一、協同過濾思想簡介
二、協同過濾演算法原理介紹
三、基于用戶的協同過濾演算法描述
四、基于物品的協同過濾演算法
基于物品的協同過濾演算法的優缺點

一、協同過濾思想簡介
協同過濾,從字面上理解,包括協同和過濾兩個操作,首先我們在外出和朋友吃飯的時候肯定會問身邊的朋友哪些飯店味道比較好,看看最近有什么美食推薦,而我們一般更傾向于從口味比較類似的朋友那里得到推薦,這就是協同過濾的核心思想,
所謂協同就是利用群體的行為來做決策(推薦),生物上有協同進化的說法,通過協同的作用,讓群體逐步進化到更佳的狀態,對于推薦系統來說,通過用戶的持續協同作用,最終給用戶的推薦會越來越準,而過濾,就是從可行的決策方案中將用戶喜歡的方案找出來,協同過濾就是對從群體的行為中來尋找存在的普遍相似性,通過相似性來對用戶做出決策和推薦,
協同過濾利用了兩個非常樸素的自然哲學思想:“群體的智慧”和“相似的物體具備相似的性質”,群體的智慧從數學上講應該滿足一定的統計學規律,是一種朝向平衡穩定態發展的動態程序,越相似的物體化學及物理組成越一致,當然表現的外在特性會更相似,雖然這兩個思想很簡單,也很容易理解,但是正因為思想很樸素,價值反而非常大,所以協同過濾演算法原理很簡單,但是效果很不錯,而且也非常容易實作,
協同過濾推薦演算法分為兩類,分別是基于用戶的協同過濾演算法(user-based collaboratIve filtering),和基于物品的協同過濾演算法(item-based collaborative filtering),
二、協同過濾演算法原理介紹
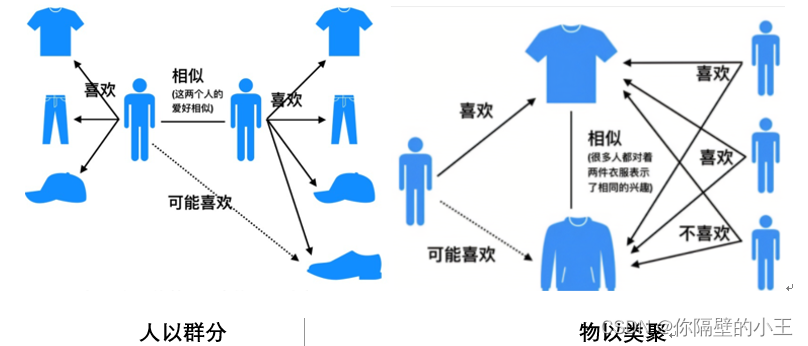
簡單的說就是:物以類聚,人以群分,所謂物以類聚,就是計算出每個物品最相似的物品串列,可以為用戶推薦相似的物品,所謂人以群分,就是我們可以將與該用戶相似的用戶喜歡過的物品推薦給該用戶,
三、基于用戶的協同過濾演算法描述
基于用戶的協同過濾演算法的實作主要分為兩個步驟:
- 1)如何找到和你有相似愛好的人,也就是要計算資料的相似度:
- 2)通過相似愛好的人來推薦商品
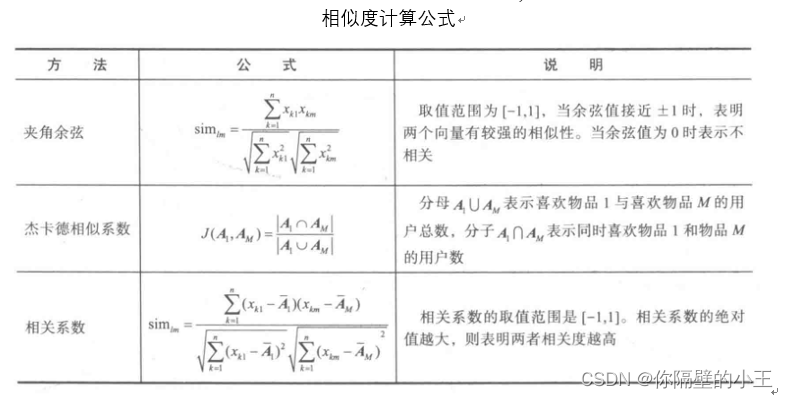
計算相似度需要根據資料特點的不同選擇不同的相似度計算方法,有幾個常用的計算方法:
我們在尋找有有相同愛好的人的時候,可能會找到許多個,例如幾百個人都喜歡A商品,但是這幾百個人里,可能還有幾十個人與你同時還喜歡B商品,他們的相似度就更高,我們通常設定一個數K,取計算相似度最高的K個人稱為最相鄰的K個用戶,作為推薦的來源群體,
這里存在一個小問題,就是當用戶資料量十分巨大的時候,在所有人之中找到K個基友花的時間可能會比較長,而且實際中大部分的用戶是和你沒有什么關系的,所以在這里需要用到反查表
所謂反查表,就是比如你喜歡的商品有A、B、C,那就分別以ABC為行名,列出喜歡這些商品的人都有哪些,其他的人就必定與你沒有什么相似度了,從這些人里計算相似度,找到K個人
通過這K個人推薦商品
| 你 | A | B | C | D |
| X(相似度30%) | √ | √ | √ | |
| Y(相似度40%) | √ | √ |
我們假設找到的人的喜好程度如下,那么對于產品ABCD,推薦度可以計算為:
- A:1*0.3=0.3
