特征是什么?為什么需要工程設計?
基本上,所有機器學習演算法都是將一些輸入資料轉化為輸出,這些輸入資料包括若干特征,通常是以由列組成的表格形式出現,而演算法往往要求輸入具有某些特性的特征才能正常作業,因此,出現了對特征工程的需求,
特征工程至少有兩個目標,
-
構建適合機器學習演算法要求的輸入資料,
-
改善機器學習模型的性能,
根據《福布斯》的一項調查,資料科學家把 80% 左右的時間花在資料收集、清晰以及預處理等資料準備上,
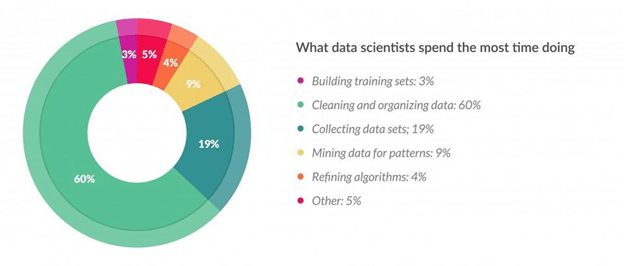
這點顯示了特征工程在資料科學中的重要性,因此有必要整理一下特征工程的主要技術,本篇通過 Pandas 和 Numpy 等庫來實際操練,
import pandas as pd
import numpy as np
獲得特征工程專業知識的最佳方法是對各種資料集試驗不同的技術,并觀察其對模型性能的影響,
本文主要介紹以下幾個方面,內容較多,建議收藏、關注、點贊,文末提供技術交流群,
-
1、資料插補
-
2、處理例外值
-
3、分箱操作
-
4、對數轉換
-
5、獨熱編碼
-
6、分組操作
-
7、特征拆分
-
8、縮放操作
-
9、日期處理
1、資料插補
缺失值是為機器學習準備資料時可能遇到的最常見問題之一,缺少值的原因可能是人為錯誤、資料流中斷、隱私問題等,無論是什么原因,缺少值都會影響機器學習模型的性能,
一般來說,機器學習演算法不接受包含缺失值的輸入,而有一些機器學習平臺會自動洗掉包含缺失值的行,但這樣做往往會降低模型性能,
處理缺失值的最簡單方案是洗掉行或整個列,沒有最佳的洗掉閾值,但是可以使用 70% 作為閾值,并嘗試洗掉缺失值高于此閾值的行和列,
threshold = 0.7
# Dropping columns with missing value rate higher than threshold
data = data[data.columns[data.isnull().mean() < threshold]]
# Dropping rows with missing value rate higher than threshold
data = data.loc[data.isnull().mean(axis=1) < threshold]
數值插補
缺失值插補法,與缺失值洗掉法比較起來是一個更好的選擇,至少它可以保持資料的規模不變,但是,插補法需要考慮插補什么值,
首先,你可以考慮列中缺失的默認值,例如,你有一列僅有 1 和 nan,行中的 nan 可能就是 0,另一個例子,你有一個串列示上個月客戶訪問的次數,缺失值可能也是 0,
產生缺失值的另一個原因是在連接大小不同的表時格引入的,此時插補 0 也可能是個合理的做法,
除了用默認值插補缺失值外,還有一個比較有效的做法就是使用列的中位數插補缺失值,而不是平均值,因為中位數比均值更為穩健,
# Filling all missing values with 0
data = data.fillna(0)
# Filling missing values with medians of the columns
data = data.fillna(data.median())
類別插補
用列中出現次數最多的值替換缺失值是處理類別型資料時的一個不錯的選擇,但是,如果該列中的值是均勻分布的,則使用 Other 類別插補可能更加合理,
# Max fill function for categorical columns
data['column_name'].fillna(data['column_name'].value_counts().idxmax(), inplace=True)
2、處理例外值
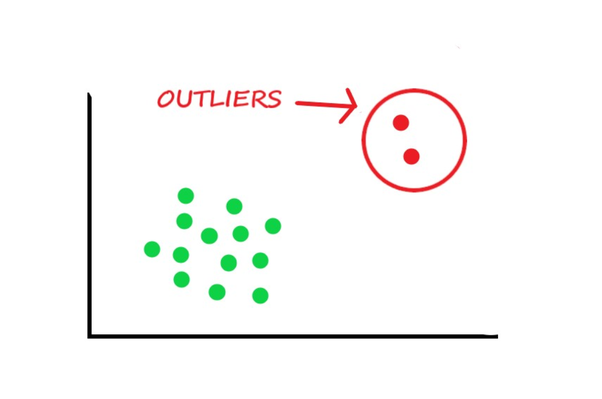
在提到如何處理例外值之前,檢測例外值的最佳方法是直觀地展示資料,所有其他統計方法都容易犯錯誤,而將例外值可視化則有機會進行高精度的決策,
正如我所提到的,統計方法不夠精確,但另一方面,它們卻具有優勢,而且速度很快,在這里,我將列出兩種處理例外值的不同方法,這些將使用標準差和百分位來檢測例外值,
基于標準差的例外值檢測
如果某個值與平均值的距離大于 標準差,則可以將其視為例外值,那么, 應該是多少呢? 取多少并沒有通用的解,但通常來說取 到 之間的值似乎是可行的,
