.columns=a,b,c <tablename> <inputdir>
The column names of the TSV data must be specified using the -
Dimporttsv.columns
option. This option takes the form of comma-separated column names, where
each
column name is either a simple column family, or a columnfamily:qualifier.
The special column name HBASE_ROW_KEY is used to designate that this column
should be used as the row key for each imported record.
To instead generate HFiles of data to prepare for a bulk data load, pass
the option:
-Dimporttsv.bulk.output=/path/for/output
'-Dimporttsv.separator=|' - eg separate on pipes instead of tabs
For performance consider the following options:
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
分別演示采用直接
Put
方式和
HFile
檔案方式將資料匯入
HBase
表,命令如下:
2.1 直接匯入Put方式
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf
${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0-
cdh5.14.0.jar \
importtsv \
-Dimporttsv.columns=HBASE_ROW_KEY,detail:log_id,detail:remote_ip,detail:s
ite_global_ticket,detail:site_global_session,detail:global_user_id,detai
l:cookie_text,detail:user_agent,detail:ref_url,detail:loc_url,detail:log
_time \
tbl_logs \
/user/hive/warehouse/tags_dat.db/tbl_logs
上述命令本質上運行一個
MapReduce
應用程式,將文本檔案中每行資料轉換封裝到
Put
物件,然后插入到
HBase
表中,
回顧一下:
采用Put方式向HBase表中插入資料流程:
Put
-> WAL 預寫日志
-> MemStore(記憶體) ,當達到一定大寫Spill到磁盤上:
StoreFile(
HFile)
思考:
對海量資料插入,能否將資料直接保存為HFile檔案,然后加載到HBase表中2.2 轉換為HFile檔案,再加載至表
# 1. 生成HFILES檔案
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf
${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0-
cdh5.14.0.jar \
importtsv \
-Dimporttsv.bulk.output=hdfs://bigdata-
cdh01.itcast.cn:8020/datas/output_hfile/tbl_logs \
-
Dimporttsv.columns=HBASE_ROW_KEY,detail:log_id,detail:remote_ip,detail:
site_global_ticket,detail:site_global_session,detail:global_user_id,det
ail:cookie_text,detail:user_agent,detail:ref_url,detail:loc_url,detail:
log_time \
tbl_logs \
/user/hive/warehouse/tags_dat.db/tbl_logs
# 2. 將HFILE檔案加載到表中
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf ${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0- cdh5.14.0.jar \ completebulkload \
hdfs://bigdata-cdh01.itcast.cn:8020/datas/output_hfile/tbl_logs \ tbl_logs
缺點:
1
)、
