目錄
樸素貝葉斯
背景介紹
概念及原理
貝葉斯演算法
貝葉斯分類器
樸素貝葉斯應用場景
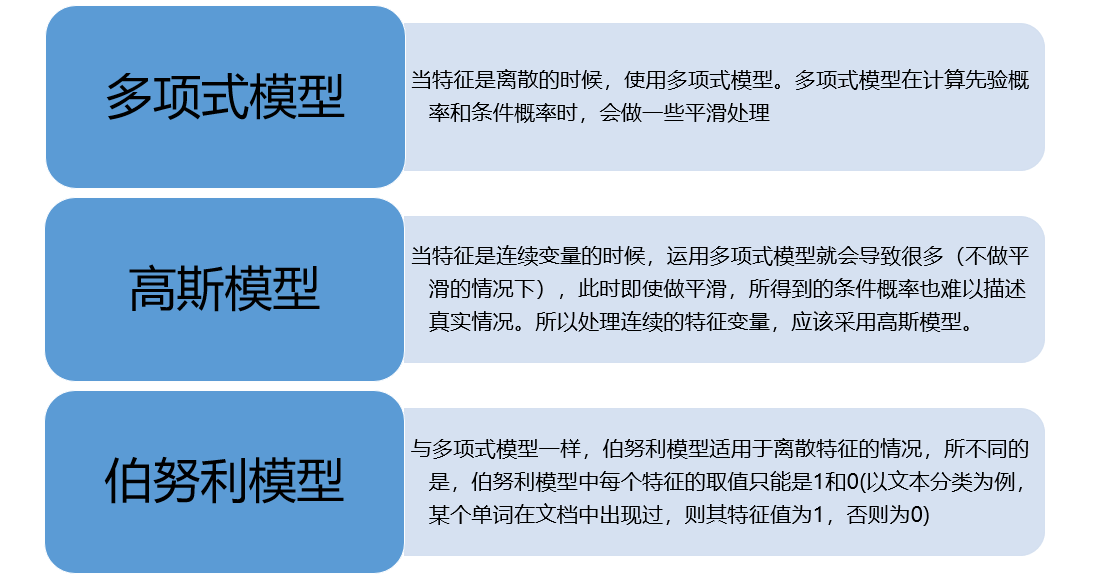
多項式貝葉斯
代碼實作
高斯貝葉斯
其他模型嘗試
優點缺點、引數總結
每文一語
樸素貝葉斯
背景介紹
20世紀80年代發展起來,最早由Judea Pearl于1986年提出,多用于專家系統,是處理不確定性
知識和推理問題的最流行的方法,

貝葉斯演算法基于貝葉斯統計分析的數學原理,是概率論和圖論相結合的產物,
樸素貝葉斯模型的泛化能力要比線性分類器(如LogisticRegression 和 LinearSVC)稍差,
樸素貝葉斯模型如此高效的原因在于,它通過單獨查看每個特征來學習引數,并從每個特征中收集簡單的類別統計資料,
scikit-learn 中實作了三種樸素貝葉斯分類器:GaussianNB、 BernoulliNB 和 MultinomialNB, GaussianNB 可 應 用 于 任 意 連 續 數 據, 而BernoulliNB 假定輸入資料為二分類資料, MultinomialNB 假定輸入資料為計數資料(即每個特征代表某個物件的整數計數,比如一個單詞在句子里出現的次數), BernoulliNB 和MultinomialNB 主要用于文本資料分類,
概念及原理
頻率 & 概率
頻率:是指事件發生的頻繁程度,嚴格定義是:在相同的條件下,進行n次試驗,事件A發生的次數a稱為事件A的頻數,比值a/n 稱為事件A發生的頻率,
概率:是指某事件出現的可能性大小,嚴格定義是:設E是隨機試驗(一定是要隨機的),S是樣本空間(說白了就是可能出現的每種情況),對于E的每一個事件A賦予一個實數,記作P(A),稱為事件A的概率,如果集合函式P(·)滿足以下條件:
1.非負性:P(A)≥0;
2.規范性:對必然事件S,有P(S)=1
3.可列可加性:對于兩兩互不相容事件,或事件的概率=各單獨事件的概率之和
先驗概率 & 后驗概率 & 條件概率
先驗概率:事件發生前的預判概率,可以是基于歷史資料的統計,可以由背景常識得出,也可以是人的主觀觀點給出,一般都是單獨事件概率,如P(x),P(y),
條件概率:一個事件發生后另一個事件發生的概率,一般的形式為P(x|y)表示y發生的條件下x發生的概率,
后驗概率:結果發生后反推事件發生原因的概率;或者說,基于先驗概率求得的反向條件概率,概率形式與條件概率相同,
感覺又回到了大學里面的概率論與數理統計的課程,其實基本的思想就是如此
貝葉斯公式
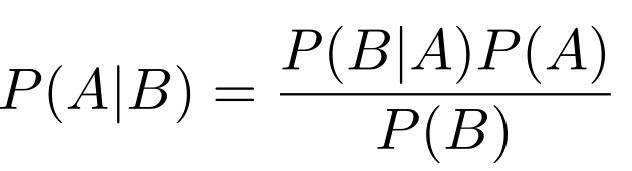
P(A|B)表示在B發生的條件下A發生的概率是多少?
