本文我們介紹幾個常用回歸模型度量引數,分別對比它們之間的差異和應用場景,
回歸模型常用于量化一個或多個預測變數與回應變數之間的關系,當擬合回歸模型時,我們需要了解預測變數預測回應變數的程度,常用指標有:mean squared error (MSE) 和 the root mean squared error (RMSE),另外還包括R-Squared,
MSE(均方誤差)
判定預測模型的準確度的常用方法是均方差MSE( mean squared error),計算公示為:
MSE = (1/n) * Σ(actual – prediction)^2
- Σ 求和符號
- n 樣本大小
- actual 實際資料值
- prediction 預測資料值
mse越小,預測模型準確性越高,
對于邏輯回歸模型預測誤差計算公式不同,因為回應變數為二值,通常度量變數為總體分類誤差率:
Total misclassification rate = (# incorrect predictions / # total predictions)
分類誤差率越低,模型預測回應變數結果越好,
RMSE(均方根誤差)
均方誤差的平方根,RMSE越小,模型擬合程度越好,
RMSE = √ Σ ( y ^ i – y i ) 2 / n  ̄ \overline{Σ(?_i – y_i)^2 / n } Σ(y^?i?–yi?)2/n?
- Σ 求和符號
- n 樣本大小
- ?i 為第i個觀測記錄的預測值
- yi 為第i個觀測記錄的觀測值
我們看公式幾乎一樣,RMSE就是MSE的平方根,
RMSE Vs. MSE
實際在評估模型擬合程度時,通常使用RMSE,因為它與回應變數度量單位一樣,理解起來更直觀,相反MSE是回應變數的平方,
實際應用中我們會對同一資料集使用多個模型進行擬合并計算它們的RMSE,然后選擇最低RMSE的模型作為最佳模型,因為其預測值更接近實際值,相較MSE,RMSE解釋起來更直接,
RMSE Vs. R-Squared
R-Squared
也稱為決定系數,它是衡量線性回歸模型擬合資料集的程度,表示一定比例回應變數的方差能夠被預測變數解釋,R-Squared 取值范圍是0 ~ 1,R-Squared 值越高,模型擬合資料集越好,0 表示回應變數完全不能被預測變數解釋,1表示回應變數可以完美無誤被預測變數解釋,
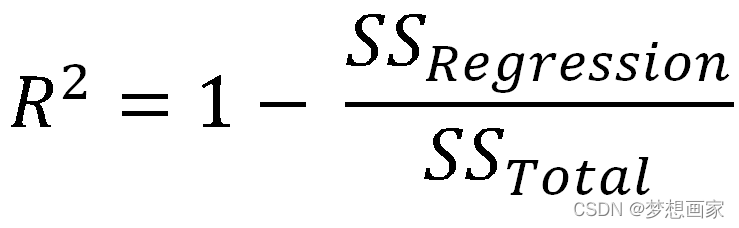
那么R-Squared值為多少時表示好呢?
首先,R-Squared值并不表示預測變數與回應變數之間的相關性,
其次,R-Squared值越大,則預測變數預測會越準確,到底多大要取決于研究領域,如在科研領域可能需要0.95以上視為可靠,在其他領域資料中包括極值可能大于0.3就已滿足,為了獲得準確值,可能需要按照特定領域普遍接受值,也可以客戶溝通具體能夠接受值,一般認為0.8以上能夠被接受,
RMSE 和 R-Squared 兩者都可以度量模型的擬合程度,前者表示預測值與實際值直接的誤差,R-Squared表示回應變數能夠被預測變數解釋的比例,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423310.html
標籤:AI
上一篇:周志華《機器學習》個人筆記