剪枝引數
作為
天生過擬合
的模型,
XGBoost
應用的核心之一就是減輕過擬合帶來的影響,作為樹模型,減輕過擬合的方式主要是靠對決策樹
剪枝
來降低模型的復雜度,以求降低方差,在之前的博文中,已經介紹了好幾個可以用來防止過擬合的引數,包括上一節提到的復雜度控制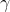 ,正則化的兩個引數
,正則化的兩個引數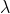 和
和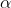 ,控制迭代速度的引數
,控制迭代速度的引數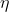 以及管理每次迭代前進行的隨機有放回抽樣的引數subsample
,所有的這些引數都可以用來減輕過擬合,但除此之外,我們還有幾個影響重大的,專用于剪枝的引數:
以及管理每次迭代前進行的隨機有放回抽樣的引數subsample
,所有的這些引數都可以用來減輕過擬合,但除此之外,我們還有幾個影響重大的,專用于剪枝的引數:
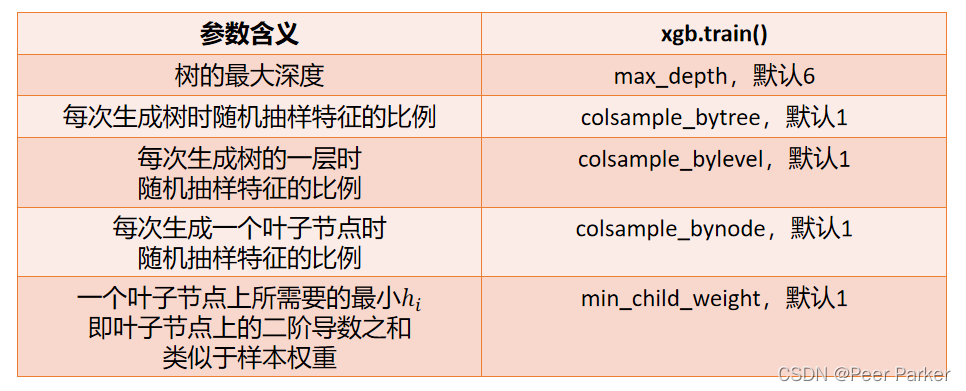
這些引數中,
樹的最大深度是決策樹中的剪枝法寶
,算是最常用的剪枝引數,不過在XGBoost中,最大深度的功能與引數相似,因此如果先調節了,則最大深度可能無法展示出巨大的效果,當然,如果先調整了最大深度,則也有可能無法顯示明顯的效果,通常來說,這兩個引數中我們只使用一個,不過兩個都試試也是不錯的選擇,
三個隨機抽樣特征的引數中,前兩個比較常用,在建立樹時對特征進行抽樣其實是決策樹和隨機森林中比較常見的一種方法,但是在XGBoost
之前,這種方法并沒有被使用到
boosting
演算法當中過,
Boosting
演算法一直以抽取樣本(橫向抽樣)來調整模型過擬合的程度,而實踐證明其實縱向抽樣(
抽取特征
)更能夠防止過擬合,
引數
min_child_weight
不太常用,它是一篇葉子上的二階導數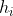 之和,當樣本所對應的二階導數很小時,比如說為0.01,
min_child_weight
若設定為
1
,則說明一片葉子上至少需要
100個樣本,本質上來說,這個引數其實是在
控制葉子上所需的最小樣本量
,因此對于樣本量很大的資料會比較有效,就剪枝的效果來說,這個引數的功能也被替代了一部分,通常來說我們會試試看這個引數,但這個引數不是優先選擇,
之和,當樣本所對應的二階導數很小時,比如說為0.01,
min_child_weight
若設定為
1
,則說明一片葉子上至少需要
100個樣本,本質上來說,這個引數其實是在
控制葉子上所需的最小樣本量
,因此對于樣本量很大的資料會比較有效,就剪枝的效果來說,這個引數的功能也被替代了一部分,通常來說我們會試試看這個引數,但這個引數不是優先選擇,
調參策略
通常當我們獲得了一個資料集后,我們先使用網格搜索找出比較合適的
n_estimators(num_round)
和
eta
組合,然后使用
gamma
或者max_depth
觀察模型處于什么樣的狀態(過擬合還是欠擬合,處于方差
-
偏差影像的左邊還是右邊?),最后再決定是否要進行剪枝,通常來說,對于XGB
模型,大多數時候都是需要剪枝的,
波士頓房價資料集實戰
import datetime
import xgboost as xgb
import matplotlib.pyplot as plt
from time import time
from sklearn.datasets import load_boston
# 加載資料
data = load_boston()
X = data.data
y = data.target
# 讀取全資料
dfull = xgb.DMatrix(X,y)
# 引數設定
param1 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":6
,"eta":0.3
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5
,'verbosity':0}
num_round = 200
# 計算模型訓練時間
time0 = time()
cvresult1 = xgb.cv(param1, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