# Dropping the outlier rows with standard deviation
factor = 3
upper_lim = data['column'].mean () + data['column'].std () * factor
lower_lim = data['column'].mean () - data['column'].std () * factor
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]
此外,可以使用 分數代替上面的公式, 分數(或標準分數)使用標準差來標準化資料與平均值之間的距離,
基于百分位的例外值檢測
檢測例外值的另一種統計方法是使用百分位,你可以從頂部或底部劃分某些區間中的值作為例外值,這再次需要設定百分比這個閾值,這取決于資料分布,
此外,一個常見的錯誤是根據資料范圍使用百分位,換句話說,如果你的資料范圍是 0 到 100,則前 5% 的值不是 96 到 100 之間的值,這里的前 5% 表示值不在資料量的第 95 個百分點之內,

# Dropping the outlier rows with Percentiles
upper_lim = data['column'].quantile(.95)
lower_lim = data['column'].quantile(.05)
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]
設限與丟棄
處理例外值的另一種方法是將其設定為上限,而不是丟棄,這樣做可以保留資料規模,并且對于最終模型性能來說可能會更好,
另一方面,設上限封頂可能會影響資料的分布,因此也不要過于吹捧它,
# Capping the outlier rows with Percentiles
upper_lim = data['column'].quantile(.95)
lower_lim = data['column'].quantile(.05)
data.loc[(df[column] > upper_lim), column] = upper_lim
data.loc[(df[column] < lower_lim), column] = lower_lim
3、分箱
分箱可以應用于類別型資料和數值型資料,
# Numerical Binning Example
Value Bin
0-30 -> Low
31-70 -> Mid
71-100 -> High
# Categorical Binning Example
Value Bin
Spain -> Europe
Italy -> Europe
Chile -> South America
Brazil -> South America
分箱的主要動機是使模型更加健壯并防止過擬合,但同時也會降低性能,每次分箱不僅會犧牲資訊,也會使得資料更加規范化,
性能與過擬合之間的權衡是分箱程序的關鍵,
-
對于數值型特征,除了一些明顯的過擬合的情況外,分箱對于某種演算法可能是多余的,因為它對模型性能有影響,
-
然而,對于類別型特征,低頻標簽可能會對統計模型的魯棒性產生負面影響,因此,為這些不太頻繁的值分配一般類別有助于保持模型的魯棒性,例如,資料大小為 100,000 行,則將計數少于 100 的標簽合并到
Other之類的新類別可能是一個不錯的選擇,
# Numerical Binning Example
data['bin'] = pd.cut(data['value'], bins=[0,30,70,100], labels=["Low", "Mid", "High"])
value bin
0 2 Low
1 45 Mid
2 7 Low
3 85 High
4 28 Low
# Categorical Binning Example
Country
0 Spain
1 Chile
2 Australia
3 Italy
4 Brazil
conditions = [
data['Country'].str.contains('Spain'),
data['Country'].str.contains('Italy'),
data['Country'].str.contains('Chile'),
data['Country'].str.contains('Brazil')]