全概率公式

貝葉斯公式的意義
案例:
某地區居民肝癌的發病率為0.0004,現用甲胎蛋白法進行普查,醫學研究表明,化驗結果是有錯檢的可能性,已知患有肝癌的人其化驗結果99%呈陽性(有病),而沒患肝癌的人其化驗結果99.9%呈陰性(無病),
現某人的檢查結果呈陽性,問他真正得肝癌的概率有多大?
解答:
設A=“結果檢查呈陽性”,B=“被檢查患者確實有肝癌”,已知P(B)=0.0004, P(B-)=0.9996 , P(A|B)=0.99,P(A|B-)=0.001.由貝葉斯公式可得到:
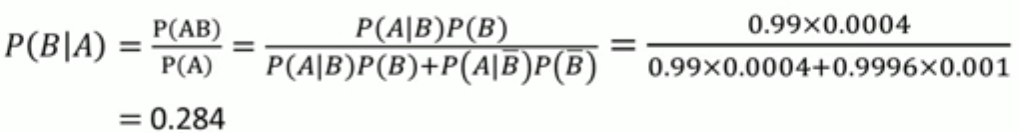
復檢能夠大大提高化驗的準確率
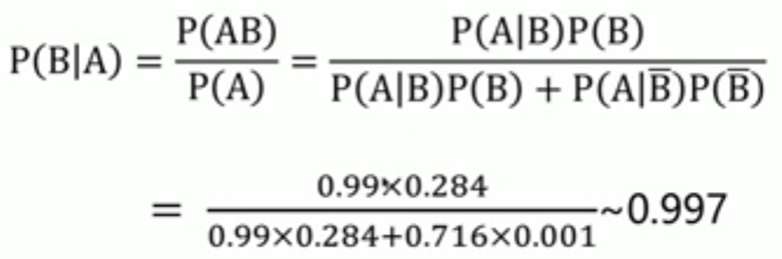
如果某人首次化驗,成果呈陽性,第二次復檢,仍然呈陽性,請問該患者患肝癌的概率有多大?
首次檢查呈陽性的患者,他的P(B)=0.284,復檢仍然呈陽性,則患肝癌的概率為:
貝葉斯演算法
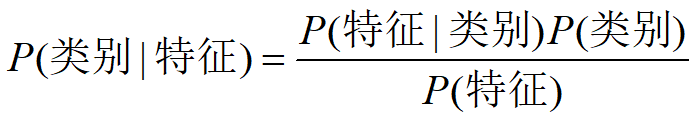
樸素貝葉斯( Naive Bayes)模型是一種基于概率的學習方法
“樸素”不是指艱苦樸素的“樸素”,是指假設每個屬性條件都是相互獨立的,沒有相關性
經典案例
現在給我們的問題是,如果一對男女朋友,男生想女生求婚,男生的四個特點分別是不帥,性格不好,身高矮,不上進,請你判斷一下女生是嫁還是不嫁?