ROWKEY
不能是組合主鍵 只能是某一個欄位
2
)、當表中列很多時,書寫
-Dimporttsv.columns
值時很麻煩,容易出錯
3. HBase Bulkload
在大量資料需要寫入
HBase
時,通常有
put
方式和
bulkLoad
兩種方式,
1
、
put
方式為單條插入,在
put
資料時會先將資料的更新操作資訊和資料資訊
寫入
WAL
,
在寫入到
WAL
后,
資料就會被放到
MemStore
中
,當
MemStore
滿后資料就會被
flush
到磁盤
(
即形成
HFile
檔案
)
,在這種寫操作程序會涉及到
flush
、
split
、
compaction
等操作,容易造
成節點不穩定,資料匯入慢,耗費資源等問題,在海量資料的匯入程序極大的消耗了系統
性能
,避免這些問題最好的方法就是使用
BulkLoad
的方式來加載資料到
HBase
中,
val put = new Put(rowKeyByts)
put.addColumn(cf, column, value)
put.addColumn(cf, column, value)
put.addColumn(cf, column, value)
put.addColumn(cf, column, value)
table.put(put)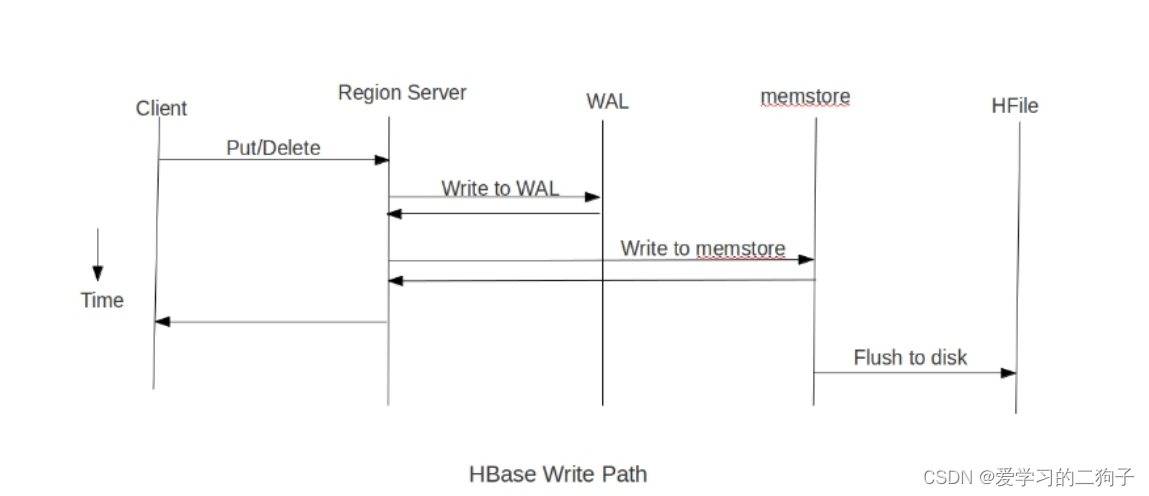
2
、
BulkLoader
利用
HBase
資料
按照
HFile
格式存盤在
HDFS
的原理,使用
MapReduce
直接批量
生成
HFile
格式檔案后,
RegionServers
再將
HFile
檔案移動到相應的
Region
目錄下
,
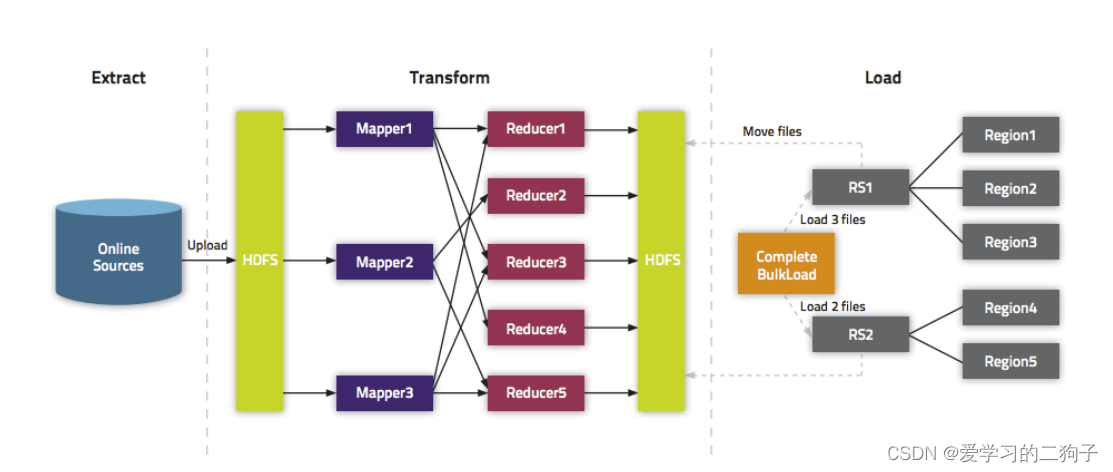
1)、Extract,異構資料源資料匯入到 HDFS 之上,
2)、Transform,通過用戶代碼,可以是 MR 或者 Spark 任務將資料轉化為 HFile,
3)、Load,HFile 通過 loadIncrementalHFiles 呼叫將 HFile 放置到 Region 對應的 HDFS 目錄上,該程序可能涉及到檔案切分,
1、不會觸發WAL預寫日志,當表還沒有資料時進行資料匯入不會產生Flush和Split,
2、減少介面呼叫的消耗,是一種快速寫入的優化方式,
Spark讀寫HBase之使用Spark自帶的API以及使用Bulk Load將大量資料匯入HBase: https://www.jianshu.com/p/b6c5a5ba30af
Bulkload
程序主要包括三部分:
1
)、
Extract
,異構資料源資料匯入到
HDFS
之上,
2
)、
Transform
,通過用戶代碼,可以是
MR
或者
Spark
任務將資料轉化為
HFile
,
3
)、
Load
,
HFile
通過
loadIncrementalHFiles
呼叫將
HFile
放置到
Region
對應的
HDFS
目錄上,該程序可能涉及到檔案切分,
1
、不會觸發
WAL
預寫日志,當表還沒有資料時進行資料匯入不會產生
Flush
和
Split
,
2
、減少介面呼叫的消耗,是一種快速寫入的優化方式,
Spark
讀寫
HBase
之使用
Spark
自帶的
API
以及使用
Bulk Load
將大量資料匯入
HBase
:
https://www.jianshu.com/p/b6c5a5ba30af
Bulkload程序主要包括三部分:
1、從資料源(通常是文本檔案或其他的資料庫)提取資料并上傳到HDFS,
抽取資料到HDFS和Hbase并沒有關系,所以大家可以選用自己擅長的方式進行,
2、利用MapReduce作業處理事先準備的資料 ,
這一步需要一個MapReduce作業,并且大多數情況下還需要我們自己撰寫Map函式,而Reduce
函式不需要我們考慮,由HBase提供,
該作業需要使用rowkey(行鍵)作為輸出Key;KeyValue、Put或者Delete作為輸出Value,
MapReduce作業需要使用HFileOutputFormat2來生成HBase資料檔案,
為了有效的匯入資料,需要配置HFileOutputFormat2使得每一個輸出檔案都在一個合適的區
域中,為了達到這個目的,MapReduce作業會使用Hadoop的TotalOrderPartitioner類根據表的
key值將輸出分割開來,
HFileOutputFormat2的方法configureIncrementalLoad()會自動的完成上面的作業,
3、告訴RegionServers資料的位置并匯入資料,
這一步是最簡單的,通常需要使用LoadIncrementalHFiles(更為人所熟知是
completebulkload工具),將檔案在HDFS上的位置傳遞給它,它就會利用RegionServer將資料導
入到相應的區域,轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/421865.html
標籤:其他