# 繪制迭代程序的均方誤差
fig,ax = plt.subplots(1,figsize=(15,10))
ax.grid()
ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
ax.legend(fontsize="xx-large")
plt.show()
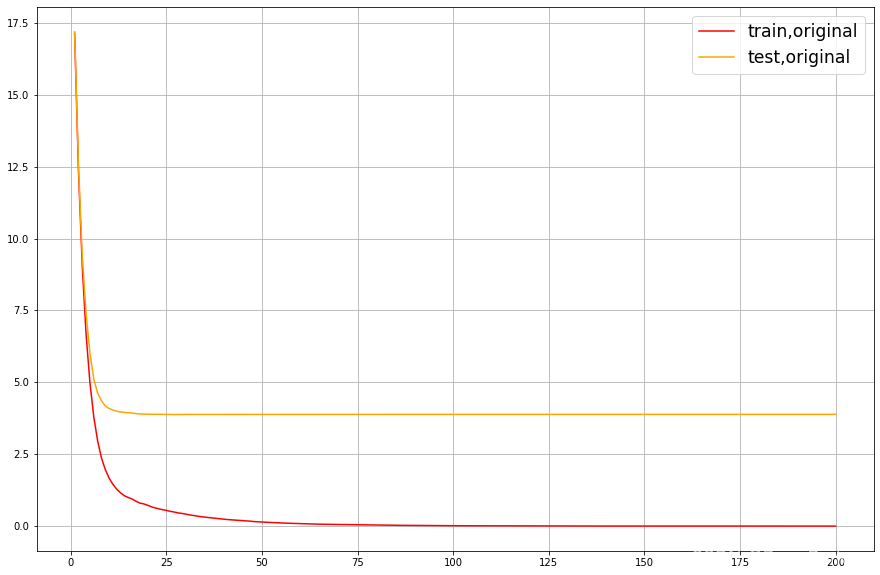
從曲線上可以看出,模型現在處于過擬合的狀態,我們決定要進行剪枝,我們的目標是:訓練集和測驗集的結果盡量接近,如果測驗集上的結果不能上升,那訓練集上的結果降下來也是不錯的選擇(讓模型不那么具體到訓練資料,增加泛化能力),在這里,我們要使用
三組曲線
,一組用于展示原始資料上的結果,一組用于展示上一個引數調節完畢后的結果,最后一組用于展示現在我們在調節的引數的結果,具體怎樣使用,我們來看:
# 調參結果1
param2 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":4
,"eta":0.05
,"gamma":20
,"lambda":3.5
,"alpha":0.2
,"colsample_bytree":0.4
,"colsample_bylevel":0.6
,"colsample_bynode":1
,"nfold":5
,'verbosity':0}
# 調參結果2
param3 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":2
,"eta":0.05
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":0.4
,"colsample_bynode":1
,"nfold":5
,'verbosity':0}
# 繪制對比圖
fig,ax = plt.subplots(1,figsize=(15,8))
ax.set_ylim(top=5)
ax.grid()
ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,last")
ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,last")
ax.plot(range(1,201),cvresult3.iloc[:,0],c="gray",label="train,this")
ax.plot(range(1,201),cvresult3.iloc[:,2],c="pink",label="test,this")
ax.legend(fontsize="xx-large")
plt.show()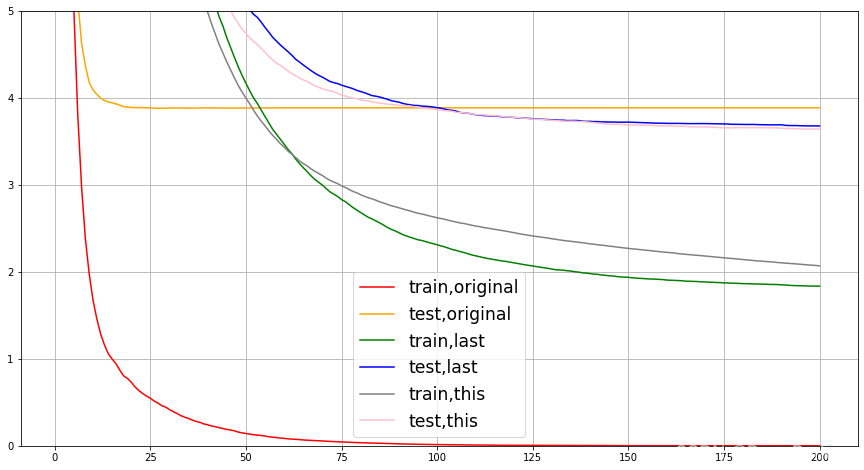
從上圖可以看到,XGBoost模型通過剪枝,模型的過擬合被削弱,泛化能力增強,且模型的復雜度降低!!!
調參建議
- 可以使用網格搜索進行調參,但是建議至少先使用xgboost.cv來確認引數的范圍,否則很可能花很長的時間做了無用功,并且,在使用網格搜索的時候,最好不要一次性將所有的引數都放入進行搜索,最多一次兩三個,有一些互相影響的引數需要放在一起使用,比如學習率eta和樹的數量n_estimators(num_round),
- 調參的時候引數的順序也會影響調參結果,因此在現實中,我們會優先調整那些對模型影響巨大的引數,在這里,我建議的剪枝上的調參順序是:n_estimators(num_round)與eta共同調節,gamma或者max_depth,采樣和抽樣引數(縱向抽樣影響更大),最后才是正則化的兩個引數,當然,可以根據自己的需求來進行調整,
- 若調參之后測驗集上的效果還沒有原始設定上的效果好,但交叉驗證曲線確實顯示測驗集和訓練集上的模型評估效果是更加接近的,推薦使用調參之后的效果,我們希望增強模型的泛化能力,然而泛化能力的增強并不代表著在新資料集上模型的結果一定優秀,因為未知資料集并非一定符合全資料的分布,在一組未知資料上表現十分優秀,也不一定就能夠在其他的未知資料集上表現優秀,因此不必過于糾結在現有的測驗集上是否表現優秀,當然了,在現有資料上如果能夠實作訓練集和測驗集都非常優秀,那模型的泛化能力自然也會是很強的,
繼續加油,我們一定會成功的!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423313.html
標籤:AI
上一篇:Machine Learning Lecture Notes
下一篇:論文寫作技巧總結