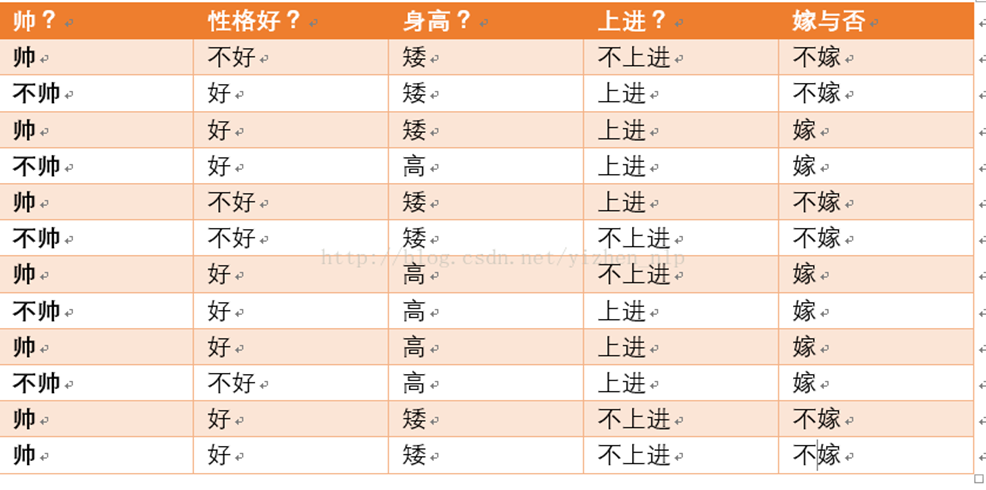
看到上述規則的男同胞們,及時你被上帝關上了一扇窗,那你也可以自己撬開一扇門
樸素貝葉斯案例
這是一個典型的分類問題
數學問題就是比較
p(嫁|(不帥、性格不好、身高矮、不上進))
p(不嫁|(不帥、性格不好、身高矮、不上進))
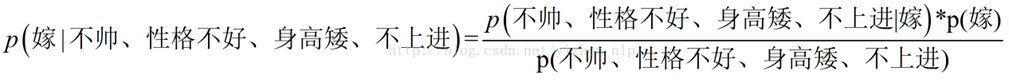

下面我將一個一個的進行統計計算(在資料量很大的時候,中心極限定理,頻率是等于概率的)
p(嫁)=?
首先我們整理訓練資料中,嫁的樣本數如下:則 p(嫁) = 6/12(總樣本數) = 1/2
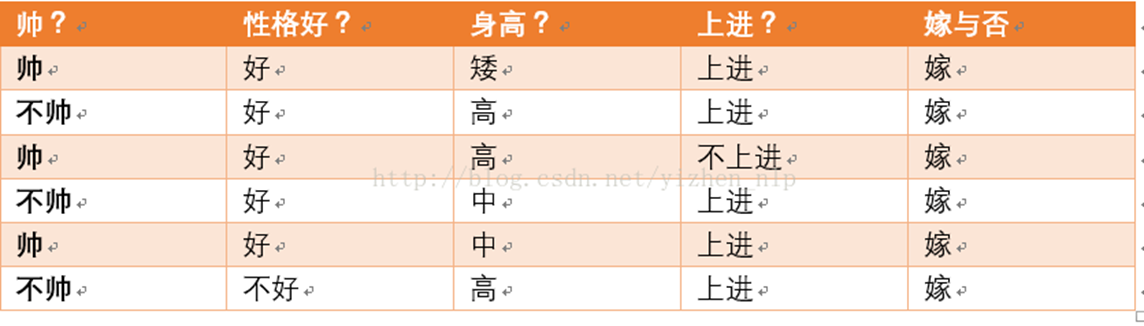
則 p(嫁) = 6/12(總樣本數) = 1/2
p(不帥|嫁)=?統計滿足樣本數如下

則p(不帥|嫁) = 3/6 = 1/2 在嫁的條件下,看不帥有多少
帶入其他統計量

= (1/2*1/6*1/6*1/6*1/2)/(5/12*1/3*7/12*5/12)
貝葉斯分類器
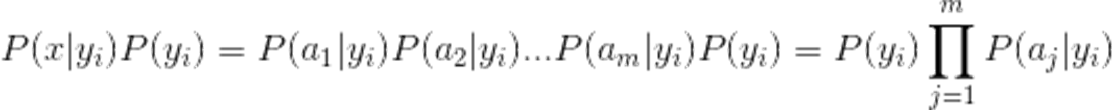
分母對于所有類別為常數,我們只要將分子最大化皆可,又因為各特征屬性是條件獨立的,所以有:
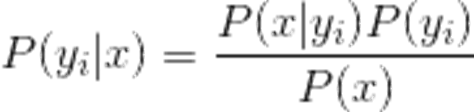
1、設x={a1,a2,a3,......am}為一個待分類項,而每個a為x的一個特征屬性,
2、有類別集合C={y1,y2,......yn},
3、計算P(y1|x),P(y2|x),......,P(yn|x),,
4、如果,P(yk|x)=max{P(y1|x),P(y2|x),......,P(yn|x)},則x屬于yk,
常見的三種貝葉斯模型
樸素貝葉斯應用場景
在文本分類中,假設我們有一個檔案d∈X,X是檔案向量空間(document space),和一個固定的類集合C={c1,c2,…,cj},類別又稱為標簽,
顯然,檔案向量空間是一個高維度空間,我們把一堆打了標簽的檔案集合<d,c>作為訓練樣本,<d,c>∈X×C,例如:<d,c>={Beijing joins the World Trade Organization, China}
對于這個只有一句話的檔案,我們把它歸類到 China,即打上china標簽,我們期望用某種訓練演算法,訓練出一個函式γ,能夠將檔案映射到某一個類別:γ:X→C
多項式貝葉斯