choices = ['Europe', 'Europe', 'South America', 'South America']
data['Continent'] = np.select(conditions, choices, default='Other')
Country Continent
0 Spain Europe
1 Chile South America
2 Australia Other
3 Italy Europe
4 Brazil South America
4、Log 對數變換
對數變換是特征工程中最常用的數學變換之一,它的好處有,
-
它有助于處理偏度不為 0 的資料,并且在轉換后,分布變得更接近正態分布,
-
在大多數情況下,資料的數量級在不同范圍內是不同的,例如,年齡 15 和 20 之間的數量差異并不等于年齡 65 和 70 之間的數量差異,就年份而言,是的,它們是相同的,但是對于其他方面,年輕年齡的 5 年差異意味著更高的數量差異,這種型別的資料來自乘性程序,對數變換將起到規范化(normalize)數量差異的作用,
-
由于數量差異的歸一化,模型變得更加健壯,因此它也減少了例外值的影響,
需要注意的是,你要應用對數變換的資料必須是正值,否則會出現錯誤,另外,可以在轉換資料之前將 1 加到資料中,用于確保變換后的輸出值也是正的,
Log(x+1)
# Log Transform Example
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['log+1'] = (data['value']+1).transform(np.log)
# Negative Values Handling
# Note that the values are different
data['log'] = (data['value']-data['value'].min()+1) .transform(np.log)
value log(x+1) log(x-min(x)+1)
0 2 1.09861 3.25810
1 45 3.82864 4.23411
2 -23 nan 0.00000
3 85 4.45435 4.69135
4 28 3.36730 3.95124
5 2 1.09861 3.25810
6 35 3.58352 4.07754
7 -12 nan 2.48491
5、獨熱編碼
獨熱編碼是機器學習中最常見的編碼方法之一,此方法將一列中的值分布到多個標記列,并為其分配 0 或 1,這些二進制值表示類別和編碼之間的關系,
該方法將演算法難以正確理解的分型別資料更改為數值格式,并使你可以在不丟失任何資訊的情況下對類別資料進行分組,
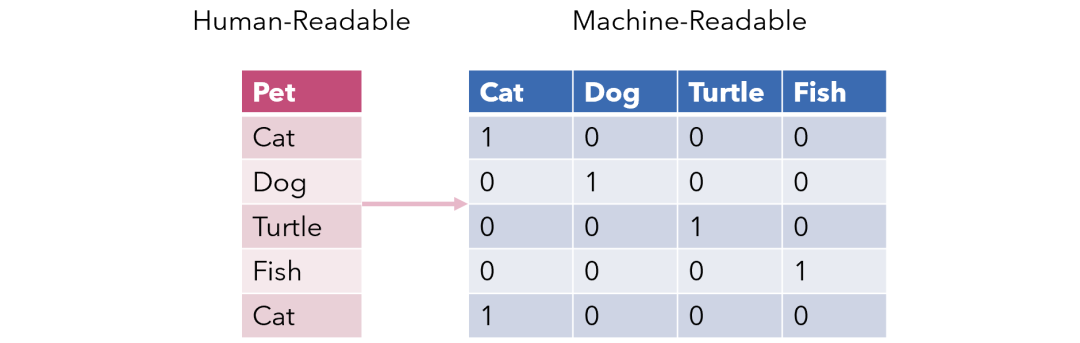
Why 獨熱編碼?
如果該列中有 N 個不同的值,則將它們映射到 N-1 個二進制列就足夠了,因為可以從其他列中扣除該缺失值,如果我們手中的所有列都等于 0,則缺失值必須等于 1,這就是為什么將其稱為獨熱編碼的原因,但是,我將使用 Pandas 的 get_dummies 函式給出一個示例,此函式將一列映射到多個列,
encoded_columns = pd.get_dummies(data['column'])
data = data.join(encoded_columns).drop('column', axis=1)
6、分組操作
在大多數機器學習演算法中,每個實體對應訓練資料集中的一行,而不同列對應不同特征,這種形式的資料稱為整齊(tidy)資料,
整齊資料集易于操作、建模和可視化,并具有特定的結構: 每個變數是一列,每個觀察值是一行,每種型別的觀察單位是表格,
諸如涉及事務處理之類的資料集由于一個實體對應多行資料而很少適合整齊資料的定義,在這種情況下,我們按實體對資料進行分組,然后每個實體僅由一行代表,
按操作分組的關鍵是確定特征的聚合函式,對于數值型特征,平均值和求和函式通常是不錯的選擇,而對于分型別特征,則較為復雜,
分類特征分組
建議使用三種不同的方式來聚合分類特征:
- 第一種是選擇頻率最高的標簽,換句話說,這是分類特征的 max 操作,但是普通的 max 函式通常不回傳此值,因此你需要自己定義,例如使用 lambda 函式,
data.groupby('id').agg(lambda x: x.value_counts().index[0])