- B:1*0.3=0.3
- C:1*0.4=0.4
- D:1*0.3+1*0.4=0.7
很明顯,我們首先會推薦D商品,其次是C商品,再后是其余商品
當然我們也可以采用其他的推薦度計算方法,但是我們一定會使用得到的相似度0.3和0.4,也即一定是進行加權的計算,
基于用戶的協同推薦演算法的步驟可以總結為:
1.計算其他用戶的相似度,可以使用反查表除掉一部分用戶
2.根據相似度找到最相似的K個用戶
3.在這些鄰居喜歡的物品中,根據與你的相似度算出每一件物品的推薦度
4.根據相似度推薦物品
四、基于物品的協同過濾演算法(item-based collaborative filtering)
基于物品的協同過濾演算法(簡稱ItemCF 演算法)主要分為2個步驟:
- 1)計算物品之間的相似度;
- 2)根據物品的相似度和用戶的歷史行為給用戶生成推薦串列;
其中,關于物品相似度計算的方法有夾角余弦、杰卡德(Jaccard)相似系數和相關系數等,
將用戶對某一產品的喜好或者評分作為一個向量,例如用戶對產品1的評分為
![]()
,對產品m的評分或者喜好程度為
![]()
其中m為物品,n為用戶數
計算各個物品之間的相似度之后,即可構成一個物品之間的相似度矩陣,通過相似度矩陣,推薦演算法會給用戶推薦與其物品最相似的K個物品,推薦系統是根據物品的相似度以及用戶的歷史行為對用戶的興趣度進行預測并推薦的,在評價模型的時候一般是將資料集劃分成訓練集和測驗集兩部分,模型通過在訓練集的資料上進行訓練學習得到推薦模型,然后在測驗集資料上進行模型預測,最終統計出相應的評測指標來評價模型預測效果的好與壞,
模型的評測采用的方法是交叉驗證法,交叉驗證法即將用戶行為資料集按照均勻分布隨機分成M份,挑選一份作為測驗集,將剩下的M-1份作為訓練集,然后在訓練集上建立模型,并在測驗集上對用戶行為進行預測,統計出相應的評測指標,為了保證評測指標并不是過擬合的結果,需要進行M次實驗,并且每次都使用不同的測驗集,最后將M次實驗測出的評測指標的平均值作為最終的評測指標,
基于用戶的協同過濾推薦演算法進行推薦,構建模型的流程如下圖所示:
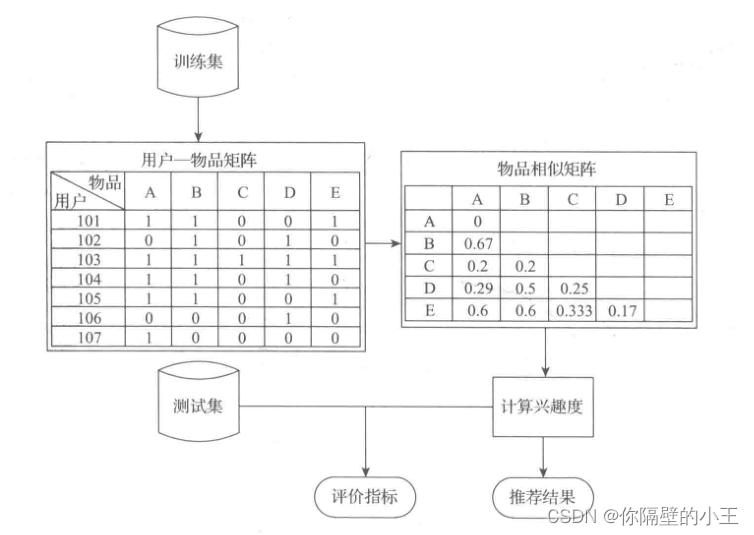
訓練集與測驗集是通過交叉驗證的方法劃分后的資料集,通過協同過濾演算法的原理可知,在建立推薦系統時,建模的資料量越大越能消除資料中的隨機性,得到的模型準確度也就越高,但是隨之而來也會導致計算時長過長,
基于物品的協同過濾演算法的優缺點
優點:
- 可以離線完成相似性步驟,降低了在線計算量,提高了推薦效率,可以利用用戶的歷史行為給用戶做出推薦解釋,結果容易讓客戶信服
缺點:
- 現有的協同過濾演算法沒有充分利用到用戶間的差別,使計算得到的相似度不夠準確,導致影響了推薦精度;此外,用戶的興趣是隨著時間不斷變化的,演算法可能對用戶新點擊興趣的敏感性較低,缺少一定的實時推薦,從而影響了推薦質量,
- 基于物品的協同過濾適用于物品數明顯小于用戶數的情形,如果物品數很多,會導致計算物品相似度矩陣代價巨大,
- 不積跬步,無以至千里

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423170.html
標籤:AI
下一篇:機器學習分類演算法之樸素貝葉斯