在多項式模型中, 設某檔案d=(t1,t2,…,tk),tk是該檔案中出現過的單詞,允許重復,則
先驗概率P(c)= 類c下單詞總數/整個訓練樣本的單詞總數
類條件概率P(tk|c)=(類c下單詞tk在各個檔案中出現過的次數之和+1)/(類c下單詞總數+|V|)
V是訓練樣本的單詞表(即抽取單詞,單詞出現多次,只算一個),|V|則表示訓練樣本包含多少種單詞,在這里,m=|V|, p=1/|V|,
P(tk|c)可以看作是單詞tk在證明d屬于類c上提供了多大的證據,而P(c)則可以認為是類別c在整體上占多大比例(有多大可能性),
伯努利模型
伯努利模型跟多項式模型的差別在計算公式不同:
P(c)= 類c下檔案總數/整個訓練樣本的檔案總數
P(tk|c)=(類c下包含單詞tk的檔案數+1)/(類c的檔案總數+2)
二者的計算粒度不一樣,多項式模型以單詞為粒度,伯努利模型以檔案為粒度,因此二者的先驗概率和類條件概率的計算方法都不同,
計算后驗概率時,對于一個檔案d,多項式模型中,只有在d中出現過的單詞,才會參與后驗概率計算,伯努利模型中,沒有在d中出現,但是在全域單詞表中出現的單詞,也會參與計算,不過是作為“反方”參與的,
高斯模型
有些特征可能是連續型變數,比如說人的身高,物體的長度,這些特征如果使用決策樹那些模型,可以轉換成離散型的值,比如如果身高在160cm以下,特征值為1;在160cm和170cm之間,特征值為2;在170cm之上,特征值為3,也可以這樣轉換,將身高轉換為3個特征,分別是f1、f2、f3,如果身高是160cm以下,這三個特征的值分別是1、0、0,若身高在170cm之上,這三個特征的值分別是0、0、1,
不過這些方式都不夠細膩,高斯模型可以解決這個問題,高斯模型假設這些一個特征的所有屬于某個類別的觀測值符合高斯分布:
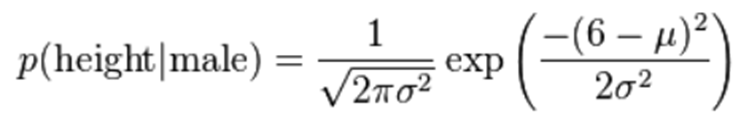
μ:獲取各個類標記在各個特征上的均值
σ:獲取各個類標記在各個特征上的方差
代碼實作

高斯貝葉斯
# 加載模型
model = GaussianNB()
# 訓練模型
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
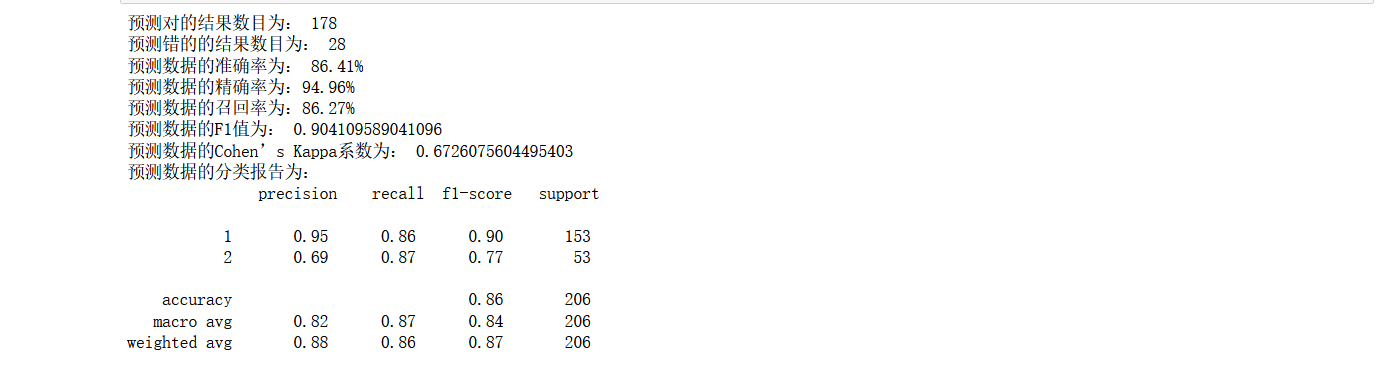
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
from sklearn.metrics import classification_report