- 第二種選擇是制作資料透視表(pivot table),這種方法與上一步驟中的編碼方法類似,略有不同,代替二值符號,可以將其定義為分組列和編碼列之間的值的聚合函式,如果你打算超越二值標記列并將多重特征合并為更有用的聚合特征,那么這將是一個不錯的選擇,(該方法與 Pandas 中另一個函式 groupby 作用類似,可以結合下圖例子來理解這一點,)
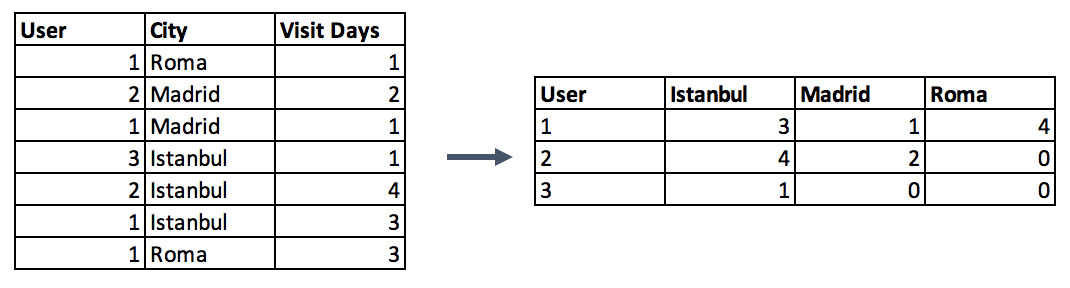
# Pivot table Pandas Example
data.pivot_table(index='column_to_group', columns='column_to_encode', values='aggregation_column', aggfunc=np.sum, fill_value = 0)
- 最后一種分類特征分組方案是在應用獨熱編碼后應用分組函式
group by,此方法將保留所有資料(在上面第一種方案中,會丟失一些資料),與此同時,還將編碼列從分類轉換為數值,可以閱讀下一部分以了解數值特征分組的說明,
數值特征分組
在大多數情況下,數值特征使用求和以及均值函式分組,根據特征的含義,兩者都是可取的,例如,如果要獲取比率列,則可以取二值列的平均值,在同一示例中,sum 函式可用于獲得總數,
# sum_cols: List of columns to sum
# mean_cols: List of columns to average
grouped = data.groupby('column_to_group')
sums = grouped[sum_cols].sum().add_suffix('_sum')
avgs = grouped[mean_cols].mean().add_suffix('_avg')
new_df = pd.concat([sums, avgs], axis=1)
7、特征拆分
拆分特征是使它們在機器學習中發揮作用的好辦法,很多時候,資料集包含一些字串列,這就違反了整齊資料的原則,通過將列的可用部分提取成新特征,有利于
-
讓機器學習演算法能夠理解它們,
-
可以將它們分箱和分組,
-
通過發掘潛在資訊來提高模型性能,
split 函式是一個不錯的選擇,但是,沒有一種適用于拆分所有特征的通用方法,它取決于列的特性以及如何拆分它,讓我們通過兩個示例對其進行介紹,
首先,一個可用于拆分普通名字列的簡單 split 函式,
data.name
0 Luther N. Gonzalez
1 Charles M. Young
2 Terry Lawson
3 Kristen White
4 Thomas Logsdon
# Extracting first names
data.name.str.split(" ").map(lambda x: x[0])
0 Luther
1 Charles
2 Terry
3 Kristen
4 Thomas
# Extracting last names
data.name.str.split(" ").map(lambda x: x[-1])
0 Gonzalez
1 Young
2 Lawson
3 White
4 Logsdon
上面的示例通過僅使用第一個和最后一個詞來處理長度超過兩個單詞的名字,這使該函式在遇到極端情況時具有魯棒性,在處理此類字串時應考慮到這一方法,
split 函式的另一個使用場景是提取兩個字符之間的字串部分,以下示例顯示了通過在一行代碼中連續使用兩個 split 函式來實作此情況的方法,
# String extraction example
data.title.head()
0 Toy Story (1995)
1 Jumanji (1995)
2 Grumpier Old Men (1995)
3 Waiting to Exhale (1995)
4 Father of the Bride Part II (1995)
data.title.str.split("(", n=1, expand=True)[1].str.split(")", n=1, expand=True)[0]
0 1995
1 1995
2 1995
3 1995
4 1995
8、縮放
在大多數情況下,資料集的數值特征沒有特定范圍,并且彼此不同,在實際中,如果要求年齡列和收入列具有相同的數值范圍肯定會讓人覺得沒道理,但是如果站在機器學習的角度來看的話,該如何比較這兩個數值特征呢?