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))

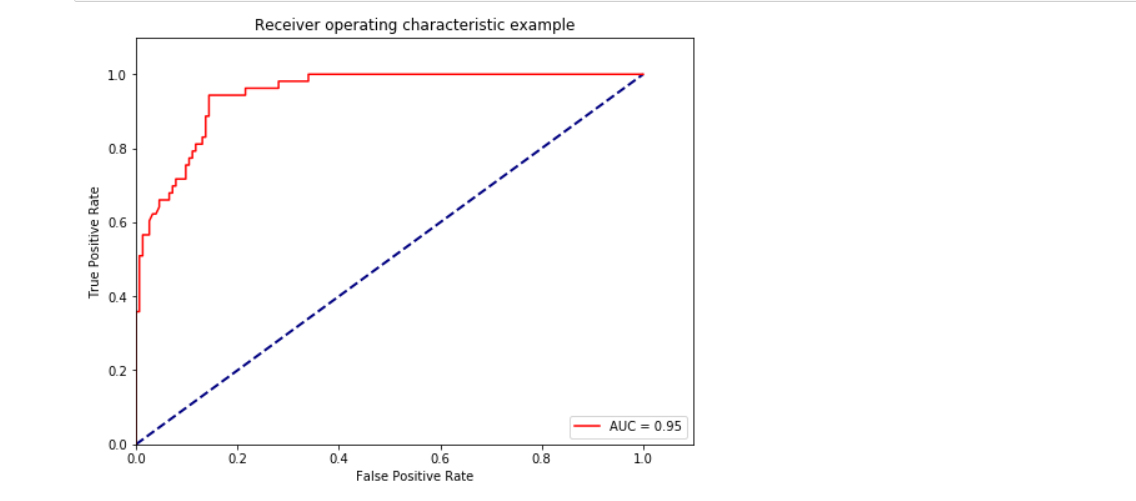
ROC曲線和AUC面積
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show() 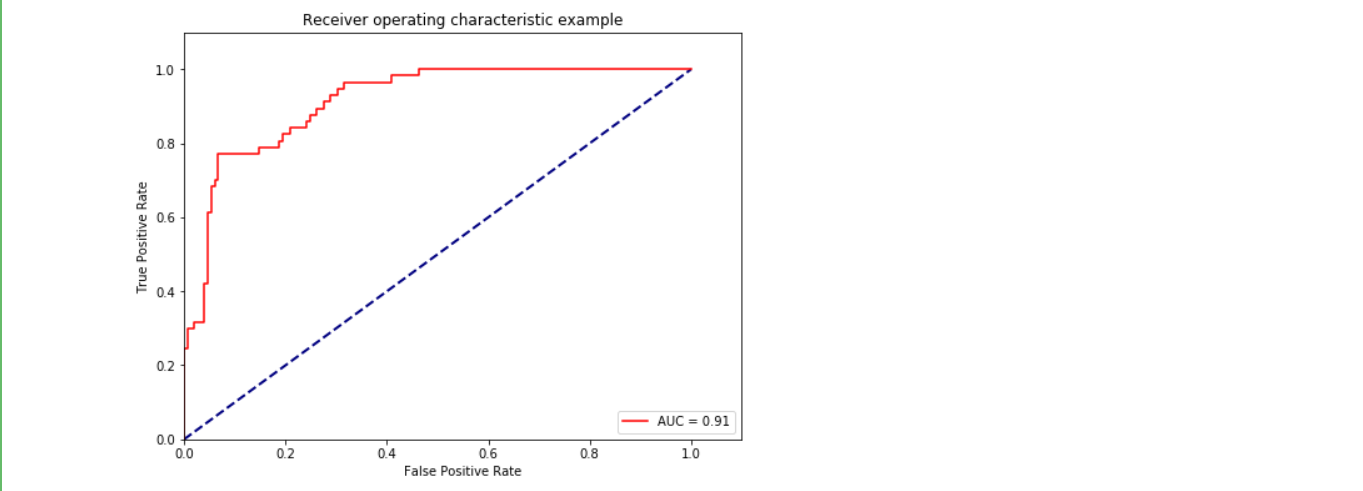
對于高斯貝葉斯模型的引數,一般是不需要進行調參的,使用該模型一般在資料集以及特征方面進行改進
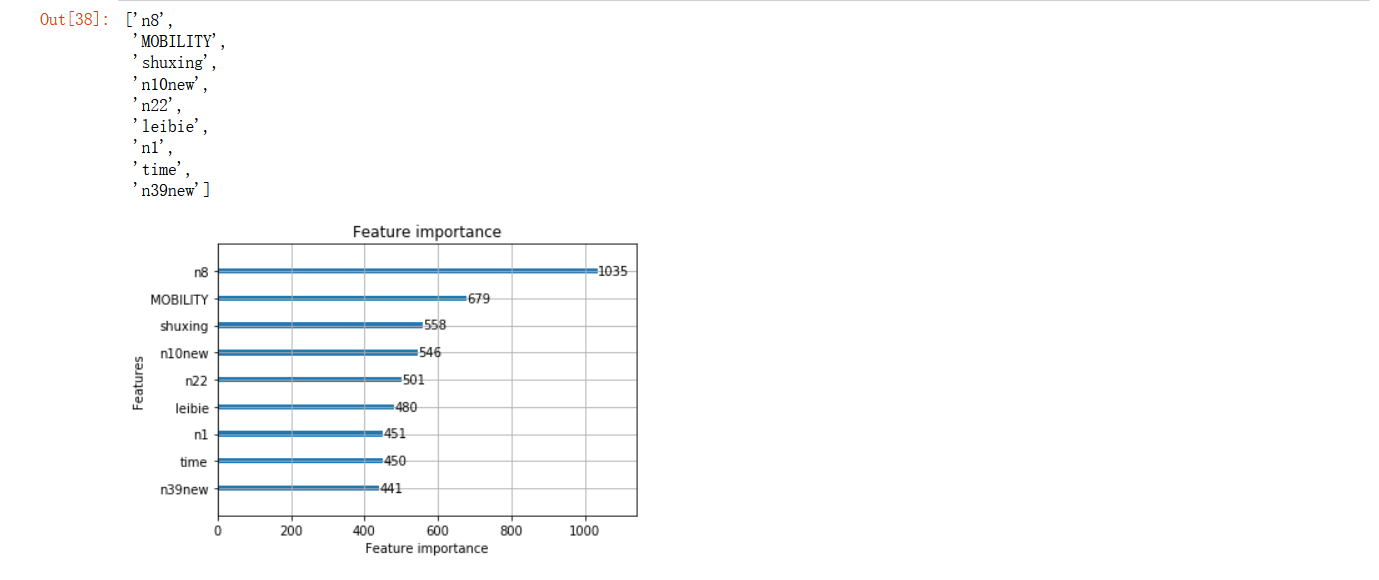
通過模型進行選擇重要的特征:9個,用于預測
from sklearn.model_selection import train_test_split,cross_val_score #拆分訓練集和測驗集
import lightgbm as lgbm #輕量級的高效梯度提升樹
X_name=df.corr()[["n23"]].sort_values(by="n23",ascending=False).iloc[1:].index.values.astype("U")
X=df.loc[:,X_name.tolist()]
y=df.loc[:,['n23']]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
lgbm_reg = lgbm.LGBMRegressor(objective='regression',max_depth=6,num_leaves=25,learning_rate=0.005,n_estimators=1000,min_child_samples=80, subsample=0.8,colsample_bytree=1,reg_alpha=0,reg_lambda=0)
lgbm_reg.fit(X_train, y_train)
#選擇最重要的20個特征,繪制他們的重要性排序圖
lgbm.plot_importance(lgbm_reg, max_num_features=9)
##也可以不使用自帶的plot_importance函式,手動獲取特征重要性和特征名,然后繪圖
feature_weight = lgbm_reg.feature_importances_
feature_name = lgbm_reg.feature_name_
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
# plt.figure(figsize=(10,8))
# sns.barplot(feature_sort.values,feature_sort.index, orient='h')
lgbm_name=feature_sort.index[:9].tolist()
lgbm_nameX=df.loc[:,lgbm_name]
y=df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
# 加載模型
model = GaussianNB()
# 訓練模型
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
from sklearn.metrics import classification_report
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show()結果展示:
果不其然,通過了特征選取的方式,模型的效果有了一定的改善,這里你也可以結合之前的博客文章:
機器學習框架及評估指標詳解
特征選取之單變數統計、基于模型選擇、迭代選擇
將所有的指標都可以進行探究最后通過特征選取等方法,去增加模型的指標
其他模型嘗試
多項式貝葉斯
適用于服從多項分布的特征資料
class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
alpha:先驗平滑因子,默認等于1,當等于1時表示拉普拉斯平滑,fit_prior:是否去學習類的先驗概率,默認是Trueclass_prior:各個類別的先驗概率,如果沒有指定,則模型會根據資料自動學習, 每個類別的先驗概率相同,等于類標記總個數N分之一,
class_log_prior_:每個類別平滑后的先驗概率
intercept_:是樸素貝葉斯對應的線性模型,其值和class_log_prior_相同
feature_log_prob_:給定特征類別的對數概率(條件概率), 特征的條件概率=(指定類下指定特征出現的次數+alpha)/(指定類下所有特征出現次數之和+類的可能取值個數*alpha)
coef_: 是樸素貝葉斯對應的線性模型,其值和feature_log_prob相同
class_count_: 訓練樣本中各類別對應的樣本數
feature_count_: 每個類別中各個特征出現的次數