縮放解決了這個問題,經過縮放程序后,連續特征的范圍變得相同,對于許多演算法來說,此程序不是強制性的,但應用起來效果可能很好,但是,基于距離計算的演算法(例如 k-NN 或 k-Means)需要具有可縮放的連續特征作為模型輸入,
有兩種基本的資料縮放方式,
歸一化
歸一化(或 min-max 歸一化)在 0 到 1 之間的固定范圍內縮放所有值,
此變換不會更改特征的分布,并且由于標準差降低,例外值的影響會增加,因此,建議在該歸一化之前處理例外值,
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['normalized'] = (data['value'] - data['value'].min()) / (data['value'].max() - data['value'].min())
value normalized
0 2 0.23
1 45 0.63
2 -23 0.00
3 85 1.00
4 28 0.47
5 2 0.23
6 35 0.54
7 -12 0.10
標準化
標準化(或 z-分數規范化)在考慮標準差的同時縮放特征值,如果特征的標準差不同,則它們的范圍也將彼此不同,這減少了特征中例外值的影響,
在以下標準化公式中, 是平均值,而 是標準差,
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['standardized'] = (data['value'] - data['value'].mean()) / data['value'].std()
value standardized
0 2 -0.52
1 45 0.70
2 -23 -1.23
3 85 1.84
4 28 0.22
5 2 -0.52
6 35 0.42
7 -12 -0.92
9、提取日期
盡管日期列通常給有關模型目標值提供了很多有用資訊,但它們在機器學習學習中往往被忽略,日期可以以多種格式顯示,這使得演算法很難理解,即使將日期簡化為 01-01-2017 之類的格式也是如此,
如果不處理日期列,那么在這些值之間建立序數關系對于機器學習演算法來說是非常具有挑戰性的,在這里,建議對日期進行三種預處理,
-
將日期部分提取到不同的列中: 年、月、日等,
-
根據年、月、日等提取當前日期和這些列之間的時間差,
-
從日期中提取一些特定特征: 作業日的名稱,是否周末、是否休假等,
如果將日期列按上述方法提取出新的列,則它們的資訊將會被更合理地表達出來,并且機器學習演算法可以輕松地理解它們,
from datetime import date
data = pd.DataFrame({'date':
['01-01-2017',
'04-12-2008',
'23-06-1988',
'25-08-1999',
'20-02-1993',
]})
# Transform string to date
data['date'] = pd.to_datetime(data.date, format="%d-%m-%Y")
# Extracting Year
data['year'] = data['date'].dt.year
# Extracting Month
data['month'] = data['date'].dt.month
# Extracting passed years since the date
data['passed_years'] = date.today().year - data['date'].dt.year
# Extracting passed months since the date
data['passed_months'] = (date.today().year - data['date'].dt.year) * 12 + date.today().month - data['date'].dt.month
# Extracting the weekday name of the date
data['day_name'] = data['date'].dt.day_name()
date year month passed_years passed_months day_name
0 2017-01-01 2017 1 2 26 Sunday
1 2008-12-04 2008 12 11 123 Thursday
2 1988-06-23 1988 6 31 369 Thursday
3 1999-08-25 1999 8 20 235 Wednesday
4 1993-02-20 1993 2 26 313 Saturday

推薦文章
- 上癮了,最近又給公司擼了一個可視化大屏(附原始碼)
- 如此優雅,4款 Python 自動資料分析神器真香啊
- 梳理半月有余,精心準備了17張知識思維導圖,這次要講清統計學
- 年侄訓總:20份可視化大屏模板,直接套用真香(文末附原始碼)
技術交流
歡迎轉載、收藏、有所識訓點贊支持一下!

目前開通了技術交流群,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友
- 方式①、發送如下圖片至微信,長按識別,后臺回復:加群;
- 方式②、添加微信號:dkl88191,備注:來自CSDN
- 方式③、微信搜索公眾號:Python學習與資料挖掘,后臺回復:加群

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423169.html
標籤:AI
上一篇:[Python從零到壹] 三十九.影像處理基礎篇之影像幾何變換(鏡像仿射透視)
下一篇:協同過濾推薦演算法