伯努利樸素貝葉斯
用于多重伯努利分布的資料,即有多個特征,但每個特征都假設是一個二元 (Bernoulli, boolean) 變數
class sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)alpha:平滑因子,與多項式中的alpha一致,
binarize:樣本特征二值化的閾值,默認是0,如果不輸入,則模型會認為所有特征都已經是二值化形式了;如果輸入具體的值,則模型會把大于該值的部分歸為一類,小于的歸為另一類,
fit_prior:是否去學習類的先驗概率,默認是True
class_prior:各個類別的先驗概率,如果沒有指定,則模型會根據資料自動學習, 每個類別的先驗概率相同,等于類標記總個數N分之一,
class_log_prior_:每個類別平滑后的先驗對數概率,feature_log_prob_:給定特征類別的經驗對數概率,class_count_:擬合程序中每個樣本的數量,feature_count_:擬合程序中每個特征的數量,
這些都是可以通過嘗試進行探索,總的來說,紙上得來終覺淺,絕知此事要躬行,
優點缺點、引數總結
MultinomialNB 和 BernoulliNB 都只有一個引數 alpha,用于控制模型復雜度,
alpha 的作業原理是,演算法向資料中添加 alpha 這么多的虛擬資料點,這些點對所有特征都取正值,這可以將統計資料“平滑化”(smoothing), alpha 越大,平滑化越強,模型復雜度就越低,
演算法性能對 alpha 值的魯棒性相對較好,也就是說, alpha 值對模型性能并不重要,但調整這個引數通常都會使精度略有提高,
GaussianNB 主要用于高維資料,而另外兩種樸素貝葉斯模型則廣泛用于稀疏計數資料,比
如文本,
MultinomialNB 的性能通常要優于 BernoulliNB,特別是在包含很多非零特征的資料集(即大型檔案)上,樸素貝葉斯模型的許多優點和缺點都與線性模型相同,它的訓練和預測速度都很快,訓練
程序也很容易理解,
該模型對高維稀疏資料的效果很好,對引數的魯棒性也相對較好,樸素貝葉斯模型是很好的基準模型,常用于非常大的資料集,在這些資料集上即使訓練線性模型可能也要花費大量時間,

每文一語
堅持也是一種快樂!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423171.html
標籤:AI
上一篇:協同過濾推薦演算法